RISK 5.5 - Logiciel informatique PALISADE - Notice d'utilisation et mode d'emploi gratuit
Retrouvez gratuitement la notice de l'appareil RISK 5.5 PALISADE au format PDF.

| Type de produit | Logiciel d'analyse de risque |
| Marque | PALISADE |
| Modèle | RISK 5.5 |
| Version | 5.5 |
| Éditeur | Palisade Corporation |
| Plateforme | Microsoft Excel 2000 ou ultérieur |
| Système d'exploitation requis | Windows 2000 SP4, Windows XP ou version ultérieure |
| Matériel requis | PC Pentium ou compatible, disque dur |
| Fonctions principales | Simulation Monte Carlo et Hypercube latin, plus de 30 distributions de probabilités, analyse de sensibilité, ajustement de distributions, graphiques haute résolution |
| Types de distributions | Normale, Uniforme, Triangulaire, Bêta, Exponentielle, Lognormale, Poisson, Weibull, etc. |
| Intégration | Complément Microsoft Excel, barre d'outils et ruban dédiés |
| Langues | Français, anglais, et autres (traduction disponible) |
| Activation | Code d'activation, activation en ligne ou par email, période d'essai de 15 jours |
| Assistance technique | Support par email, téléphone, FAQ en ligne |
| Mise à jour | Téléchargement via le site web, correctifs disponibles |
| Sécurité | Signature numérique des macros, activation de licence |
| Entretien et nettoyage | Mise à jour régulière, désinstallation via Panneau de configuration |
| Informations générales | Notice de 724 pages incluse, manuel PDF téléchargeable |
FOIRE AUX QUESTIONS - RISK 5.5 PALISADE
Questions des utilisateurs sur RISK 5.5 PALISADE
0 question sur cet appareil. Repondez a celles que vous connaissez ou posez la votre.
Poser une nouvelle question sur cet appareil
Téléchargez la notice de votre Logiciel informatique au format PDF gratuitement ! Retrouvez votre notice RISK 5.5 - PALISADE et reprennez votre appareil électronique en main. Sur cette page sont publiés tous les documents nécessaires à l'utilisation de votre appareil RISK 5.5 de la marque PALISADE.
MODE D'EMPLOI RISK 5.5 PALISADE
Version 5.5
Palisade Corporation
798 Cascadilla St. Ithaca, NY USA 14850 +1-607-277-8000 +1-607-277-8001 (fax)
http://www.palisade.com (site Web)
sales@palisade.com (courriel)
Avis de copyright
Microsoft, Excel et Windows sont des marques déposées de Microsoft Corporation. IBM est une marque déposée d'International Business Machines, Inc. Palisade, TopRank, BestFit et RISKview sont des marques déposées de Palisade Corporation. RISK est une marque commerciale de Parker Brothers, une division de Tonka Corporation, exploitée sous licence.
@RISK pour microsoft excel
Bienvenue à @RISK, système logiciel révolutionnaire conçu pour l'analyse des situations commerciales et techniques sujettes au risque! Les techniques d'analyse du risque sont considérées depuis longtemps comme des outils puissants auxquels font appel les décideurs pour gérer avec succès les situations sujettes à l'incertitude. Elles sont toutefois d'une utilisation peu répandue en raison de leur coût élevé et des nombreux calculs nécessaires qui en rendent l'exploitation difficile. L'informatisation croissante des secteurs scientifiques et commerciaux laisse désormais entrevoir la mise à disposition de ces techniques à tous les décideurs.
@RISK (prononcé « at risk ») fait enfin du réve réalité, en dotant le tableau Microsoft Excel de ces techniques. @RISK et Excel permettent de modéliser n'importe quelle situation hasardeuse, qu'elle soit de nature commerciale, scientifique ou technique. Personne ne peut évaluer moins que vous les besoins de vos analyses. @RISK, allié aux fonctions de modélisation d'Excel, vous permet de concevoir un modèle répondant à ces besoins. Face à chaque décision ou analyse sujette à l'incertitude, @RISK vous dresse un tableau plus précis de ce que pourrait vous réserver l'avenir.
Nécessité de l'analyse de risque et de @RISK
Les analyses traditionnelles associant de simples estimations « ponctuelles » aux variables d'un modèle pour prédire un résultat unique. Il s'agit là du modèle Excel standard : la feuille de calcul représentant une estimation de résultats unique. Vous devez estimer les variables du modèle, car les valeurs réelles ne sont pas connues avec certitude. Dans la réalité, les choses ne tournent cependant souvent comme prévu. Certaines estimations sont parfois trop conservatrices, et d'autres, trop optimistes. Les erreurs combinées de chacune donnent souvent lieu à une différence considérable entre les résultats estimés et la réalité avérée. Une décision prise en fonction d'un résultat « espéré » aurait peut-être été évitée en présence d'un aperçu plus complet de toutes les issues possibles. Toutes les décisions commerciales, techniques, scientifiques et autres reposent sur des estimations et des suppositions. @RISK vous permet d'inclure explicitement l'incertitude présente dans vos estimations et de
générer ainsi des résultats traduisant toutes les conséquences possibles.
@RISK fait appel à une technique dite « de simulation » pour regrouper tous les aléas identifiés dans une situation de modélisation. Vous n'êtes plus obligé de réduire à un seul nombre ce que vous savez d'une variable. Vous pouvez plutôt inclure tout ce que vous en savez, y compris la plage complète de valeurs possibles et la vraisemblance de chacune. Au moyen de toutes ces informations et du modèle Excel défini, @RRISK analyse tous les résultats possibles, comme si vous analysiez tout à la fois des centaines ou même des milliers de scénarios hypothétiques! De fait, @RISK vous présente l'éventail complet des issues possibles de la situation à l'étude. Un peu comme si vous pouviez « vivre et revivre », encore et encore, la situation, mais dans des circonstances à chaque fois différentes, et avec les résultats variables qui en émanent.
Cette avalanche d'informations semble susceptible de compliquer vos décisions, mais, en fait, l'un des points forts de la simulation reste dans sa puissance de communication. Les résultats produits par @RISK illustrent graphiquement les risques auxquels vous vous trouvez confronté. Vous n'aurrez aucune difficulté à comprendre cette présentation graphique, et vous pourrez l'expliquer aisément à vos interlocuteurs.
Ainsi l'utilisation de @RISK s'avère utile et nécessaire chaque fois que vous effectuez dans Excel une analyse sujette à l'incertitude. Dans les secteurs commerciaux, scientifiques et techniques, @RISK trouve des applications quasiment illimitées, à partir de modèles Excel existants. Les analyses @RISK peuvent être exploitées en autonome ou apporter les résultats nécessaires à d'autres analyses. Pensez aux décisions que vous prenez et aux analyses que vous réalisez chaque jour. S'il vous arrive de penser à l'incidence possible du risque sur ces situations, vous disposez d'une bonne raison d'utiliser @RISK!
Fonctions de modélisation
En tant que « compagnon » de Microsoft Excel, @RISK se « lie » à Excel et y ajoute ses fonctionnalités d'analyse du risque. Le système @RISK apporte tous les outils nécessaires à la configuration d'analyses du risque, à leur exécution et à l'affichage de leurs résultats. Son interface vous sera parfaitement familière, avec ses menus et fonctions de style Excel.
@RISK permet de définir les valeurs incertaines de cellules Excel sous forme de distributions faisant appel à des fonctions. @RISK ajoute de nouvelles fonctions à l'ensemble de fonctions Excel, permettant chacune de spécifier un type de distribution différent comme valeur de cellule. Les fonctions de distribution peuvent être ajoutées à un nombre quelconque de cellules et de formules, dans toutes vos feuilles de calcul. Elles peuvent aussi inclure des arguments (références de cellule et expressions) et permettent ainsi une specification extrémentement précise de l'incertitude. Pour facilitier l'affectation des distributions aux valeurs incertaines, @RISK permet leur affichage et leur ajout aux formules dans une fenêtre contextuelle graphique.
Types de distribution disponibles
Les distributions de probabilités proposées par @RISK permettent d'indiquer, pour ainsi dire, n'importe quel type d'incertitude dans les valeurs de cellule d'une feuille de calcul. Une cellule contenant la fonction de distribution NORMAL(10;10), par exemple, renvoie des échantillons prélevés d'une distribution normale (moyenne = 10, écarts type = 10) au cours d'une simulation. Les fonctions de distribution ne sont invoquées qu'en cours de simulation - dans les opérations Excel normales, elles représentent une seule valeur de cellule - tout comme Excel avant @RISK. Les types de distribution disponibles sont les suivants :
| Bêta | Bêta générale | Bêta subjective |
| Binomiale | Chi carré | Cumulative |
| Discrète | Uniforme discrète | Fonction d'erreur |
| Erlang | Exponentielle | Valeur extrête |
| Gamma | Générale | Géométrique |
| Histogramme | Hypergéométrique | Gauss inverse |
| Uniforme nombre entier | Logistique | Logistique logarithmique |
| Normale logarithmique | Normale logarithmique 2 | Binomiale négative |
| Normale | Pareto | Pareto2 |
| Pearson V | Pearson VI | PERT |
| Poisson | Rayleigh | Student t |
| Triangulaire | Triangulaire générale | Uniforme |
| Weibull |
Toutes les distributions peuvent être tronquées et limitées ainsi aux échantillons compris dans des plages de valeurs données. Beaucoup de distributions peuvent aussi être assorties de paramètres secondaires, exprimés en centiles. Cette approche permet de spécifier les valeurs de centiles particuliers d'une distribution en entrée, par opposition aux arguments traditionnels de la distribution.
Analyse de simulation @RISK
@RISK est doté de fonctionnalités sophistiquées permettant de spécifier et d'exécuter les simulations de modèles Excel. Les techniques d'échantillonnage Monte Carlo et Hypercube latin sont toutes deux prises en charge, et les distributions de résultats possibles peuvent être générées pour une cellule ou une plage de cellules quelconque du modèle définis dans le tableau. Les options de simulation et la sélection des sorties du modèle se configuent à l'aide de menus et boîtes de dialogue de style Windows, au moyen de la souris.
Graphiques
Des graphiques haute résolution illustrent les distributions de sortie des simulations @RISK. Les histogrammes, courbes cumulatives et graphiques de synthèse de plages de cellules sont autant d'outils remarquablement efficaces de présentation des résultats. Tous les graphiques peuvent être affichés dans Excel, en vue de leur amélioration ou de leur impression. Une seule simulation suffit à générer un nombre pratiquement illimité de distributions de sortie, permettant l'analyse de feuilles de calcul extrêmement volumineuses et complexes!
Capacités de simulation expertes
Les options de contrôle et d'exécution de simulation dans @RISK sont d'une puissance exceptionnelle. Elles comprennent :
- échantillonnage Hypercube latin ou Monte Carlo
- nombre quelconque d'itérations par simulation
- nombre quelconque de simulations par analyse
- animation de l'échantillonnage et recalcul de la feuille
- définition du générateur de nombres aléatoires
- résultats et statistiques en temps réel, en cours de simulation
Affichages graphiques à haute résolution
@RISK représente graphiquement une distribution de probabilités des résultats possibles pour chaque cellule de sortie sélectionnée dans @RISK. Les graphiques @RISK comprennent :
- distributions de fréquence relative et courbes cumulatives de probabilité
- graphiques de synthèse pour distributions multiples sur plages de cellules (ligne ou colonne de feuille de calcul, par exemple)
- rapports statistiques des distributions générées
- probabilité des valeurs cibles d'une distribution
- exportation des graphiques comme métafichiers Windows à des fins d'amélioration
Vitesse d'exécution
La durée d'exécution est d'une importance critique car la simulation comporte de nombreux calculs. @RISK est conçu pour une vitesse de simulation optimale grâce à l'utilisation de techniques d'échantillonnage évoluées.
Table des matières
Chapitre 1: Mise en route 1
Installation 7
Activation du logiciel. 10
Démarrage rapide 13
Chapitre 2 : Présentation de l'analyse de risque 17
Définition du risque 21
Définition de l'analyse de risque 25
Elaboration d'un modèle @RISK. 27
Analyse d'un modèle avec simulation 29
Prise de décision : Interprétation des résultats 33
Limites de l'analyse de risque 37
Chapitre 3: Guide de mise à niveau 39
Nouvelles barres d'outils, icônes et commandes @RISK......43
Construction d'un modèle @RISK. 47
Paramètres de simulation 69
Simulations 73
Résultats graphiques d'une simulation 75
Rapports de résultats de simulation 85
Enregistrement des simulations 93
Bibliothèque @RISK 95
Chapitre 4: Présentation sommaire de @RISK 97
Présentation rapide de @RISK 99
Configuration et simulation d'un modèle @RISK 111
Chapitre 5: Techniques de modélisation @RISK 143
Modélisation de taux d'intérêts et autres tendances 147
Projection de valeurs connues dans l'avenir 149
Modélisation d'événements incertains ou « aléatoires » 151
Puits de pétrole et sinistres d'assurance 153
Introduction de l'incertitude autour d'une tendance fixe. 155
Relations de dépendance 157
Simulation de sensibilité 159
Simulation d'un nouveau produit 161
Identification de la valeur à risques (VAR) d'un portefeuille....171
Simulation d'un tournoi de la NCAA 175
Chapitre 6: Ajustement de distributions 179
Définition des données en entrée 183
Sélection des distributions à ajuster 187
Exécution de l'ajustement 189
Interprétation des résultats 193
Application des résultats de l'ajustement. 201
Chapitre 7: Guide de référence @RISK 203
Référence : Icones @RISK 213
Référence : Commandes @RISK 223
Commandes Modèle 225
Commandes d'ajustement de distributions 281
Commandes Distribution Artist 301
Commandes Paramètres 305
Commandes Simulation 323
Simulation-Analyses avancées. 325
Valeur cible 327
Analyse de contrainte 335
Analyse de sensibilité avancée 349
Commandes Résultats 365
Commande Rapports Excel 393
Commande : Permuter les fonctions @RISK. 395
Commandes Utilitaires 403
Enregistrement et ouverture de simulations @RISK. 411
Commandes Bibliothèque 415
Commandes d'aide 417
Référence : Graphiques @RISK 419
Référence : Fonctions @RISK 453
Tableau des fonctions disponibles 465
Référence : Fonctions de distribution 479
Référence : Fonctions de propriété des distributions 595
Référence : Fonctions de sortie 611
Référence : Fonctions statistiques 613
Référence : Fonctions Six Sigma 625
Référence : Fonctions supplémentaires 637
Référence : Fonction graphique 639
Référence : Bibliothèque @RISK 641
Distributions dans la Bibliothèque @RISK 643
Résultats dans la Bibliothèque @RISK 649
Référence : Kit de développement @RISK pour Excel (XDK) 659
Annexe A: Méthodes d'échantillonnage 661
Définition de l'échantillonnage 661
Annexe B: Utilisation de @RISK avec d'autres outils DecisionTools 669
DecisionTools Suite 669
DecisionTools - Étude de cas 673
TopRank 675
@RISK avec TopRank 679
PrecisionTreeTM 683
@RISK avec PrecisionTree 687
Annexe C : Glossaire 691
Glossaire 691
Annexe D: Lectures recommandées 697
Lectures par catégorie 697
Index 701
Chapitre 1 : mise en route
Contenu du coffret 3 A propos de cette version 3 Votre compte d'exploitation 4 Si vous avez besoin d'aide 4 Configuration requise 6
Installation 7
Généralités 7 DecisionTools Suite. 8 Configuration des icônes ou raccourcis @RISK 8 Messages d'avertissement de sécurité des macros au démarrage...9
Démarrage rapide 13
Didacticiel en ligne 13 Pour démarrer vous-même 13 Démarrage rapide avec vos propres feuilles de calcul. 14 Feuilles de calcul @RISK 5.5 sous les versions @RISK 3.5 et antérieures............15 Feuilles de calcul @RISK 5.5 sous la version @RISK 4.0............15 Feuilles de calcul @RISK 5.5 sous la version @RISK 4.5............16
Cette introduction décrit le contenu de votre coffret @RISK et vous indique comment installer et relier @RISK à votre copie de Microsoft Excel 2000 pour Windows ou version supérieure.
Contenu du coffret
Le coffret @RISK doit contenir les éléments suivants :
ce guide d'utilisation @RISK complétant les sections suivantes :
- Mise en route
- Présentation de l'analyse de risque et de @RISK Guide de mise à niveau
- Présentation sommaire de @RISK Techniques de modélisation @RISK
- Ajustement de distributions Guide de référence @RISK Annexes techniques
le CD-ROM @RISK, comportant
la licence d'exploitation de @RISK
Si votre coffret est incomplet, prenez contact avec votre revendeur @RISK ou appelez Palisade Corporation directement au +1 -607-277-8000.
Cette version de @RISK est compatible avec les versions Microsoft Excel 2000 et ultérieures.
Votre contexte d'exploitation
Les descriptions contenues dans ce guide présupposent une connaissance générale du système d'exploitation Windows et du tableur Excel, notamment :
familiarité avec l'ordinateur et la souris - compréhension des termes icônes, cliquer, double-clic, menu, fenêtre, commande, objet, etc. notions élémentaires de structure de répertoires et désignation des fichiers
Si vous avez besoin d'aide
Un service d'assistance technique est proposé gratuitement à tous les utilisateurs enregistrés de @RISK dotés d'un plan de maintenance courant, ou sur forfait à l'incident. Pour assurer que vous êtes bien un utilisateur enregistré de @RISK, enregistrez-vous en ligne sur www.palisode.com/support/register.asp.
Si vous nous contactez par téléphone, soyez prêts à nous communiquer le numéro de série de vos outils et gardez votre guide d'utilisation à portée de main. Nous pourrons vous être d'une meilleure assistance si vous vous trouvez face à votre ordinateur, prêts à exécuter les commandes du programme.
Avant d'appeler
Avant d'appeler le service d'assistance technique, passez en revue la liste de contrôle suivante :
- Avez-vous consulté l'aide en ligne?
- Avez-vous consulté ce manuel et passé en revue le didacticiel multimédia en ligne ?
- Avez-vous consulté le fichier LISEZMOI ? Il contient des informations sur @RISK non disponibles lors de l'impression du manuel.
- Pouvez-vous reproduire le problème de manière constante ? Pouvez-vous reproduire le problème sur un autre ordinateur ou avec une autre méthode ?
- Avez-vous consulté notre site Web, à l'adresse http://www.palisade.com? Vous y trouvez notre dernier fichier FAQ (base de données consultable de questions et réponses techniques) et les correctifs @RISK dans la section de support technique. Il est utile de consulter régulièrement notre site pour obtenir les dernières informations publiées sur @RISK et sur les autres logiciels Palisade.
Contacter palisade
Vos questions, commentaires ou suggestions au sujet de @RISK sont les bienvenus! Vous pouvez prendre contact avec notre personnel d'assistance technique par l'une des méthodes suivantes:
Courriel: support@palisade.com - Téléphone: +1-607-277-8000, du lundi au vendredi, de 9 à 17 heures, heures de l'Est des États-Unis. Suivez les instructions données pour joindre l'Assistance technique (Technical Support). - Fax: +1-607-277-8001 - Adresse postale :
Palisade Asie-Pacifique :
Courriel: support@palisade.com.au - Téléphone: +61 2 9929 9799 (Australie) - Fax: +61 2 9954 3882 (Australia) - Adresse postale: Palisade Asia-Pacific Pty Limited Suite 101, Level 1 8 Cliff Street Milsons Point NSW 2061 AUSTRALIA
Quelle que soit la méthode voie, veillez à indiquer le nom de votre produit, sa version exacte et son numéro de série. La version exacte de votre produit est indiquée sous la commande Aide, À propos de... du menu @RISK proposé dans Excel.
L'assistance téléphonique n'est pas disponible pour la version étudiants de @RISK. Si vous avez besoin d'aide, procédez de l'une des manières suivantes :
- Consultez votre professeur ou assistant.
- Consultez le fichier FAQ sur http://www.palisade.com.
- Adressez-vous au service d'assistance technique par courriel ou par fax.
Configuration requise
Configuration requise pour l'installation de @RISK 5.5 pour Microsoft Excel pour Windows :
- PC Pentium ou Mistroux avec disque dur.
- Microsoft Windows 2000 SP4, Windows XP ou mistrues.
- Microsoft Excel 2000 ou versions ultérieures.
Généralités
Le programme d'installation copie les fichiers système @RISK dans un répertoire spécifique du disque dur. Sous Windows 2000 ou version ultérieure :
1) Insérez le CD-ROM @RISK dans le lecteur CD-ROM. 2) Cliquez sur le bouton Démarrer, puis sur Paramètres et enfin sur Panneau de configuration. 3) Cliquez deux fois sur l'icône Ajout/Suppression de programmes. 4) Cliquez sur le bouton Installer de l'onglet Installation/désinstallation. 5) Suivez les instructions d'installation affichées à l'écran.
En cas de problème, vérifie que vous disposez d'un espace suffisant sur le disque prévu pour l'installation. Après avoir libéré l'espace disque requis, essayez de réexécuter l'installation.
Suppression de @RISK de l'ordinateur
Pour désinstaller @RISK, utilisez l'utilitaire Ajout/Suppression de programmes du Panneau de configuration et sélectionnez l'entrée correspondant à @RISK.
@RISK pour Excel fait partie de la série d'outils d'analyse du risque et de décision DecisionTools Suite, décrite à l'Annexe D : Utilisation de @RISK avec d'autres outils DecisionTools. L'installation par défaut de @RISK place le programme dans un sous-répertoire du répertoire principal « Program Files\Palisade », de la même manière qu'Excel s'installe généralement dans un sous-répertoire du répertoire « Microsoft Office »
Ce sous-répertoire de Program Files\Palisade devient le répertoire @RISK (appelé par défaut, RISK5). Ce répertoire contient les fichiers programmes, plus les modèles types et les autres fichiers nécessaires à l'exécution de @RISK. Un autre sous-répertoire de Program Files\Palisade, intitulé SYSTEM, reçoit les fichiers nécessaires à tous les programmes de la série DecisionTools Suite, y compris les fichiers d'aide et bibliothèques communes.
Configuration des icônes ou raccourcis @RISK
Création du raccourci sur la barre des tâches Windows
L'installation crée automatiquement une commande @RISK dans le menu Programmes de la barre des tâches. Si toutefois vous rencontrez des problèmes en cours d'installation ou que vous souhaitez exécuter cette opération ultérieurement, procédez comme suit :
1) Cliquez sur le bouton Démarrer et pointez sur Paramètres. 2) Cliquez sur Barre des tâches, puis sur l'onglet Programmes du menu Démarrer. 3) Cliquez sur Ajouter, puis sur Parcourir. 4) Repérez le fichier RISK. EXE et cliquez deux fois dessus. 5) Cliquez une fois sur Suivant, puis deux fois sur le menu de votre choix. 6) Tapez le nom « @RISK » et cliquez sur Terminer.
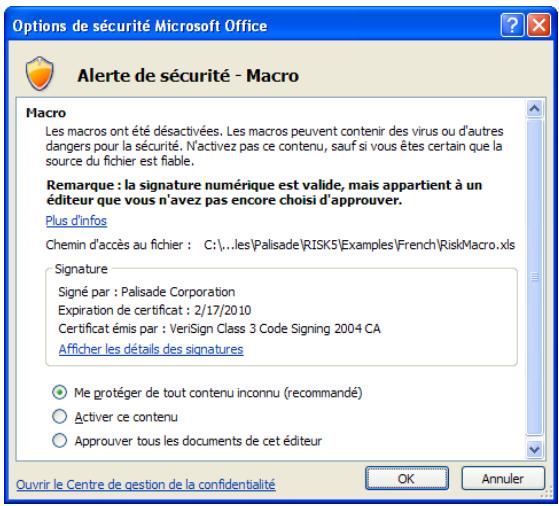
Messages d'avertissement de sécurité des macros au démarrage
Microsoft Office propose plusieurs paramètres de sécurité (sous Outils>Macro>Sécurité) pour éviter l'exécution de macros indésirables ou hostiles dans vos applications Office. Sauf sous le paramètre de sécurité le plus faible, un message d'advertissement s'affiche à chaque tentative de chargement d'un fichier assorti de macros. Pour éviter l'affichage de ce message à chaque exécution d'une macro complémentaire Palisade, Palisade signe numériquement des fichiers. Après avoir spécifié Palisade Corporation en tant que source fiable, vous pouvez alors ouvrir les macros Palisade sans message d'advertissement. Pour ce faire :
- Sélectionnez l'option Approuver tous les documents de cet éditeur lorsqu'une boîte de dialogue Avertissement de sécurité (telle que celle illustrée ci-dessous) s'ouvre au démarrage de @RISK.
Activation du logiciel
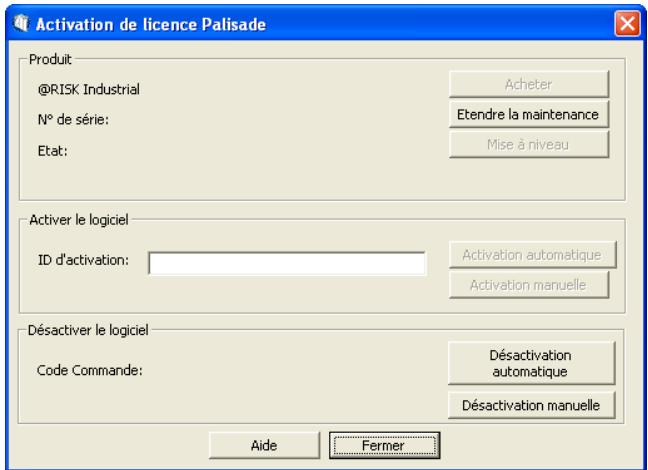
L'activation est une opération de vérification de licence exigée, une seule fois, pour l'exploitation du logiciel @RISK sous pleine autorisation. Notre code d'activation (séquence de type « 19a0-c7c1-15ef-1be0-4d7f-cd ») figure sur la facture qui vous a été envoyée par courrier ou par courriel. Si vous entrez ce code au moment de l'installation, votre logiciel s'active dès la première exécution et aucune autre intervention n'est nécessaire. Pour activer le logiciel après l'installation, CHOISSEZ la commande Activation de licence dans le menu d'aide de @RISK et entrez votre code d'activation dans la boîte de dialogue d'activation qui s'affiche.
Foire aux questions
Que se passera-t-il si mon LOGiciel n'est pas activé?
Si vous n'entrez pas de code d'activation lors de l'installation ou que vous installez une version d'essai, votre logiciel s'exécutera en tant que tel et sera soumis aux limites de temps/ nombre d'ouvertures applicables. Pour disposer d'une logithèque sous licence pleinement autorisée, vous devrez l'activer sous le code d'activation approprié.
2) Pendant combien de temps puis-je utiliser le logiciel avant de l'activer ?
Le logiciel non activé s'exécute pendant 15 jours. Toutes les fonctions sont accessibles, mais la boîte de dialogue d'activation de la licence s'ouvre à chaque démarrage du programme pour vous indiquer le temps d'exploitation restant sans activation. Au bout de la période d'essai de 15 jours, le logiciel ne s'exécutera plus que s'il est activé.
3) Comment vérifier l'objet d'activation de mon logiciel ?
La commande Activation de licence du menu d'aide de @RISK donne accès à la boîte de dialogue d'activation. Le logiciel activé y figure sous l'état Activé et la version d'essai, sous l'état Non activé. Si le logiciel n'est pas activé, la durée restante de la période d'essai est indiquée.
4) Comment activer mon logiciel ?
En l'absence de code d'activation, cliquez sur le bouton Acheter de la boîte de dialogue Activation de licence. En cas d'achat en ligne, vous recevez immédiatement un code d'activation et un lien (facultatif) de téléchargement du programme d'installation, au cas où la réinstallation du logiciel serait nécessaire. Pour acheter @RISK par téléphone, prenez contact avec votre représentation Palisade locale, au numéro indiqué dans ce chapitre sous Contacter Palisade.
L'activation peut se faire sur Internet ou par courriel :
- Si vous avez accès à Internet
Dans la boîte de dialogue Activation de licence, tapez ou collez votre code d'activation et cliquez sur « Automatique via Internet ». Un message de confirmation devrait s'afficher après quelques secondes et la boîte de dialogue Activation de licence doit refléter l'état activé du calculiciel.
- Si vous n'avez pas accès à Internet
Pour activer votre logiciel par courriel, procédez comme suit :
- Cliquez sur « Manuel par courriel » pour ouvrir le fichier de demande request.xml, à enregistrer sur disque ou copier dans le Presse-Papiers Windows. (Ne manquez pas de noter le lieu d'enregistrement de ce fichier sur votre ordinateur.)
- Copiez ou joignez le fichier XML à un courriel adressé à activation@palisade. com. Vous devriez recevoir rapidement une confirmation automatique par retour de courriel.
- Enregistrez le fichier response.xml joint au courriel de réponse sur votre disque dur.
- Cliquez sur le bouton Traiter qui apparaitMAINANT dans la boite de dialogue d'activation de licence Palisade et naviguez jusqu'au fichier response. xml. Sélectionnez le fichier et cliquez sur OK.
Un message de confirmation devrait apparaitre et la boite de dialogue Activation de licence doit refléter l'état activé du logiciel.
5) Comment transférer ma licence logicielle sur un autre ordinateur?
Le transfert d'une licence, ou réhébergement, peut s'effectuer en deux étapes à travers la boîte de dialogue Activation de licence de Palisade : par désactivation sur le premier ordinateur, puis activation sur le second. Un exemple type de réhébergement consiste à transférer @RISK d'un PC de bureau sur portable. Pour transférer la licence de l'ordinateur1 à l'ordinateur2, veillez à ce que le logiciel soit installé sur les deux ordinateurs et à ce que les deux soient connectés à Internet pendant l'opération de désactivation/activation.
- Sur l'ordinateur1, CHOISISEZ LA DESACTIVATION Automatique via Internet dans la boîte de dialogue Activation de licence. Attendez que s'affiche le message de confirmation.
- Sur l'ordinateur2, CHOISISEZ L'activation Automatique via Internet. Attendez que s'affiche le message de confirmation.
Si les ordinateurs n'ont pas accès à Internet, suivez la procédure décrite plus haut pour l'activation par courriel.
6) J'ai accès à Internet mais je ne réussis pas à activer/désactiver automatiquement.
Votre barrière de sécurité doit être configurée de manière à autoriser l'accès TCP au serveur de licences. Pour les installations mono-utilisateur (hors réseau), il s'agit de http://service.palisade.com:8888 (port TCP 8888 sur http://service.palisade.com).
Didacticiel en ligne
Dans le didacticiel en ligne, des experts @RISK vous guident à travers différents modèles types en format cinéma. Ce didacticiel est une présentation multimédia des principales fonctionnalités de @RISK.
Pour y accéder, CHOISSEZ la commande Didacticiel du menu Aide de @RISK.
Pour démarrer vous-même
Si le temps presse, ou que vous désirez simplement explorer @RISK par vous-même, voici le moyen de démarrer rapidement.
Après avoir connecté @RISK selon les instructions d'installation indiquées plus haut, procédez comme suit :
1) Dans le menu Demarrer Programmes de Windows, cliquez sur l'icone @RISK dans le groupe Palisade DecisionTools. Si la fenetre de dialogue Avertissement de sécurité s'affiche, suivez les instructions enoncées dans la section « Configurer Palisade en tant que source fiable » de ce chapitre. 2) Utilisez la commande Ouvrir d'Excel pour ouvrir la feuille de calcul type FINANCE. XLS. Les exemple se trouvent par défaut dans le repertoire C:\PROGRAM FILES\PALISADE\RISK5\EXAMPLES\FRENCH. 3) Cliquez sur l'icone de fenêtre Modèle (flèche rouge et bleue) de la barre d'outils @RISK. La liste Sorties/Entrées des fonctions de distribution de la feuille de calcul FINANCE s'affiche, avec la cellule de sortie C10, VAN à 10%. 4) Cliquez sur l'icone Simuler (courbe de distribution rouge). Vous venez de démarrer une analyse de risque sur VAN pour la feuille de calcul FINANCE. L'analyse de simulation est en cours. La cellule de sortie s'affiche sous forme graphique pendant la simulation.
Pour toutes les analyses, si vous désirez suivre la simulation en temps réel avec @RISK, cliquez sur l'icône de mode Démo sur la barre d'outils @RISK. @RISK affiche les changements apportés à la feuille de calcul, itération par itération, et les résultats générés.
Démarrage rapide avec vos propres feuilles de calcul
La meilleure façon de vous préparer à utiliser @RISK sur vos propres feuilles de calcul passe par le didacticiel en ligne et la lecture du guide de référence. Si vous êtes pressé ou que le didacticiel ne vous intéresse pas, procédez comme suit pour utiliser @RISK dans vos propres feuilles de calcul :
1) Dans le menu Démarrer Programmes de Windows, cliquez sur l'icone @RISK dans le groupe Palisade DecisionTools. 2) Au besoin, utilisez la commande Ouvrir d'Excel pour ouvrir votre feuille de calcul. 3) Examinez votre feuille et identifiez les cellules contenant les suppositions ou entrées incertaines. Vous allez remplacer ces valeurs par des fonctions de distribution @RISK. 4) Entrez, pour les entrées incertaines, des fonctions de distribution qui reflètent la plage des valeurs possibles et leur probabilité. Commencez par les types de distribution simples (UNIFORM ne requiert par exemple qu'une valeur minimum et maximum possible, et TRIANG, qu'une valeur minimum, la plus probable et maximum possible). 5) Après avoir entre vos distributions, sélectionnez la ou les cellules de la feuille de calcul pour lesquelles vous souhaitez Obtenir les résultats de la simulation et cliquez sur l'icone Ajouter une sortie (simple flèche rouge) de la barre d'outils @RISK.
Pour exécuter une simulation :
- Cliquez sur l'icône Démarrer la simulation (courbe de distribution rouge) de la barre d'outils @RISK. La simulation de la feuille de calcul s'exécute et les résultats s'affichent à l'écran.
Feuilles de calcul @RISK 5.5 sous les versions @RISK 3.5 et antérieures
Les feuilles de calcul @RISK 5.5 ne sont compatibles avec les versions @RISK 3.5 ou antérieures du programme que sous les formes simples des fonctions de distribution. Sous ce format, seuls les paramètres de distribution obligatoires sont admis. Aucune nouvelle fonction de propriété de distribution @RISK 5.5 ne peut être ajoutée. De plus, les fonctions RiskOutput doivent être éliminées et les sorties, reselectionnées pour les simulations soumises à la version @RISK 3.5.
Feuilles de calcul @RISK 5.5 sous la version @RISK 4.0
Les feuilles de calcul @RISK 5.5 sont compatibles avec @RISK 4,0, sauf exceptions suivantes :
- Les fonctions à paramètres secondaires telles que RiskNormalAlt ne sont pas compatibles et renvoient une erreur.
- Les fonctions cumulatives décroissantes telles que RiskCumulD ne sont pas compatibles et renvoient une erreur.
- Les fonctions de propriété de distribution spécifiques à @RISK 5.5, telles que RiskUnits sont omises dans @RISK 4,0.
- Les fonctions statistiques spécifiques à @RISK 5.5 telles que RiskTheoMean renvoie #NOM dans @RISK 4.0.
- Les autres nouvelles fonctions propres à @RISK 5.5, telles que RiskCompound, les fonctions statistiques RiskSixSigma, RiskConvergenceLevel et les fonctions supplémentaires telles que RiskStopRun, renvoient #NOM dans @RISK 4.0.
Feuilles de calcul @RISK 5.5 sous la version @RISK 4.5
Les feuilles de calcul @RISK 5.5 sont compatibles avec @RISK 4.5, sauf exceptions suivantes :
- Les fonctions de propriété de distribution spécifiques à @RISK 5.5 telles que RiskUnits sont omises dans @RISK 4.5. Les fonctions qui les contiennent s'échantillonnent cependant ajustées.
- Les fonctions statistiques spécifiques à @RISK 5.5 telles que RiskTheoMean renvoient #NOM dans @RISK 4.5.
- Les autres nouvelles fonctions propres à @RISK 5.5, telles que RiskCompound, les fonctions statistiques RiskSixSigma, RiskConvergenceLevel et les fonctions supplémentaires telles que RiskStopRun, renvoient #NOM dans @RISK 4.5.
Chapitre 2: présentation de l'analyse de risque
Définition du risque 21
Caractéristiques du risque 21
Nécessité de l'analyse du risque 22
Évaluation et quantification du risque 23
Description du risque avec une distribution de probabilités....24
Définition de l'analyse de risque 25
Elaboration d'un modèle @RISK. 27
Variables 27
Variables de sortie 28
Analyse d'un modèle avec simulation 29
Simulation 29
Fonctionnement de la simulation 30
Autre approche de la simulation 31
Prise de décision : Interprétation des résultats 33
Interprétation d'une analyse traditionnelle 33
Interprétation d'une analyse @RISK 33
Préférences individuelles 34
Étagement de la distribution. 34
Asymétrie 36
Limites de l'analyse de risque 37
@RISK enrichit Microsoft Excel d'une capacité experte de modélisation et d'analyse du risque. Vous vous demandez peut-être si vos tâches répondent à des besoins de modélisation ou d'analyse du risque. Si vous utilisez des données pour résoudre des problèmes, faire des prévisions, élaborer des stratégies ou prendre des décisions, l'analyse de risque ne peut que vous être utile.
Modélisation est un terme générique désignant tout type d'activité qui vise à représenter une situation réelle en vue de son analyse. Notre représentation — ou modèle — peut servir à examiner la situation et vous aider à comprendre ce que l'avenir vous réserve. S'il vous est jamais arrivé de soumettre un projet à une situation « hypothétique », en modifiant les valeurs de ses entrées, vous n'aurez pas de difficulté à comprendre l'importance de l'incertitude dans une situation de modélisation.
Quels sont donc les éléments qui intervennent dans l'incorporation explicite du risque dans une analyse ou un modèle ? Nous allons tenter de répondre à cette question dans la description qui suit. Ne vous inquiétez pas, il n'est pas nécessaire d'être expert en statistiques ou en théorie décisionnelle pour analyser les situations sujettes au risque, et encore moins pour utiliser @RISK. Nous ne pouvons tout vous enseigner en quelques pages, mais nous allons vous mettre sur la bonne voie. L'utilisation de @RRISK vous permettra d'acquérir le type d'expertise qu'aucun livre ne pourrait vous apprendre.
Ce chapitre présente par ailleurs la manière dont @RISK et votre tableau s'associent pour executer leurs analyses. Il n'est pas nécessaire de connaître le fonctionnement de @RISK pour pouvoir l'utiliser, mais certaines explications peuvent s'avérer utiles et intéressantes. Ce chapitre aborde les sujets suivants :
- Définition et méthodes d'évaluation quantitative du risque. Nature de l'analyse de risque et techniques utilisées dans @RISK.
- Exécution d'une simulation
- Interprétation des résultats @RISK
- Limites de l'analyse de risque
Définition du risque
Tout le monde sait que le risque affecte le joueur sur le point de jeter les dés, le foreur sur le point de forer un puits de pétrole, ou le funambule sur le point de poser le pied sur la corde. Hormis ces simples exemples, le concept de risque trouve sa raison d'être dans le fait que nous reconnaissons le caractère incertain de l'avenir, notre incapacité de connaître le lendemain d'une action exécutée aujourd'hui. Dans la notion du risque se reflète la multiplicité des résultats possibles d'une action donnée.
En ce sens, toutes les actions sont risquées, de la traversée d'une rue à la construction d'un barrage. Toutefois, le terme est généralement réservé à des situations dans lesquelles l'éventail des issues possibles d'une action donnée est significatif. Les actions courantes, comme traverser la rue, ne sont généralement pas risquées ; en revanche, la construction d'un barrage peut présenter un risque substantiel. Entre ces deux extrêmes, il existe divers degrés de risques. Bien que vague, cette distinction est importante. Si vous estimez une situation hasardeuse, le risque devient un critère de décision dans la ligne de conduite à adopter, et une forme d'analyse du risque devient alors viable.
Caractéristiques du risque
Le risque découle de notre inaptitude à connaître l'avenir ; il indique un degré d'incertitude suffisant pour que nous le remarquions. Les caractéristiques importantes du risque permettent de cerner cette définition un peu vague.
En premier lieu, le risque peut être objectif ou subjectif. Jouer à pile ou face est un risque objectif car les chances sont connues. Bien que l'issue soit incertaine, la théorie, l'expérience ou le bon sens permettent de décrire en toute précision le risque objectif. Tout le monde s'accorde sur la description d'un risque objectif. En revanche, la description des chances qu'il pleuve le jour suivant est moins évidente : il s'agit là d'un risque subjectif. À partir des mêmes informations, théories, ordinateurs, etc., un météorologue A peut déterminer un risque de pluie de 30%, tandis que pour le météorologue B, ce risque est de 65%. Aucun des deux n'a tort. La description d'un risque subjectif est laissée à la libre interprétation de l'auteur dans la mesure où il peut toujours raffiner son évaluation sur la base de nouvelles informations, d'une étude plus approfondie, ou en considérant l'opinion d'autrui. La plupart des risques étant subjectifs, il y a là des implications importantes pour toute personne responsable d'analyser le risque ou de prendre des décisions en fonction d'une analyse de risque.
En deuxième lieu, décide qu'une opération est hasardeuse fait intervenir un jugement personnel, même en présence de risques objectifs. Supposons par exemple que vous gagniez 1 euro sur pile et que vous en perdiez 1 sur face. La marge comprise entre 1 et -1 euros est généralement considérée comme négligeable. Si l'enjeu était de 100 et -100 mille euros, par contre, la plupart des gens trouveraient la situation plutôthasardeuse.
Cependant, pour une minorité nantie, cette plage d'issues ne serait pas significative.
En troisième lieu, les actions hasardeuses, et donc le risque, sont des situations que l'on peut souvent désirer ou éviter. La quantité de risque jugée acceptable varie d'un individu à l'autre. Par exemple, deux personnes disposant d'un actif net égal sont susceptibles de réagir tout à fait différemment au parti de 100 mille euros décrit ci-dessus : l'une peut l'accepter et l'autre, le refuser. Leurs préférences individuelles, en matière de risque, sont différentes.
Nécessité de l'analyse du risque
La première étape de l'analyse du risque et de la modélisation consiste à en reconnaître la nécessité. La situation qui vous intéresse présente-t-elle un risque significatif ? Les quelques exemples qui suivent vous aideront peut-être à évaluer le caractère risqué ou non de vos propres situations :
- Risque lié à la création et à la commercialisation d'un nouveau produit - Le service de recherche et développement sera-t-il en mesure de résoudre les problèmes techniques qui se posent? Est-ce qu'un concurrent vous devancera dans la commercialisation ou la qualité du produit? Les règlements et homologations de l'État retarderont-ils le lancement du produit? Quel sera l'impact de la campagne publicitaire proposée sur les niveaux de vente? Les coûts de production seront-ils conformes aux prévisions? Le prix de vente proposé devra-t-il être modifié pour refléter des niveaux de demande non anticipés?
- Risques liés à l'analyse de valeurs mobilières et de gestion d'actif - Dans quelles mesures une proposition d'achat affectera-t-elle la valeur d'un portefeuille? Les nouveaux directeurs auront-ils une influence sur le cours du marché? Une société acquise produit-elle les bénéfices prévus? Quel sera l'impact d'un redressement du marché sur un secteur industriel donné?
- Risques liés à la gestion d'entreprise et à la planification – Un niveau de stocks donné suffira-t-il à répondre aux niveaux imprévisibles de la demande ? Les négociations contractuelles syndicales imminentes vont-elles produire une hausse nette des coûts de la main-d'œuvre ? Quel sera l'impact de la législation écologique en cours sur les coûts de production ? Dans quelle mesure les événements politiques et
commerciaux affecteront-ils les fournisseurs étrangers en termes de taux de change, de protectionnisme et de dates de livraison ?
- Risques liés à la conception et à la construction d'une structure (bâtiment, pont, barrageage, etc.) — Les coûts des matérieliaux de construction et de main-d'oeuvre seront-ils conformes aux prévisions ? Une grève du travail affectera-t-elle le calendrier de construction ? Les niveaux d'effort maximum dus aux charges de pointe, à la foule et aux éléments correspondront-ils aux prévisions ? L'effort risque-t-il d'atteindre le point de rupture ?
- Risques liés aux investissements dans l'exploration minière et pétrolière - L'exploration sera-t-elle productive ? Si un gissement est découvert, sera-t-il coû
- Risques liés à la planification politique — Si la politique est sujette à la ratification législative, sera-t-elle approuvée? Le niveau de conformité à une directive politique quelconque sera-t-il complet ou partiel? Les coûts de mise en œuvre seront-ils conformes aux prévisions? Le niveau de rentabilité sera-t-il conforme aux projections?
Évaluation et quantification du risque
La première étape de l'analyse du risque et de la modélisation consiste à en reconnaître la nécessité. La situation qui vous intéresse présente-t-elle un risque significatif ? Les quelques exemples qui suivent vous aideront peut-être à évaluer le caractère risqué de vos propres situations :
La prise de conscience du risque représenté par une situation ne constitue que la première étape. Comment quantifier le risque identifié pour une situation incertaine ? « Quantifier le risque », c'est déterminer toutes les valeurs possibles d'une variable de risque et la vraisemblance relative de chacune. Supposons que la situation incertaine envisagée soit l'issue d'un jeu de pile ou face. Vous pouvez lancer la pièce autant de fois qu'il le faut pour établir l'égalité des probabilités des issues possibles. Vous pouvez aussi calculer ce résultat mathématiquement, par application de simples notions élémentaires de probabilités et statistiques.
Dans la plupart des situations réelles, il n'est pas possible de recourir à « l'expérience », comme dans le cas de pile ou face, pour calculer le risque. Comment calculer la courbe de formation probable associée à l'introduction d'un nouvel équipement ? Vous pouvez vous reférer à vos expériences passées ; une fois le matériel sur le marché, l'incertitude disparaît. Il n'existe aucune formule mathématique apte à déterminer le risque associé aux issues possibles. Vous devez évaluer le risque sur la base des informations dont vous disposez.
Si vous pouvez calculer le risque comme dans une situation de pile ou face, il s'agit d'un risque de nature objective. Personne ne niera l'exactitude de votre quantification. La plupart des quantifications de risque sont cependant une question de jugement personnel.
Vous ne disposez pas nécessairement d'informations complètes sur la situation, elle ne peut être réitérée comme le jet d'une pièce de monnaie, ou elle peut être trop complexe pour produire une réponse sans équivoque. La quantification est alors subjective, et votre évaluation n'obtiendra pas nécessairement l'approbation de tous.
Les évaluations subjectives sont susceptibles de varier en fonction des informations supplémentaires éventuellement obtenues sur la situation. Lorsque l'approche est subjective, vous devez toujours vous demander s'il existe d'autres informations utiles à votre évaluation. Si oui, que vous en couterait-il de les atteindre ? Dans quelle mesure exigeraient-elles la modification de l'évaluation que vous avez déjà faite ? Dans quelle mesure cette modification affecterait-elle les résultats finaux de votre modèle ?
Description du risque avec une distribution de probabilités
Si vous avez quantifié un risque, par détermination des issues possibles et de la probabilité associée à chacune, vous pouvez en faire la synthèse à l'aide d'une distribution de probabilités. Les distributions de probabilités offrent une méthode de présentation du risque quantifié d'une variable. @RISK y fait appel pour décrire les valeurs incertaines de vos feuilles de calcul Excel et pour en présenter les résultats. Il existe plusieurs formes et types de distributions, décrivant chacune une plage de valeurs possibles et la probabilité de chacune. La forme de distribution normale (« courbe en cloche » traditionnelle) est généralement connue. Il en existe cependant toute une variété, des distributions uniformes et triangulaires aux formes plus complexes des distributions gamma et de Weibull.
Tous les types de distribution font appel à un ensemble d'arguments pour spécifier une plage de valeurs réelles et une distribution de probabilités. La distribution normale, par exemple, utilise une moyenne et un écart type comme arguments. La moyenne définit la valeur autour de laquelle la courbe en cloche sera centrée, et l'écart type, la plage de valeurs autour de la moyenne. @RISK propose plus de 30 types de distribution pour décrire les valeurs incertaines des feuilles de calcul Excel.
Vous pouvez afficher graphiquement ces distributions dans la fenêtre @RISK. Définir une distribution avant de les affecter à vos valeurs incertaines. Les graphiques révèlent rapidement la plage de valeurs possibles décrite par la distribution choisie.
Définition de l'analyse de risque
Au sens large, l'analyse de risque désigne toutes les méthodes - qualitatives ou quantitatives - qui permettent d'évaluer l'incidence du risque sur les situations qui nécessitent une décision. De nombreuses techniques associant les méthodes à la fois qualitatives et quantitatives. Elles ont toutes pour but d'aider le décideur à adopter une ligne de conduite et de permettre une meilleure appréciation des résultats susceptibles de se produire.
L'analyse du risque dans @RISK fait appel à une méthode quantitative cherchant à déterminer les issues d'une situation requérant une décision sous forme de distribution de probabilités. En général, les techniques d'analyse @RISK se définissent en quatre étapes :
- Développement d'un modèle - par la définition du problème ou de la situation au format de feuille de calcul Excel.
- Identification de l'incertitude - dans les variables de la feuille de calcul Excel, par l'indication de leurs valeurs possibles à l'aide de distributions de probabilités, et par l'identification des résultats incertains à analyser.
- Analyse du modèle avec simulation - pour déterminer la plage et les probabilités de toutes les issues possibles de la feuille de calcul.
- Prise de décision - en fonction des résultats obtenus et des préférences personnelles du décideur.
@RISK est utile aux trois premières étapes, en ce qu'il fournit un outil puissant et souple s'alliant à Excel pour faciliter la création de modèles et l'analyse du risque. Les résultats produits par @RISK peuvent ensuite aider le décideur à adopter une ligne de conduite.
Par bonheur, les techniques d'analyse du risque employées par @RISK sont particulièrement intuitives. Vous n'aurez donc pas à accepter aveuglement notre méthodologie, pas plus qu'à hausser les épaules et vous résoudre à considérer @RISK comme une «boîte noire» lorsque vos collégues et supérieurs vous interrogeront sur la nature de votre analyse du risque. L'exposé qui suit explique clairement ce dont @RISK a besoin en termes de modèle, et comment il procède à l'analyse du risque.
Élaboration d'un modèle @RISK
Vous seul êtes en mesure de bien comprendre les problèmes et situations que vous souhaitez analyser. S'ils sont sujets au risque, @RISK s'associe à Excel pour vous aider à en créer un modèle complet et logique.
Un des plus grands avantages de @RISK est qu'il vous permet de travailler dans le contexte de création de modèle standard familier de Microsoft Excel. @RISK œuvre de concert avec votre modèle Excel pour vous permettre de réaliser une analyse de risque tout en conservant les fonctionnalités ordinaires du tableau. Si vous savez commentisser des modèles Excel, @RISK vous donne maintainant la possibilité de les modifier, en toute simplicité, aux fins de l'analyse de risque.
Variables
Les variables sont les éléments de base de vos feuilles Excel que vous avez identifiés comme les ingrédients importants de votre analyse. La modélisation d'une situation financière, par exemple, peut faire intervenir les variables Ventes, Coûts, Revenus ou Bénéfices, tandis que celle d'une situation géologique impliquera plutôt des variables telles que Profondeur du gissement, Épaisseur du filon houiller, Porosité, etc. À chaque situation ses variables propres, qu'il vous revient d'identifier. Dans une feuille de calcul typique, les variables libellent les lignes ou les colonnes. Par exemple :
Certaines ou incertaines
Si vous connaissiez les valeurs que prendront vos variables dans le cadre temporel de votre modèle, il s'agit de variables certaines ou, dans le jargon des statisticiens, « déterministes ». Au contraire, si vous ne connaissiez pas ces valeurs, vos variables sont incertaines, ou « stochastiques ». Vous devez, dans ce cas, déscrire la nature de leur incertitude. Cet ajustement s'effectue à l'aide de distributions de probabilités, qui indiquent à la fois la plage des valeurs que la variable est susceptible de prendre (du minimum au maximum) et la probabilité de réalisation associée à chaque valeur. Dans @RISK, les variables et les valeurs de cellules incertaines se définissent sous forme de fonctions de distribution de probabilités. Par exemple :
RiskNormal(100;10)
RiskUniform(20;30)
RiskExpon(A1+A2)
RiskTriang(A3/2,01; A4; A5)
Indépendantes ou dépendantes
Vous pouvez placer ces fonctions de « distribution » dans les cellules et les formules d'une feuille de calcul tout comme n'importe quelle autre fonction Excel.
Outre certaines ou incertaines, les variables d'un modèle d'analyse de risque peuvent être « indépendantes » ou « dépendantes ». Une variable indépendante est indifférente à toutes les autres variables du modèle. Par exemple, dans un modèle financier évaluant la profitability d'une récolte agricole, vous pourriez inclure une variable incertaine appelée Précipitations. On peut supposer sans trop d'incertitude que d'autres variables du modèle, telles que le prix de la récolte et le coût de l'engrais, seraient sans incidence sur les précipitations. La variable Précipitations est donc une variable indépendante.
Par opposition, une variable dépendante est déterminée, en tout ou en partie, par une ou plusieurs autres variables du modèle. Par exemple, la variable Rendement du modèle considéré dépendrait probablement de la variable indépendante Précipitations. S'il pleut trop ou pas assez, le rendement est faible. S'il pleut à peu près normalement, le rendement peut se situer dans une fourchette comprise entre le dessous et le dessus de la moyenne. D'autres variables peuvent également affecter le rendement des cultures (Température, Pertes dues aux insectes, etc.)
Lors de l'identification des valeurs incertaines de votre feuille de calcul Excel, vous devez déterminer la corrélation ou non de vos variables. Celles considérées ici sont bel et bien « corrélées ». Dans @RISK, la fonction Cormat permet d'identifier les variables corrélées. Il est extrêmement important d'identifier correctement les correlations entre les variables. Le modèle risquerait sinon de produire des résultats insensés. Si, par exemple, vous omettiez la relation entre les variables Précipitations et Rendement, @RISK pourrait très bien désirer une valeurasse pour les précipitations et une valeurraisee pour le rendement, ce qui serait naturellement absurde.
Variables de sortie
Comme tous les autres modèles, ceux d'analyse du risque nécessitent des valeurs en entrée et des résultats de sortie. L'analyse de risque @RISK produit ses résultats sur les cellules de la feuille de travail Excel. Ces résultats sont les distributions de probabilités des valeurs susceptibles de se produire. Ils correspondent généralement aux cellules de résultats d'une analyse Excel ordinaire (bénéfices, première ligne ou autre entrée similaire de la feuille de calcul).
Analyse d'un modèle avec simulation
Une fois introduites les valeurs incertaines dans les cellules de la feuille de calcul et identifiées les sorties de l'analyse, vous disposez d'une feuille de calcul Excel que @RISK peut analyser.
Simulation
@RISK recourt à la simulation, parfois appelée simulation Monte Carlo, pour exécuter l'analyse du risque. En ce sens, la simulation désigne la méthode par laquelle la distribution des issues possibles résulte de l'exécution, par l'ordinateur, de calculs répétés de la feuille de calcul, sur la base, à chaque fois, d'un ensemble de valeurs différentes, sélectionnées au hasard dans les distributions de probabilités introduites dans les valeurs et formules des cellules. L'ordinateur essaie en somme toutes les combinaisons valables des variables en entrée pour simuler toutes les issues possibles, comme si vous analysiez tout à la fois des centaines ou même des milliers de scénarios hypothétiques!
Qu'entend-on par « la simulation essaie toutes les combinaisons valables des valeurs de variables d'entrée » ? Imaginons un modèle limité à deux variables en entrée. Si ces variables ne présentent aucun degré d'incertitude, une valeur possible unique peut être identifiée pour chacune. Les deux valeurs déterminées peuvent être combinées par les formules de la feuille pour calculer les résultats recherchés (valeur certaine ou déterministe). Par exemple, si les variables en entrée certaines sont les suivantes :
Revenues = 100
Coots = 90
alors le résultat
Bénéfices = 10
est calculé par Excel à partir de
Bénéfices = 100 - 90
Il n'est qu'une combinaison des valeurs de variable en entrée, car il n'est qu'une valeur possible pour chaque variable.
Considérons maintenant une situation représentant un certain degré d'incertitude dans les deux variables en entrée. Par exemple :
Revenus = 1 0 0 ou 1 2 0
Couts = 9 0 ou 8 0
donne deux valeurs pour chaque variable d'entrée. Lors de la simulation, @RISK considère toutes les combinaisons possibles de ces valeurs afin de calculer les valeurs possibles du résultat, Bénéfices.
Les quatre combinaisons suivantes sont possibles :
Bénéfices = Revenus - Coûts
Étant calculée à partir de variables incertaines, la variable Bénéfices l'est aussi.
Fonctionnement de la simulation
Dans @RISK, la simulation exécute deux opérations distinctes :
- Sélection d'ensembles de valeurs pour les fonctions de distribution de probabilités introduites dans les cellules et les formules de la feuille de calcul. Recalcul de la feuille de calcul Excel en fonction des nouvelles valeurs.
La sélection des valeurs est appelée « échantillonnage », et chaque calcul de la feuille de calcul, « iteration »
Les diagrammes qui suivent illustrent la manière dont chaque iteration fait appel à un ensemble de valeurs unique échantillonnées à partir des fonctions de distribution pour calculer des résultats à valeur unique.
@RISK génère les distributions de sortie par consolidation des résultats à valeur unique de toutes les iterations.
Autre approche de la simulation
Il existe deux approches fondamentales de l'analyse quantitative du risque. Elles visent toutes deux le même but - produire une distribution de probabilités décrivant les issues possibles d'une situation incertaine - et elles générent toutes deux des résultats valables. La première approche est celle que nous venons de décrire pour @RISK (la simulation). Elle repose sur le fait que l'ordinateur peut exécuter de nombreuses tâches très rapidement, et résoudre ainsi le problème d'une feuille de calcul par répétition de nombreuses combinaisons possibles des valeurs de variables en entrée.
La seconde approche de l'analyse du risque est de nature analytique. Les méthodes analytiques nécessitant la description mathématique des distributions de toutes les variables incertaines d'un modèle. Les équations de ces distributions sont ensuite combinées mathématiquement pour produire une autre équation, dérivant la distribution des issues possibles. Cette approche ne se prête cependant pas à tous les usages et tous les utilisateurs ne l'apprécient pas. Il est difficile de décrire les distributions sous forme d'équations, et encore plus difficile de les combiner de manière analytique, même pour un modèle modérément complexe. De plus, l'expertise mathématique nécessaire à l'application des techniques analytiques est considérable.
Prise de décision : interprétation des résultats
Les résultats de l'analyse @RISK sont présentés sous forme de distributions de probabilités que le décideur doit interpréter afin de prendre une décision. Comment interpréter une distribution de probabilités ?
Interprétation d'une analyse traditionnelle
Commençons par examiner comment un décideur interpréterait un résultat à valeur unique d'analyse traditionnelle – « valeur probable ». La plupart des décideurs comparent le résultat probable à une norme ou valeur minimum acceptable. Si le résultat est au moins égal à la norme, ils l'estiment acceptable. La plupart des décideurs reconnaissent toutefois que le résultat probable ne reflète guère l'incertitude et ils doivent le manipuler pour prévoir une part de risque. Ils peuvent augmenter arbitrairement le résultat minimum acceptable, ou bien calculer approximativement la probabilité que le résultat réel atteigne ou non le résultat prévu. Dans le meilleur des cas, l'analyse peut être étendue à d'autres résultats – le « pire des cas » et le « meilleur des cas » –, dont il faudra tenir compte également dans l'évaluation du résultat probable. Le décideur juge ainsi si la valeur probable et celle du « meilleur des cas » ont assez de poids pour l'emporter sur celle du « pire des cas ».
Dans une analyse @RISK, les distributions de probabilités de sortie donnent au décideur un aperçu complet des issues possibles. Il s'agit d'une élaboration sophistiquée de l'approche du « meilleur des cas/résultat probable/pire des cas » décrite plus haut. La distribution de probabilités fait cependant plus que combler le vide entre ces trois valeurs :
- Elle détermine une plage « correcte » — Du fait de la définition plus rigoureuse de l'incertitude associée à chaque variable en entrée, la plage des résultats possibles peut être bien différente de celle du « meilleur/pire des cas » et désigner un plus haut degré d'exactitude.
- Elle indique la probabilité de réalisation - Une distribution de probabilités indique la probabilité relative de chaque issue.
Vous n'êtes plus réduit à comparer les issues désirables aux issues indésirables. Vous pouvez en revanche reconnaître que certaines issues ont plus de chances de se produire que d'autres et doivent donc avoir plus d'influence dans votre évaluation. Ce processus est beaucoup plus facile à comprendre que l'analyse traditionnelle, car une distribution de probabilités est un graphique, qui vous permet d'examiner les probabilités et de vous faire une idée des risques à envisager.
Préférences individuelles
Il vous revient d'interpréter les résultats d'une analyse @RISK, de manière individuelle. Les mêmes résultats peuvent être interprétés différemment par différentes personnes, qui adopteront des lors différents lignes de conduite. Il ne s'agit pas là d'un point faible de la technique, mais d'une conséquence directe des préférences propres à chaque individu en matière de CHOIX, de temps et de risque. Vous pourriez ainsi percevoir dans la forme d'une distribution de sortie une probabilité d'issue indésirable beaucoup plus grande que celle d'une issue désirable, alors qu'un collègue prêt à courir plus de risques arrivera peut-être à la conclusion inverse.
Étalement de la distribution
La plage des probabilités et leur vraisemblance sont directement liées au niveau de risque associé à un événement particulier. En examinant l'étalement et la probabilité des résultats possibles, vous pouvez prendre une décision avisée en fonction du niveau de risque que vous êtes prêt à courir. Les décideurs peu enclins à courir de risque préfèrent un étalement restreint de résultats possibles, avec une large probabilité de résultats désirables. Si vous aimez le risque, vous acceptez par contre un étalement ou une variation possible plus grande dans votre distribution des issues. Les preneurs de risques se laisseront du reste influencer par les issues fructueuses, même si leur probabilité pourrait être.
Quelles que soient vos préférences personnelles, certaines conclusions générales, en matière de risque, s'appliquent à tous les décideurs. Les distributions de probabilités suivantes illustrent ces conclusions.
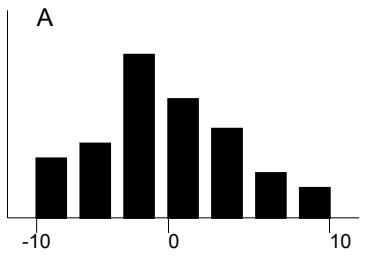
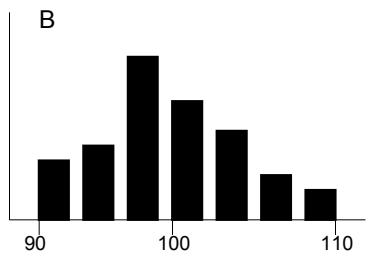
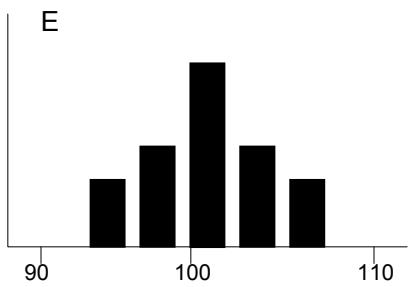
La distribution de probabilités A représente un plus grand risque que la distribution B malgré la similarité des formes, car la plage de A comprend des résultats moins désirables - l'étalement par rapport à la moyenne est plus grand dans A que dans B.
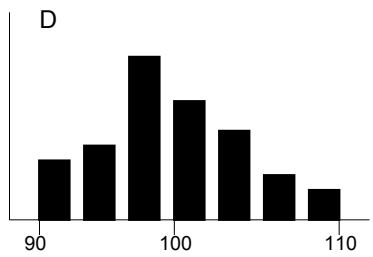
La distribution de probabilités C représente un plus grand risque que la distribution D car la probabilité est uniforme sur toute la plage pour C, tandis qu'elle se concentre autour de 98 pour D.

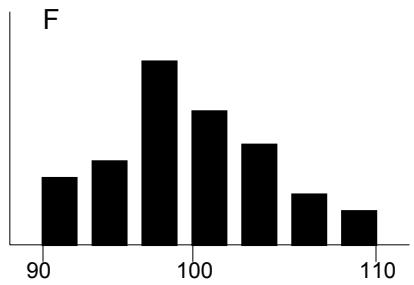
La distribution de probabilités F représente un plus grand risque que la distribution E, car la plage est plus grande et la probabilité est plus étalée que pour E.
Asymétrie
Une distribution de sortie de simulation peut aussi démontrer une certaine asymétrie, dans la mesure où la distribution des résultats possibles n'est pas symétrique. Supposons par exemple une distribution à longue « queue» positive. Si le résultat probable était limité à un seul nombre, vous ne vous rendriez peut-être pas compte de la possibilité d'une issue hautement positive dans la queue. L'asymétrie peut s'avérer extrêmement importante pour les décideurs. En représentant des informations complètes, toutes issues possibles incluses, @RISK « ouvre » le panorama de la décision.
Limites de l'analyse de risque
Au cours de ces dernières années, les techniques d'analyse quantitative ont acquis une réputation favorable parmi les décideurs et les analystes. Malheureusement, beaucoup y ont aussi vu, erronément, une panacée apte à fournir, sans équivoque, la réponse ou la décision correcte. Aucune technique, y compris celles utilisées par @RISK, ne peut prétendre à une telle capacité. Les techniques proposées sont des outils utiles à la prise de décision et à la résolution des problèmes. Comme tous les outils, elles peuvent se révéler précieuses au service d'utilisateurs compétents, ou être source de ravages entre les mains de novices non qualifiés. Dans le contexte de l'analyse du risque, les outils quantitatifs ne doivent jamais remplacer le jugement personnel.
En dernier lieu, il convient de reconnaître que l'analyse de risque n'offre aucune garantie quant à savoir si la ligne de conduite adoptée - sur la base même d'un choix expert effectué selon les préférences personnelles de l'utilisateur - est la(Meilleure), comme le révélera le temps.
L'évaluation « après coup » repose toujours sur des informations complètes, jamais disponibles au moment où la décision doit être prise. Vous pouvez toutefois être sûr d'avoir choses la(Meilleure)strategie personnelle compte tenu des informations qui vous sont disponibles. Ce n'est pas la une garantie négligeable!
Chapitre 3 : guide de mise à niveau
Nouvelles barres d'outils, icônes et commandes @RISK......43
Construction d'un modèle @RISK 47
Nouvelles fonctions @RISK et fonctions améliorées dans Excel..47
Définition des distributions de probabilités dans le tableau....50
Corrélation des distributions de probabilités 55
Définition des sorties de simulation dans le tableau 59
Examen d'un modèle dans la fenêtre @RISK Modèle. 60
Propriétés de distributions en entrées et sorties de simulation....62
Permutation des fonctions @RISK 63
Définition de distributions à partir des données. 65
Paramètres de simulation 69
Simulations 73
Résultats graphiques d'une simulation 75
Mode Parcours 75
Fenêtre @RISK - Synthèse des résultats 77
Nouveaux graphiques @RISK 5.5. 79
Personnalisation et rapports graphiques @RISK. 83
Rapports de résultats de simulation 85
Enregistrement des simulations 93
Bibliothèque @RISK 95
@RISK 5.5 représente une sérieuse évolution par rapport aux versions antérieures du programme. Par une meilleure intégration à Microsoft Excel, @RISK 5.5 offre un accès plus simple aux résultats de ses simulations, directement dans le tableau. @RISK 5.5 est proposé en trois éditions : Standard, Professional et Industrial. Vous pouvez ainsi désirer les fonctionnalités et les derniers adaptations à vos besoins.
Les principales fonctionnalités de @RISK 5.5 sont les suivantes :
- Les fenêtres séparées de modèle et de synthèse des résultats des versions @RISK 4.0 et 4.5 sont désormais intégrées à la fenêtre Excel.
- Les graphiques des résultats de simulation et des entrées peuvent être directement liés aux cellules auxquelles ils se réfèrent dans Excel par l'intermédiaire de fenêtres « légendes ».
- Un nouveau « navigateur graphique » parcourt rapidement les entrées et sorties @RISK dans les classeurs ouverts, avec indication à la cellule de l'entrée ou de la sortie.
- Les corrélations entre les distributions se définissent rapidement dans les matrices qui s'ouvrent directement par-dessus Excel et une série temporelle corrélée peut être ajoutée d'un simple clic sur un bouton.
- Un nouveau moteur graphique, conçu pour les données de simulation, assure une représentation graphique plus rapide et l'actualisation en temps réel des résultats de simulation.
- Presque toutes les opérations de modélisation peuvent s'effectuer par glissement-déplacement ou d'un simple clic sur la barre d'outils.
- La nouvelle barre de paramètres @RISK, sous Excel, donne rapidement accès aux paramètres de simulation.
- De nouveaux diagrammes de dispersion et en boîte éclaircissant davantage les résultats des simulations.
- Un plus large évventail de fonctions @RISK dans Excel gère les analyses six sigma, les statistiques relatives aux entrées de simulation, entre autrestraitements de résultats.
- La nouvelle fonction RiskCompound, particulièrement influençant le domaine des assurances, combine deux distributions pour cré èle. La Bibliothèque @RISK offre un référentiel d'échange d'entrées et de résultats de simulation @RISK.
- La permutation de fonctions permet l'enlèvement puis le rétablissement des fonctions @RISK dans les classeurs, pour faciliter le partage avec les non-utilisateurs de @RISK. Les données d'une simulation peuvent être triées en fonction des valeurs clés qui vous intéressent.
- Les itérations d'une simulation exécutée précédemment peuvent être passées en revue, avec mise à jour des valeurs échantillonnées et des résultats calculés dans Excel. L'approche est utile à la recherche des itérations erronées, des itérations ayant mené à certains scénarios de sortie, etc.
- Gestion des versions Microsoft Excel jusqu'à Excel 2007, y compris les feuilles de calcul plus volumineuses d'Excel 2007.
Nouvelles barres d'outils, icônes et commandes @RISK
@RISK 5.5 propose de nouvelles barres d'outils, icônes et commandes destinées à faciliter la définition directe du modèle de simulation dans le tableau.
Barre d'outils @RISK sous Excel 2003 et versions antérieures

Ruban @RISK sous Excel 2007

Nouvelles icônes :
L'icône Définir les corrélations ouvre une matrice de corrélation par-dessus la fenêtre Excel, pour corrélation rapide des distributions de probabilités. - L'icône Parcours des résultats active le nouveau mode « Parcours » de @RISK 5.5, affichant automatiquement un graphique des résultats de simulation d'une cellule lors de la sélection de cette cellule dans Excel. - Quatre nouvelles icônes de rapport affichent directement par-dessus Excel les rapports des résultats de simulation (Statistiques détaillées, Données, Analyse de sensibilité et Analyse de scénario). - L'icône Filtres permet de définir les filtres appelés à limiter la plage de calcul des statistiques et des graphiques. - L'icône Permuter les fonctions active ou désactive les fonctions @RISK dans les classeurs ouverts. - L'icône Bibliothèque affiche la Bibliothèque @RISK de définition des distributions en entrée courantes et d'archivage des résultats de simulation. - L'icône Utilitaires donne notamment accès à la commande Paramètres d'application, où se définissent les paramètres par défaut de @RISK.
Une barre de paramètres @RISK s'ajoute aux versions Excel 2003 et antérieures, pour accélérer l'accès à de nombreux paramètres de simulation. Sous Excel 2007, les commandes de cette barre sont intégrées au ruban @RISK standard.

Ses icônes sont les suivantes :
- Paramètres de simulation ouvre la boîte de dialogue du même nom.
- La liste déroulante Itérations permet de changer rapidement, depuis la barre d'outils, le nombre d'iterations à exécuter.
- La liste déroulante Simulations permet de changer rapidement, depuis la barre d'outils, le nombre de simulations à exécuter.
- Aléatoire/Statique fait basculer @RISK entre le renvoi de valeurs probables ou statiques des distributions et celui d'échantillons Monte Carlo lors d'un recalcul Excel standard.
- Graphique, Résultats et Démo régissant ce qui s'affiche à l'écran pendant et après une simulation.
- Actualisation en direct détermine si les fenêtres ouvertes s'actualisent pendant l'exécution d'une simulation.
Une nouvelle fenêtre de progression s'affiche lors des simulations. Ses icônes permettent d'exécuter, interrompre momentanément ou abandonner une simulation, ainsi que d'activer ou désactiver l'actualisation en temps réel des graphiques et les recalculs Excel.
Paramètres d'application @RISK
La nouvelle boîte de dialogue Paramètres d'application définit les valeurs par défaut générales des options standard (couleurs des graphiques, centiles décroissants, nombre d'iterations, etc.) applicables à chaque exécution de @RISK.

Construction d'un modèle @RISK
@RISK 5.5 (comme les versions antérieures de @RISK) permet, pour définir le risque, l'ajout de fonctions de distribution de probabilités aux formules d'une feuille de calcul. @RISK permet aussi l'accès direct aux résultats des simulations dans les formules du tableau, à travers les fonctions statistiques @RISK. @RISK 5.5 élargit l'éventail de fonctions de modélisation du tableau et apporte une nouvelle interface graphique d'entrée et modification de ces fonctions dans le tableau. Comme dans les versions antérieures, les fonctions @RISK se tapent directement dans les formules Excel ou s'y définissent essentiellement à travers l'interface graphique.
Nouvelles fonctions @RISK et fonctions améliorées dans excel
@RISK 5.5 propose de nouvelles fonctions personnalisées et d'autres améliorées pour inclusion dans les cellules et formules Excel.
Fonction de composition Renvoie
La nouvelle fonction RiskCompound, pour les modèles de fréquence-gravité, combine deux distributions pour n'en former plus qu'une en entrée. RiskCompound s'accompagne de deux arguments, représentant normalement chacun une fonction de distribution @RISK. Dans une itération donnée, l'échantillon de la première distribution précise le nombre d'échantillons à prélever dans la seconde. Les échantillons de la seconde distribution sont ensuite totalisés pour conduire la valeur renvoyée par la fonction RiskCompound. Par exemple, la fonction
RiskCompound(RiskPoisson(5); RiskLognorm(100000;10000))
pourrait être utilisée dans le domaine des assurances, avec description de la fréquence ou nombre de sinistres par RiskPoisson(5) et indication de la gravité de chacun par RiskLognorm(100000;10000). La valeur d'échantillon renvoyée par RiskCompound représente le montant total des sinistres pour l'iteration, tel que produit par un nombre de sinistres échantillonnés depuis RiskPoisson(5), représentant chacun un montant échantillonné dans RiskLognorm(100000;10000). Deux arguments facultatifs, Franchise et Limité, permettent de soustraire un montant de franchise de chaque échantillon de gravité ou de limiter l'échantillon au plafond indiqué.
Des centaines ou même des milliers de fonctions de distribution peuvent ainsi être éliminées des modèles @RISK existants par encapsulation dans une seule fonction RiskCompound. Mieux encore, ces modèles s'exécutent beaucoup plus rapidement.
| Fonctions statistiques | Un nouvel ensemble de fonctions statistiques @RISK renvoie les statistiques désirées sur les entrées de la simulation. Par exemple, la fonction RiskTheoMean(A10) renvoie la moyenne de la distribution de probabilités de la cellule A10.Les fonctions statistiques @RISK existantes pour les résultats de simulation (RiskMean, par exemple) admettent les arguments facultatifs min-max pour la précision d'un centile ou d'une plage de calcul des statistiques. On peut ainsi calculator les statistiques sur un sous-ensemble réduit de données de simulation recueillies (la queue d'une distribution, par exemple). La plage min-max se définit à l'aide de la fonction RiskTruncate. |
| Fonctions de sensibilité | La nouvelle fonction RiskSensitivity renvoie les résultats de l'analyse de sensibilité directement au tableau. Les entrées les plus critiques d'un résultat de simulation et les coefficients qui identifient leur niveau d'impact peuvent ainsi être renvoyés aux formules du tableau. |
| Fonctions de propriété | De nouvelles fonctions de propriété de distribution ont également été ajoutées à @RISK 5.5. Incorporatedes à une fonction de distribution ou de sortie, ces fonctions seront à préciser une information complémentaire au sujet d'une distribution en entrée ou d'une sortie de simulation. Par exemple, RiskNormal(10;1,RiskUnits("Dollars")) spécifie Dollars comme libellé d'unités des graphiques et rapports de cette entrée. |
| Fonction RiskMakeInput | La nouvelle fonction RiskMakeInput spécifie que la valeur calculée d'une formule doit être traitée comme une entrée de simulation, au même titre qu'une fonction de distribution. Grâce à cette fonction, les résultats de calculs Excel (ou d'une combinaison de fonctions de distribution) peuvent êtretraités comme une simple « entrée » dans une analyse de sensibilité. Les distributions qui précédent ou « alimentent » la fonction RiskMakeInput sont exclues de l'analyse de sensibilité pour éviter le redoublement de leur impact. |
| Fonction TruncateP | La nouvelle fonction de propriété TruncateP sert à tronquer une distribution de probabilités au moyen de centiles只不过 que de valeurs réelles. |
| Fonctions statistiques Six Sigma | Un nouvel ensemble de fonctions statistiques @RISK renvoie les statistiques Six Sigma désirées sur une sortie de la simulation. Par exemple, la fonction RiskCPK(A10) renvoie la valeur CPK de la sorite de simulation de la cellule A10. Par défaut, ces fonctions utilisent l'information six sigma LSI, LSS et cible entraîée pour la sortie dans la fonction de propriété RiskSixSigma. Rien n'empêche cependant de préciser directement les valeurs LSI, LSS et cible comme arguments facultatifs d'une fonction statistique six sigma. |
Fonctions de convergence
ARISK peut rapporter l'information de surveillance de convergence en cours de simulation à travers la nouvelle fonction RiskConvergence. Cette fonction permet de préciser les statistiques d'une sortie précise dont la convergence doit être suivie et le seuil de convergence utilisé. La fonction RiskConvergenceLevel identifie le moment de convergence d'une sortie dans une simulation.
Fonction de commande de simulation
La nouvelle fonction RiskStopRun peut être utilisée de concert avec RiskConvergenceLevel pour arrêter ponctuellement une simulation ou pour l'arrêter lorsqu'une formule ou fonction du modèle s'avère (VRAI).
Définition des distributions de probabilités dans le tableau
Avec @RISK 5.5, vous pouvez affecter des fonctions de distribution de probabilités aux valeurs incertaines de vos modèles de calcul à travers la fenêtre Définir une distribution. Cette fenêtre est désormais interactive et vous pouvez passer d'une cellule à l'autre du classeur, en y affectant ou prévisualisant les distributions, sans jamais fermer la fenêtre. La flèche de la fenêtre désigne la cellule pour laquelle la distribution est définie. Pour déplacer la fenêtre de définition d'une cellule à l'autre dans les classeurs ouverts, appuyez simplement sur la touche.
La fenêtre Définir une distribution permet les opérations suivantes :
- Affichage et affectation de probabilités aux valeurs de cellules et formules Excel. On peut ainsi affecter graphiquement, en toute rapidité, une distribution à une valeur numérique de formule de cellule Excel, et modifier les fonctions de distribution entrées précédemment.
- Introduction automatique de fonctions de distribution dans les formules. Toutes les modifications apportées dans la fenêtre s'ajoutent directement à la formule de cellule Excel correspondante.
- Modification de distributions multiples dans une même cellule. Un simple clic sur une valeur de formule sélectionne cette valeur pour remplacement par une distribution de probabilités.
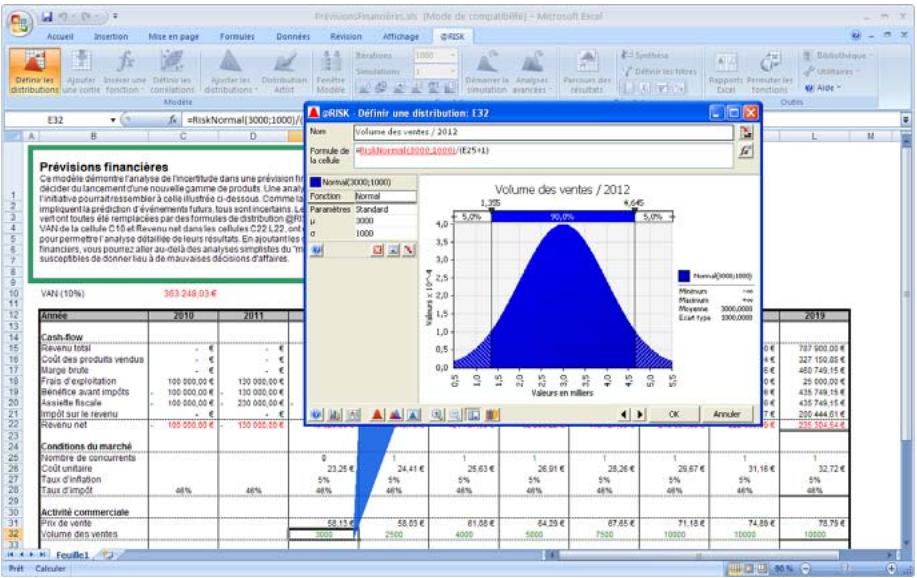
Évaluation graphique des probabilités
Grâce à la fenêtre Définir une distribution de @RISK 5.5, vous pouvez passer interactivement d'une distribution à l'autre et visualiser les probabilités décrites par chacune. La prévisualisation admet les interventions suivantes :
- Configuration et comparaison interactives des probabilités à l'aide des délimiteurs coulissants. Superposition de plusieurs distributions à comparer.
- Changement de type de graphique et d'échelle à l'aide des barres d'outils et de la souris.
De nouvelles distributions de probabilités peuvent être ajoutées aux formules à l'aide de la nouvelle palette de distributions. Il suffit de cliquer sur une valeur de formule pour la sélectionner. Cette valeur peut ensuite être remplaçée par un type de distribution proposé dans la palette, d'un double clic sur l'image de la distribution.
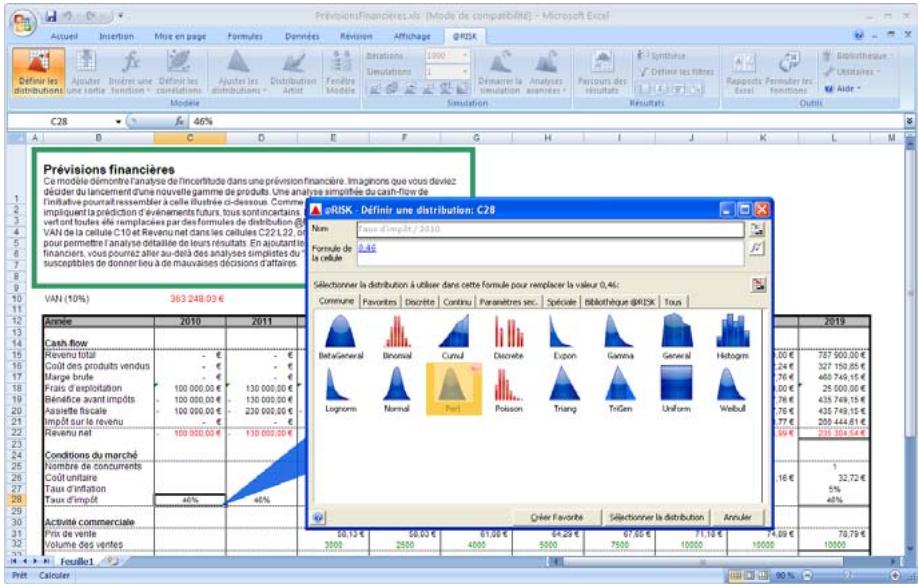
Entrée de valeurs d'argument
Les valeurs d'argument se saisissent dans le volet d'arguments ou, directement, dans la formule affichée. Ce volet s'affiche à gauche du graphique.
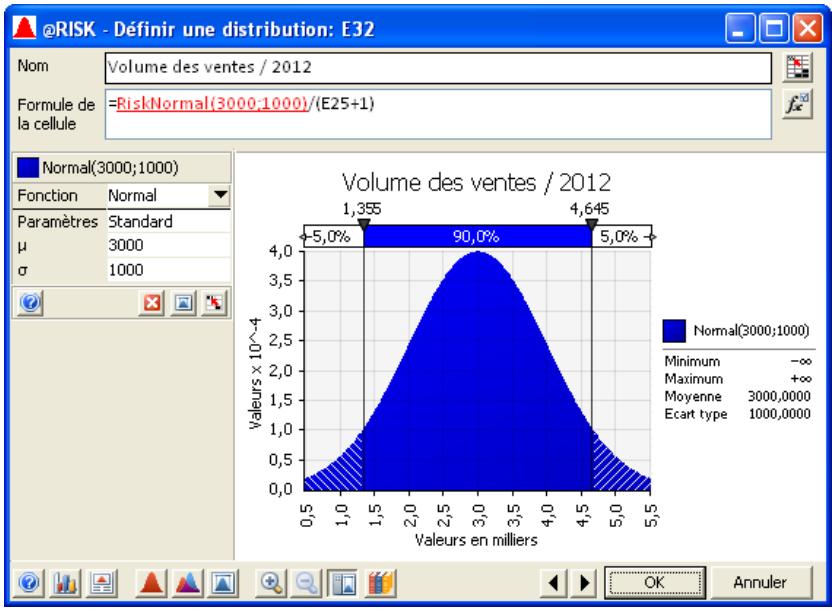
Type de paramètres
Si vous changez le type de paramètres, vous pouvez sélectionner l'entrée de paramètres secondaires ou tronquer la distribution.
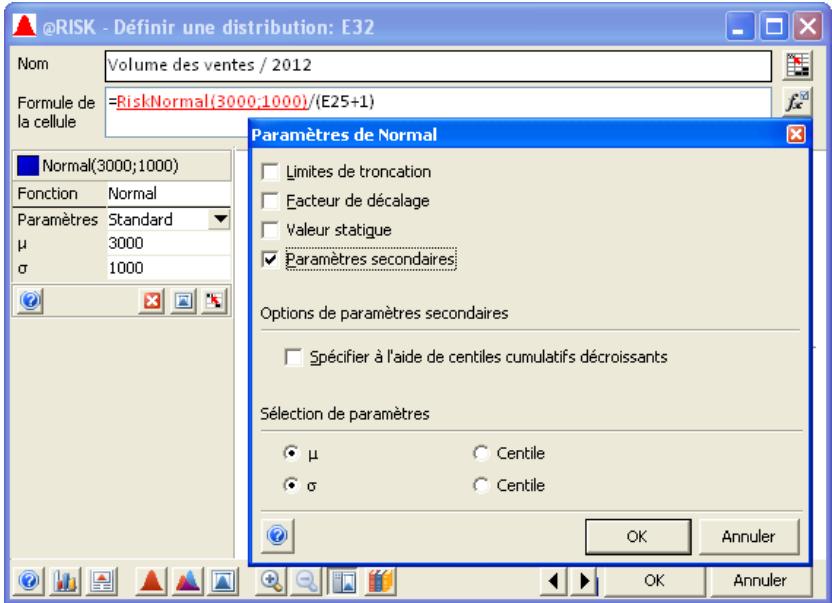
Changement de type de graphique
La fenêtre Définir une distribution (comme les autres fenêtres graphiques) permet de changer le type de graphique affiché en cliquant sur l'icône Type de graphique proposée dans le coin inférieur gauche.
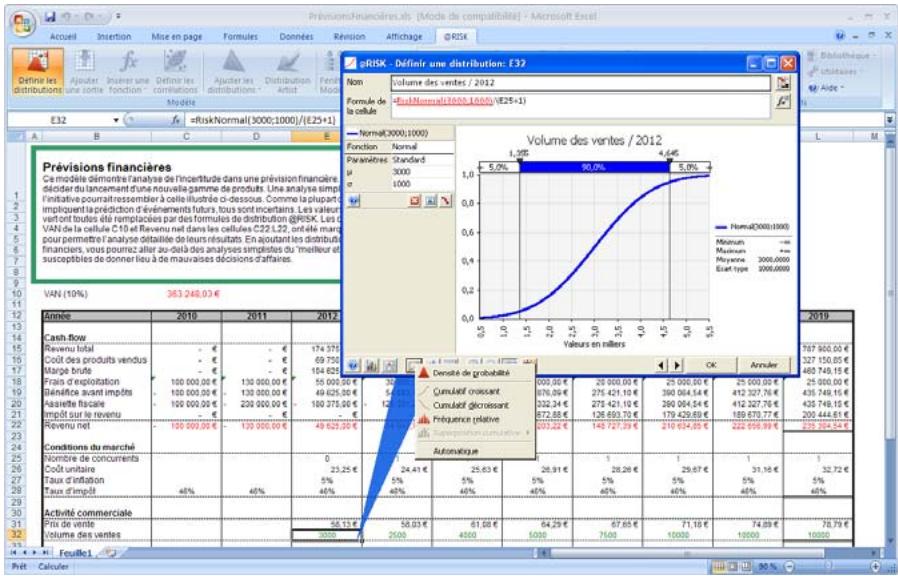
Personnalisation d'un graphique
La fenêtre Définir une distribution (de même que les autres fenêtres graphiques) permet la personnalisation des graphiques à travers la boîte de dialogue Options graphiques. Plusieurs paramètres (titres, couleurs, délimiteurs et autres options) peuvent y être définis. Il suffit souvent de cliquer directement sur le graphique pour le personnaliser (pour lui donner un titre, par exemple).
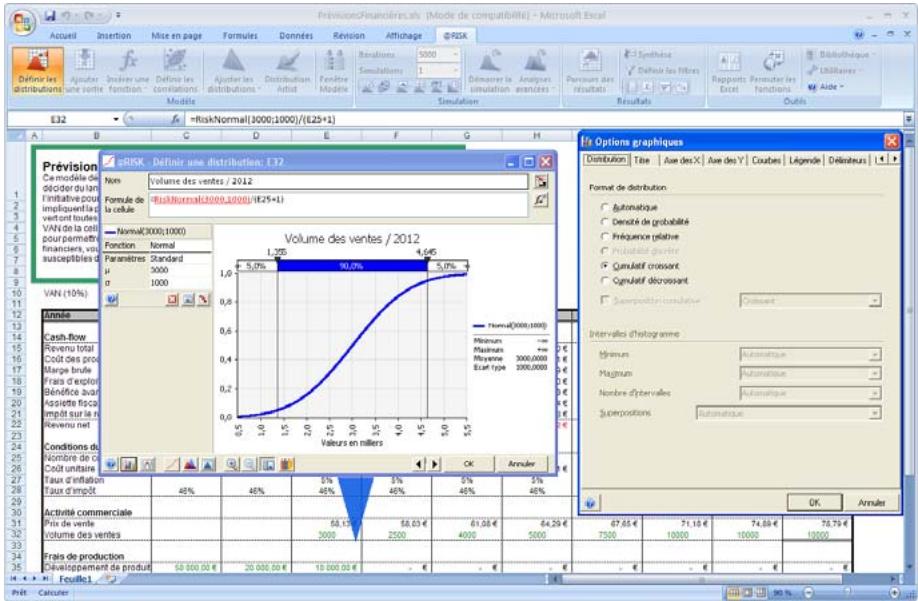
Superpositions dans la fenêtre Définir une distribution
Dans la fenêtre Définir une distribution, les superpositions s'ajoutent à travers une version réduite de la palette de distributions. Affichée sous le graphique, cette palette permet l'ajout et la suppression de superpositions.
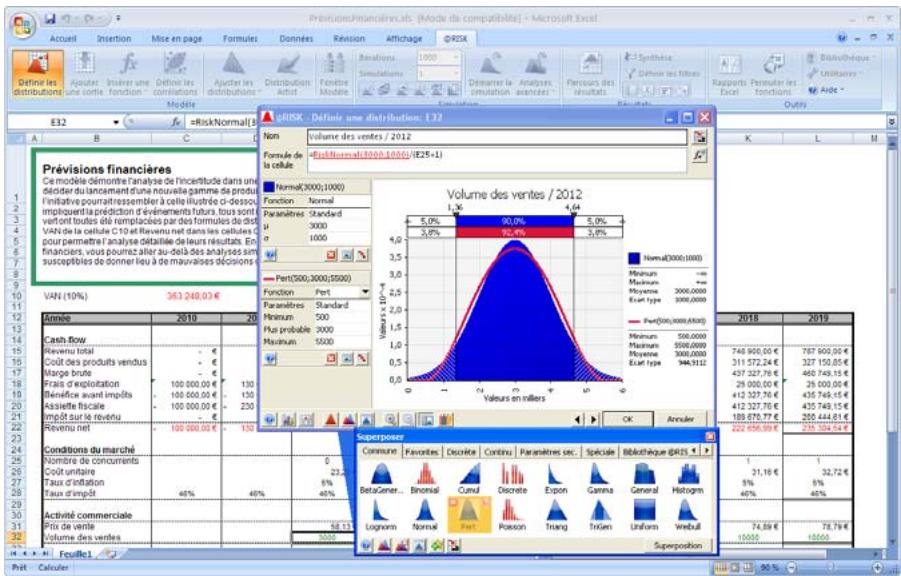
Entrée de références Excel
Le volet des arguments, à gauche du graphique, peut servir à la sélection de cellules Excel appelées à servir d'arguments à une fonction de distribution. Il suffit pour ce faire de cliquer sur l'icône Récurrence Excel pour la distribution désirée dans le volet d'arguments.
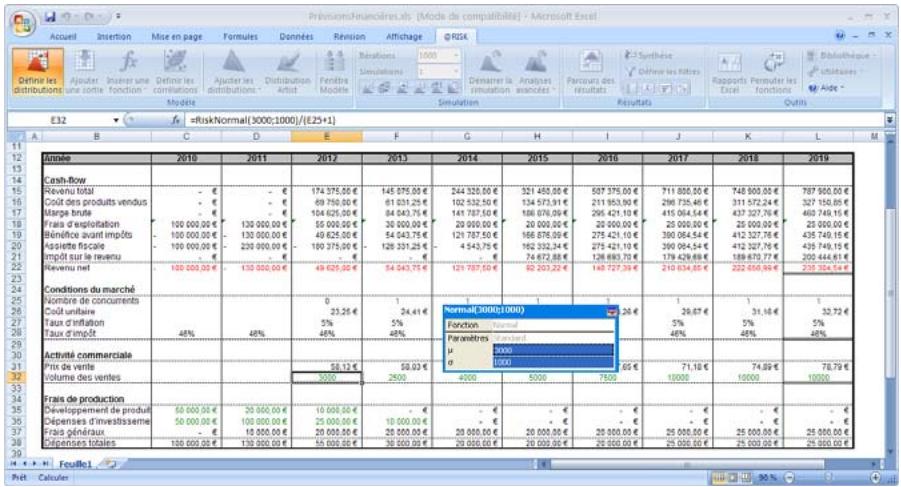
Corrélation des distributions de probabilités
La nouvelle fenêtre Définir les correlations de @RISK 5.5 facilite la définition des correlations entre les distributions de probabilités. Cette fenêtre présente une matrice de correlation et les coefficients de corrélation entre les distributions de probabilités de la matrice.
Pour ajouter une corrélation, il suffit de sélectionner les cellules Excel qui contiennent les distributions en entrée à corréler, puis de cliquer sur l'icône Définir les correlations. Il est également possible d'ajouter les entrées à une matrice affichée en cliquant sur Ajouter des entrées et en sélectionnant les cellules Excel désirées.
Lorsqu'une matrice est affichée, vous pouvez entrer les coefficients de corrélation entre les entrées dans les cellules de la matrice, copier les valeurs d'une matrice Excel ou faire appel aux diagrammes de dispersion pour évaluer et saisir les correlations.
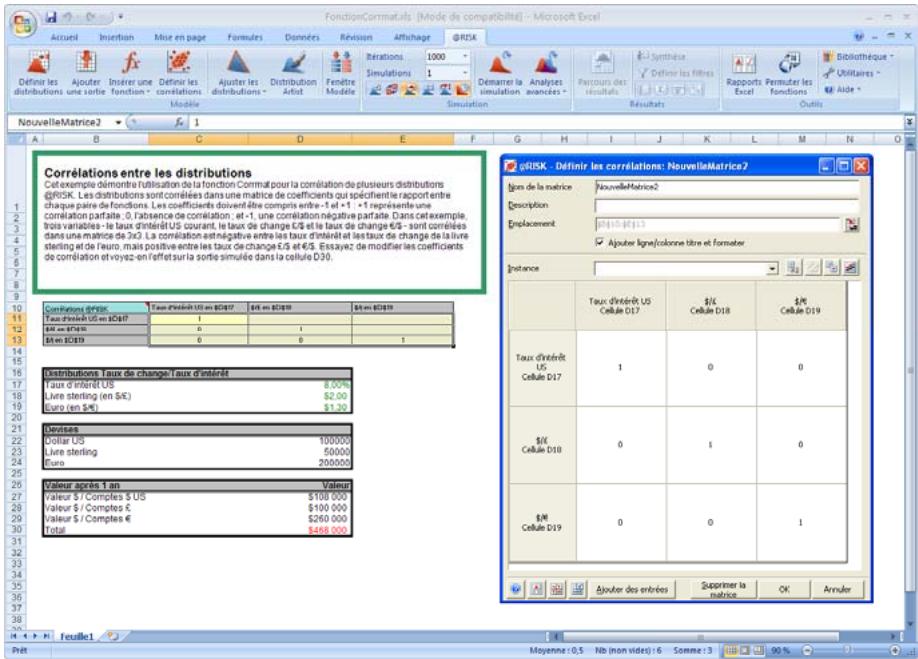
Diagrammes de dispersion et corrélations
L'icône Diagrammes de dispersion, dans le coin inférieur gauche de la fenêtre Définir les correlations, ouvre une matrice de diagrammes de dispersion. Les diagrammes, dans les cellules de la matrice, indiquent la correlation entre les deux distributions correspondantes. Le curseur de corrélation change dynamiquement le coefficient de correlation et le diagramme de dispersion de chaque paire d'entrées.
En glissant-déplaçant une cellule de diagramme de dispersion hors de la matrice, vous pouvez étendre la vignette du diagramme à une fenêtre graphique plein format. Cette fenêtre s'actualise aussi dynamiquement selon le mouvement du curseur de corrélation.
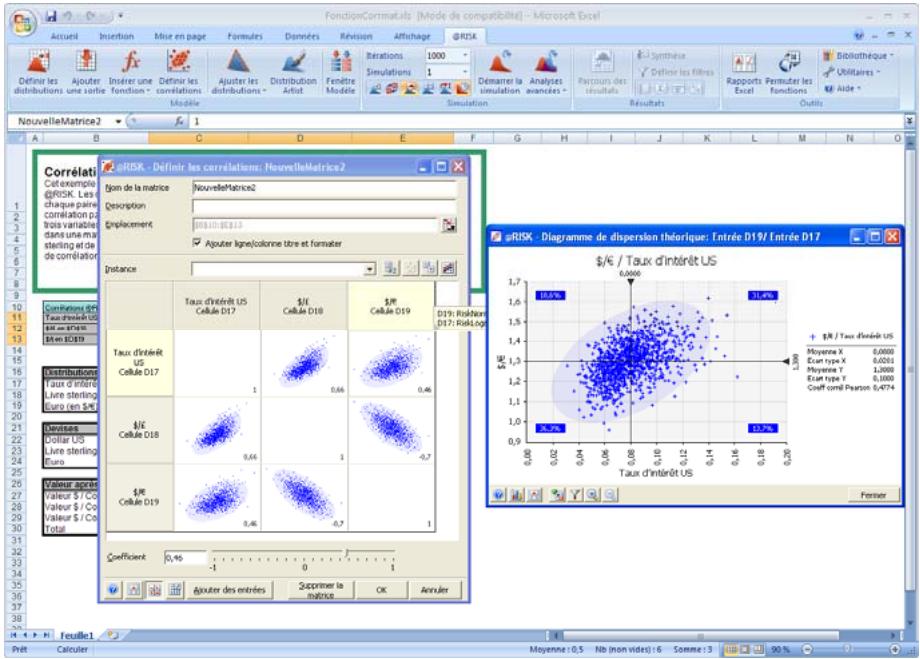
Placement d'une matrice dans excel
@RISK 5.5 permet de placer des matrices n'importe où dans les classeurs ouverts. Au besoin, vous pouvez changer les coefficients de corrélation en tapant simplement de nouvelles valeurs dans la matrice introduite dans Excel.
Toutes les corrélations définies dans la fenêtre Définir les corrélations donnent lieu à l'ajout de fonctions de propriété RiskCorrmat aux fonctions de distribution corrélées dans vos formules. Ces fonctions de propriété RiskCorrmat font référence à l'emplacement de la matrice affichée dans Excel.
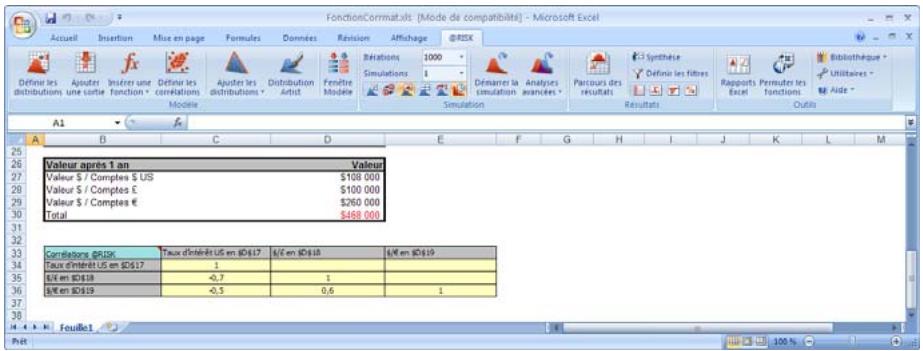
Passage en revue des corrélations simulées
Après une simulation, vous pouvez vérifier les correlations simulées effectives en cliquant sur une cellule de la matrice lors du « parcours » des résultats de simulation dans le tableau.
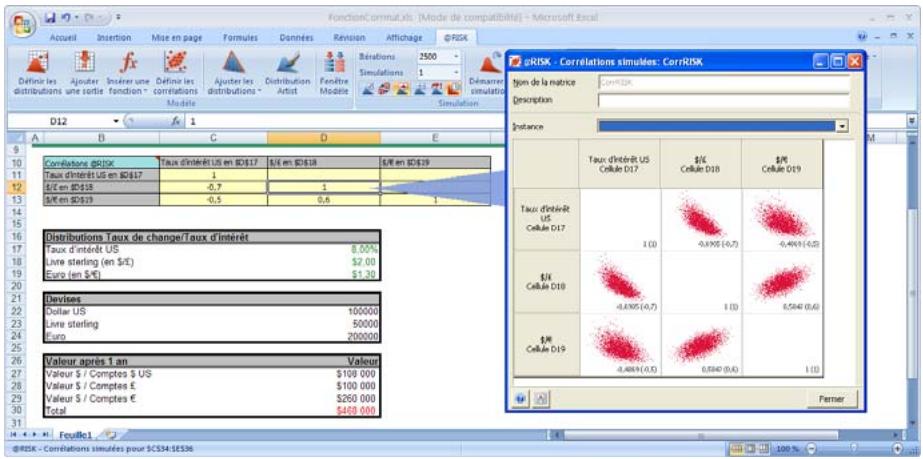
Série temporelle corréée
Une série temporelle corrélée se crée au départ d'une plage multi-période contenant un ensemble de distributions similaires dans chaque période temporelle. Il est souvent désirable de corréler les distributions de chaque période selon la même matrice de corrélation. Dans @RISK 5.5, l'icône Série temporelle corréée de la fenêtre Définir les corrélation permet de créer cette série, par sélection de la plage voulue dans Excel.
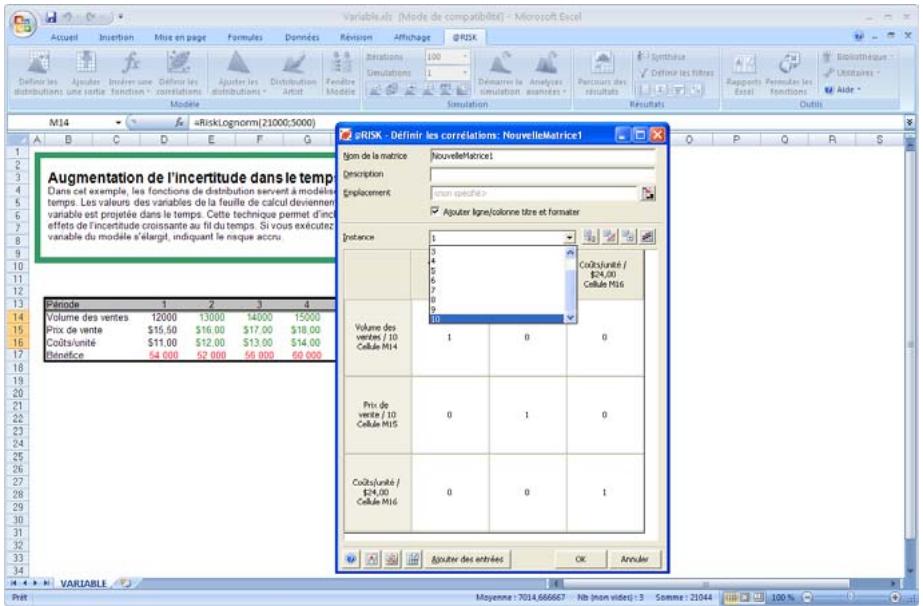
@RISK configure automatiquement une « instance » de la matrice de corrélation pour chaque ensemble de distributions similaires dans chaque période temporelle.
Définition des sorties de simulation dans le tableau
@RISK 5.5 propose plusieurs outils d'ajout ou de suppression des sorties de simulation dans le tableau. Les ajouts et suppressions s'effectuent depuis la boîte de dialogue contextuelle correspondante.
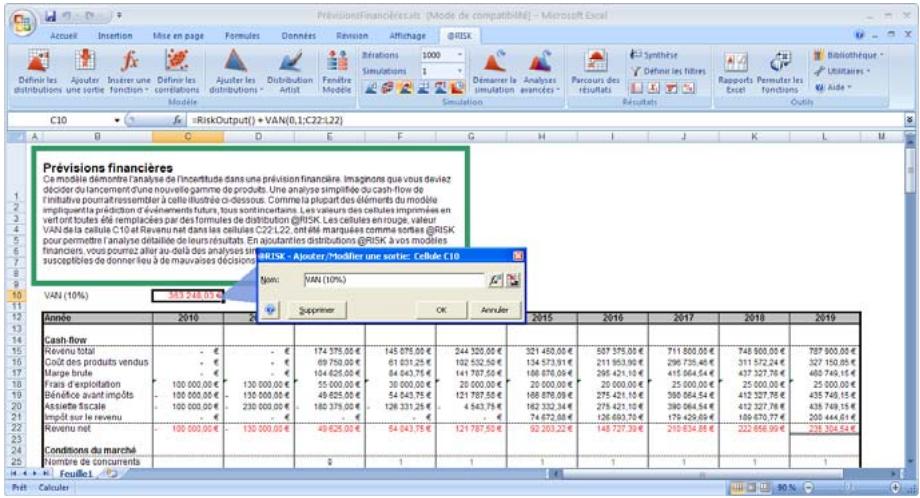
Examen d'un modèle dans la fenêtre @RISK Modèle
La fenêtre @RISK Modèle présente un tableau complet des distributions de probabilités en entrée, des sorties de simulation et des matrices de corrélation décrites dans le modèle. Cette fenêtre s'ouvre par-dessus Excel. Elle remplace la fenêtre de modèle séparée des versions @RISK 4.5 et antérieures. Les interventions suivantes peuvent y être effectuées :
- Modification d'une distribution en entrée ou d'une sortie en tapant simplement dans le tableau.
- Représentation rapide de vignettes graphiques de toutes les entrées définies.
- Expansion d'une vignette graphique au format fenêtre complète par glissement-déplacement.
- Accès, par double-clic sur une entrée quelconque du tableau, au navigateur graphique pour parcours des cellules du classeur porteuses de distributions en entrée.
- Affichage et modification des matrices de corrélation.
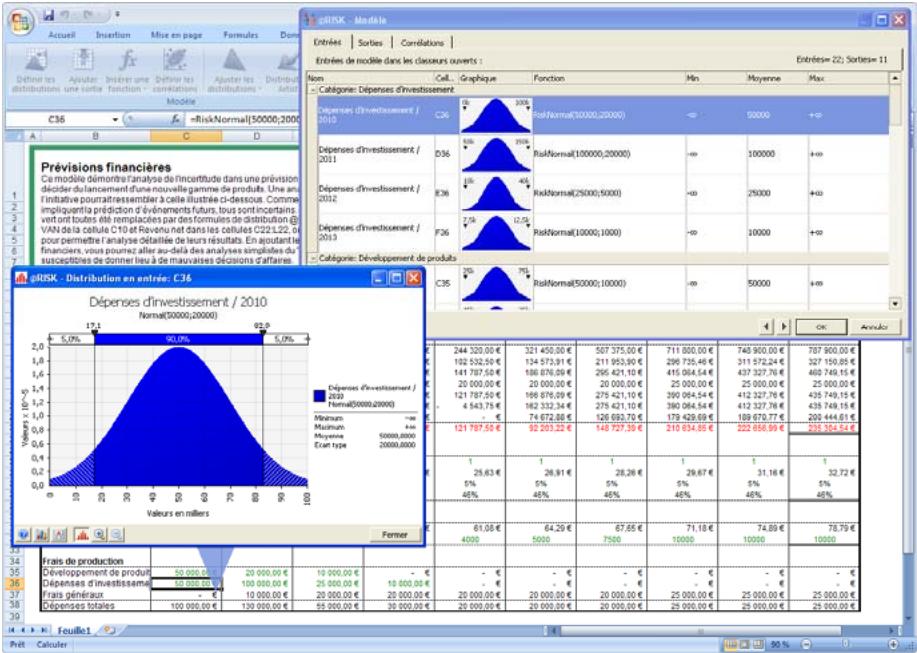
Personnalisation des statistiques affichées
Les colonnes de la fenêtre Modèle peuvent être personnalisées en fonction des statistiques à afficher sur les distributions en entrée du modèle.
L'icône de sélection des colonnes du tableau, au bas de la fenêtre, ouvre la boîte de dialogue Colonnes du tableau.
Catégorisation des entrées
Les entrées de la fenêtre Modèle sont groupées par catégorie. Par défaut, une catégorie se crée quand un groupe d'entrées partage un même nom de ligne (ou colonne). Vous pouvez aussi placer les entrées dans la catégorie de votre choix.
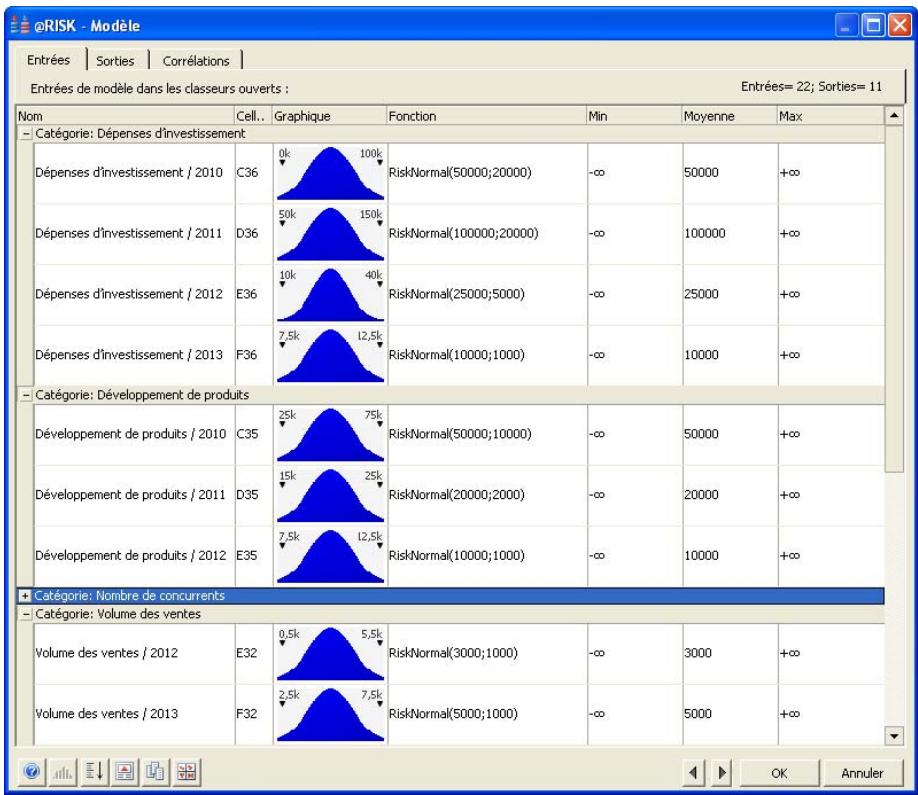
Propriétés de distributions en entrées et sorties de simulation
Une nouvelle fenêtre Propriétés permet de définir rapidement les fonctions de propriété des distributions en entrée et des sorties de simulation. Il s'agit en quelque sorte d'un assistant de saisie des fonctions de propriété des fonctions de distribution @RISK. La fenêtre est accessible lorsqu l'icône Propriétés de fonction (fx) est affichée.
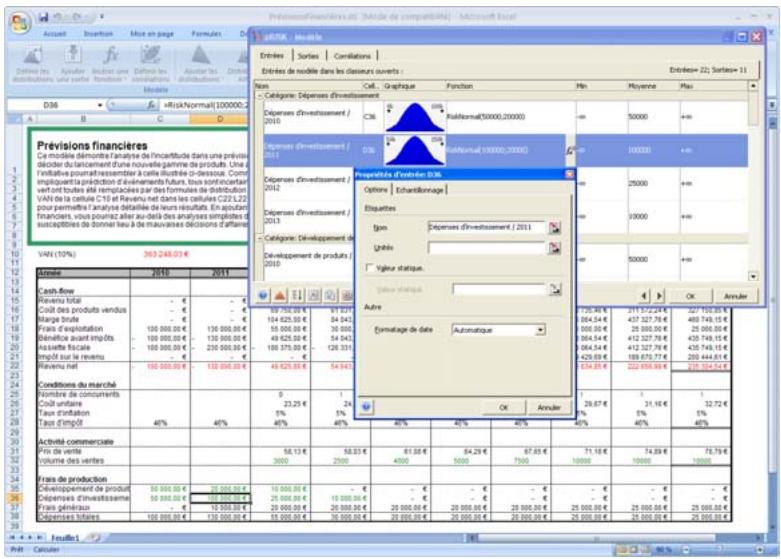
Nouvelles fonctions de propriété des distributions en entrée :
- RiskUnits - définit le libellé des unités dans les graphiques et rapports.
- RiskStatic - définit la valeur 1) renvoyée par la fonction lors d'un rec calcul Excel standard et 2) qui remplace la fonction @RISK en permutation.
- RiskSeed - générateur (racine) de nombres aléatoires d'une entrée.
Nouvelles fonctions de propriété des sorties de simulation : Renvoie uniquement la version corrigée du passage, en respectant les règles. N'ajoute aucun mot qui ne soit pas déjà présent ou clairement tronqué.
- RiskUnits - définit le libellé des unités dans les graphiques et rapports.
- RiskIsDiscrete - force @RISK à produire les graphiques et statistiques de la sortie sous forme discrète.
- RiskSixSigma - précise les valeurs LSI, LSS et cible à utiliser dans les calculs statistiques six sigma.
Permutation des fonctions @RISK
Dans @RISK 5.5, la nouvelle icône Permuter les fonctions active ou déactive par permutation les fonctions @RISK de vos classeurs. Elle facilite ainsi l'échange de vos modèles avec vos collégues qui ne disposent pas de @RISK. Si le modèle change alors que les fonctions @RISK sont déactivées, @RISK actualise leurs emplacements et valeurs statiques lors de leur réactivation.
La nouvelle fonction de propriété RiskStatic facilite l'opération. RiskStatic conserve la valeur appelée à remplacer la fonction lors de sa désactivation. Elle précise aussi la valeur que @RISK renverra pour la distribution dans un recalcul Excel standard. Si vous entrez une nouvelle distribution dans la fenêtre Définir une distribution, @RISK peut stocker automatiquement la valeur remplacée par une distribution dans la fonction de propriété RiskStatic. Supposons par exemple que la cellule C10 contienne la valeur 1000, comme indiquée dans la formule
Si, dans la fenêtre Définir une distribution, vous remplacez cette valeur par une distribution normale à moyenne de 990 et écart type de 100, la formule Excel devient :
C 1 0: = RiskNormal (9 9 0; 1 0 0; RiskStatic (1 0 0 0))
Remarquez que la valeur originale de la cellule (1000) est conservée dans la fonction de propriété RiskStatic.
En l'absence de RiskStatic, @RISK peut utiliser la valeur probable, la médiane, le mode ou un centile d'une distribution comme valeur statique lors de la désactivation par permutation des fonctions.
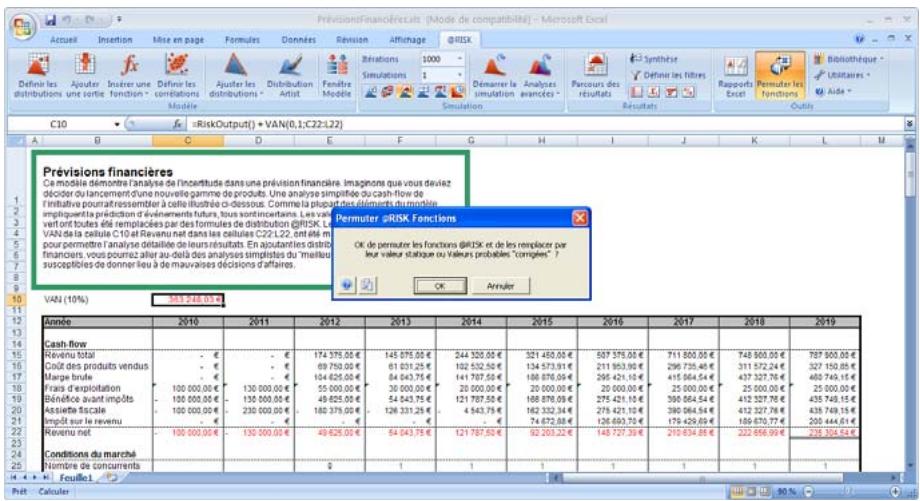
Lorsque les fonctions sont désactivées par permutation, la barre d'outils @RISK se désactive et les fonctions @RISK évientement entreees ne sont pas reconnues.
Le mode d'opération de @RISK lors de la permutation des fonctions se définit dans la boîte d'options de permutation. En cas de changements apportés au classeur alors que les fonctions @RISK sont permutées-désactivées, @RRISK peut vous signaler comment il procédera à la réinsertion des fonctions @RISK dans le modèle modifié. Dans la plupart des cas, @RISK peut : gérer automatiquement les changements apportés au classeur sous permutation-désactivation des fonctions.
Définition de distributions à partir des données
L'ajustement des distributions s'effectue désormais entièrement dans Excel, sans recours à une application séparée comme dans @RISK 4.5. L'ajustement de distributions dans les versions @RISK 5.5 Professional et Industrial se caractérisse comme suit :
- Ajustement des données échantillonnées (continues ou discrètes) à celles d'une courbe de densité ou cumulative.
- Classement des ajustements en fonction de statistiques chi carré, Kolmogorov-Smirnov ou Anderson-Darling. Graphiques comparatifs, différentiels et traces P-P et Q-Q.
- Statistiques et tests de qualité de l'ajustement.
- Fenêtre de synthèse affichant les résultats de tous les ajustements dans un seul rapport.
- Maîtrise experte de l'ajustement par spécifications précises du calcul statistique chi carré par répartition en intervalles égaux, à probabilités égales ou personnalisés.
- Capacité de créer une liste personnalisée de distributions d'ajustement prédéfinies.
- Liaison des fonctions @RISK aux données d'ajustement de sorte que les fonctions s'actualisent automatiquement quand les données changent et que le modèle est re-simulé.
L'icône Ajuster les distributions de la barre d'outils @RISK sert à ajuster les distributions aux données et à gérer les ajustements existants.
Boîte de dialogue Ajuster les distributions aux données
La boîte de dialogue Ajuster les distributions aux données permet la sélection d'une plage de données dans Excel et la spécification des options d'ajustement. Vous pouvez y sélectionner le type de données à soumettre à l'ajustement (continues, discrètes ou cumulatives), filtrer les données, préciser les types de distribution à ajuster et spécifier les intervalles Chi carré à utiliser.
Résultats graphiques d'ajustement
Les résultats de l'ajustement peuvent être représentés dans des graphiques comparatifs, différentiels et traces P-P et Q-Q. Il suffit, pour afficher les résultats de chaque distribution ajustée, de cliquer sur la liste de classement.
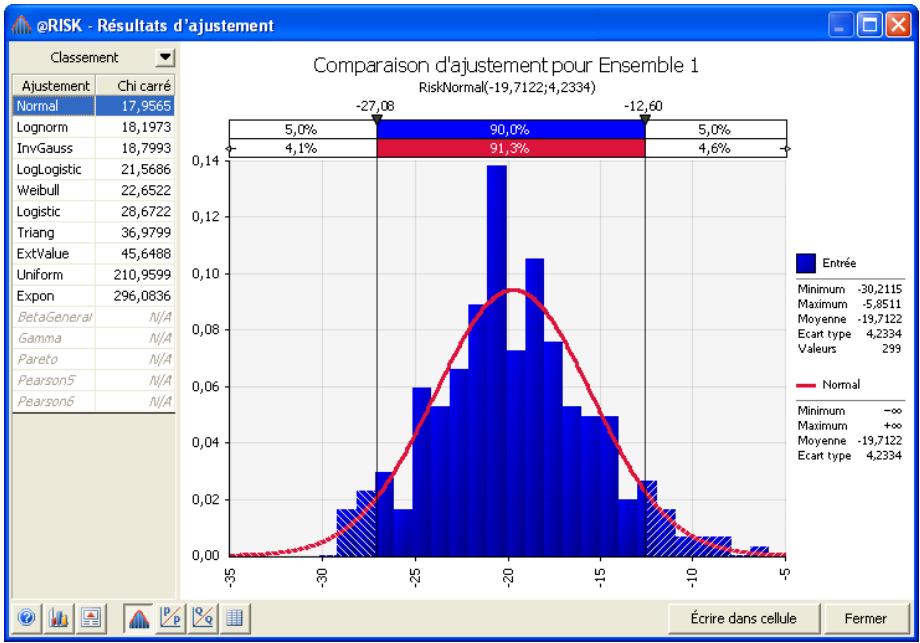
Placement d'un résultat d'ajustement dans Excel
Cellule place le résultat d'un ajustement dans le modèle sous forme de nouvelle fonction de distribution.
Sous l'option Actualiser et réajuster au début de chaque simulation, @RISK réajuste automatiquement la distribution aux données modifiées et place la nouvelle fonction de distribution réalisante dans le modèle au début de chaque simulation.
La fenêtre Distribution Artist permet de tracer librement des courbes, des histogrammes ou des graphiques de probabilité discrète pouvant servir à la création de distributions @RISK. L'approche permet d'évaluer graphiquement les probabilités puis de créer des distributions à partir du graphique.
La courbe se trace par simple glissement de la souris sur la fenêtre. Écrire dans la cellule place la courbe tracée dans le modèle sous forme de nouvelle fonction de distribution.
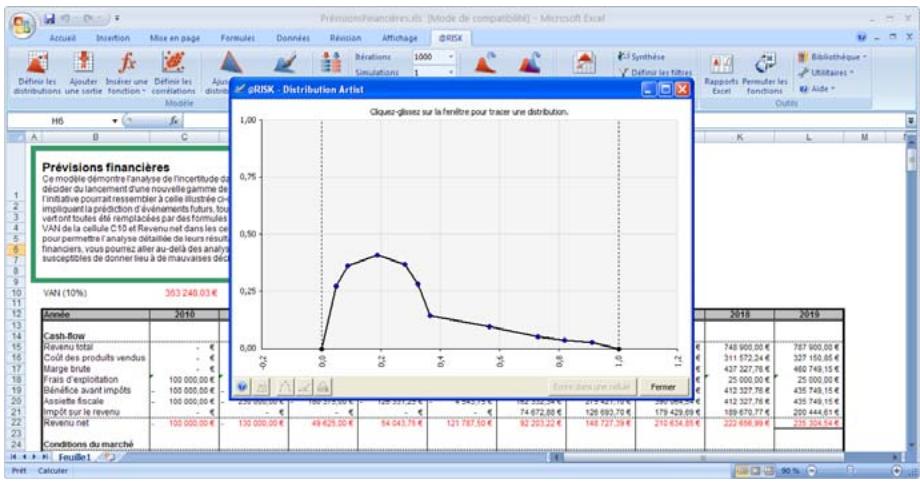
Paramètres de simulation
Les paramètres de simulation @RISK ont été améliorés pour refléter les nouvelles approches conceptuelles et capacités de @RISK 5.5. Beaucoup de ces options sont aussi modifiables depuis la nouvelle barre d'outils Paramètres @RISK.
Paramètres de simulation @RISK - Général
Les paramètres du nouvel onglet Général régissant le mode d'opération général de @RISK. Les options proposées sous "En l'absence de simulation, les distributions renvoient" s'affichent en réponse à la touche, après recalcul Excel standard. Si les valeurs aléatoires (Monte Carlo) ne sont pas sélectionnées, les valeurs statiques entrées dans une fonction de propriété RiskStatic sont renvoyées. En l'absence de fonction RiskStatic, la valeur probable, mode, médiane ou le centile sélectionné de la distribution est renvoyé.
La nouvelle icône Aléatoire/Statique de la barre Paramètres @RISK inverse rapidement la sélection du paramètre Valeurs aléatoires (Monte Carlo) ou Valeurs statiques.
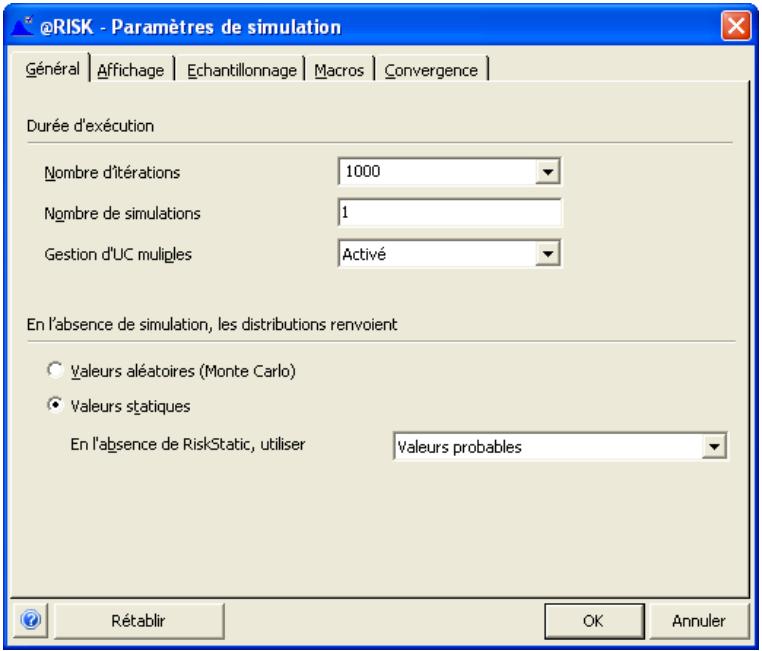
Les nouveaux paramètres de l'onglet Affichage déterminent l'affichage représenté par @RISK en cours de simulation. Tous les graphiques de résultats de simulation s'affichent désormais directement par-dessus Excel et peuvent facultativement « pointer » sur la cellule du classeur dont la distribution est affichée.
Nouveaux paramètres Affichage : automatique des résultats :
- Graphique de sortie. Sous cette configuration, un graphique des résultats de simulation de la cellule sélectionnée s'affiche automatiquement dans Excel :
- au démarrage de la simulation (si l'actualisation en temps réel est activée sous l'option Actualiser en cours de simulation toutes les XXX secondes) ou
- en fin de simulation.
- Fenêtre Synthèse des résultats. Affiche la fenêtre @RISK - Synthèse des résultats en début d'exécution de la simulation (si l'actualisation en temps réel est activée sous l'option Actualiser en cours de simulation toutes les XXX secondes) ou en fin de simulation.
- Aucun. Aucune nouvelle fenêtre @RISK ne s'affiche en début ou fin de simulation.
Nouvelles options de l'onglet Affichage de la boîte de dialogue Paramètres de simulation :
- Démo. Le mode Démo est un affichage prédéfini dans lequel @RISK actualise le classeur à chaque iteration pour démontrer le changement des valeurs et affiche et actualise un graphique de la première sortie du modèle. Ce mode est utile à l'illustration de la simulation dans @RISK.
- Actualiser en cours de simulation toutes les XXX secondes. Cette option active ou désactive l'actualisation en temps réel des fenêtres @RISK ouvertes et définit la fréquence de cette actualisation. Sous le paramètre Automatique, @RISK sélectionne la fréquence d'actualisation en fonction du nombre d'iterations et de la durée d'exécution de chacune.
Paramètres de simulation
@RISK—
Échantillonnage
Les nouveaux paramètres de l'onglet Échantillonnage déterminant le mode de prélèvement d'échantillons dans les distributions de probabilités en cours de simulation.
Nouveaux paramètres sous Nombres aléatoires :
Générateur - l'un des 8 générateurs de nombres aléatoires proposés peut être sélectionné pour les simulations. Par défaut, @RISK propose le nouveau générateur aléatoire Mersenne Twister.
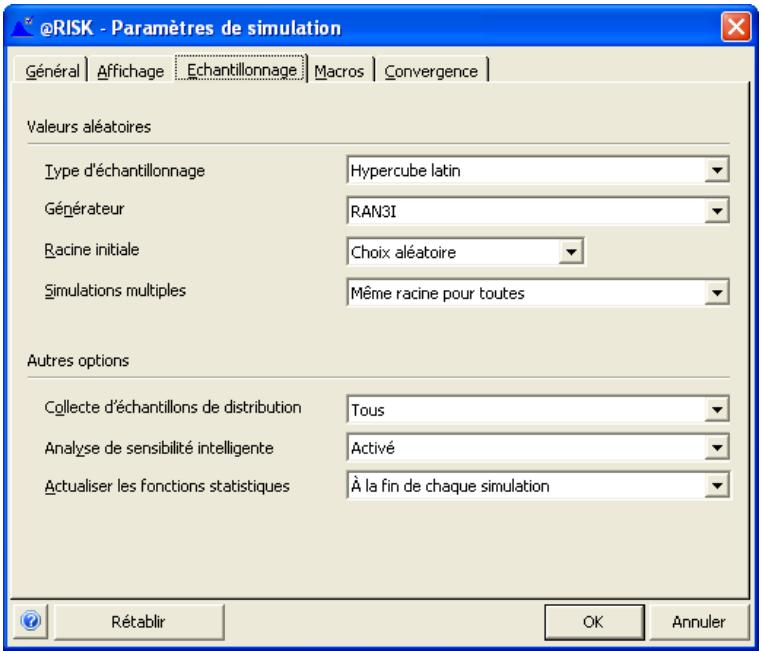
Les nouveaux paramètres de l'onglet Convergence déterminent le mode de surveillance de convergence des sorties en cours de simulation. La nouvelle fonction de propriété RiskConvergence permet de gérer dans @RISK 5.5 le test de convergence des sorties individuelles, et la boîte de dialogue Paramètres de simulation en permet la configuration générale pour toutes les sorties.
Nouvelles options de convergence :
- Tolerance - Spécifie la tolérance admise pour la statistique testée. Les paramètres ci-dessous configurent par exemple l'estimation de la moyenne de chaque sortie simulée dans une marge de 3% de sa valeur réelle.
- Niveau de confiance - Spécifie le niveau de confiance relatif à l'estimation. Par exemple, les paramètres ci-dessous spécifient que l'estimation de la moyenne de chaque sortie simulée (dans la marge de tolérance définie) doit être exacte 95% du temps.
- Tests sur - Spécifie les statistiques de sortie à tester.
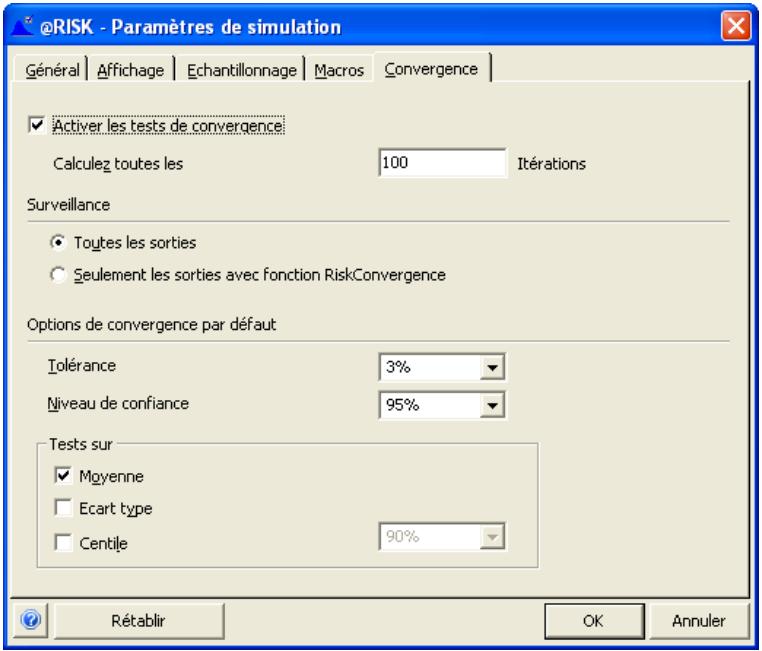
Simulations
Dans @RISK 5.5, les simulations couvrent la mise à jour des graphiques et rapport par-dessus Excel en cours d'exécution de la simulation. Les simulations peuvent être interrompues temporairement ou arrêtées à l'aide des commandes de la fenêtre de progression. La fenêtre @RISK - Synthèse des résultats présente un « tableau de bord » de toutes les sorties de simulation assorties de petites vignettes graphiques actualisées à mesure de l'exécution de la simulation.
Pendant une simulation dans @RISK 5.5
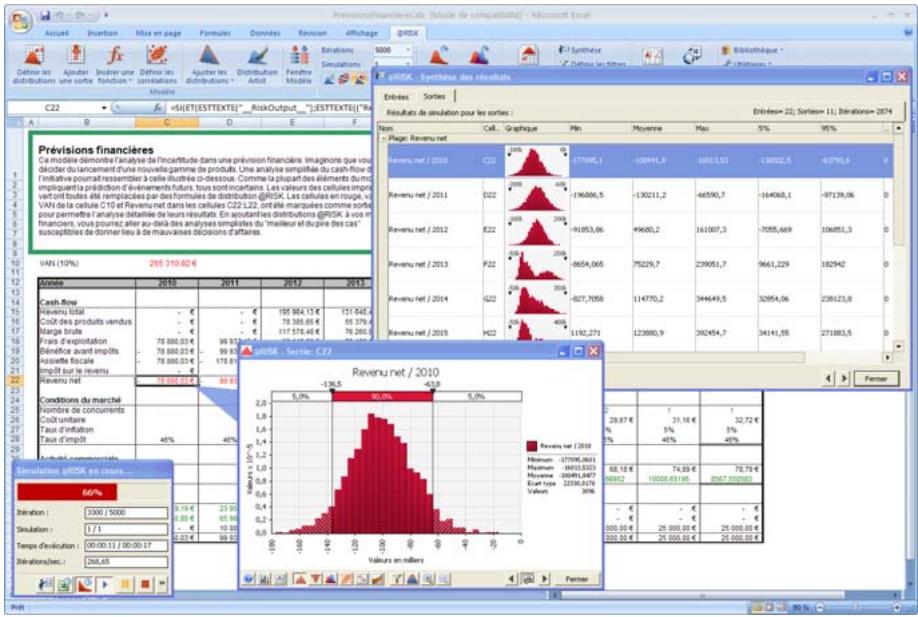
Résultats graphiques d'une simulation
Après l'exécution d'une simulation, @RISK 5.5 propose :
- un nouveau mode Parcours qui permet d'afficher aisément les graphiques des résultats de la simulation par sélection de cellules du tableau :
- la fenêtre @RISK - Synthèse des résultats où s'affichent la synthèse des résultats du modèle ainsi que des vignettes graphiques et les statistiques de synthèse de la cellule de sortie simulée et des distributions en entrée :
- de nouveaux types de graphiques - synthèse en boîte, tornado - valeurs mappées de régression et diagrammes de dispersion - pour vous aider à et interpréter vos résultats de simulation; et
- un nouveau moteur graphique assorti de nombreuses options de personnalisation pour améliorer vos rapports de résultats.
Mode parcours
Pour accéder au mode Parcours, cliquez sur l'icône Parcours des résultats de la barre d'outils @RISK. Le mode Parcours s'active automatiquement en fin de simulation si vous sélectionnez l'affichage d'un graphique en cours d'exécution.
En mode Parcours, @RISK affiche les graphiques de résultats en réponse à vos clics sur les cellules du tableau :
- Si la cellule sélectionnée est une sortie de simulation (ou contient une fonction de distribution simulée), @RISK affiche la distribution simulée dans une fenêtre légende pointant sur la cellule.
- Si la cellule sélectionnée fait partie d'une matrice de corrélation, une matrice des corrélations simulées entre les entrées de la matrice s'ouvre.
Chaque clic sur une cellule du classeur fait apparaître le graphique de résultats correspondant. Pour déplacer la fenêtre Graphique d'une cellule de sortie porteuse de résultats de simulation à l'autre dans les classeurs ouverts, appuyez sur la touche.
Depuis une fenêtre graphique, il est facile d'ajouter des superpositions et de créer des diagrammes de dispersion et graphiques de synthèse en cliquant sur les icônes prévues au bas de la fenêtre et en sélectionnant dans Excel les cellules à inclure dans le graphique.
Pour quitter le mode Parcours, il suffit de fermer le graphique ou de cliquer sur l'icône Parcours des résultats, sur la barre d'outils.
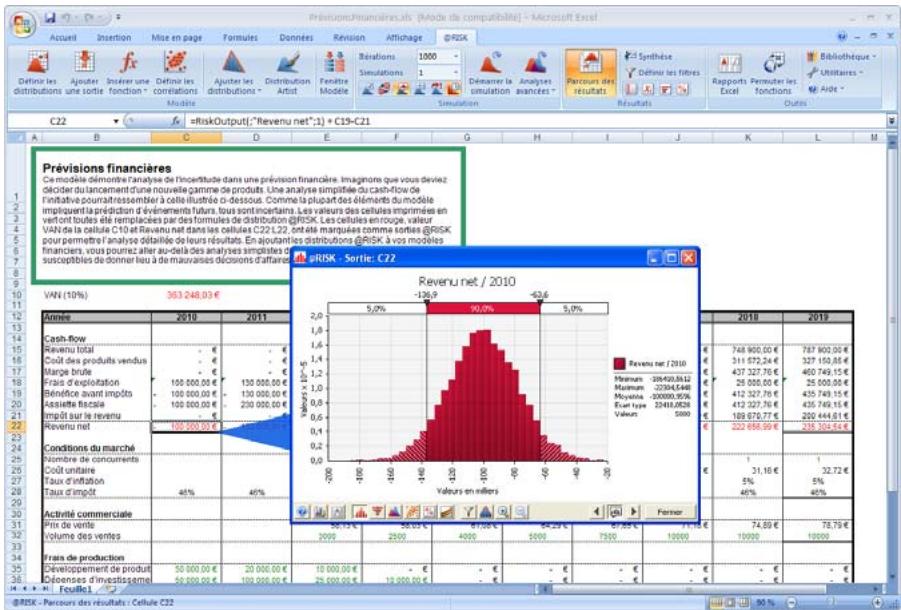
Fenêtre @RISK — synthèse des résultats
la fenêtre @RISK - Synthèse des résultats affiche la synthèse des résultats du modèle ainsi que des vignettes graphiques et les statistiques de synthèse des distributions en entrée et de la cellule de sortie simulée. Comme la fenêtre Modèle, celle-ci permet :
- l'expansion d'une vignette graphique au format fenêtre complète par glissement-déplacement;
- l'accès, par double-clic sur une entrée quelconque du tableau, au navigateur graphique pour parcours des cellules du classeur porteuses de résultats de simulation;
- la personnalisation des colonnes en fonction des statistiques à afficher sur les résultats.
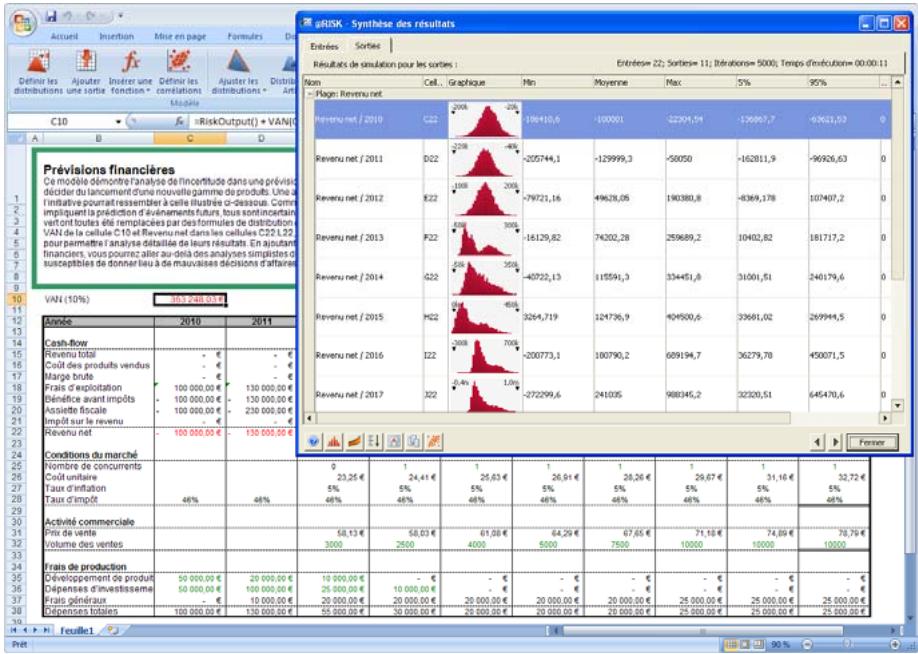
Déplacement des graphiques par glissement
Pour afficher un graphique @RISK, faites-en simplement glisser la vignette hors de la fenêtre Résultats ou Modèle. Pour l'ajout de superposition, glissez-déplacez les graphiques (ou vignettes) les uns par-dessus les autres.
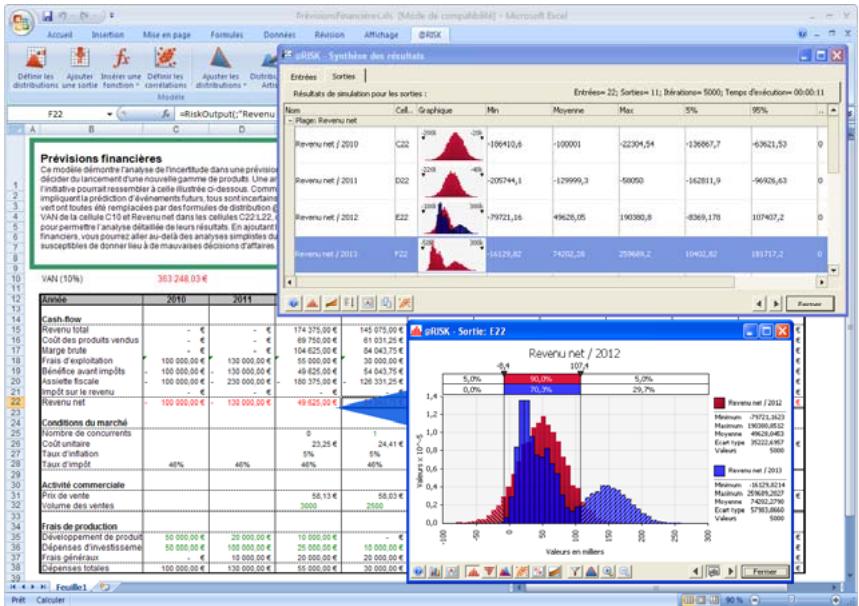
Multiplicité graphique
La sélection de plusieurs lignes dans la fenêtre @RISK - Synthèse des résultats suivie d'un clic sur l'icône Graphique, au bas de la fenêtre, permet de créer plusieurs graphiques en même temps.
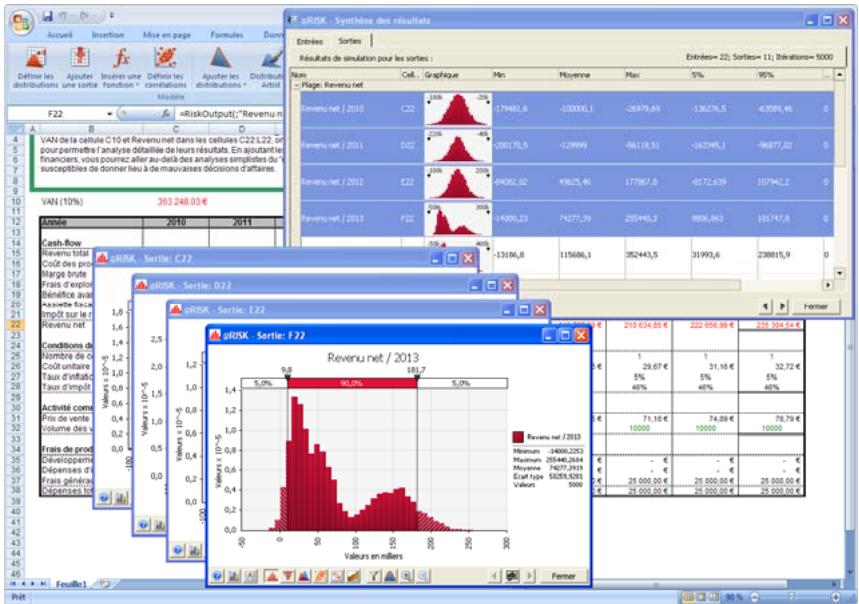
Nouveaux graphiques @RISK 5.5
Les graphiques de résultats de simulation proposés dans @RISK 5.5 incluent les nouveaux diagrammes en boîte de synthèse, graphiques tornades et diagrammes de dispersion, pour faciliter l'examen et l'interprétation de vos résultats de simulation.
Graphiques de synthèse
@RISK 5.5 propose deux types de graphiques de synthèse des tendances d'un groupe de sorties simulées (ou d'entrées) : tendance et boîte de synthèse. Pour les représenter, cliquez sur l'icône Graphique de synthèse au bas de la fenêtre graphique et sélectionnez les cellules Excel à inclure dans le graphique.
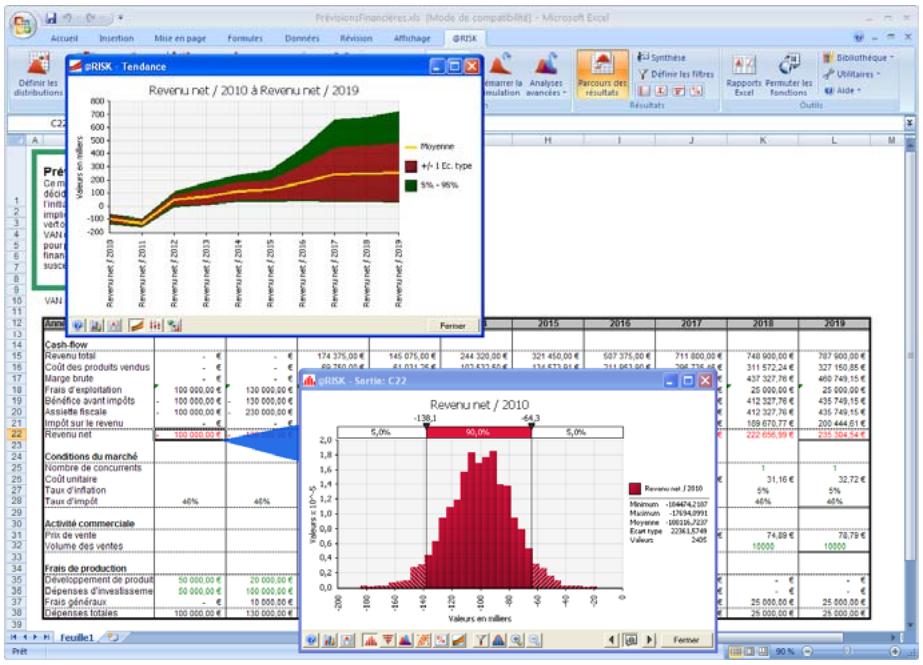
Les graphiques tornades d'une analyse de sensibilité affichent le classement des distributions en entrée qui affectent une sortie. Dans
@RISK 5.5, les graphiques tornades peuvent s'afficher selon trois méthodes : Coefficients de régression, Régression (Valeurs mappées) et Coefficients de corrélation.
Les graphiques tornades s'affichent par sélection d'une ou de plusieurs lignes dans la fenêtre @RISK - Synthèse des résultats, clic sur l'icône Tornado au bas de la fenêtre et sélection de l'une des trois options de graphique tornado proposées. Le graphique de distribution d'une sortie simulée peut aussi être changé en graphique tornado d'un clic sur l'icône Tornado dans le coin inférieur gauche du graphique.
@RISK 5.5 propose un nouveau type de graphique tornado : Regression - Valeurs mappées. Les valeurs de l'axe X de ce type de graphique tornado indiquent la quantité de changement de la sortie imputable à une variation de +1 écart type au niveau de chaque entrée. Par exemple, dans le graphique ci-dessous, quand le Volume des ventes 2017 augmente de 8 000 unités (1 écart type), la sortie VAN (10 %) augmente de 44 614.
@RISK 5.5 propose une analyse de sensibilité intelligente par pré-sélection des entrées en fonction de leur précédence par rapport aux sorties du modèle. Les entrées des formules sans lien (à travers les formules du modèle) aux sorties sont éliminées de l'analyse de sensibilité pour éviter les résultats erronés.
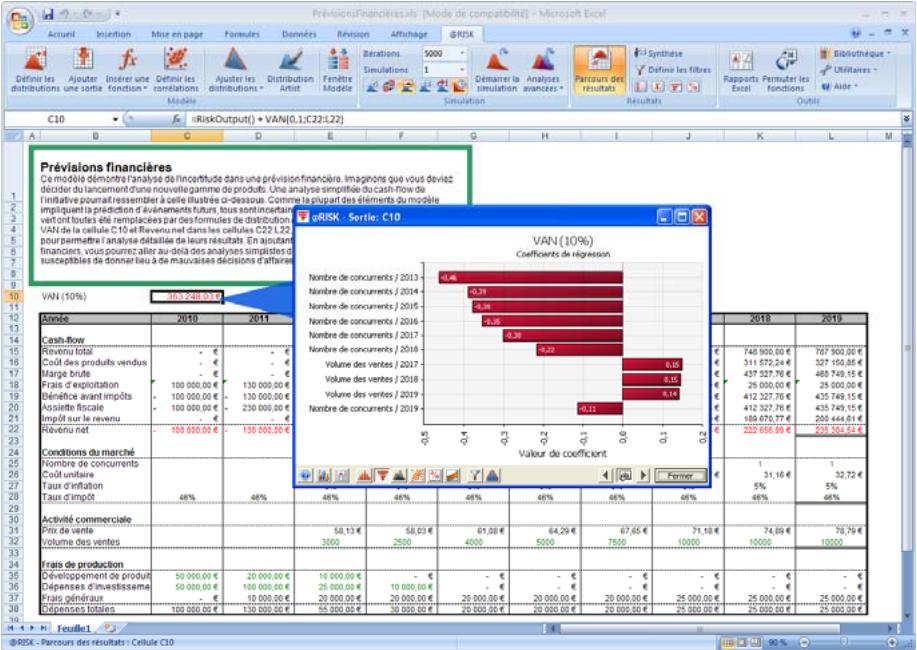
Diagrammes de dispersion
Les diagrammes de dispersion de @RISK 5.5 affichent le rapport entre les entrées et les sorties simulées. Un diagramme de dispersion est un graphique x-y qui présente les valeurs calculées à chaque itération de la simulation pour deux entrées ou sorties. L'ellipse de confiance identifie la région où tombent, à un niveau de confiance donné, les valeurs x-y. Les graphiques de dispersion peuvent aussi être normalisés de sorte que les valeurs de plusieurs entrées soient plus facilement comparables sur un même diagramme.
Pour créer un diagramme de dispersion :
- Cliquez sur l'icône Dispersion d'un graphique affiché et sélectionnez la ou les cellules Excel dont les résultats doivent être inclus dans le diagramme.
- Sélectionnez une ou plusieurs sorties ou entrées dans la fenêtre @Risk - Synthèse des résultats et cliquez sur l'icône Diagramme de dispersion.
- Déplacez par glissement une barre (l'entrée à représenter dans le diagramme de dispersion) du graphique tornado d'une sortie.
- Affichez une matrice de diagrammes de dispersion dans la fenêtre Analyse de sensibilité (voir plus bas).
- Cliquez sur une matrice de corrélation en mode Parcours pour afficher une matrice de diagrammes de dispersion représentant les correlations simulées entre les entrées corréclées dans la matrice.
À l'image des autres graphiques @RISK, les diagrammes de dispersion s'actualisent en temps réel en cours de simulation.
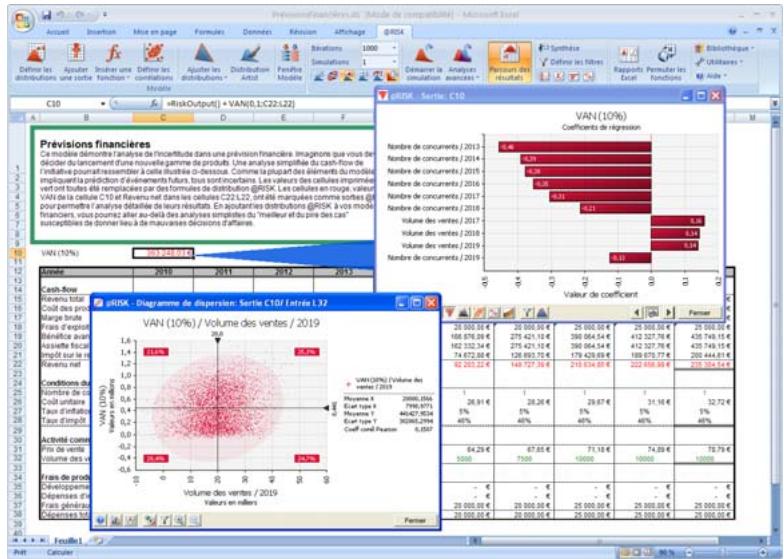
Diagrammes de dispersion de corrélations simulées
Si vous avez défini une matrice de corrélation, il est souvent utile de vérifier les corrélations effectives simulées entre une paire d'entrées de la matrice. Pour ce faire, cliquez simplement sur une cellule de la matrice lors du parcours des résultats de la simulation. Une matrice de dispersion affiche les diagrammes de dispersion entre les paires d'entrées de la matrice. Pour afficher le graphique plein format d'une vignette de la matrice, glissez-déplacez simplement la cellule hors de la matrice vers une nouvelle fenêtre graphique.
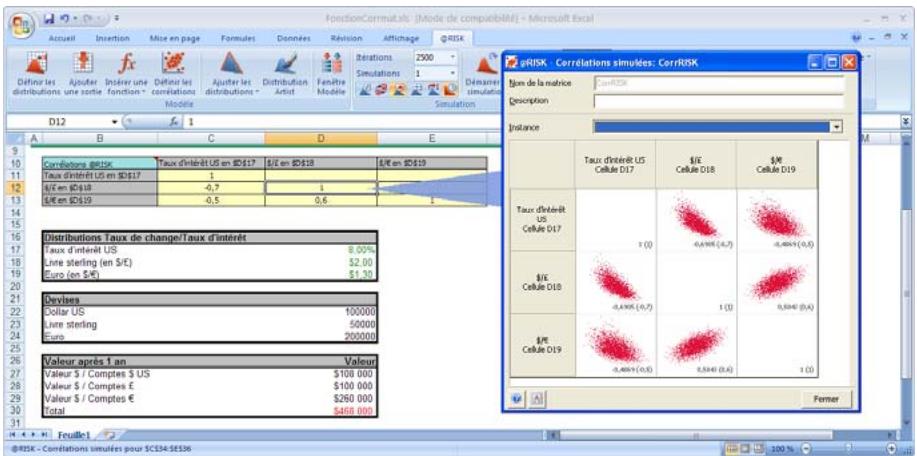
Superposition de diagrammes de dispersion
À l'image de nombreux autres graphiques @RISK, plusieurs diagrammes de dispersion peuvent être superposés pour indiquer le rapport entre les valeurs de deux (ou plusieurs) entrées et celle d'une sortie.
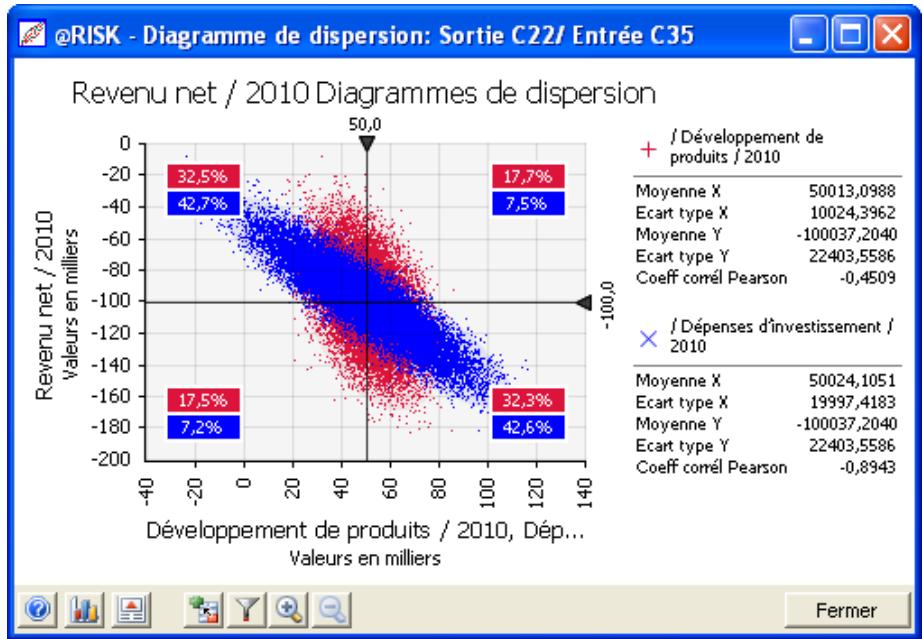
Personnalisation et rapport graphiques @RISK
Les graphiques @RISK 5.5 bénéficient d'un nouveau moteur graphique spécialement conçu pour le traitement des données de simulation. Les graphiques peuvent être personnalisés et améliorés, souvent d'un simple clic sur l'élément approprié. Par exemple, pour changer le titre d'un graphique, il suffit de cliquer dessus et de taper le nouveau titre désiré.
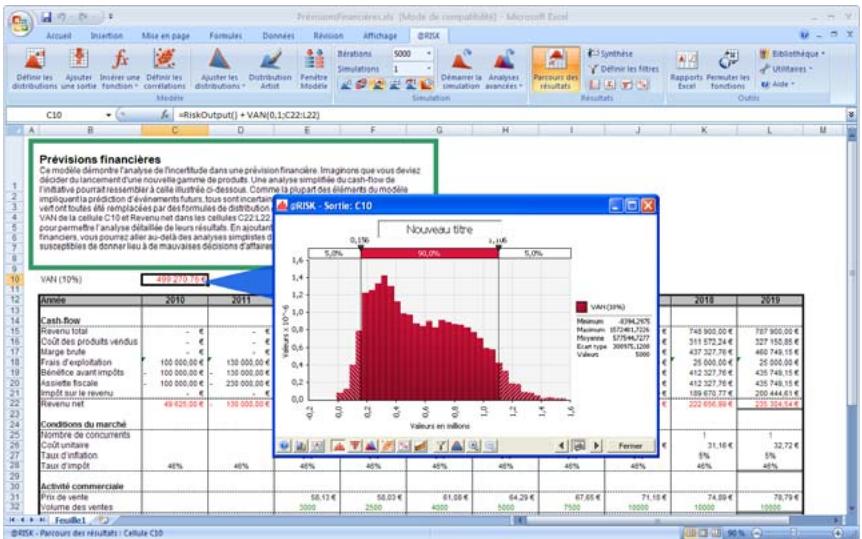
La personnalisation d'un graphique affiché peut aussi s'effectuer à travers la boîte de dialogue Options graphiques. La personnalisation concerne les couleurs, l'échelle, les polices et les statistiques affichées.
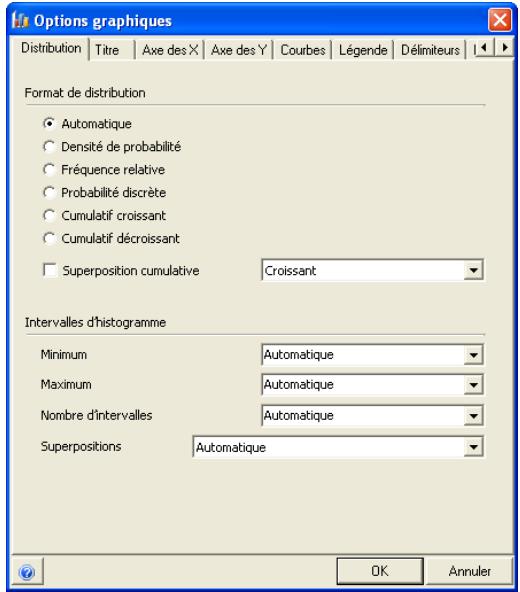
Graphique @RISK dans word avec statistiques
Les statistiques affichées se joignent à tout graphique copié-collé dans votre classeur Excel ou dans un rapport PowerPoint ou Word. Il suffit de cliquer droit sur le graphique, de le copier, puis de le coller dans le rapport.
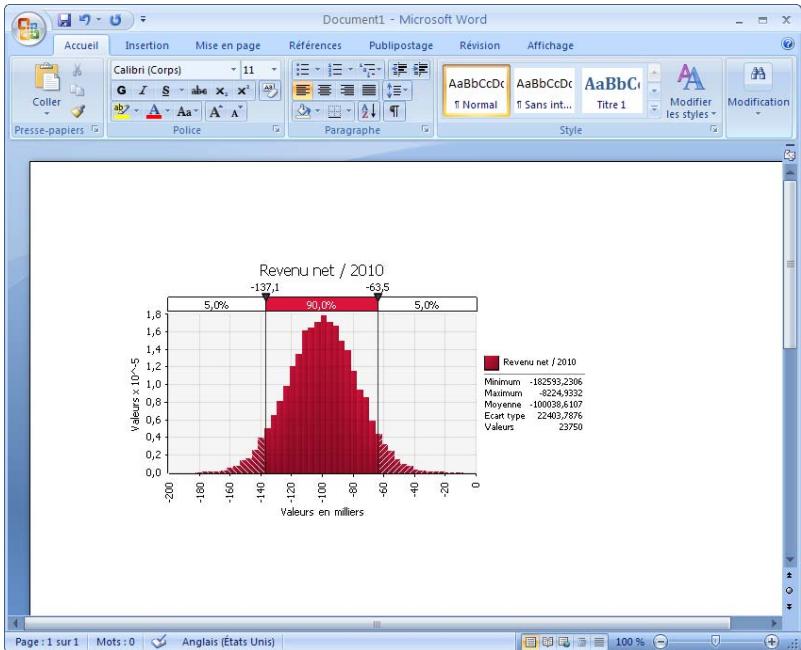
Rapports de résultats de simulation
Dès le moment où une simulation a été exécutée, @RISK 5.5 propose une série de rapports utiles à l'interprétation des résultats : Statistiques détaillées, Données, Analyse de sensibilité et Analyse de scénario. Dans les versions antérieures, jusqu'à @RISK 4.5, ces rapports s'affichaient dans la fenêtre séparée @RISK - Synthèse des résultats. Il suffit désormais de cliquer, sur la barre d'outils @RISK, sur l'icône du rapport désiré.
Exportées vers Excel, ces fenêtres de rapport sont exploitables dans un classeur Excel.
Si le paramètre de simulation Actualiser en cours de simulation toutes les XXX secondes est sélectionné, toutes les fenêtres de rapport s'actualisent pendant la simulation.
Ce rapport présente toutes les statistiques relatives aux sorties simulées et aux entrées. Il admet l'entrée de valeurs cibles pour les entrées et les sorties. La nouveauté de ce rapport dans @RISK 5.5 est sa capacité de « pivoter » et de présenter les statistiques par lignes plutôt qu'en colonnes.
Fenêtre données
Ce rapport affiche, par itération, toutes les valeurs calculées pour les sorties simulées, ainsi que toutes les valeurs échantillonnées pour les distributions de probabilités en entrée. De plus :
- les données d'une simulation peuvent être triées en fonction des valeurs clés qui vousInterested.
Passage en revue des itérations dans la fenêtre Données
Les itérations d'une simulation exécutée précédemment peuvent être passées en revue, avec mise à jour des valeurs échantillonnées et calculées dans Excel. L'approche est utile à la recherche des itérations erronées et des itérations ayant mené à certains scénarios de sortie.
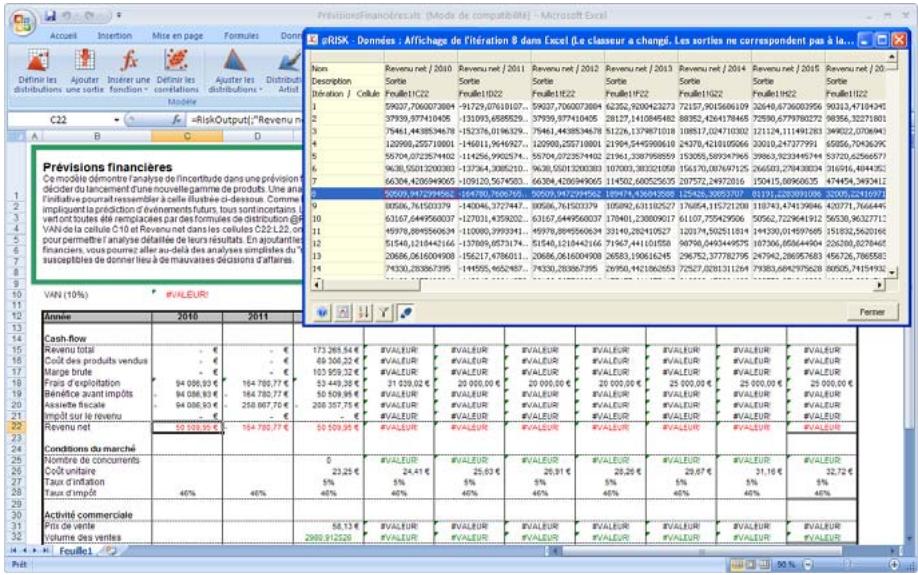
Fenêtre de sensibilité
Ce rapport présente les résultats de l'analyse de sensibilité pour toutes les sorties du modèle. Les résultats sont classés en fonction de la sortie sélectionnée. Nouveau dans @RISK 5.5 :
Rapport de Régression - Valeurs mappées - Affichage d'une matrice de diagrammes de dispersion, représentant les diagrammes de dispersion individuels de chaque entrée par rapport à chaque sortie du rapport.
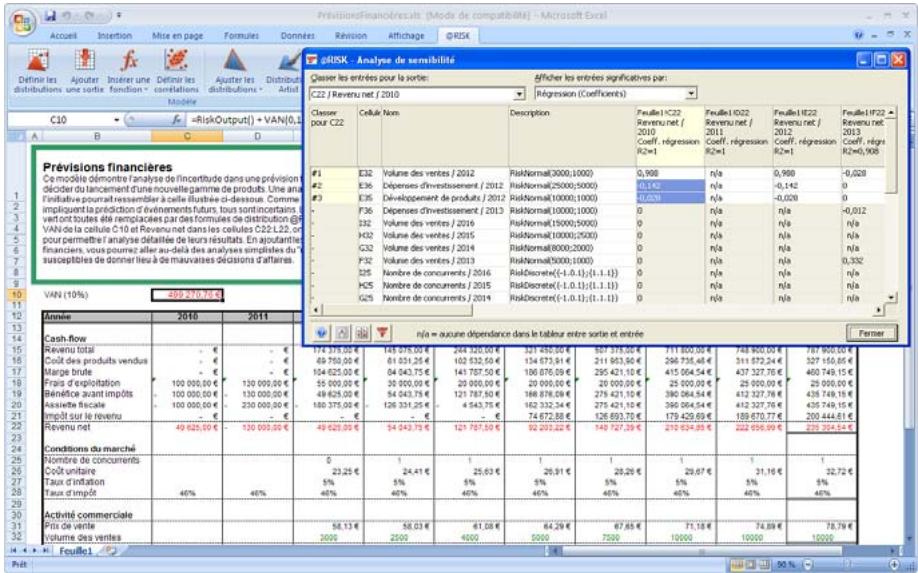
Matrice de diagrammes de dispersion dans la fenêtre de sensibilité
Un diagramme de dispersion est un graphique x-y qui présente la valeur en entrée échantillonnée par rapport à la valeur de sortie calculée à chaque itération de la simulation. Dans la matrice des diagrammes de dispersion, les résultats classés de l'analyse de sensibilité sont affichés avec leurs diagrammes de dispersion. Pour afficher la matrice, cliquez sur l'icône Dispersion dans le coin inférieur gauche de la fenêtre Sensibilité.
En glissant-déplaçant une vignette de diagramme de dispersion hors de la matrice, vous pouvez l'étendre à une fenêtre graphique plein format. Il est également possible de superposer plusieurs diagrammes de dispersion par glissement-déplacement d'autres vignettes de la matrice sur un diagramme existant.
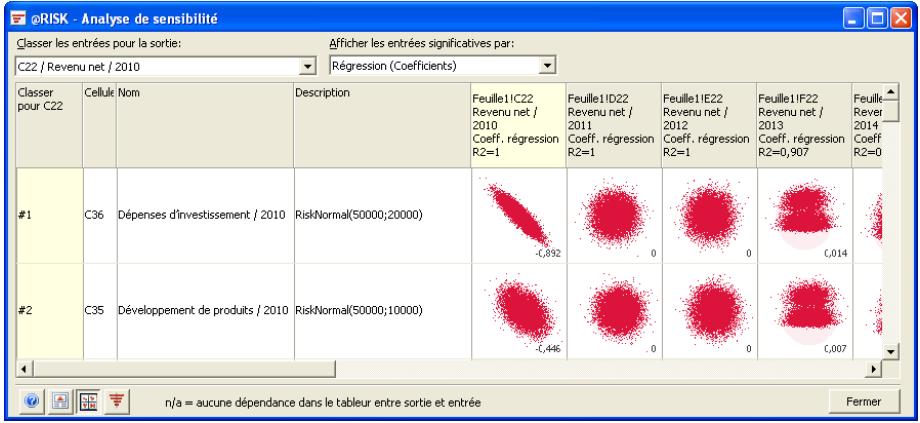
L'analyse de scénario permet de déterminer les variables en entrée qui contribuent de façon significative à la réalisation d'un but. Par exemple, lesquelles sont les variables qui contribuent à un niveau de vente exceptionnellement élevé? Ou lesquelles sont les variables qui contribuent à la réalisation de bénéfices inférieurs à 1 million d'euros?
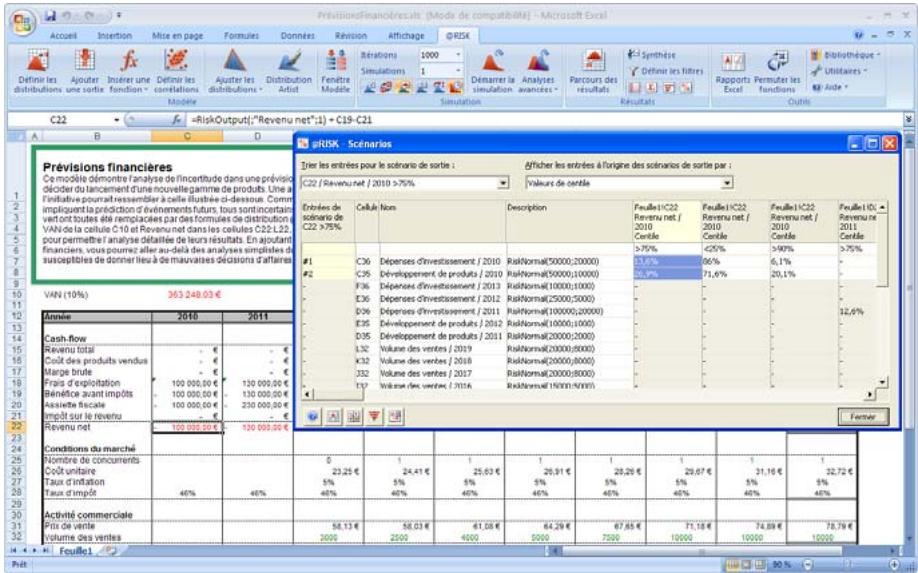
Matrice de diagrammes de dispersion dans la fenêtre de scénarios
Un diagramme de dispersion, dans la fenêtre de scénarios, est un diagramme de dispersion x-y superposé. Ce graphique présente :
1) la valeur en entrée échantillonnée par rapport à la valeur de sortie calculée à chaque itération de la simulation, 2) superposée d'un graphique de dispersion de la valeur en entrée échantillonnée par rapport à la valeur de sortie calculée lorsque la valeur de sortie correspond au scénario entré.
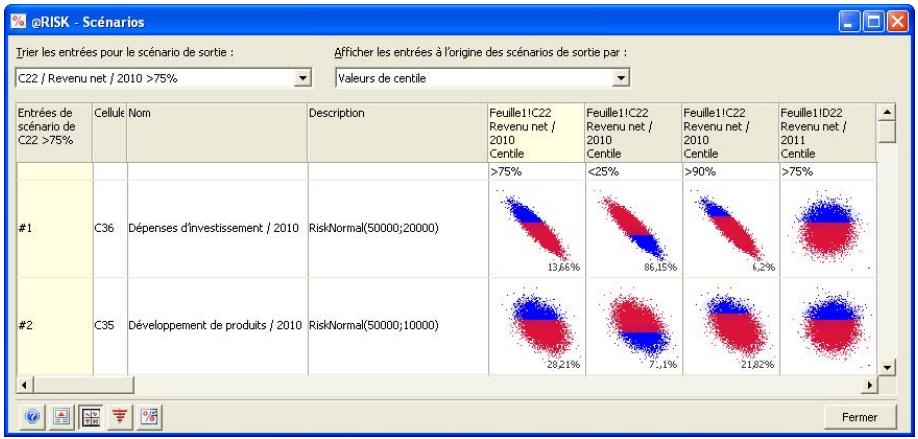
Dans la matrice des diagrammes de dispersion, les résultats classés de l'analyse de scénario sont affichés avec leurs diagrammes de dispersion. Pour afficher la matrice, cliquez sur l'icône Dispersion dans le coin inférieur gauche de la fenêtre Scénarios.
En glissant-déplaçant une vignette de diagramme de dispersion hors de la matrice, vous pouvez l'étendre à une fenêtre graphique plein format. Il est également possible de superposer plusieurs diagrammes de dispersion par glissement-déplacement d'autres vignettes de la matrice sur un diagramme existant.
Exportation des rapports vers excel
Chaque fenêtre de Rapport @RISK 5.5 est exportable et exploitable dans Excel. Pour exporter un rapport, cliquez sur l'icône Édition au bas de sa fenêtre et Sélectionnez Dans Excel.
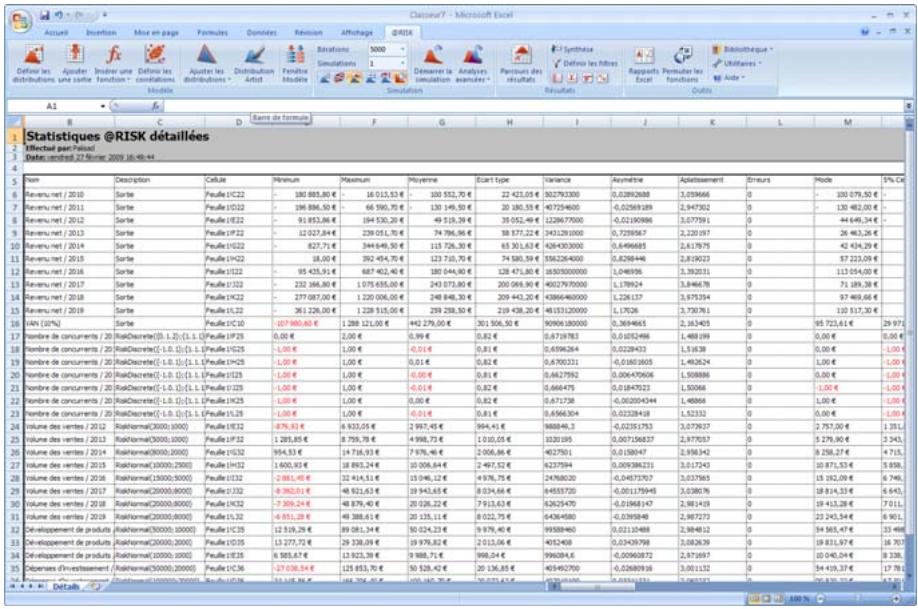
Enregistrement des simulations
@RISK 5.5 propose de nouvelles options d'enregistrement des simulations exécutées et de comparaison avec d'autres :
Stockage des simulations dans le classeur Excel. Stockage et comparaison de différentes simulations dans la Bibliothèque @RISK (voir plus bas).
@RISK 5.5 permet l'enregistrement de toutes les données - résultats de simulation et graphiques - dans le classeur Excel. Cette nouvelle approche facilite le partage des simulations avec d'autres utilisateurs, sans avoir à s'inquiéter du fichier. RSK distinct des versions @RISK antérieures.
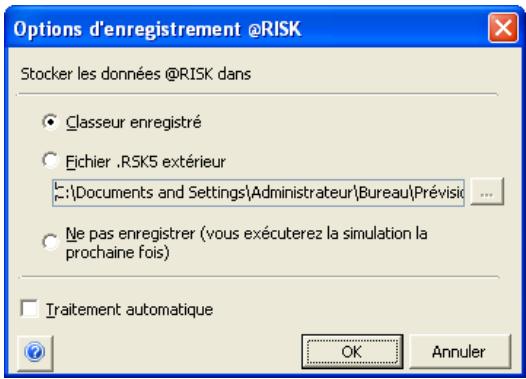
Quand une simulation est enregistrée dans un classeur, toutes les données et tous les graphiques stockés s'ouvrent automatiquement à chaque ouverture du classeur dans Excel quand @RISK tourne aussi.
La nouvelle commande Paramètres d'application du menu Utilitaires de @RISK permet également de spécifier l'emplacement de stockage par défaut de vos données @RISK.
Bibliothèque @RISK
Les versions @RISK 5.5 Professional et Industrial s'accompagnent de la Bibliothèque @RISK, application de base de données distincte utilisée au partage des distributions de probabilités en entrée de @RISK et à la comparaison des résultats de différentes simulations. La Bibliothèque @RISK repose sur SQL Server pour le stockage des données @RISK. Au sein d'une organisation, une bibliothèque @RISK partagée donne accès
aux distributions de probabilités en entrée communes, prédéfinies pour les modèles de risque de l'organisation, aux résultats de simulation de différents utilisateurs et
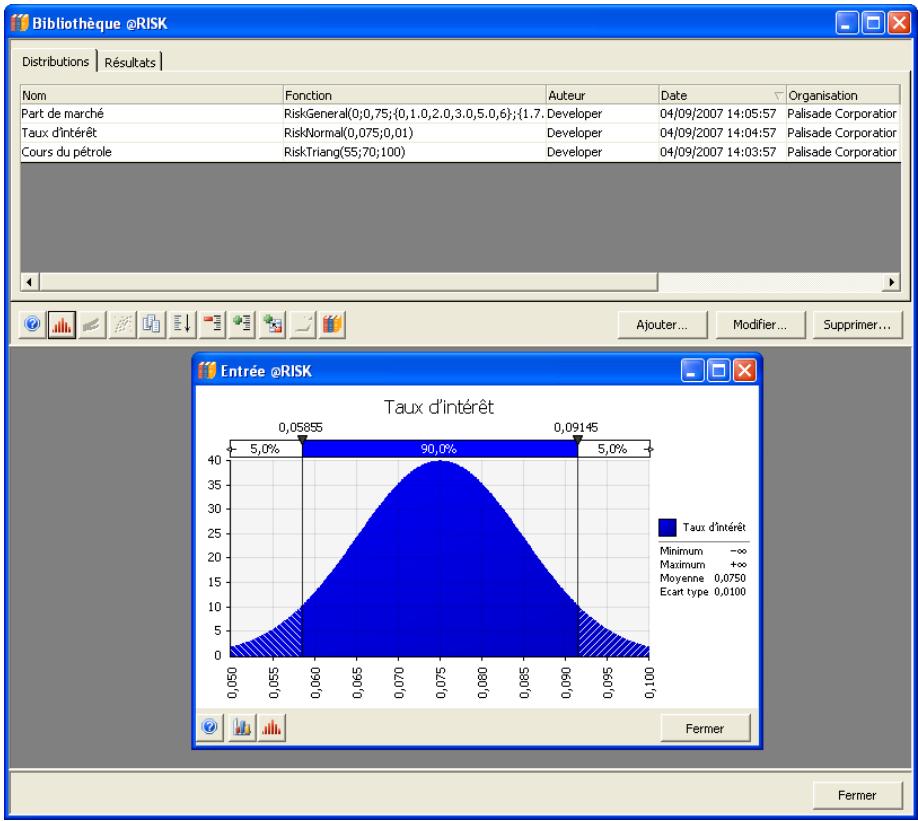
Présentation rapide de @RISK. 99
Procédure d'analyse de risque. 99
Comment @Risk se « lie » à Excel 99
Entrée de distributions dans les formules d'un classeur...........101
Sorties de simulation 102
Fenêtre Modèle 103
Définition des distributions à partir des données. 104
Exécution d'une simulation. 104
Résultats de la simulation 106
Capacités analytiques expertes 108
Configuration et simulation d'un modèle @RISK 111
Distributions de probabilités dans une feuille de calcul 111
Corrélation des variables en entrée 115
Ajustement des distributions aux données. 117
Fenêtre @RISK Modèle 120
Paramètres de simulation 122
Exécution d'une simulation. 124
Mode Parcours 127
Fenêtre @RISK Synthèse des résultats. 128
Fenêtre Statistiques détaillées 129
Cibles. 129
Représentation graphique des résultats. 130
Résultats de l'analyse de sensibilité 137
Résultats de l'analyse du scénario. 139
Rapports Excel 141
Présentation rapide de @RISK
Ce chapitre présente une introduction rapide à l'usage de @RISK en combinaison avec Microsoft Excel. Il vous guidera à travers les étapes de configuration d'un modèle Excel à exploiter sous @RISK, la simulation de ce modèle et l'interprétation des résultats de cette simulation.
L'information présente dans ce chapitre est également proposée dans le didacticiel @RISK en ligne. Pour accéder au didacticiel, CHOISSEZ Démarrer/Programmes/Palisade DecisionTools/Tutorials/@RISK Tutorial.
Procédure de l'analyse de risque
@RISK étend les fonctionnalités analytiques de Microsoft Excel à l'analyse de risque et à la simulation. Ces techniques vous permettent d'analyser le risque dans vos feuilles de calcul. L'analyse de risque identifie l'éventail des résultats possibles d'une feuille de calcul et leur probabilité relative.
@RISK utilise la technique de simulation Monte Carlo pour analyser le risque. Par cette technique, les valeurs en entrée incertaines d'une feuille de calcul se spécifient en tant que distributions de probabilités. Une valeur en entrée est une valeur, dans une cellule ou une formule de feuille de calcul, servant à générer les résultats de la feuille. Dans @RRISK, une distribution de probabilités descriptive de la plage des valeurs possibles de l'entrée remplace sa valeur fixe unique originale. Les entées et les distributions de probabilités sont décrites en détails au Chapitre 2 : Présentation de l'analyse de risque.
Comment @risk se « lie » à excel
Pour ajouter l'analyse de risque à votre tableau, @RISK y introduit ses menus, barres d'outils et fonctions de distribution personnalisées.
Le menu @RISK
Un menu @RISK s'ajoute aux versions Excel 2003 et antérieures. Il donne accès à toutes les commandes nécessaires à la configuration et à l'exécution des simulations.
Les barres d'outils @RISK
Une barre d'outils @RISK s'ajoute à Excel (versions 2003 et précédentes), ainsi qu'un ruban @RISK sous Excel 2007. Les icônes et commandes de ces barres donnent rapidement accès à la plupart des options @RISK.
Les fonctions de distribution @RISK
Dans @RISK, les distributions de probabilités se définissent directement dans les formules de la feuille de calcul à l'aide de fonctions personnalisées. @RISK intègre ces nouvelles fonctions, qui représentent chacune un type de distribution de probabilités (tel que NORMAL ou BETA), à l'ensemble des fonctions du tableau. L'entrée d'une fonction de distribution comporte deux éléments : le nom de la fonction (RiskTriang - distribution triangulaire -, par exemple) et les arguments qui décrivent la forme et l'étendue de la distribution (RiskTriang(10;20;30), par exemple, où 1_ représente la valeur minimum, 20, la valeur la plus probable et 30, la valeur maximum).
Vous pouvez faire appel aux fonctions de distribution chaque fois qu'une valeur utilisée compte un degré d'incertitude. Les fonctions @RISK s'utilisent comme n'importe quelle fonction de tableau ordinaire : vous pouvez les inclure dans des expressions mathématiques et employer des références de cellule ou des formules comme arguments.
Entrée de distributions dans les formules d'un classeur
La fenêtre automatique Définir une distribution de @RISK permet d'ajouter des fonctions de distribution de probabilités en toute capacité aux formules de la feuille de calcul. Cette fenêtre s'ouvre d'un clic sur l'icône Définir une distribution.
Elle représente graphiquement les distributions de probabilités susceptibles de représenter les valeurs d'une formule de tableau. Chaque distribution affichée décrit la plage de valeurs possibles d'une entrée incertaine du modèle. Les statistiques affichées indiquent, de plus, la manière dont la distribution définit une entrée incertaine.
L'affichage graphique d'une entrée incertaine est utile à la présentation de votre définition de l'entrée à vos collègues et autres interlocuteurs. Le graphique présente la plage des valeurs possibles d'une entrée et la probabilité relative de chaque valeur comprise dans la plage. Grâce aux graphiques de distribution, vous pouvez aisément incorporer vos évaluations expertes de l'incertitude dans vos modèles d'analyse du risque.
Pour déplacer la fenêtre Définir une distribution affichée d'une cellule adjacente de distributions à l'autre dans les classeurs ouverts, appuyez simplement sur la touche.
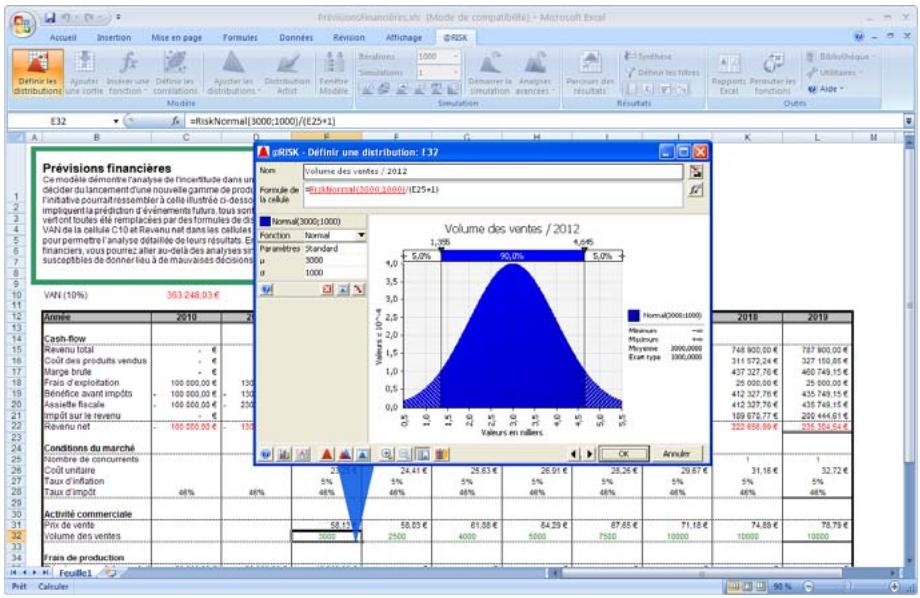
Sorties de simulation
Après avoir entré les fonctions de distribution dans une feuille de calcul, vous devez identifier les cellules ou les plages de cellules pour lesquelles vous souhaitez obtenir des résultats de simulation. Ces cellules sont généralement celles des résultats du modèle («profit», par exemple), mais il peut aussi s'agir de n'importe lesquelles d'autres. Pour sélectionner les sorties, mettez la cellule ou la plage de cellules souhaitées comme sorties en surbrillance dans la feuille de calcul et cliquez sur l'icône Ajouter une sortie (flèche rouge vers le bas).
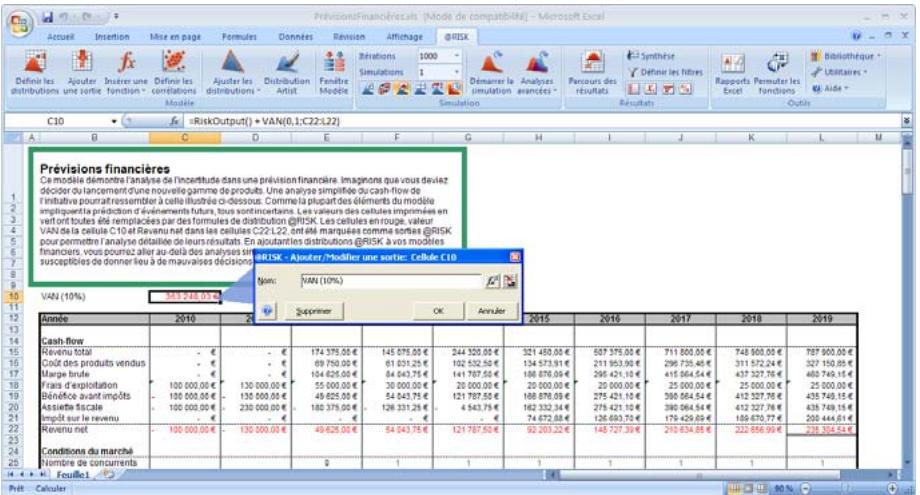
Fenêtre modèle
La fenêtre @RISK - Modèle présente un tableau complet des distributions de probabilités en entrée et des sorties de simulation décrites dans le modèle. La fenêtre @RISK - Modèle s'ouvre par-dessus Excel et permet les opérations suivantes :
- Modification d'une distribution en entrée ou d'une sortie en tapant simplement dans le tableau.
- Expansion d'une vignette graphique au format fenêtre complètement par glissement-déplacement.
- Représentation rapide de vignettes graphiques de toutes les entrées définies.
- Accès, par double-clic sur une entrée quelconque du tableau, au navigateur graphique pour parcours des cellules du classeur porteuses de distributions en entrée.
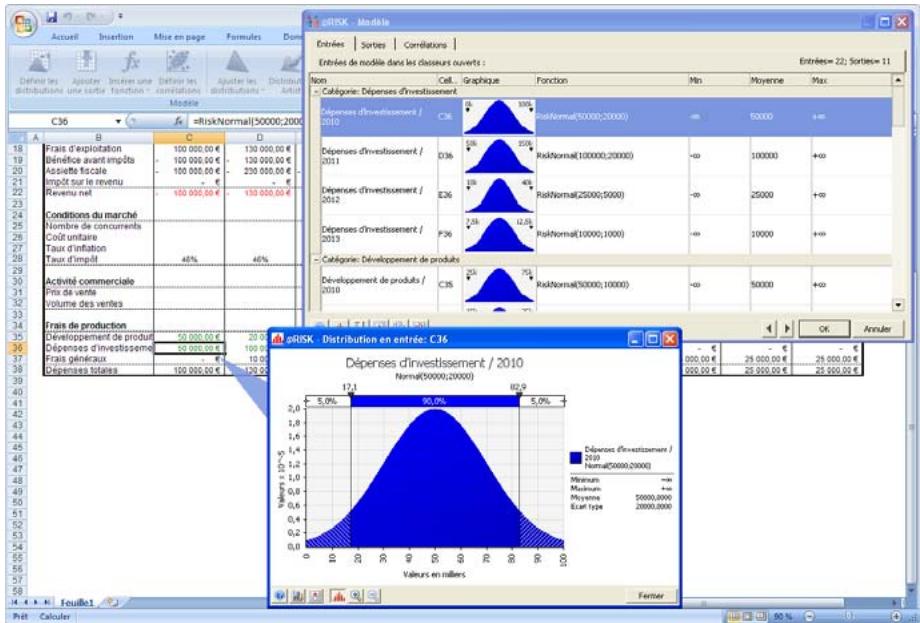
Les colonnes de la fenêtre Modèle peuvent être personnalisées en fonction des statistiques à afficher sur les distributions en entrée du modèle.
Définition de distributions à partir des données
La barre d'outils d'ajustement @RISK (versions Professional et Industrial uniquely) permet d'ajuster les distributions de probabilités à vos données. L'ajustement est utile en présence de données existantes dont on peut faire la base d'une distribution en entrée. Il se peut, par exemple, que vous disposiez de données historiques relatives au prix d'un produit et que vous désiriez créer une distribution des prix à partir de ces données.
Les distributions résultat d'une opération d'ajustement peuvent être affectées à une valeur incertaine du modèle définis dans le tableau. Mieux encore, les données Excel utilisées dans un ajustement peuvent être mises en « liaison interactive » pour actualisation automatique de l'ajustement en cas de variation des données et nouvelle simulation du modèle.
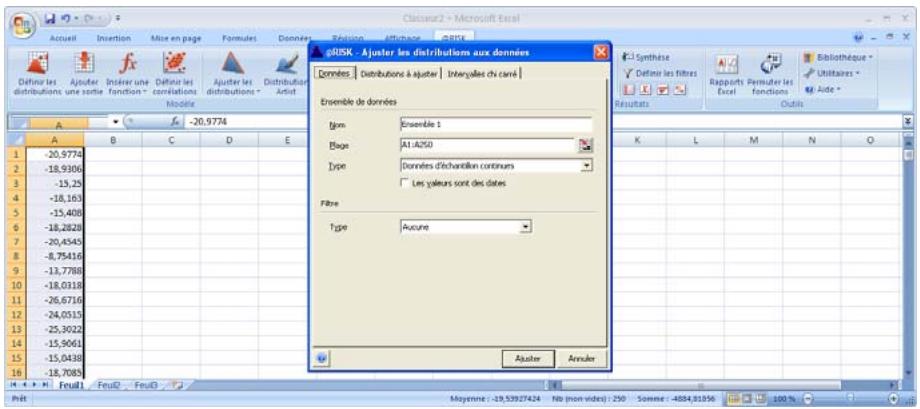
Exécution d'une simulation
Pour exécuter une simulation, cliquez sur l'icône Démarrer la simulation, sur la barre d'outils ou le ruban @RISK.

Lors de l'exécution d'une simulation, la feuille de calcul se calcule de façon répétitive, selon un processus dit d'« iterations », avec à chaque fois un ensemble de nouvelles valeurs possibles échantillonnées dans chaque distribution en entrée. À chaque iteration, la feuille est recalculée avec le nouvel ensemble de valeurs échantillonnées et un nouveau résultat possible est généré pour les cellules de sortie.
Au fur et à mesure que la simulation avance, de nouvelles issues possibles sont générées à chaque iteration. @RISK tient le compte de ces valeurs de sortie et les affiche sur un graphique contextual associé à une sortie.
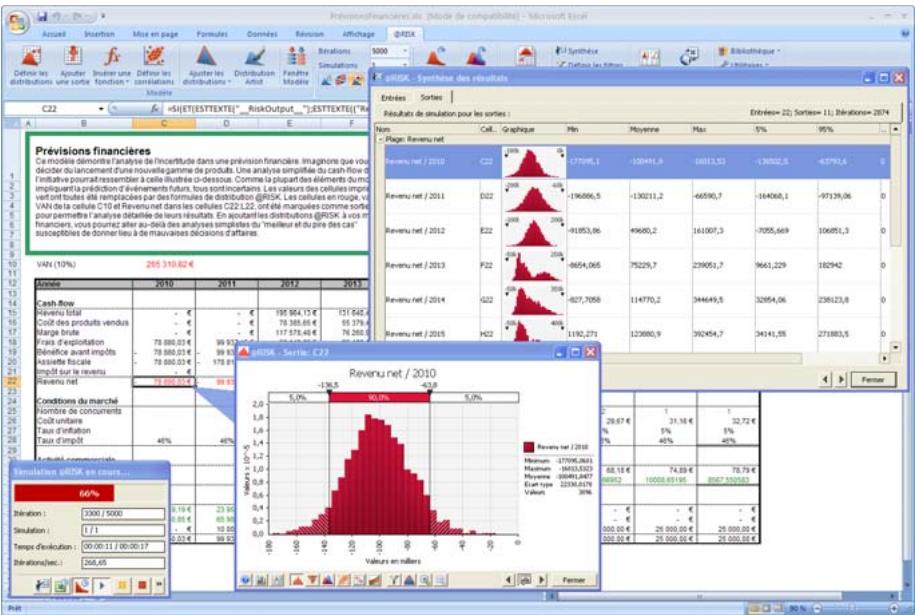
Ce graphique de la distribution des issues possibles se crée sur la base de toutes les valeurs de sortie obtenues : elles sont analysées et leur distribution statistique est calculée sur leur plage minimum-maximum.
Résultats de la simulation
Les résultats d'une simulation @RISK comprennent les distributions de résultats possibles pour les sorties demandées. @RISK génère par ailleurs des rapports d'analyse de sensibilité et de scénario qui identifient les distributions en entrée les plus influentes. Les résultats sont représentés clairement par des graphiques (distributions de fréquence des valeurs de variables de sortie possibles, courbes de probabilités cumulatives, graphiques tornades représentant les sensibilités d'une sortie à différentes entrées et graphiques de synthèse représentatifs de la variation du risque sur une plage de cellules de sortie).
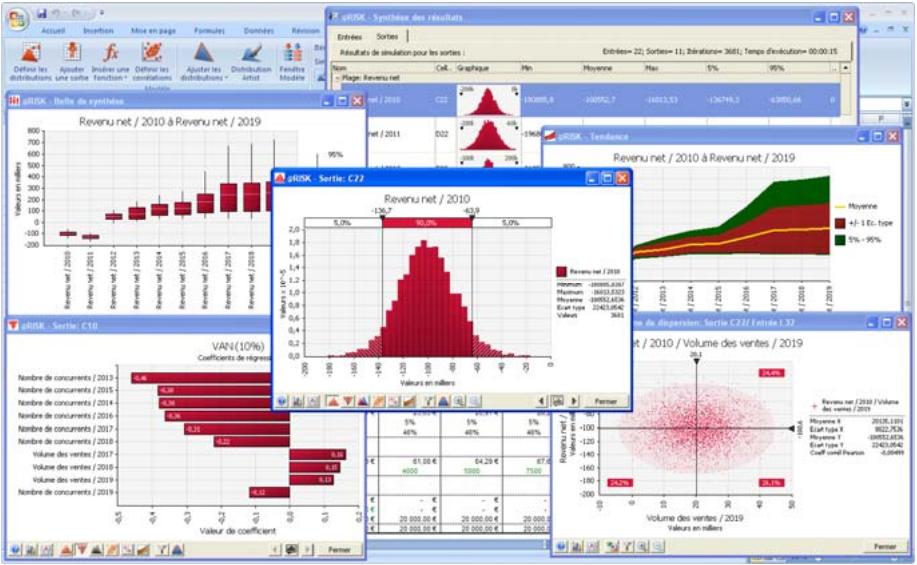
Rapports excel d'une simulation @RISK
Le moyen le plus simple d'obtenir un rapport de simulation @RISK dans Excel (ou Word) consiste à en copier-coller le graphique et les statistiques.
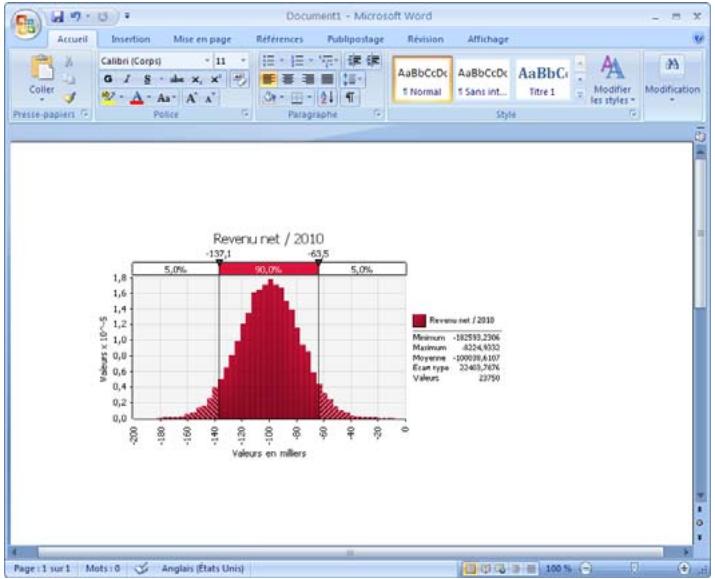
Toutes les fenêtres de rapport sont en outre exportables vers une feuille Excel, où les formules donnent accès aux valeurs.
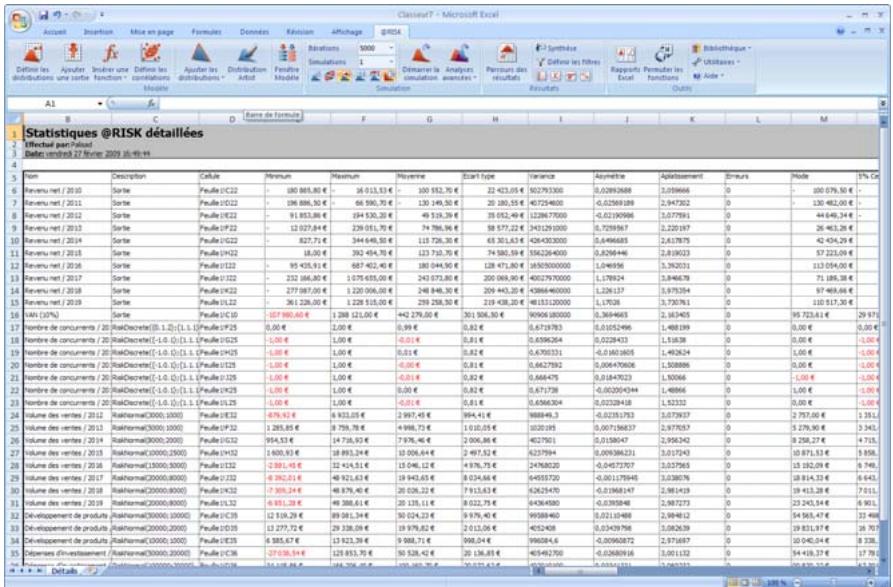
@RISK propose aussi un ensemble de rapports standard de simulation, qui en récapitulent les résultats. De plus, les rapports @RISK générés dans Excel peuvent se conformer aux masques personnalisés qui en régissent le formatage, les titres et les logos.
Capacités analytiques expertes
@RISK apporte des fonctionnalités expertes qui permettent l'analyse sophistiquée des données de simulation. Le programme recueille les données de simulation par itération pour les distributions en entrée comme pour les variables de sortie. Il analyse cet ensemble de données pour déterminer :
- la sensibilité, en identifiant les distributions en entrée qui sont « significatives » dans la détermination des valeurs des variables de sortie, et les scénarios, ou combinaisons de distributions en entrée qui génèrent les valeurs de sortie cibles.
Analyse de sensibilité
L'analyse de sensibilité — qui identifie les entrées significatives — s'exécute selon deux techniques analytiques distinctes : l'analyse de régression et le calcul de corrélation des rangs. Les résultats d'une analyse de sensibilité peuvent être représentés dans un graphique de type « tornado », dont les barres plus longues du haut représentent les variables en entrée les plus significatives.
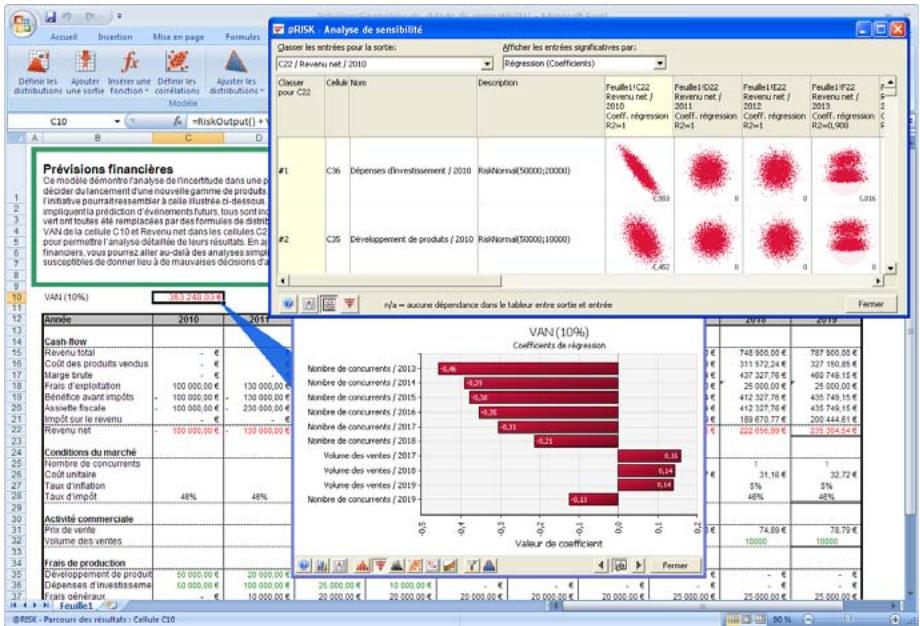
Analyse de scénario
L'analyse de scénario identifie les combinaisons d'entrées conduisant aux valeurs de sortie cibles. Elle cherche à identifier les groupes d'entrées associés à certaines valeurs de sortie, permettant la caractérisation des résultats d'une simulation par une déclaration du type : « Quand les bénéfices sont élevés, les entrées significatives sont : frais d'exploitation faibles, prix de vente très élevés, volumes de vente élevés, etc. »
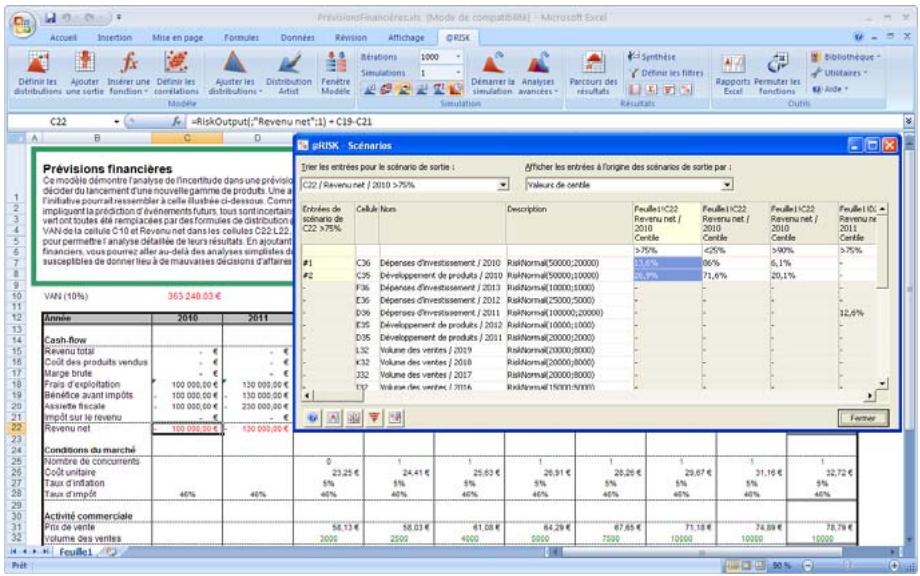
Configuration et simulation d'un modèle @RISK
Maintenant que vous vous faites une idée du fonctionnement de @RISK, examinons le processus de configuration d'un modèle @RISK dans le tableau et l'exécution d'une simulation sur ce modèle. Nous aborderons brièvement les sujets suivants :
- Distributions de probabilités dans une feuille de calcul Correlations entre les distributions
- Exécution d'une simulation
- Résultats de la simulation Graphiques des résultats de la simulation
Distributions de probabilités dans une feuille de calcul
Comme mentionné plus haut, l'incertitude dans un modèle @RISK se définit à l'aide de fonctions de distribution. Plus de 30 fonctions sont possibles, décrivant, chacune, un type de distribution de probabilités différent. Les fonctions les plus simples sont les fonctions
RiskUniform(min, max), dont les arguments spécifient la valeur possible minimum, la plus probable et maximum de l'entrée incertaine. Les fonctions plus complexes prennent des arguments propres à la distribution, tels que RiskBeta(alpha; bêta).
Pour les modèles sophistiqués, @RISK permet la configuration de fonctions de distribution faisant appel, pour leurs arguments, à des références de cellule et formules de calcul. Ces types de fonction donnent une puissance extrême à la modélisation. Vous pouvez par exemple définir un groupe de fonctions de distribution sur une ligne de feuille de calcul, et faire déterminer la moyenne de chacune par la valeur échantillonnée pour la fonction précédente. Les expressions mathématiques sont aussi admises comme arguments des fonctions de distribution.
Distributions dans la fenêtre Définir une distribution
Toutes les fonctions de distribution peuvent être définies et modifiées dans la fenêtre Définir une distribution. Cette fenêtre permet aussi, entre autres possibilités, d'entrer des fonctions de distribution multiples dans la formule d'une cellule, de définir le nom d'une distribution et de tronquer une distribution.
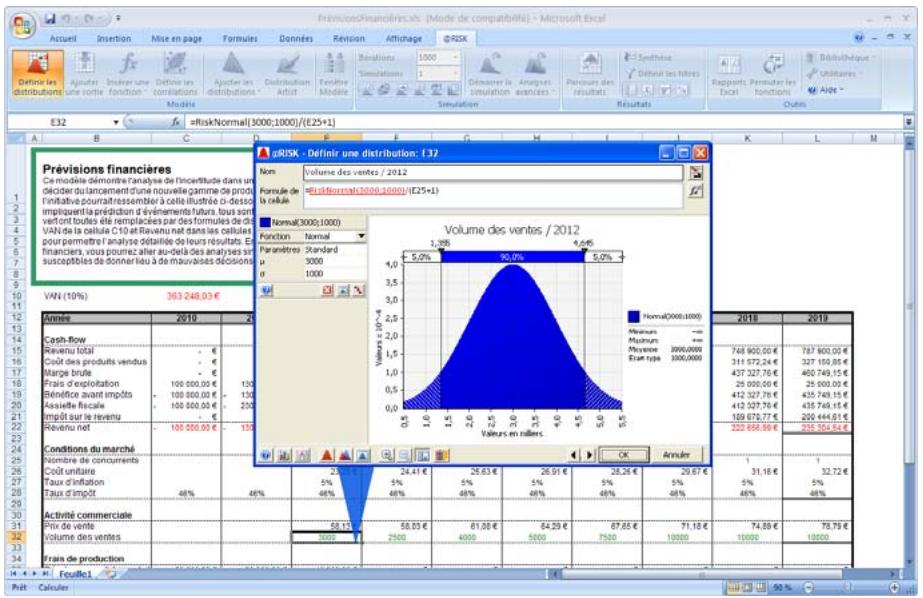
Entrée de valeurs d'argument
Les valeurs d'argument se saisissent dans le volet d'arguments ou, directement, dans la formule affichée. Ce volet s'affiche à gauche du graphique.
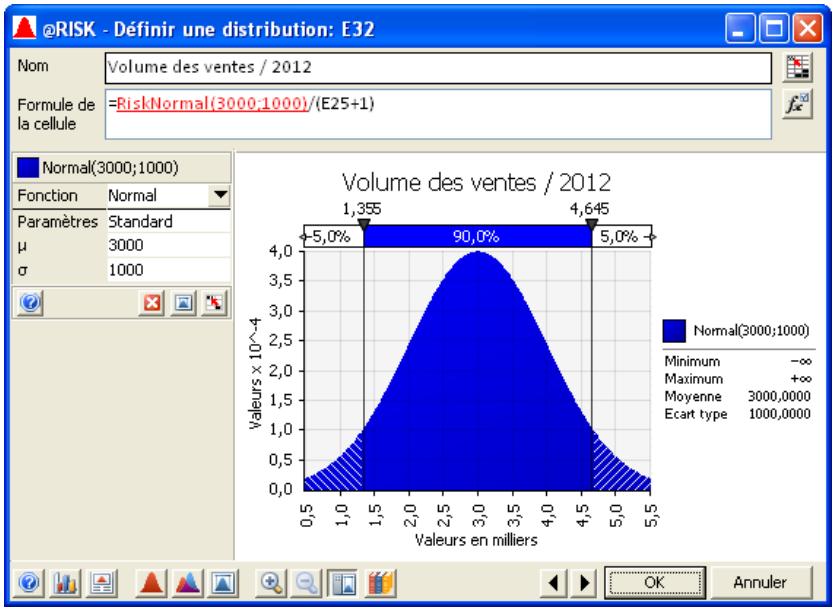
Si vous changez le type de paramètres, vous pouvez sélectionner l'entrée de paramètres secondaires ou tronquer la distribution.
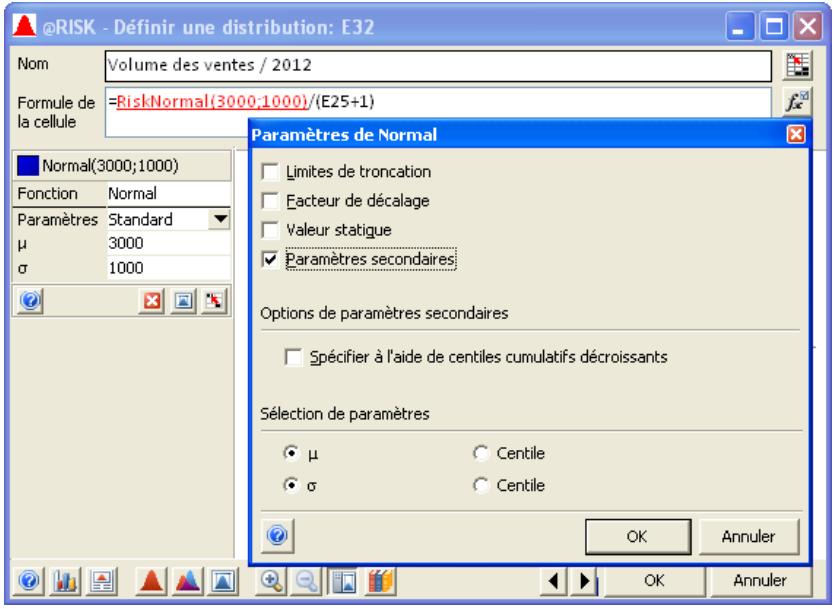
Propriétés des fonctions de distribution @RISK
Certains arguments des fonctions de distribution @RISK sont obligatoires ; d'autres ne sont que facultatifs. Les seuils arguments obligatoires sont les valeurs numériques qui définissent la forme et l'étendue de la distribution. Tous les autres arguments (nom, troncation, corrélation, etc.) sont facultatifs. Ces arguments facultatifs se définissent à l'aide des fonctions de propriété, dans la fenêtre contextuelle Propriétés d'entrée.
Fenêtre Définir une distribution et fonctions réalisantes dans Excel
Toutes les entrées définies dans la fenêtre Définir une distribution se transforment en fonctions de distribution insérées dans la feuille de calcul. Ainsi, la fonction de distribution créée par les entrées de la fenêtre illustrée ici serait la suivante :
= RiskNormal (3 0 0 0; 1 0 0 0; RiskTruncate (1 0 0 0; 5 0 0 0))
Tous les arguments de distribution affectés à travers la fenêtre Définir une distribution peuvent aussi être définis directement dans la distribution même. À l'image des fonctions Excel ordinaires, tous les arguments peuvent aussi être définis sous forme de références de cellule ou de formules.
Il est souvent utile de recourir, dans une première fois, à la fenêtre Définir une distribution pour la définition des fonctions. Elle permet en effet de comprendre comment affecter les valeurs appropriées aux arguments. Lorsque vous maîtriserez la syntaxe de ces arguments, vous pourrez les définir directement dans Excel, sans passer par la fenêtre de définition.
Corrélation des variables en entrée
Lors d'une analyse de simulation, il importe de tenir compte de la corrélation entre les variables en entrée. Il y a corrélation lorsque l'échantillonnage d'une distribution en entrée est lié à celui d'une ou de plusieurs autres (par exemple, lorsque l'échantillonnage d'une distribution en entrée renvoie une valeur relativement élevée, il est possible que l'échantillonnage d'une seconde entrée doive aussi renvoyer une valeur relativement élevée). Pour illustrer cet exemple, prenons le cas d'une entrée intitulée « Taux d'intérêt » et d'une autre appelée « Développement du logement ». Il peut exister une distribution pour chaque de ces variables en entrée, mais leur échantillonnage doit être lié pour éviter des résultats qui n'auraient aucun sens. Ainsi, lorsque la variable Taux d'intérêt est élevée, l'échantillonnage de la variable Développement du logement doit produire une valeur relativement faible. Réciproquement, lorsque les taux d'intérêt sont bas, le développement du logement sera relativement élevé.
Matrice décorrélation
Pour ajouter une corrélation, il suffit de sélectionner les cellules Excel qui contiennent les distributions en entrée à corréler, puis de cliquer sur l'icône Définir les corrélations. Il est également possible d'ajouter les entrées à une matrice affichée en cliquant sur Ajouter des entrées et en sélectionnant les cellules Excel désirées.
Lorsqu'une matrice est affichée, vous pouvez entrer les coefficients de corrélation entre les entrées dans les cellules de la matrice, copier les valeurs d'une matrice Excel ou faire appel aux diagrammes de dispersion pour évaluer et saisir les correlations.
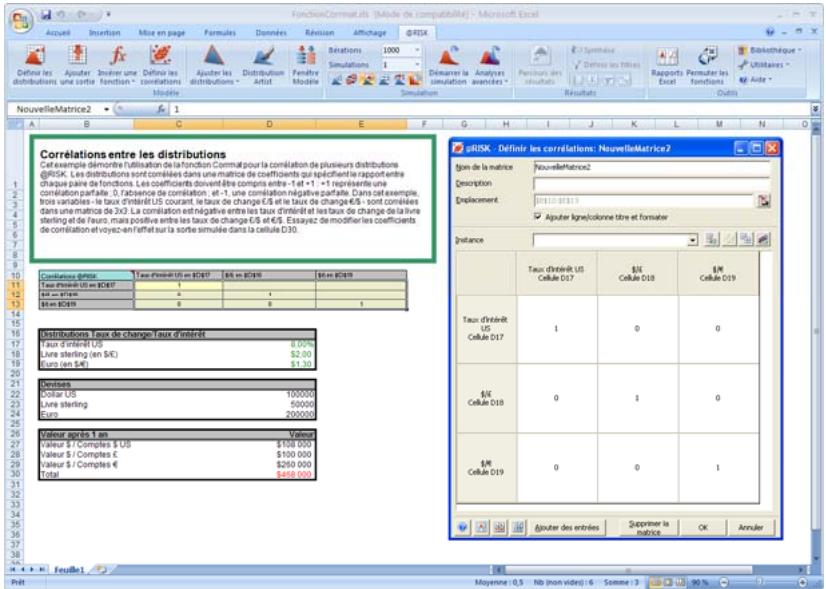
Diagrammes de dispersion et corrélations
L'icône Diagrammes de dispersion, dans le coin inférieur gauche de la fenêtre Définir les correlations, ouvre une matrice de diagrammes de dispersion. Les diagrammes, dans les cellules de la matrice, indiquent la correlation entre les deux distributions correspondantes. Le curseur de correlation proposé sous la matrice change dynamiquement le coefficient de correlation et le diagramme de dispersion de la paire d'entrées sélectionnée.
En glissant-déplaçant une cellule de diagramme de dispersion hors de la matrice, vous pouvez étendre la vignette du diagramme à une fenêtre graphique plein format. Cette fenêtre s'actualise aussi dynamiquement selon le mouvement du curseur de corrélation.
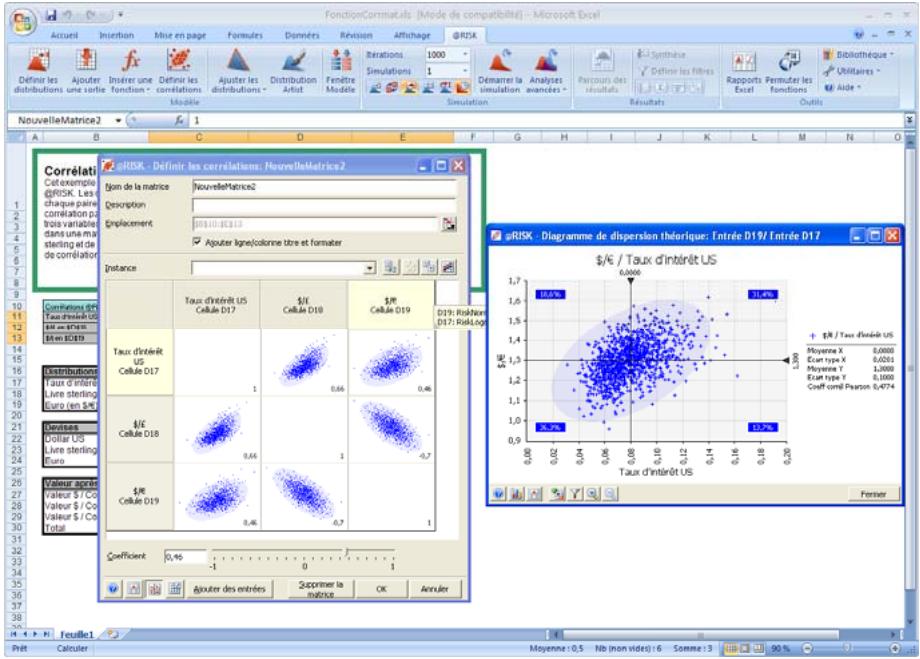
Avec la fenêtre Définir une distribution, les matrices de corrélation qui y sont définies changent les fonctions @RISK dans le modèle de calcul. Les fonctions RiskCormat ajoutées contiennent toutes les informations de corrélation définies dans la matrice. Lorsque la syntaxe des fonctions RiskCormat vous sera familière, vous pourrez les formuler vous-même, directement dans le tableau, sans passer par la fenêtre Définir les corrélations.
Ajustement de distributions aux données
@RISK (versions Professional et Industrial uniquement) permet aussi l'ajustement de distributions de probabilités à vos données existantes. L'ajustement est utile en présence de données existantes dont on peut faire la base d'une distribution en entrée. Il se peut, par exemple, que vous disposiez de données historiques relatives au prix d'un produit et que vous désiriez créer une distribution des prix à partir de ces données.
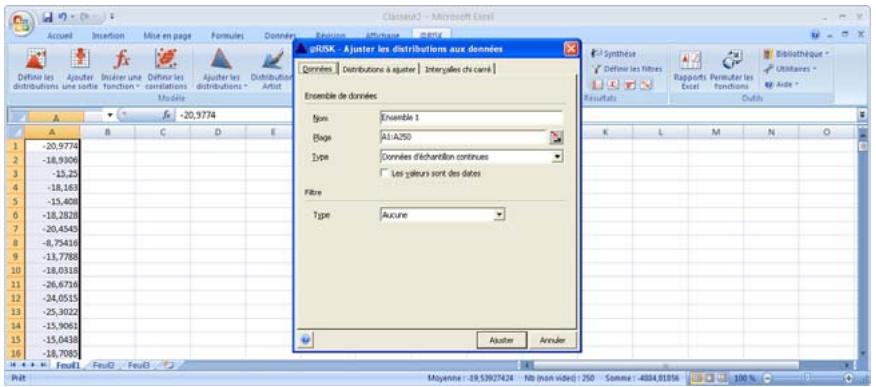
Options d'ajustement
Différentes options permettent de : gérer le processus d'ajustement. Des distributions spécifiques peuvent être sélectionnées. Les données en entrée peuvent se présenter sous forme de données d'échantillon, de densité ou cumulatives. Elles peuvent aussi être filtrées avant l'ajustement.
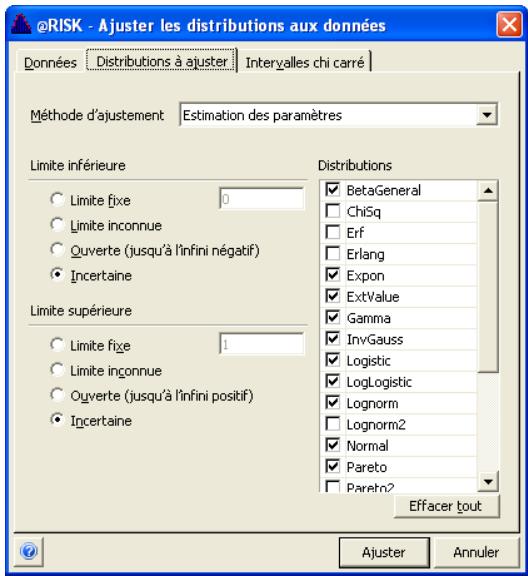
Rapports d'ajustement
Des tracés comparatifs, de double probabilité P-P ou double quantile Q-Q, sont proposés pour l'examen des résultats de l'ajustement. Les délimiteurs prévus sur les graphiques permettent de calculer rapidement les probabilités associées aux valeurs des distributions ajustées.
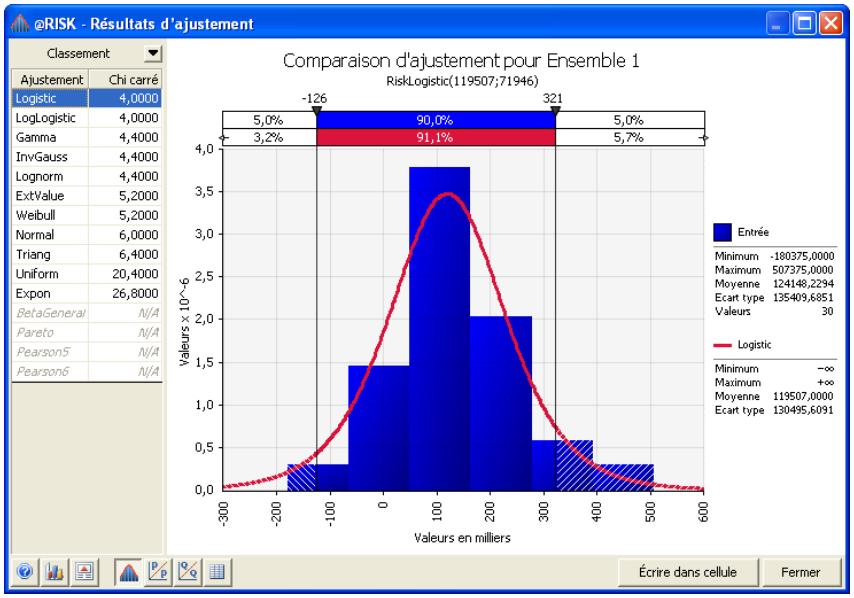
Placement d'un résultat d'ajustement dans excel
Cellule place le résultat d'un ajustement dans le modèle sous forme de nouvelle fonction de distribution. Sous l'option Actualiser et REAJUSTER au début de chaque simulation, @RISK reajuste automatiquement la distribution aux données modifiées et place la nouvelle fonction de distribution resultante dans le modèle au début de chaque simulation.
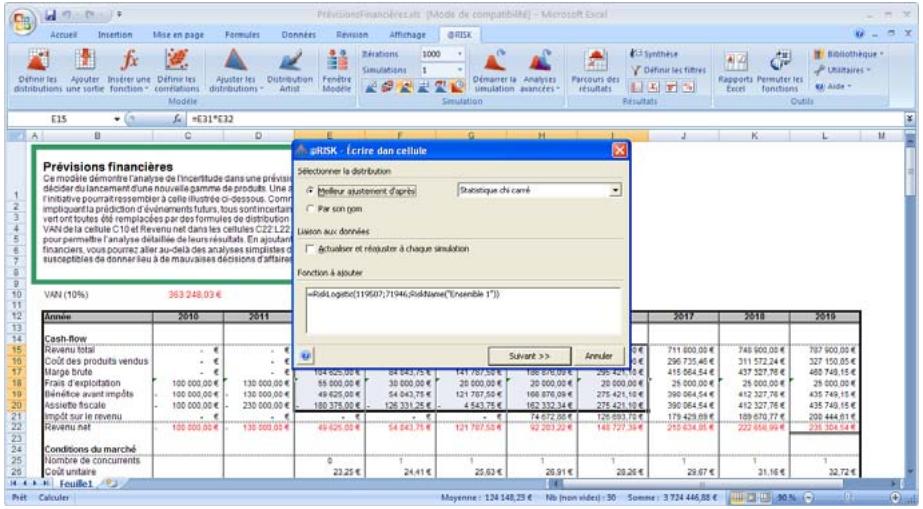
Gestionnaire d'ajustement
Le gestionnaire d'ajustement vous permet de naviguer entre les jours de données soumis à l'ajustement dans le classeur et de supprimer les ajustements déjà exécutés précédemment.
Fenêtre @RISK modèle
Pour vous aider à évaluer votre modèle, @RISK détecte toutes les fonctions de distribution, sorties et corrélations définies dans la feuille de calcul et les répertorie dans la fenêtre @RISK Modèle. La fenêtre @RISK Modèle s'ouvre par-dessus Excel et permet les opérations suivantes :
- Modification d'une distribution en entrée ou d'une sortie en tapant simplement dans le tableau.
- Expansion d'une vignette graphique au format fenêtre complète par glissement-déplacement.
- Représentation rapide de vignettes graphiques de toutes les entrées définies.
- Accès, par double-clic sur une entrée quelconque du tableau, au navigateur graphique pour parcours des cellules du classeur porteuses de distributions en entrée.
- Modification et affichage des matrices de corrélation.
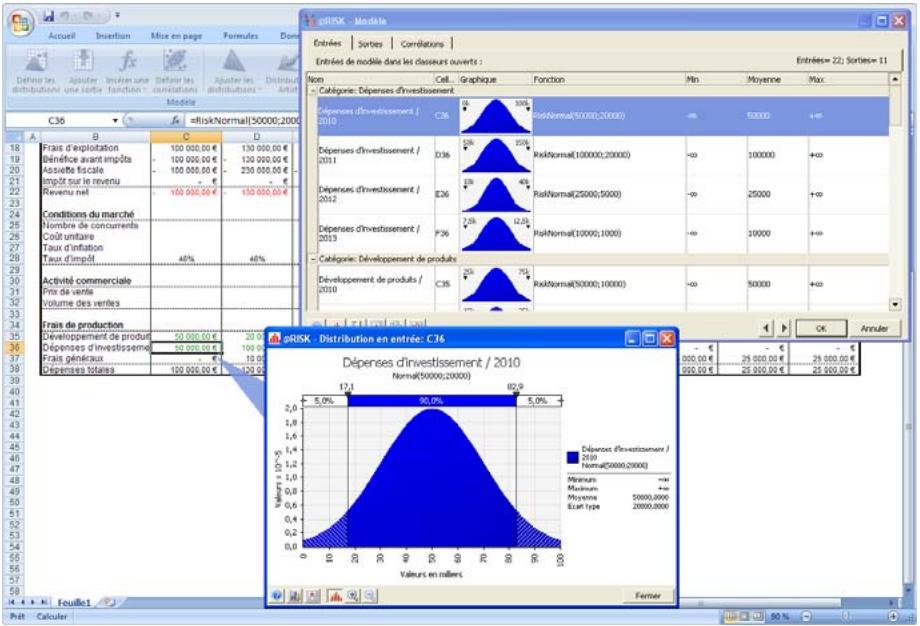
Personnalisation des statistiques affichées
Les colonnes de la fenêtre Modèle peuvent être personnalisées en fonction des statistiques à afficher sur les distributions en entrée du modèle. L'icône Colonnes, au bas de la fenêtre, ouvre la boîte de dialogue Colonnes du tableau.
Catégorisation des entrées
Les entrées de la fenêtre Modèle peuvent être groupées par catégorie. Par défaut, une catégorie se crée quand un groupe d'entrées partage un même nom de ligne (ou colonne). Vous pouvez aussi placer les entrées dans la catégorie de votre choix.
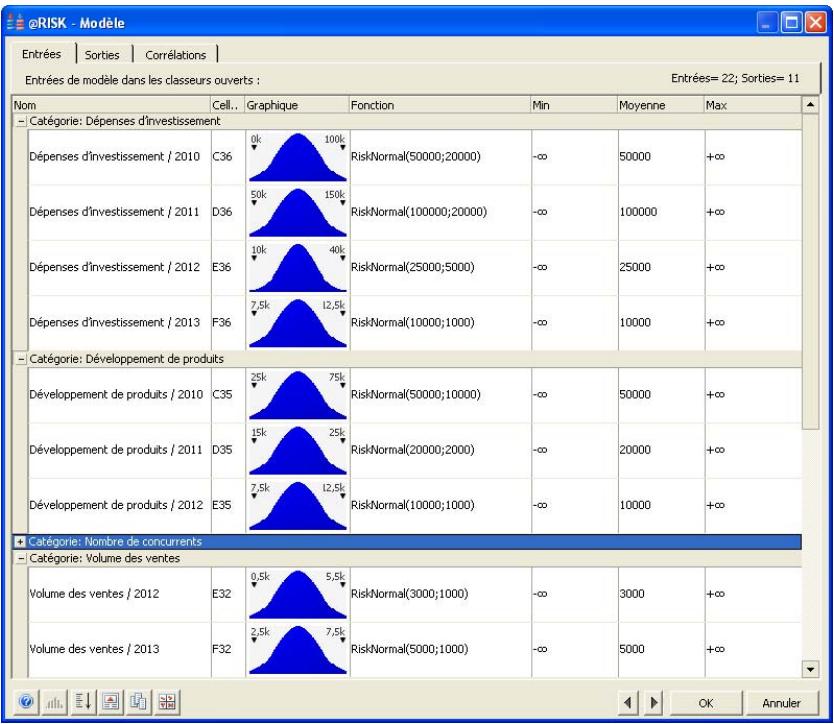
Paramètres de simulation
Divers paramètres gèrent le type de simulation executé par @RISK. La simulation @RISK admet des iterations illimitées et des simulations multiples. Les simulations multiples permettent la réalisation de simulations successives sur un même modèle. Vous pouvez, à chacune, changer les valeurs définies dans le tableau de manière à comparer les résultats des simulations sous différentes hypothèses.
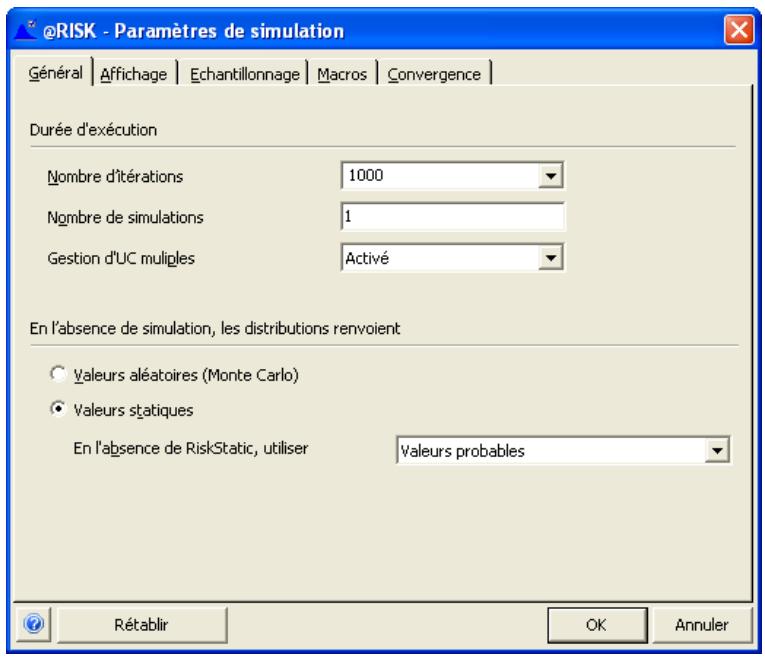
Une barre de paramètres @RISK s'ajoute à la barre de menus Excel, pour accélérer l'accès à de nombreux paramètres de simulation.
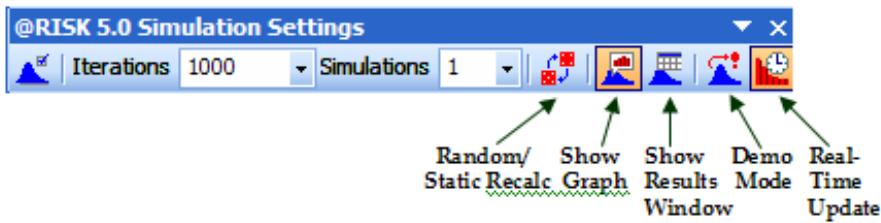
Cette barre propose les icônes suivantes :
- Paramètres de simulation ouvre la boîte de dialogue du même nom.
- La liste déroulante Itérations permet de changer rapidement, depuis la barre d'outils, le nombre d'iterations à exécuter.
- La liste déroulante Simulations permet de changer rapidement, depuis la barre d'outils, le nombre de simulations à executer.
- Aléatoire/Statique fait basculer @RISK entre le renvoi de valeurs probables ou statiques des distributions et celui d'échantillons Monte Carlo lors d'un recalcul Excel standard.
- Graphique, Résultats et Démo régissant ce qui s'affiche à l'écran pendant et après une simulation.
- Actualisation en temps réel détermine si les fenêtres ouvertes s'actualisent pendant l'exécution d'une simulation.
Exécution d'une simulation
La simulation dans @RISK consiste à exécuter des recalculs répétés d'une feuille de calcul. Chaque recalcul est appelé « iteration ». À chaque iteration :
toutes les fonctions de distribution sont échantillonnées, les valeurs échantillonnées sont renvoyées aux cellules et formules de la feuille de calcul, la feuille de calcul est recalculée, les valeurs calculées pour les cellules de sortie sont recueillies dans la feuille de calcul et stockées, les graphiques et rapports @RISK ouverts s'actualisent, si nécessaire.
Le processus peut impliquer des centaines, ou même des milliers d'itérations.
Cliquez sur l'icône Démarrer la simulation pour lancer une simulation. Pendant la simulation, vous verrez Excel recalculer la feuille, encore et encore, sur différents échantillons des fonctions de distribution. Vous pourrez aussi suivre la convergence de vos distributions de sortie, avec actualisation en temps réel des représentations graphiques des résultats.

Une fenêtre de progression s'affiche pendant les simulations. Ses icônes permettent d'exécuter, interrompre momentanément ou abandonner une simulation, ainsi que d'activer ou désactiver l'actualisation en temps réel des graphiques et les recalculs Excel.
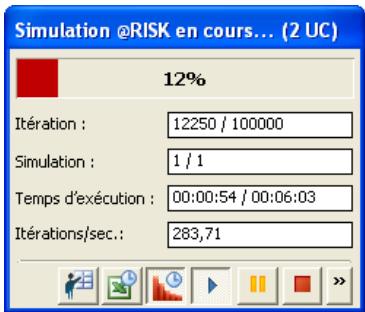
Actualisation graphique en cours de simulation
@RISK affiche graphiquement la variation des distributions des issues possibles en cours de simulation. Les fenêtres graphiques s'actualisent selon les distributions d'issues calculées et leurs statistiques. Si vous lancez une nouvelle simulation, @RISK affiche automatiquement un graphique de la distribution correspondant à la première cellule de sortie de votre modèle.
Ce graphique de la distribution des issues possibles se crée sur la base de toutes les valeurs de sortie obtenues : elles sont analysées et leur distribution statistique est calculée sur leur plage minimum-maximum.
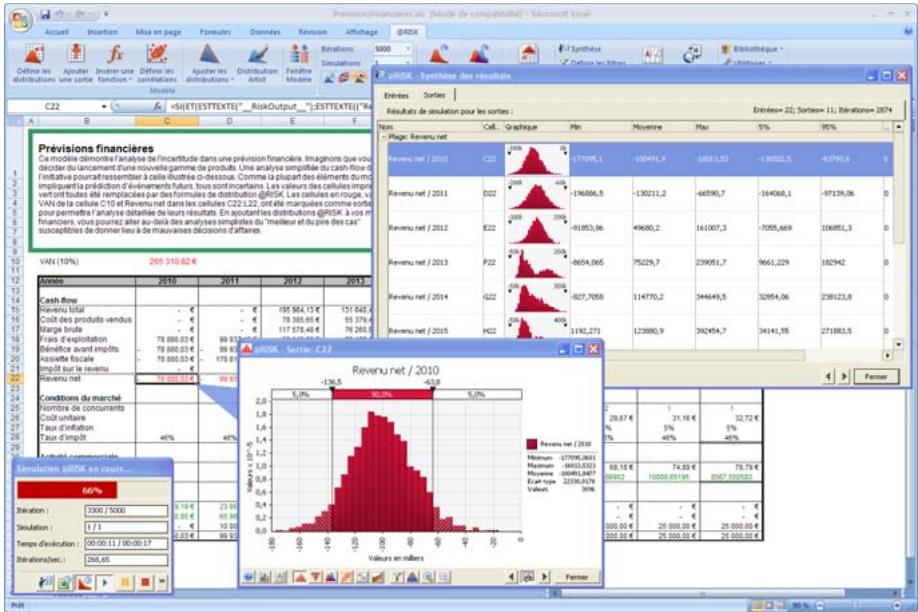
Surveillance de convergence
@RISK est doté d'une capacité de surveillance de convergence utile au contrôle de la stabilité des distributions de sortie en cours de simulation. Les distributions de sortie se « stabilisent » avec le nombre d'iterations exécutées : les statistiques décrivent en effet une variation moindre de chaque distribution à chaque nouvelle iteration. Il importe d'exécuter suffisamment d'iterations pour assurer la fiabilité des statistiques générées sur les sorties. Il arrive toutefois un moment où le temps passé à la réalisation de chaque itération supplémentaire est essentiellement perdu, car les statistiques ne varient plus de façon significative.
Les paramètres de l'onglet Convergence déterminent le mode de surveillance de convergence des sorties en cours de simulation. La fonction de propriété RiskConvergence permet de : gérer le test de convergence de sortie individuelle, et la boîte de dialogue Paramètres de simulation en permet la configuration générale pour toutes les sorties.
@RISK contrôle un ensemble de statistiques de convergence sur chaque distribution de sortie en cours de simulation. En mode de surveillance, @RISK calcule ces statistiques pour chaque sortie à intervalles sélectionnés (toutes les 100 iterations, par exemple) pendant toute la simulation.
Plus le nombre d'iterations exécutées augmente, plus la variation des statistiques diminue jusqu'à atteindre la « convergence » et le « niveau de confiance » que vous avez définis.
Au besoin, @RISK peut tourner en mode d'arrêt automatique. Dans ce cas, @RISK continue à exécuter les itérations jusqu'à la convergence de toutes les sorties. Le nombre d'itérations nécessaires dépend du modèle simulé et des fonctions de distribution inclues dans le modèle. Les modèles complexes à distributions fort asymétriques nécessitant un plus grand nombre d'itérations que les modèles plus simples.
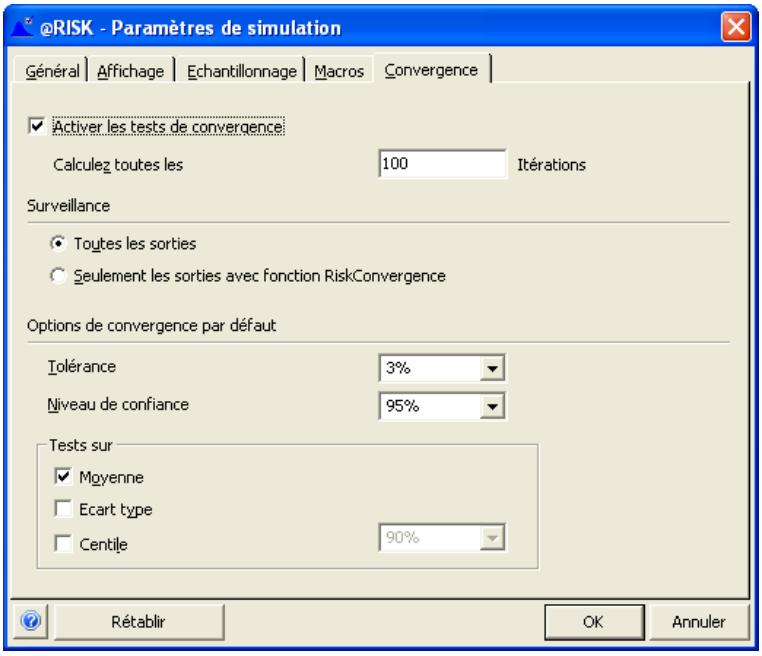
Mode parcours
Pour accéder au mode Parcours, cliquez sur l'icône Parcours des résultats de la barre d'outils @RISK. Le mode Parcours s'active automatiquement en fin de simulation si vous sélectionnez l'affichage d'un graphique en cours d'exécution.
En mode Parcours, @RISK affiche les graphiques de résultats en réponse à vos clics sur les cellules du tableau :
- Si la cellule sélectionnée est une sortie de simulation (ou contient une fonction de distribution simulée), @RISK affiche la distribution simulée dans une fenêtre légende pointant sur la cellule.
- Si la cellule sélectionnée fait partie d'une matrice de corrélation, une matrice des corrélations simulées entre les entrées de la matrice s'ouvre.
Chaque clic sur une cellule du classeur fait apparaître le graphique de résultats correspondant. Pour déplacer la fenêtre Graphique d'une cellule de sortie porteuse de résultats de simulation à l'autre dans les classeurs ouverts, appuyez sur la touche.
Pour quitter le mode Parcours, il suffit de fermer le graphique ou de cliquer sur l'icône Parcours des résultats, sur la barre d'outils.
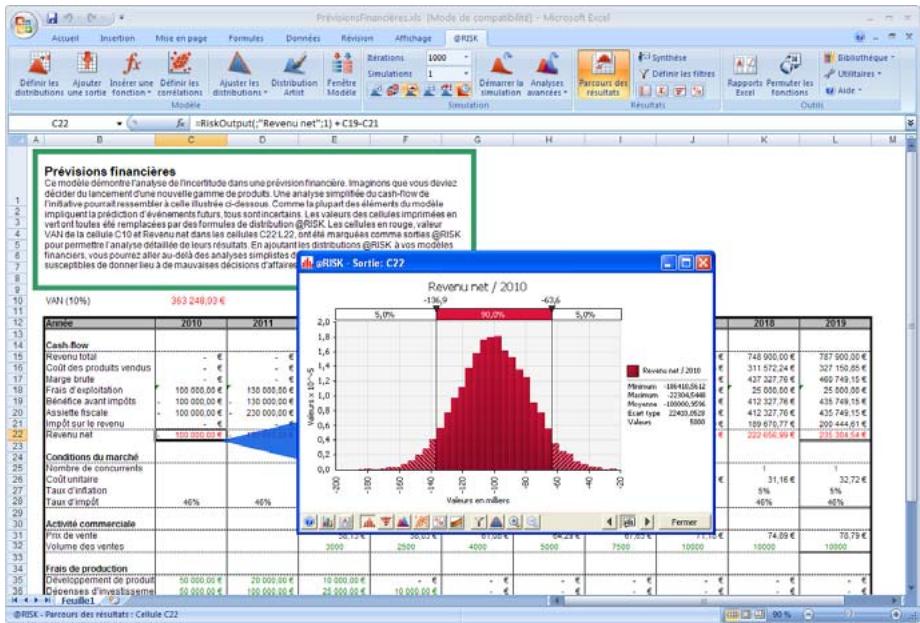
Fenêtre @RISK synthèse des résultats
la fenêtre @RISK - Synthèse des résultats affiche la synthèse des résultats du modèle ainsi que des vignettes graphiques et statistiques de synthèse des cellules de sortie simulées et des distributions en entrée. Les colonnes du tableau présentées dans cette fenêtre sont personnalisables en fonction des statistiques que vous désirez afficher.
La fenêtre de synthèse des résultats permet les opérations suivantes :
- Expansion d'une vignette graphique au format fenêtre complète par glissement-déplacement.
- Accès, par double-clic sur une entrée quelconque du tableau, au navigateur graphique pour parcours des cellules du classeur porteuses de distributions en entrée.
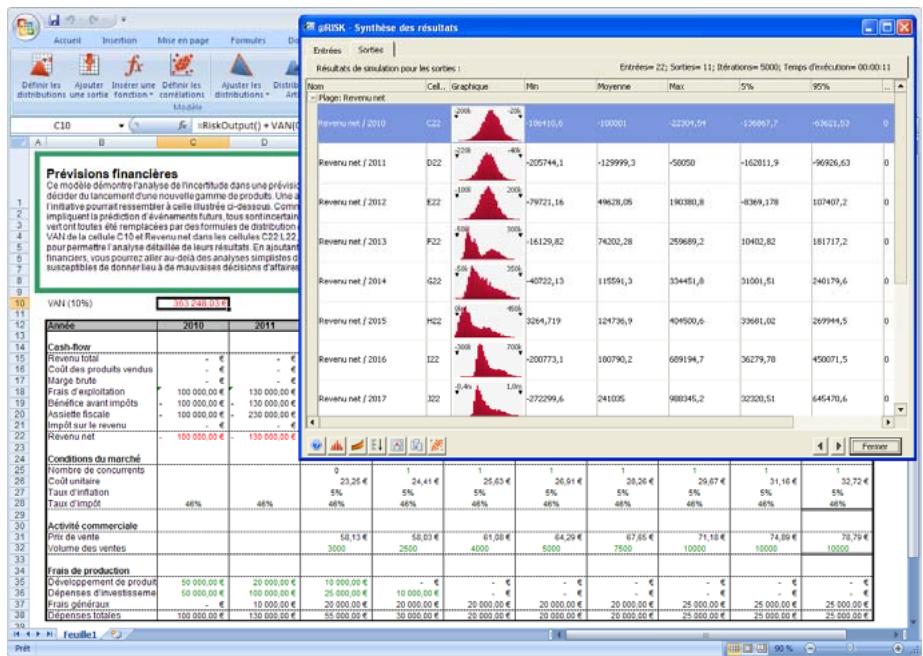
Fenêtre statistiques détaillées
Des statistiques détaillées sont disponibles sur les sorties et entrées simulées et des valeurs cibles peuvent être entrées pour une ou plusieurs entrées et sorties.
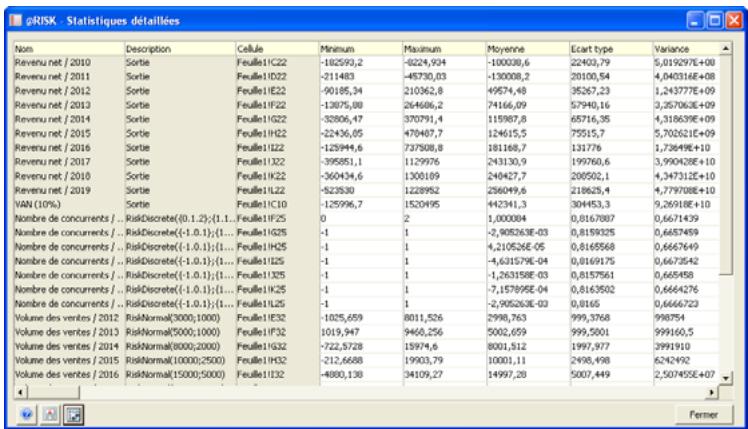
Cibles
Vous pouvez calculer des valeurs cibles sur les résultats de la simulation. Une cible indique la probabilité d'obtenir un résultat spécifique ou la valeur associée à un niveau de probabilité. Grâce aux cibles, il est possible de répondre à des questions du genre : « Quelle est la probabilité d'obtenir un résultat supérieur à un million ? » ou « Quel est le risque d'aboutir à un résultat négatif ? » Les cibles se définissent dans la fenêtre Statistiques détaillées, dans la fenêtre @RISK - Synthèse des résultats ou, directement, à l'aide des délimiteurs des graphiques de résultats de simulation.
En entrant une cible désirée (1%, par exemple) pour une sortie dans la fenêtre @RISK - Synthèse des résultats et en la recopiant pour toutes les sorties, vous pouvez obtenir rapidement le calcul d'une même cible sur tous les résultats d'une simulation.
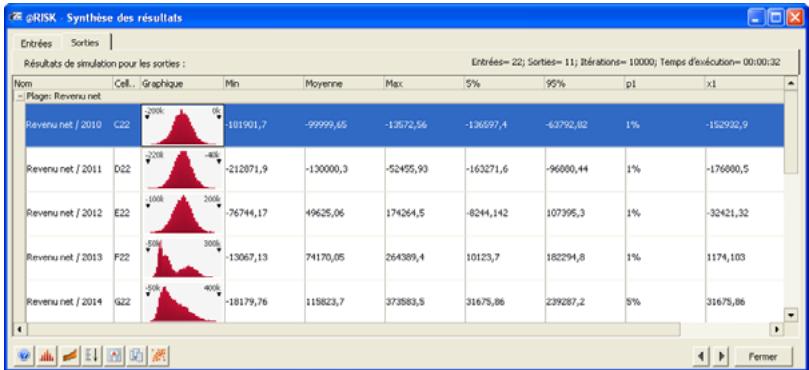
Réprésentation graphique des résultats
Les résultats d'une simulation s'experimentaisent sous forme graphique. La fenêtre Synthèse des résultats affiche notamment des vignettes graphiques des résultats de simulation de toutes les sorties et entrées. Il suffit de glisser-déplacer une vignette hors de la fenêtre de synthèse pour l'afficher dans une plus grande fenêtre.
Un graphique des résultats d'une sortie indique la plage des issues possibles et leur probabilité relative. Ce type de graphique peut être représenté sous forme d'histogramme standard ou de distribution de fréquence. Les distributions d'issues possibles peuvent aussi être affichées sous forme cumulative.
Résultats de simulation sous forme d'histogramme et de courbe cumulative
Chaque graphique @RISK s'accompagne des statistiques relatives à la sortie ou à l'entrée représentée. Les icônes, au bas de la fenêtre Graphique, permettent de changer le type de graphique affiché. Un clic droit dans une fenêtre de graphique affiche par ailleurs un menu contextuel des commandes de format, échelle, couleur, titres et statistiques affichées. Chaque graphique peut être copié dans le Presse-papiers puis collé dans le tableau. comme le transfert se fait par métafichiers Windows, les graphiques peuvent être redimensionnés et annotés dans le tableau.
La commande Graphique Excel permet de tracer les graphiques au format graphique naturel d'Excel. À l'image des autres graphiques Excel, ils sont modifiables et personnalisables à loisir.
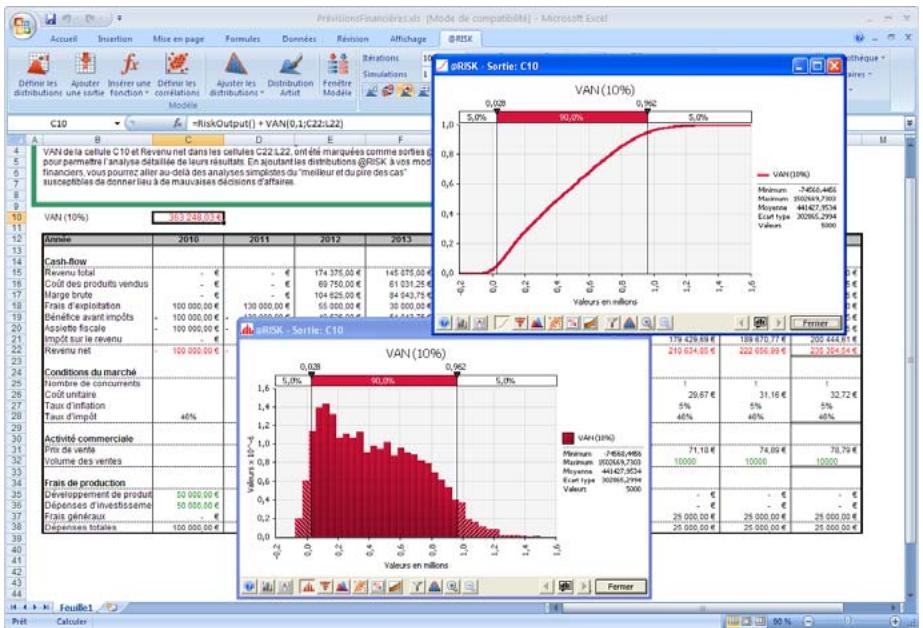
Superposition de graphiques à comparer
La comparaison graphique de distributions simulées est souvent utile. Il suffit, pour ce faire, de superposer les graphiques.
La superposition s'effectue en cliquant sur l'icône Superposer au bas d'une fenêtre graphique, en glissant-déplaçant un graphique par-dessus un autre ou en glissant-déplaçant une vignette graphique de la fenêtre Synthèse des résultats par-dessus un graphique ouvert. Cela fait, les statistiques des délimiteurs représentent les probabilités relatives à toutes les distributions inclues dans les graphiques superposés.
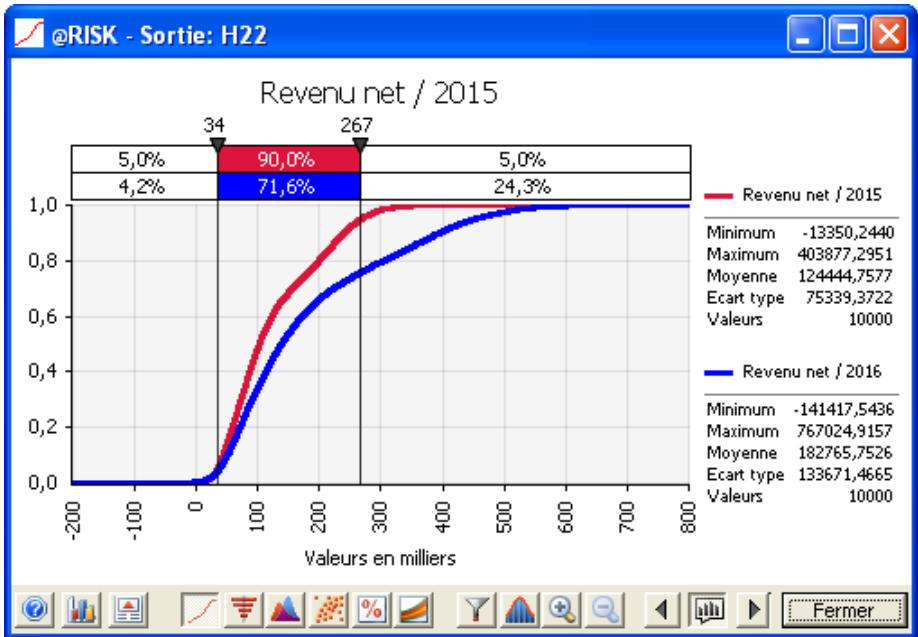
Délimiteurs
Faites glisser les délimiteurs d'un historiagramme ou d'un graphique cumulatif pour calculer différentes probabilités cibles. Les probabilités calculées s'affichent dans la barre des délimiteurs, au-dessus du graphique. L'approche permet de représenter graphiquement les réponses aux questions du type : « Quelle est la probabilité d'obtenir un résultat compris entre 1 et 2 millions ? » ou « Quelle est la mesure du risque d'un résultat négatif ? »
Les délimiteurs peuvent être affichés pour un nombre quelconque de superpositions. Le nombre de barres de délimiteurs affichées se définit dans la boîte de dialogue Options graphiques.
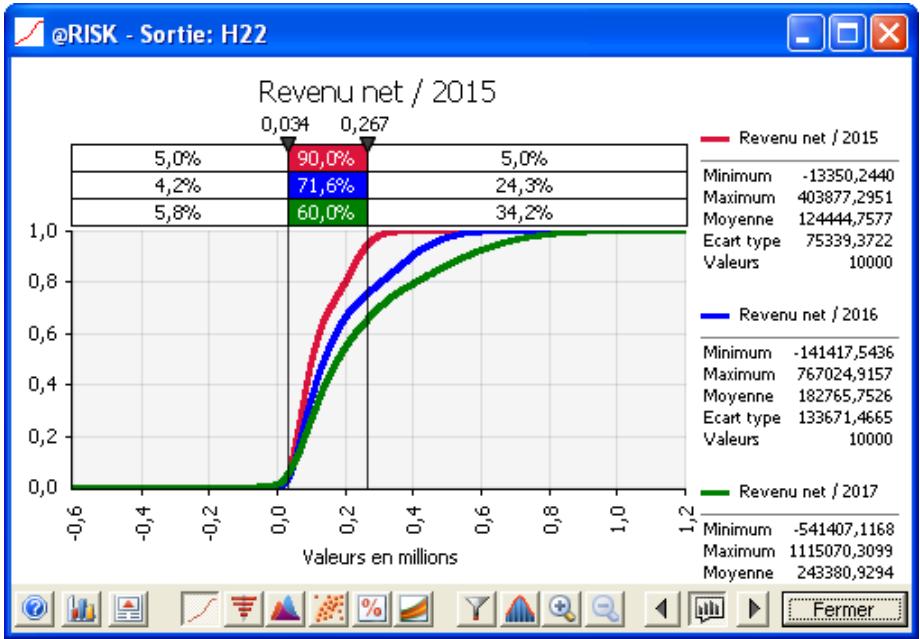
Formatage des graphiques
Chaque distribution incluse dans un graphique superposé peut être formatée indépendamment des autres. Les options de l'onglet Courbes, dans la boîte de dialogue Options graphiques, configurent les paramètres de couleur, style et motif de chaque courbe superposée.
Graphiques de synthèse
Un graphique de synthèse affiche les variations du risque sur une plage de cellules de sortie ou d'entrée. Vous pouvez utiliser un graphique de synthèse pour une plage de sortie ou sélectionner les entrées ou sorties individuelles à comparer dans un graphique de synthèse. Les graphiques de synthèse peuvent rester deux formes : Tendance ou Boîte de synthèse. Pour l'un ou l'autre de ces graphiques :
- Cliquez sur l'icone Graphique de synthèse au bas d'une fenêtre graphique et sélectionnez la ou les cellules Excel dont les résultats doivent être inclus dans le diagramme.
- Dans la fenêtre @RISK - Synthèse des résultats, sélectionnez les lignes des sorties, ou entrées, à inclure dans le graphique de synthèse, puis cliquez sur l'icône Graphique de synthèse au bas de la fenêtre (ou cliquez droit dans le tableau) et sélectionnez Tendance ou Boîte de synthèse.
Le graphique Tendance est particulièrement utile à l'affichage des tendances telles que les variations du risque dans le temps. Si, par exemple, une plage de 10 cellules de sortie contient les bénéfices réalisables au cours des années 1 à 10 d'un projet, le graphique de tendance de cette plage indique les variations du risque encouru au cours de la décennie. Plus la bande est étroite, moins les bénéfices estimés sont sujets à l'incertitude. De même, plus la bande est large, plus la variance possible des bénéfices est élevée et plus le risque est grand.
La ligne centrale du graphique de tendance représente la tendance moyenne de la plage. Les deux bandes extérieures, au-dessus de la moyenne, représentent un écart type au-dessus de la moyenne et le 95e centile. Les deux bandes extérieures, au-dessous de la moyenne, représentent un écart type au-dessous de la moyenne et le 5e centile. Vous pouvez modifier la définition de ces bandes sur l'onglet Tendance de la boîte de dialogue Options graphiques.
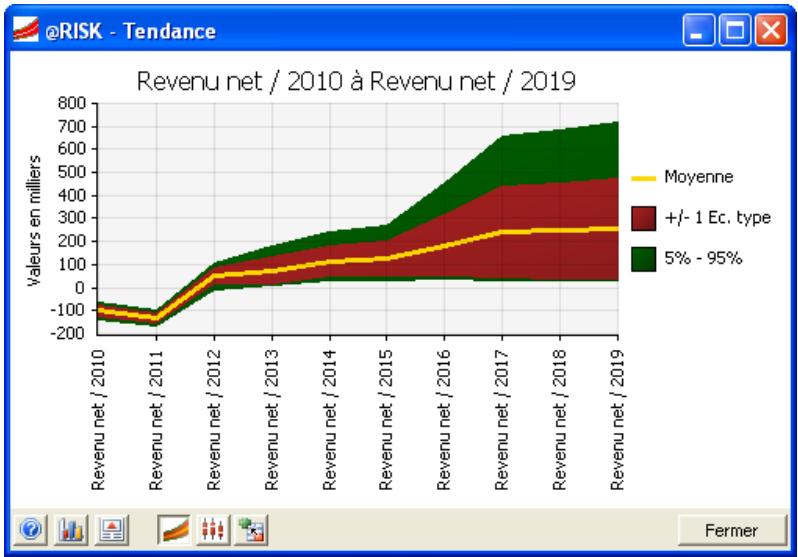
Boîte de synthèse
La forme graphique Boîte de synthèse présente un diagramme en boîte pour chaque distribution sélectionnée pour le graphique de tendance. Un graphique en boîte (ou « boîte à moustaches ») affiche une « boîte » représentant la plage interne définie d'une distribution et des « moustaches » représentatives des limites extérieures de la distribution. La ligne interne, dans la boîte, marque l'emplacement de la moyenne, médiane ou du mode de la distribution.
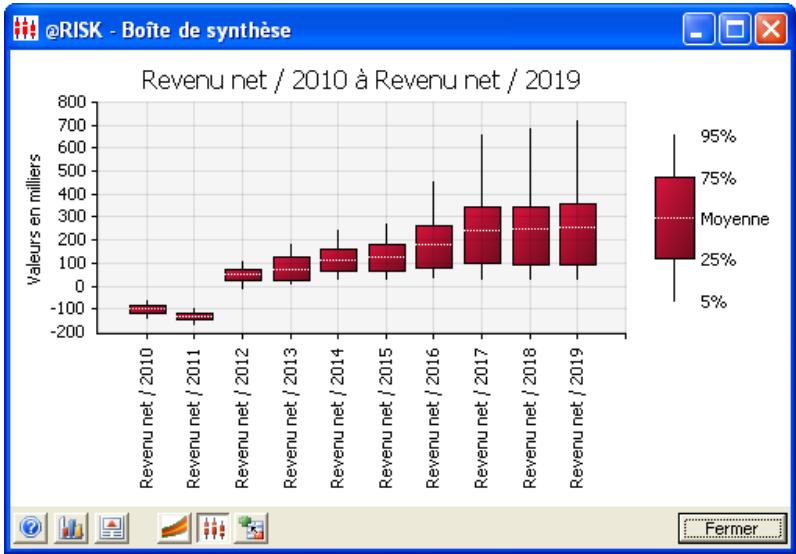
Un diagramme de dispersion est un graphique x-y qui présente la valeur en entrée échantillonnée par rapport à la valeur de sortie calculée à chaque iteration de la simulation. Ce graphique est utile à l'examen détaillé du rapport entre une entrée et une sortie de simulation. L'ellipse de confiance identifie la région où tombent, à un niveau de confiance donné, les valeurs x-y. Les diagrammes de dispersion peuvent aussi être normalisés de sorte que les valeurs de plusieurs entrées soient plus facilement comparables sur un même diagramme.
Pour créer un diagramme de dispersion :
- Cliquez sur l'icône Dispersion d'un graphique affiché et sélectionnez la ou les cellules Excel dont les résultats doivent être inclus dans le diagramme.
- Sélectionnez une ou plusieurs sorties ou entrées dans la fenêtre Synthèse des résultats et cliquez sur l'icône Diagramme de dispersion.
- Déplacez par glissement une barre (l'entrée à représenter dans le diagramme de dispersion) du graphique tornado d'une sortie.
- Affichez une matrice de diagrammes de dispersion dans la fenêtre du rapport d'analyse de sensibilité (voir Analyse de sensibilité vers la fin de cette section).
- Cliquez sur une matrice de corrélation en mode Parcours pour afficher une matrice de diagrammes de dispersion représentant les correlations simulées entre les entrées corréllées dans la matrice.
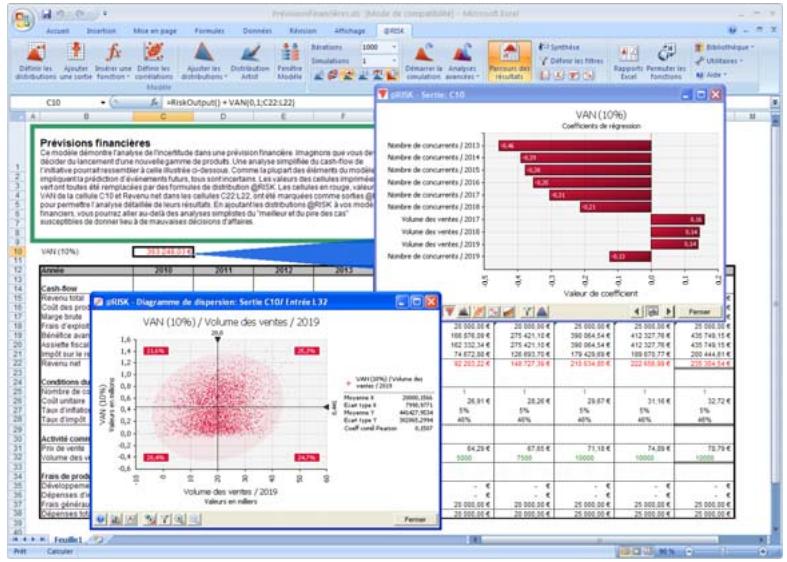
Résultats de l'analyse de sensibilité
L'icône Fenêtre de sensibilité commande l'affichage des résultats de l'analyse de sensibilité. Ces résultats révètent la sensibilité de chaque variable de sortie aux distributions en entrée de la feuille de calcul. Les entrées les plus « critiques » du modèle sont ainsi identifiées. Faites-y particulièrement attention lors de l'élaboration de plans reposant sur un modèle.
Les données affichées dans la fenêtre Sensibilité sont classées, pour la sortie sélectionnée, dans la zone « Classer les entrées pour la sortie : ». La sensibilité de toutes les autres sorties aux entrées répertoriées est également indiquée.
Les analyses de sensibilité effectuées sur les variables de sortie et les entrées qui leur sont associées font appel à la régression multidimensionnelle en escalier ou à la corrélation des rangs. Le type d'analyse désiré se définit dans la zone « Afficher les entrées significatives par : » de la fenêtre Sensibilité.
Dans l'analyse de régression, les coefficients calculés pour chaque variable en entrée mesurent la sensibilité de la sortie à la distribution en question. L'ajustement général de l'analyse de régression est mesuré par l'ajustement rapporté ou 2 du modèle. Le niveau d'ajustement est proportionnel à la stabilité des statistiques de sensibilité rapportées. Si l'ajustement est trop faible - au-dessous de 0,5 - une simulation identique du même modèle pourrait donner un classement différent des sensibilités en entrée.
L'analyse de sensibilité faisant appel aux corrélations des rangs repose sur le calcul des coefficients de corrélation des rangs de Spearman. Dans cette analyse, le coefficient de corrélation des rangs est calculé entre la variable de sortie sélectionnée et les échantillons de chaque distribution en entrée. Plus la corrélation entre l'entrée et la sortie est grande, plus l'entrée est significative dans la détermination de la valeur de sortie.
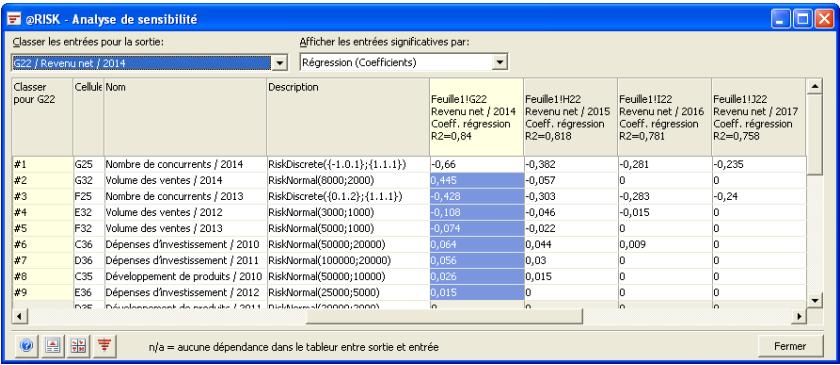
Analyse de sensibilité avec matrice de diagrammes de dispersion
Un diagramme de dispersion est un graphique x-y qui présente la valeur en entrée échantillonnée par rapport à la valeur de sortie calculée pour chaque iteration de la simulation. Dans la matrice des diagrammes de dispersion, les résultats classés de l'analyse de sensibilité sont affichés avec leurs diagrammes de dispersion. Pour afficher la matrice, cliquez sur l'icone Dispersion dans le coin inférieur gauche de la fenêtre Sensibilité.
En glissant-déplaçant une vignette de diagramme de dispersion hors de la matrice, vous pouvez l'étendre à une fenêtre graphique plein format. Il est également possible de superposer plusieurs diagrammes de dispersion par glissement-déplacement d'autres vignettes de la matrice sur un diagramme existant.
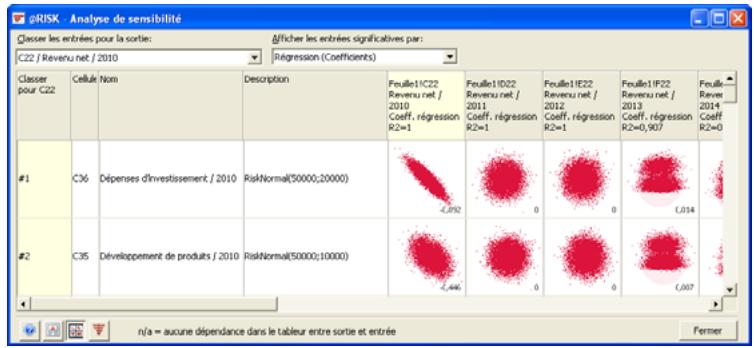
Graphique tornado
Les résultats de sensibilité s'affichent, graphiquement, dans des graphiques de type « tornado ». Pour produire un graphique tornado, il suffit de cliquer droit sur une sortie de la fenêtre Synthèse des résultats ou de désirer l'onglet Tornado d'une fenêtre graphique.
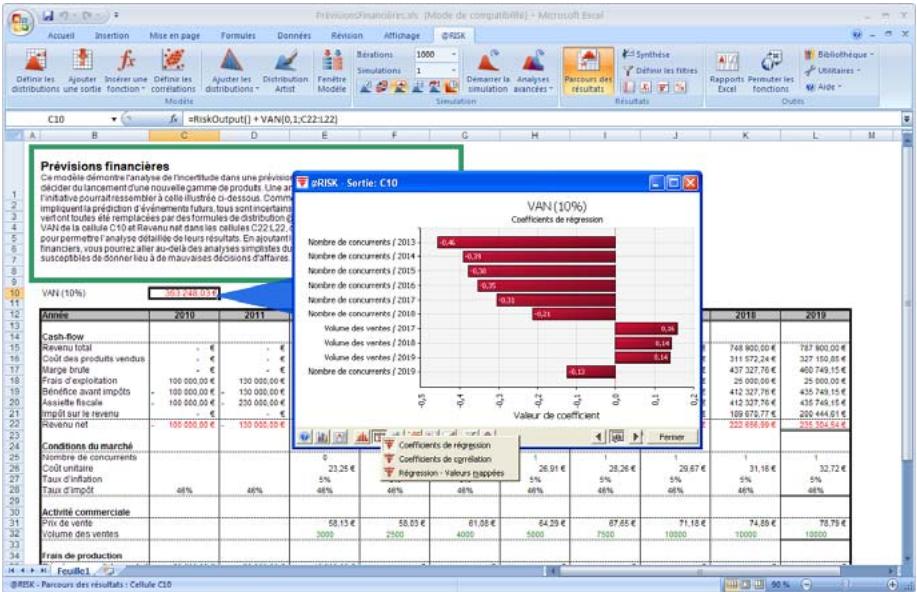
Résultats de l'analyse de scénario
L'icone Scénarios renvoie les résultats de l'analyse de scénario de vos variables de sortie. Trois cibles de scénario peuvent être entrées par variable de sortie.
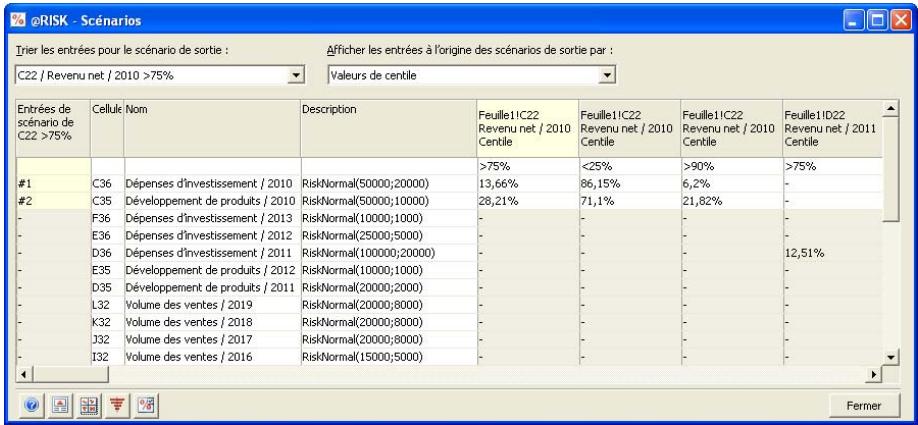
Comment s'exécute l'analyse de scenario ?
L'analyse de scénario effectuée sur les cibles de variable de sortie repose sur une analyse médiane conditionnelle. Lors de l'analyse, @RISK commence par créer un sous-ensemble limité aux itérations de la simulation dans lesquelles la variable de sortie atteint la cible entrée. @RISK analyse ensuite les valeurs échantillonnées pour chaque variable en entrée dans ces itérations. @RRISK identifie la médiane de ce « sous-ensemble » de valeurs échantillonnées pour chaque entrée et la compare à la médiane de l'entrée pour toutes les itérations.
Le processus vise à identifier les entrées dont le sous-ensemble, ou la mediane conditionnelle, diffère substantiellement de la mediane globale. Si la mediane du sous-ensemble est proche de la mediane globale, la variable en entrée est considérée insignifiante. Les valeurs échantillonnées dans les iterations où la cible est atteinte ne différent en effet pas nettement de celles échantillonnées pour l'entrée dans la simulation tout entière. Si toutefois la mediane du sous-ensemble de la variable en entrée présente un écart significatif par rapport à la mediane globale (la moitié d'un écart type au moins), la variable en entrée est significative. Les scénarios rapportés indiquent toutes les entrées contribuant de façon significative à la cible entrée.
Matrice de diagrammes de dispersion dans la fenêtre de scénarios
Un diagramme de dispersion, dans la fenêtre de scénarios, est un diagramme de dispersion x-y superposé. Ce graphique présente :
1) la valeur en entrée échantillonnée par rapport à la valeur de sortie calculée à chaque itération de la simulation, 2) superposée d'un graphique de dispersion de la valeur en entrée échantillonnée par rapport à la valeur de sortie calculée lorsque la valeur de sortie correspond au scénario entré.
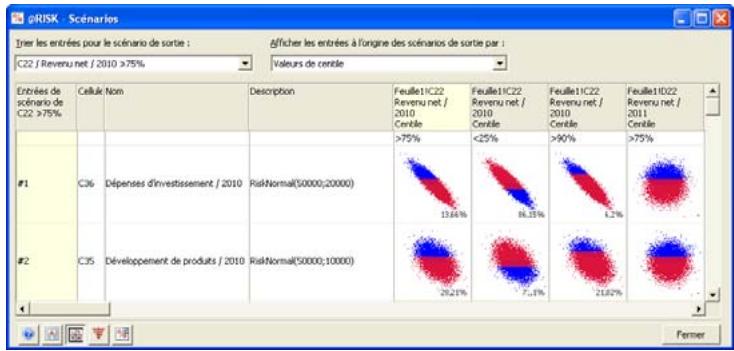
Dans la matrice des diagrammes de dispersion, les résultats classés de l'analyse de scénario sont affichés avec leurs diagrammes de dispersion. Pour afficher la matrice, cliquez sur l'icône Dispersion dans le coin inférieur gauche de la fenêtre Scenarios.
Les résultats d'analyse de scenario s'affichent, graphiquement, dans des graphiques de type « tornado ». Pour produire un graphique tornado, cliquez sur l'icone Tornado de la fenêtre Scenarios ou sur l'icone Scenarios d'une fenêtre graphique. Le graphique tornado illustré ici présente les entrées clés qui affectent la sortie lorsque celle-ci correspond au scenario entre - quand la sortie est supérieure au 90e centile, par exemple.
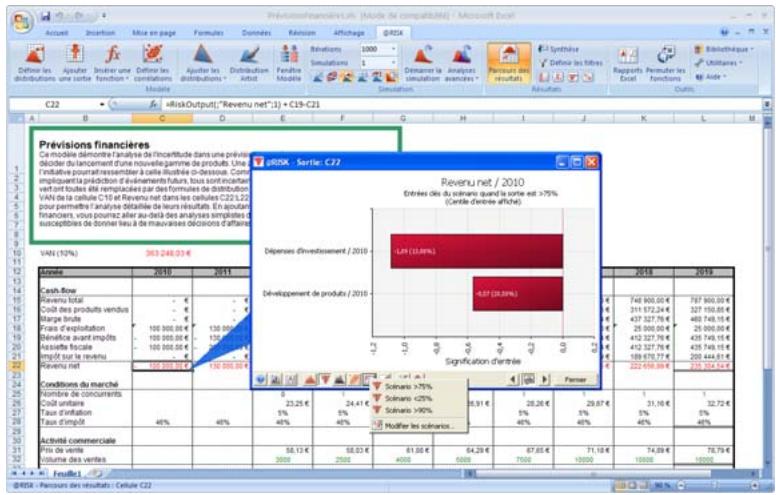
Graphique tornado de scénarios
Rapports excel
Les rapports et graphiques de simulation générés dans Excel donnent accès à toutes les options de formatage Excel. De plus, les rapports @RISK générés dans Excel peuvent se conformer aux masques @RISK personnalisés prédéfinis qui en régissent le formatage, les titres et les logos.
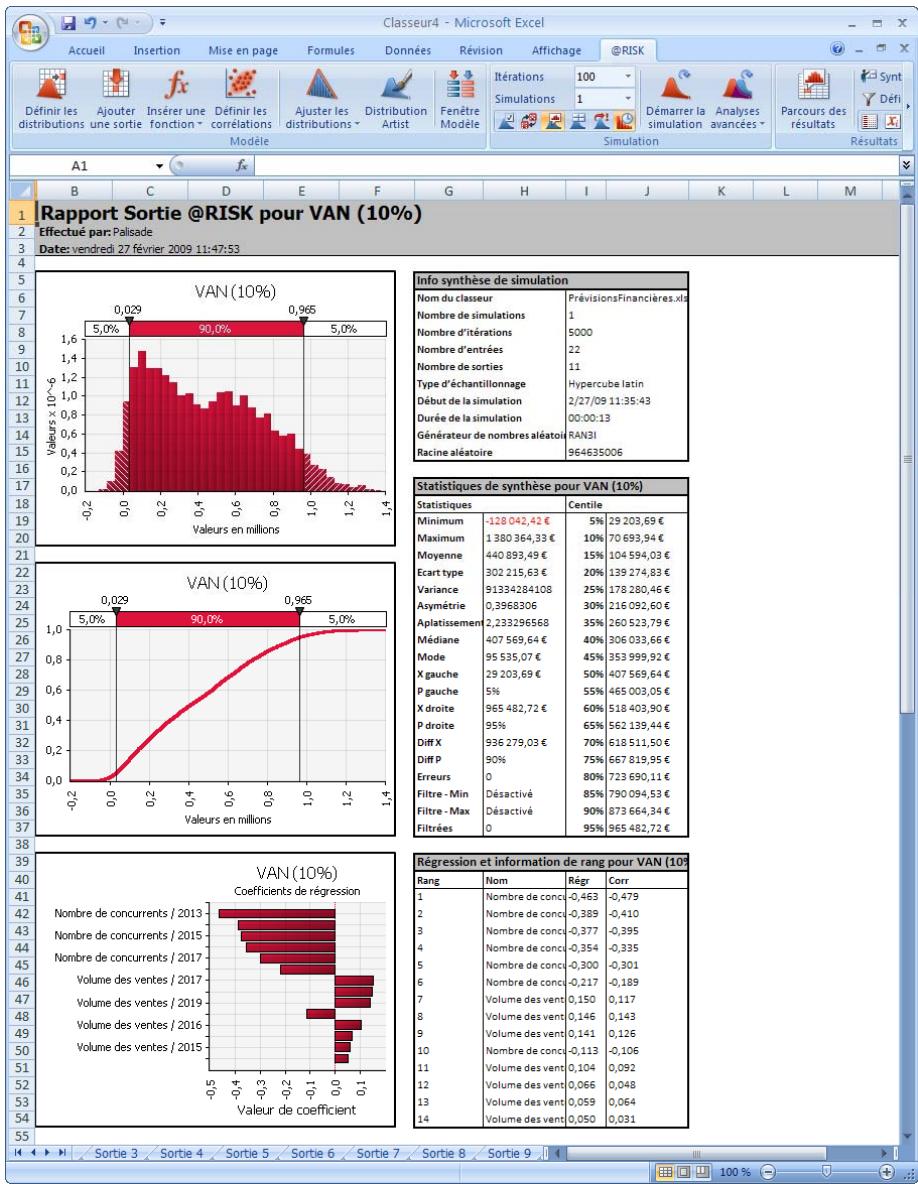
Vous pouvez vous servir des masques proposés pour créer vos propres rapports de simulation personnalisés. Les statistiques et graphiques de simulation s'introduisent dans un masque à l'aide de fonctions @RISK ajoutées à Excel. Lorsqu'une fonction statistique ou graphique est définie dans un masque, les statistiques et graphiques désirés s'insèrent, en fin de simulation, dans une copie du masque pour produire le rapport voulu. Le masque original porteur des fonctions @RISK reste intact, prêt à servir aux rapports de la simulation suivante.
Les masques sont définis au format de feuilles de calcul Excel ordinaires. Ils figurent, dans @RISK, dans la boîte de dialogue Paramètres des rapports. Leurs fichiers peuvent aussi contenir des formules Excel standard, pour permettre l'exécution de calculs personnalisés sur les résultats de simulation.
Chapitre 5 : techniques de modélisation @RISK
Modélisation de taux d'intérêts et autres tendances 147
Projection de valeurs connues dans l'avenir 149
Modélisation d'événements incertains ou « aléatoires » 151
Puits de pétrole et sinistres d'assurance 153
Introduction de l'incertitude autour d'une tendance fixe............155
Relations de dépendance 157
Simulation de sensibilité 159
Simulation d'un nouveau produit 161
Identification de la valeur à risques (VAR) d'un portefeuille....171
Simulation d'un tournoi de la NCAA 175
Le chapitre Techniques de modélisation @RISK vous apprendra comment convertir des situations à risque types en modèles @RISK. Ces situations se veulent le reflet de problèmes de modélisation réels souvent rencontrés par les utilisateurs d'Excel. Référez-vous aux exemples et illustrations fournis dans ce chapitre pour appliquer @RISK à l'analyse de vos propres feuilles de calcul Excel. Vous y trouverez sans doute des conseils ou techniques utiles à la représentation optimale de l'incertitude dans vos modèles @RISK.
Ce chapitre présente sept techniques @RISK illustrant des situations de modélisation courantes sujettes à l'incertitude. Pour vous aider à mieux comprendre les techniques de modélisation employées, des exemples de feuilles de calcul Excel et les simulations @RISK correspondantes sont fournis avec le système @RISK. Les simulations ont été « pré-exécutées » pour vous permettre d'examiner les résultats, sans plus. Lors de l'étude de chaque technique représentée, examinez la feuille de calcul et la simulation correspondantes : elles vous aident à comprendre les concepts et techniques @RISK qui intervennent dans la modélisation.
Les sept techniques de modélisation illustrées dans ce chapitre sont les suivantes :
Modélisation de taux d'intérêt et autres tendances - tendances aléatoires dans le temps et « trajets aléatoires » Projection de valeurs actuelles connues dans l'avenir — un avenir de plus en plus incertain ou « variabilité croissante » - Les inondations vont-elles se produire ou un concurrent va-t-il entrer sur le marché ? - modélisation d'événements « aléatoires » incertains. - Puits de pétrole et sinistres d'assurance - modélisation d'un nombre incertain d'événements, comptant chacun des paramètres incertains. - « Je dois utiliser cette projection mais elle ne m'inspire pas confiance » — ajout de l'incertitude autour d'une tendance fixe à l'aide des « termes d'erreur » - « Ces valeurs seront affectées par des événements se produisant ailleurs » - relations de dépendance utilisant des arguments variables et des corrélations. - Simulation de sensibilité — dans quelle mesure les modifications de modèle affectent les résultats de la simulation.
Outre les sept modèles annoncés plus haut, ce chapitre inclut trois exemples @RISK extraits de Financial Models Using Simulation and Optimization, de l'auteur Wayne Winston. Ces modèles illustrent l'application de @RISK aux tâches de modélisation ordinaires de l'entreprise. L'ouvrage complet présente 63 exemples d'application de @RISK et autres « compagnons » à un vaste éventail de problèmes financiers. Si l'achat de l'ouvrage intégral vous intéresse, prenez contact avec Palisade Corporation ou rendez-vous sur www.palisade.com.
Tous les modèles de tableau types discutés ici se trouvent dans le répertoire d'installation par défaut C:\PROGRAM FILES\PALISADE\RISK5\EXAMPLES.
Projection de tendances
Modèle type : TAUX.XLS
Qu'il s'agisse d'une hypothèque ou du coût d'un prêt à taux variable, les prévisions des taux d'intérêt sont sujettes à un haut degré d'incertitude. Les fluctuations des taux d'intérêt sont souvent considérées comme aléatoires : elles semblent augmenter et diminuer sans régularité d'année en année. Le mouvement peut être entièrement aléatoire ou constituer une fluctuation aléatoire autour d'une tendance sous-jacente connue. Dans un cas comme dans l'autre, la modélisation de la partie aléatoire d'une projection est une technique importante de l'analyse de risque.
La simulation rend compte du caractère aléatoire d'une tendance dans le temps - en essayant notamment, de façon répétée, une série de taux possibles différente à chaque iteration. Vous pouvez par exemple définir une tendance aléatoire pour anticiper le taux d'intérêt sur une décennie. À chaque iteration, une nouvelle valeur est sélectionnée au hasard pour le taux d'intérêt de chaque année et les résultats sont calculés. Ce faisant, la simulation inclut les effets de tous les taux d'intérêt à partir possibles dans les résultats, que de se limiter à la seule prévision la plus probable.
Avec @RISK, vous pouvez inclure facilement, et directement, une « tendance aléatoire » dans une feuille de calcul Excel. Mieux encore, avec les commandes de copie d'Excel, vous pouvez placer cette tendance aléatoire à tous les endroits désirés de la feuille de calcul.
La tendance aléatoire la plus simple est une distribution copiée dans le temps. La valeur sélectionnée au hasard dans une période est indépendante de celle sélectionnée dans les autres :
1) Entrez une fonction de distribution pour la première cellule de la tendance. 2) Copiez la distribution sur la plage de cellules.
Une nouvelle valeur sera ainsi échantillonnée à chaque période : une tendance entière aléatoire sans correlation dans le temps.
Tendances aléatoires simples
« Trajet aléatoire » avec corrélation d'une période à l'autre
Vous pensez peut-être que les taux à partir ne sont pas entièrement aléatoires. Le taux de l'année prochaine risque d'être influencé par celui de l'année en cours. En termes Excel, il existe une corrélation entre une cellule de la plage et la suivante. Il existe un moyen simple de modéliser cette situation :
1) Entrez une fonction de distribution pour la première cellule de la plage. 2) Entrez une fonction de distribution pour la deuxième cellule de la plage, en utilisant la valeur échantillonnée pour la première cellule comme l'un de ses arguments (sa moyenne ou valeur la plus probable, par exemple). 3) Copiez la formule de la deuxième cellule sur la plage. L'argument lié référencé dans la formule est une reference relative - la troisième cellule utilise la valeur de la comme argument de reference, de même pour la quatrième, la cinquième, etc.
Par example :
Une corrélation est ainsi établie entre chaque cellule de la plage et la suivante.
Raffinement de tendances aléatoires
Ces simples exemples illustrent la modélisation des processus aléatoires dans le temps. Avec l'expérience, vous pourrez inclure vos termes aléatoires dans les formules et imposer ainsi des limites au nombre de modifications, augmenter le nombre de modifications possibles avec le temps, ou spécifier d'autres extensions ou variations. N'oubliez pas que les taux d'intérêt ne représentent qu'une application des tendances aléatoires parmi d'autres, que vous pourrez certainement identifier dans vos feuilles de calcul Excel et les situations incertaines que vous modélisez.
Augmentation de l'incertitude dans le temps
Vous connaissez les valeurs actuelles des variables critiques de vos modèles, mais que dire des mêmes variables dans l'avenir ? Le temps produit souvent un impact considérable sur les estimations : plus une projection s'étend dans le temps, moins elle est certaine. Aussi le caractère risqué de résultats représentant une estimation optimale augmente-t-il avec le temps.
L'élargissement de la variation autour de la tendance des meilleures estimations illustre ce problème. @RISK permet de modéliser l'effet du temps sur une estimation par accroissement de la variabilité d'une valeur aléatoire dans le temps.
La plage des valeurs possibles d'une cellule de feuille de calcul est indiquée dans la fonction de distribution. Plus on avance dans le temps - sur une plage de cellules de la feuille de calcul -, plus les arguments de la fonction qui spécifient l'étendue des valeurs possibles peuvent augmenter. Par exemple :
A1: RiskLognorm(10;10)
A2: RiskLognorm(10;15)
A3: RiskLognorm(10;20)
A4: RiskLognorm(10;25)
L'écart type de la fonction de distribution LOGNORM régit la variation possible de la valeur. Dans cet exemple, l'écart type augmente à mesure de la progression le long de la plage de cellules.
L'augmentation de la variance possible des valeurs à mesure de l'extension d'une projection dans le temps est la méthode empirique qu'il convient de suivre. Vos résultats reflèteront ainsi plus précisément la plus grande incertitude associée à l'avoir lointain.
Les inondations vont-elles se produire ou un concurrent va-t-il entrer sur le marché ?
Modèle type : DISCRÈTE. XLS
L'incertitude se manifeste souvent sous la forme d'événements aléatoires susceptibles d'affecter vos résultats de façon significative. Vous allez trouver un filon de pétrole, ou vous n'en trouvrez pas. Un concurrent va percer sur le marché ou il n'y parviendra pas, mais s'il y parvenait... Il y a 25% de chances que la grêle anéantisse la récolte de cette année.
L'introduction de la possibilité de ces types d'événements dans un modèle est une technique importante de l'analyse de risque. Si l'on n'en tient pas compte, les issues imputables à ces événements ne seront pas incluses dans les résultats et les modèles seront incomplets. Les fonctions DISCRETE de @RISK et SI d'Excel facilitent la modélisation de ces événements.
Introduction de l'événement discret
La fonction DISCRETE permet d'inclure les probabilités d'événements aléatoires dans les modèles de feuille de calcul.
Cet exemple modélise les caractéristiques de « pile ou face » — l'événement aléatoire le plus simple. En l'occurrence, une issue de 0 représentée Pile et 1 représentée Face, et les deux ont les mêmes chances de se produire. Un exemple plus complexe illustre quatre scénarios possibles de dégâts résultant des inondations causées par les orages annuels :
Dans ce cas, les issues dotées des valeurs 0 à 3 représentent quatre niveaux d'inondation possibles s'échelonnant entre nul (0), modéré (1), moyen (2) et important (3). La probabilité de dégâts nuls est de 20%, celle de dégâts modérés, de 40%, de dégâts moyens, de 30%, et de dégâts importants, de 10%.
Introduction des effets d'événements aléatoires dans les feuilles de calcul
La fonction DISCRETE renvoie une valeur, à chaque itération, indiquant l'événement qui s'est produit. Le modèle de feuille de calcul doit reconnaître l'événement qui s'est produit et calculer les résultats appropriés. C'est là que la fonction SI d'Excel entre en jeu. Considérez l'exemple et les entrées de cellule Excel suivants :
La cellule C2 décrit un événement : l'entrée possible d'un concurrent sur un marché. Il a 50% de chances de percer. S'il réussit, votre niveau de vente sera de 65; sinon, il sera de 100.
Dans l'exemple ci-dessus, la fonction SI de la cellule D2 renverra une valeur de 100 si le résultat de la cellule C2 est 1 (le concurrent n'entre pas sur le marché) et de 65 si le résultat est 0 (il y entre). Vous pouvez appliquer ce simple exemple à tous vos modèles @RISK. À chaque itération d'une simulation, la fonction DISCRETE renvoie l'une des valeurs possibles. Les calculs de la feuille de calcul peuvent varier suivant la valeur renvoyée.
Attention!
Les utilisateurs habitués aux estimations uniques dans les feuilles de calcul recourent souvent à une distribution discrète là où une distribution continue s'impose. Ils utilisent par exemple une distribution discrète pour définir trois niveaux de prix possibles, alors qu'en réalité, le prix pourrait prendre n'importe quelle valeur comprise dans une plage.
La fréquence de cette erreur est due au fait que de nombreux utilisateurs sont habitués à la modélisation « hypothétique » manuelle, qui limite l'utilisateur à un petit nombre d'estimations discrètes. La forme continue s'impose quand une valeur quelconque de plage est possible; réserves la fonction DISCRETE à la modélisation d'événements et aux variables discrètes.
Modélisation d'un nombre incertain d'événements, comptant chacun des paramètres incertains
Modèle type : SINISTRES. XLS
Dans les situations réelles, l'incertitude a souvent plusieurs dimensions. Une situation peut désigner un nombre incertain d'événements, comptant chacun une valeur incertaine. Considérez par exemple le secteur des assurances : un nombre incertain de sinistres peuvent être déclarés dans le cadre d'une nouvelle police, et chaque déclaration représente un montant monétaire incertain. Comment simuler le montant total possible des déclarations ? Le secteur pétrolier est confronté à un problème similaire. Lors du forage, un nombre incertain de puits peuvent localiser un fissurement, et la quantité de pétrole découverte dans chacun est incertaine. Comment simuler la quantité totale de pétrole découverte ?
L'analyse de risque s'avère extrêmement utile dans de telles situations de modélisation. La fonction @RISK RiskCompound facilite cette analyse. Examinons, pour bien comprendre cette technique de modélisation, la simulation type SINISTRES. XLS.
Pour exécuter l'analyse :
1) Une distribution sert à échantillonner le nombre d'événements se produit dans une itération donnée. Il s'agit du premier argument de la fonction RiskCompound. 2) Une autre distribution précise l'importance de chaque événement. Il s'agit du second argument de la fonction RiskCompound.
Quand la simulation s'exécute, @RISK échantillonne le nombre d'événements, puis prévient dans la seconde distribution un nombre d'échantillons égal au nombre d'événements. La fonction RiskCompound renvoie le total des échantillons prélevés dans la seconde distribution. Cette valeur apporte la réponse désirée, qu'il s'agisse du montant total des sinistres déclarés ou de la quantité totale de pétrole découverte.
Je dois utiliser cette projection mais elle ne m'inspire pas confiance
Modèle type : ERREUR. XLS
Les responsables de la modélisation Excel disposent souvent de données provenant d'autres sources, à inclure dans leurs feuilles de calcul. La directive reçue pourrait être : « Le groupe économique ayant déterminé cette projection pour la croissance du PNB, incluez-la dans votre modèle de feuille de calcul ». Combien de fois, pourtant, l'ont-ils suivi exactement les projections, même optimes ?
Tout en reconnaissant l'incertitude inhérente aux projections, il peut être utile d'observer la direction de base définie par les valeurs de la tendance. En l'occurrence, les « termes d'erreur » laissent prévoir une certaine variation autour des valeurs de la tendance, ce qui permet d'examiner l'impact de la variation de la valeur de la tendance sur vos résultats.
@RISK permet l'ajout d'un terme d'erreur à une tendance fixe préalablement entrée dans une feuille de calcul. Supposons que la ligne B de la feuille de calcul contienne la tendance fixe du modèle. Un terme d'erreur est tout simplement un facteur par lequel multiplier chaque valeur de cellule de la feuille de calcul. (Vous pourriez aussi ajouter un terme d'erreur à chaque valeur de la tendance.)
Ligne B - Croissance du PNB en pourcentage
B1: 3,2 * RiskNormal(1;0,05) B2: 3,5 * RiskNormal(1;0,05) B3: 3,4 * RiskNormal(1;0,05) B4: 4,2 * RiskNormal(1;0,05) B5: 4,5 * RiskNormal(1;0,05) B6: 3,5 * RiskNormal(1;0,05) B7: 3,0 * RiskNormal(1;0,05)
Dans cet exemple extrait d'Excel, le terme d'erreur pour l'ensemble des valeurs de la tendance est extrait d'une distribution normale dotée d'une moyenne de 1 et d'un écart type de 0,05. À chaque itération de simulation, un nouveau terme d'erreur est échantillonné pour chaque cellule et sert à multiplier l'estimation de la tendance fixe dans cette cellule, permettant la variation autour de l'estimation fixe.
Le terme d'erreur présente l'avantage supplémentaire de la valeur probable générée dans les recalculs Excel normaux. Du fait que les valeurs probables des termes d'erreur de l'exemple sont égales à un, elles n'affectent pas les recalculs normaux de la feuille de calcul. Vous pouvez ainsi laisser les termes d'erreur dans vos formules et n'observer leur effet qu'à l'exécution des simulations. De même si vous ajoutez, plutôt que de multiplier, le terme d'error. Si vous ajoutez le terme d'erreur à l'estimation fixe, la moyenne de la distribution de probabilités du terme d'erreur doit être de zéro.
Utilisation d'arguments variables et de corrélations - ces valeurs seront affectées par des événements survenant ailleurs.
Modèle types : DÉP. XLS, FONCTIONCORRMAT. XLS
Bien souvent, vous ne connaissez pas les valeurs d'argument précises d'une fonction de distribution de votre feuille de calcul. La plage d'une cellule de feuille de calcul dépend souvent de la valeur calculée, ou échantillonnée, ailleurs dans le modèle. La condition suivante illustre ce type de dilemme : « Si le prix est bas, la plage du volume des ventes est de 1 à 2 millions, mais si le prix est élevé, elle n'est que de 500 à 750 mille. »
@RISK propose deux techniques de modélisation aptes à résoudre les problèmes d'arguments variables pour les fonctions de distribution et de corrélations dans l'échantillonnage.
Arguments variables
La première technique - les arguments variables pour les fonctions de distribution - repose sur une fonction Excel standard bien connue de la majorité des créateurs de modèles. La référence aux adresses de cellules dans les fonctions est permise dans @RISK tout comme dans Excel. Par exemple :
Cet exemple illustre la variation de la plage de la distribution uniforme de la variable en fonction de la valeur échantillonnée pour les variables Minimum et Maximum. En l'occurrence, la plage varie à chaque iteration de la simulation. Elle dépend ainsi des variables Minimum et Maximum.
Corrélations dans l'échantillonnage
La deuxième technique de modélisation pouvant affecter des valeurs échantillonnées sur la base d'autres calculs dans une feuille de calcul est celle des corrélations dans l'échantillonnage. La fonction @RISK CORRMAT sert à corréler les valeurs échantillonnées dans des fonctions de distribution distinctes. Cette corrélation vous permet de spécifier un rapport entre les valeurs échantillonnées dans différentes cellules de la feuille de calcul, tout en maintenant toutefois le degré d'incertitude de chacune.
Taux d'intérêt
A1: RiskUniform(6,14;200000; RiskCorrmat(D1:E2;1))
Développement du logement :
B1: RiskUniform(100000;200000; RiskCorrmat(D1:E2;2))
Ci-dessus, la variable Taux d'intérêt - décrite par la distribution RiskUniform(6;14) - représente la distribution avec laquelle la distribution Développement du logement - RiskUniform(100000;200000) - doit être corréllée. La plage D1: E2 contient une matrice de quatre cellules et un simple coefficient de corrélation (-0,75), spécifiant la relation entre les deux valeurs échantillonnées. Les coefficients sont compris entre -1 et 1. Une valeur de -0,75 est une corrélation négative : lorsque le Taux d'intérêt monte, le Développement du logement baisse.
En présence de variables échantillonnées incertaines dans les modèles de feuilles de calcul, il importe de reconnaître les corrélations dans l'échantillonnage. En l'absence de méthodes comparables à celles représentées ci-dessus, toutes les variables incertaines sont échantillonnées comme si elles étaient totalement indépendantes des autres variables du modèle. Cette situation peut produire des résultats erronés. Imaginez ce qui pourrait se passer si les variables Taux d'intérêt et Développement du logement dans l'exemple ci-dessus étaient totalement indépendantes. Elles seraient échantillonnées en parfaite indépendance l'une par rapport à l'autre. Un Taux d'intérêt élevé et une valeur élevée pour la variable Développement du logement constitueraient un scénario possible de l'échantillonnage. Mais pourrait-il réellement se produire? Certainement pas dans la conjoncture actuelle!
Corrélation entre distributions multiples
Les fonctions de distribution multiples peuvent être corréllées de deux manières : à l'aide de la fonction CORRMAT ou, après sélection des cellules concernées, à travers la commande Définir les corrélations. Les deux approches permettent de définir une matrice de coefficients de corrélation. @RISK utilise ces coefficients pour corréler l'échantillonnage des fonctions de distribution. L'approche est particulièrement utile lorsque des coefficients de corrélation préexistants (calculés à partir de données réelles collectées) sont disponibles et que vous pouze qu'ils régissant l'échantillonnage. Excel peut calculer les corrélations au départ de jours de données existants à l'aide de la fonction CORREL. Pour plus de détails sur l'utilisation de Corréler ou de la fonction CORRMAT, voir l'exemple de simulation FONCTIONCORRMAT. XLS.
Dans quelle mesure les changements apportés aux variables du modèle affectent-ils les résultats de la simulation ?
Modèle type : SIMSEN.XLS
@RISK permet d'observer l'impact des paramètres incertains d'un modèle sur les résultats. Que se passerait-il cependant si vous pouviez maîtriser certains de ces paramètres ? La valeur prise par une variable ne serait alors pas aléatoire, car vous pourriez la définir. Vous pourriez par exemple choisir entre différents prix possibles, différentes matières premières possibles ou différentes offres ou paris possibles. Pour analyser correctement le modèle, vous devez exécuter une simulation à chaque valeur possible des variables « régies par l'utilisateur » et comparer les résultats. Une simulation de sensibilité dans @RISK permet de réaliser cette opération rapidement et facilement, offrant ainsi une puissante technique analytique de sélection entre différentes solutions possibles.
Les avantages de la simulation de sensibilité ne se limitent pas à l'évaluation de l'impact des variables contrôlées par l'utilisateur sur les résultats de la simulation. Vous pouvez également exécuter une analyse de sensibilité sur les distributions de probabilités qui décrivent les variables incertaines de votre modèle. Il peut aussi être utile de répéter l'exécution d'une simulation, en modifiant chaque fois les paramètres d'une ou de plusieurs distributions du modèle. Lorsque toutes les simulations individuelles sont terminées, vous pouvez en comparer les résultats.
La clé d'une simulation de sensibilité est la simulation répétitive du même modèle avec apport de modifications sélectionnées au modèle à chaque simulation. @RISK admet un nombre quelconque de simulations dans une même simulation de sensibilité. La fonction SIMTABLE sert à introduire dans les cellules et formules de la feuille de calcul les listes de valeurs à utiliser dans les simulations individuelles. @RISK traite et affiche automatiquement l'ensemble des résultats de chaque simulation individuelle, facilitant ainsi la comparaison.
Pour exécuter une simulation de sensibilité :
Commencez par entrer les listes de valeurs à utiliser à chaque simulation individuelle dans les cellules et formules appropriées à l'aide de la fonction SIMTABLE. Par exemple, différents niveaux de prix possibles peuvent être entrés dans la cellule B2 :
B2: RiskSimtable({100;200;300;400})
La simulation °1 doit utiliser pour le prix une valeur de 100, la simulation °2, une valeur de 200, la simulation °3, une valeur de 300 et la simulation °4, une valeur de 400.
2) Définissez le nombre de simulations dans la boîte de dialogue Paramètres et choisissez la commande Démarrer la simulation pour exécuter la simulation de sensibilité.
Chaque simulation exécute le même nombre d'itérations et recueille données des mêmes plages de sortie spécifiées, en utilisant toutefois une valeur différente des fonctions SIMTABLE de la feuille de calcul.
@RISK traite les données de la simulation de sensibilité de la même manière que celles d'une simulation ordinaire. Chaque cellule de sortie, pour laquelle des données ont été recueillies, comporte une distribution par simulation. En cliquant sur l'icone Afficher le numéro de simulation d'une fenêtre graphique, vous pouvez comparer les résultats des différentes approches ou « scénarios » décrits par chaque simulation individuelle. Le graphique Synthèse de distribution récapitule aussi les variations de la plage de sortie. Il existe un graphique de synthèse différent pour chaque plage de sortie de chaque simulation; les graphiques peuvent être comparés pour indiquer les différences entre les simulations individuelles. Le rapport Synthèse de simulation est également utile à la comparaison des résultats de simulations multiples.
La simulation de sensibilité permet aussi d'observer l'effet des différentes fonctions de distribution sur les résultats. Les valeurs entrées dans la fonction SIMTABLE peuvent être des fonctions de distribution. Vous pouvez par exemple observer la variation des résultats lorsqu'elles essayez alternatively TRIANG, NORMAL ou LOGNORM comme type de distribution dans une cellule.
Attention!
Il importe de bien désigner 1) les changements contrôleurs par simulation (modélisés par la fonction SIMTABLE) et 2) la variation aléatoire au sein d'une simulation unique (modélisée par les fonctions de distribution). Il ne faut pas remplaçer la fonction DISCRETE par SIMTABLE lors de l'évaluation de différents événements discrets aléatoires possibles. La plupart des situations de modélisation combinent des variables incertaines aléatoires et des variables incertaines mais « contrôlables ». Les variables contrôlables finissent généralement par être fixées à une valeur spécifique par l'utilisateur, en fonction de la comparaison réalisée par simulation de sensibilité.
Analyse de sensibilité avancée
Les versions @RISK 5.5 Professional et Industrial proposent un nouvel outil d'analyse experte intitulé Analyse de sensibilité avancée. Cette analyse étend largement les capacités de simulation de sensibilité décrites ici. Pour plus de détails, voir la commande Analyses avancées dans la section Référence : Menu compagnon @RISK de ce manuel.
L'exemple « hippo
Lorsqu'une entreprise développe un nouveau produit, la rentabilité de ce produit est extrêmement incertaine. La simulation offre un excellent outil d'évaluation de la rentabilité moyenne et du risque associés aux nouveaux produits. L'exemple qui suit illustre l'utilité de la simulation dans l'évaluation d'un nouveau produit.
L'entreprise ZooCo envisage le lancement d'un nouveau médicament pour hippopotames. Au début de l'année courante, un million d'hippopotames sont susceptibles d'utiliser le produit. Chaque hippopotame prendra le Médicament (ou celui d'un concurrent), au plus, une fois par an. Selon les prévisions, la population d'hippopotames devrait s'accroître, en moyenne, de 5% par an, et l'on est sur, à 95%, qu'elle s'accroître chaque année de 3% à 7%. La consommation du Médicament durant la première année est incertaine, mais on imagine qu'elle sera, au pire, de 20%, le plus probablement, de 40% et, au moins, de 70%. Pour les années suivantes, la proportion des hippopotames qui prendront le Médicament (ou celui d'un concurrent) devrait rester la même, mais durant toute année suivant l'arrivée d'un concurrent sur le marché, l'entreprise perdra vraisemblablement 20% de sa part par concurrent. Nous allons modéliser le marché de l'année 1 à l'aide d'une variable aléatoire triangulaire. Voir la figure 28.1. Essentiellement,
@RISK générale consommation de l'année 1 en rendant la probabilité d'une consommation donnée proportionnelle à la hauteur du « triangle » illustré à la figure 28.1. Ainsi, une consommation de 40% pour l'année 1 semble la plus probable; une consommation de 30% est deux fois moins probable qu'une consommation de 40%, etc. La hauteur maximale du triangle est 4, car cette valeur produit une zone totale, sous le triangle, égale à un. La probabilité d'une consommation tombant dans une plage donnée est égale à la zone de cette plage sous le triangle. Par exemple, la probabilité d'une consommation représentant au plus 40% est 0.5 (4) (0.4 - 0.2) = 0.4 ou 40%.
Figure 28.1
L'intervention de trois concurrents potentiels (en plus de ZooCo) doit être envisagée. Au début de chaque année, chaque nouvel entrant non encore présent sur le marché présente un risque mesuré à 40% d'y faire son entrée. L'année suivant l'arrivée d'un concurrent, la consommation du produit ZooCo baisse de 20% par concurrent entré sur le marché. Ainsi, si deux concurrents pénètrent le marché pendant l'année 1, la consommation du produit ZooCo se réduira de 40% durant l'année 2. La variable aléatoire binomiale (dans @RISK, la fonction =RISKBinomial) permet de modéliser le nombre d'entrants. La formule
= RISKBinomial(n; p)
général représentant n épreuves binomiales indépendantes (aboutissant chacune à un succès ou un échec) représentant une probabilité de succès égale à p, avec comptabilisation du nombre de succès.
Le terme « succès » désigne ici l'entrée d'un concurrent sur le marché. La formule
simule ainsi le nombre d'entrants pour une année durant laquelle deux concurrents peuvent encore faire leur entrée sur le marché. Il faut s'assurer, si les trois entrants ont déjà fait leur entrée, qu'aucun autre ne puisse apparaître sur le marché.
Chaque unité du médicament se vend au prix de 2,20 et est sujette à un coût variable de0,40. Les bénéfices sont réduits de 10% (taux ajusté en fonction du risque) par an.
Cherchons un intervalle de confiance de 95% pour la VAN ajustée en fonction du risque du projet. Ne nous préoccupons pas pour l'instant du coût fixe du développement du médicament.
Rappelons que la VAN ajustée en fonction du risque est la valeur réduite probable des cash-flows (réduite au taux ajusté en fonction du risque).
Figure 28.2
La feuille de calcul est illustrée à la figure 28.2 (fichier hippo.xls).
| Année | 1 | 2 | 3 | 4 | 5 |
| Taille marché | 1000000 | 1050000 | 1102500 | 1157625 | 1215506,25 |
| Consom. | 0,433333333 | 0,346666667 | 0,277333333 | 0,277333333 | 0,277333333 |
| Concurrents | 0 | 1 | 2 | 2 | 2 |
| Entrants | 1 | 1 | 0 | 0 | 0 |
| Ventes | 433333,3333 | 364000 | 305760 | 321048 | 337100,4 |
| Revenues | 953 333 | 800 800 | 672 672 | 706 306 | 741 621 |
| Coûts | 173 333 | 145 600 | 122 304 | 128 419 | 134 840 |
| Bénéfices | 780 000 | 655 200 | 550 368 | 577 886 | $ 606 781 |
VAN
$2 435 545
Pas à pas...
Première étape : À la ligne 8, on détermine la taille du marché pour chacune des cinq prochaines années. Dans la cellule B8, on entre =D3. Compte tenu d'une croissance du marché normalement distribuée d'année en année, les informations données indiquent que le nombre d'animaux augmente chaque année d'un pourcentage représentant une variable aléatoire normale dont la moyenne est 0,05 et l'écart type, 0,01 (dans 95 % des cas, une variable aléatoire normale s'inscrit dans l'espace de 2 écarts types de sa moyenne). On peut donc conclure que 2σ = 0,02 ou σ = 0,01. Dans la cellule C8, on détermine ainsi la taille du marché pour l'année 2 selon la formule
= B 8* RISKNormal (1, 0 5; 0, 0 1).
Cette formule assure essentiellement, pour chaque année, une chance de 68% de voir la taille du marché des hippopotames s'accroître de 4 à 6%, une chance de 95% de la voir croître de 3 à 7%, et une chance de 99,7% de voir le marché croître de 2 à 8%. En copiant cette formule sur la plage D8: F8, on obtient la taille du marché pour les années 3 à 5.
Deuxième étape : À la ligne 9, on détermine la consommation/hippopotame pour chaque année. Pour l'année 1, la consommation/hippopotame est calculée dans la cellule B9 par la formule
Aux niveaux C9 : F9, on tient compte du fait que l'année après l'entrée, chaque entrant réduit de 20% notre part du marché. Dans la cellule C9, on calcule donc la consommation/hippopotame de l'année 2 selon la formule
= B9 × (1 - B11 × DS2).
Copie sur la plage D9:F9, cette formule calcule la part du marché pour les années 3 à 5.
Troisième étape : À la ligne 11, on détermine le nombre d'entrants durant chaque année. Si moins de 3 concurrents ont pénétré le marché, ceux non encore entrés représentent chacun une chance de 40% d'y entrer durant l'année courante. Si les trois concurrents sont tous entrés, plus personne ne peut entrer. Dans la cellule B11, on calcule le nombre d'entrants pour l'année 1 selon la formule
=SI(B10<3;RISKBinomial(3-B10;B5);0).
On copie ensuite cette formule dans C11: F11 pour calculer les entrées des années 2 à 5. En l'absence de l'instruction =Si, un message d'erreur serait renvoyé pour une année ultérieure à l'entrée des trois concurrents car =RISKBinomial n'admet pas 0 essai comme premier argument.
Quatrième étape : À la ligne 10, on calcule le nombre de concurrents présents au début de chaque année, par ajustement du nombre de nouveaux entrants à celui des concurrents déjà présents. Dans la cellule B10, on entre 0, et dans C10, on entre
Copiée sur la plage D10:F10, cette formule calcule le nombre de concurrents présents au début de chaque année.
Cinquième étape : À la ligne 12, on calcule les ventes de chaque année, soit (consommation/hippopotame)*marché, en copiant la formule
= B8 * B9
de B12 à C12 : F12.
Sixième étape : À la ligne 13, on calcule les revenus annuels en copiant la formule
= = B B 2* B 1 2
de B13 à C13 : F13.
Septième étape : À la ligne 14, on calcule les coûts variables annuels en copiant la formule
= \B\ 3*B12
de B14 à C14 : F14.
Huitième étape : À la ligne 15, on calcule les bénéfices annuels en copiant la formule
Neuvième étape : Dans la cellule B17, on calcule la VAN des bénéfices des cinq années selon la formule
Dixième étape: On exécute maintenant une simulation avec la cellule B17 (VAN) comme cellule de prévision. Sur la base de 500 iterations, les résultats sprésentent comme suit:
Figure 28.3
| Statistiques de synthèse pour VAN / 1 | |||
| Statistiques | Centile | ||
| Minimum | 1 202 238 | 5% | 1 435 119 |
| Maximum | 4 038 368 | 10% | 1 596 386 |
| Moyenne | 2 304 088 | 15% | 1 673 877 |
| Ecart type | 598 648 | 20% | 1 797 048 |
| Variance | 3,5838E+11 | 25% | 1 854 705 |
| Asymétrie | 0,658069216 | 30% | 1 925 525 |
| Aplissemen | 3,297130554 | 35% | 1 964 973 |
| Médiane | 2 247 712 | 40% | 2 065 520 |
| Mode | 2 454 781 | 45% | 2 156 039 |
| X gauche | 1 435 119 | 50% | 2 247 712 |
| P gauche | 5% | 55% | 2 357 714 |
| X droite | 3 531 459 | 60% | 2 418 463 |
| P droite | 95% | 65% | 2 453 680 |
| Diff X | 2 096 340 | 70% | 2 534 750 |
| Diff P | 90% | 75% | 2 655 503 |
| Erreurs | 0 | 80% | 2 757 133 |
| Filtre - Min | Désactivé | 85% | 2 883 177 |
| Filtre - Max | Désactivé | 90% | 3 025 786 |
| Filtrées | 0 | 95% | 3 531 459 |
Notre estimation ponctuelle de la VAN ajustée en fonction du risque est la moyenne d'échantillon des VAN obtenue de la simulation (€2.312.372,866). L'intervalle de confiance de 95% pour la moyenne d'une simulation repose sur le fait que l'on est sûr à 95% que la VAN moyenne réelle est comprise entre
(Moyenne d'échantillon de VAN) ± 2 * (Écart type d'échantillon) / √n,
ou n = nombre d'itérations.
En l'occurrence, nous sommes sûrs à 95% que la VAN moyenne (ou VAN ajustée en fonction du risque) se situe entre
√ 5 0 0 ou
€2.255.718 et €2.369.028.
La VAN ajustée en fonction du risque se situe donc presque certainement entre 2,26 et 2,37 millions. Comme, dans 95% des cas, la précision tombe dans une marge de €50.000 (soit 2% de la moyenne d'échantillon), le nombre d'itérations effectuées peut être aisément considéré comme suffisant.
La valeur réduite (au taux de 10%) réelle des cash-flows est beaucoup plus variable que ne l'indiquerait notre intervalle de confiance pour la VAN ajustée. Voyez plutôt l'histogramme suivant :
Figure 28.4
Remarque: Si vous comptez utiliser la distribution des VAN comme outil de comparaison de vos projets, veillez à réduire tous les projets de l'entreprise au même taux (tel qu'obtenu, probablement, du MEDAF). Vous doubleriez sinon l'incidence du risque.
Graphiques tornades et scénarios
On se demandera naturellement quels sont les facteurs les plus susceptibles d'influencer la réussite du projet. La croissance du marché importe-t-elle plus que le moment de l'entrée des concurrents ? Les graphiques tornades et analyses de scénario @RISK permettent de répondre aisément à ces questions.
a. Quels sont les facteurs qui semblent exercer le plus d'influence sur la VAN du nouveau médicament?
b. Lorsque la VAN se trouve dans les 10% supérieurs de toutes les VAN possibles, quels sont les facteurs réunis?
Un graphique tornado répond à cette question. Dans les « Paramètres de simulation », l'option « Collecte d'échantillons de distribution » doit être sélectionnée. Cliquez ensuite sur l'icône Graphique tornado du graphique affiché pour VAN/B17. Trois options vous sont possibles : Un graphique tornado par régression (Figure 28.5), un graphique tornado par corrélation (Figure 28.6), ou un graphique tornado indiquant les valeurs en entrée, que les coefficients, à l'extrémité des barres.
Figure 28.5
Le graphique en tornade par régression (obtenu par sélection de « Régression-Coefficients » après le clic sur l'icône de graphique en tornade) révèle notamment que
- une augmentation d'un écart type au niveau de la consommation de l'année 1 fait augmenter la VAN de 0,853 écart type;
- Une augmentation d'un écart type au niveau du nombre d'entrants de l'année 1 fait augmenter la VAN de 0,371 écart type; rien d'autre n'importe juste.
En somme, pour l'exécution d'un graphique tornade, @RISK exécute une régression dans laquelle chaque itération représente une observation. La variable dépendante est la cellule de sortie (VAN) et les variables indépendantes représentent chacune les fonctions @RISK « aléatoires » de la feuille de calcul. Le coefficient 0,853 relatif à la consommation de l'année 1 représente ainsi le coefficient réduit, ou bêta, de cette consommation dans la régression.
Figure 28.6
Le graphique tornado par corrélation illustré à la figure 28.6 (tel qu'obtenu par sélection de l'option Corrélation que Régression) révèle que:
- La consommation de l'année 1 présente la plus forte corrélation (0,89) avec VAN;
- viennent ensuite les entrants de l'année 1 (-0,44) ; les autres cellules aléatoires de la feuille de calcul sont sans grande importance !
Il s'agit là de corrélations de rangs : pour toutes les iterations, les valeurs de consommation de l'année 1 sont classées par rang, de même que les valeurs de VAN. Les rangs obtenus (pas les valeurs réelles) sont ensuite corrélés.
Si vous avez coché l'option de collecte d'échantillons de distribution dans les paramètres de simulation, vous pouvez obtenir une analyse de scenario. Pour un scenario donné (toutes les iterations où VAN se situe dans les 10% supérieurs, par exemple), l'analyse de scenario identifie les variables aléatoires dont les valeurs different significativement de leurs valeurs médianes. 1
On observe dans l'approche Scénario (Figure 28.7) (cliquez sur l'icône « Scénarios ») que dans les itérations qui produisent les 10% supérieurs des VAN, les variables suivantes diffèrent significativement de leur médiane globale :
- Consommation de l'année 1 (médiane de 0,596, soit 1,66 sigma supérieure à la moyenne)
- Entrants de l'année 2 (médiane de 0, soit 1,53 sigma inférieure à la moyenne)
Pour changer les paramètres du scenario, cliquez simplement sur la ligne « Scénario = » dans la zone Analyse de scenario. La figure 28.7iste trois paramètres de scenario (25% supérieurs, 25% inférieurs et 10% supérieurs des VAN) et les variables aléatoires qui diffèrent significativement de leurs valeurs moyennes dans le scenario donné. Par exemple, pour les iterations dans lesquelles la VAN se situe dans les 25% inférieurs de l'ensemble des iterations, la moyenne de la consommation de l'année 1 est de 13,9%.
Figure 28.7
Identification de la valeur à risques (VAR) d'un portefeuille
(traduit de Financial Models Using Simulation and Optimization, chapitre 45.)
Le titulaire d'un portefeuille d'actions sait combien l'incertitude en affecte la valeur future. La notion de valeur à risques (VAR) a été inventée pour déscrire cette incertitude. Sans entrer dans les détails, la valeur à risques d'un portefeuille, en un point du futur, est généralement considérée comme représentant le cinquième centile de la perte de valeur du portefeuille en ce point du futur. En bref, on considère qu'il n'existe qu'une chance sur 20 de voir la perte du portefeuille surpasser la VAR. Supposons, pour illustrer l'idée, un portefeuille d'une valeur actuelle de 100 euros. On simule la valeur du portefeuille à un an et on découvre un risque de 5% de voir la valeur tomber à 80 dollars ou moins. La VAR du portefeuille est ainsi égale à 20 euros ou 20%. L'exemple qui suit illustre la mesure de la VAR à l'aide de @RISK. L'exemple démontre également combien les options de vente réduisent le risque de la spéculation.
Supposons une action Dell détenue, au 30 juin 1998, au cours de 94 dollars. D'après les données historiques dont on dispose (voir le chapitre 41), on estime que la croissance des actions Dell peut être modélisée sous forme de variable aléatoire normale logarithmique avec µ = 57% et σ = 55,7%. Pour couvrir le risque associé à la détention de l'action Dell, on envisage l'achat (au prix de 5,25 dollars) d'une option de vente européenne sur Dell avec prix de levée de 80 dollars et date d'expiration fixée au 22 novembre 1998. Il faut procéder aux opérations suivantes :
a) Calculer la VAR au 22 novembre 1998 pour la détention d'actions Dell sans option de vente. b) Calculer la VAR au 22 novembre 1998 pour la détention d'actions Dell avec option de vente.
Solution
Le point essentiel est de bien comprendre qu'en évaluant l'option de vente, on laisse le cours de l'action Dell monter au taux sans risque, mais qu'en effectuant un calcul de VAR, on doit laisser ce cours monter au taux de croissance attendu. Le fichier var.xls illustrate la situation. Voir aussi la Figure 45.1.
Figure 45.1
Pas à pas...
Les noms de plage définis sont indiqués à la figure 45.1.
Première étape : Dans la cellule B11, on génère le cours de l'action Dell au 22 novembre 1998 selon la formule
= S ^ EXP ((g - 0. 5 ^ v ^ 2) ^ d + RISKNormal (0; 1) ^ v* SQRT (d)).
Deuxième étape : Dans la cellule B12, on calcule les paiements de l'option de vente à l'expiration selon la formule
= SI(B11 gt; x; 0; x - B11).
Troisième étape : Le gain en pourcentage du portefeuille sur simple détention de l'action Dell est donné par
Ending Dell Price - Beginning Dell Price/Beginning Dell Price
Dans la cellule B14, on calcule le gain en pourcentage du portefeuille sans achat de l'option de vente, selon la formule
= (B11 - S) / S.
Quatrième étape : Le gain en pourcentage du portefeuille sur détention de l'action Dell avec option de vente est
Dans la cellule B15, on calcule le gain en pourcentage du portefeuille avec achat de l'option de vente, selon la formule
= ((B12 + B11) - (S + p)) / (S + p).
Cinquième étape : Après élection des cellules B14 et B15 comme cellules de sortie et execution de 1.600 iterations, on obtient la sortie @RISK illustrée à la figure 45.2.
Figure 45.2
| Nom | % gain sans option / VAR_p | % gain avec option / VAR_p | Cours Dell à expiration / VAR_p |
| Description | Sortie | Sortie | RiskNormal(0;1) |
| Cellule | Feuille1!C24 | Feuille1!C25 | Feuille1!C21 |
| Minimum | -0,6295196 | -0,1939547 | -3,297835 |
| Maximum | 2,671963 | 2,477729 | 3,235581 |
| Moyenne | 0,2538988 | 0,210691 | -4,036741E-05 |
| Ecart type | 0,4529166 | 0,4013703 | 0,9991838 |
| Variance | 0,2051335 | 0,1610981 | 0,9983683 |
| Asymétrie | 1,091227 | 1,417488 | -1,320796E-04 |
| Aplisissement | 4,967934 | 5,693235 | 2,962567 |
| Erreurs | 0 | 0 | 0 |
| Mode | 5,439337E-02 | -0,1939547 | -1,242844E-02 |
| 5% Cent | -0,3388837 | -0,1939547 | -1,648219 |
| 10% Cent | -0,2488414 | -0,1939547 | -1,28451 |
| 15% Cent | -0,1811313 | -0,1939547 | -1,03867 |
| 20% Cent | -0,1226967 | -0,1691032 | -0,8423297 |
| 25% Cent | -6,992144E-02 | -0,1191195 | -0,6759344 |
| 30% Cent | -1,912058E-02 | -7,100589E-02 | -0,524453 |
| 35% Cent | 0,0299081 | -2,457067E-02 | -0,3855194 |
| 40% Cent | 7,857564E-02 | 2,152252E-02 | -0,2540019 |
| 45% Cent | 0,1281219 | 6,844795E-02 | -0,1260701 |
| 50% Cent | 0,1786324 | 0,1162866 | -1,306796E-03 |
| 55% Cent | 0,2320259 | 0,1668558 | 0,1248938 |
| 60% Cent | 0,2887377 | 0,2205677 | 0,2530829 |
| 65% Cent | 0,3498554 | 0,2784524 | 0,3850633 |
| 70% Cent | 0,4166918 | 0,3417535 | 0,5227199 |
| 75% Cent | 0,4933597 | 0,4143658 | 0,672844 |
| 80% Cent | 0,5834769 | 0,4997162 | 0,8397474 |
| 85% Cent | 0,6959567 | 0,6062462 | 1,035219 |
| 90% Cent | 0,8478212 | 0,7500775 | 1,279502 |
| 95% Cent | 1,099214 | 0,9881727 | 1,642837 |
Il apparait que la VAR, sans achat de l'option de vente, représenté 33,9 % de la somme investie, tandis qu'avec l'option, cette VAR tombe à 19,4 % de la somme investie. La raison en est, bien sûr, que si l'action Dell baisse au-dessous de 80 dollars, chaque baisse de un dollar est contrée par une hausse égale de la valeur de l'option de vente. Remarquez aussi que sans l'option de vente, l'action Dell (en dépit de son taux de croissance élevé) pourrait perdre jusqu'à 64 % de sa valeur.
Les historiques qui suivent illustrent la distribution du gain en pourcentage réalisé avec ou sans option de vente.
Figure 45.3
Figure 45.4
Les figures 45.3 et 45.4 révèlent un risque de perte importante beaucoup plus grand en l'absence de l'option de vente. On remarquera toutefois que le rendement moyen est de 25,4% sans l'option de vente, et de 21,1% seulement avec l'option. L'achat de l'option représentée en fait une assurance de portefeuille, soit une forme d'assurance dont il faut payer la prime.
Simulation d'un tournoi de la NCAA
Le fichier NCAA.xls vous offre l'occasion de rejouer le tournoi de la NCAA autant de fois que vous le désirez. Les avantages de chaque équipe sont pris en compte (d'après les classements SAGARIN publiés dans USA Today). L'analyse approfondie des données a indiqué que les équipes suivent, en moyenne, les classements SAGARIN, avec un écart type de 7 points. Par exemple, en 1997, SAGARIN avait donné à NC la cote 94 et à Fairfield, la cote 70. On peut ainsi modéliser le jeu de NC par RISKNormal(94;7), et Fairfield, par RISKNormal(70;7) et déclarer vainqueur l'équipe la plus performante. Notre simulation du tournoi NCAA 1996 peut être consultée dans le fichier NCAA96.xls.
Commençons par libeller les équipes de la région EAST de 1 à 16, dans l'ordre de leur apparition dans la liste. Les équipes 17 à 32 sont celles de la région SOUTHEAST, 33 à 48, celles de la région WEST, et 49 à 64, celles du MIDWEST. Il est important de bien lister les choses, de manière à ce que le gagnant de 1 et 2 rencontres celui de 3 et 4.
Pas à pas...
Première étape : On entre les classements, codes numériques et noms des équipes sur les lignes 2 à 4 et on désigne la plage A3: BL4 sous l'appellation Classements.
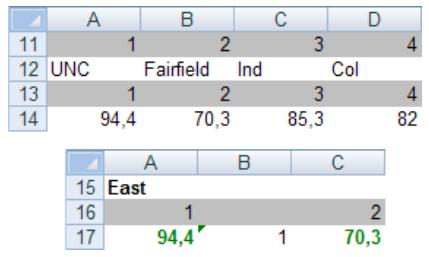
Deuxième étape : On modélise la rencontre UNC Fairfield dans la plage A6:C7. Dans la cellule A7, on génère la performance de l'UNC selon la formule
On consulte ainsi le classement de l'UNC et on génère la performance en fonction de cette moyenne et d'un écart type de 7.
De même, on génère la performance de Fairfield dans la cellule C7. Dans la cellule B7, on détermine l'équipe gagnante selon la formule
= SI(A7 > C7; A6; C6).
Après la rencontre Colorado-Indiana dans la plage E6:G7 (Figure 62.1), on oppose les gagnants des deux rencontres dans la plage A9:C10.
On s'assure que l'entrée A9 est le gagnant de la rencontre UNC-Fairfield, et l'entrée C9, celui de la rencontre Indiana-Colorado. On « joue » ensuite la nouvelle rencontre sur la ligne 10, voir la figure 62,2.
Figure 62.3
La même logique s'applique jusqu'à la ligne 57, où commencent les demi-finales. Voir la figure 62.3.
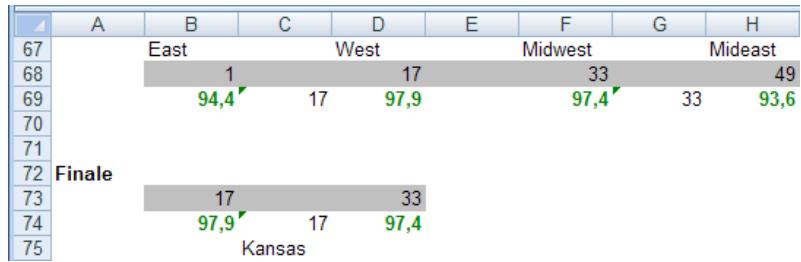
En 1997, la région East avait joué contre la région West, et le Midwest contre le Mideast. Chaque année, les quatre dernières rencontres varieront et vous devrez ajuster cette partie de la feuille de calcul. Dans la cellule C65, on imprime le vainqueur selon la formule
Cette formule identifie le nom de l'équipe correspondant au numéro de code du gagnant. Appuyez plusieurs fois sur la touche F9 et voyez ce qui se passe.
Nous avons utilisé C64 comme cellule de sortie et exécuté 5.000 fois le tournoi. Les équipes qui avaient une chance d'au moins 5% de l'emporter étaient :
UNC: Kansas: Kentucky: Duke: Minnesota:
Bien sûr, l'Arizona a gagné! (Nous lui avions donné une chance de 0,0084!) C'est là tout le plaisir du sport!
Remarques
N'oubliez pas que la configuration des quatre finalistes change chaque année. Vous devrez par conséquent réarranger les lignes réservées aux régions East, Midwest, Mideast et West.
Chapitre 6 : ajustement de distributions
Définition des données en entrée 183
Données d'échantillon 183
Données de densité 184
Données cumulatives. 185
Filtrage des données 185
Sélection des distributions à ajuster 187
Distributions continues ou discrètes 187
Paramètres estimés ou distributions prédéfinies. 187
Limites de domaine 188
Exécution de l'ajustement 189
Données d'échantillon - Estimateurs du maximum de vraisemblance (EMV) 189
Données de courbe - Méthode des moindres carrés 191
Interprétation des résultats 193
Graphiques. 193
Statistiques de base et centiles 195
Statistiques d'ajustement 196
Valeurs P et valeurs critiques 198
Application des résultats de l'ajustement. 201
Exportation des graphiques et des rapports 201
Utilisation des distributions ajustées dans Excel. 202
@RISK (versions Professional et Industrial uniquement) permet l'ajustement de distributions de probabilités à vos données existantes. L'ajustement est utile en présence de données existantes dont on peut faire la base d'une distribution en entrée. Il se peut, par exemple, que vous disposiez de données historiques relatives au prix d'un produit et que vous désiriez créer une distribution des prix à partir de ces données.
Cinq étapes doivent être envisagées pour l'ajustement des distributions aux données existantes à l'aide de @RISK :
Définition des données en entrée - Spécification des distributions à ajuster - Exécution de l'ajustement - Interprétation des résultats - Application des résultats de l'ajustement
La description de ces étapes fait l'objet de ce chapitre.
Définition des données en entrée
Pour l'ajustement de distributions, @RISK admet l'analyse des trois types de données suivants : données d'échantillon, courbe de densité et courbe cumulative. @RISK peut : gérer jusqu'à 100.000 points de données pour chacun de ces types. Les types de données disponibles sont indiqués sous l'onglet Données de la boîte de dialogue Ajuster les distributions aux données.
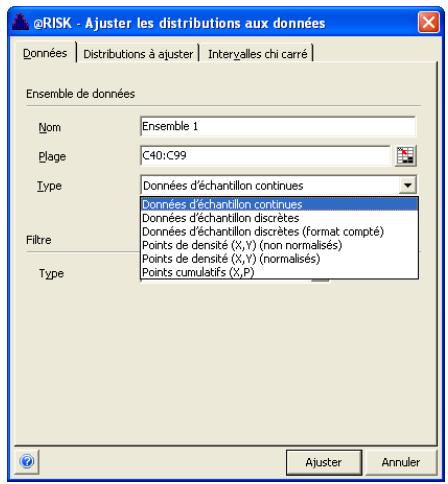
Données d'échantillon
Les données d'échantillon (ou d'observation) représentent un ensemble de données extraites aléatoirement d'une vaste population. Les distributions s'ajustent aux données d'échantillon pour estimer les propriétés de cette population.
Les données d'échantillon sont soit continues, soit discrétisées. Les données continues peuvent représenter une valeur quelconque d'une plage continue, tandis que les données discrétisées sont limitées aux valeurs entières. Les données discrétisées peuvent être définies sous deux formats. Au format « standard », on entre chaque point de données individuellement. Au format « compté », les données s'entrent par paires, la première valeur représentant la valeur échantillonnée et la seconde, le nombre d'échantillons prélevés avec cette valeur.
Conditions à remplir
Les conditions suivantes doivent être respectées pour les données d'échantillon :
Vous devez être disposé d'au moins cinq valeurs de données. Les valeurs de données discrètes doivent être des nombres entiers. Toutes les valeurs d'échantillon doivent être comprises dans la plage -1E + 37 <= x <= +1E + 37 ou être des dates.
Données de densité
Les données de densité représentent un ensemble de points (x, y) décrivant la fonction de densité de probabilité d'une distribution continue. Les distributions s'ajustent aux données de densité pour produire une représentation optimale des points de la courbe en fonction d'une distribution de probabilités théorique.
Normalisation des données de densité
Comme toutes les fonctions de distribution de probabilités doivent compter une zone d'unité, @RISK définit automatiquement l'échelle des valeurs y de manière à ce que la courbe de densité décrite par les données couvre une zone égale à un. Comme les points que vous spécifiez sont des points isolés d'un continuum, le facteur de normalisation se calcule par interpolation linéaire entre ces points. La normalisation @RISK n'est pas toujours désirable : dans le cas, par exemple, de l'ajustement à des données générées par une fonction mathématique déjà normalisée. Dans de tels cas, la fonction peut être désactivée.
Conditions à remplir
Les conditions suivantes doivent être respectées pour les données de densité :
Vous devez disposer d'au moins trois paires de données (x, y). Toutes les valeurs x doivent être comprises dans la plage -1E + 37 <= x <= +1E + 37 ou être des dates. Toutes les valeurs x doivent être distinctes. Toutes les valeurs y doivent être comprises dans la plage 0 <= y <= + 1E + 37. Au moins une valeur y doit être non nulle.
Données cumulatives
Les données cumulatives représentent un ensemble de points (x, p) dérivant une fonction de distribution cumulative continue. La valeur p associée à une valeur x donnée représente la probabilité d'obtenir une valeur inférieure ou égale à x. Les distributions s'ajustent aux données cumulatives pour produire une représentation optimale des points de la courbe en fonction d'une distribution de probabilités théorique.
Interpolation
Pour calculer les statistiques et afficher les graphiques de vos données cumulatives, @RISK doit connaître le minimum et le maximum de l'entrée (les points p = 0 et p = 1). Si vous n'indiquez pas explicitement ces points, @RISK les déduit des données fournies par interpolation linéaire. Il est généralement recommandé, dans la mesure du possible, d'inclure les points p = 0 et p = 1 dans l'ensemble de données.
Conditions à remplir
Les conditions suivantes doivent être respectées pour les données cumulatives:
Vous devez disposer d'au moins trois paires de données (x, p) Toutes les valeurs x doivent être comprises dans la plage -1E + 37 <= x <= +1E + 37 ou être des dates. Toutes les valeurs x doivent être distinctes. Toutes les valeurs p doivent être comprises dans la plage 0 <= p <= 1 Les valeurs x croissantes doivent toujours correspondre à des valeurs p croissantes elles aussi.
Filtrage des données
Vous pouvez raffiner davantage vos données en entrée par l'application d'un filtrage d'entrée. Le filtrage instruct @RISK d'omettre les valeurs hors norme, en fonction des critères que vous spécifiez, sans que vous deviez les éliminer explicitemment de votre ensemble de données. Par exemple, vous pouvez ainsi limiter l'analyse aux valeurs x supérieures à zéro. Vous pouvez aussi filtrer les valeurs non conformes à deux écarts types de la moyenne.
Sélection des distributions à ajuster
Après avoir défini l'ensemble de données, il faut spécifier les distributions que vous désirez y ajuster. Trois grandes considérations entrent en jeu :
Distributions continues ou discrètes
Pour les données d'échantillon, commencez par déterminer si les données sont continues ou discrètes. Les distributions discrètes renvoient toujours des valeurs entières. Supposons par exemple un ensemble de données décrivant le nombre d'échecs dans une série de 100 lots itératifs. Vous ne pourriez qu'ajuster des distributions discrètes à cet ensemble car les échecs partiers ne sont pas admis. En revanche, les données continues peuvent représenter n'importe quelle valeur comprise dans une plage. Ainsi, pour un ensemble de données décrivant, en centimètres, la taille de 300 personnes, vous choisisseriez l'ajustement de distributions continues, cette taille pouvant être exprimée par des valeurs non entières.
Si vous précisez que vos données sont discrètes, toutes leurs valeurs doivent être entières. L'inverse n'est cependant pas nécessairement vrai, et ce n'est pas parce que toutes vos valeurs de données sont entières que vous ne pouvez y ajuster que des distributions discrètes. Dans l'exemple qui précède, les données de taille peuvent être arrondies au centimètre le plus proche, mais l'ajustement de distributions continues reste approprié.
@RISK ne gère pas l'ajustement de distributions discrètes aux données de densité et de courbe cumulative.
Vous pouvez spécifier un ensemble de données continues ou discrètes sous l'onglet Données de la boîte de dialogue Ajuster les distributions aux données.
Paramètres estimés ou distributions prédéfinies
@RISK estime généralement les paramètres des distributions. Il est cependant parfois utile de préciser les distributions exactes à utiliser. @RISK peut par exemple comparer deux hypothèses concurrenttes et vous indiquer celle qui déscrit le mieux vos données.
Les distributions prédéfinies se configurent sous l'onglet Distributions à ajuster de la boîte de dialogue Ajuster les distributions aux données.
Limites de domaine
Pour les ensembles de données continues (données d'échantillon ou de courbe), vous pouvez spécifier le traitement des limites supérieures et inférieures des distributions. Quatre sont possibles pour chaque limite : limite fixe, limite inconnue, ouverte et incertaine.
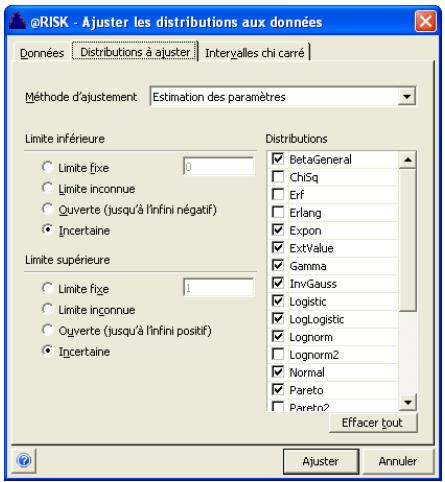
Limite fixe
Sous l'option Limite fixe, @RISK doit respecter, comme limite de la distribution, la valeur que vous indiquez. Ainsi, pour un ensemble de données relatives aux intervalles d'arrivée de clients dans une file d'attente, il serait utile de restreindre l'ajustement aux distributions assorties d'une limite inférieure de zéro puisqu'un intervalle négatif serait impossible.
L'option Limitée inconnue indique à @RISK que la distribution est limitée (par opposition à infinie), mais que, contrairement à l'option de limite fixe, la valeur précise de cette limite n'est pas connue. @RISK désigne lui-même cette valeur en cours d'ajustement.
Ouverte
Sous l'option Ouverte, la limite de la distribution s'étend à l'infini, côte négative pour une limite inférieure, et côte positive pour une limite supérieure.
Incertaine
L'option Incertaine est configurée par défaut. Elle représentée une combinaison de limite inconnue et ouverte. Les limites des distributions non asymptotiques sont traitées comme dans le cas de la limite inconnue, tandis que les distributions asymptotiques sont inclues dans la catégorie de la limite ouverte.
Remarquez que toutes les distributions ne sont pas compatibles avec tous les choix possibles. Ainsi, une limite inférieure fixe ou inconnue ne peut pas être précisée pour la distribution Normal, dont la portée asymptotique s'étend à l'infini négative.
Exécution de l'ajustement
Pour lancer l'ajustement, cliquez sur le bouton Ajuster de la boîte de dialogue Ajuster les distributions aux données.
Pour chacune des distributions spécifiées à l'étape précédente, @RISK recherche l'ensemble de paramètres qui rapprochent le plus la fonction de distribution de l'ensemble de données. N'oubliez pas que @RISK ne recherche pas à produire une réponse absolue; il identifie plutôt la distribution la plus susceptible d'avoir produit vos données. Veillez toujours à évaluer vos résultats @RISK de manière quantitative et qualitative, et examinez toujours les graphiques comparatifs et les statistiques avant de retenir un résultat.
@RISK calcule les distributions les derniers adaptations aux données selon deux méthodes : Pour les données d'échantillon, les paramètres de distribution sont estimés à l'aide d'estimateurs du maximum de vraisemblance (EMV). Pour les données de densité et cumulatives (appelées, collectivement, données de courbe), la méthode des moindres carrés permet de minimiser l'erreur de moyenne quadratique entre les points de la courbe et la fonction théorique.
Données d'échantillon — estimateurs du maximum de vraisemblance (EMV)
Les EMV d'une distribution sont les paramètres de la fonction aptes à maximiser la probabilité d'obtention de l'ensemble de données considéré.
Définition
Pour une distribution de densité f(x) dotée du paramètre α et un ensemble correspondant de n valeurs échantillonnées Xi, une expression dite de vraisemblance peut être définie:
= i = 1n f(Xi, α)
Pour trouver l'EMV, il suffit de maximiser L par rapport à α
dL/d α = 0
puis de résoudre la valeur de α. La méthode décrite ci-dessus est aisément généralisable aux distributions assorties de plusieurs paramètres.
Par exemple
Une fonction exponentielle assortie d'une limite inférieure fixe de zéro ne comporte qu'un paramètre ajustable et son EMV est facile à calculer. La fonction de densité de la distribution est
f(x) = 1/βe-x / β
et la fonction de vraisemblance,
L (β) = i = 1n 1/βe-Xi / β = β-n (- 1/β i = 1n Xi)
Pour simplifier les choses, on utilise le logarithme naturel de la fonction de vraisemblance :
(β) = (β) = - n (β) - 1/β i = 1n Xi
Pour maximiser le logarithme de la vraisemblance, il suffit d'en fixer le dérivé par rapport à β à zéro :
dl/d β = - n/β + 1β^ 2 _ i = 1 ^ n X _ i
La valeur zéro est obtenue quand
β = i = 1n in
Par conséquent, lorsque @RISK tente d'ajuster vos données à la meilleure fonction exponentielle à limite inférieure fixe de zéro, il repère d'abord la moyenne des données en entrée et s'en sert comme EMV pour β.
Adaptations de la méthode EMV
La méthode EMV décrite plus haut ne convient pas à toutes les distributions. Ainsi, une distribution gamma à 3 paramètres (dont la limite inférieure peut varier) ne peut pas toujours être ajustée au moyen des EMV. @RISK a alors recours à un algorithme hybride, combinant l'approche EMV avec une procédure de correspondance de moments.
Dans certaines distributions, un EMV rigoureux peut produire des paramètres largement biaisés pour les petites tailles d'échantillon. Par exemple, l'EMV du paramètre de « décalage » d'une distribution exponentielle et les paramètres minimum et maximum de la distribution uniforme sont largement biaisés pour les tailles d'échantillon réduites. Autant que possible, @RISK cherche à rectifier le biais.
Données de courbe — méthode des moindres carrés
L'erreur de moyenne quadratique entre un ensemble de n points de courbe (Xi, i) et une fonction de distribution théorique f(x) dotée d'un paramètre α est
RMSErr = √ 1/n _ i = 1 ^ n (f (x _ i, α) - y _ i) ^ 2
La valeur de α apte à minimiser cette valeur est qualifiée de valeur des moindres carrés. Dans un certain sens, cette valeur minimise la «distance» entre la courbe théorique et les données. La formule ci-dessus est aisément généralisable à plus d'un paramètre.
Cette méthode sert à calculer la distribution optimale pour les données de densité et de courbe cumulative.
Interprétation des résultats
Après l'ajustement par @RISK, il convient d'examiner les résultats.
@RISK vous offre un large éventail de graphiques, statistiques et rapports utiles à l'évaluation des distributions ajustées et à la sélection du meilleur choix possible pour vos modèles.
@RISK classe toutes les distributions ajustées en fonction de différentes statistiques d'ajustement. Pour les données d'échantillon continues, vous pouvez désirer un classement en fonction de la statistique chi carré, Anderson-Darling ou Kolmogorov-Smirnov. Ces options sont décrites en détail plus loin dans cette section. Pour les données d'échantillon discrètes, seule la statistique chi carré peut être utilisée. Pour les données de densité et cumulatives, les distributions se classent en fonction de leur valeur d'erreur de moyenne quadratique.
Graphiques
@RISK propose quatre types de graphiques utiles à l'évaluation visuelle de la qualité des distributions ajustées.
Graphiques comparatifs
Un graphique comparatif superpose les données en entrée et la distribution ajustée sur un même graphique. Vous pouvez ainsi les comparer visuellement sous forme de courbe de densité ou cumulative. Ce graphique permet d'évaluer la correspondance entre la distribution et les données en entrée en certains endroits. Par exemple, la correspondance autour de la moyenne ou aux extrémités est parfois très importante.
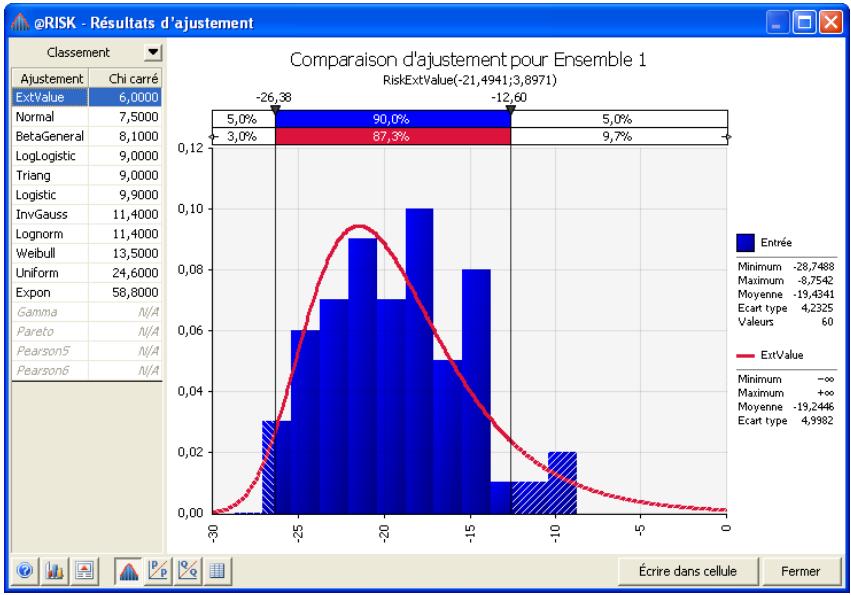
Graphiques p-p
Les graphiques double probabilité (P-P) représentent la distribution des données en entrée (Pi) par rapport à celle du résultat (F(xi)). Si la qualité de l'ajustement est bonne, le trace paraît presque linéaire. Les graphiques P-P ne sont disponibles que pour les ajustements aux données d'échantillon.
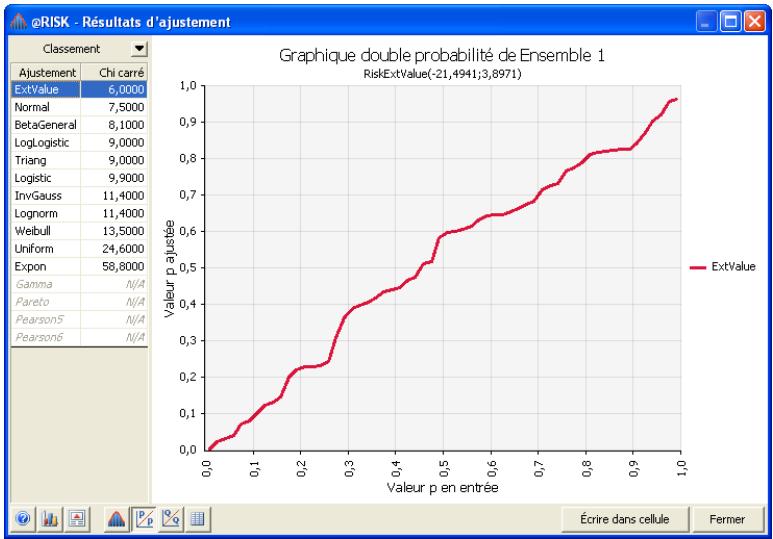
Graphiques Q-Q
Les graphiques double quantile (Q-Q) représentent les valeurs de centile de la distribution en entrée (xi) par rapport à celles du résultat (F-1(Pi)). Si la qualité de l'ajustement est bonne, le trace pourrait presque être linéaire. Les graphiques Q-Q ne sont disponibles que pour les ajustements aux données d'échantillon continues.
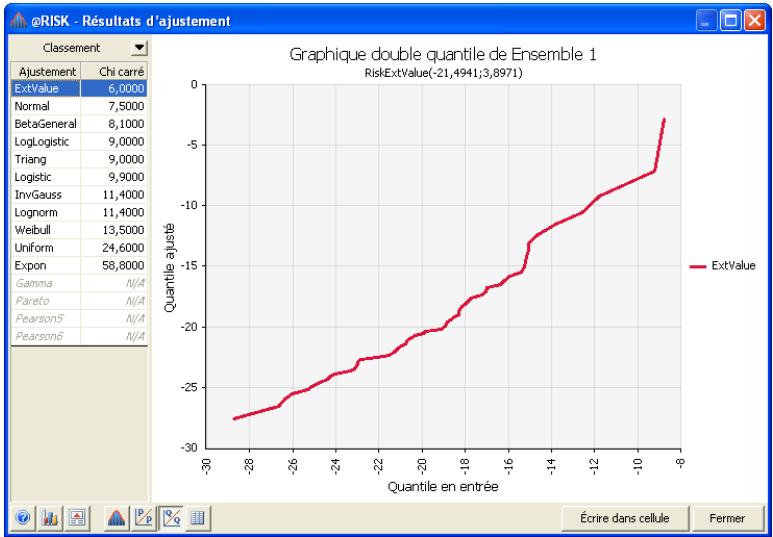
Statistiques de base et centiles
@RISK présente les statistiques de base (moyenne, variance, mode, etc.) de chaque distribution ajustée. Ces statistiques sont aisément comparables à celles correspondantes des données en entrée.
@RISK permet la comparaison des centiles entre distributions et données en entrée. Si, par exemple, les valeurs des 5e et 95e centiles vous sont importantes, vous pouvez procéder de deux manières : d'abord, tous les graphiques @RISK sont dotés de « délimiteurs », grâce auxquels vous pouvez délimiter différentes cibles, ou centiles. Ensuite, les graphiques @RISK peuvent afficher les centiles sélectionnés dans la légende, à droite du graphique.
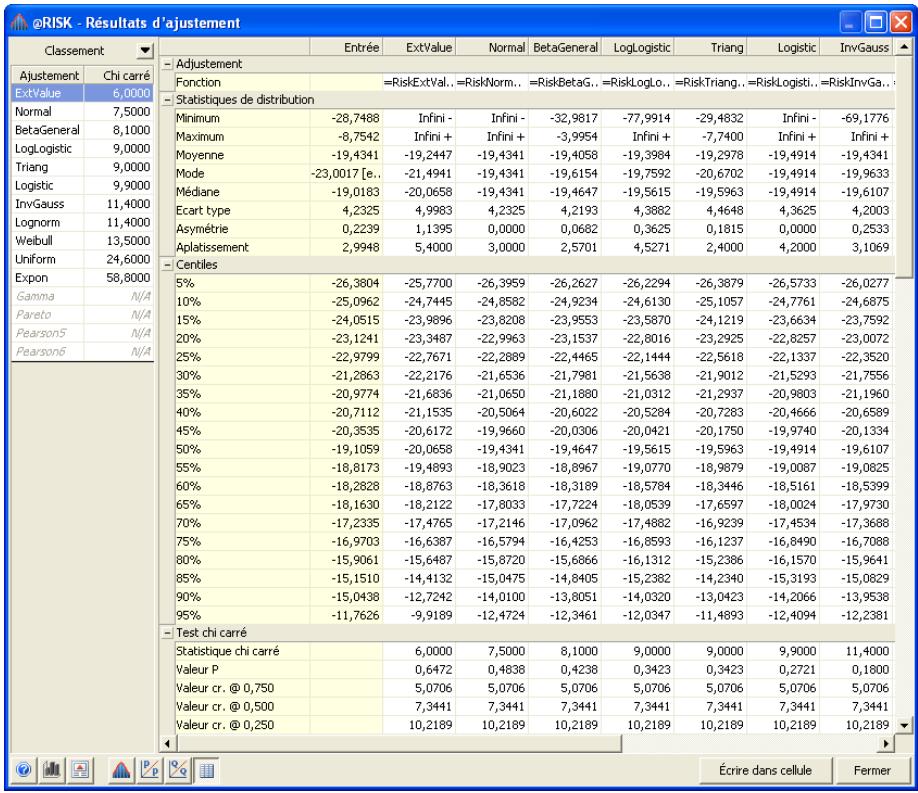
Statistiques d'ajustement
Pour chaque ajustement, @RISK présente au moins un rapport statistique. Ces statistiques mesurent le degré de correspondance entre la distribution et les données en entrée, ainsi que le degré de confiance que vous pouvez avoir dans le fait que la fonction de distribution aurait produit ces données. Pour chacune de ces statistiques, plus la valeur est réduite, plus l'ajustement est précis. @RISK fait appel à quatre différents types de statistiques : chi carré, Kolmogorov-Smirnov, Anderson-Darling et erreur de la moyenne quadratique.
Si plusieurs statistiques sont disponibles, aucune n'est nécessairement la meilleure. Chaque test présente ses avantages et ses inconvénients. Il vous revient de déterminer les informations qui vous importent le plus lors de la sélection du test à utiliser.
La statistique chi carré est la mieux connue pour l'évaluation de la précision d'un ajustement. Elle peut être appliquée aux données d'échantillon continues et discrètes. Pour la calculer, commencez par diviser le domaine de l'axe x en plusieurs « intervalles ». La statistique chi carré se définit ensuite comme suit :
2 = i = 1K (Ni - Ei)2/Ei
Ni représente le nombre d'échantillons observé dans le ie intervalle
Ei représente le nombre d'échantillons attendu dans le ie intervalle
Un inconvénient de la statistique chi carré tient à l'absence de directive claire quant à la sélection du nombre et de l'emplacement des intervalles. Dans certains cas, vous pourriez aboutir, au départ des mêmes données, à des conclusions différentes suivant la manière dont vous avez spécifié ces intervalles.
Le choix d'intervalles équiprobables permet d'éliminer quelque peu ce caractère arbitraire. Sous cette option, @RISK ajuste les tailles d'intervalle en fonction de la distribution ajustée, de manière à inclure dans chacun une quantité égale de probabilités. La procédure est simple pour les distributions continues. Pour les distributions discrètes, @RISK ne peut égaliser qu'approximativement les intervalles.
Statistique kolmogorov-smirnov (K-S)
@RISK vous permet de maîtriser entièrement la définition des intervalles pour le test chi carré, à travers les paramètres de l'onglet Intervalles chi carré de la boîte de dialogue Ajuster les distributions aux données.
La statistique Kolmogorov-Smirnov convient aussi aux données d'échantillon continues. Elle se définit comme suit :
D _ n = [| F _ n (x) - F (x) | ]
n représente le nombre total de points de données
F(x) représente la fonction de distribution cumulative ajustée
F _ n (x) = N _ xn
Nx représente le nombre de Xi s inférieurs à x.
La statistique K-S n'exige aucune répartition ; elle est moins arbitraire que la méthode chi carré. Elle a cependant pour inconvénient de ne pas bien détecter les divergences en queue de distribution.
Statistique anderson-darling (a-d)
Enfin, la statistique Anderson-Darling s'applique aux données d'échantillon continues. Elle se définit comme suit :
A _ n ^ 2 = n _ - ∞ ^ + ∞ [F _ n (x) - F (x) ] ^ 2 (x) f (x) dx
n représente le nombre total de points de données
^ 2 = 1/F (x) [1 - F (x) ]
f (x) représente la fonction de densité hypothétique
F (x) représente la fonction de distribution cumulative hypothetique
F _ n (x) = N _ xn
Nx représente le nombre de Xi's inférieurs à x.
Erreur de moyenne quadratique
Tout comme la statistique K-S, le test A-D n'exige aucune répartition en intervalles. Contrairement à la statistique K- S, qui se concentre sur le milieu de la distribution, la statistique A-D souligne toutes les différences entre les queues de la distribution ajustée et des données en entrée.
Pour les données de courbe de densité et cumulative, la seule statistique d'ajustement utilisée est l'erreur de la moyenne quadratique. Il s'agit de la même quantité que celle minimisée par @RISK pour déterminer les paramètres de la distribution durant l'ajustement : une mesure de l'erreur carrée « moyenne » entre la courbe en entrée et la courbe ajustée.
Valeurs p et valeurs critiques
La statistique de qualité de l'ajustement représente une mesure de l'écart entre la distribution ajustée et les données en entrée. Comme indiqué plus haut, plus la valeur statistique est réduite, plus l'ajustement est précis. À partir de quel niveau peut-on cependant juger l'ajustement ajusté? Pour les ajustements aux données d'échantillon, cette section décrit l'utilité des valeurs P et des valeurs critiques à l'analyse de ce caractère ajustat.
La description ci-dessous repose sur une distribution ajustée à un ensemble de données échantillonnées N et une statistique d'ajustement correspondante représentée par s.
Valeurs p
Dans quelle mesure un nouvel ensemble de N échantillons extrait de la distribution ajustée produit. Il est possible que la valeur P se rapproche de zéro, moins il est probable que la distribution ajustée puisse avoir général l'ensemble de données originaI. À l'inverse, plus la valeur P s'approche de l'unité (un), moins on peut rejeter l'hypothèse des données produites par la distribution ajustée.
Valeurs critiques
Il est souvent utile d'inverser la question et de préciser un niveau de signification particulier, généralement représenté par α. Cette valeur représente la probabilité de rejet incorrect d'une distribution ayant généralement, sous l'effet de fluctuations statistiques, une valeur s extrêmement élevée. Il faut maintenant déterminer, étant donné ce niveau de signification, la plus grande valeur s acceptable pour l'ajustement. Cette valeur s est dite « valeur critique » de la statistique d'ajustement au niveau de signification α. Les ajustements dont la valeur s est supérieure à la valeur critique sont rejetés, et ceux dont la valeur s est inférieure à cette valeur critique sont acceptés. Les valeurs critiques varient généralement selon le type d'ajustement, la statistique d'ajustement particulière utilisée, le nombre de points de données et le niveau de signification.
Pour le test chi carré, les valeurs P et valeurs critiques peuvent être calculées par recherche des points appropriés sur une distribution chi carré à k-1 degrés de liberté (k représenté le nombre d'intervalles). Bien que parfaitement exacte en présence de distributions prédéfinies, cette méthode n'est qu'approximative pour les distributions dont @RISK a du estimer un ou plusieurs paramètres. Heureusement, l'approximation n'est jamais trop optimiste et les valeurs rapportées pour les valeurs critiques et P sont toujours légèrement supérieures aux valeurs exactes. Pour plus d'informations à ce sujet, reportez-vous à l'Annexe D : Lectures recommendées de ce manuel.
Pour les statistiques A-D et K-S, la plupart des valeurs critiques et valeurs P peuvent être identifiées par une analyse Monte Carlo très détaillée (voir les références suggérées à l'Annexe D : Lectures recommandées). Toutes les distributions ne sont malheureusement pas analysées de manière suffisamment détaillée. Dans la mesure du possible, @RISK rapporte les valeurs P et valeurs critiques appropriées. Nouvent, si le calcul exact de la valeur P n'est pas possible, @RISK renvoie une plage limitée par les valeurs maximale et minimale de la vraie valeur P.
Exportation des graphiques et des rapports
Après l'analyse des résultats du calcul, il peut être utile d'exporter ces résultats vers un autre programme. Vous pouvez bien sûr toujours copier-coller vos graphiques et rapports @RISK dans Excel, ou vers une autre application Windows, en passant par le Presse-papiers. La commande Graphique Excel vous permet de plus de créer un exemplaire du graphique @RISK courant au format graphique naturel de Excel.
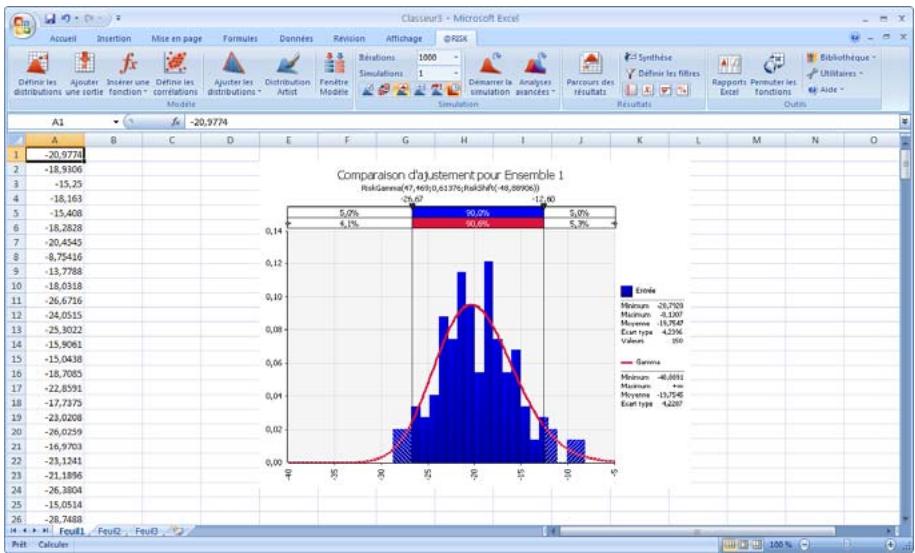
Utilisation des distributions ajustées dans excel
Il vous sera souvent utile d'introduire le résultat de vos ajustements dans un modèle @RISK. Cellule place le résultat d'un ajustement dans le modèle sous forme de nouvelle fonction de distribution.
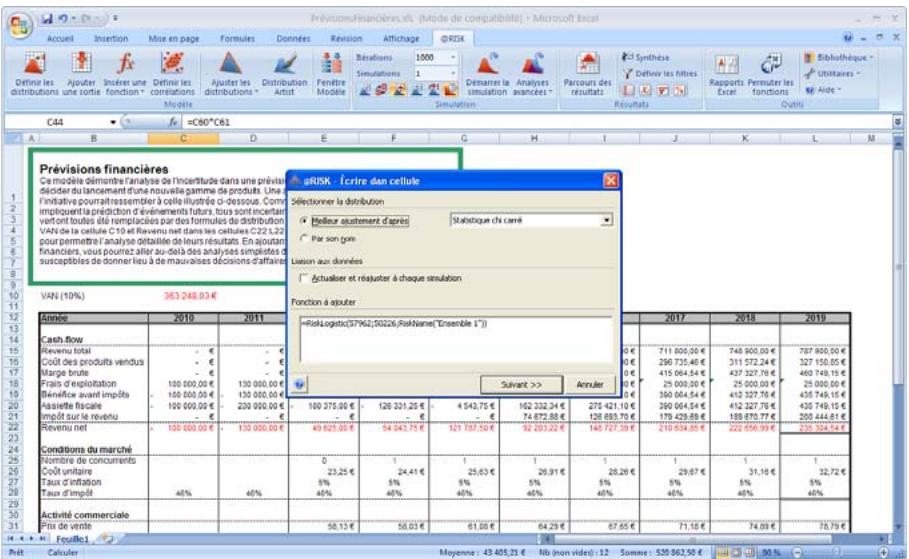
Sous l'option Actualiser et réajuster au début de chaque simulation, @RISK réajuste automatiquement la distribution aux données modifiées et place la nouvelle fonction de distribution dans le modèle au début de chaque simulation.
Référence : icones @RISK 213
Ruban @RISK (Excel 2007) 213
Barre d'outils principale @RISK (Excel 2003 et versions antérieures) 217
Barre de paramètres @RISK (Excel 2003 et versions antérieures) 219
Icones des fenêtres graphiques. 220
Commandes modèle 225
Commande Définir les distributions 225
Propriétés d'entrée 236
Commande Ajouter une sortie. 241
Propriétés de sortie 244
Commande : Insérer une fonction. 249
Commande Définir les corrélations. 255
Commande : Afficher la fenêtre Modèle 270
Fenêtre Modèle - Onglet Entrées 272
Fenêtre Modèle - Onglet Sorties. 279
Fenêtre Modèle - Onglet Corrélations. 280
Commandes d'ajustement de distributions 281
Commande Ajuster les distributions aux données. 281
Onglet Données 282
Onglet Distributions à ajuster 285
Onglet Intervalles Chi-carré 288
Fenêtre Résultats de l'ajustement 291
Résultats d'ajustement - Graphiques. 294
Commande Cellule - Fenêtre Résultats d'ajustement 296 Fenêtre Synthèse d'ajustement. 298 Commande Gestionnaire d'ajustement 300
Commandes distribution artist 301
Commande Distribution Artist 301
Commandes paramètres 305
Commande Paramètres de simulation 305 Onglet Général 306 Onglet Affichage 310 Onglet Échantillonnage 314 Onglet Macros 319 Onglet Convergence 321
Commandes simulation 323
Commande Démarrer la simulation 323
Valeur cible 327
Commande Valeur cible 327 Boîte de dialogue Valeur cible. 328 Boîte de dialogue Options de Valeur cible 330 Analyser 332
Analyse de contrainte 335
Commande Analyse de contrainte 335 Boîte de dialogue Analyse de contrainte 336 Boîte de dialogue Définition d'entrée 338 Boîte de dialogue Options de contrainte 340 Analyser 342
Analyse de sensibilité avancée 349
Commande Analyse de sensibilité avancée 349 Boîte de dialogue Analyse de sensibilité avancée 350 Définition d'entrée 351 Options 357 Analyser 359
Commandes résultats 365
Commande Parcours des résultats 365 Commande Fenêtre Synthèse des résultats 366 Commande Statistiques détaillées 373 Commande Données 376 Commande Sensibilités 380 Commande Scénarios 385
Commande Définir les filtres 390
Commande Rapports Excel 393
Commande : Permuter les fonctions @RISK 395
Commandes Utilitaires 403
Commande Paramètres d'application 403
Commande Fenêtres 407
Commande Ouvrir un fichier de simulation 408
Commande Supprimer les données @RISK. 409
Commande Décharger le compagnon @RISK 410
Enregistrement et ouverture de simulations @RISK. 411
Commandes Bibliothèque 415
Ajouter les résultats à la Bibliothèque. 415
Afficher la Bibliothèque 415
Commandes d'aide 417
Aide @RISK. 417
Manuel en ligne. 417
Commande d'activation de licence. 417
Commande A propos. 417
Référence : Graphiques @RISK 419
Histogrammes et graphiques cumulatifs. 423
Ajuster une distribution à un résultat simulé. 431
Graphiques « tornades » 432
Diagrammes de dispersion. 435
Graphiques de synthèse. 440
Formatage des graphiques. 447
Référence : Fonctions @RISK 453
Fonctions de distribution 453
Fonctions de sortie de simulation 462
Fonctions statistiques de simulation 463
Fonction graphique 464
Fonctions supplémentaires. 464
Tableau des fonctions disponibles 465
Référence : Fonctions de distribution 479
RiskBeta 480 RiskBetaGeneral. 482 RiskBetaGeneralAlt, RiskBetaGeneralAltDD. 485 RiskBetaSubj. 486 RiskBinomial 489 RiskChiSq. 492 RiskCompound. 494 RiskCumul. 495 RiskCumulD 498 RiskDiscrete 501 RiskDUniform 504 RiskErf. 507 RiskErlang. 509 RiskExpon. 511 RiskExponAlt, RiskExponAltDD. 513 RiskExtValue 513 RiskExtValueAlt, RiskExtValueAltDD. 515 RiskGamma. 516 RiskGammaAlt, RiskGammaAltDD 518 RiskGeneral. 519 RiskGeomet 522 RiskHistogram 524 RiskHypergeo 527 RiskIntUniform 530 RiskInvgauss 532 RiskInvgaussAlt, RiskInvgaussAltDD 534 RiskJohnsonMoments 535 RiskJohnsonSB 537 RiskJohnsonSU. 539 RiskLogistic. 541 RiskLogisticAlt, RiskLogisticAltDD 543 RiskLogLogistic 544 RiskLogLogisticAlt, RiskLogLogisticAltDD 546 RiskLognorm. 547 RiskLognormAlt, RiskLognormAltDD. 550 RiskLognorm2. 551 RiskMakeInput. 553 RiskNegbin 554 RiskNormal 556 RiskNormalAlt, RiskNormalAltDD 559 RiskPareto. 560 RiskParetoAlt, RiskParetoAltDD. 562 RiskPareto2. 563 RiskPareto2Alt, RiskPareto2AltDD. 565 RiskPearson5. 566 RiskPearson5Alt, RiskPearson5AltDD 568
Risque Pearson 6. 569
RiskPert. 571
RiskPertAlt, RiskPertAltDD 573
Risque Poisson. 574
RisqueRayleigh. 576
RiskRayleighAlt, RiskRayleighAltDD 578
RiskResample 578
RiskSimtable. 579
RiskSplice 580
Risque. 581
Risque Triang. 583
Référence : fonctions de propriété des distributions. 595
RiskCategory. 595
RiskCollect 596
Risque Convergence 597
Risque de choc. 598
RiskDepC 600
RiskFit 602
RiskIndepC 603
Risque est discret. 603
RiskLibrary. 604
RiskLock 604
RiskName 605
RiskSeed 606
RiskShift. 606
Risque Six Sigma. 607
RiskStatic 607
RiskTruncate 608
RiskTruncateP 608
RiskUnits 609
Référence : fonctions de sortie 611
Risque Output. 612
Référence : fonctions statistiques 613
RiskConvergenceLevel 614
RiskData 615
RiskKurtosis. 615
RiskMax. 616
RiskMean. 616
RiskMin 616
RiskMode. 617
RiskPercentile, RiskPtoX, RiskPercentileD, RiskQtoX. 617
RiskRange. 617
Référence : fonctions six sigma 625
RiskCp 626
RiskCpm 626
RiskCpk 627
RiskCpkLower 628
RiskCpkUpper 628
RiskDPM 629
RiskK 629
RiskLowerXBound 630
RiskPNC. 630
Risque PNCLower 631
RiskPNCUpper 631
Risque PPM Inférieur 632
RiskPPMUpper 632
RiskSignalLevel 633
RiskUpperXBound 634
RiskYV 634
RiskZlower 635
RiskZMin. 636
RiskZUpper 636
Référence : fonctions supplémentaires 637
Risque de correction mat. 637
RisqueIterCourante 637
Risque courant sim. 638
RiskStopRun 638
Référence : Fonction graphique 639
Référence : Bibliothèque @RISK 641
Distributions dans la Bibliothèque @RISK 643
Résultats dans la Bibliothèque @RISK 649
Référence : Kit de développement @RISK pour Excel (XDK) 659
Ce chapitre décrit les icônes, commandes, fonctions de distribution de probabilités et macros servant à définir et exécuter une analyse de risque à l'aide de @RISK. Le chapitre Guide de référence @RISK s'organise en six sections :
1) Référence : Icônes @RISK 2) Référence : Commandes du menu @RISK 3) Référence : Graphiques @RISK 4) Référence : Ajustement de distribution @RISK 5) Référence : Bibliothèque @RISK 6) Référence : Kit de développement @RISK (XDK)
Les icônes @RISK permettent d'exécuter rapidement et facilement les tâches nécessaires à la configuration et à l'exécution des analyses de risque. Elles figurent sur la « barre d'outils » du tableau (sous forme de barre d'outils personnalisée dans Excel ou de ruban personnalisé dans Excel 2007) et dans les fenêtres graphiques ouvertes. Cette section décrit brièvement chaque icône, en expliquant les fonctions qu'elles exécutent et leurs commandes de menu équivalentes.
Remarque: Le compagnon @RISK d'Excel 2003 et versions antérieures propose deux barres d'outils : la barre principale et une barre de paramètres pour la spécification des paramètres de simulation.
Ruban @RISK (Excel 2007)
| Icône | Fonction et emplacement |
| Définir les distributions | Ajouter ou modifier des distributions de probabilités dans la formule de la cellule courante. Emplacement : Groupe Modèle, Définir les distributions |
| Ajouter une sortie | Ajouter la cellule (ou plage de cellules) sélectionnée comme sortie de simulation. Emplacement : Groupe Modèle, Ajouter une sortie |
| Insert Function | Insérer une fonction @RISK dans la formule de la cellule active. Emplacement : Groupe Modèle, Insérer une fonction |
| Définir les correlations | Définir les correlations entre les distributions de probabilités. Emplacement : Groupe Modèle, Définir les correlations |
| Ajuster les distributions | Ajuster les distributions aux données. Emplacement : Groupe Modèle, Ajustement de distributions |
| Distribution Artist | Tracer des courbes de distribution Emplacement : Groupe Modèle, Distribution Artist |
| Fenêtre Modèle | Afficher dans la fenêtre @RISK Modèle la ou les cellules de sortie courantes ainsi que toutes les fonctions de distribution entrées dans la feuille de calcul. Emplacement : Groupe Modèle, fenêtre Modèle |
| Itérations 10000 | Définir le nombre d'iterations à exécuter. Emplacement : Groupe Simulation, Itérations |
| Simulations 1 | Définir le nombre de simulations à exécuter. Emplacement : Groupe Simulation, Simulations |
| Afficher ou modifier les paramètres de simulation (name d'iterations, nombre de simulations, type d'échantillonnage, méthode de recalcul standard, macros exécutées, etc.) Emplacement : Groupe Simulation, Paramètres de simulation | |
| Définir le type de valeurs (aléatoires ou statiques) renvoyées par les fonctions de distribution @RISK lors d'un recalcul Excel standard. Emplacement : Groupe Simulation, Aléatoire/Statique | |
| Sélectionner l'affichage automatique du graphique de sortie pendant ou après la simulation. Emplacement : Groupe Simulation, Affichage automatique du graphique de sortie | |
| Sélectionner l'affichage de la fenêtre Synthese des résultats pendant ou après la simulation. Emplacement : Groupe Simulation, Affichage automatique de la fenêtre Synthese des résultats | |
| Activer ou désactiver le mode Démo. Emplacement : Groupe Simulation, Mode Démo | |
| S | Activer ou désactiver l'actualisation des fenêtres @RISK ouvertes pendant la simulation. Emplacement: Groupe Simulation, Actualisation en direct |
| Démarrer la simulation | Simuler la ou les feuilles de calcul courantes. Emplacement: Groupe Simulation, Demarrer la simulation |
| Analyses avancées | Exécuter une analyse avancée. Emplacement: Groupe Simulation, Analyses avancées |
| Exécuter une recherche Valeur cible @RISK. Emplacement: Groupe Simulation, Analyses avancées, Valeur cible | |
| Exécute une analyse de contrainte. Emplacement: Groupe Simulation, Analyses avancées, Analyse de contrainte | |
| Afficher une analyse de sensibilité avancée. Emplacement: Groupe Simulation, Analyses avancées, Analyse de sensibilité avancée | |
| Parcours des résultats | Parcourir les résultats sur la ou les feuilles de calcul courantes. Emplacement: Groupe Résultats, Parcours des résultats |
| Synthèse | Afficher la fenêtre Synthese des résultats. Emplacement: Groupe Résultats, fenêtre Synthese |
| Définir les filtres | Définir les filtres. Emplacement: Groupe Résultats, Définir les filtres |
| Afficher la fenêtre des statistiques détaillées. Emplacement: Groupe Résultats, Statistiques détaillées | |
| Xi | Afficher la fenêtre des données. Emplacement: Groupe Résultats, Données de simulation |
| Afficher la fenêtre d'analyse de sensibilité. Emplacement : Groupe Résultats, Sensibilités | |
| % | Afficher la fenêtre d'analyse de scenario. Emplacement : Groupe Résultats, Scénarios de simulation |
| Rapports Excel | Sélectionner les rapports Excel à exécuter. Emplacement : Groupe Outils, Rapports Excel |
| Permuter les fonctions | Activer ou désactiver les fonctions @RISK par permutation dans les classeurs ouverts. Emplacement : Groupe Outils, Permuter les fonctions |
| Bibliothèque | Afficher la Bibliothèque @RISK ou y ajouter les résultats. Emplacement : Groupe Outils, Bibliothèque |
| Utilitaires | Ouvrir les paramètres d'application,:gérer les fenètres, ouvrir un fichier de simulation, supprimer les données @RISK, décharger le compagnon @RISK. Emplacement : Groupe Outils, Utilitaires |
| Aide | Afficher l'aide @RISK. Emplacement : Groupe Outils, Aide |
Barre d'outils principale @RISK (excel 2003 et versions antérieures)
Les icônes décrites ci-dessous figurent sur la barre d'outils @RISK installée dans Excel.
| Icône | Fonction et commande équivalente |
| Ajouter ou modifier des distributions de probabilités dans la formule de la cellule courante. Commande équivalente : Modèle, Définir les distributions | |
| Ajouter la cellule (ou plage de cellules) sélectionnée comme sortie de simulation. Commande équivalente : Modèle, Ajouter une sortie | |
| fx | Insérer une fonction @RISK dans la formule de la cellule active. Commande équivalente : Modèle, Insérer une fonction |
| Définir les correlations entre les distributions de probabilités. Commande équivalente : Modèle, Définir les correlations | |
| Ajuster les distributions aux données. Commande équivalente : Modèle, Ajuster les distributions aux données | |
| Tracer des courbes de distribution Commande équivalente : Modèle, Distribution Artist | |
| Afficher dans la fenêtre @RISK Modèle la ou les cellules de sortie courantes ainsi que toutes les fonctions de distribution entrées dans la feuille de calcul. Commande équivalente : Modèle, Fenêtre Modèle | |
| Simuler la ou les feuilles de calcul courantes. Commande équivalente : Simulation, Démarrer la simulation | |
| Exécuter une analyse avancée. Commande équivalente : Simulation, Analyses avancées | |
| Parcourir les résultats sur la ou les feuilles de calcul courantes. Commande équivalente : Simulation, Parcours des résultats | |
| Afficher la fenêtre Synthèse de résultats. Commande équivalente : Résultats, Fenêtre Synthèse des résultats | |
| Filtrer les résultats. Commande équivalente : Résultats, Définir les filtrés | |
| Afficher la fenêtre des statistiques détaillées. Commande équivalente : Résultats, Statistiques détaillées | |
| X1 | Afficher la fenêtre des données. Commande équivalente : Résultats, Données |
| Afficher la fenêtre d'analyse de sensibilité. Commande équivalente : Résultats, Sensibilité | |
| Afficher la fenêtre d'analyse de scenario. Commande équivalente : Résultats, Scénarios | |
| Afficher les options de rapport. Commande équivalente : Résultats, Rapports Excel | |
| Permuter les fonctions. Commande équivalente : Permuter les fonctions @RISK | |
| Afficher la Bibliothèque @RISK. Commande équivalente : Bibliothèque, Afficher la Bibliothèque @RISK | |
| Afficher les utilisaires @RISK. Commande équivalente : Utilitaires | |
| Afficher l'aide @RISK. Commande équivalente : Aide |
Barre de paramètres @RISK (excel 2003 et versions antérieures)
Les icônes décrites ci-dessous figurent sur la barre de paramètres @RISK installée dans Excel.
| Icône | Fonction et commande équivalente |
| Afficher ou modifier les paramètres de simulation ( nombre d'iterations, nombre de simulations, type d'échantillonnage, méthode de recalcul standard, macros exécutées, etc.)Commande équivalente : Simulation, Paramètres | |
| Iterations 100 | Définir le nombre d'iterations à exécuter.Commande équivalente : Paramètres, Paramètres de simulation, Nombres d'iterations |
| Simulations 1 | Définir le nombre de simulations à exécuter.Commande équivalente : Paramètres, Paramètres de simulation, Nombres de simulations |
| Définir le type de valeurs (aléatoires ou statiques) renvoyées par les fonctions de distribution @RISK lors d'un recalcul Excel standard.Commande équivalente : Paramètres, Recalcul standard aléatoire(F9) | |
| Sélectionner le parcours des résultats dans le tableau en fin de simulation et l'affichage automatique d'un graphique de sortie pendant la simulation.Commande équivalente : Paramètres, Affichage automatique du graphique de sortie | |
| Sélectionner l'affichage de la fenêtre @RISK - Synthese des résultats pendant et après la simulation.Commande équivalente : Paramètres, Affichage automatique de la fenêtre Synthese des résultats | |
| Activer ou désactiver le mode Démo.Commande équivalente : Paramètres, Mode Démo | |
| Activer ou désactiver l'actualisation des fenêtres @RISK ouvertes pendant la simulation.Commande équivalente : Paramètres, Actualisation en direct | |
Icônes des fenêtres graphiques
Les icônes décrites ci-dessous figurent au bas des fenêtres graphiques @RISK ouvertes. Selon le type de graphique affiché, toutes les icônes ne sont pas nécessairement affichées.
| Icône | Fonction et commande équivalente |
| Afficher la boîte de dialogue Options graphiques. Commande équivalente : Options graphiques | |
| Copier le résultat affché ou en faire le rapport. Commande équivalente : Rapports | |
| Afficher et définir le type de graphique de distribution affché. Commande équivalente : Options graphiques, Type | |
| Afficher et définir le type de graphique tornado affché. Commande équivalente : Options graphiques, Type | |
| Ajouter un graphique superposé au graphique affché. Commande équivalente : Aucune | |
| Créer un diagramme de dispersion à l'aide des données du graphique affché. Commande équivalente : Aucune | |
| Afficher un graphique tornado de scenario ou modifier les scénarios. Commande équivalente : Aucune | |
| Créer un graphique de synthèse à l'aide des données du graphique affché. Commande équivalente : Aucune | |
| Ajouter une variable au diagramme de dispersion ou graphique de synthèse. Commande équivalente : Aucune | |
| Sélectionner un graphique sur la base d'un numéro de simulation en présence de simulations multiples. Commande équivalente : Aucune | |
| Définir un filtré pour le résultat affché. Commande équivalente : Résultats, Définir les filtrés | |
| Ajuster les distributions à un résultat simulé. Commande équivalente : Aucune | |
| Zoom avant sur une région d'un graphique. Commande équivalente : Aucune | |
| Ramener le zoom à l'échelle par défaut. Commande équivalente : Aucune | |
| Attacher un graphique flottant à la cellule à laquelle il se rapporte. Commande équivalente : Aucune |
Référence : commandes @RISK
Cette section du Guide de référence @RISK décrit les commandes @RISK accessibles à travers le ruban @RISK dans Excel 2007 ou les barres d'outils et le menu @RISK dans Excel 2003 et versions antérieures.
Un menu @RISK s'ajoute aux versions Excel 2003 et antérieures. Dans Excel 2007, le ruban @RISK donne accès à toutes les commandes du compagnon @RISK.
Plusieurs commandes @RISK sont également disponibles dans un menu contextuel flottant invoqué par clic du bouton droit de la souris sur une cellule d'Excel.
Commande définir les distributions
Définit ou modifie les distributions de probabilités entrées dans la formule de la cellule courante.
La commande Définir les distributions ouvre la fenêtre de définition. À travers cette fenêtre, vous pouvez affecter des distributions de probabilités aux valeurs contenues dans la formule de la cellule sélectionnée. Vous pouvez aussi modifier les distributions déjà générées dans cette formule.
La fenêtre @RISK Définir une distribution représente graphiquement les distributions de probabilités substituables aux valeurs de la formule de la cellule courante. Chaque distribution affichée décrit la plage de valeurs possibles d'une entrée incertaine du modèle. Les statistiques affichées indiquent également la manière dont la distribution définit une entrée incertaine.
L'affichage graphique d'une entrée incertaine est utile à la présentation de votre définition du risque à vos collègues et autres interlocuteurs. Le graphique présente clairement la plage des valeurs possibles d'une entrée et la probabilité relative de chaque valeur comprise dans la plage. Grâce aux graphiques de distribution, vous pouvez aisément incorporer d'autres évaluations individuelles de l'incertitude dans vos modèles d'analyse du risque.
Définir une distribution, fenêtre
Cette fenêtre s'ouvre d'un clic sur l'icône Définir les distributions. À chaque clic sur une cellule différente du tableau, la fenêtre s'actualise et reflète la formule de la cellule sélectionnée. Pour déplacer la fenêtre d'une cellule assortie de distributions à l'autre dans les classeurs ouverts, appuyez simplement sur la touche.
Tous les changements apportés s'ajoutent directement à la formule de la cellule quand (1) vous cliquez sur une autre cellule pour en refléter la formule dans la fenêtre de définition ou (2) vous cliquez sur OK pour fermer la fenêtre.
La fenêtre Définir une distribution présente une courbe primaire — celle de la fonction entrée dans la formule de la cellule — et admet jusqu'à 10 courbes superposées, représentant les autres distributions que vous choisissez de représenter graphiquement par-dessus la courbe primaire. Les courbes superposées s'ajoutent en cliquant sur l'icône Superposer au bas de la fenêtre.
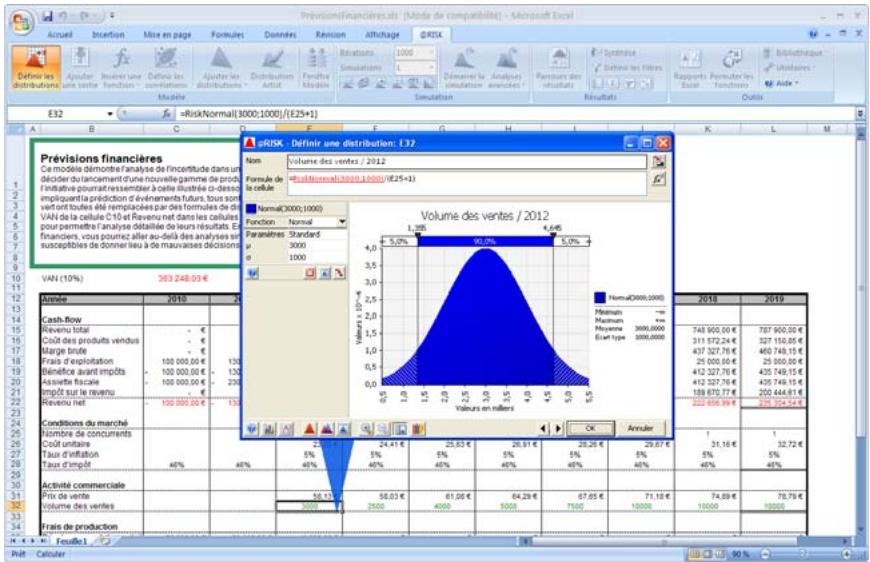

La fenêtre Définir une distribution se compose des éléments décrits ci-dessous.
- Nom. Affiche le nom par défaut que @RISK a identifié pour la cellule. En cliquant sur l'icône Entrée de référence (proposée en regard du nom), vous pouvez sélectionner une autre cellule Excel, dont vous désirez utiliser le nom. Rien ne vous empêche non plus de taper directement le nom désiré.
- Formule. Affiche la formule courante de la cellule, y compris ses fonctions de distribution @RISK. Vous pouvez modifier cette formule ici tout aussi bien que dans Excel. Le texte souligné et affiché en rouge correspond à la distribution représentée graphiquement.
- Sélectionner la distribution. Ajoute la distribution sélectionnée dans la palette. Raccourci : Plutôt que de cliquer sur le bouton Sélectionner la distribution, cliquez deux fois, dans la palette, sur la distribution à utiliser.
- Créer Favorite. Ajoute la distribution sélectionnée sur la palette des distributions à l'onglet Favorites.
- Barre de séparation. Pour agrandir ou réduire la zone réservée à la Formule, déplacez vers le haut ou vers le bas la barre de séparation entre la zone Formule et le graphique. Pour agrandir le volet des arguments, déplacez de gauche à droite la barre de séparation entre le volet et le graphique.
Les délimiteurs et les statistiques régissant l'affichage des statistiques fondamentales des graphiques de distribution affichés :
- Delimitsurs. Les délimiteurs permettent la définition des probabilités cibles et le réglage d'échelle de l'axe x au moyen de la souris. Les probabilités cumulatives peuvent être définies directement sur un graphique de distribution à l'aide des délimiteurs de probabilités affichés. Le glissement des délimiteurs de probabilités fait varier les valeurs x et p gauches et droites affichées sur la barre des probabilités, audressus du graphique. Le glissement des délimiteurs d'extrémité de l'axe x fait varier l'échelle de l'axe.
- ont sélectionnées sous l'onglet Légende de la boîte de dialogue Options graphiques. Pour l'ouvrir, cliquez sur l'icône Options graphiques, dans le coin inférieur gauche de la fenêtre.
Palette des distributions
Pour affecter une distribution à une valeur spécifique de la formule, cliquez simplement sur cette valeur (elle s'affiche en bleu), puis cliquez deux fois sur la distribution de votre choix dans la palette proposée.
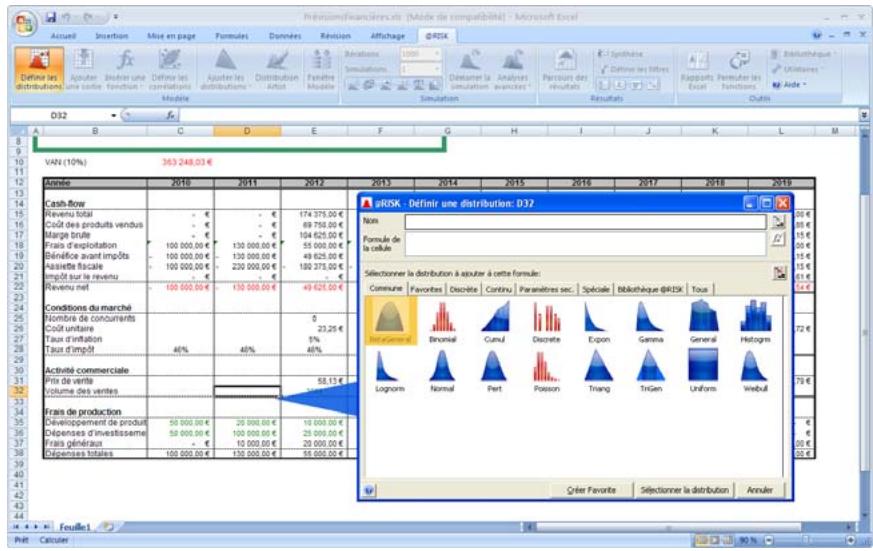
Changer la distribution au moyen de la palette
Pour changer la distribution utilisée dans la formule, cliquez sur le bouton Remplacer une distribution dans la formule, au bas de la fenêtre, ou cliquez deux fois sur la nouvelle distribution voulue de la palette.
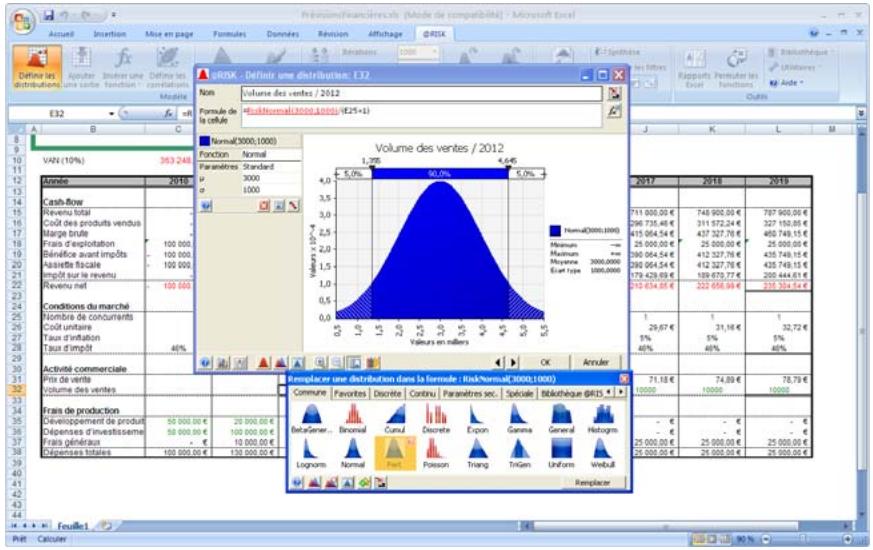
La version réduite de la palette propose d'autres icônes, au bas de la fenêtre, qui permettent de supprimer toutes les superpositions, de faire figurer les distributions préférées sous l'onglet Favorites ou de sélectionner une distribution à utiliser depuis une cellule d'Excel.
Ajout de superpositions au moyen de la palette
Volet des arguments de distribution
Pour ajouter des courbes superposées au graphique de la distribution affichée, cliquez sur le bouton Superposer au bas de la fenêtre.
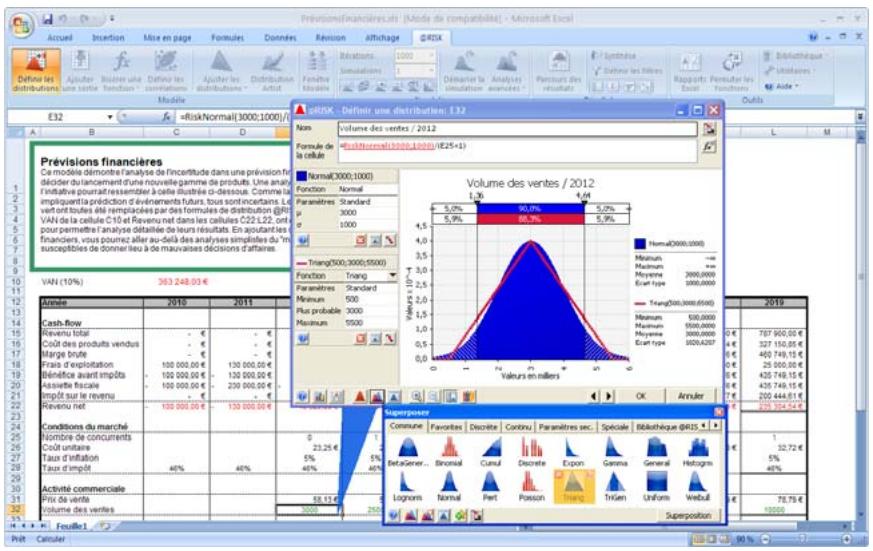
Les valeurs d'argument se saisissent dans le volet d'arguments ou, directement, dans la formule affichée. Ce volet s'affiche à gauche du graphique. Ses boutons fléchés permettent de changer rapidement la valeur d'un paramètre. En présence de graphiques superposés, le volet des arguments permet de passer facilement de la courbe primaire à l'une quelconque des courbes superposées.
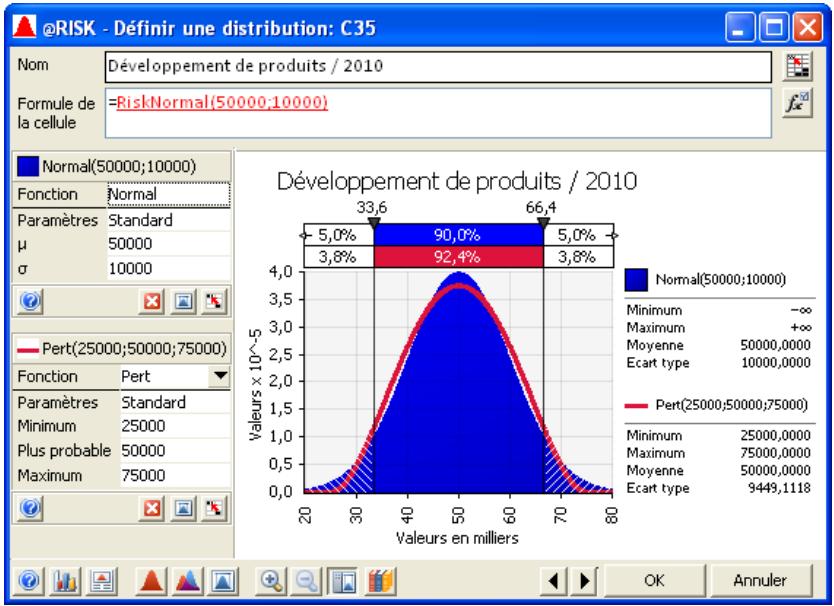
Options du volet des arguments de distribution :
- Fonction. Cette entrée sélectionne le type de distribution affichée dans le volet graphique. Cette sélection peut aussi se faire dans la palette des distributions.
Paramètres. Cette entrée sélectionne le type d'arguments à utiliser pour la distribution. Il peut s'agir de Limites de troncation, Facteur de décalage, Formatage de date et, dans de nombreux cas, de Paramètres secondaires. Vous pouvez aussi désirer d'afficher une entrée pour la valeur statique à renvoyer pour la distribution.
- La sélection de Limites de troncation introduit une entrée Minimum et Maximum dans le volet des arguments. La distribution peut ainsi être tronquée aux valeurs indiquées.
- La sélection de Facteur de décalage introduit une entrée de Décalage dans le volet des arguments. Ce facteur décale le domaine de la distribution dans laquelle il est utilisé de la valeur décalage indiquée.
- La sélection de Paramètres secondaires permet l'entrée de paramètres secondaires pour la distribution.
- La sélection de Valeur statique permet l'entrée de la valeur statique de la distribution.
- La sélection de Formatage de date commande l'affichage de dates dans le volet des arguments et celui de graphiques et statistiques au format date. Cette sélection introduit aussi la fonction de propriété RiskIsDate dans la distribution.
Remarque: Dans la boîte de dialogue Paramètres d'application, vous pouvez configurer l'affichage par défaut des Limites de troncation, Facteur de décalage et Valeur statique dans le volet des arguments.
Les paramètres secondaires permettent de désigner les valeurs de centiles particuliers d'une distribution en entrée, par opposition aux arguments traditionnels de la distribution. Les centiles se désignent sous les options Paramètres secondaires de distribution affichées après sélection de Paramètres secondaires.
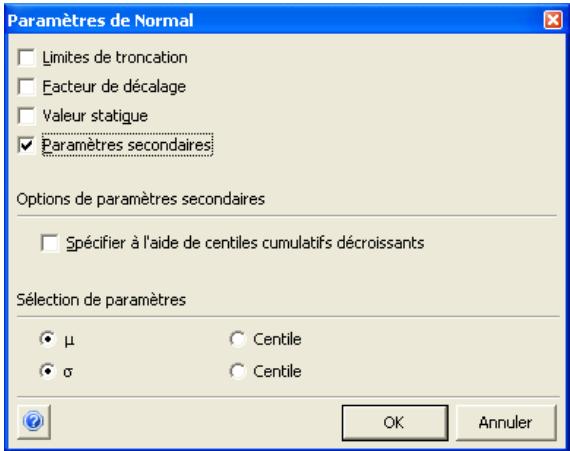
Les paramètres secondaires vous donnent l'option de
- Spécifier en centiles cumulatifs décroissants pour que les centiles utilisés comme paramètres secondaires le soient en termes de probabilités cumulatives décroissantes. Les centiles définis dans cette case spécifique la probabilité d'une valeur supérieure à la valeur d'argument x entrée.
Lors de la sélection des paramètres, les centiles peuvent être combinés avec les paramètres standard par sélection des cases d'options appropriées.
Valeurs par défaut des distributions à paramètres secondaires
Dans la boîte de dialogue Paramètres d'application, vous pouvez sélectionner les paramètres par défaut à utiliser pour les distributions à paramètres secondaires, ou les types de distribution qui finissent en ALT (RiskNormalAlt, etc.). Vos paramètres par défaut s'appliqueront à chaque sélection d'une distribution à paramètres secondaires dans la palette.
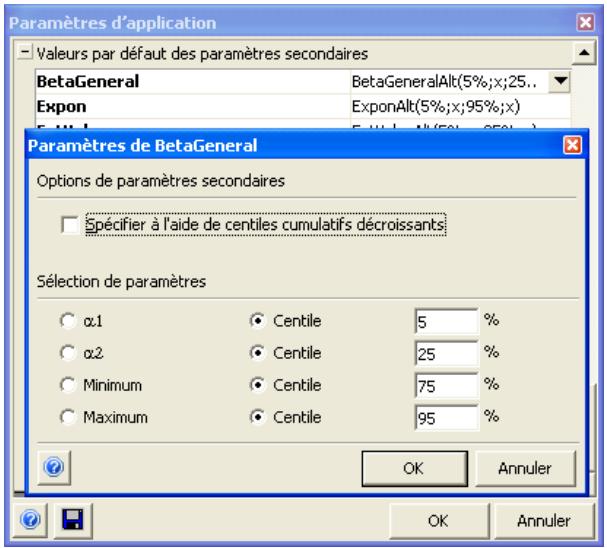
Icônes du volet des arguments de distribution
Les icônes proposées dans le volet des arguments permettent de supprimer les courbes, d'afficher la palette de distributions et d'admettre les références de cellule Excel comme valeurs d'argument.
Les icônes suivantes sont proposées :
Supprime la courbe dont les arguments sont affichés dans la région sélectionnée du volet d'arguments. Affiche la palette des distributions pour sélection d'un nouveau type de distribution pour la courbe sélectionnée. K Affiche le volet des arguments de distribution de façon à permettre la sélection de références de cellule Excel comme valeurs d'argument. Dans ce mode, il suffit de cliquer sur les cellules Excel contenant les valeurs d'argument à utiliser. En fin d'opération, cliquez sur l'icône Rejeter l'entrée de référence (en haut de la fenêtre).
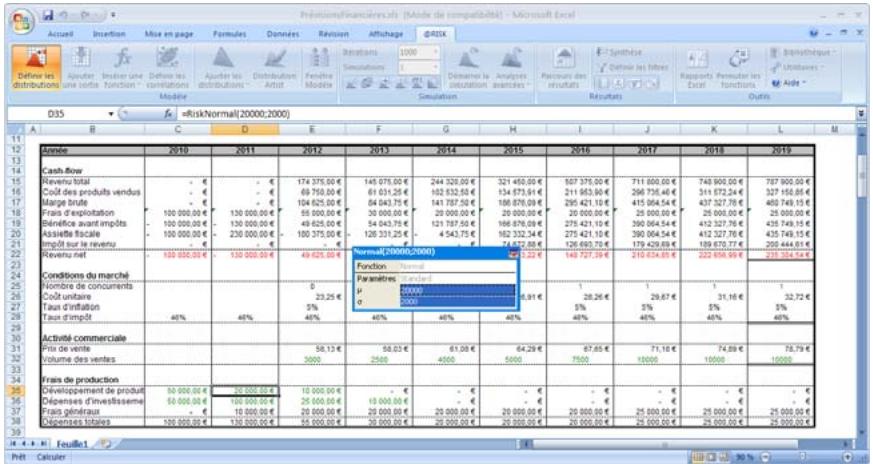
Le volet des arguments peut être masqué. Au bas de la fenêtre, le cinquième bouton, en partant de la gauche, sert à masquer ou afficher le volet des arguments, comme illustré ci-dessous:

Changement de type de graphique
La fenêtre Définir une distribution (comme les autres fenêtres graphiques) permet de changer le type de graphique affiché en cliquant sur l'icône Type de graphique proposée dans le coin inférieur gauche.
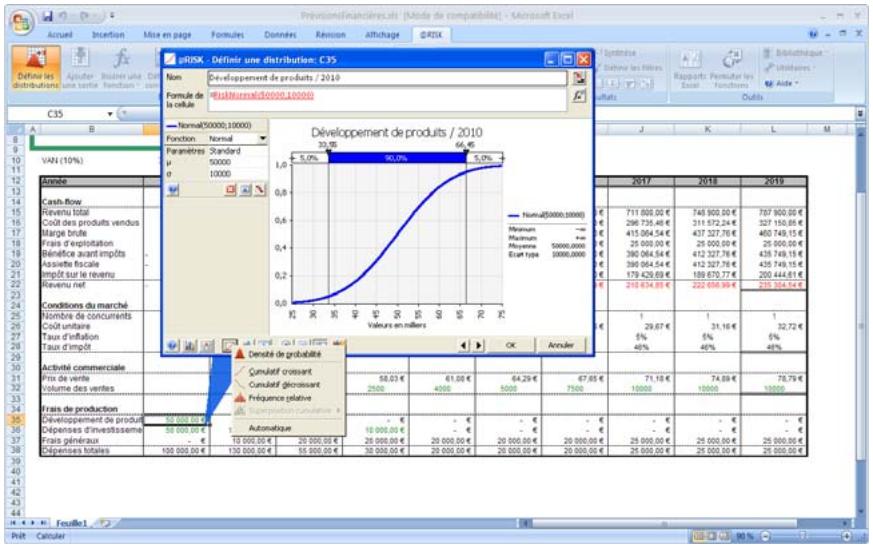
Propriétés d'entrée
Certains arguments des fonctions de distribution @RISK sont obligatoires ; d'autres ne sont que facultatifs. Les seuils arguments obligatoires sont les valeurs numériques qui définissent essentiellement la forme et l'étendue de la distribution. Tous les autres arguments (nom, troncation, corrélation, etc.) sont facultatifs. Ces arguments facultatifs se définissent essentiellement à l'aide des fonctions de propriété, dans la fenêtre contextuelle Propriétés d'entrée.
L'icône fx, à l'extrémité de la zone de texte Formule, donne accès à cette fenêtre.
Beaucoup des propriétés peuvent s'exprimer par référence aux cellules Excel. Il suffit, pour ajouter une référence de cellule, de cliquer sur l'icône Entrée de référence en regard de la propriété.
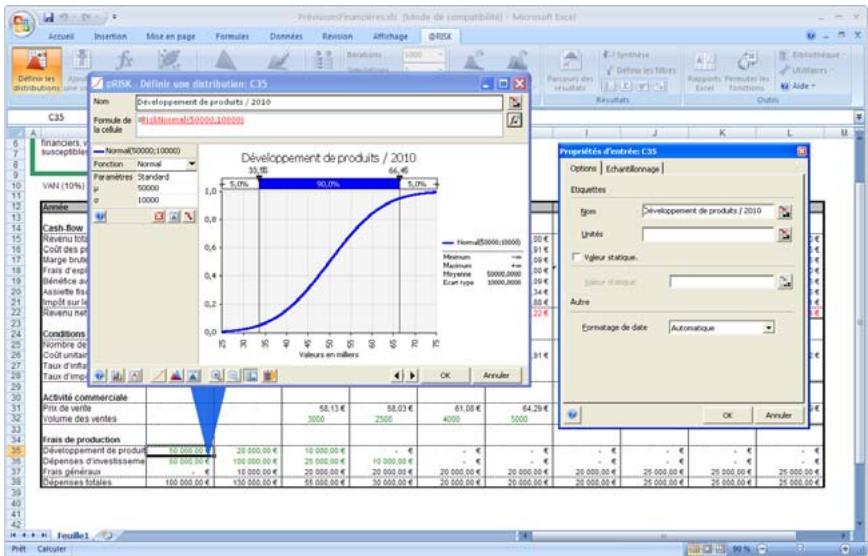
L'onglet Options de la fenêtre Propriétés d'entrée permet de définir les propriétés de distribution suivantes :
- Nom. Nom par lequel @RISK désignera la distribution en entrée dans les rapports et les graphiques. Le nom déterminé par @RISK en fonction des titres de ligne et de colonne est proposé par défaut. Si ce nom par défaut est modifié, la fonction de propriété Name s'ajoute à la fonction de distribution entrée pour conserver le nom défini.
- Unités. Unités que @RISK utiliserait sur l'axe x des graphiques. Si cette zone est validée, la fonction de propriété RiskUnits s'ajoute à la fonction de distribution entrée pour conserver les unités définies.
- Valeur statique. Valeur 1) que la distribution renverra lors des recalculs Excel normaux (non aléatoires) et 2) qui se susbeituera à la distribution en entrée en cas permutation-désactivation des fonctions @RISK. Lorsqu'une nouvelle distribution en entrée est définie dans la fenêtre Définir une distribution, la Valeur statique se règle sur la valeur que la distribution remplace dans la formule. Si aucune valeur statique n'est définie, @RISK utilise la valeur probable, la mediane, le mode ou un centile de la distribution 1) lors des recalculs Excel normaux (non aléatoires) et 2) quand les fonctions @RISK sont désactivées par permutation. Si une valeur statique est entrée, la fonction de propriété RiskStatic s'ajoute à la fonction de distribution entrée pour conserver la valeur définie.
- Formatage de date. Spécifie si les données de l'entrée doivent être traitées en tant que dates dans les rapports re les graphiques et statistiques de l'entrée au format numérique, quel que soit celui de la cellule. Si l'option Activé ou Désactivé est sélectionnée, une fonction de propriété RiskIsDate s'introduit pour représenter le paramètre de date.
L'onglet Échantillonnage de la fenêtre Propriétés d'entrée peut définir les propriétés de distribution suivantes :
- Valeur de départ distincte. Définit, pour cette entrée particulière, la valeur de départ à utiliser pendant la simulation. Le paramétrage d'une valeur de départ propre à une entrée assure que chaque modèle qui utilise la distribution en entrée ait le même flux de valeurs échantillonnées pour l'entrée lors d'une simulation. L'option est utile lorsque plusieurs modèles partagent les distributions en entrée classées dans la Bibliothèque @RISK.
- Verrouiller l'entrée à l'échantillonnage. Empêche l'échantillonnage de l'entrée lors d'une simulation. Une entrée verrouillée renvoie sa valeur statique (si précisé) ou, sinon, sa valeur probable, ou la valeur spécifique à travers les options proposées sous En l'absence de simulation, les distributions renvoient dans la boîte de dialogue Paramètres de simulation.
- Collecte d'échantillons de distribution. Configure la collecte d'échantillons pour l'entrée lorsque l'option Entrées marquées de la propriété Collect est sélectionnée sous l'onglet Échantillonnage de la boîte de dialogue Paramètres de simulation. Si cette option est sélectionnée, seules les entrées marquées de cette propriété sont reprises dans les analyses de sensibilité, les statistiques et les graphiques disponibles après une simulation.
Commande ajouter une sortie
Ajoute une cellule ou plage de cellules comme sortie ou plage de sortie de simulation.
L'icone Ajouter une sortie ajoute la plage de cellules sélectionnée de la feuille de calcul comme sortie de simulation. Une distribution des issues possibles est générée pour chaque cellule de sortie sélectionnée. Ces distributions de probabilités se créent moyennant la collecte des valeurs calculées pour la cellule, à chaque itération d'une simulation.
Un graphique de synthèse peut être généré pour les plages de sortie qui comportent plusieurs cellules. Par exemple, une plage de sortie peut comprendre toutes les cellules d'une ligne de la feuille de calcul. Les distributions de sortie de ces cellules peuvent être récapitulées dans un graphique de synthèse. Il est également possible d'afficher la distribution de probabilités individuelle de chaque cellule comprise dans la plage.
Les résultats des analyses de sensibilité et de scénario sont aussi fournis pour chaque cellule de sortie. Pour plus de détails sur ces analyses, voir les descriptions représentées dans la section de ce chapitre consacrée à la fenêtre Synthèse des résultats.
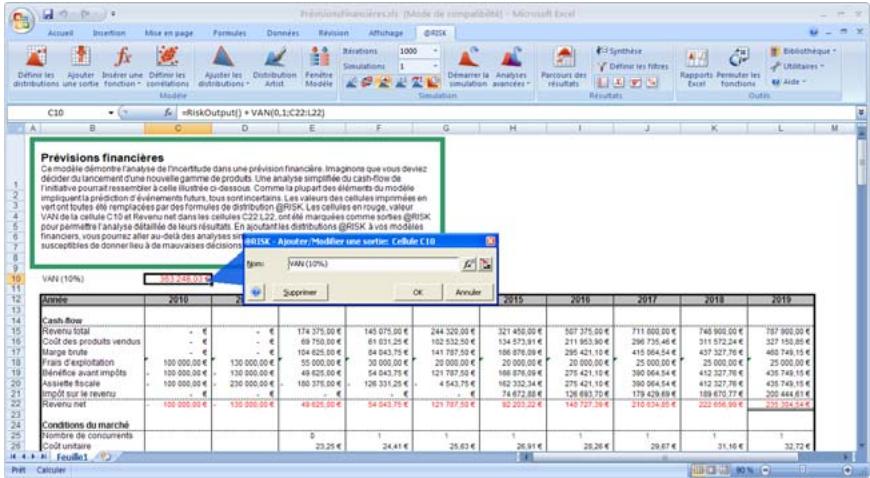
Fonctions RiskOutput
Quand une cellule est ajoutée en tant que sortie de simulation, une fonction RiskOutput s'installe dans la cellule. Ces fonctions permettent de copier, coller et déplacer les cellules de sortie en toute simplicité. Les fonctions RiskOutput peuvent aussi être introduites dans les formules, de la même manière que les fonctions Excel standard, sans passer par la commande Ajouter une sortie. Elles permettent facultativement de nommer les sorties de simulation et d'ajouter des cellules de sortie individuelles aux plages de sortie. Par exemple :
= RISKOUTPUT("Profit") + VAN(0, 1; H1:H10)
Avant d'être sélectionnée comme sortie de simulation, la cellule contenait simplement la formule
= VAN (0, 1; H 1: H 1 0)
La fonction RiskOutput ajoutée fait de la cellule une sortie de simulation intitulée « Profit ». Pour plus de détails sur les fonctions RiskOutput, voir la section Référence : Fonctions @RISK.
Nom de sortie
Lors de l'ajout d'une sortie, l'occasion vous est donnée de nommer cette sortie ou d'utiliser le nom par défaut identifié par @RISK. Vous pouvez entrer une reference à une cellule Excel contenant le nom désiré en cliquant simplement sur cette cellule. Le nom (s'il ne s'agit pas de celui identifié par défaut par @RISK) s'ajoute aux arguments de la fonction RiskOutput utilisée pour identifier la cellule de sortie.
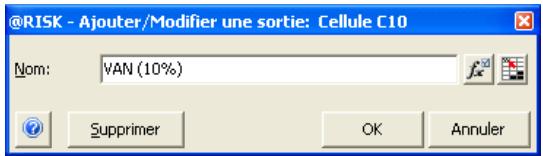
Le nom peut être remplacé à tout moment par 1) modification de l'argument de nom de la fonction RiskOutput, 2) re-sélection de la cellule de sortie et nouveau clic sur l'icône Ajouter une sortie ou 3) remplacement du nom affiché pour la sortie dans la fenêtre Modèle.
Ajout d'une plaque de sortie de simulation
Pour ajouter une nouvelle plage de sortie :
1) Sélectionnez dans la feuille de calcul la plage de cellules à ajouter comme plage de sortie. Si la plage comprend plusieurs cellules, sélectionnez-les toutes par glissement de la souris. 2) Cliquez sur l'icône Ajouter une sortie (simple flèche rouge). 3) Entrez le nom de la plage de sortie, ainsi que les cellules de sortie individuelles de la plage, dans la fenêtre Ajouter une plage de sortie qui s'affiche. Pour définir les propriétés des cellules de sortie individuelles, sélectionnez la sortie voulue dans le tableau et cliquez sur l'icône fx.
Propriétés de sortie
Les sorties @RISK (définies par la fonction RiskOutput) peuvent être assorties d'arguments facultatifs qui en précisent, au besoin, les propriétés (telles que nom et unités). Ces arguments facultatifs se définissent à l'aide des fonctions de propriété, dans la fenêtre contextuelle Propriétés de sortie.
L'icône fx, à l'extrémité de la zone de texte Nom, donne accès à cette fenêtre.
Beaucoup des propriétés peuvent s'exprimer par référence aux cellules Excel. Il suffit, pour ajouter une référence de cellule, de cliquer sur l'icône Entrée de référence en regard de la propriété.
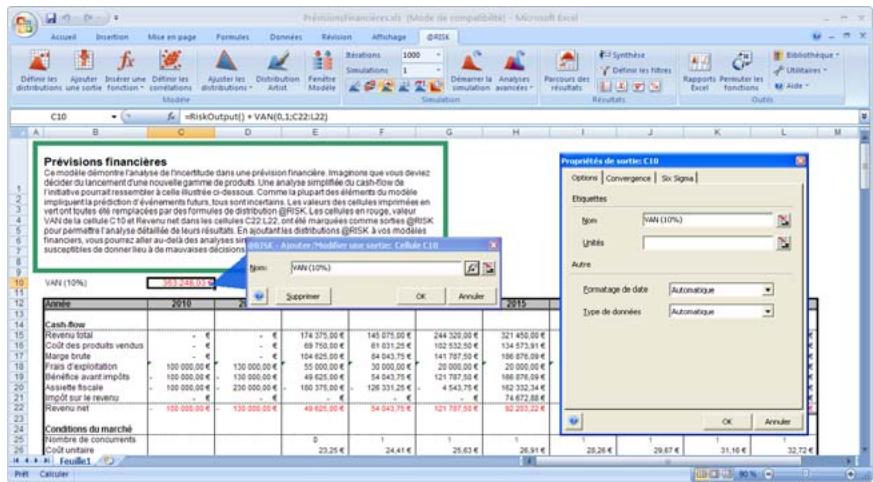
L'onglet Options de la fenêtre Propriétés de sortie permet de définir les propriétés de sortie suivantes :
- Nom. Nom par lequel @RISK désignera la sortie dans les rapports et les graphiques. Le nom déterminé par @RISK en fonction des titres de ligne et de colonne est proposé par défaut.
- Unités. Unités que @RISK utilisera sur l'axe x des graphiques. Si cette zone est validée, la fonction de propriété RiskUnits s'ajoute à la fonction de distribution pour conserver les unités définies.
- ée et produit des graphiques et statistiques conformes à ce type. La sélection de Discrètes force @RISK à toujours produire les graphiques et statistiques de la sortie au format de données discrètes. De même, la sélection de Continues force @RISK à toujours produire les graphiques et statistiques de la sortie au format continu. Si l'option Discrètes est sélectionnée, une fonction de propriété RiskIsDiscrete s'ajoute à la fonction RiskOutput de la sortie.
- Formatage de date. Spécifie si les données de la sortie doivent être traitées en tant que dates dans les rapports et les graphiques. Sous le paramètre Automatique, @RISK détecte re les graphiques et statistiques de la sortie au format numérique, quel que soit celui de la cellule.
Propriétés de sortie - Onglet Convergence
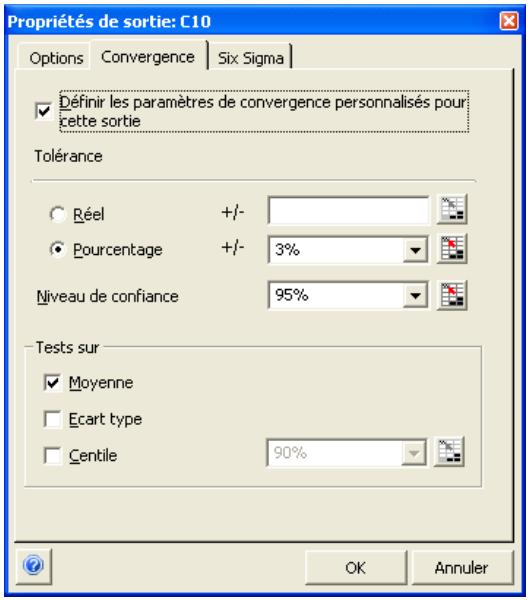
Les paramètres de surveillance de convergence d'une sortie se définissent sous l'onglet Convergence :
- Tolerance. Spécifie la tolérance admise pour la statistique testée. Les paramètres ci-dessus configurent par exemple l'estimation de la moyenne de la sortie simulée dans une marge de 3% de sa valeur réelle.
- Niveau de confiance. Spécifie le niveau de confiance de l'estimation. Par exemple, les paramètres ci-dessus spécifient que l'estimation de la moyenne de la sortie simulée (dans la marge de tolérance définie) doit être exacte 95% du temps.
- Tests sur. Spécifie les statistiques de sortie à tester.
Tous les paramètres de surveillance de la convergence s'inscrivent dans la fonction de propriété RiskConvergence.
Propriétés des sorties — Onglet Six Sigma
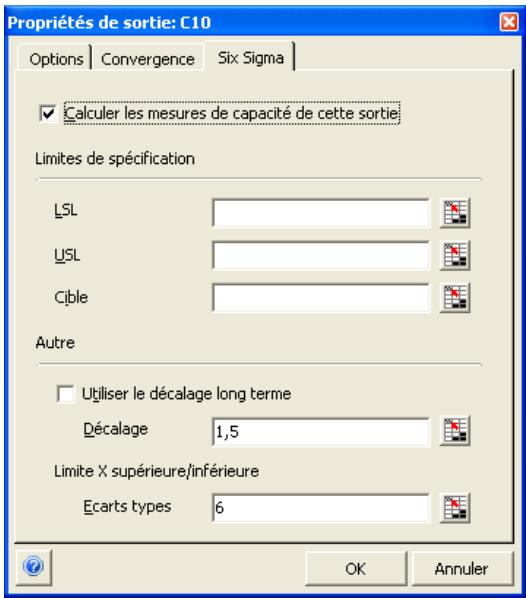
Les paramètres par défaut d'une sortie à utiliser dans les calculs Six Sigma se configurent sous l'onglet Six Sigma. Les propriétés concernées sont les suivantes :
- Calculer les mesures de capacité de cette sortie. Spécifie l'affichage des mesures de capacité dans les rapports et graphiques relatifs à la sortie. Ces mesures reposent sur les valeurs LSI, LSS et Cible entrées. LSI, LSS et Cible. Définit les valeurs LSI (limite de spécifications inférieure), LSS (limite de spécifications supérieure) et Cible de la sortie.
- Décalage long terme et Décalage. Spécifient un décalage facultatif pour le calcul des mesures de capacité à long terme.
- Limite X supérieure/inferieure. Nombre d'écartypes, à droite ou à gauche de la moyenne, pour le calcul des valeurs X supérieure et inférieure.
Les paramètres Six Sigma définis s'inscrivent dans une fonction de propriété RiskSixSigma. Seules les sorties dotées de la fonction de propriété RiskSixSigma affichent les marqueurs et statistiques six sigma dans les graphiques et rapports. Les fonctions statistiques six sigma @RISK des feuilles de calcul Excel peuvent faire référence à n'importe quelle cellule de sortie porteuse d'une fonction de propriété RiskSixSigma.
Remarque : Tous les graphiques et rapports @RISK utilisent les valeurs LSI, LSS et cible des fonctions de propriété RiskSixSigma en place au moment du démarrage d'une simulation. Si vous changez les limites de spécification d'une sortie (et sa fonction de propriété RiskSixSigma associée), veillez à réexécuter la simulation pour en afficher l'effet sur les graphiques et rapports.
Commande insérer une fonction
Insère une fonction @RISK dans la cellule active.
@RISK propose une série de fonctions personnalisées à utiliser dans les formules Excel pour définir des distributions de probabilités, renvoyer des statistiques de simulation au tableau et exécuter d'autres tâches de modélisation. La commande Insérer une fonction de @RISK permet d'insérer rapidement une fonction @RISK dans un modèle du tableau. Vous pouvez aussi configurer une liste de vos fonctions favorites, pour les rendre aisément accessibles. La commande Insérer une fonction ouvre la fenêtre d'arguments de fonction Excel, pour la saisie des arguments de la fonction.
Si vous choisissez la commande @RISK Insérer une fonction pour entrer une fonction de distribution, un graphique de la fonction peut aussi être affiché. Comme dans le cas de la fenêtre Définir une distribution, vous pouvez superposer différentes courbes sur ce graphique, ajouter des fonctions de propriété d'entrée ou même changer le type de la fonction de distribution entrée.
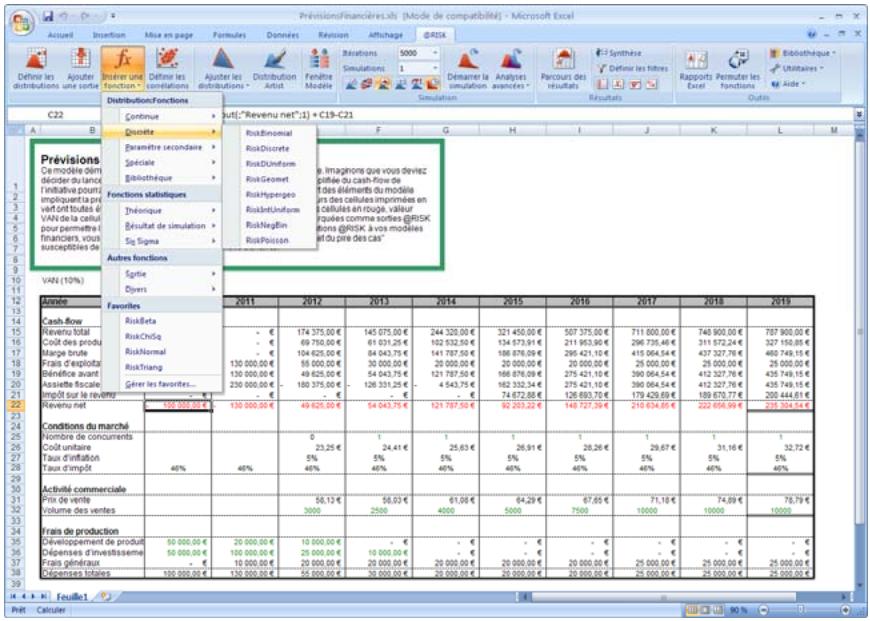
Catégories disponibles de fonctions @RISK
La commande Insérer une fonction gère les trois catégories suivantes de fonctions @RISK :
- Fonctions de distribution, telles que RiskNormal, RiskLognorm et RiskTriang
- Fonctions statistiques, telles que RiskMean, RiskTheoMode et RiskPNC
- Autres fonctions, telles que RiskOutput, RiskResultsGraph et RiskConvergenceLevel
Pour plus de détails sur ces fonctions, voir la section Récurrence : Fonctions @RISK de ce manuel.
Gérer les favorites
Les fonctions @RISK que vous sélectionnez se classent dans la liste des Favorites, rapidement accessibles sous le menu Insérer une fonction ou sous l'onglet Favorites de la palette de distributions. La commande Gérer les favorites affiche la liste de toutes les fonctions @RISK disponibles pour vous permettre d'y sélectionner celles que vous utilisez fréquemment.
Insérer une fonction et graphiques des fonctions de distribution
Si vous choisissez la commande @RISK Insérer une fonction pour entrer une fonction de distribution, un graphique de la fonction peut aussi être affiché. Ce graphique s'affiche aussi à chaque entrée ou modification d'une distribution @RISK à travers la boîte de dialogue Arguments de fonction Excel - en réponse à un clic sur le petit symbole Fx en regard de la barre de formule Excel, par exemple, ou à la commande d'insertion de fonction Excel.
Pour éviter l'affichage graphique des fonctions de distribution @RISK aux côtés de la boîte de dialogue d'arguments de fonction Excel, désactiver l'option Fenêtre graphique 'Insérer une fonction' dans les Paramètres d'application (menu Utilitaires).
Remarque : Les graphiques des fonctions RiskCompound ne s'affichent pas dans la fenêtre graphique d'insertion de fonction. Ouvrez la fenêtre Définir une distribution pour prévisualiser ces fonctions.
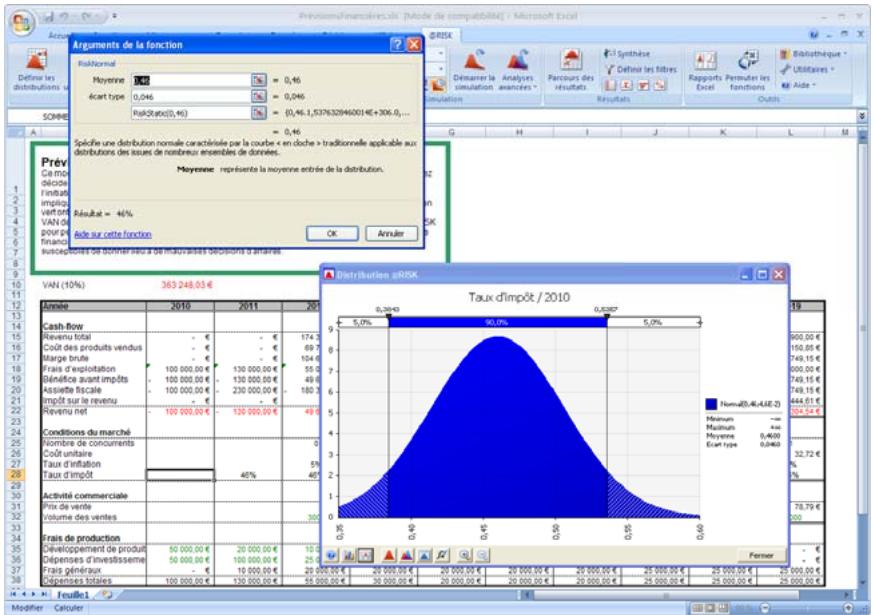
Boutons de la fenêtre graphique insérer une fonction
Les boutons, au bas de la fenêtre graphique Insérer une fonction, permettent les opérations suivantes :
- Accès à la boîte de dialogue Options graphiques pour changer l'échelle, les titres, les couleurs, les marqueurs et autres paramètres du graphique.
- Création d'une représentation Excel du graphique.
- Changement du type du graphique affiché (cumulatif, fréquence relative, etc.)
- Ajout de courbes superposées au graphique.
- Ajout de propriétés (fonctions de propriété de distribution telles que RiskTruncate) à la fonction de distribution entrée.
- Changement du type de fonction de distribution représenté.
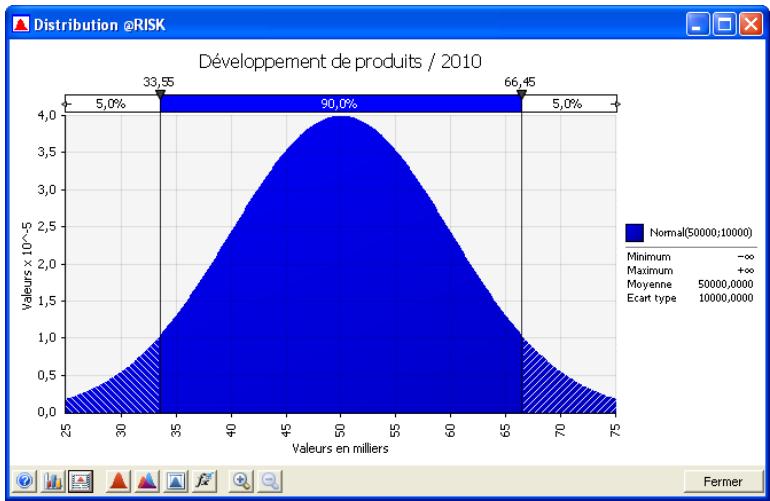
Superposition dans la fenêtre graphique Insérer une fonction
Pour ajouter une courbe superposée à un graphique Insérer une fonction, cliquez sur le bouton Superposer au bas de la fenêtre et sélectionnez la distribution à superposer dans la palette. Une fois la courbe ajoutée, vous pouvez changer les valeurs d'argument de la fonction dans le volet des arguments. Ce volet s'affiche à gauche du graphique. Ses boutons fléchés permettent de changer rapidement la valeur d'un paramètre. Pour plus de détails sur le volet d'arguments des distributions, voir la section de ce chapitre consacrée à la commande Définir une distribution.
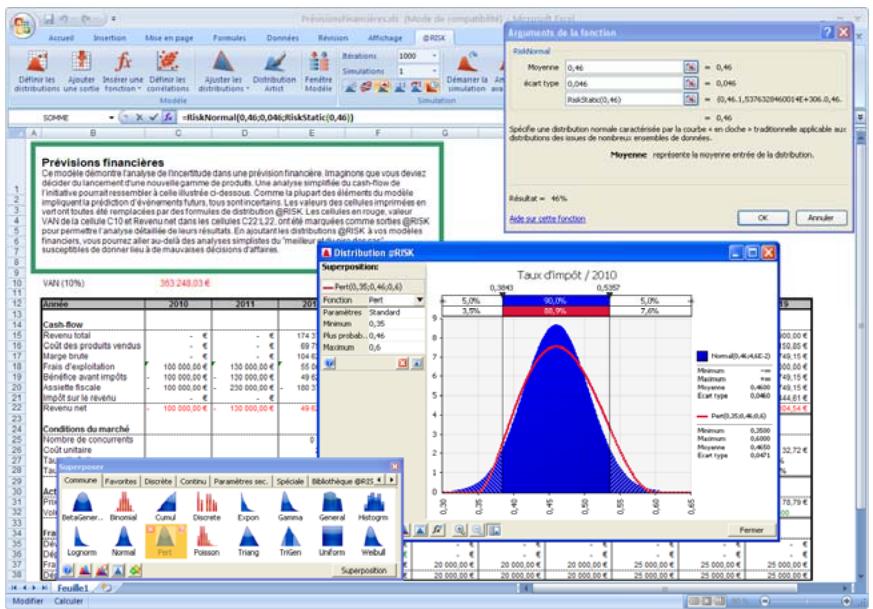
Changer la distribution dans la fenêtre graphique Insérer une fonction
Pour changer la distribution utilisée dans la formule depuis la fenêtre graphique Insérer une fonction, cliquez sur le bouton Palette au bas de la fenêtre et sélectionnez ou cliquez deux fois sur la nouvelle distribution voulue de la palette. La nouvelle distribution sélectionnée et ses arguments s'inscrivent sur la barre de formule Excel et une représentation graphique de la nouvelle fonction apparait.
Propriétés d'entrée dans la fenêtre graphique insérer une fonction
Pour ajouter des propriétés d'entrée dans la fenêtre graphique Insérer une fonction, cliquez sur le bouton Propriétés d'entrée au bas de la fenêtre et sélectionnez les propriétés désirées. Au besoin, modifiez la configuration de la propriété dans la fenêtre Propriétés d'entrée.
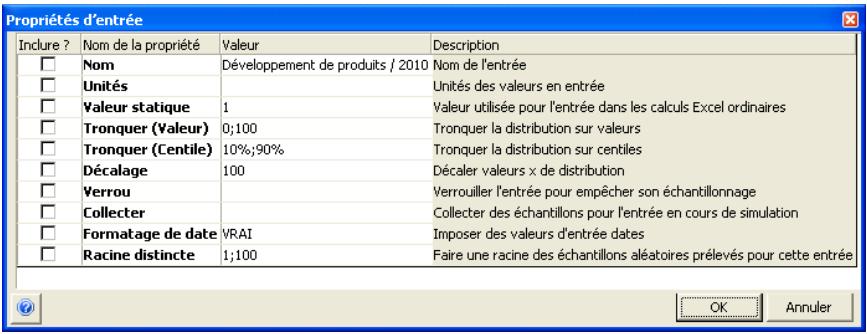
Cliquez sur OK pour saisir la fonction de propriété de distribution. Cela fait, il suffit de cliquer sur la fonction de propriété dans la barre de formule Excel pour ouvrir la fenêtre d'arguments de fonction Excel de la fonction de propriété en soi et y modifier les arguments.
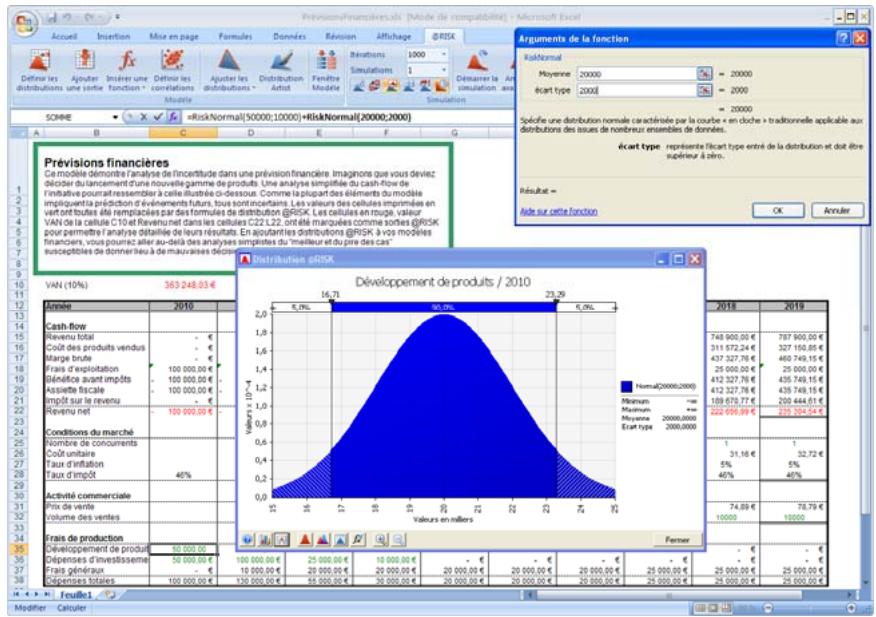
Commande définir les corrélations
Définit les corrélations entre les distributions de probabilités dans une matrice de corrélation.
La commande Définir les corrélations permet la corrélation des échantillons des distributions de probabilités en entrée. L'icône Définir les corrélations renvoie une matrice responsable d'une ligne et une colonne par distribution de probabilités comprise dans les cellules Excel sélectionnées. Les coefficients de corrélation entre les distributions se définissent dans cette matrice.
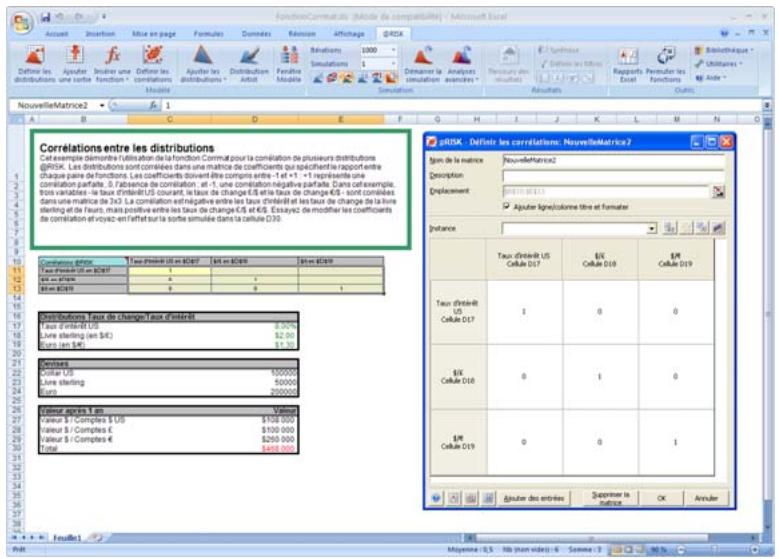
Pourquoi corréler les distributions ?
Deux distributions en entrée sont corréées lorsqu’les échantillons doivent être « liés », ce qui veut dire que la valeur échantillonnée pour une distribution doit affecter celle échantillonée pour l'autre. La correlation est nécessaire quand, dans la réalité, deux variables d'entrée variant, dans une certaine mesure, en tandem. Imaginez par exemple un modele comportant deux distributions en entrée : Taux d'intérêt et Développement du logement. Ces deux entrees sont liées, puisque la valeur de la seconde dépend de celle de la première. Un taux d'intérêt élevé tend à produit une valeur faible pour la variable Développement du logement et, réciproquement, un taux d'intérêt faible tend à produit une valeur élevé pour la variable Développement du logement. Si la correlation n'était pas prise en compte dans l'échantillonnage, certaines iterations de la simulation reflèteraient des conditions absurdes, impossibles dans la réalité (un taux d'intérêt élevé et une valeur de développement du logement également élevée, par exemple).
Entrée des coefficients de corrélation
La corrélation entre les distributions en entrée se définit dans la matrice affichée. Les lignes et colonnes de la matrice sont étiquetées au nom de chaque distribution en entrée définie dans les cellules sélectionnées. Les cellules de la matrice indiquent chacune le coefficient de correlation entre les deux distributions en entrée identifiées par la ligne et la colonne de la cellule.
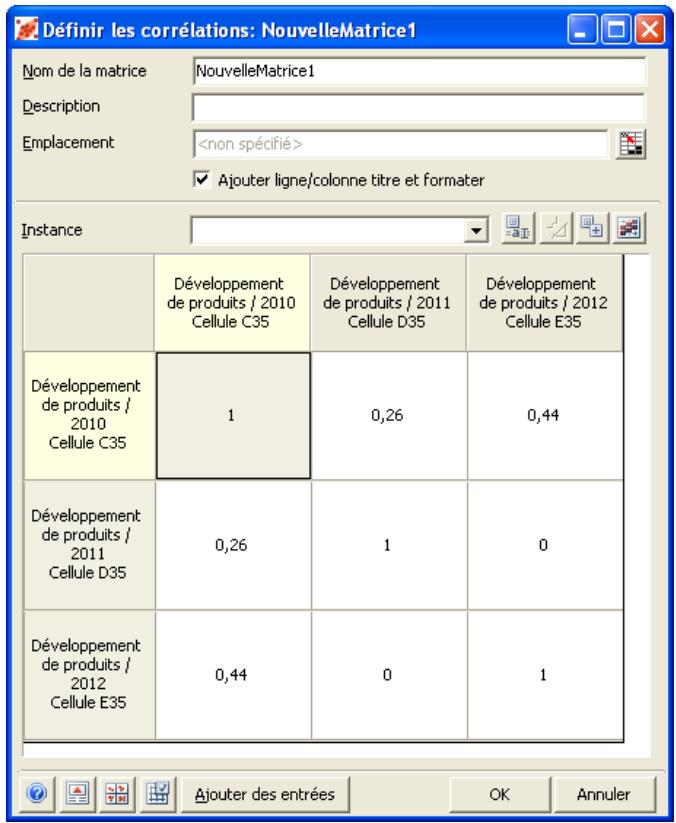
Les coefficients de corrélation sont des valeurs comprises entre -1 et 1. La valeur 0 indique l'absence de corrélation entre les deux variables, qui sont donc indépendantes. La valeur 1 représentée une corrélation positive complète entre les deux variables : lorsque la valeur échantillonnée pour une entrée est « élevé », celle échantillonnée pour l'autre l'est aussi. La valeur -1 représentée une corrélation inverse complète entre les deux variables : lorsque la valeur échantillonnée pour une entrée est « élevé », celle échantillonnée pour l'autre est « faible ». Les valeurs intermédiaires (-0,5 ou 0,5, par exemple) indiquent une corrélation partielle. Par exemple, un coefficient de 0,5 indique que lorsque la valeur échantillonnée pour une entrée est « élevé », celle échantillonnée pour la seconde l'est généralement aussi, mais pas toujours.
Une corrélation peut être définie entre n'importe quelles distributions en entrée. Une distribution peut être corrélée avec de nombreuses autres distributions en entrée. Les coefficients de corrélation sont souvent calculés à partir des données historiques réelles ayant servi de base aux fonctions de distribution du modèle.
Remarque: La corrélation entre deux entrées peut être définie dans deux cellules : ligne de la première et colonne de la seconde, ou colonne de la première et ligne de la seconde. Peu importe celle où vous entrez le coefficient : il s'inscrit automatiquement dans la deuxième.
Modification des corrélations existantes
Il est possible, dans la fenêtre Définir les correlations, de modifier les matrices de correlation existantes et de créer de nouvelles instances des matrices existantes. Si vous sélectionnez 1) une cellule Excel complétant une distribution précédemment corrélée ou 2) une cellule comprise dans une matrice de correlation existante et que vous cliquez sur l'icône Définir les correlations, la matrice existante s'affiche. Vous pouvez y changer les coefficients, ajouter de nouvelles entrées, ajouter d'autres instances, déplacer la matrice ou la modifier.
Ajout d'entrées dans une matrice
Le bouton Ajouter des entrées de la fenêtre Définir les correlations permet de sélectionner les cellules Excel porteuses de distributions @RISK à ajouter à la matrice et instance affichée. Une plage de cellules peut être sélectionnée : celles qui ne contiennent pas de distributions sont simplement omises.
Remarque: Si la fenêtre @RISK - Modèle est affichée, les distributions en entrée peuvent être ajoutées à la matrice par simple glissement-déplacement de la fenêtre à la matrice.
Suppression d'une matrice
Le bouton Supprimer la matrice supprime la matrice de corrélation affichée. Toutes les fonctions RiskCorrmat s'éliminent des fonctions de distribution introduites dans la matrice et la matrice affichée dans Excel s'efface.
La fenêtre Définir les corrélations propose les options suivantes pour la désignation et l'emplacement d'une matrice dans Excel :
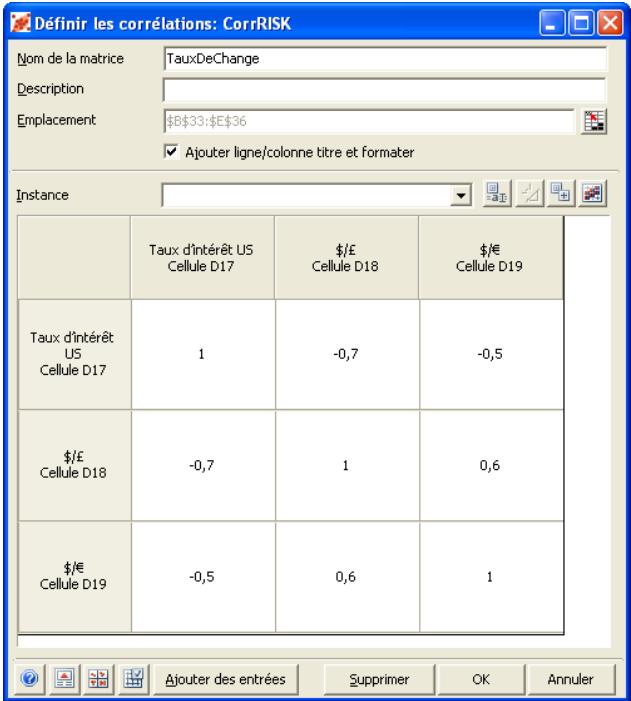
- Nom de la matrice. Spécifie le nom de la matrice. Ce nom servira 1) à nommer la plage couverte par la matrice dans Excel et 2) à identifier la matrice dans les fonctions RiskCorrmat créées pour chaque distribution en entrée incluse dans la matrice. Ce nom doit être un nom de plage Excel correct. Description. Décrit les correlations définies dans la matrice. Cette entrée est facultative.
- Emplacement. Spécifie la plage Excel que la matrice doit occuper.
- Ajouter ligne/colonne titre et formater. Affiche facultativement une ligne et colonne de titres incluant les noms et références de cellule des entrées corrélées et formant la matrice de couleurs et cordures, comme illustré ci-dessous :
| Corrélations @RISK | Taux d'intérêt US en D17 | /€ enD18 | /€ en D19 |
| Taux d'intérêt US en D17 | 1 | ||
| /€ enD18 | -0,7 | 1 | |
| /€ en D19 | -0,5 | 0,6 | 1 |
Instances de matrice
Une instance est une copie de matrice existante pouvant servir à la corrélation d'un nouvel ensemble d'entrées. Les coefficients sont les mêmes pour chaque instance ; les entrées corréllées dans chacune sont différentes. Vous pouvez ainsi configurer aisément différents groupes de variables corréllées de manière similaire sans avoir à redéfinir à chaque fois la matrice. Mieux encore, la modification d'un coefficient de corrélation dans une instance se produit automatiquement dans toutes les instances de la matrice.
Chaque instance de matrice est identifiée par une appellation différente. Vous pouvez supprimer ou renommer vos instances à tout moment.
L'instance est le troisième argument (facultatif) de la fonction RiskCorrmat. Les instances peuvent ainsi être spécifiées en toute simplicité lors de la définition des matrices ou des fonctions RiskCorrmat directement dans Excel. Pour plus de détails sur la fonction RiskCorrmat et l'argument Instance, voir la fonction RiskCorrmat dans la section Récurrence : Fonctions @RISK de ce chapitre.
Remarque: Quand une matrice de corrélation à instances multiples est créée dans la fenêtre Définir les correlations et entrée dans Excel, seules les entrées de la première instance figurent dans les titres de la matrice. De plus, lors de l'affichage d'une matrice de dispersion de correlations simulées pour la matrice après une exécution, seuls les diagrammes de dispersion des correlations de la première instance sont affichés.
Les options suivantes sont proposées pour les instances :
- Instance. Sélectionne l'instance à partager dans la matrice affichée. Le bouton Ajouter des entrées permet d'ajouter des entrées à l'instance affichée.
Les icônes sont proposées en regard du nom de l'instance :
- Renommer l'instance. Renomme l'instance courante de la matrice de corrélation affichée.
- Supprimer l'instance. Supprime l'instance courante de la matrice de corrélation affichée.
- Ajouter une nouvelle instance. Ajoute une nouvelle instance de la matrice de corrélation affichée.
Série temporelle corréée
Une série temporelle corrélée se crée au départ d'une plage Excel contenant un ensemble de distributions similaires dans chaque ligne ou colonne de la plage. Souvent, chaque ligne ou colonne représente une « période temporelle ». Il est souvent désirable de corréler les distributions de chaque période selon la même matrice de corrélation, mais sous instance distincte pour chacune.
L'icône Créer une série temporelle corréée vous invite à sélectionner le bloc de cellules Excel contenant les distributions de la série. Chaque période peut être représentée par les distributions d'une colonne, ou ligne, de la plage.
@RISK configure automatiquement une instance de la matrice de corrélation pour chaque ensemble de distributions similaires, dans chaque ligne ou colonne, de la plage sélectionnée.
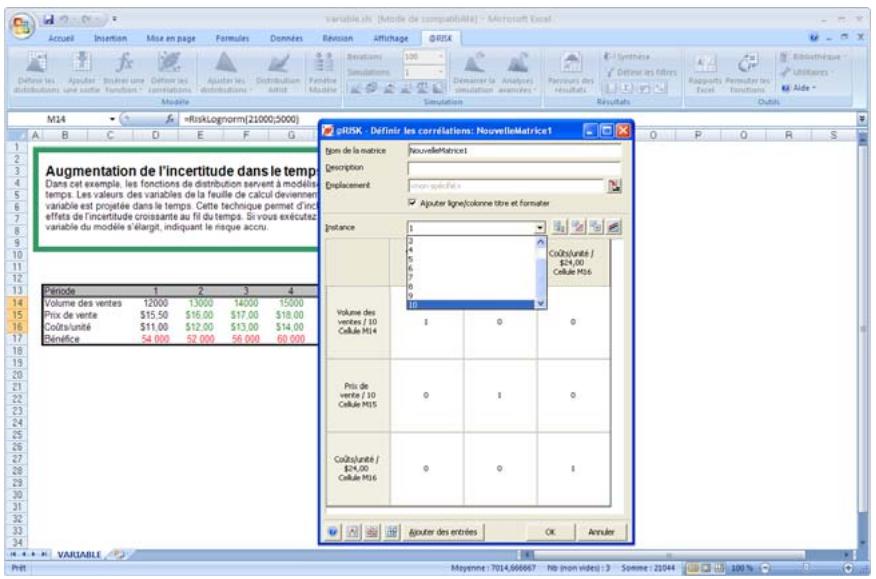
Les colonnes d'une matrice de corrélation peuvent être réorganisées par simple glissement-déplacement du titre de la colonne vers le nouvel emplacement désiré dans la matrice.
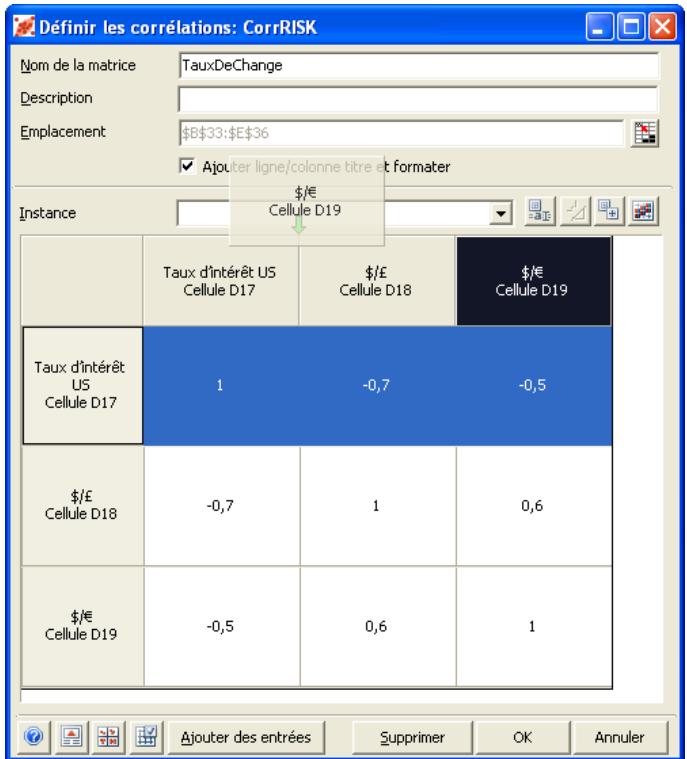
Suppression de lignes, colonnes et entrées
D'autres options, accessibles d'un clic droit sur la matrice, permettent de supprimer des lignes ou colonnes d'une matrice, ou d'en supprimer une entrée :
- Insérer une ligne/colonne. Insère une nouvelle ligne et colonne dans la matrice de corrélation active. La nouvelle colonne s'insère à l'emplacement indiqué par le curseur, repoussant les colonnes existantes restantes vers la droite. La ligne s'insère au même endroit que la colonne, repoussant les autres lignes vers le bas.
- Supprimer les lignes/colonnes sélectionnées Supprime les lignes et colonnes sélectionnées de la matrice de correlation active.
- Supprimer les entrées des lignes/colonnes sélectionnées Supprime les entrées sélectionnées de la matrice de corrélation active. Cette commande n'élimine que les entrées : les coefficients spécifiés dans la matrice restent intacts.
Diagrammes de dispersion
L'icône Afficher les diagrammes de dispersion (dans le coin inférieur gauche de la fenêtre Définir les corrélations) affiche une matrice de diagrammes de dispersion représentant chacun les valeurs échantillonnées possibles de deux entrées de la matrice lorsqu'elles sont corrélées en fonction des coefficients définis. Ces diagrammes représentent graphiquement la relation entre les valeurs échantillonnées des deux entrées au moment de la simulation.
Le curseur de corrélation proposé sous la matrice change dynamiquement le coefficient de corrélation et le diagramme de dispersion de la paire d'entrées sélectionnée. Si vous avez tendu ou glissé-déplacé la vignette du diagramme pour l'afficher en grand format, cette fenêtre s'actualise aussi dynamiquement.
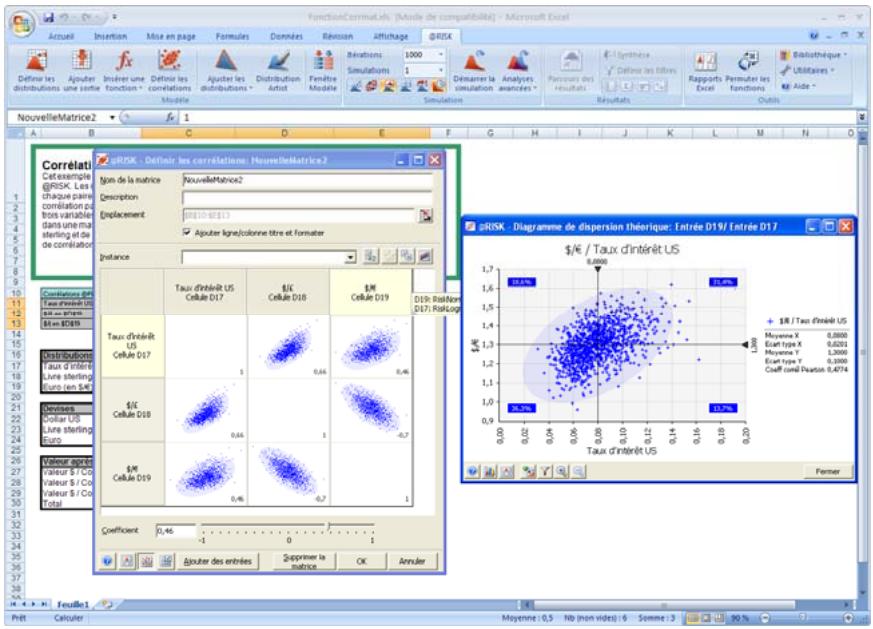
Diagrammes de dispersion de corrélations simulées
Après une simulation, vous pouvez vérifier les corrélations simulées en cliquant sur une cellule de la matrice lors du « parcours » des résultats de simulation dans le tableau. La matrice de dispersion affiche le coefficient de corrélation effectif calculé entre les échantillons prélevés pour chaque paire d'entrées, de même que celui entré dans la matrice avant l'exécution. Si une matrice présente plusieurs instances, seuls les diagrammes de dispersion des corrélations de la première instance s'affichent après l'exécution.
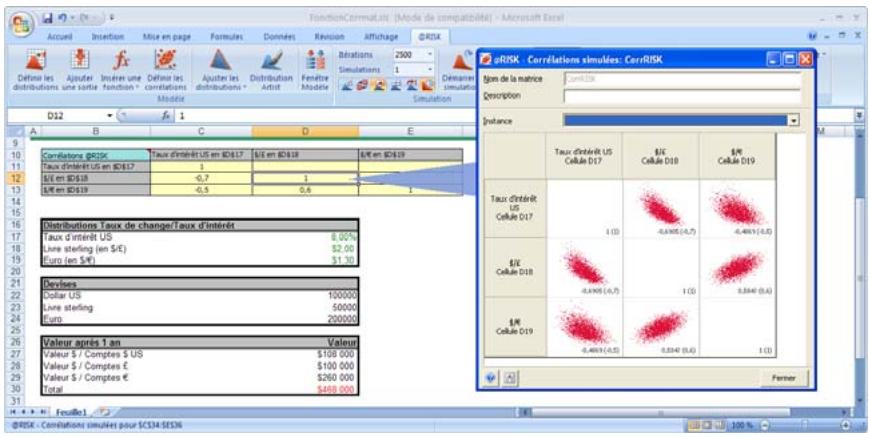
Vérifier la cohérence de la matrice
La commande Vérifier la cohérence de la matrice, invoquée d'un clic sur l'icône du même nom, vérifie la validité de la matrice définie dans la fenêtre de corrélation active. @RISK peut corriger les matrices incorrectes et générer la matrice correcte la plus proche d'une matrice incorrecte.
Une matrice incorrecte spécifie des rapports simultanés incompatibles entre trois entrées ou plus. Les matrices incorrectes ne sont pas rares. Par exemple : une corrélation associant A et B selon un coefficient de +1, B et C selon un coefficient de +1 et C et A selon un coefficient de -1 serait clairément incorrecte. L'erreur n'est cependant pas toujours aussi évidente. De manière générale, une matrice n'est correcte que si elle semi-définie positive, soit une matrice dont les valeurs propres sont toutes supérieures ou égales à zéro et dont une valeur propre au moins est supérieure à zéro.
En présence d'une matrice jugée incorrecte après invocation de l'icône Vérifier la cohérence de la matrice, @RISK offre l'option de générer la matrice correcte la plus proche, selon la procédure suivante :
1) @RISK commence par identifier la plus petite valeur propre (E0). 2) @RISK « décale » les valeurs propres de manière à ce que la plus petite soit égale à zéro, par ajust du produit de -E0 et de la matrice d'identité (I) à la matrice de corrélation (C): C' = C - E0I. 3) @RISK divise la nouvelle matrice par 1 - E0 de manière à ce que les termes diagonaux égalent : C'' = (1 / 1 - E0)C'
La nouvelle matrice est semi-définie positive, et donc correcte. Ne manquez pas de vérifier la matrice corrigée et de vous assurer que ses coefficients de corrélation reflètent bien la corrélation connue entre ses entrées. Vous pouvez, facultativement, contrôler les coefficients ajustés lors de la correction d'une matrice en entrant des pondérations d'ajustement pour les coefficients individuels.
Remarque: La vérification de la cohérence des matrices de corrélation définies dans la fenêtre Corrélation s'effectue automatiquement lorsque vous cliquez sur le bouton OK, avant l'insertion de la matrice dans Excel et l'ajout des fonctions RiskCormat pour chaque entrée de la matrice.
Pondérations d'ajustement
Des pondérations d'ajustement peuvent être spécifiées pour les coefficients individuels d'une matrice de corrélation. Ces pondérations régissent la mesure dans laquelle les coefficients peuvent être ajustés lors de la correction par @RISK d'une matrice incorrecte. La pondération peut être définie entre 0 (tous changements admis) et 100 (aucun changement admis). Ces pondérations sont utiles lorsque vous avez calculé avec certitude certaines corrélations entre les entrées d'une matrice et que vous pouvez éviter leur modification lors du processus d'ajustement.
Pour définir les pondérations d'ajustement dans la fenêtre Définir les correlations, sélectionnez la ou les cellules de la matrice concernées puis désignez la commande Entrer une pondération d'ajustement affichée en réponse à un clic droit sur la matrice ou à l'icone Vérifier la cohérence de la matrice.
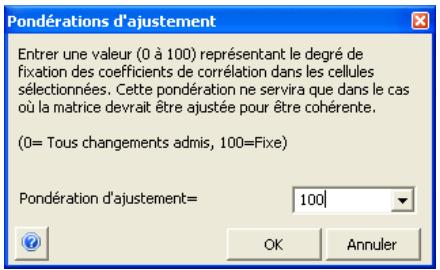
À mesure de l'entrée des pondérations, les cellules de la matrice se colorent pour indiquer la marge de souplesse de leur coefficient.
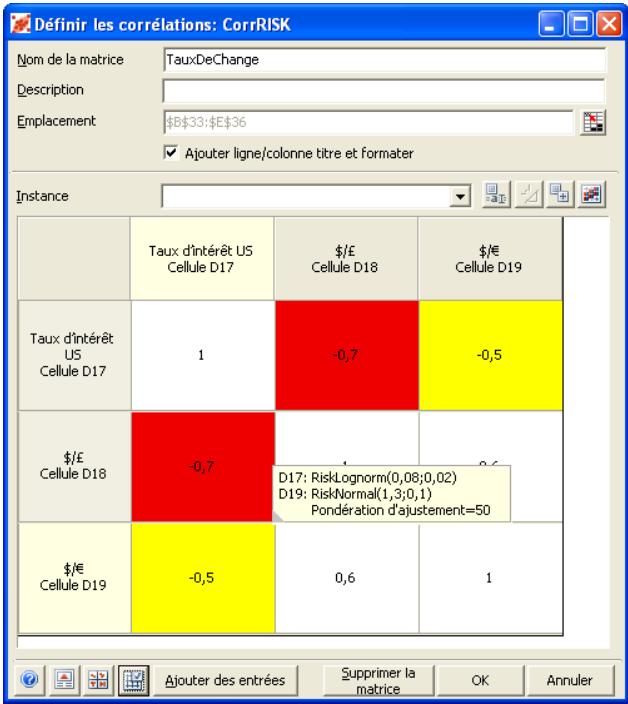
Lors du placement d'une matrice de corrélation dans Excel (ou en réponse à la commande Vérifier la cohérence de la matrice), @RISK vérifie si la matrice entrée est valable. Il la rectifie sinon en fonction des pondérations entrées.
Matrice des pondérations d'ajustement dans excel
Lorsque vous placez une matrice de corrélation dans Excel, ses pondérations d'ajustement peuvent aussi être introduites dans une matrice des pondérations d'ajustement dans Excel. Cette matrice comporte le même nombre d'éléments que la matrice de corrélation correspondante. Les cellules de cette matrice contiennent les valeurs des pondérations d'adjustement définies. Les cellules pour lesquelles aucune pondération n'a été définie (affichées en blanc dans la matrice) reçoivent une pondération de 0, ce qui peut dire qu'elles peuvent être ajustées autant que nécessaire en cas de correction de la matrice. La matrice des pondérations d'ajustement dans Excel reçoit un nom de plage Excel identique à celui de la matrice de corrélation correspondante, plus l'extension _Pondérations. Par exemple, une matrice appelée Matrice1 pourrait avoir été assortie d'une matrice de pondérations d'ajustement appelée Matrice1_Pondérations.
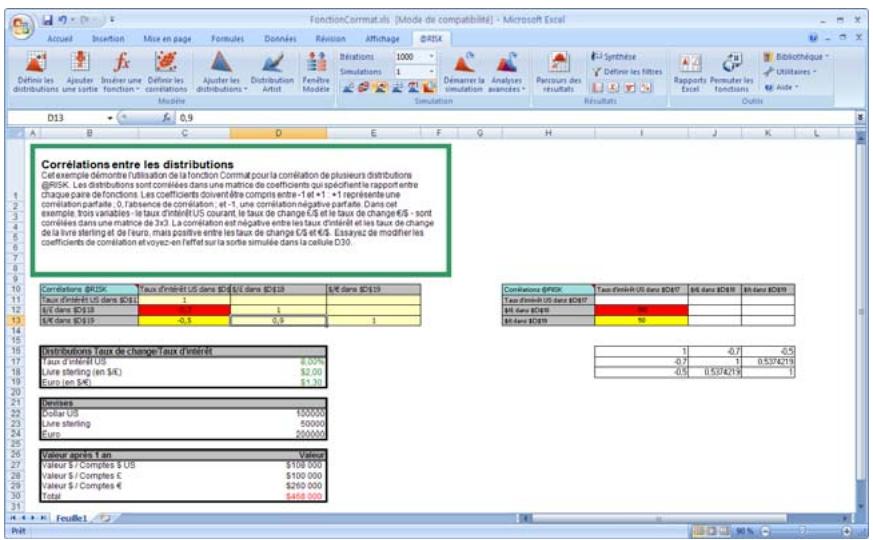
Remarque: Il n'est pas obligatoire de placer une matrice de pondérations d'ajustement dans Excel à la sortie de la fenêtre Définir les correlations. Il suffit de placer la matrice de correlation corrigée dans Excel et d'éliminer les pondérations évientuelles entrees si les corrections apportées sont satisfaisantes et que vous ne désirez pas réacceder aux pondérations dans le futuror.
Il peut être utile d'afficher dans Excel la matrice corrigée que @RISK génère et utilise lors de la simulation. Si @RISK détecte la présence d'une matrice de corrélation incohérente dans un modèle, il la corrige, en fonction de la matrice de pondérations d'ajustement correspondante éventuellement définie. La matrice incohérente originale reste cependant intacte dans Excel. Pour afficher la matrice corrigée dans le tableau :
1) Sélectionnez une plage contenant le même nombre de lignes et colonnes que la matrice de corrélation originale. 2) Entrez la fonction = RiskCorrectCorrmat(Plage_matrice_de_corrélation; Plage_matrice_d'ajustement) 3) Appuyez simultanément sur pour saisir la formule sous forme de formule matricielle. Remarque: L'argument Plage_matrice_d'ajustement est facultatif. Il ne s'utilise qu'en cas d'application de pondérations d'ajustement.
Ainsi, si la matrice de corrélation couvrait la plage A1: C3 et celle des pondérations d'ajustement, la plage E1: G3, on entraînerait :
= RiskCorrectCorrmat(A1:C3; E1:G3)
Les coefficients corrigés de la matrice sont renvoyés à la plage.
La fonction RiskCorrectCorrmat actualise la matrice corrigée à chaque changement de coefficient dans la matrice ou de pondération dans la matrice des pondérations d'ajustement.
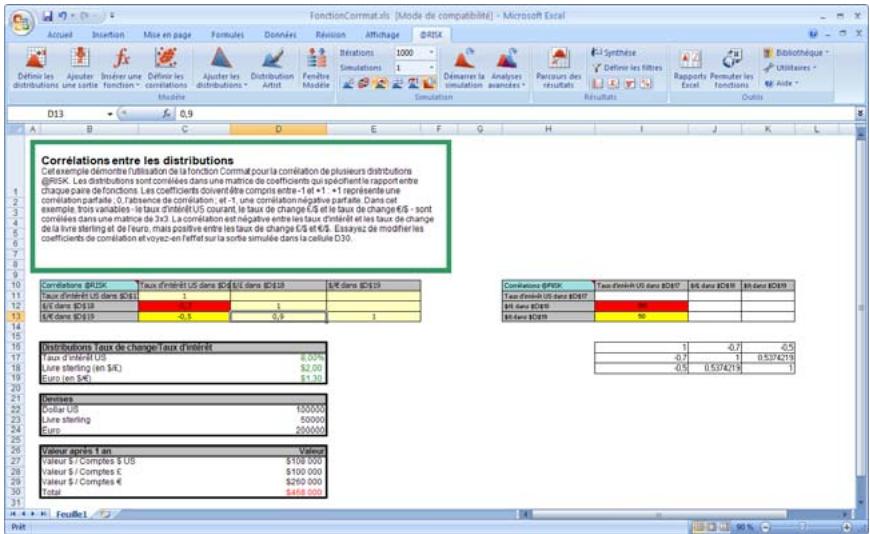
Ajout d'une matrice de corrélation au modèle excel
Lorsque vous entrez une matrice de corrélation dans la fenêtre Définir les corrélations et que vous cliquez sur OK, il se produit ici :
La matrice s'ajoute à l'emplacement spécifique d'Excel.
- Facultativement, les pondérations d'ajustement éventuellement définies peuvent être introduites dans Excel, dans une matrice de pondérations d'ajustement.
Les fonctions RiskCorrmat s'ajoutent à chacune des fonctions de distribution en entrée inclues dans la matrice. La fonction RiskCorrmat s'ajoute sous forme d'argument de la fonction de distribution. Par exemple :
= RiskNormal(200000;30000; RiskCorrmat(NouvelleMatrice;2))
NouvelleMatrice représente le nom de plage de la matrice et le chiffre 2, la position de la fonction de distribution dans la matrice.
Après l'ajout de la matrice et des fonctions RiskCorrmat dans Excel, vous pouvez changer les valeurs des coefficients (et les pondérations de la matrice des pondérations d'ajustement) sans avoir à passer par la matrice dans la fenêtre Définir les correlations. Aucune nouvelle entrée ne peut toutefois être ajoutée à la matrice affichée dans Excel, sauf ajustement individuel des fonctions RiskCorrmat nécessaires dans Excel. Pour l'ajout de nouvelles entrées, la modification de la matrice, dans la fenêtre Définir les correlations, est sans doute plus simple.
Spécification des corrélations avec les fonctions
Les corrélations entre les distributions en entrée peuvent aussi être entrées directement dans la feuille de calcul à l'aide de la fonction RiskCorrmat. Les corrélations définies à l'aide de cette fonction sont identiques à celles définies dans la fenêtre Définir les corrélations. Vous pouvez aussi introduire une matrice de pondérations d'ajustement directement dans la feuille de calcul. N'oubliez pas, dans ce cas, de préciser un nom de plage pour la matrice de corrélation, puis de donner le même nom, assorti de l'extension Ponderations à la matrice des pondérations d'ajustement. Si @RISK doit corriger la matrice de corrélation au début d'une simulation, il se référera à la matrice des pondérations d'ajustement définie.
Pour plus de détails sur les fonctions de corrélation, voir leur description dans la section Référence : Fonctions @RISK de ce chapitre.
Comprendre les valeurs de coefficient de corrélation des rangs
La corrélation des distributions en entrée dans @RISK repose sur les corrélations des rangs. La notion de coefficient de corrélation des rangs a été définie par C. Spearman au début des années 1900. Ce coefficient se calcule sur la base d'un classement des valeurs, et non des valeurs elles-mêmes (comme dans le cas du coefficient de corrélation linéaire). Le « rang » d'une valeur est déterminé par sa position dans la plage min-max des valeurs possibles de la variable.
@RISK génère des paires de valeurs échantillonnées corréées par rang en un processus à deux étapes. Dans un premier temps, un ensemble de « cotes de rang » distribuées au hasard est générée pour chaque variable. Si, par exemple, 100 iterations doivent être exécutées, 100 cotes sont générées pour chaque variable. (Les cotes de rang sont simplement des valeurs de grandeur variant entre un minimum et un maximum. @RISK utilise les cotes de Van Der Waerden basées sur la fonction inverse de la distribution normale). Ces cotes de rang sont ensuite réorganisées pour produire des paires de cotes qui génèrent le coefficient de corrélation des rangs souhaité. Il existe une paire de cotes pour chaque itération, avec une cote pour chaque variable.
Dans un deuxième temps, un ensemble de nombres aléatoires (compris entre 0 et 1) à utiliser dans l'échantillonnage est généré pour chaque variable. La encore, si 100 iterations doivent être executées, 100 nombres aléatoires sont générés pour chaque variable. Ces nombres aléatoires sont ensuite classés par ordre de rang croissant.
Pour chaque variable, le plus petit nombre aléatoire est utilisé dans l'itération associée à la plus petite cote de rang, le plus petit nombre aléatoire suivant est utilisé dans l'itération associée à la plus petite cote de rang suivante, et ainsi de suite. Cet arrangement basé sur le classement par ordre de rang continue pour tous les nombres aléatoires, jusqu'à ce que le plus grand soit utilisé dans l'itération dotée de la plus grande cote de rang.
Dans @RISK, ce processus de réorganisation des nombres aléatoires se produit avant la simulation. Il produit un ensemble de nombres aléatoires appariés, pouvant être utilisés dans l'échantillonnage, des distributions corréées à chaque itération de la simulation.
Cette méthode de corrélation est qualifiée d'approche « indépendante de la distribution » car n'importe quels types de distributions peuvent être corrélés. Bien que les échantillons prélevés pour les deux distributions soient corrélés, l'intégrité des distributions originales est conservée. Les échantillons qui en résultent pour chaque distribution reflètent la fonction de distribution en entrée dont ils sont tirés.
Commande afficher la fenêtre modèle
Affiche toutes les distributions en entrée et cellules de sortie dans la fenêtre @RISK - Modèle.
Cette commande ouvre la fenêtre @RISK - Modèle, qui présente un tableau complet des distributions de probabilités en entrée et des sorties de simulation décrites dans le modèle. La fenêtre @RISK - Modèle s'ouvre par-dessus Excel et permet les opérations suivantes :
- Modification d'une distribution en entrée ou d'une sortie en tapant simplement dans le tableau.
- Expansion d'une vignette graphique au format fenêtre complété par glissement-déplacement.
- Représentation rapide de vignettes graphiques de toutes les entrées définies.
- Accès, par double-clic sur une entrée quelconque du tableau, au navigateur graphique pour parcours des cellules du classeur porteuses de distributions en entrée.
- Modification et affichage des matrices de corrélation.
La fenêtre Modèle et le Navigateur graphique
La fenêtre Modèle est « liée » à vos feuilles de calcul Excel. Un simple clic sur une entrée du tableau révèle les cellules porteuses de l'entrée et de son nom dans Excel. Un double clic sur une entrée du tableau suffit à afficher le graphique de l'entrée dans Excel, avec liaison à la cellule correspondante.
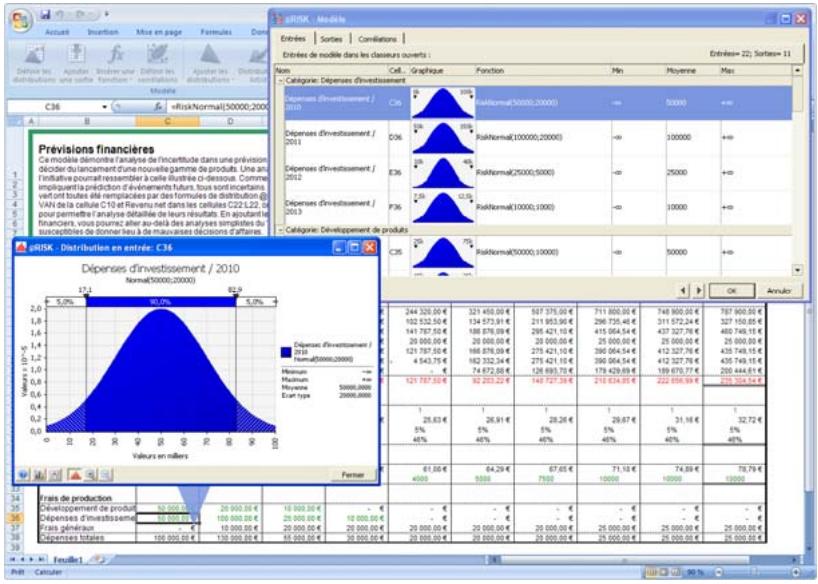
Les commandes de la fenêtre Modèle sont accessibles d'un clic sur les icônes proposées au bas du tableau ou d'un clic droit et sélection dans le menu contextuel. Les commandes choisies s'exécutent sur les lignes sélectionnées du tableau.
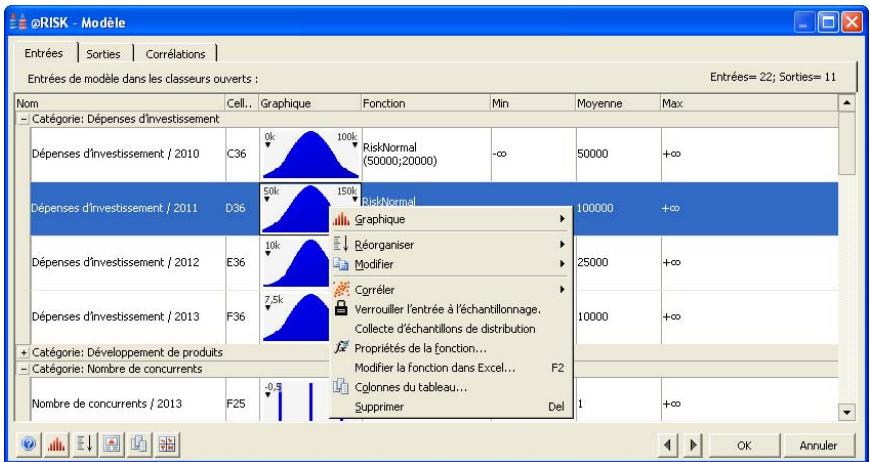
Le tableau Sorties et Entrées de la fenêtre @RISK - Modèle se configure automatiquement à l'ouverture de la fenêtre : le programme analyse ou ré-analyse vos feuilles de calcul, à la recherche des fonctions @RISK.
Comment sont générés les noms de variable?
Si aucun nom n'est défini pour une fonction RiskOutput ou une fonction de distribution, @RISK recherche à la la nommer automatiquement. Les noms ainsi créés le sont par analyse, dans la feuille de calcul, des alentours de la cellule contenant l'entrée ou la sortie considérée. Au départ de la cellule d'entrée ou de sortie, @RISK procède vers la gauche, le long de la ligne de la feuille de calcul, et vers le haut de la colonne correspondante, jusqu'à trouver une cellule porteuse d'une étiquette ou ne contenant aucune formule. Les « titres » ainsi rencontrés sont combinés pour former un nom possible pour l'entrée ou la sortie.
Fenêtre modèle — onglet entrées
Liste toutes les fonctions de distribution présentes dans les classeurs Excel ouverts.
L'onglet Entrées de la fenêtre Modèle liste toutes les fonctions de distribution comprises dans le modèle. Par défaut, le tableau indique, pour chaque entrée :
- Nom - le nom de l'entrée. Pour changer le nom d'une entrée, tapez simplement le nouveau nom voulu dans le tableau ou cliquez sur l'icône Entrée de référence pour sélectionner la cellule Excel où trouver le nom à utiliser.
- Cellule - l'emplacement de la distribution.
- Vignette graphique - représentation graphique de la distribution. Pour élargir un graphique, glissez-déplacez simplement la vignette hors du tableau.
- Fonction - la fonction de distribution entrée dans la formule Excel. Vous pouvez modifier cette fonction directement dans le tableau.
- Min, Moyenne et Max - plage des valeurs décrites par la distribution en entrée.
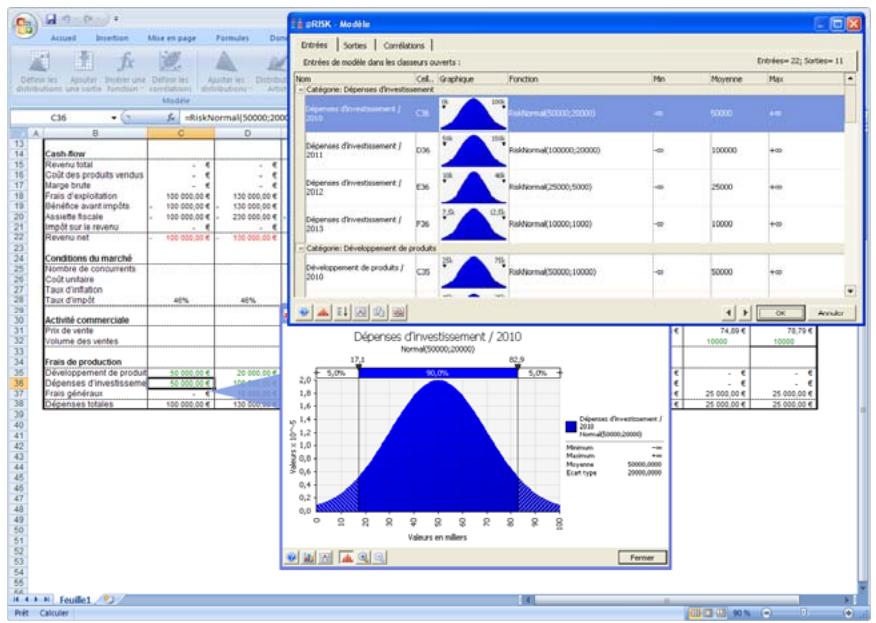
Colonnes affichées dans la fenêtre modèle
Les colonnes de la fenêtre Modèle peuvent être personnalisées en fonction des statistiques à afficher sur les distributions en entrée du modèle. L'icône Sélection des colonnes du tableau, au bas de la fenêtre, ouvre la boîte de dialogue Colonnes du tableau.
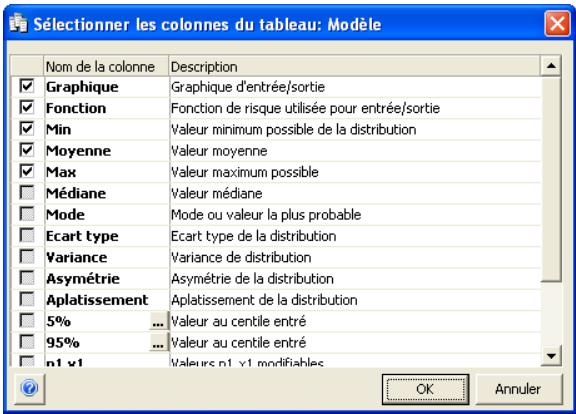
Si vous choisissez d'inclure les valeurs de centile dans le tableau, le centile effectif s'inscrit sur les lignes Valeur au centile entre.
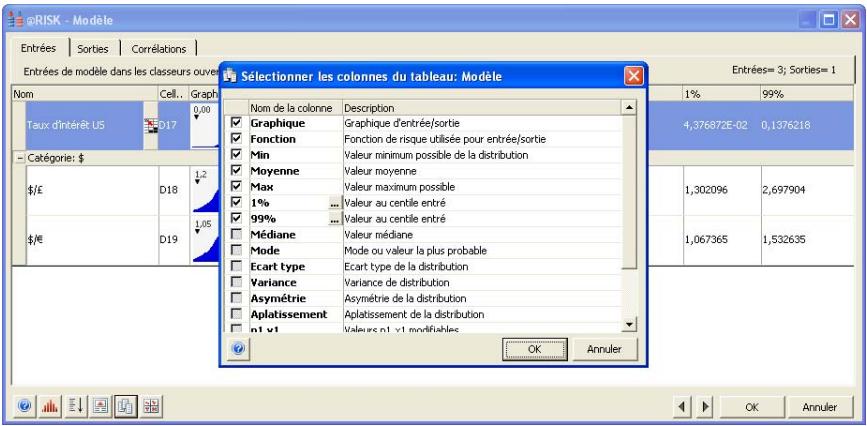
Les valeurs modifiables p1, x1 et p2, x2 sont des colonnes modifiables directement dans le tableau. Ces colonnes vous permettent d'entrer des valeurs cibles et/ou probabilités cibles spécifiques directement dans le tableau.
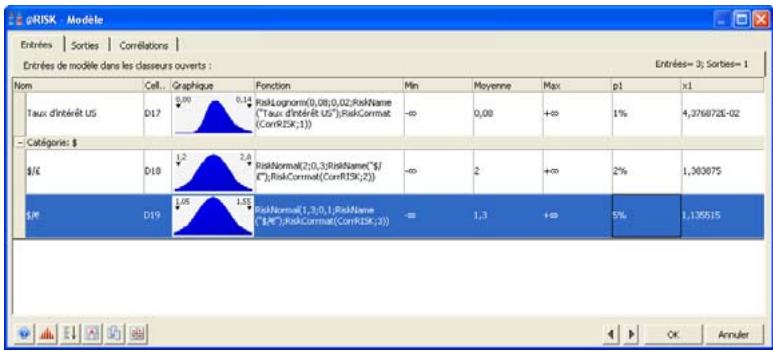
Catégories affichées dans la fenêtre Modèle
Les entrées de la fenêtre Modèle peuvent être groupées par catégorie. Par défaut, une catégorie se crée quand un groupe d'entrées partage un même nom de ligne (ou colonne). Vous pouvez aussi placer les entrées dans la catégorie de votre choix. Chaque catégorie d'entrées peut être développée ou réduite en cliquant sur le signe + ou - sur la ligne d'en-tête de catégorie.
L'icône Réorganiser, au bas de la fenêtre Modèle, permet d'activer ou désactiver le regroupement par catégorie, de changer le type de catégories par défaut, de créer de nouvelles catégories et de déplacer les entrées d'une catégorie à une autre. La fonction de propriété RiskCategory spécifie la catégorie d'une entrée (quand elle ne se trouve pas dans la catégorie par défaut identifiée par @RISK).
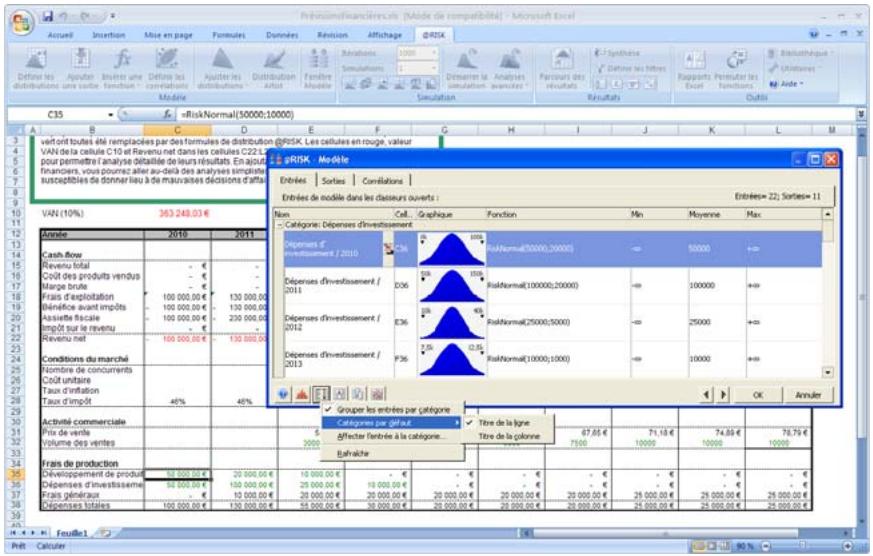
Le menu Réorganiser propose les commandes suivantes :
- Grouper les entrées par catégorie. Cette commande spécifie si le tableau des entrées doit être organisé par catégorie ou non. Si l'option est sé électionnée.
- Catégories par défaut. Cette commande précise le mode de génération automatique @RISK des noms de catégorie à partir des noms d'entrée. Ces noms se créent ainsi à partir des noms d'entrée définis par @RISK. La section de ce manuel consacrée à la création des noms par défaut décrit la manière dont les noms par défaut se définisse
Titre de ligne spécifique : le regroupement dans une même catégorie des noms qui partagent un même titre de ligne. - Titre de colonne spécifique : le regroupement dans une même catégorie des noms qui partagent un même titre de colonne.
Les catégories par défaut peuvent aussi être définies à partir des noms d'entrée définis à l'aide d’une fonction RiskName, pourvu que le séparateur « / » y figure pour séparer le texte à utiliser comme « titre » de ligne ou de colonne dans le nom. Par exemple, la fonction
figureraisit dans une catégorie par défaut intitulée « Coûts R&D » si l'option de catégories par défaut Titre de ligne était sélectionnée, ou « 2010 » si l'option Titre de colonne était sélectionnée.
- Affecter l'entrée à la catégorie... Cette commande place une entrée, ou un ensemble d'entrées, dans une catégorie. La boîte de dialogue Catégories des entrées permet la création d'une nouvelle catégorie ou la sélection d'une catégorie existante où placer les entrées sélectionnées.
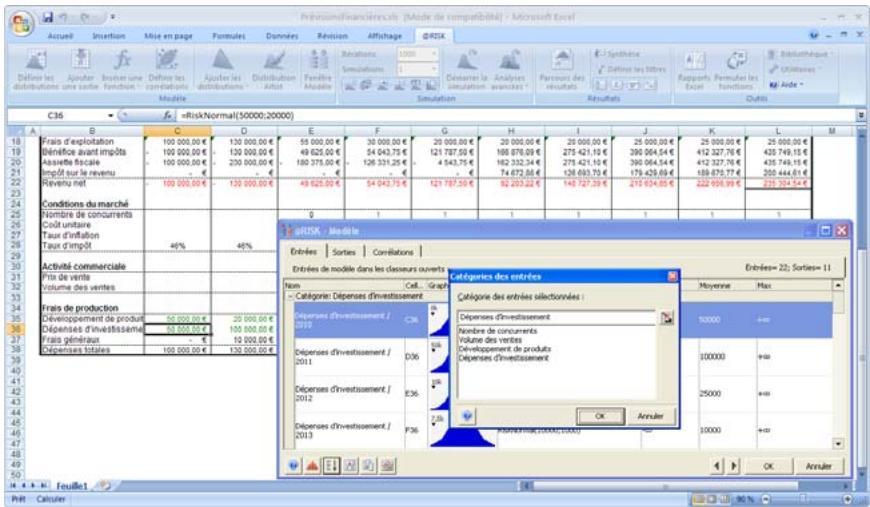
Lorsque vous affectez une entrée à une catégorie, la catégorie se définit dans une fonction @RISK au moyen de la fonction de propriété RiskCategory. Pour plus de détails sur cette fonction, voir la Liste des fonctions de propriété dans la section de ce manuel consacrée aux fonctions.
La fenêtre @RISK - Modèle peut être copiée dans le Presse-papiers ou exportée vers Excel à travers les commandes du menu Édition. Au besoin, il est également possible de recopier vers le bas ou de copier-coller les valeurs du tableau. L'approche permet notamment la reproduction rapide d'une fonction de distribution @RISK pour plusieurs entrées, ou la copie de valeurs P1 et X1 modifiables.
Le menu Édition propose les commandes suivantes :
- Copier la sélection. Copie la sélection courante du tableau dans le Presse-papiers.
- Coller, Recopier vers le bas. Colle ou produit les valeurs dans la sélection courante du tableau. Rapports Excel. Génére le tableau sur une nouvelle feuille de calcul Excel.
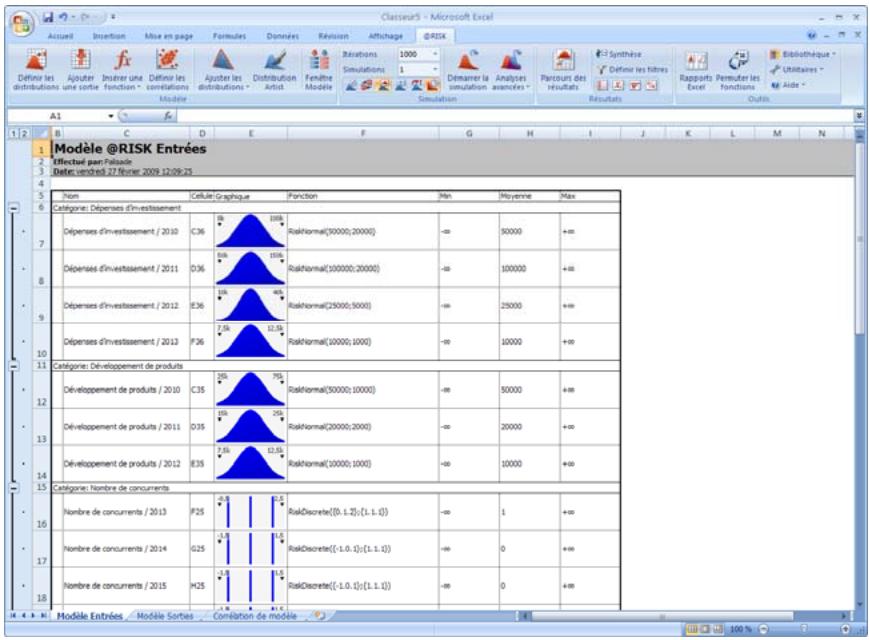
Menu graphique
Pour accéder au menu Graphique, 1) cliquez sur l'icône Graphique au bas de la fenêtre Modèle ou 2) cliquez sur le tableau avec le bouton droit de la souris. Les commandes choisies s'exécutent sur les lignes sélectionnées du tableau. Elles permettent la représentation graphique rapide de plusieurs distributions en entrée du modèle. Il suffit de sélectionner le type de graphique désiré. La commande Automatique crée le graphique en fonction du type par défaut (densité de probabilité) des distributions en entrée.
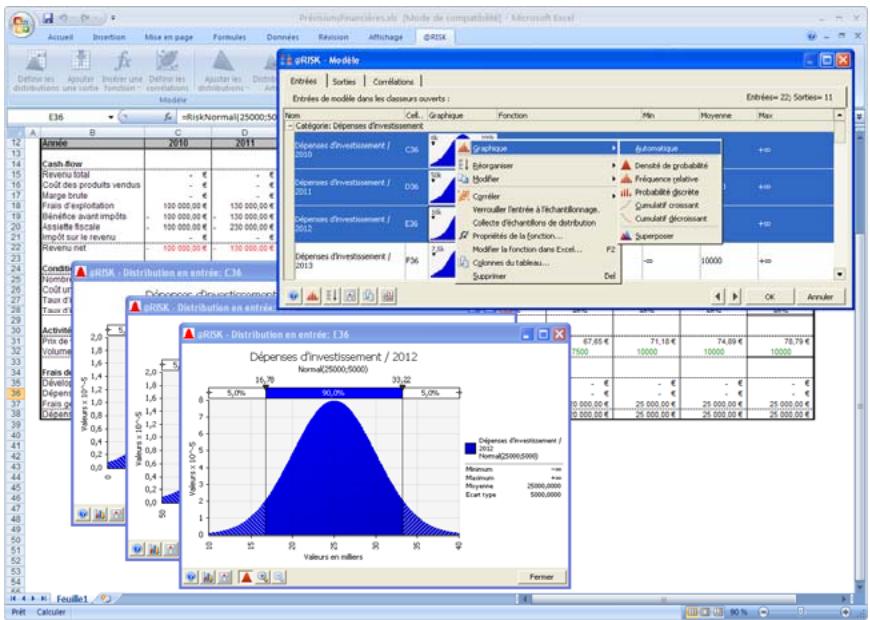
Fenêtre modèle — onglet sorties
Liste toutes les cellules de sortie des classeurs Excel ouverts.
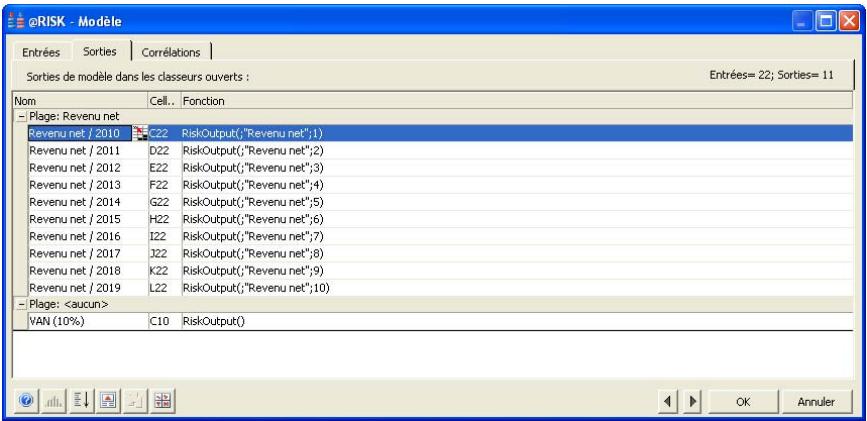
L'onglet Sorties de la fenêtre Modèle liste toutes les sorties du modèle, soit les cellules qui contiennent la fonction RiskOutput. Pour chaque sortie, le tableau indique :
- Nom - le nom de la sortie. Pour changer le nom d'une sortie, tapez simplement le nouveau nom désiré dans le tableau ou cliquez sur l'icône Entrée de référence pour sélectionner la cellule Excel où trouver le nom à utiliser.
- Cellule - l'emplacement de la sortie.
- Fonction - la fonction RiskOutput entrée dans la formule Excel. Vous pouvez modifier cette fonction directement dans le tableau.
Pour définir les propriétés de chaque sortie, cliquez sur l'icône fx en regard de chaque ligne. Pour plus de détails sur les propriétés des sorties, voir la section de ce chapitre consacrée à la commande Ajouter une sortie.
Fenêtre modèle — onglet corrélations
Liste toutes les matrices de corrélation des classeurs ouverts, ainsi que toutes les distributions en entrée qui y sont inclues.
L'onglet Corrélations de la fenêtre Modèle liste toutes les matrices de corrélation comprises dans les classeurs ouverts, ainsi que toutes les instances définies pour ces matrices. Chaque distribution en entrée incluse dans chaque matrice et instance est indiquée.
Les entrées peuvent être modifiées sous l'onglet Corrélations, tout comme elles le peuvent sous l'onglet Entrées.
Pour modifier la matrice de corrélation d'une entrée :
- Cliquez sur l'icône Matrice de corrélation en regard de la colonne Fonction.
- Cliquez avec le bouton droit sur l'entrée, sous l'onglet Corrélations ou Entrées, et désélez la commande Modifier la matrice.
- Sélectionnez la cellule Excel où trouver la distribution en entrée (ou une cellule de la matrice) et désélez la commande Définir les correlations.
Pour plus de détails, voir la section de ce chapitre consacrée à la commande Définir les corrélations.
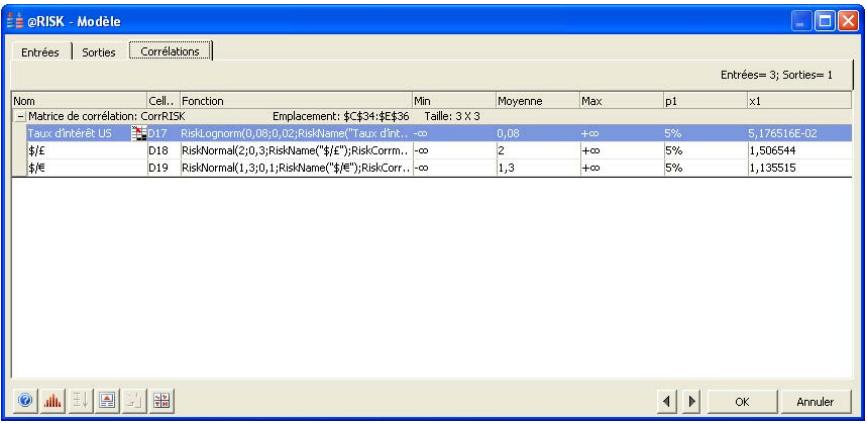
Commande ajuster les distributions aux données
Ajuste les distributions de probabilités aux données d'Excel et affiche les résultats.
La commande Modèle Ajuster les distributions aux données (également invoquée par l'icône Ajuster les distributions aux données) ajuste les distributions de probabilités aux données d'une plage Excel sélectionnée. Cette commande n'est proposée que sous les versions @RISK Professional et Industrial.
Une distribution en entrée sélectionnée parfois par ajustement de distributions de probabilités à un ensemble de données. Ainsi, si vous disposez de données d'échantillon en entrée, vous pouvez rechercher la distribution de probabilités la mieux adaptée à ces données. La boîte de dialogue Ajuster les distributions aux données comporte toutes les commandes nécessaires à l'ajustement de distributions aux données. Après l'ajustement, la distribution peut être introduite dans le modèle, comme fonction de distribution @RISK à utiliser lors des simulations.
Une distribution de résultat simulé peut aussi servir de source des données à soumettre à l'ajustement. Pour ajuster les distributions à un résultat simulé, cliquez sur l'icône Ajuster les distributions aux données dans le coin inférieur gauche de la fenêtre graphique de la distribution simulée dont les données doivent servir à l'ajustement.
Onglet données — commande ajuster les distributions aux données
Spécifie les données en entrée à soumettre à l'ajustement, leur type, leur domaine et les filtres éventuels à appliquer.
L'onglet Données de la boîte de dialogue Ajuster les distributions aux données spécifie la source et le type des données en entrée, le caractère continu ou discret de leur distribution et l'application éventuelle de filtres.
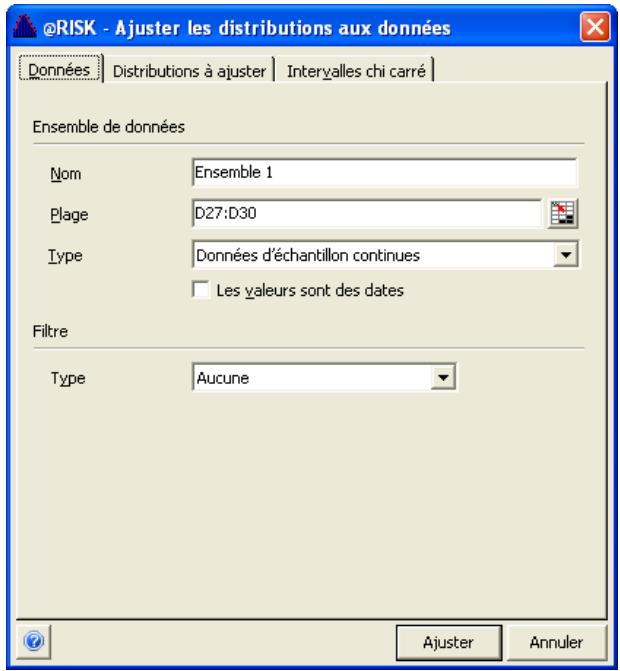
Ensemble de données
Les options Ensemble de données précisent la source des données à soumettre à l'ajustement. Les options suivantes sont proposées :
- Nom. Spécifie le nom de l'ensemble de données à soumettre à l'ajustement. Ce nom figurera dans le Gestionnaire d'ajustement, ainsi que dans toutes les fonctions RiskFit de liaison d'une fonction de distribution aux résultats d'un ajustement.
- Plage. Spécifie la plage Excel contenant les données à soumettre à l'ajustement.
Options type d'ensemble de données
Les options Type spécifique le type des données à soumettre à l'ajustement. Six types de données sont possibles :
- Données d'échantillon continues. Spécifie des données d'échantillon (ou d'observation), soit un ensemble de données choisis dans une population. Les données d'échantillon servent à estimer les propriétés de cette population. Ces données peuvent se couvrir dans une colonne, une ligne ou un bloc de cellules Excel.
- Données d'échantillon discrètes. Spécifie des données d'échantillon (ou d'observation) discrètes, indiquant que la distribution décrite par les données en entrée est discrète et que les valeurs entières sont les seules possibles (sans aucune valeur intermédiaire). Ces données peuvent se couvrir dans une colonne, une ligne ou un bloc de cellules Excel.
- Données d'échantillon discrètes (format compté). Spécifie des données d'échantillon (ou d'observation) discrètes au format compté. Dans ce cas, les données en entrée se présentent sous forme de paires X, compte, la valeur compte représentant le nombre de points tombant à la valeur X. Ces données doivent se couvri compte, dans la cellule correspondante de la seconde colonne.
- Points de densité (X-Y) (non normalisés). Les données d'une courbe de densité se sont utilisées telles que spécifiées. Cette option convient généralement si les données Y proviennent d'une courbe déjà normalisée. Ces données doivent se tr Y, dans la cellule correspondante de la seconde colonne.
- Points de densité (X-Y) (normalisés). Les données d'une courbe de densité se de la courbe de densité entrée (sous forme de paires [X, Y]) sont normalisées, de sorte que la zone située sous la courbe de densité représente l'unité (un). L'option est recommandée pour améliorer l'ajustement aux données d'une courbe de densité. Ces données doivent se couvrir dans deux colonnes
Excel : les valeurs X dans la première colonne et la valeur Y dans la cellule correspondante de la seconde colonne.
- Points cumulatifs (X-P). Les données d'une courbe cumulative se présentent sous forme de paires [X, p]. Chaque paire se compose d'une valeur X et d'une probabilité cumulative p spécifique la hauteur (distribution) de la courbe cumulative à la valeur X. p représente la probabilité d'une valeur inférieure ou égale à la valeur X correspondante. Ces données doivent se trouver dans deux colonnes Excel : les valeurs X dans la première colonne et la valeur p, dans la cellule correspondante de la seconde colonne.
- Les valeurs sont des dates. Cette option spécifie l'ajustement de données de type date et l'affichage des graphiques et statistiques au format date. Si @RISK détecte des dates dans les données de référence, cette option est sélectionnée par défaut.
Options filtre
Le filtrage permet l'exclusion de valeurs indésirables, extérieures à une plage spécifiée, de l'ensemble des données en entrée. Le filtrage permet de spécifier les valeurs hors norme des données, à omettre lors de l'ajustement. Par exemple, vous pouvez limiter l'analyse aux valeurs X supérieures à zéro. Vous pouvez aussi éliminer les valeurs de queue et ne considérer que les données distantes, tout au plus, de quelques écarts types de la moyenne. Les options de filtre proposées sont les suivantes :
Aucun. Spécifie l'ajustement aux données telles qu'entrées. - Absolu. Spécifie une valeur X minimum, une valeur X maximum, ou les deux, définissant ainsi la plage des données à inclure à l'ajustement. Les valeurs extérieures à cette plage sont omises. Si la plage n'est définie que par un minimum ou un maximum, les données ne sont filtrées qu'en-deçà ou au-delà de ce minimum ou maximum, respectivement. - Relatif. Spécifie que les données extérieures au nombre d'écarts types entré par rapport à la moyenne seront éliminées de l'ensemble de données avant l'ajustement.
Onglet distributions à ajuster — commande ajuster les distributions aux données
Sélectionne les distributions de probabilités à ajuster ou spécifie la distribution prédéfinie à ajuster.
Les options de l'onglet Distributions à ajuster de la fenêtre Ajuster les distributions aux données seront à sélectionner les distributions de probabilités à inclure dans un ajustement. Elles permettent aussi la spécification de distributions prédéfinies dont les valeurs paramétriques sont déjà configurées. Les distributions de probabilités à considérer à l'ajustement peuvent aussi être sélectionnées moyennant l'entrée des limites inférieures et supérieures des distributions admises.
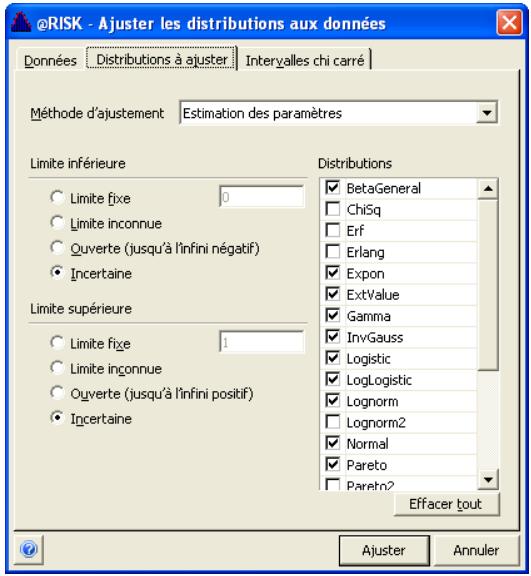
Méthode d'ajustement
Les options de méthode d'ajustement déterminent 1) si un groupe de types de distribution doit être ajusté ou 2) si un ensemble de distributions prédéfinies doit être utilisé. Les autres options affichées sur l'onglet dépendent de la sélection opérée ici. Les options Méthode d'ajustement proposées sont les suivantes :
- Estimation des paramètres, pour la recherche des paramètres des types de distribution sélectionnés et leurs adaptations à l'ensemble de données.
- Distributions prédéfinies, pour déterminer comment les distributions de probabilités entrées (dont les paramètres sont déjà configurés) s'ajustent à l'ensemble de données.
Si vous sélectionnez Estimation des paramètres comme méthode d'ajustement, l'onglet Distributions à ajuster propose les options suivantes :
- Liste des types de distribution. La sélection ou désélection d'un type de distribution particulier inclut ou supprime le type en question de l'ajustement à effectuer. La liste des types de distribution affichée dépend des options sélectionnées pour les paramètres Limite inférieure et Limite supérieure. Par défaut, certains types de distribution ne sont pas cochés dans la liste. La raison en est 1) qu'il s'agit de formes spéciales d'un type de distribution déjà coché (par exemple, une distribution Erlang est une distribution Gamma à paramètre de forme entier) et leur ajustement serait superflu ou 2) qu'il s'agit d'un type de distribution généralement exclu de l'ajustement (Student ou Chi carré, par exemple).
Chaque type de distribution présente des caractéristiques différentes quant à la plage et aux limites des données décrites. À travers les options Limite inférieure et Limite supérieure, vous pouvez sélectionner les types de distribution à inclure et limiter les options paramétrées en fonction de ce que vous savez de la plage des valeurs possibles de l'objet décrit par vos échantillons en entrée.
Les options de limite inférieure et limite supérieure suivantes sont proposées :
- Limite fixe. Spécifie une valeur fixe régissant la limite inférieure et/ou supérieure de la distribution ajustée. Certains types de distribution seulement (triangulaire, par exemple) admettent des limites inférieure et supérieure fixes. La valeur entrée ici limite l'ajustement à certains types de distributions.
- Limite inconnue. Indique que la distribution ajustée a une limite inférieure et/ou supérieure finie, mais que vous n'en connaissiez pas la valeur.
- Ouverte (jusqu'à l'infini +/-). Indique que les données décrites par la distribution ajustée peuvent s'étendre à une valeur positive ou négative infinie.
- Incertaine. Indique que vous n'êtes pas sûr des valeurs possibles et que la gamme compte de distributions doit par conséquent être disponible à l'ajustement.
Si vous sélectionnez Distributions prédéfinies comme méthode d'ajustement, seul l'ensemble de distributions prédéfinies indiqué est soumis à l'ajustement.
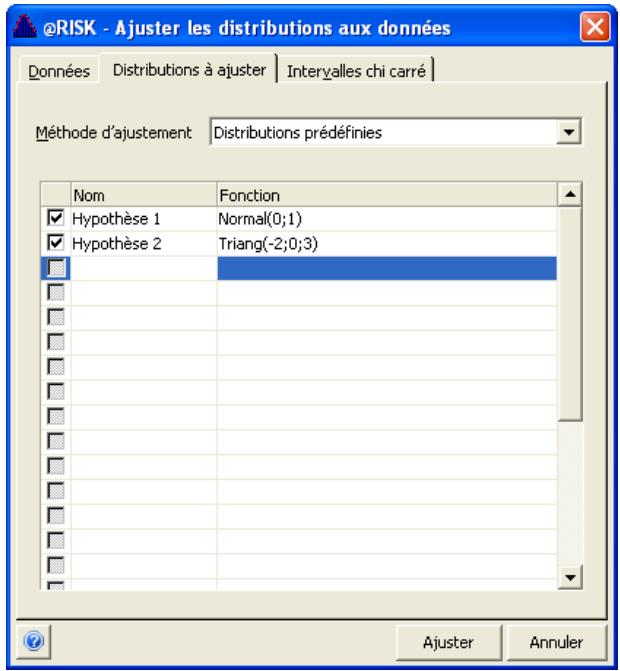
Les options suivantes permettent de spécifier les distributions prédéfinies :
- Nom. Spécifie le nom à donner à la distribution prédéfinie.
- Fonction. Spécifie la fonction de la distribution prédéfinie.
Les distributions prédéfinies peuvent être inclues dans un ajustement, ou en être exclues, par simple sélection ou désélection dans le tableau.
Onglet intervalles chi carré — commande ajuster les distributions aux données
Définit les intervalles à utiliser dans les tests de qualité de l'ajustement Chi carré.
L'onglet Intervalles Chi carré de la boîte de dialogue Ajuster les distributions aux données définit le nombre d'intervalles, leur type et la répartition personnalisée à appliquer aux tests de qualité de l'ajustement Chi carré. Les intervalles représentent les groupes de répartition des données en entrée, comparables aux classes utilisées pour le tracé d'un histogramme. Les intervalles définis peuvent affecter les résultats des tests Chi carré et ceux générés pour l'ajustement. Les options d'intervalles Chi carré vous permettent d'appliquer la répartition que vous jugez appropriée. Pour plus de détails sur l'effet des intervalles dans un test Chi carré, voir le chapitre 6 : Ajustement de distributions.
Remarque: Si vous n'êtes pas sûr du nombre ou du type d'intervalles à utiliser pour un test Chi carré, CHOISISSEZ « Automatique » pour « Nombre d'intervalles » et « Probabilités égales » pour « Disposition »
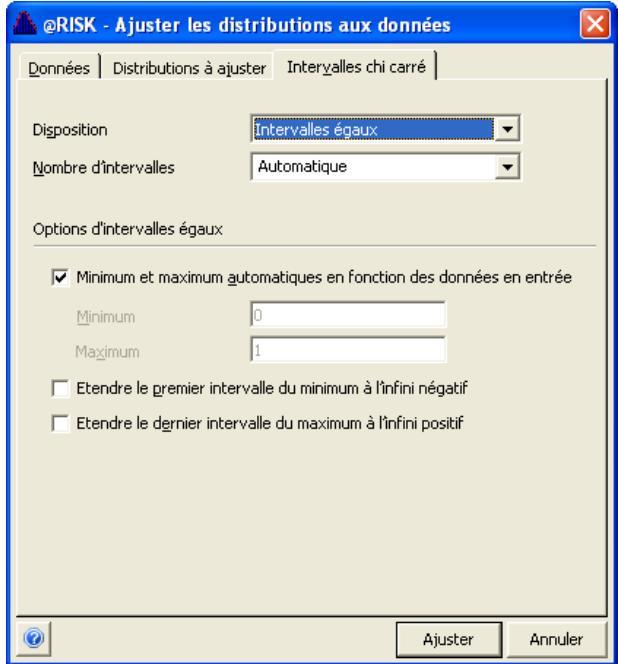
Les options de disposition des intervalles spécifient le style des intervalles à définir. Vous pouvez aussi préciser des intervalles personnalisés dont vous entrez vous-même les valeurs minimum et maximum. Les options de disposition suivantes sont proposées :
- Probabilités égales. Spécifie la répartition à intervalles de probabilités égaux de la distribution ajustée. Il en résulte généralement des intervalles de longueur variable. Par exemple, si dix intervalles sont définis, le premier s'étend de la valeur minimale au 10e centile, le deuxième, du 10e au 20e centile, et ainsi de suite. Sous cette option, @RISK ajuste ètes, toutefois, @RISK ne peut égaliser qu'approximativement les intervalles.
- Intervalles égaux. Spécífie des intervalles de longueur égale sur l'ensemble de données en entrée. Plusieurs options sont proposées. Elles peuvent être activées individuellement ou toutes ensemble:
1) Minimum et maximum automatiques en fonction des données en entrée. Spécifie le calcul des valeurs minimum et maximum d'intervalles égaux en fonction de celles de l'ensemble de données. Le premier intervalle et le dernier peuvent cependant être soumis aux paramètres des options Étendre le premier intervalle et Étendre le dernier intervalle. Si l'option de calcul automatique du minimum et du maximum n'est pas sélectionnée, vous pouvez entrer vous-même la valeur Minimum et Maximum devant marquer le début et la fin des intervalles. Vous pouvez ainsi définir une plage précise de répartition, indépendante des valeurs minimum et maximum de l'ensemble de données. 2) Étendre le premier intervalle du minimum à l'infini négatif. Spécifie un premier intervalle s'étendant du minimum spécifique à l'infini négatif. Tous les autres intervalles seront de longueur égale. Dans certaines circonstances, cette option améliore l'ajustement aux ensembles de données dont la limite inférieure est inconnue. 3) Étendre le dernier intervalle du maximum à l'infini positif. Spécifie un dernier intervalle s'étendant du maximum spécifique à l'infini positif. Tous les autres intervalles seront de longueur égale. Dans certaines circonstances, cette option
améliore l'ajustement aux ensembles de données dont la limite supérieure est inconnue.
- Intervalles personnalisés. Le contrôle total des intervalles à utiliser dans les tests Chi carré est parfois utile. La personnalisation des intervalles est par exemple utile en présence d'un regroupement naturel de données d'échantillon recueillies, dont vous désirez refléter l'importance dans vos intervalles Chi carré. La personnalisation vous permet de définir une plage minimum-maximum pour chaque intervalle défini.
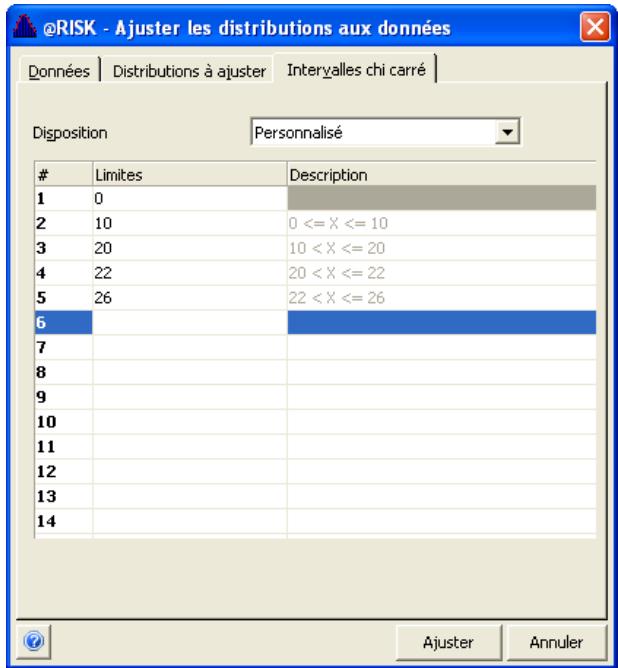
Pour personnaliser vos intervalles :
1) Choisissez la disposition Personnalisée. 2) Entrez les limites de chaque intervalle. À mesure de l'entrée de valeurs dans les cases, l'étendue de chaque intervalle se remplit automatiquement.
Nombre d'intervalles
L'option Nombre d'intervalles désigne spécifie un nombre d'intervalles fixe ou, automatiquement, le nombre calculé par le système.
Fenêtre résultats de l'ajustement
Affiche la liste des distributions ajustées, ainsi que les graphiques et statistiques de chacune.
La fenêtre Résultats de l'ajustement affiche la liste des distributions ajustées, les graphiques illustrant l'ajustement de la distribution sélectionnée aux données et les statistiques relatives à la distribution ajustée, aux données en entrée et aux résultats des tests de qualité de l'ajustement.
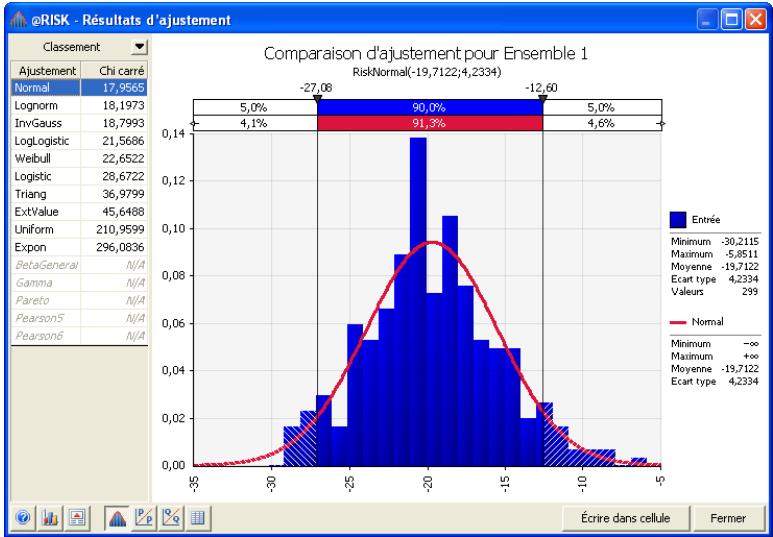
Remarque: Aucune information de test de qualité de l'ajustement n'est disponible pour les types de données en entrée Points de densité et Points cumulatifs. Seuls les graphiques Comparaison et Différence sont disponibles pour ces types de données.
Classement
La liste Classement répertorie toutes les distributions pour lesquelles des résultats d'ajustement valables ont été générés. Les distributions sont classées en fonction du test de qualité d'ajustement sélectionné au moyen de l'icône de classement (en haut du tableau de classement). Seuls les types de distribution sélectionnés sous l'onglet Distributions à ajuster de la boîte de dialogue Ajuster les distributions aux données sont testés lors de l'ajustement.
La statistique de qualité de l'ajustement indique la probabilité qu'une fonction de distribution donnée ait produit l'ensemble de données considéré. Elle peut être comparée à la qualité d'ajustement d'autres fonctions de distribution. Les informations de qualité de l'ajustement ne sont disponibles que si le type de données en entrée est Valeurs échantillonnées.
Cliquez sur une distribution, dans le tableau de classement, pour afficher les résultats d'ajustement qui la concernent, graphiques et statistiques compris.
La sélection opérée sous l'icone Classer par régit le classement des distributions en fonction du test de qualité de l'ajustement sélectionné. Ce test mesure la précision de l'ajustement entre les données d'échantillon et une fonction de densité hypothétique. Trois types de test sont proposés :
- Chi carré. Le test Chi carré représente le test de qualité d'ajustement le plus courant. Il convient aux données d'échantillon et à tous les types de fonction de distribution (discrete ou continue). Sa faiblesse tient à l'absence de directives claires quant à la sélection des intervalles, ou répartitions, nécessaires au test. Dans certains cas, vous pourriez aboutir, au départ des mêmes données, à des conclusions différentes suivant la manière dont vous avez spécifié ces intervalles. Les intervalles se définissent dans la boîte de dialogue Ajuster les distributions aux données et sous l'onglet Définir les intervalles chi carré.
- K-S, ou test de Kolmogorov-Smirnov. Le test de Kolmogorov-Smirnov ne dépend d'aucune répartition en intervalles, ce qui le rend beaucoup plus efficace que le test Chi carré. Il convient aux données d'échantillon, mais pas aux fonctions de distribution discrètes. La méthode a pour inconvénient de ne pas bien détecter les divergences en queue de distribution.
- A-D, ou test d'Anderson-Darling. Le test Anderson-Darling semble fort à l'épreuve Kolmogorov-Smirnov, à la différence qu'il accorde plus d'importance aux valeurs de queue. Ce test n'est pas non plus tributaire du nombre d'intervalles.
- Erreur de moyenne quadratique. Si le type de données en entrée est Courbe de densité ou Courbe cumulative (sous l'onglet Données de la boîte de dialogue Ajuster les distributions aux données), ce test est le seul effectué à l'ajustement. Pour plus de détails sur le test d'erreur de moyenne quadratique, voir le Chapitre 6 : Ajustement de distributions.
Affichage des résultats d'ajustement de distributions multiples
Pour afficher simultanément les résultats d'ajustement de plusieurs distributions de la liste des distributions ajustées, sélectionnez simplement plusieurs distributions dans le tableau en vous aidant de la touche.
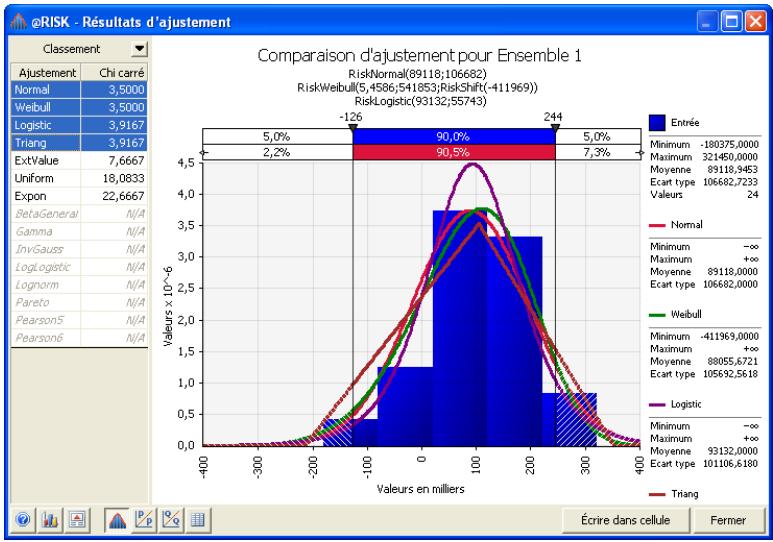
Résultats d'ajustement — graphiques
Pour le type de données Valeurs échantillonnées, trois graphiques - Comparaison, P-P et Q-Q - sont proposés pour la distribution sélectionnée dans la liste des distributions ajustées. Pour les types Courbe de densité et Courbe cumulative, les graphiques Comparaison et Différence sont proposés.
Sur tous les types de graphique, les délimiteurs permettent de définir graphiquement les valeurs X-P.
Un graphique comparatif affiche deux courbes : celle de la distribution en entrée et celle de la distribution créée par l'analyse d'ajustement.
Deux délimiteurs peuvent être réglés, pour définir les valeurs X gauche et P gauche, d'une part, et X droite et P droite, d'autre part. Les valeurs renvoyées par les délimiteurs s'affichent sur la barre des probabilités, au-dessus du graphique.
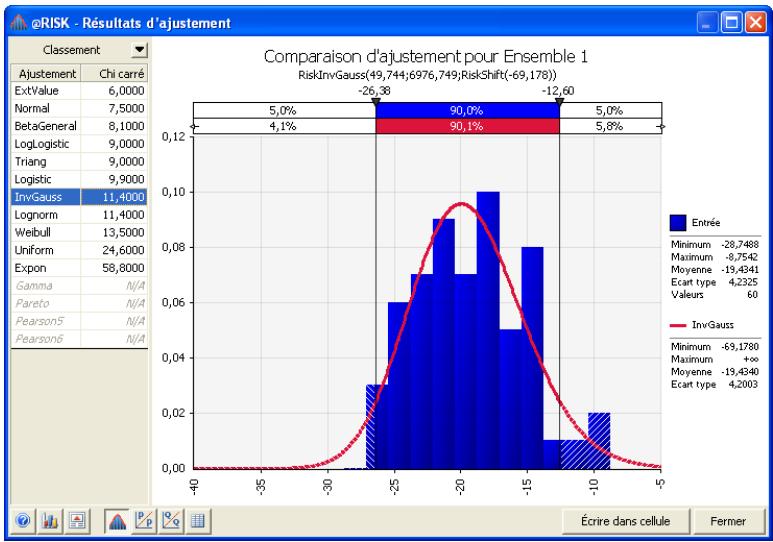
Le graphique P-P (double probabilité) trace la valeur p de la distribution ajustée par rapport à la valeur p du résultat ajusté. Si la qualité de l'ajustement est bonne, le tracé paraît presque linéaire. Un seul délimiteur renvoie la valeur p des données en entrée et la distribution ajustée en n'importe quel point X du graphique.
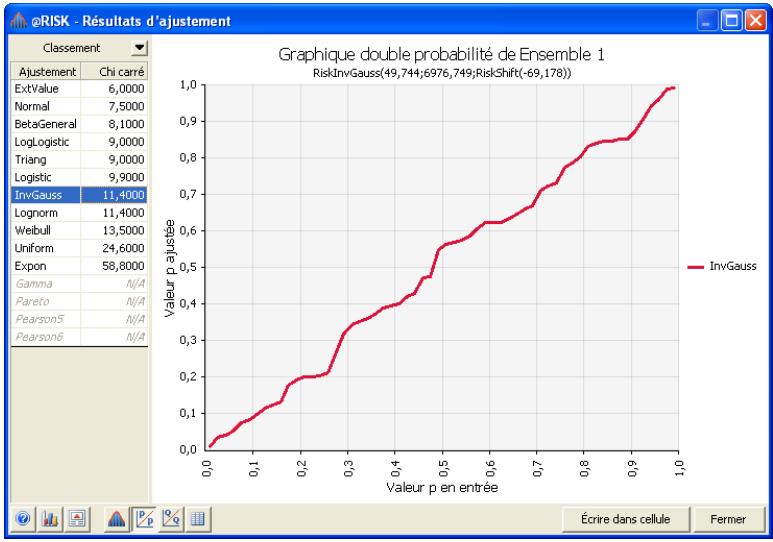
Graphique q-q
Le graphique Q-Q (double quantile) trace les valeurs de centile de la distribution ajustée par rapport à celles des données en entrée. Si la qualité de l'ajustement est bonne, le tracé paraît presque linéaire. Un seul délimiteur renvoie la valeur de centile des données en entrée et la distribution ajustée en n'importe quel point X du graphique.
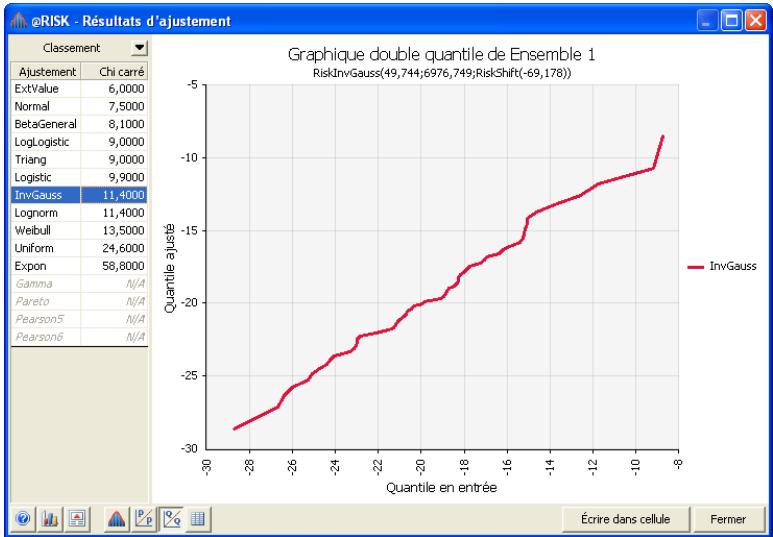
Commande cellule — fenêtre résultats d'ajustement
Écrit le résultat d'un ajustement dans une cellule Excel sous forme de fonction de distribution @RISK.
Le bouton Cellule de la fenêtre Résultats d'ajustement consigne le résultat d'un ajustement dans une cellule Excel sous forme de fonction de distribution @RISK.
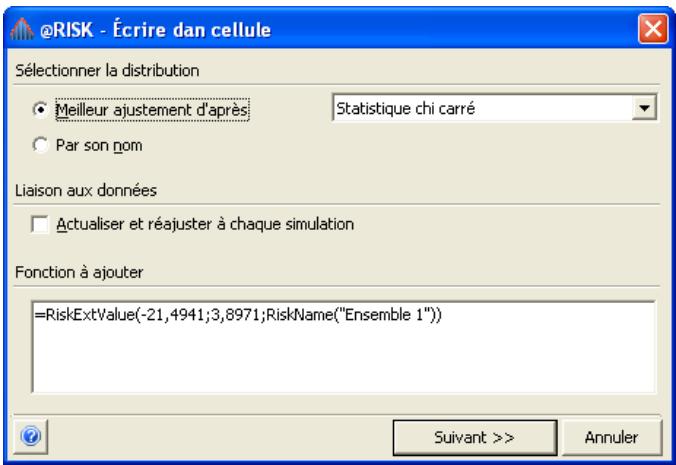
La boîte de dialogue Écrite dans une cellule propose les options suivantes :
- Sélectionner la distribution. La fonction de distribution à inscrite dans Excel peut refléter la(Meilleure)distribution ajustée en fonction du test sélectionné (Meilleur ajustement d'après) ou elle peut être sélectionnée spécifique dans la liste des distributions ajustées (Par son nom)
- Liaison aux données. La fonction de distribution à inscrite dans Excel peut être actualisée automatiquement chaque fois que les données en entrée de la plage de données Excel de référence changent et qu'une nouvelle simulation est exécutée. Si l'option Actualiser et réajuster à chaque simulation est sélectionnée, un nouvel ajustement s'exécute quand @RISK démarre une simulation et détecte un changement dans les données. La liaison s'établit par une fonction de propriété RiskFit telle que
RiskNormal(2,5;1; RiskFit("Prix";"Meilleure A-D"))
Cette fonction spécifique que la distribution est liée à la distribution ajustée d'après le test Anderson-Darling, pour les données associées à l'ajustement intitulé « Données de prix ». Il s'agit pour le moment d'une distribution normale représentant une moyenne de 2,5 et un écart type de 1.
La fonction de propriété RiskFit s'ajoute automatiquement à la fonction écrite dans Excel lorsque l'option Actualiser et réajuster à chaque simulation est sélectionnée. Si aucune fonction RiskFit ne figure dans la fonction de distribution d'un résultat d'ajustement, la fonction est « désassociée » des données à l'origine de sa sélection. En cas de changement ultérieur des données, la distribution reste inchangée.
Pour plus de détails sur la fonction de propriété RiskFit, voir le chapitre de référence de ce manuel consacré aux fonctions de propriété @RISK.
- Fonction à ajouter. Cette zone affiche la fonction de distribution @RISK qui s'ajoutera effectivement dans Excel en réponse au bouton d'écriture dans la cellule.
Fenêtre de synthèse d'ajustement
Affiche la synthèse des statistiques calculées et des résultats de test de toutes les distributions ajustées.
La fenêtre Synthèse d'ajustement présent à l'ensemble de données courant.
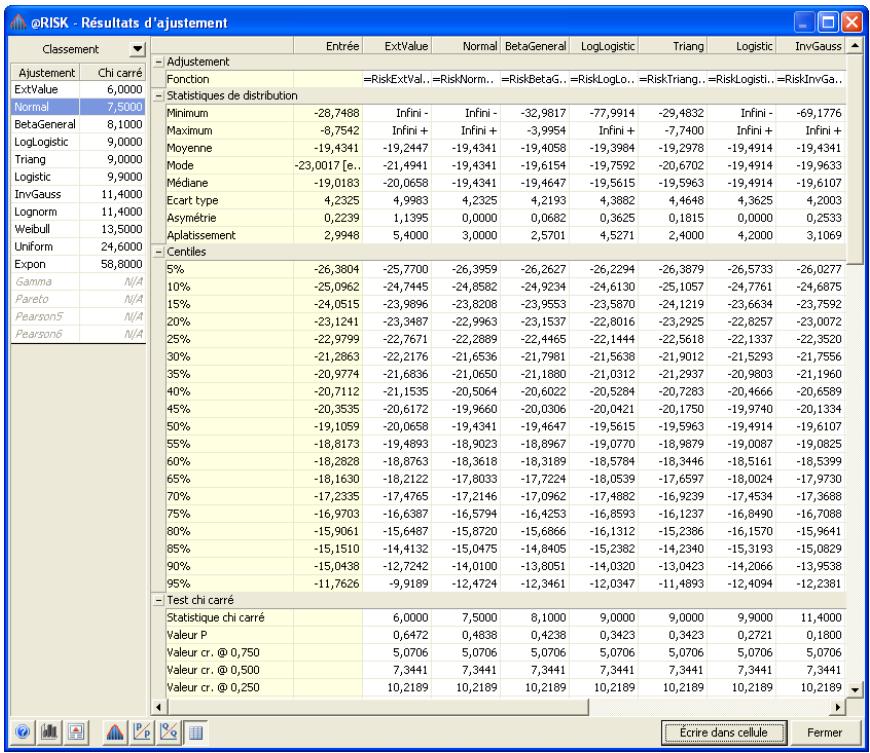
La fenêtre Synthèse d'ajustement présente les informations suivantes :
- Fonction - distribution et arguments de la distribution ajustée. Quand l'ajustement sert d'entrée dans un modèle @RISK, cette formule est celle de la fonction de distribution qui sera introduite dans la feuille de calcul.
- Statistiques de distribution (Minimum, Maximum, Moyenne, etc.) Ces entrées affichent les statistiques calculées pour toutes les distributions ajustées et pour la distribution des données en entrée.
- Les centiles identifient la probabilité d'obtenir un résultat spécifique ou la valeur associée à un niveau de probabilité donné.
Pour chacun des trois tests réalisés (Chi carré, A-D et K-S), la fenêtre Synthèse d'ajustement affiche :
Valeur de test - statistique de test de la distribution de probabilités ajustée pour chacun des trois tests.
Valeur P - niveau de signification observé de l'ajustement. Pour plus de détails sur les valeurs P, voir le chapitre 6, Ajustement de distributions.
- Classement - classement de la distribution ajustée par rapport à tous les autres ajustements pour chacun des trois tests. Le classement indiqué peut varier suivant le test considéré.
Valeur C - valeurs critiques aux différents niveaux de signification pour chacun des trois tests. Pour plus de détails sur les valeurs critiques et leur calcul, voir le Chapitre 6 : Ajustement de distributions.
- Statistiques d'intervalle — pour chaque intervalle de la distribution en entrée et de la distribution ajustée (test chi carré uniquement). Les valeurs min et max de chaque intervalle sont indiquées, de même que la valeur de probabilité de l'intervalle, pour les deux distributions, en entrée et ajustée. Les intervalles se configurent sous l'onglet Intervalles chi carré de la boîte de dialogue Ajuster les distributions aux données.
Commande gestionnaire d'ajustement
Affiche la liste des ensembles de données soumis à l'ajustement dans le classeur courant, pour modification et suppression.
La commande Modèle Gestionnaire d'ajustement (également invoquée par l'icone Ajuster les distributions aux données) affiche la liste des ensembles de données soumis à l'ajustement dans les classeurs ouverts.
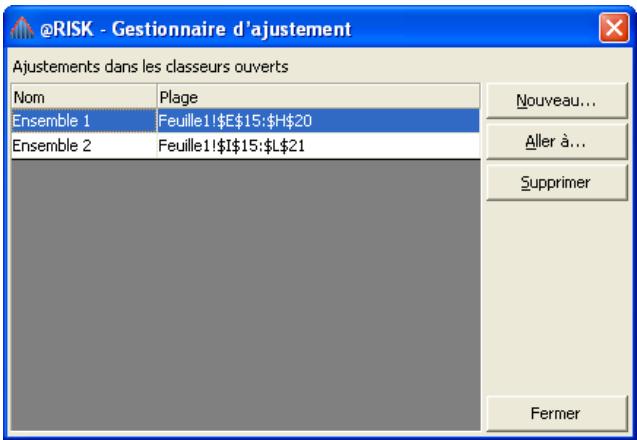
Ces ensembles de données et leurs paramètres s'enregistrent en même temps que le classeur. La commande Gestionnaire d'ajustement permet d'en parcourir la liste et de supprimer ceux devenus inutiles.
La fenêtre Artist permet de tracer des courbes libres pouvant servir à la création de distributions de probabilités. Les commandes du menu Artist régissent à la fois le mode d'exécution du tracé dans la fenêtre Artist et la création d'une distribution de probabilités au départ d'une courbe tracée. Le menu Artist n'est disponible que si la fenêtre active est une fenêtre Artist.
Ouvre la fenêtre Distribution Artist pour le dessin d'une courbe appelée à servir de distribution de probabilités.
La commande Modèle Distribution Artist permet de tracer des courbes libres pouvant servir à la création de distributions de probabilités. L'approche permet d'évaluer graphiquement les probabilités puis de créer des distributions à partir du graphique. Les distributions peuvent être tracées sous forme de courbes de densité de probabilité (General), d'histogrammes, de courbes cumulatives ou de distributions discrètes.
Après l'ouverture d'une fenêtre Artist par la commande Distribution Artist, vous pouvez y tracer une courbe par simple glissement de la souris.
La courbe tracée peut ensuite être ajustée à une distribution de probabilités à travers l'icône Ajuster la distribution aux données. Les données représentées par la courbe sont ainsi ajustées à une distribution de probabilités. Une courbe tracée dans la fenêtre Distribution Artist peut aussi être écrite dans une cellule Excel sous forme de distribution RiskGeneral, RiskHistogramm ou RiskDiscrete; les points de la courbe y deviennent les arguments de la distribution.
Si vous invoquez la commande Distribution Artist et que la cellule active d'Excel contient une fonction de distribution, la fenêtre Artist affiche un graphique de densité de probabilité de cette fonction, avec points ajustables. Cette approche permet aussi de revoir des courbes tracées précédemment et inscrites dans une cellule Excel comme distributions RiskGeneral, RiskHistogramm ou RiskDiscrete.
L'échelle et le type de graphique tracé dans la fenêtre Artist se configurent dans la boîte de dialogue Options de Distribution Artist. Pour y accéder, cliquez sur l'icône Tracer une nouvelle courbe (2e icône, en partant de la gauche, au bas de la fenêtre) ou cliquez-droit sur le graphique et choisissez la commande Tracer une nouvelle courbe.
Les options suivantes sont proposées :
- Nom. Nom par défaut donné par @RISK à la cellule sélectionnée, ou nom de la distribution utilisée pour créer la courbe affichée, tel qu'indiqué dans sa fonction de propriété RiskName.
- Format de distribution. Spécifie le type de courbe à créer : Densité de probabilité (Général) représentée une courbe de densité de probabilité à points x-y; Densité de probabilité (Histogramme), une courbe de densité à barres d'histogramme; Cumulatif croissant, une courbe cumulative croissante; Cumulatif décroissant, une courbe cumulative décroissante; et Probabilité discrète, une courbe à probabilités discrètes.
- Minimum et Maximum. Spécifient l'échelle X du graphique tracé.
- Nombre de points ou barres. Définit le nombre de points ou barres tracés lors du déplacement du pointeur dans la plage min-max du graphique. Vous pouvez déplacer les points sur la courbe ou les barres d'un historique vers le haut ou vers le bas pour changer la forme de la courbe.
Pour une distribution de type cumulatif croissant (tel que spécifique sous l'option Format), vous ne pouvez tracer qu'une courbe à valeurs Y croissantes, et vice-versa pour une courbe cumulative décroissante.
En fin de trace, les points extrêmes de la courbe se marquent automatiquement.
Quelques remarques à propos des courbes tracées à l'aide de Distribution Artist :
Après avoir tracé une courbe, vous pouvez « faire glisser » l'un de ses points en un nouvel emplacement. Cliquez simplement sur le point et, sans relâcher le bouton de la souris, faites-le glisser vers le nouvel emplacement désiré. Lorsque vous relâchez le bouton, la courbe se retrace automatiquement de manière à inclure le nouveau point de données défi ni.
- Vous pouvez déplacer les points de données le long de l'axe X ou Y (sauf pour un histogramme).
- Vous pouvez déplacer les points extrêmes en dehors des axes par glissement-déplacement.
- Déplacez un pointillé de fond vertical pour déplacer une courbe toute entière.
D'un clic droit sur la courbe, vous pouvez ajouter de nouveaux points ou de nouvelles barres.
Icônes de la fenêtre Artist
Les icônes suivantes sont proposées dans la fenêtre Distribution Artist :
- Copier. Les commandes Copier copient les données sélectionnées ou le graphique de la fenêtre Artist vers le Presse-papiers. Copier les données limite la copie aux points X et Y des marqueurs. Copier le graphique place une copie du graphique tracé dans le Presse-papiers.
- Format de distribution. Affiche la courbe actuelle dans l'un des autres formats de distribution disponibles.
- Tracer une nouvelle courbe. La sélection de cette icône ( 3e en partant de la gauche, au bas de la fenêtre) efface la courbe active dans la fenêtre Artist et entame le tracé d'une nouvelle.
- Ajuster les distributions aux données. Cette commande ajuste une distribution de probabilités à une courbe tracée. Lors de l'ajustement, les valeurs X et Y associées à la courbe sont ajustées. Les résultats de l'ajustement s'affichent dans une fenêtre de résultats ordinaire, où toutes les distributions ajustées peuvent être passées en revue. Toutes les options d'ajustement des distributions aux données d'une feuille de calcul Excel sont également disponibles à l'ajustement à une courbe tracée dans la fenêtre Artist. Pour plus de détails sur ces options, voir le Chapitre 6 : Ajustement de distributions.
Écrire dans une cellule
La commande Écrire dans une cellule crée une fonction de distribution RiskGeneral, RiskHistogramm ou RiskDiscrete au départ de la courbe tracée et permet de sélectionner la cellule Excel ou introduire cette fonction. Une distribution RiskGeneral est une distribution @RISK définie par l'utilisateur, dotée d'une valeur minimum, d'une valeur maximum et d'un ensemble de points de données X, P qui la définissent. Ces points de données proviennent des valeurs X et Y des marqueurs de la courbe. Une distribution RiskHistogramm est une distribution @RISK définie par l'utilisateur, dotée d'une valeur minimum, d'une valeur maximum et d'un ensemble de points de données P qui définissent les probabilités de l'histogramme. Une distribution RiskDiscrete est une distribution @RISK définie par l'utilisateur, assortie d'un ensemble de points de données X, P. Seules les valeurs X spécifiées sont admises.
Commande des paramètres de simulation
Modifie les paramètres des simulations exécutées par @RISK.
La commande Paramètres de simulation affecte les tâches executées au cours d'une simulation. Tous les paramètres sont dotés de valeurs par défaut, que vous pouvez modifier. Les paramètres de simulation affectent le type d'échantillonnage effectué par @RISK, la mise à jour de l'affichage de la feuille de calcul en cours de simulation, les valeurs renvoyées par Excel dans un recalcul standard, la racine de nombres aléatoires utilisé pour l'échantillonnage, l'état du contrôle de convergence et l'exécution des macros en cours de simulation. Tous les paramètres de simulation s'enregistrent en même temps que le classeur dans Excel.
Pour enregistrer vos paramètres de simulation de manière à en faire les paramètres par défaut à chaque démarrage de @RISK, désélectionnez la commande Paramètres d'application des Utilitaires.
Une barre de paramètres de simulation @RISK s'ajoute aux versions Excel 2003 et antérieures. Les mêmes icônes figurent sur le ruban @RISK installé dans Excel 2007. Elles donnent accès à beaucoup des paramètres de simulation.

Les icônes suivantes sont proposées :
- Paramètres de simulation ouvre la boîte de dialogue du même nom.
- Les listes déroulantes Itérations/ Simulations permettent de changer rapidement, depuis la barre d'outils, le nombre d'itérations à exécuter.
- Aléatoire/Statique fait basculer @RISK entre le renvoi de valeurs probables ou statiques des distributions et celui d'échantillons Monte Carlo lors d'un recalcul Excel standard.
- Graphique, Résultats et Démo régissant ce qui s'affiche à l'écran pendant et après une simulation.
- Actualisation en temps réel déterminée si les fenêtres ouvertes s'actualisent pendant l'exécution d'une simulation.
Onglet général — commande paramètres de simulation
Définit le nombre d'itérations et de simulations à exécuter et spécifie le type de valeurs renvoyées par les distributions @RISK lors des recalculs Excel normaux.
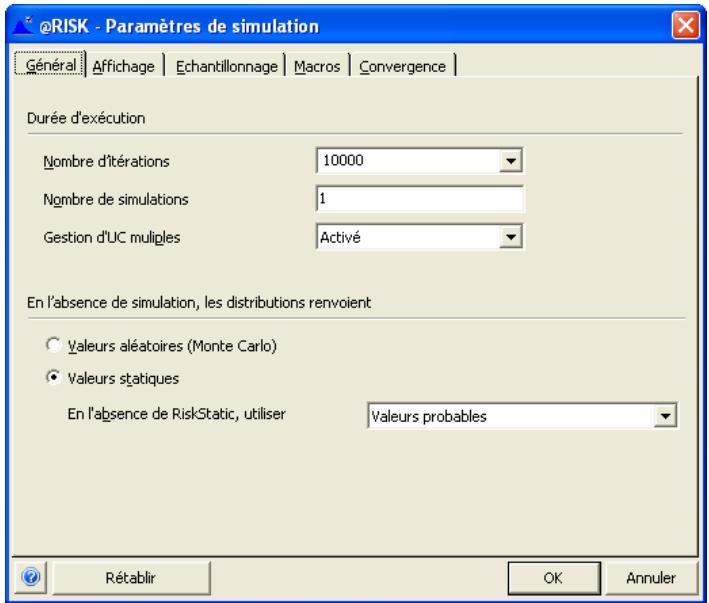
Les options d'exécution de simulation suivantes sont proposées :
- Nombre d'itérations. Permet d'entrer ou de modifier le nombre d'itérations à exécuter lors d'une simulation. Ce paramètre se définit par une valeur entière positive (jusqu'à 2 147 483 647). La valeur par défaut est 100. À chaque itération :
1) toutes les fonctions de distribution sont échantillonnées, 2) les valeurs échantillonnées sont renvoyées aux cellules et formules de la feuille de calcul, 3) la feuille de calcul est recalculée, 4) les nouvelles valeurs calculées dans les cellules des plages de sortie sélectionnées sont enregistrées en vue de la création des distributions de sortie.
Le nombre d'iterations affecte la durée d'exécution de la simulation ainsi que la qualité et la précision des résultats. Pour obtenir des résultats rapides, n'exécutez pas plus de 100 iterations. Pour atteindre des résultats plus précis, exécutez-en 300 ou 500 (au moins). Pour exécuter le nombre d'iterations nécessaires à l'obtention de résultats précis et stables, sélectionnez les options de surveillance de convergence (décrites dans cette section). Sous le paramètre
Automatique, @RISK détermine automatiquement le nombre d'iterations à exécuter. Ce paramètre s'utilise en combinaison avec la surveillance de convergence pour arrêter la simulation lorsque toutes les distributions de sortie convergent. Voir l'onglet Convergence, plus loin dans cette section, pour plus de détails sur la surveillance de convergence.
L'option Itérations de la commande Options... Calcul du menu Excel Outils sert à résoudre les feuilles de calcul qui contiennent des références circulaires. Vous pouvez simuler des feuilles de calcul faisant appel à cette option, car @RISK n'intervient pas dans la résolution des références circulaires. @RRISK permet à Excel « d'itérer » pour résoudre ses références circulaires à chaque itération d'une simulation.
Important! Un recalcul unique avec échantillonnage, exécuté sous l'option « En l'absence de simulation, les distributions renvoient des valeurs aléatoires (Monte Carlo) », risque de ne pas résoudre les références circulaires. Si une cellule recalculée au cours d'une iteration Excel contient une fonction de distribution @RISK, cette fonction sera rééchantillonnée à chaque iteration du recalcul simple. L'option « En l'absence de simulation, les distributions renvoient des valeurs aléatoires (Monte Carlo) » ne doit par conséquent pas être utilisée pour les feuilles de calcul faisant appel aux fonctions d'iteration d'Excel pour résoudre leurs références circulaires.
- Nombre de simulations. Permet d'entrer ou de modifier le nombre de simulations à exécuter au cours d'une simulation @RISK. Ce paramètre se définit par une valeur entière positive. La valeur par défaut est 1. À chaque itération de chaque simulation :
1) toutes les fonctions de distribution sont échantillonnées, 2) les fonctions SIMTABLE renvoient l'argument correspondant au numéro des simulations en cours, 3) la feuille de calcul est recalculée, 4) les nouvelles valeurs calculées dans les cellules des plages de sortie sélectionnées sont enregistrées en vue de la création des distributions de sortie.
Le nombre de simulations demandées doit être inférieur ou égal à celui des arguments entrés dans les fonctions SIMTABLE. À défaut, la fonction SIMTABLE renvoie une valeur d'erreur lors d'une simulation dont le numéro est supérieur au nombre d'arguments.
Pour tous les détails relatifs à la simulation de sensibilité et l'utilisation de la fonction SIMTABLE, voir le Chapitre 5 : Techniques de modélisation @RISK.
Important! Quand le nombre de simulations est supérieur à 1, chaque simulation exécutée fait appel à la même valeur racine de nombres aléatoires, afin de réduire les différences entre les simulations aux seuls changements des valeurs renvoyées par les fonctions SIMTABLE. Pour éviter ce paramètre, sélectionnez l'option Racines différentes pour simulations multiples dans la section Générateur de nombres aléatoires de l'onglet Échantillonnage avant l'exécution de simulations multiples.
- UC multiples. Commande l'utilisation de toutes les UC générées sur l'ordinateur pour accélérer les simulations. Remarque: Cette option n'est proposée qu'aux utilisateurs de @RISK Industrial sous Windows NT 4.0 ou mistroux.
Simulations nommées
Si vous exécutez plusieurs simulations, il peut être utile de les nommer. Le nom donné à chacune servira à identifier les résultats dans les rapports et les graphiques. Fixez le nombre de simulations à une valeur supérieure à 1, cliquez sur le bouton Nom des simulations et entrez le nom désiré pour chacune.
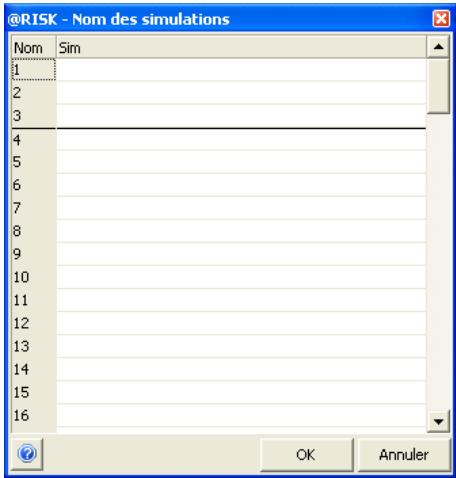
En l'absence de simulation, les distributions renvoient... options
Les options « En l'absence de simulation, les distributions renvoient » régissant ce qui s'affiche en réponse à la touche, après recalcul Excel standard. Les options suivantes sont proposées :
- Valeurs aléatoires (Monte Carlo). Sous cette option, les fonctions de distribution renvoient un échantillon Monte Carlo aléatoire lors d'un recalcul ordinaire. Ce paramètre présente les valeurs de la feuille de calcul telles qu'elles apparaitraient à l'exécution d'une simulation, avec prélevement de nouveaux échantillons à chaque recalcul.
- Valeurs statiques. Sous cette option, les fonctions de distribution renvoient les valeurs statiques entrées dans une fonction de propriété RiskStatic lors d'un calcul ordinaire. Si une valeur statique n'est pas définie pour une fonction, elle renvoie :
Valeur probable - la valeur probable ou moyenne d'une distribution. Pour les distributions discrètes, le paramètre Valeur probable « corrigée » renvoie comme valeur permutée la valeur discrète de la distribution la plus proche de la vraie valeur probable. Vraie valeur probable - les valeurs permutées sont identiques à celles de l'option Valeur probable « corrigée », sauf dans le cas des distributions discrètes telles que DISCRETE, POISSON, etc. Pour ces distributions, la vraie valeur probable est renvoyée comme valeur permutée même si la valeur probable est impossible pour la distribution entrée (s'il ne s'agit pas de l'un des points discrets de la distribution, notamment). - Mode - la valeur mode d'une distribution. - Centile - la valeur de centile entrée pour chaque distribution.
L'icône Aléatoire/Statique de la barre Paramètres @RISK inverse rapidement la sélection du paramètre Valeurs aléatoires (Monte Carlo) ou Valeurs statiques.
Onglet affichage — commande paramètres de simulation
Spécifie ce qui s'affiche à l'écran pendant et après une simulation.
Les paramètres de l'onglet Affichage déterminent l'affichage créé par @RISK pendant et après l'exécution d'une simulation.
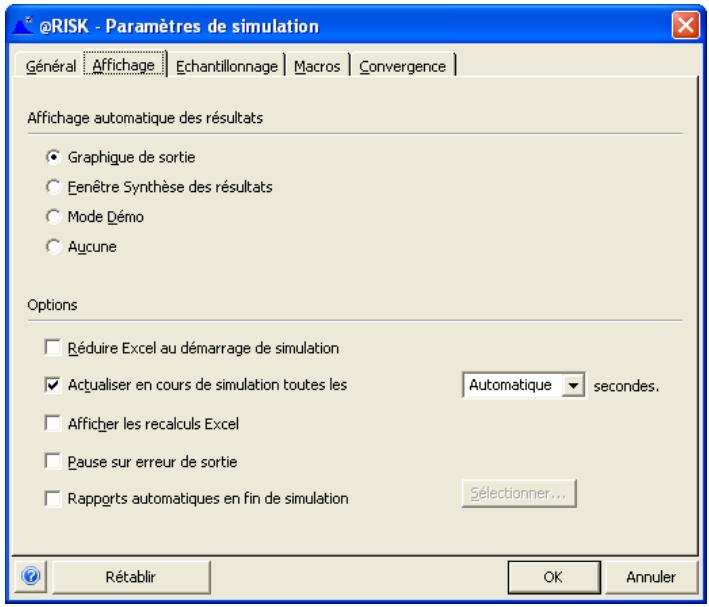
Les options d'Affichage automatique des résultats suivantes sont proposées :
- Graphique de sortie. Sous cette configuration, un graphique des résultats de simulation s'affiche automatiquement pour la cellule sélectionnée dans Excel :
- dès le démarr Actualiser en cours de simulation toutes les XXX secondes) ou
- en fin de simulation.
Sous cette option, le mode Parcours des résultats s'active aussi en fin d'exécution de la simulation. Si la cellule sélectionnée n'est pas une sortie ou entrée @RISK, un graphique de la première cellule de sortie du modèle s'affiche.
- Fenêtre Synthese des résultats. Sous cette option, la fenêtre Synthese des résultats s'ouvre en début d'exécution de la simulation (si l'actualisation en temps réel est activée sous l'option Actualiser en cours de simulation toutes les XXX secondes) ou en fin de simulation.
- Le mode Démo est un affichage prédéfini dans lequel @RISK actualise le classeur à chaque itération pour démontrer èle. Ce mode est utile à l'illustration de la simulation dans @RISK.
- Aucun. Aucune nouvelle fenêtre @RISK ne s'affiche en début ou fin de simulation.
Les paramètres suivants sont proposés sous le titre Options de l'onglet Affichage de la boîte de dialogue Paramètres de simulation :
- Réduire Excel au démarrage de simulation. Réduit la fenêtre Excel et toutes les fenêtres @RISK au démarrage d'une simulation. Il suffit de cliquer sur une fenêtre dans la barre de tâches pour la réafficher en cours de simulation.
- Actualiser en cours de simulation toutes les XXX secondes. Cette option active ou désactive l'actualisation en temps réel des fenêtres @RISK ouvertes et définit la fréquence de cette actualisation. Sous le paramètre Automatique, @RISK sélectionna la fréquence d'actualisation en fonction du nombre d'iterations et de la durée d'exécution de chacune.
- Afficher les recalculs Excel active ou déactive l'actualisation de l'affichage de la feuille de calcul en cours de simulation. À chaque iteration d'une simulation, toutes les fonctions de distribution sont échantillonnées et la feuille de calcul est recalculée. Le paramètre Afficher les recalculs Excel permet d'afficher (case cochée) ou non (case non cochée) les résultats de chaque recalculat à l'écran. Par défaut, le paramètre n'est pas activé car la mise à jour de l'affichage à chaque iteration ralentit la simulation.
- ée dans une sortie. En cas d'erreur, la boîte de dialogue Pause sur erreur de sortie affiche la liste détaillée des sorties pour lesquelles une erreur a été générée lors de la simulation, ainsi que les cellules du tableau à l'origine de l'erreur.
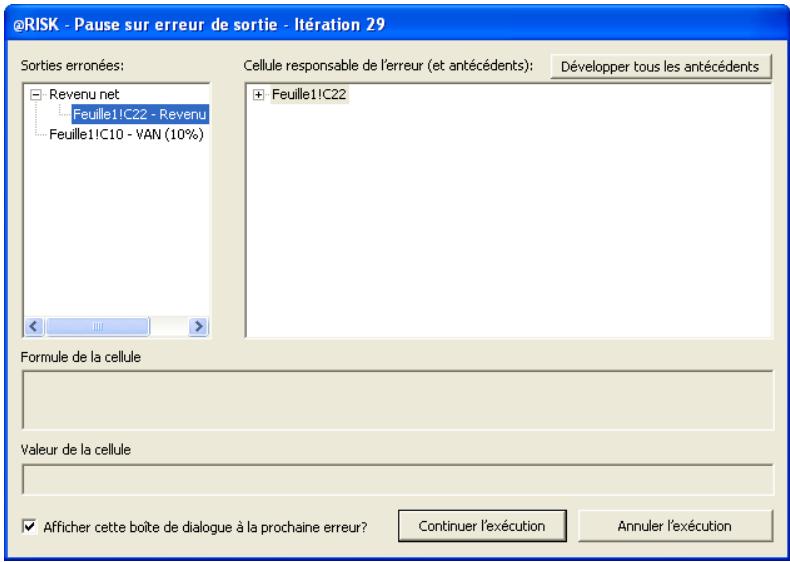
La boîte de dialogue Pause sur erreur de sortie affiche, du côté gauche, une liste de type Explorateur indiquant chaque sortie pour laquelle une erreur a été générée. Une cellule dont la formule a causé l'erreur s'affiche dans le champ de droite sur sélection d'une sortie dans la liste de gauche. @RISK identifie cette cellule en recherchant la sortie en question dans la liste des antécédents jusqu'à ce que la valeur n'en soit plus erronée. La ou les dernières cellules antécédentes renvoyant une erreur avant la valeur sans erreur sont identifiées comme cellules « responsables de l'erreur »
Vous pouvez également examiner les formules et valeurs des antécédents de la cellule « responsable de l'erreur » en développant cette cellule dans le volet droit de l'explorateur. Vous pouvez ainsi identifier les valeurs soumises à la formule problématique. Par exemple, une formule pourrait renvoyer #VALEURS sous l'effet d'une combinaison de valeurs référencées par la formule. L'examen des antécédents de la formule responsable de l'error permet d'analyser ces valeurs référencées.
- Rapports automatiques en fin de simulation. Ce paramètre régit la sélection des rapports Excel à produire automatiquement en fin de simulation.
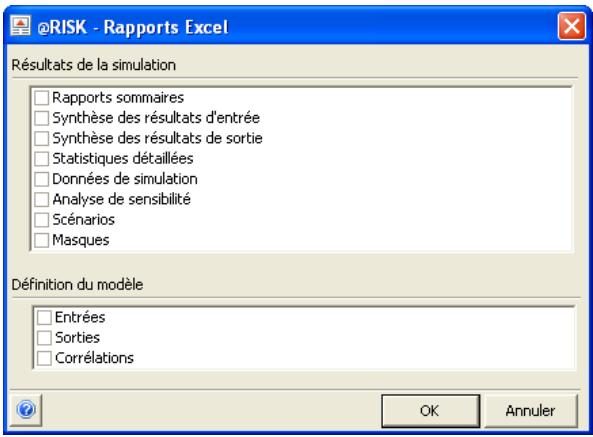
Pour plus de détails sur les rapports Excel disponibles, voir la commande Rapports Excel.
Onglet échantillonnage — commande paramètres de simulation
Spécifie la manière dont les échantillons sont prélevés et enregistrés lors d'une simulation.
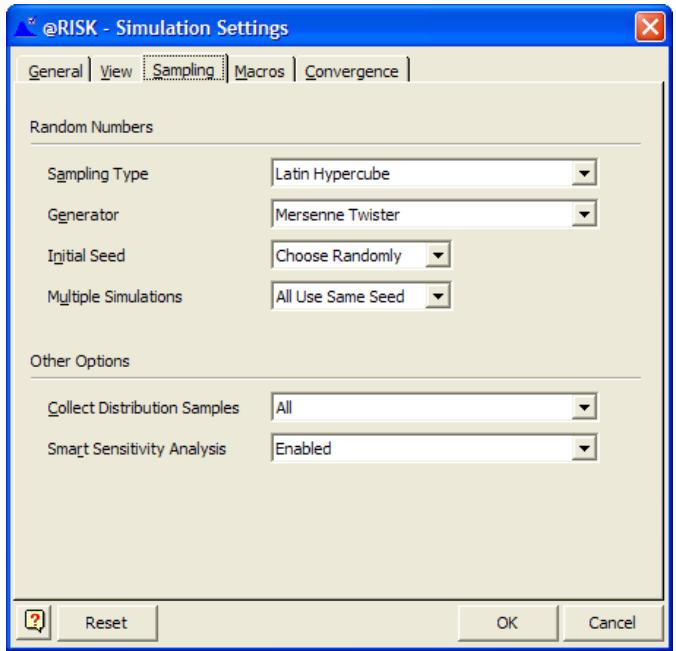
Les paramètres suivants sont proposés sous Nombres aléatoires :
- Type d'échantillonnage. Définit le type d'échantillonnage utilisé au cours d'une simulation @RISK. Les types d'échantillonnage varient selon la manière dont les échantillons sont prélevés sur l'étendue d'une distribution. L'échantillonnage Hypercube latin recrée avec précision les distributions de probabilités spécifiées par les fonctions de distribution en moins d'iterations que l'échantillonnage Monte Carlo.
Nous recommandons le type Hypercube latin (proposé par défaut) sauf si la situation de modélisation requiert spécifiquement l'échantillonnage Monte Carlo. Les détails techniques propres à chaque type d'échantillonnage sont présentés dans la section Annexes techniques.
- Latin Hypercube. Sélectionne l'échantillonnage stratifié.
- Monte Carlo. Sélectionne l'échantillonnage Monte Carlo standard.
Spécifie le générateur de nombres aléatoires à utiliser lors des simulations. @RISK5 propose les huit générateurs de nombres aléatoires (GNA) suivants :
RAN3I MersenneTwister MRG32k3a MWC KISS LFIB4 SWB KISS_SWB
Les paragraphes qui suivent décrivent brièvement ces générateurs :
1) RAN3I. GNA utilisé dans les versions @RISK 3 et 4. Il s'agit d'un générateur de marque Numerical Recipes, fondé sur un GNA portable « soustractif » de Knuth. 2) Mersenne Twister. Générateur par défaut de @RISK 5. Pour plus de détails à son sujet, consultez la page Web http://www.math.sci.hiroshima-u.ac.jp/~mat/MT/emt.html [en anglais]. 3) MRG32k3a. Solide générateur de Pierre L'Ecuyer. Pour plus de détails à son sujet, voir http://www.iro.umontreal.ca/~lecuyer/myftp/papers/streams00.pdf [en anglais]. 4) KISS. Le générateur KISS (Keep It Simple Stupid) est conçu pour combiner les deux générateurs de type multiplication avec retenue avec le registre 3 décalages SHR3 et le générateur congruentiel CONG, par addition et ou exclusif. Période d'environ 2123. 5) MWC. Le générateur MWC enchaine deux générateurs 16-bits de type multiplication avec retenue, x(n) = 36969x(n-1) + retenue, y(n) = 18000y(n-1) + retenue mod 216, a une période d'environ 260 et semble passer tous les tests de caractère aléatoire. L'un des générateurs autonomes les plus prisés - plus rapide que KISS, qui le contient. 6) LFIB4. Générateur Fibonacci déphasé: x(n) = x(n - r) op x(n - s), avec les x en ensemble fini sur lequel une opération binaire op s'opère, telle que +, - sur entiers mod 232, sur impairs, ou exclusif (xor) sur vecteurs binaires.
7) SWB. SWB est un générateur de type « subtract-with-borrow » développé pour offrir une méthode simple de production de périodes extrêmement longues :
x (n) = x (n - 2 2 2) - x (n - 2 3 7) - borrow 2 ^ 3 2
« borrow » est 0 ou 1 si le calcul x(n-1) cause un dépassement en arithmétique d'entiers 32 bits. Ce générateur a une très longue période, 27098(2480-1), d'environ 27578. Il semble passer tous les tests de caractère aléatoire, à l'exception du test d'espacement d'anniversaires, où il échoue pitoyablement, comme tous les générateurs Fibonacci déphasés utilisant +, - ou xor.
8) KISS_SWB. KISS+SWB a une période de >27700 et est vivement recommandé. SWB (Subtract-with-borrow) a le même comportement local qu'un Fibonacci déphasé avec +, -, xor - la retenue (borrow) apporte simplement une période beaucoup plus longue. SWB échoue au test d'espacement d'anniversaires, comme tous les générateurs Fibonacci et autres qui combinent simplement deux valeurs antérieures par +, -, ou xor. Ces échecs concernent un cas particulier : m=512 anniversaires dans une année de n=2^24 jours. Le test échoue également sous certains choix de m et n à déphasage >1000. Une précaution raisonnable consiste à combiner un générateur Fibonacci ou SWB doublement déphasé avec un type de générateur, à moins que le générateur n'utilise *, où la séquence de résultats entiers 32 bits impairs est très satisfaisante.
MWC, KISS, LFIB4, SWB et KISS+SWB proviennent tous de George Marsaglia (Florida State University). Voir ses commentaires sur http://www.lns.cornell.edu/spr/1999-01/msg0014148.html [en anglais].
Valeur de départ initiale. La valeur de départ initiale du générateur de nombres aléatoires, pour l'ensemble de la simulation, peut être :
- Automatique - @RISK sélectionne aléatoirement une nouvelle racine à chaque simulation.
- une valeur fixe définie par l'utilisateur - @RISK utilise la même racine à chaque simulation. Lorsque vous entrez une valeur fixe différente de zéro, la même série de nombres aléatoires se répète d'une simulation à l'autre. Les nombres aléatoires servent à prélever les échantillons dans les fonctions de distribution. Un même nombre aléatoire renvoie toujours la même valeur échantillonnée d'une fonction de distribution donnée. La racine doit être un nombre entier compris entre 1 et 2147483647.
La définition d'une valeur de départ fixe est utile au contrôle de l'environnement d'échantillonnage de la simulation. Elle permet par exemple de simuler deux fois le même modèle, en ne modifiant que les valeurs d'argument d'une fonction de distribution. Sous racine fixe, les mêmes valeurs sont échantillonnées à chaque itération, dans toutes les fonctions de distribution à l'exception de celle que vous avez modifiée. Les différences de résultats entre les deux exécutions découlent ainsi directement de la modification des valeurs d'argument de la fonction de distribution isolée.
- Simulations multiples. Spécifie la racine utilisée quand @RISK exécute des simulations multiples. Les options suivantes sont proposées :
- Même racine pour toutes spécifie que la même racine doit être utilisée de simulation en simulation quand @RISK exécute
- Racines différentes régit l'usage d'une racine différente à chaque simulation lors de l'exécution de simulations multiples.
Si une racine fixe est définie et que l'option Simulations multiples — Racines différentes est sélectionnée, chaque simulation applique une racine différente mais la même série de valeurs est utilisée à chaque réexécution de la simulation. Les résultats sont ainsi reproductibles d'une simulation à l'autre.
Remarque: La « valeur de départ initiale » configurée sous l'onglet Échantillonnage neffecte que les nombres aléatoires générés pour les distributions en entrée sans racine indépendante spécifiée par la fonction de propriété RiskSeed. Les distributions en entrée assorties de RiskSeed ont toujours leur propre flux reproducible de nombres aléatoires.
Autres options d'échantillonnage
Les paramètres suivants se configurent aussi sous l'onglet Échantillonnage :
- Collecte d'échantillons de distribution. Spécifie la manière dont @RISK doit collecter les échantillons aléatoires prélevés dans les fonctions de distribution en entrée en cours de simulation. Les options suivantes sont proposées :
- Tous. Spécifie la collecte d'échantillons pour toutes les fonctions de distribution en entrée.
- Entrées marquées de la propriété Collect. Spécifie la collecte d'échantillons pour les seules distributions en entrée assorties de la propriété Collect (par inclusion de la fonction de propriété RiskCollect dans la distribution). Les analyses de sensibilité et de scenario ne considérant que les distributions marquées de la propriété Collect.
- Aucun. Élimine la collecte d'échantillons en cours de simulation. En l'absence de collecte d'échantillons, les analyses de sensibilité et de scenario ne sont pas disponibles parmi les résultats de la simulation. Aucune statistique n'est du reste fournie sur les échantillons prélevés pour les fonctions de distribution en entrée. La sélection de cette option accélère cependant la vitesse d'exécution des simulations et permet parfois l'exécution de simulations volumineuses compteant de nombreuses sorties sur un système à mémoire limitée.
- Analyse de sensibilité intelligente Active ou désactive l'analyse de sensibilité intelligente. Pour plus de détails sur l'analyse de sensibilité intelligente et les situations où il convient de la désactiver, voir la commande Sensibilités.
- Actualiser les fonctions statistiques. Spécifie le moment où les fonctions statistiques @RISK (RiskMean, RiskSkewness, etc.) doivent s'actualiser lors d'une simulation. Dans la plupart des cas, il n'est pas nécessaire d'actualiser les statistiques avant la fin de la simulation et l'affichage des statistiques finale dans Excel. Si les calculs du modèle exigent cependant le renvoi d'une nouvelle statistique à chaque itération (pour un calcul de
convergence définie à l'aide de formules Excel, par exemple), il convient de sélectionner l'option À chaque itération.
Onglet macros — commande paramètres de simulation
Permet de spécifier l'exécution d'une macro Excel avant, pendant ou après une simulation.
Le paramètre Exécuter une macro Excel permet l'exécution des macros du tableau en cours de simulation @RISK. Les options suivantes sont proposées :
- Avant chaque simulation. La macro spécifiée s'exécute avant chaque simulation.
- Avant le recalcul de chaque itération. La macro spécifiée s'exécute avant que @RISK ne place les nouvelles valeurs échantillonnées dans le modèle, et avant le recalcul d'Excel en fonction de ces valeurs.
- Après le recalcul de chaque itération. La macro spécifiée s'exécute après l'échantillonnage et le recalcul de la feuille par @RISK, mais avant le stockage des valeurs de sortie. La macro AfterRecalc peut actualiser les valeurs des cellules de sortie @RRISK. Les rapports et calculs @RISK utilisent ces valeurs et pas les résultats du recalcul Excel.
- Après chaque simulation. La macro spécifiée s'exécute après chaque simulation.
L'exécution des macros peut intervenir à l'un quelconque ou à chacun de ces moments possibles de la simulation. Cette fonction permet d'exécuter des calculs tributaires d'une macro au cours d'une simulation. Les optimisations, calculs de « bouclage » itératif et calculs nécessitant de nouvelles données provenant de sources externes en sont quelques exemple. De plus, une macro peut inclure des fonctions de distribution @RISK échantillonnées durant l'exécution de la macro. Le nom de macro entré doit être « complet »: il doit contenir l'adresse intégrale (y compris le nom de fichier) de la macro à exécuter.
Il n'existe aucune restriction sur les opérations exécutées par la macro à chaque itération. Il convient cependant d'éviter les macrocommandes dont l'exécution fermerait la feuille de calcul en cours de simulation, quitterait Excel, etc.
@RISK comprend une interface de programmation par objets (API), qui permet l'élaboration d'applications personnalisées. Cette interface est décrite dans le fichier d'aide du Kit de développement @RISK 5.5 pour Excel, accessible à travers le menu d'aide @RISK.
Onglet convergence — commande paramètres de simulation
Définit les paramètres de surveillance de convergence des résultats de simulation.
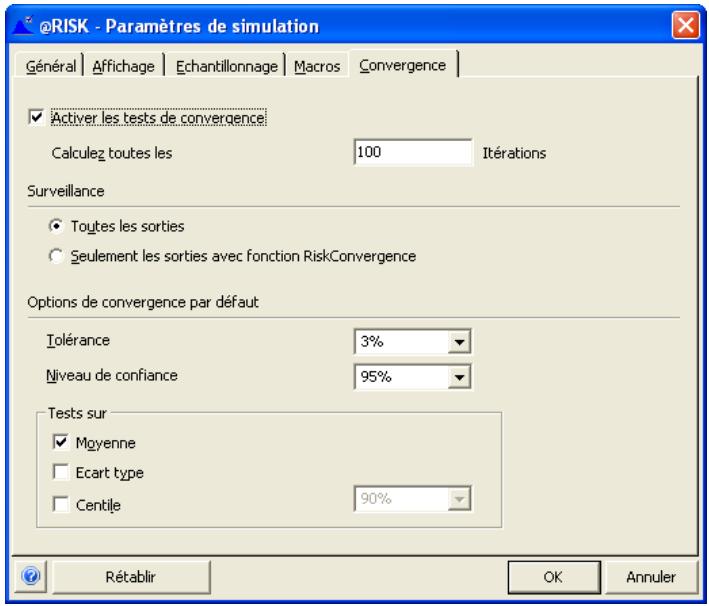
Les paramètres de l'onglet Convergence déterminent le mode de surveillance de convergence en cours de simulation. La surveillance de convergence suit la variation des statistiques relatives aux distributions de sortie au fur et à mesure des itérations de la simulation.
Plus le nombre d'iterations exécutées est élevé, plus les distributions de sortie générées deviennent « stables ». Cette stabilité se reflète dans la moindre variation des statistiques relatives aux distributions à mesure de la progression de la simulation. Le nombre d'iterations nécessaire à la stabilité des distributions de sortie varie en fonction du modèle et de ses fonctions de distribution.
La surveillance de convergence permet d'assurer l'exécution d'un nombre d'iterations suffisant, mais pas excessif. La fonction est particulièrement utile dans le cas des modèles complexes longs à recalculer.
La surveillance de convergence augmente la durée d'exécution de la simulation. Pour une simulation rapide avec nombre d'iterations prédéfini, désactivez-la.
La fonction de propriété RiskConvergence permet aussi de gérer le test de convergence de sortie individuelle. Les tests de convergence régis par les fonctions RiskConvergence de la feuille de calcul sont indépendants de ceux paramétrés sous l'onglet Convergence. La fonction RiskConvergenceLevel renvoie le niveau de convergence d'une cellule de sortie à laquelle elle fait reference. Qui plus est, la simulation s'interrompt si une fonction RiskStopRun passe une valeur d'argument VRAIE, indépendamment de l'état des tests de convergence paramétrés sous l'onglet Convergence.
Les Options de convergence par défaut suivantes sont proposées :
- Tolerance - Spécifie la tolérance admise pour la statistique testée. Les paramètres ci-dessus configurent par exemple l'estimation de la moyenne de chaque sortie simulée dans une marge de 3% de sa valeur réelle.
- Niveau de confiance - Spécifie le niveau de confiance relatif à l'estimation. Par exemple, les paramètres ci-dessus spécifient que l'estimation de la moyenne de chaque sortie simulée (dans la marge de tolérance définie) doit être exacte 95% du temps.
- Tests sur - Spécifie les statistiques de sortie à tester.
Si le paramètre Nombre d'iterations est fixé sur Auto dans la boîte de dialogue Paramètres de simulation, @RISK interrompt automatiquement une simulation lorsque la convergence est atteinte pour toutes les sorties de simulation entrées.
La fenêtre Synthèse des résultats affiche l'état de convergence lors de l'exécution d'une simulation sous activation de la surveillance de convergence. La première colonne de la fenêtre révèle l'état de chaque sortie (sous forme de valeur comprise entre 1 et 99). OK indique la convergence.
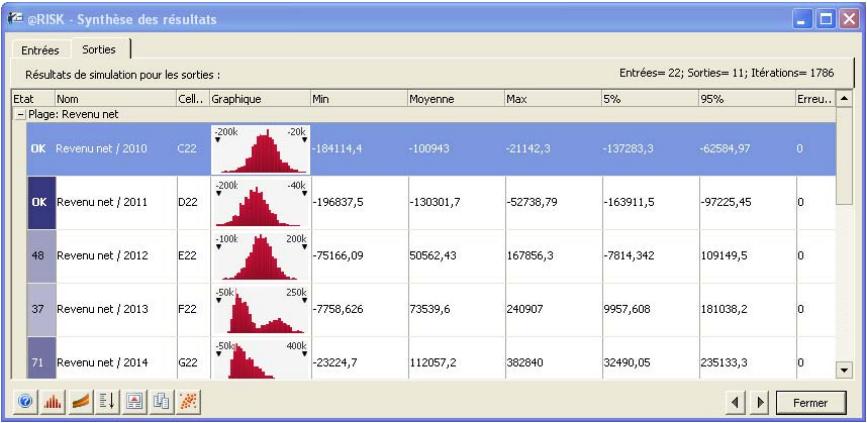
Suivi de convergence dans la fenêtre Synthèse des résultats
Commande demarrer la simulation
Démarrez l'exécution d'une simulation.
Cliquez sur l'icône Démarrer la simulation lance une simulation conforme aux paramètres définis.
Une fenêtre de progression s'affiche pendant les simulations. Ses icônes permettent d'exécuter, interrompre momentanément ou abandonner une simulation, ainsi que d'activer ou désactiver l'actualisation en temps réel des graphiques/rapports et les recalculs Excel.
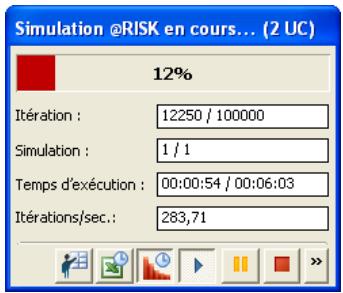
Moniteur de performance
Pour activer ou désactiver l'option Actualiser l'affichage, appuyez sur pendant la simulation.
Le bouton flèche, dans le coin inférieur droit de la fenêtre de progression, affiche le Moniteur de performance. Ce moniteur présente une information d'état complémentaire au sujet de chaque UC utilisée lors d'une simulation.
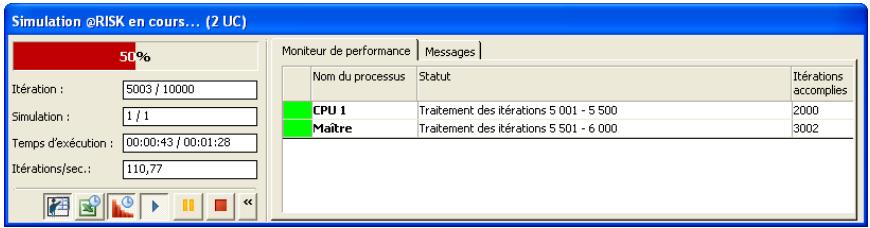
Des messages de commande peuvent aussi s'afficher, pour accélérer la réalisation de simulations longues.
Actualisation en temps réel
Si le paramètre de simulation Actualiser en cours de simulation toutes les XXX secondes est sélectionné, toutes les fenêtres @RISK ouvertes s'actualisent pendant la simulation. L'actualisation de la fenêtre @RISK - Synthèse des résultats est particulièrement utile. Les petites vignettes graphiques de cette fenêtre représentent en quelque sorte une « tableau de bord » suivant la progression de la simulation.
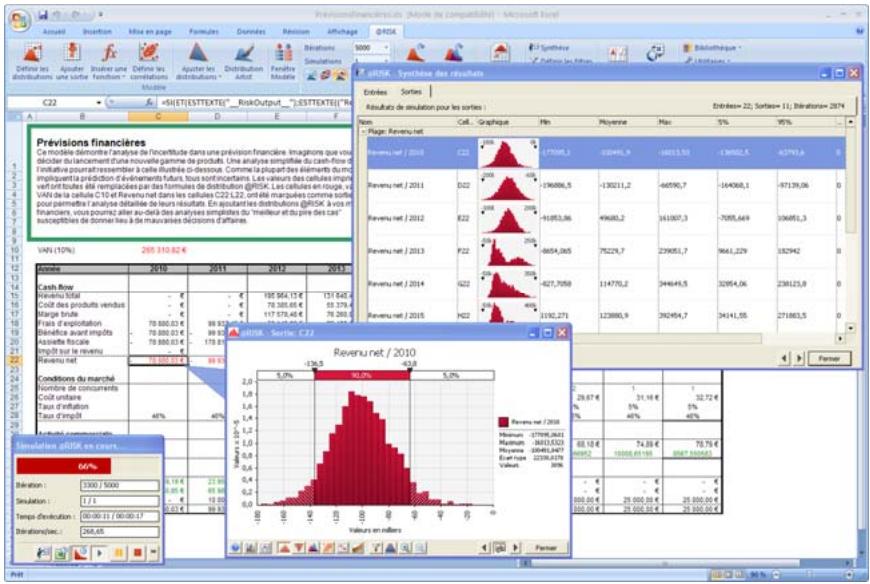
Simulation — analyses avancées
Les versions @RISK Professional et Industrial proposent trois « analyses avancées » pour vos modèles : Analyse de sensibilité avancée, Analyse de contrainte et Valeur cible. Ces analyses avancées peuvent servir à la conception d'un modèle, à sa vérification ou à l'obtention de nombreux résultats hypothétiques.
Chacune génère son propre groupe de rapports dans Excel, illustrant les résultats de l'analyse exécutée. Chacune fait cependant appel aux simulations multiples @RISK standard pour la génération de ses résultats. Ces résultats peuvent donc également être examinés dans la fenêtre @RISK - Synthèse des résultats. L'approche est utile lorsque vous désirez générer un graphique de résultats non inclus dans les rapports Excel, ou examiner en profondeur les données de l'analyse.
Paramètres de simulation des analyses avancées
Sauf Nombre de simulations, les paramètres définis dans la boîte de dialogue Paramètres de simulation sont ceux utilisés pour chacune des analyses avancées de @RISK. Les analyses avancées impliquent souvent de très nombreuses simulations. Veillez par conséquent à revoir vos paramètres de simulation pour limiter vos durées d'analyse. Pour tester et vérifier la configuration d'une analyse avancée, CHOISSEZ par exemple un Nombre d'iterations relativement faible. Rétablissez ensuite le Nombre d'iterations nécessaire à l'obtention de résultats de simulation stables et exécutez la pleine Analyse de sensibilité avancée, Analyse de contrainte ou Valeur cible.
Configure et exécute une analyse valeur cible @RISK.
Valeur cible permet la recherche d'une statistique simulée particulière pour une cellule (la moyenne ou l'écart type, par exemple) à travers la modification de la valeur d'une autre cellule. La configuration d'une recherche Valeur cible @RISK ressemble fort à celle standard proposée dans Excel. Contrairement à Valeur cible d'Excel, toutefois, Valeur cible de @RISK fait appel à de multiples simulations pour identifier la valeur de cellule ajustable produisant le résultat et poulu.
Lorsque vous connaissez la valeur statistique désirée pour une sortie mais que vous ignorez la valeur en entrée nécessaire à l'obtention de cette valeur statistique, faites appel à la fonction Valeur cible. L'entrée peut être une cellule quelconque de votre classeur Excel. La sortie doit être une cellule représentant une sortie de simulation @RISK - c.-à-d. une cellule contenant une fonction RiskOutput(). L'entrée doit être un antécédent de la cellule de sortie ciblée. Lors de la recherche, @RISK fait varier la valeur de l'entrée et exécute une simulation complète. Le processus est repété jusqu'à atteindre la valeur statistique de simulation désirée pour la sortie.
Valeur cible s'invoque à travers la commande Valeur cible sous l'icône Analyses avancées de la barre d'outils @RISK.
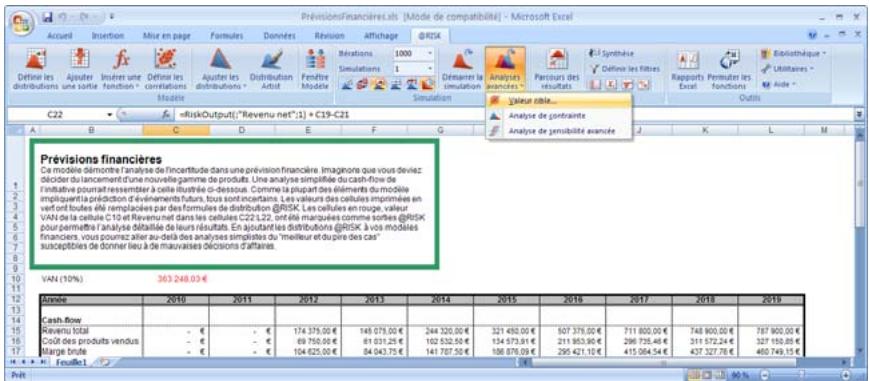
Boîte de dialogue valeur cible — commande valeur cible
Définit la cible et la cellule variable de l'analyse Valeur cible.
Les options suivantes sont proposées dans la boîte de dialogue Valeur cible @RISK :
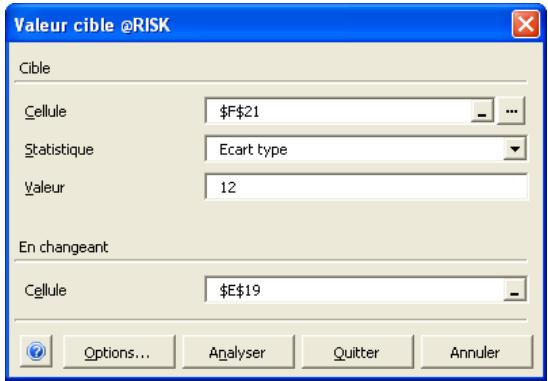
Les options du volet Cible décrivent la cible à atteindre :
- Cellule - Identifie la référence de cellule de la sortie dont vous essayez de fixer la statistique de simulation sur la valeur entrée. Cette cellule doit être une cellule de sortie @RISK. Si la cellule indiquée ne contient pas une fonction RiskOutput(), vous serez invité à l'y ajouter. Le bouton de sélection..., en regard de l'entrée Cellule, affiche la liste des sorties courantes parmi lesquelles vous pouvez opérer votre sélection :
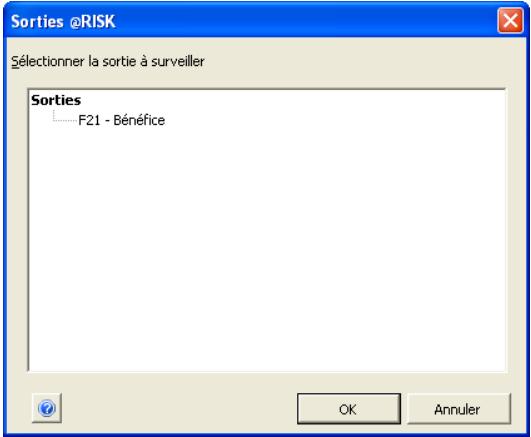
- Statistique - Permet de choisir ent, Moyenne, Mode, Médiane, 5e centile, 95e centile, Asymétrie, Écart type et Variance.
- Valeur - Spécifie la valeur sur laquelle vous pouvez
L'option En changeant identifie la cellule unique à faire varier pour que les options définies pour la Cible (Statistique pour Cellule) se rapprochent de la Valeur. La Cellule doit être dépendante de la cellule variable (En changeant) - Valeur cible ne pourrait sinon tracer de solution.
Boîte de dialogue options de valeur cible — commande valeur cible
Définit les options de l'analyse Valeur cible.
La boîte de dialogue Options de Valeur cible sert à définir les paramètres susceptibles d'affecter le succès et la qualité de la solution Valeur cible. Pour l'ouvrir, cliquez sur le bouton Options de la boîte de dialogue Valeur cible.
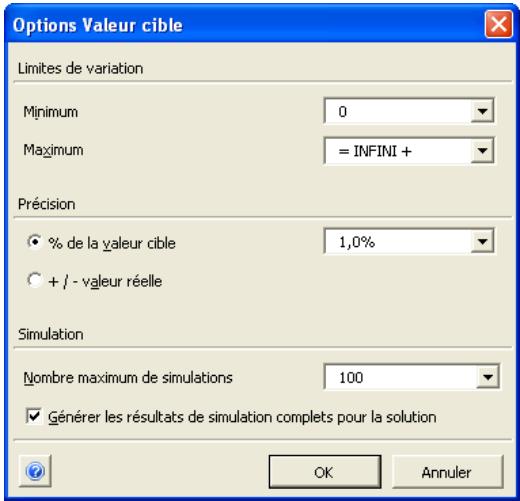
Le volet Limites de variation propose les options suivantes :
- Minimum - Permet de définir la valeur minimum à utiliser pour la cellule désignée dans le champ de la cellule variable (En changeant). Valeur cible recherche à « encadrer » une solution en présumant qu'il en existe une entre les valeurs Minimum et Maximum.
- Maximum - Permet de définir la valeur maximum à utiliser pour la cellule désignée dans le champ de la cellule variable (En changeant). Valeur cible recherche à « encadrer » une solution en présumant qu'il en existe une entre les valeurs Minimum et Maximum.
- Précision - Détermine la proximité de la solution par rapport à la cible. Cette entrée peut être considérée telle une « plage », ajustant
1) % de la valeur cible - Spécifie la précision sous forme de pourcentage de la valeur cible (Valeur). 2) +/- valeur réelle - Spécifie la précision sous forme de différence maximum entre la cible et la valeur de la statistique de Cellule trouvée par Valeur cible.
- ution de toutes les simulations, l'exécution s'interrompt et la boîte de dialogue État de Valeur cible @RISK s'affiche à l'écran.
- Générer les résultats de simulation complets pour la solution - Si cette option est sélectionnée, après avoir trouvé une solution, Valeur cible exécute une simulation encore avec la valeur trouvée pour la cellule variable (En changeant). Les statistiques de cette simulation s'affichent dans la fenêtre @Risk - Synthè sait ce remplacement.
Exécuté l'analyse valeur cible.
Lorsque vous cliquez sur Analyser, Valeur cible procède comme suit jusqu'à couvrir la valeur statistique ciblée ou jusqu'à l'execution du nombre maximum de simulations :
1) Une nouvelle valeur s'introduit dans la cellule en entrée changeante. 2) Une simulation complète de tous les classeurs ouverts s'exécute selon les paramètres courants de la boîte de dialogue Paramètres de simulation @RISK. 3) @RISK enregistre la statistique de simulation sélectionnée dans le champ Statistique pour la sortie identifiée dans le champ Cellule. Cette valeur statistique est comparée à la valeur entrée dans le champ Cible pour déterminer si la cible est atteinte (dans la plage de précision définie).
Si une solution est trouvée dans la plage de précision demandée, Valeur cible affiche une boîte de dialogue d'état. Vous pouvez y désirer de remplacer le contenu de la cellule variable (En changeant) par la solution trouvée. Si oui, le contenu intégral de la cellule est remplacé par la valeur de la solution. La formule ou les valeurs qui occupaient précédemment la cellule en seront perdues.
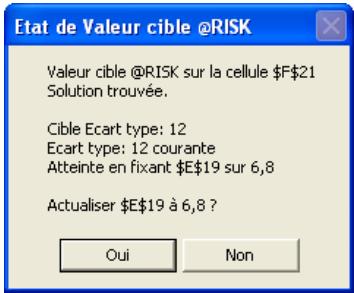
Il est possible que Valeur cible converge sur une cible, mais pas dans les limites de précision demandées. Dans ce cas, Valeur cible vous proposera la meilleure solution trouvée.
Sélection des valeurs en entrée d'une recherche Valeur cible @RISK
Valeur cible @RISK procède selon une approche à deux niveaux pour converger sur la cible :
1) En l'absence d'encadrement défini par Minimum et Maximum, Valeur cible recherche à encadrer la valeur cible par expansion géométrique autour de la valeur originale. 2) Lorsqu'une solution est encadrée, Valeur cible applique la méthode Ridders de recherche des racines. Selon la méthode Ridders, Valeur cible commence par simuler le modèle avec une valeur en entrée au milieu de la plage encadrée. L'analyse factorise ensuite la fonction exponentielle unique apte à transformer la fonction résiduelle en ligne droite. L'approche présente d'importants avantages : elle assure le strict maintien des valeurs en entrée testées à l'intérieur du cadre et aide Valeur cible à rechercher la solution en aussi peu de cycles que possible (non négligeable quand on considère que chaque « cycle » représente une simulation complète du modèle!).
En l'absence de solution
Il peut arriver que Valeur cible ne trouve pas de solution convergente. Certaines solutions sont tout simplement impossibles, ou le modèle se comporte de manière tellement imprévisible que l'algorithme de racine ne peut pas converger sur une solution. Vous pouvez faciliter la convergence :
- en lançant l'analyse Valeur cible avec une valeur différente dans la cellule variable. Comme le processus d'iteration commence par « deviner » autour de la valeur originale de la cellule changeante, le besoin d'une autre valeur peut être utile.
- en changeant l'encadrement défini. La définition d'un Minimum et d'un Maximum de cellule variable dans la boîte de dialogue Options facilite la tâche de Valeur cible.
Remarque: L'analyse Valeur cible n'est pas conçue pour les modèles à simulations multiples. Pour les fonctions RiskSimtable, la première valeur de la table est utilisée pour toutes les simulations.
Commande analyse de contrainte
Configure et exécute une Analyse de contrainte.
L'analyse de contrainte permet l'analyse d'effets de contrainte sur les distributions @RISK. La contrainte d'une distribution restreint l'échantillonnage aux valeurs comprises entre les centiles spécifiés. La contrainte peut aussi s'effectuer en spécifiant une nouvelle distribution « de contrainte » échantillonnée à la place de la distribution originale du modèle. L'analyse de contrainte permet la sélection de plusieurs distributions @RISK et l'exécution de simulations sous contrainte commune de ces distributions en une seule simulation ou séparément, en plusieurs simulations. Par la contrainte des distributions sélectionnées, vous pouvez analyser différents scénarios sans changer le modèle.
En fin de simulation, l'Analyse de contrainte renvoie un ensemble de rapports et graphiques utiles à l'analyse des effets de la contrainte de certaines distributions sur une sortie de modèle sélectionnée.
L'Analyse de contrainte s'invoque à travers la commande Analyse de contrainte, sous l'icône Analyses avancées de la barre d'outils @RISK.
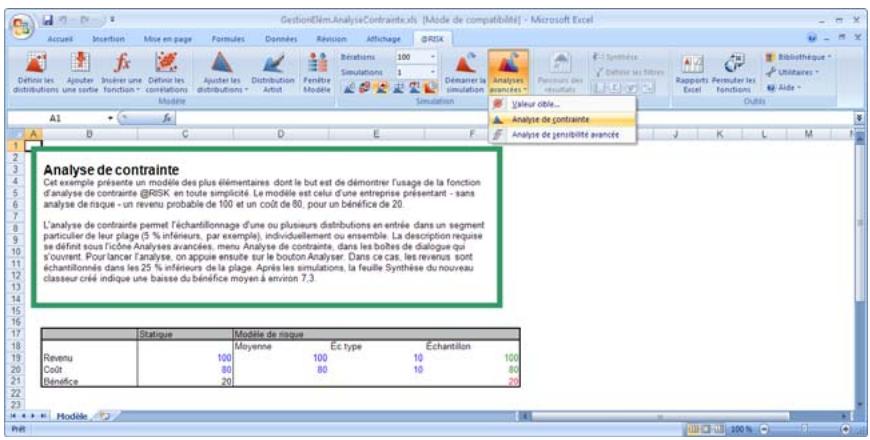
Boîte de dialogue analyse de contrainte — commande analyse de contrainte
Définit la cellule à surveiller et les entrées de l'analyse de contrainte.
La boîte de dialogue Analyse de contrainte sert à définir la cellule à surveiller lors de l'analyse, à dresser la liste des entrées à inclure et à lancer l'analyse.
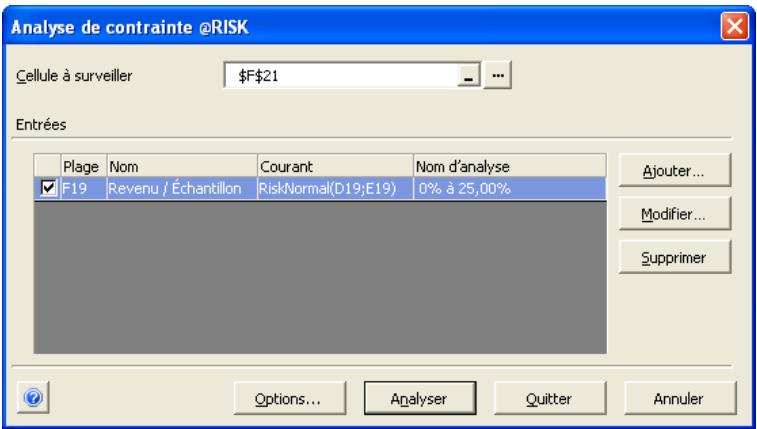
Les options de la boîte de dialogue Analyse de contrainte se décrivent comme suit :
- Cellule à surveiller - Cette cellule représente la sortie @RISK unique à surveiller sous l'effet de la contrainte des distributions @RISK spécifiées. La cellule à surveiller se spécifie par l'entrée d'une référence de cellule, en cliquant sur la cellule désirée, ou en cliquant sur le bouton.... Ce bouton renvoie une boîte de dialogue contenant la liste de toutes les sorties @RISK contenues dans les classeurs Excel actuellement ouverts. Le bouton de sélection..., en regard de l'entrée Cellule à surveiller, affiche la liste des sorties courantes parmi lesquelles vous pouvez opérer votre sélection :
La section Entrées permet d'ajouter, de modifier et de supprimer les distributions @RISK à soumettre ou non à contrainte. Les distributions spécifiées sont inscrites dans une liste contenant la plage, le nom @RISK, la distribution courante et un nom d'analyse modifiable.
- Ajouter et Modifier - Affichent la boîte de dialogue Définition d'entrée, pour la définition de la distribution @RISK ou série de distributions @RISK à soumettre à la contrainte. Vous pouvez ensuite sélectionner un échantillonnage faible, élevé ou personnalisé, ou spécifier une autre distribution ou formule de contrainte.
- Supprimer - Élimine complètement la ou les distributions @RISK sélectionnées dans la liste de l'analyse de contrainte. Pour exclure temporairement une distribution ou une série de distributions de l'analyse sans les supprimer, cliquez sur la case en regard des éléments de liste correspondants pour les désélectionner.
Boîte de dialogue définition d'entrée — commande analyse de contrainte
Définit les entrées de l'analyse de contrainte.
La boîte de dialogue Définition d'entrée sert à définir le mode de variation d'une entrée particulière d'analyse de contrainte.
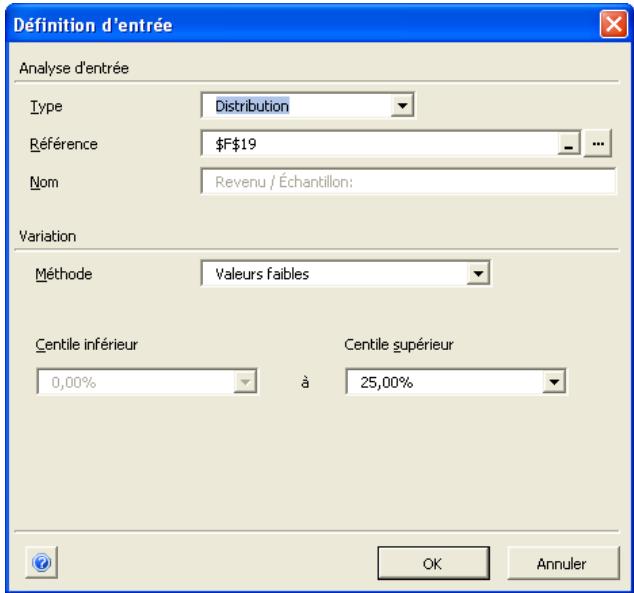
Les options de la boîte de dialogue Définition d'entrée se décrivent comme suit :
- Type - Pour l'analyse de contrainte, seules les distributions @RISK peuvent être sélectionnées comme entrées. La seule option de Type est donc Distributions.
- Référence - Sélectionne les distributions à soumettre à contrainte. Pour spécifier les distributions, tapez-en les références de cellule et sélectionnez une plage de cellules sur la feuille de calcul, ou cliquez sur le bouton... pour ouvrir la boîte de dialogue Fonctions de distribution @RISK et afficher ainsi toutes les distributions du modèle.
Les options Méthode de variation permettent la spécification d'une plage d'échantillonnage au sein de la ou des distributions de probabilités sélectionnées, ou l'entrée d'une autre distribution ou formule appelée à remplacer la ou les distributions sélectionnées pendant l'analyse.
- Valeurs faibles - Entre une plage d'échantillonnage BASSE, limitée au minimum par le minimum de la distribution. La plage inférieure par défaut est comprise entre 0 et 5%, pour un échantillonnage limite aux valeurs inférieures au 5e centile de la distribution. Rien n'empêche d'entrer un centile supérieur autre que 5%.
- Valeurs élevées - Entre une plage d'échantillonnage haute, limitée au maximum par le maximum de la distribution. La plage supérieure par défaut est comprise entre 95 et 100%, pour un échantillonnage limite aux valeurs supérieures au 95e centile. Rien n'empêche d'entrer un centile inférieur autre que 95%.
- Plage personnalisée - Permet la spécification de la plage de centiles de votre choix pour l'échantillonnage de la distribution.
- Autre fonction ou distribution - Permet l'entrée d'une autre fonction de distribution @RISK (ou formule Excel admise) appelée à remplacer la distribution sélectionnée pendant l'analyse de contrainte. Vous pouvez faire appel à l'Assistant Fonction d'Excel pour entraîr la distribution de substitution enclistuant sur l'icone prévue à droite de la zone de texte Distribution/Formule.
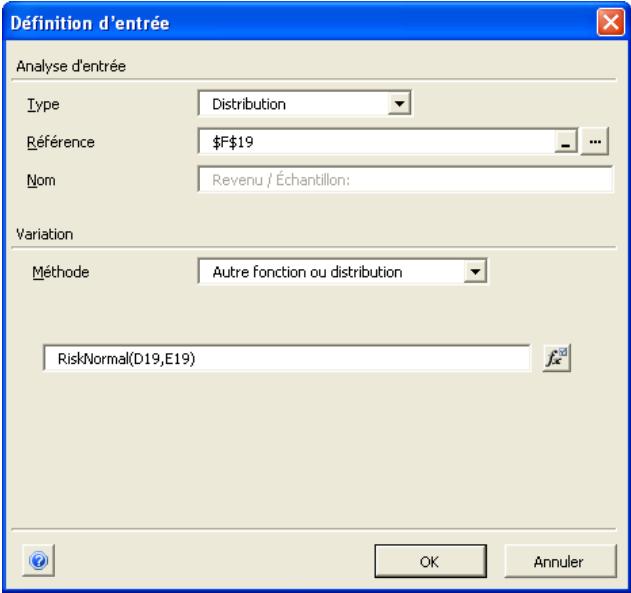
Boîte de dialogue options de contrainte — commande analyse de contrainte
Définit les options de l'Analyse de contrainte
La boîte de dialogue Options sert à définir la manière dont la contrainte doit être appliquée et les rapports ou graphiques à générer. Pour l'ouvrir, cliquez sur le bouton Options de la boîte de dialogue Analyse de contrainte.
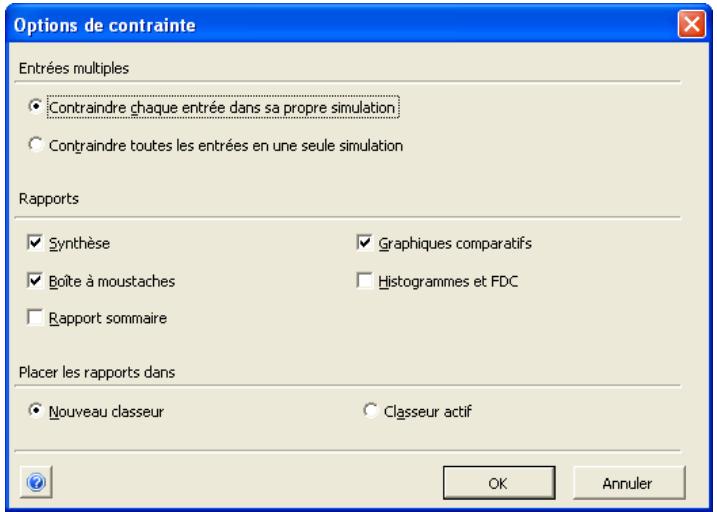
La section Entrées multiples régit la contrainte de toutes les distributions @RISK sélectionnées en une simulation, ou l'exécution d'une simulation distincte par distribution @RISK.
- Contraindre chaque entrée dans sa propre simulation – Spécifie l'exécution d'une simulation complète pour chaque plage de contrainte entrée. Le seul changement apporté au mode, à chaque simulation, sera la contrainte d'une seule entrée. Le nombre de simulations executées sera égal au nombre de plages de contrainte entrées.
- Contraindre toutes les entrées en une seule simulation - Spécifie l'exécution d'une simulation unique pour toutes les plages de contrainte entrées. Les résultats de la simulation combineront les effets de toutes les plages de contrainte.
La section Rapports permet de choisir les rapports et graphiques à générer au terme des simulations de contrainte. Les options suivantes sont proposées : Synthèse, Boîtes à moustaches, Graphiques comparatifs, Histogrammes, Fonctions de distribution cumulatives et Rapports sommaires. Pour plus de détails sur les rapports générés par l'Analyse de contrainte, voir plus bas la section Rapports.
Le volet Placer les rapports dans permet l'envoi des résultats dans le classeur actif ou dans un nouveau classeur.
- Nouveau classeur - Tous les rapports se placent dans un nouveau classeur
- Classeur actif - Tous les rapports se placent dans le classeur actif, avec le modèle.
Exécuter une analyse de contrainte.
Après avoir sélectionné la cellule à surveiller et au moins une distribution @RISK à soumettre à la contrainte, cliquez sur Analyser pour exécuter l'analyse. L'analyse exécute une ou plusieurs simulations limitant l'échantillonnage des distributions @RISK sélectionnées à la ou aux plages de contrainte spécifiées, ou substitue les distributions ou formules de contrainte définies. Les résultats des simulations s'organisent sur une feuille de synthèse et plusieurs graphiques d'analyse de contrainte.
Les résultats de l'analyse de contrainte sont également disponibles dans la fenêtre @RISK - Synthèse des résultats, où les effets de la contrainte sur les entrées @RISK peuvent être analysés en profondeur.
L'analyse de contrainte génère les rapports suivants :
Rapport de synthèse Boîtes à moustaches Graphiques comparatifs - Histogrammes - Fonctions de distribution cumulatives Rapports sommaires
Rapport de synthèse
Les rapports de synthèse décrivent les entrées contraintes et les statistiques correspondantes de la sortie surveillée : Moyenne, Minimum, Maximum, Mode, Écart type, Variance, Aplatissement, Asymétrie, 5e centile et 95e centile.
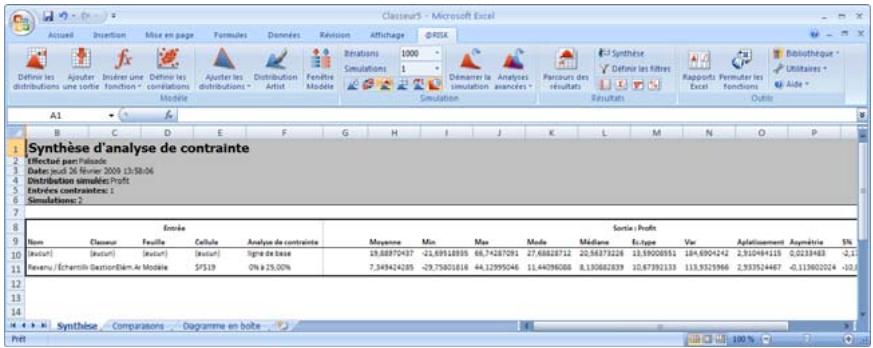
La boîte à moustaches donne une indication générale de la sortie surveillée, dont elle décrit la moyenne, la médiane et les centiles atypiques.
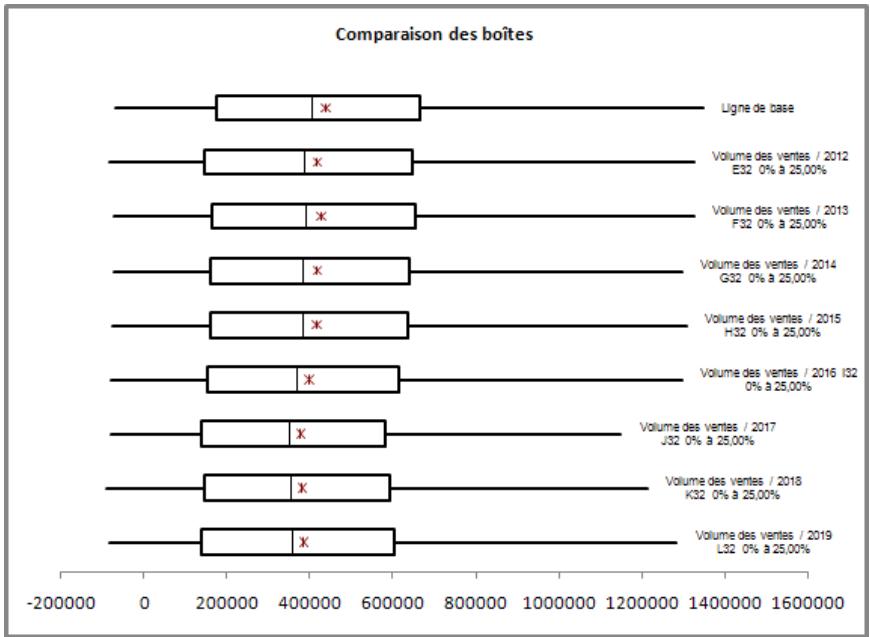
Les côtes gauche et droite de la boîte sont les indicateurs du premier et du troisième quartile. Le trait vertical, dans la boîte, représente la mediane, tandis que le X indique l'emplacement de la moyenne. La largeur de la boîte représente l'écart interquartile (ÉIQ). Cet écart est égal au point de données du 75e centile moins le point de données du 25e centile. Les traits horizontaux s'étendant de part et d'autre de la boîte indiquent le premier point de données inférieur à 1,5 fois l'écart interquartile sous le bord inférieur de la boîte, et le dernier point de données inférieur à 1,5 fois l'écart interquartile par-dessus le bord supérieur de la boîte. Les valeurs atypiques modérées, illustrées par les carrés vides, représentent les points de données compris entre 1,5 et 3 fois l'écart interquartile en dehors de la boîte. Les valeurs atypiques extrêmes, illustrées par les carrés pleins, représentent les points au-delà de 3 fois l'écart interquartile en dehors de la boîte.
Rapport sommaire
Un rapport sommaire présente une synthèse d'une page de l'analyse de contrainte dans son ensemble. Ce rapport est conçu pour n'occuper qu'une page de format ordinaire.
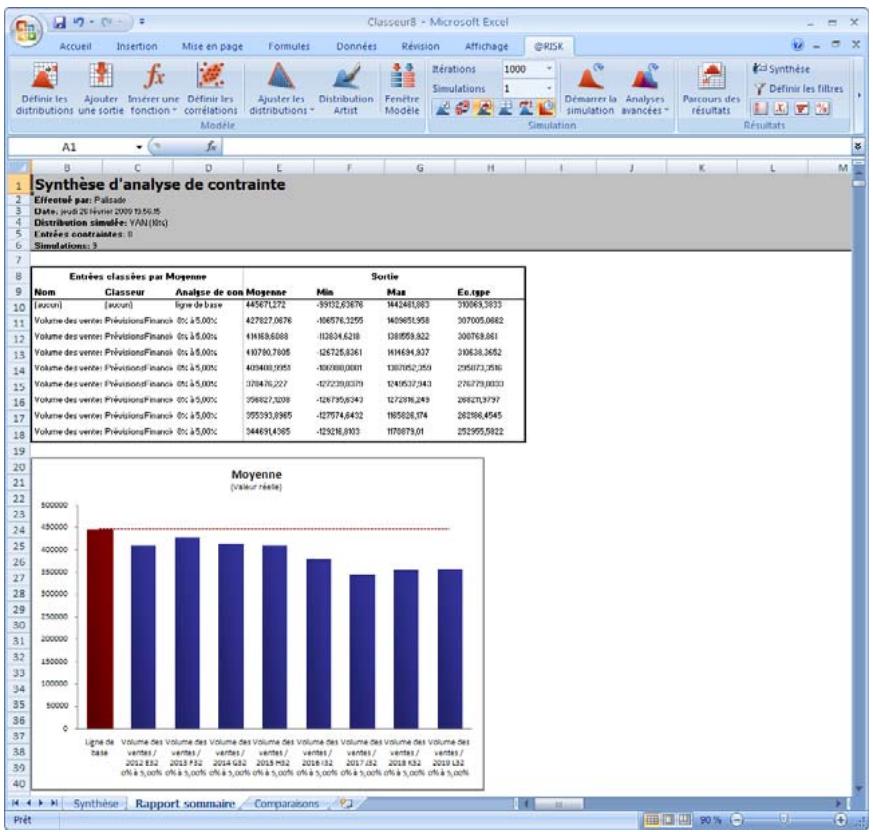
Les quatre graphiques comparatifs comparent la moyenne, l'écart type, le 5e centile et le 95e centile de chacune des entrées @RISK spécifiées (ou leur combinaison) et la simulation de ligne de base.
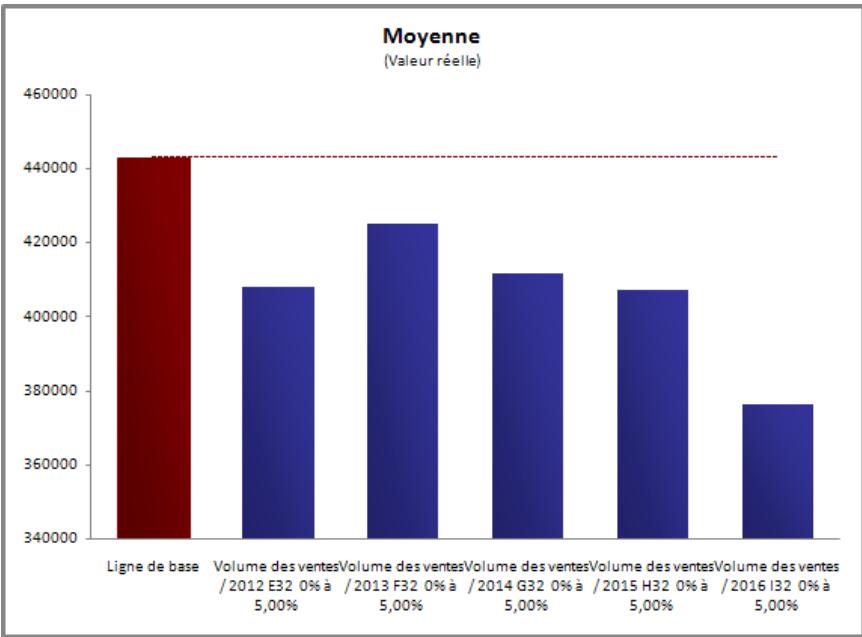
Les histogrammes sont des histogrammes @RISK standard de la sortie surveillée pour chacune des entrées (ou leur combinaison) soumises à contrainte et la simulation de ligne de base.
Lignede base
Synthèse cumulatif
Les FDC (fonctions de distribution cumulatives) sont des graphiques de densité cumulatifs croissants @RISK standard. Une FDC de synthèse est également produit pour toutes les entrées.
Lignede base
Commande analyse de sensibilité avancée
Configure et exécute une Analyse de sensibilité avancée.
L'analyse de sensibilité avancée permet de déterminer les effets d'entrées sur les sorties @RISK. Une entrée peut être soit une distribution @RISK, soit une cellule du classeur Excel. L'analyse de sensibilité avancée permet de sélectionner plusieurs distributions @RRISK, ou cellules de feuille de calcul, et d'exécuter des simulations d'essai en faisant varier ces entrées sur une plage. L'analyse de sensibilité avancée exécute une simulation complète à chacune des valeurs possibles d'une entrée, tout en suivant les résultats de la simulation à chaque valeur. Les résultats présentent alors la variation des résultats de simulation en fonction de celle de la valeur d'entrée. À l'image de l'analyse de sensibilité @RISK standard, l'analyse de sensibilité avancée présente la sensibilité d'une sortie @RISK à l'entrée spécifique.
Elle peut servir à l'évaluation de la sensibilité d'une sortie @RISK aux distributions en entrée d'un modèle. Lors du test d'une distribution @RISK, @RISK exécute une série de simulations pour l'entrée. À chaque simulation, la distribution en entrée reçoit une valeur distincte sur la plage min-max de la distribution. Ces valeurs de « pas » représentent généralement différentes valeurs de centile de la distribution en entrée.
L'analyse de sensibilité avancée s'invite à travers la commande Analyse de sensibilité avancée sous l'icône Analyses avancées de la barre d'outils @RISK.
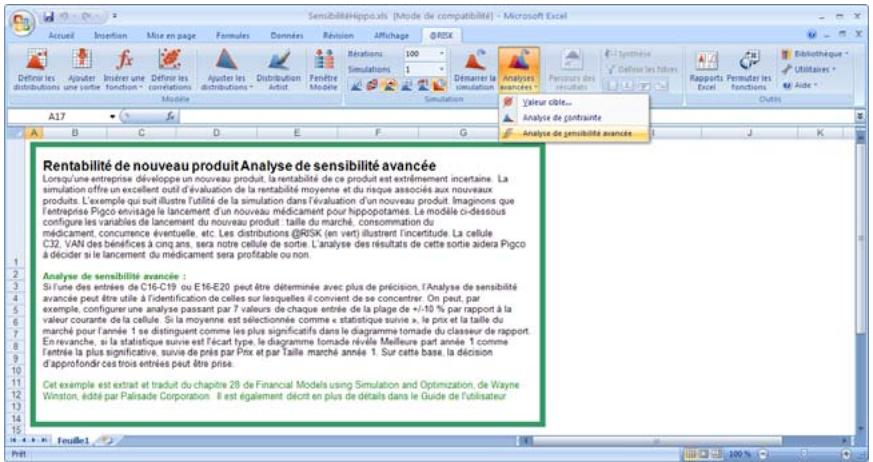
Boîte de dialogue analyse de sensibilité avancée — commande analyse de sensibilité avancée
Définit la cellule à surveiller et les entrées d'une analyse de sensibilité avancée.
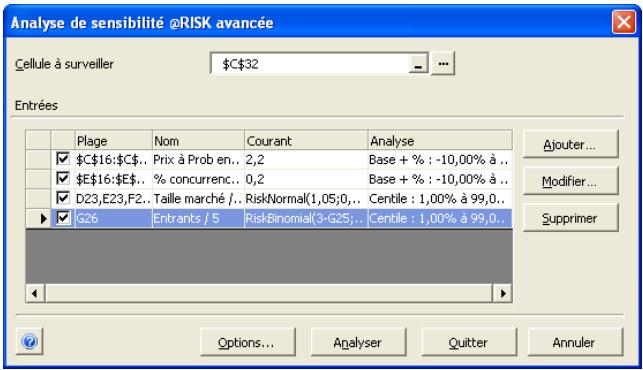
Les options de la boîte de dialogue Analyse de sensibilité avancée se décrivent comme suit :
- Cellule à surveiller — Cette cellule représente la sortie @RISK unique à surveiller, tandis que les simulations individuelles s'exécutent, à différentes valeurs d'entrée possibles. La cellule à surveiller se spécifie par l'entrée d'une référence de cellule, en cliquant sur la cellule désirée ou en cliquant sur le bouton.... Ce bouton renvoie une boîte de dialogue contenant la liste de toutes les sorties @RISK ouvertes dans les classeurs Excel.
Les options de la section Entrées permettent d'ajouter, de modifier et de supprimer les cellules de feuille de calcul et distributions @RISK à inclure ou non dans l'analyse. Les cellules et distributions spécifiées sont inscrites dans une liste contenant la plage, le nom @RISK, la distribution courante et un nom d'analyse modifiable.
- Ajouter et Modifier - Affichent la boîte de dialogue Définition d'entrée, pour la définition d'une distribution @RISK ou cellule de feuille de calcul unique ou d'une série de distributions @RISK ou cellules de feuille de calcul à analyser.
- Supprimer - Supprime complètement les entrées sélectionnées de l'analyse de sensibilité avancée. Pour exclure temporairement une entrée ou un groupe d'entrées de l'analyse sans les supprimer, cliquez sur la case de la ligne correspondante de la liste pour déselectionner l'entrée ou les entrées en question.
Définition d'entrée — commande analyse de sensibilité avancée
Définit les entrées d'une analyse de sensibilité avancée.
La boîte de dialogue Définition d'entrée permet de spécifier le type d'une entrée, son nom, une valeur de base et les données décrivant les valeurs possibles de l'entrée à tester dans l'analyse de sensibilité. Une simulation complète s'exécutera à chaque valeur spécifique pour une entrée. Les options de la boîte de dialogue Définition d'entrée sont décrites en détail dans cette section.
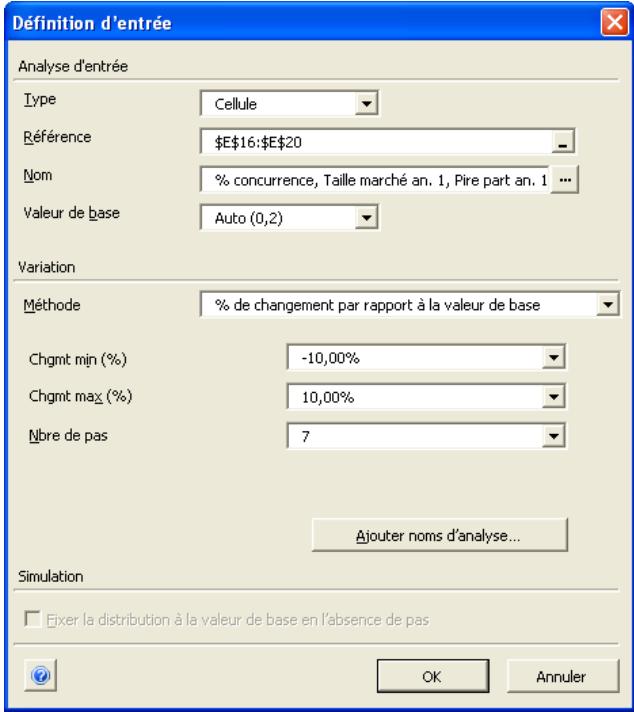
La boîte de dialogue Définition d'entrée propose les options suivantes :
- Type. Spécífie le type d'entrée (distribution ou cellule de feuille de calcul). Les entrées d'une analyse de sensibilité avancée peuvent être soit des distributions @RISK introduites dans les formules d'une feuille de calcul, soit des cellules de feuille de calcul.
- Référence. Spécifie l'emplacement de l'entrée ou des entrées dans la feuille de calcul. Pour la sélection de distribution(s), cliquez sur le bouton... pour ouvrir la boîte de dialogue Fonctions de distributions @RISK et acceder ainsi à la liste de toutes les distributions comprises dans toutes les feuilles de calcul ouvertes.
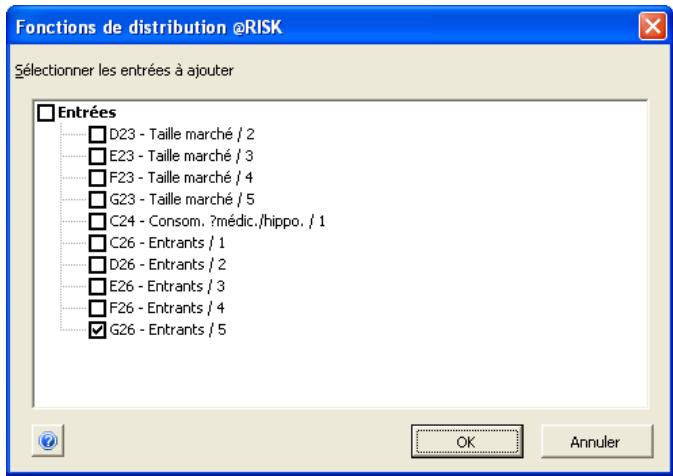
- Nom. Nommez la ou les entrées. Si vous sélectionnez des distributions, le nom @RISK existant de chaque entrée s'affiche. Pour utiliser un autre nom, changez simplement l'appellation @RISK en ajoutant une fonction RiskName à la distribution dans Excel ou en modifiant le nom dans la fenêtre @RISK - Modèle.
Si vous sélectionné des cellules de feuille de calcul comme entrées, le nom d'une seule entrée peut être tape directement dans la zone Nom. APRÈS la sélection d'une plage d'entrées, la zone Nom affiche les noms de toutes les cellules séparés par des virgules.
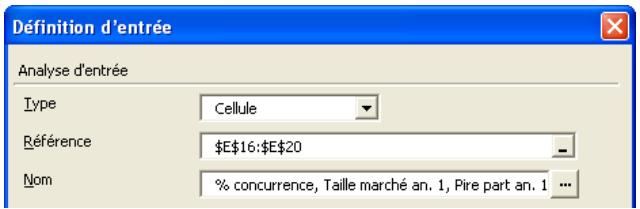
Ces noms peuvent être modifiés directement dans la zone (en maintenant le format de séparation par virgules) ou en cliquant sur le bouton... pour ouvrir la boîte de dialogue Nom des cellules d'analyse de sensibilité.
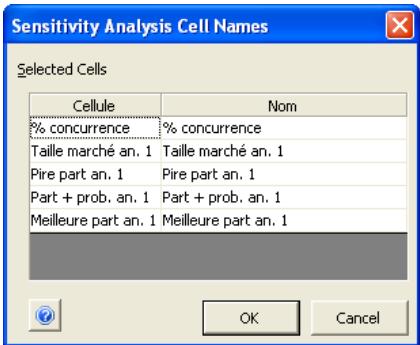
Les noms de cellule ne sont définis dans la boîte de dialogue Définition d'entrée qu'aux fins de l'analyse de sensibilité avancée. Ils sont utilisés dans la fenêtre @RISK - Synthèse des résultats et dans les rapports généraux par l'analyse de sensibilité avancée, mais ils ne deviennent pas partie intégrante du modèle Excel.
Valeur de base. Sert à déterminer la série des valeurs à considérer pour une entrée; sert aussi de point de référence dans le graphique du rapport de changement de pourcentage. La valeur de base est particulièrement importante si vous pouze appliquer un méthode de variation représentant un changement par rapport à la base tel que + / - % chgt par rapport à la base. Par défaut, la valeur de base est la valeur d'évaluation d'une distribution ou cellule lorsqu'Excel recalcule la feuille de calcul. Vous pouvez cependant spécifique une autre valeur. Remarque: Si la distribution ou la cellule s'évalue à 0 et que la valeur de base est Auto, vous devez entrer une valeur de base autre que zéro pour utiliser l'option + / - % chgt par rapport à la base.
Les options du volet Variation décrivent le type de variation à utiliser pour la sélection des valeurs à tester pour les entrées. Lors de l'analyse, les entrées progressent par « pas » le long de la plage de valeurs possibles et une simulation complète s'exécute à chaque valeur de pas. La variation définit la nature de cette plage : % chgt par rapport à la base, Chgt par rapport à val base, Valeurs de plage, Centiles de distribution, Table de valeurs ou Table de plage Excel. Ces différentes approches procurent une grande souplesse de description des valeurs à tester pour une entrée. Suivant la méthode de variation sélectionnée, les paramètres de plage et valeurs à définir (voir plus bas, boîte de dialogue Définition d'entrée) différent.
Les différentes méthodes de variation et leurs plages et valeurs associées sont décrites ici.
- % de c incrément ou décrément de la valeur de base de l'entrée des pourcentages spécifiés dans les zones Chgmt min (%) et Chgmt max (%). Les valeurs intermédiaires sont prises à intervalles égaux, selon le nombre de valeurs à tester défini dans la zone Nbre de pas.

- Changement par rapport à la valeur de base. Sous cette méthode de variation, la première et la dernière valeur de la série de pas s'obtiennent par ajustement de la valeur de base des valeurs spécifiée
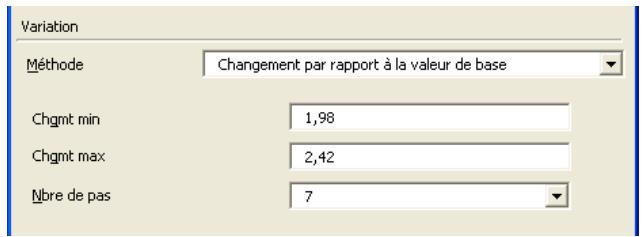
- Valeurs de plage. Sous cette méthode de variation, la série des valeurs de pas commence au Minimum et s'arrête au Maximum
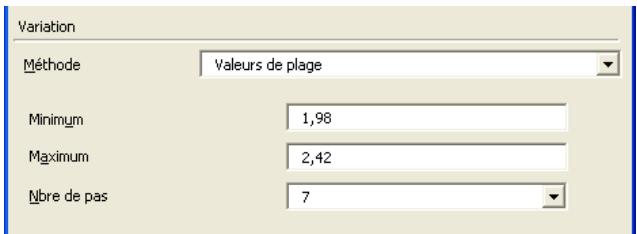
- Centiles de distribution. Cette méthode de variation n'est utilisée que lorsque le type d'entrée sélectionné est Distribution. Les pas se spécifient sous forme de centiles de la distribution @RISK sélectionnée. Un maximum de 20 pas est admis. Lors de l'analyse, l'entrée est fixée aux valeurs de centile calculées depuis la distribution en entrée.
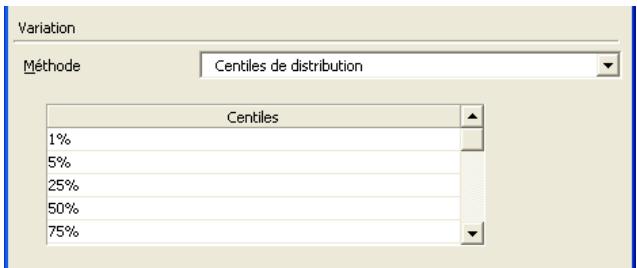
- Table de valeurs. Sous cette méthode de variation, vous entrez directement la série des valeurs de pas dans la table affichée dans le volet droit de la boîte de dialogue Définition d'entrée. La valeur de base est omise puisque les valeurs spécifiques entrées sont les valeurs testées.
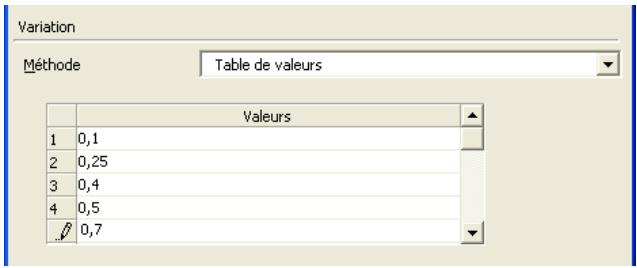
- Table de plage Excel. Sous cette méthode de variation, la série des valeurs de pas se trouve dans la plage de cellules de feuille de calcul spécifique dans la zone Plage Excel. Cette plage peut contenir un nombre quelconque de valeurs. N'oubliez cependant pas qu'une simulation complète sera effectuée pour chaque valeur de la plage référencée.
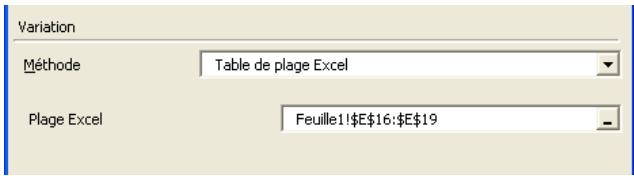
Ajouter noms d'analyse
Le bouton Ajouter noms d'analyse permet d'ajouter un nom descriptif à chaque valeur d'entrée à tester dans une analyse de sensibilité avancée. Ce nom servira à identifier la simulation exécutée lorsqu'une entrée est fixée à une valeur particulière. Les noms d'analyse facilitent la lecture des rapports et l'identification des simulations individuelles lors de l'examen des résultats dans la fenêtre @RISK - Synthèse des résultats.
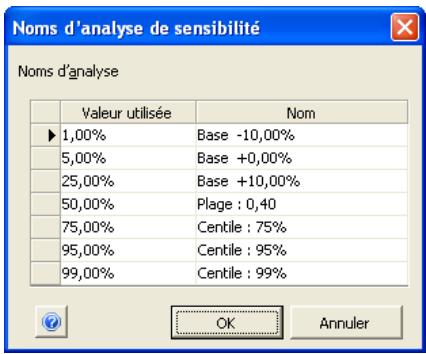
La boîte de dialogue Noms d'analyse de sensibilité permet l'entrée d'un nom pour la simulation à executer à chaque pas de valeur en entrée. Le nom @RISK par défaut proposé dans la fenêtre est modifiable à volonté.
Options — commande analyse de sensibilité avancée
Définit les options d'analyse d'une analyse de sensibilité avancée.
La boîte de dialogue Options de sensibilité permet la sélection de la statistique de sortie à évaluer durant l'analyse de sensibilité, l'identification des rapports à générer et la spécification du comportement des fonctions @RISK Simtable dans l'analyse.
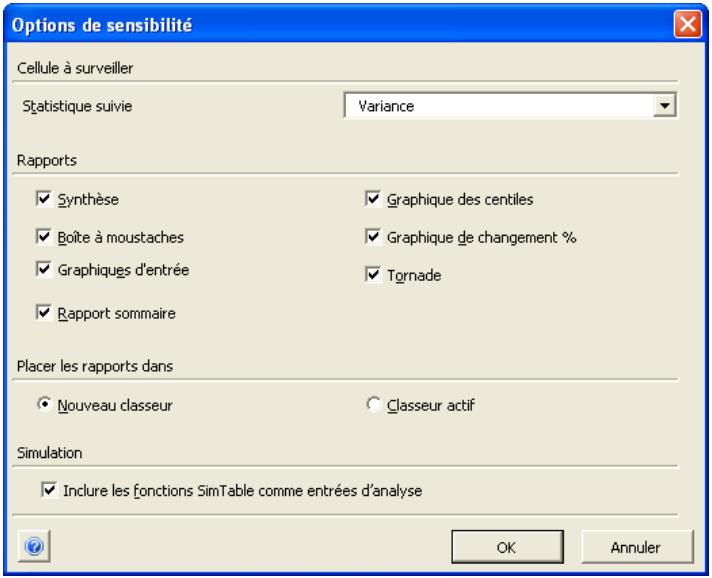
Pour l'ouvrir, cliquez sur le bouton Options de la boîte de dialogue Analyse de sensibilité avancée. Les sélections proposées sont les suivantes :
- Statistique suivie - Permet de spécifier la statistique particulière à surveiller pour la sortie @RISK à chaque simulation. Les graphiques comparatifs et les rapports de l'analyse montrés sur variation de la valeur de cette statistique, de simulation en simulation.
- Rapports - Ce volet permet la sélection des rapports d'analyse à générer en fin d'analyse de sensibilité. Les options suivantes sont proposées : Synthèse, Boîte à moustaches, Graphiques d'entrée, Rapport sommaire, Graphique des centiles, Graphique de changement % et Tornado. Pour plus de détails sur chacun de ces rapports, voir plus bas la section Rapports.
Le volet Placer les rapports dans permet l'envoi des résultats dans le classeur actif ou dans un nouveau classeur.
- Nouveau classeur - Tous les rapports se placent dans un nouveau classeur.
- Classeur actif - Tous les rapports se placent dans le classeur actif, avec le modèle.
Inclure les fonctions Simtable comme entrées d'analyse
En cas d'exécution de l'analyse de sensibilité sur des feuilles de calcul contenant des fonctions RiskSimtable, cette option fait inclure dans l'analyse les valeurs spécifiées par ces fonctions. Si l'option est sélectionnée, les classeurs ouverts sont analysés, à la recherche de fonctions RiskSimtable. L'analyse de sensibilité avancée passe alors par les valeurs spécifiées dans les arguments de fonction RiskSimtable, exécutant une simulation complète à chacune. Les rapports générés en fin d'exécution affichent la sensibilité de la statistique de sortie aux deux variations suivantes :
1) la variation des entrées configurée dans la boîte de dialogue. Analyse de sensibilité avancée et 2) la variation des valeurs des fonctions Simtable.
Cette option est particulièrement utile en cas d'exécution d'une analyse de sensibilité avancée sur un modèle @RISK configuré pour simulations multiples. Simtable et la capacité de simulation multiple @RISK servent souvent à l'analyse de la variation des résultats de simulation sous l'effet du changement d'une valeur en entrée, par simulation, au moyen de la fonction Simtable. Cette analyse est similaire à celle executée par une analyse de sensibilité avancée. En sélectionnant simplement l'option Inclure les fonctions Simtable comme entrées d'analyse et en executant une analyse de sensibilité avancée, les modèles à simulations multiples bénéficient de tous les rapports et graphiques de l'analyse de sensibilité avancée sans configuration supplémentaire.
Pour plus de détails sur la fonction RiskSimtable, voir la section Références : Fonctions @RISK de ce manuel.
Analyser — commande analyse de sensibilité avancée
Exécuter une analyse de sensibilité avancée.
Lorsque vous cliquez sur le bouton Analyser, le nombre de simulations, d'itérations par simulation et le nombre total d'itérations vous sont présentés. L'analyse peut encore être annulée à ce stade.
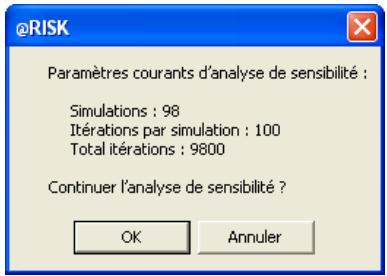
Si une analyse plus rapide, de moindre envergure, est désirée, le bouton Annuler donne à l'utilisateur l'occasion de changer le nombre d'itérations par simulation dans la boîte de dialogue Paramètres de simulation, le nombre d'entrées à analyser ou le nombre de valeurs dans la série associée à chaque entrée (nombre de pas ou éléments de table).
Lors de l'exécution d'une analyse de sensibilité avancée, les actions suivantes se produisent pour chaque entrée comprise dans l'analyse :
1) Une seule valeur de pas de l'entrée remplace la valeur de cellule ou distribution @RISK existante dans la feuille de calcul. 2) Une simulation complète du modèle s'exécute. 3) Les résultats de la simulation sont récoltés et stockés pour la sortie suivie Cellule à surveiller. 4) Le processus se répète jusqu'à ce qu'une simulation ait été exécutée pour chaque valeur de pas possible de l'entrée.
Les résultats de l'analyse de sensibilité sont également disponibles dans la fenêtre @RISK - Synthèse des résultats, où ils peuvent être analysés en profondeur à l'aide des outils proposés.
Rapports
L'analyse de sensibilité avancée produit les rapports suivants :
Synthèse Boite à moustaches Graphiques d'entrée Rapports sommaires - Graphique des centiles Graphique de changement % - Graphique tornado
Chacun de ces rapports est généré dans Excel, dans le classeur du modèle ou dans un nouveau classeur. Ces rapports sont décrits en détail dans cette section.
Synthèse
Le rapport de synthèse décrit les valeurs affectées aux entrées analysées et les statistiques correspondantes de la sortie surveillée : Moyenne, Minimum, Maximum, Mode, Médiane, Écart type, Variance, Aplatissement, Asymétrie, 5e centile et 95e centile.
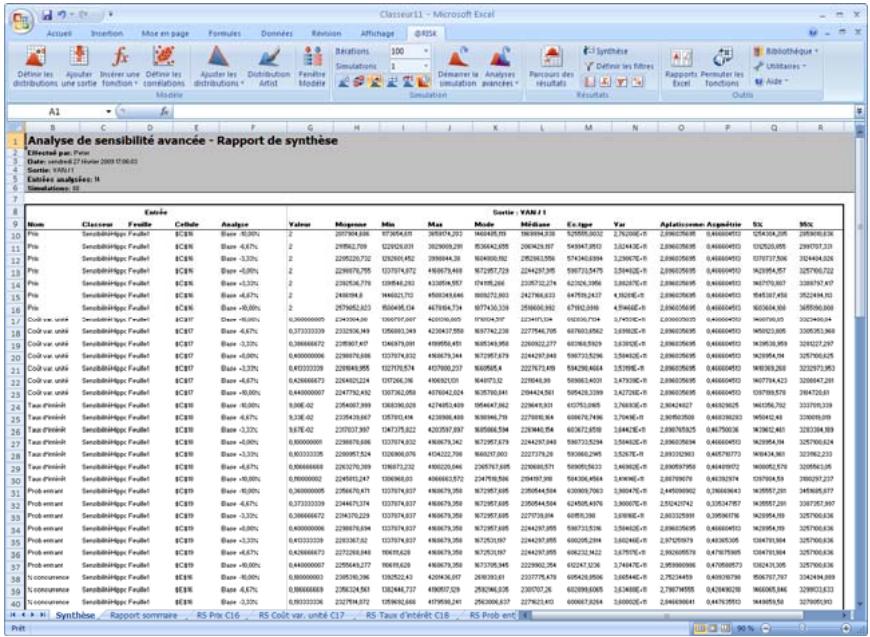
Graphiques d'entrée et boîtes à moustaches
Le rapport Graphiques d'entrée identifie la variation de la statistique de simulation suivie aux simulations executées à chacune des valeurs de pas sélectionnées pour une entrée. Ces graphiques se décrivent ainsi :
- Graphique linéaire - Trace la valeur de la statistique de simulation suivie pour la sortie par rapport à la valeur utilisée pour l'entrée à chaque simulation. Le graphique comporte un point
- Distribution cumulative superposée - Présente la distribution cumulative de la sortie dans chaque simulation à chaque valeur de pas de l'entrée. Le graphique comporte une distribution cumulative
- Boîtes à moustaches - Donnent une indication générale de la distribution de sortie à chaque simulation executée pour l'entrée, avec description de la moyenne, de la médiane et des centiles atypiques. Il y a une boîte à moustach Pour plus de détails sur les graphiques à moustaches, voir la section Analyse de contrainte de ce manuel.
Rapport sommaire
Les rapports sommaires doivent la synthèse, en une page, de l'analyse de sensibilité avancée dans son ensemble ou pour une seule entrée de l'analyse. Ces rapports sont conçus pour n'occuper qu'une seule page.
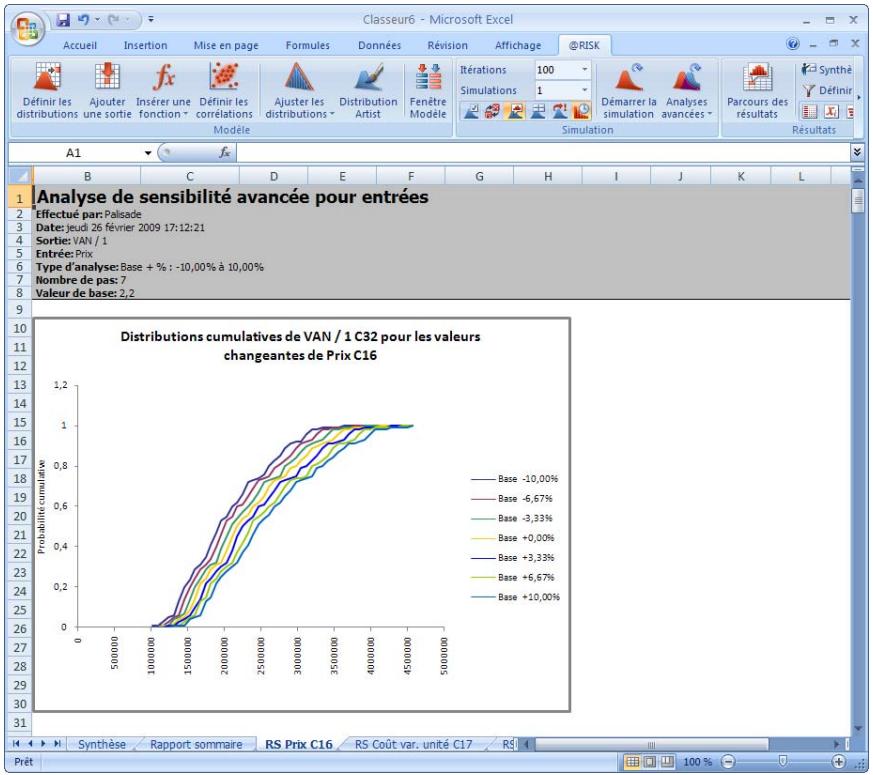
Le graphique de changement % trace la statistique de la cellule à surveiller par rapport à chacune des entrées sélectionnées sous forme de pourcentage de changement par rapport à la base. La valeur d'entrée, sur l'axe X, est calculée par comparaison de chaque valeur entrée avec la valeur de base spécifique pour l'entrée.
Variance de VAN / 1 C32 / % de variation des entrées
Graphique des centiles
Le graphique des centiles trace la statistique Cellule à surveiller par rapport aux centiles de chacune des distributions @RISK sélectionnées à l'analyse sous le type de pas Centiles de distribution. Remarque : Seules les entrées qui étaient des distributions @RISK figurent sur ce graphique.
Variance de VAN / 1 C32 / centile de distribution en entrée
Le graphique tornado présente une barre pour chacune des entrées définies à l'analyse, indiquant les valeurs minimum et maximum acquises par la statistique Cellule à surveiller, selon la variation des valeurs de l'entrée.
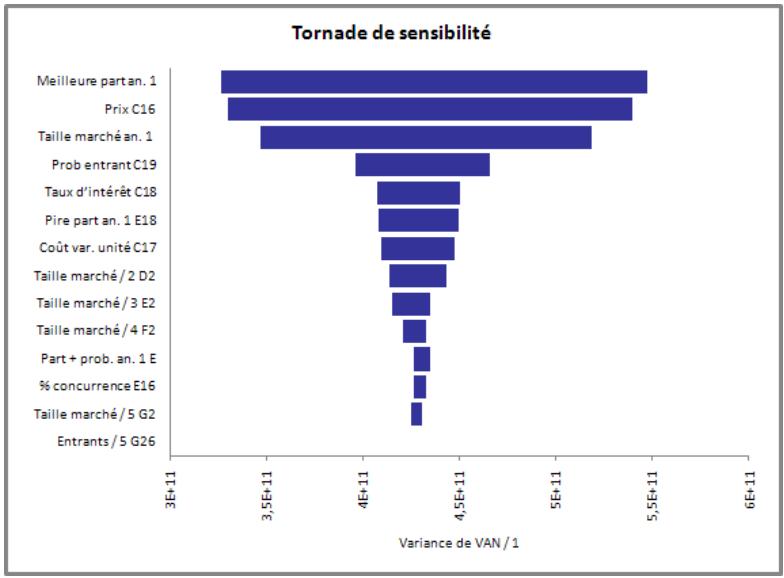
Commande parcours des résultats
Active le mode Parcours des résultats, qui affiche un graphique de résultats de simulation quand une cellule est sélectionnée dans Excel.
En mode Parcours des résultats, il suffit de cliquer sur une cellule du classeur pour afficher un graphique des résultats de simulation. La touche permet aussi de déplacer le graphique d'une cellule de sortie contenant des résultats de simulation à l'autre dans les classeurs ouverts.
En mode Parcours, @RISK affiche les graphiques de résultats de simulation en réponse à vos clicks ou « tab » sur les cellules du tableau :
- Si la cellule sélectionnée est une sortie de simulation (ou contient une fonction de distribution simulée), @RISK affiche un graphique de sa distribution simulée.
- Si la cellule sélectionnée fait partie d'une matrice de corrélation, une matrice de diagrammes de dispersion des correlations simulées entre les entrées de la matrice s'ouvre.
Si le paramètre de simulation Affichage automatique des résultats — Graphique de sortie est sélectionné, le mode Parcours s'active automatiquement en fin de simulation.
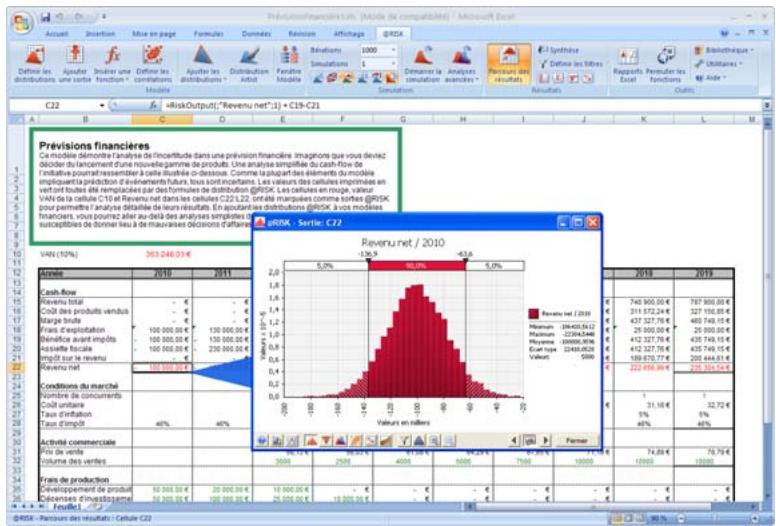
Pour quitter le mode Parcours, il suffit de fermer le graphique ou de cliquer sur l'icône Parcours des résultats, sur la barre d'outils.
Commande fenêtre synthèse des résultats
Affiche tous les résultats de simulation, avec statistiques et vignettes graphiques.
la fenêtre @RISK - Synthèse des résultats affiche la synthèse des résultats du modèle ainsi que des vignettes graphiques et statistiques de synthèse de la cellule de sortie simulée et des distributions en entrée. Comme la fenêtre Modèle, celle-ci permet :
- l'expansion d'une vignette graphique au format fenêtre complété par glissement-déplacement;
- l'accès, par double-clic sur une entrée quelconque du tableau, au navigateur graphique pour parcours des cellules du classeur porteuses de distributions en entrée;
- la personnalisation des colonnes en fonction des statistiques à afficher.
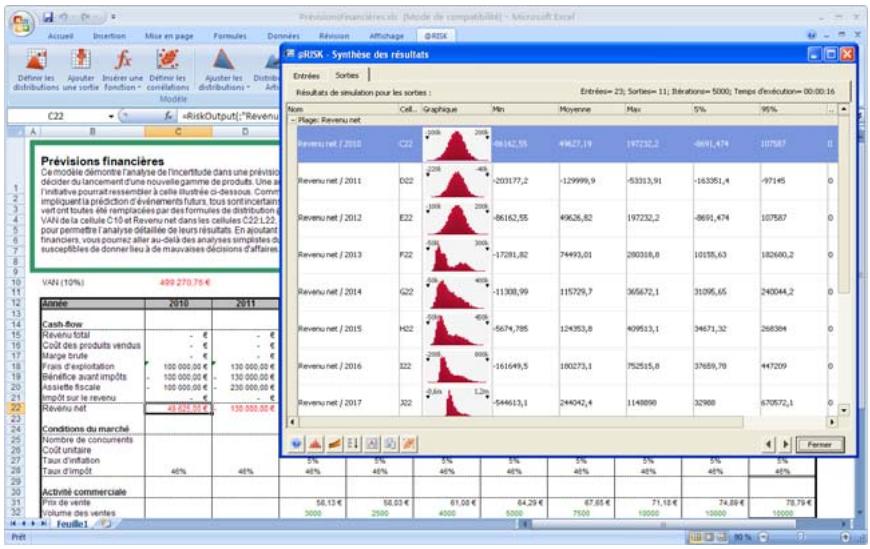
Remarque: Si le nom d'une entrée ou d'une sortie s'affiche en rouge dans la fenêtre Synthèse des résultats, la cellule référencée pour le résultat simulé est introuvable. La situation peut se produire à l'ouverture de résultats de simulation, si un classeur utilisé lors de la simulation n'est pas ouvert, ou en cas de suppression de la cellule dans le classeur après l'exécution de la simulation. Il est dans ce cas toujours possible de faire glisser un graphique du résultat depuis la fenêtre Synthèse des résultats, sans toutefois pouvoir accéder à la cellule en mode Parcours ou produire un graphique depuis la cellule.
La fenêtre Synthèse des résultats et le Navigateur graphique
La fenêtre Synthèse des résultats est « liée » à vos feuilles de calcul Excel. Un simple clic sur une sortie simulée ou une entrée du tableau révèle les cellules porteuses du résultat et de son nom dans Excel. Un double clic sur une vignette graphique du tableau suffit à afficher le graphique de la sortie simulée, ou de l'entrée, dans Excel, avec liaison à la cellule correspondante.
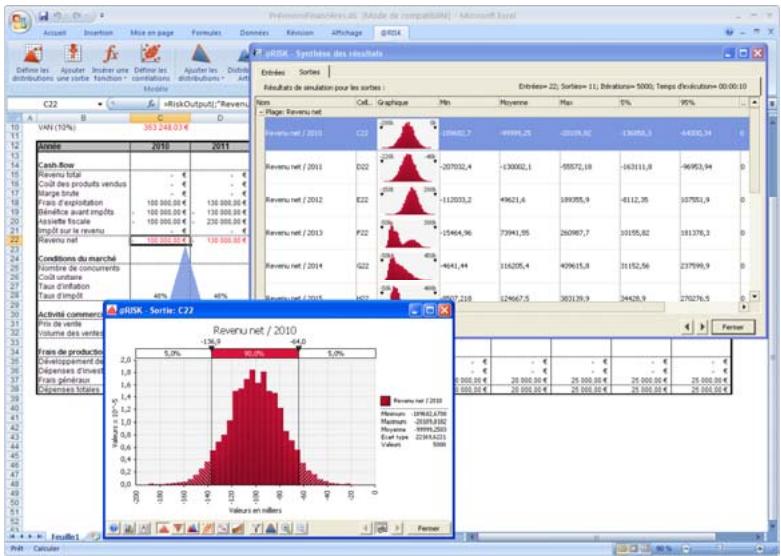
Commandes de la fenêtre Synthèse des résultats
Les commandes de la fenêtre Synthèse des résultats sont accessibles d'un clic sur les icônes proposées au bas du tableau ou d'un clic droit et sélection dans le menu contextuel. Les commandes s'exécutent sur les lignes sélectionnées du tableau.
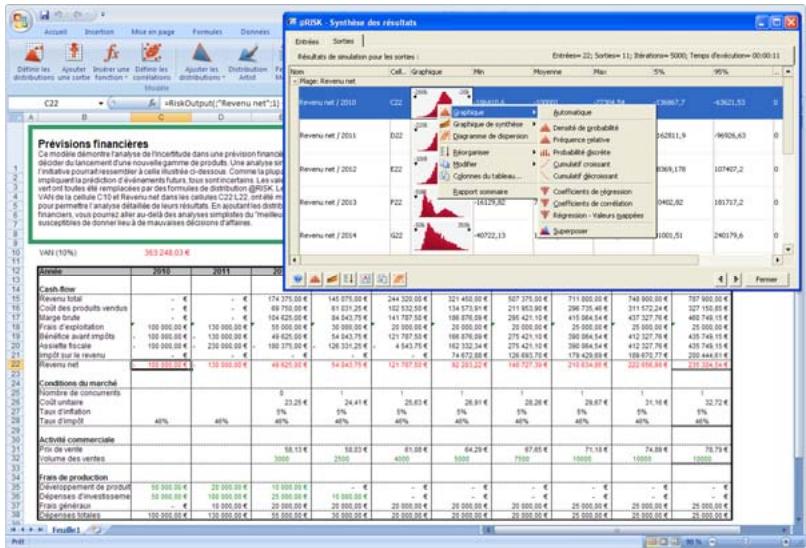
Déplacement des graphiques par glissement
Pour afficher un graphique @RISK, faites-en simplement glisser la vignette hors de la fenêtre Synthèse des résultats. Pour l'ajout de superpositions, glissez-déplacez les graphiques (ou vignettes) les uns par-dessus les autres.
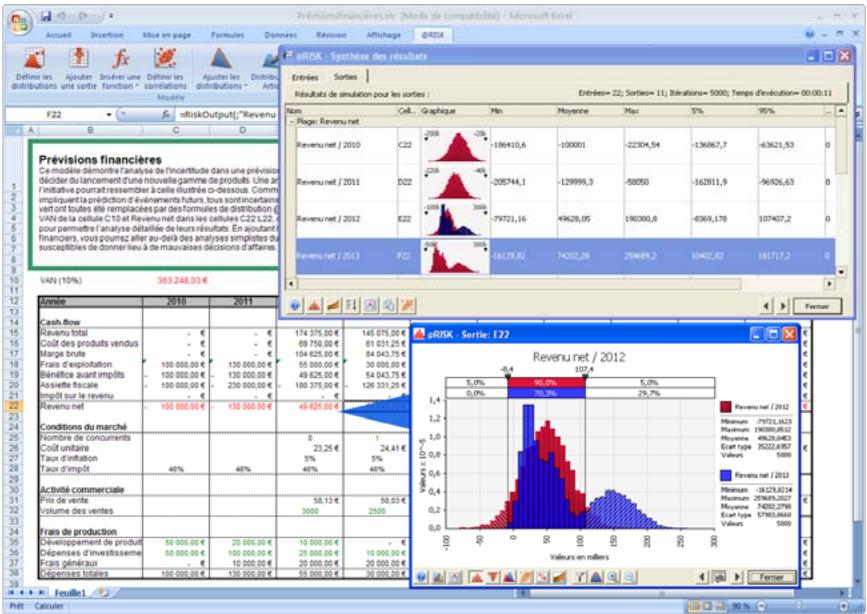
La sélection de plusieurs lignes dans la fenêtre Synthèse des résultats suivie d'un click sur l'icône Graphique, au bas de la fenêtre, permet de créer plusieurs graphiques en même temps.
Si vous modifiez un graphique plein écran, la vignette correspondante de la fenêtre Synthèse des résultats s'actualise et stocke les changements apportés. Vous pouvez ainsi fermer une fenêtre graphique sans perdre vos modifications. La fenêtre Synthèse des résultats n'admet cependant qu'une vignette graphique par sortie simulée ou entrée. Si vous ouvrez plusieurs fenêtres graphiques d'une même sortie ou entrée, seuls les changements apportés au dernier graphique modifié seront enregistrés.
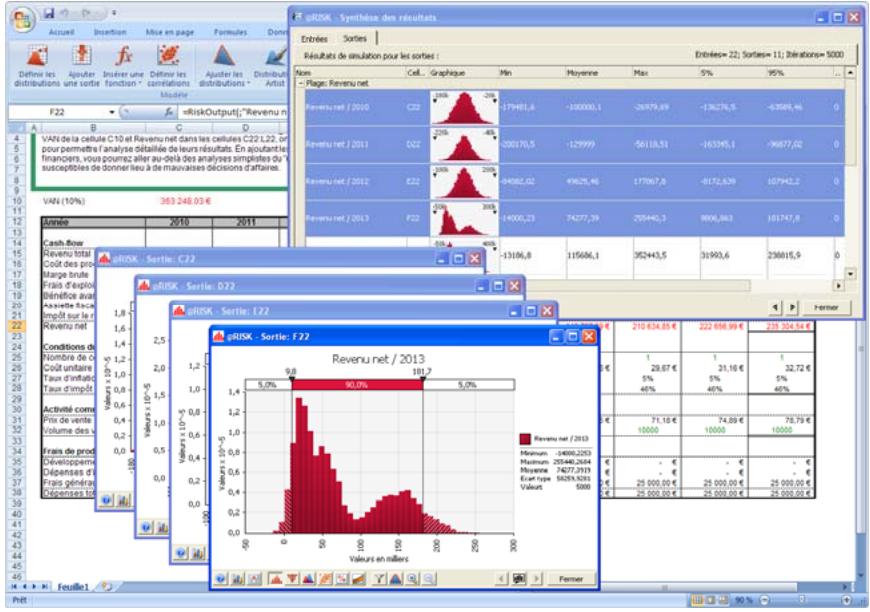
Les colonnes de la fenêtre Synthèse des résultats peuvent être personnalisées en fonction des statistiques que vous désirez afficher. L'icône Colonnes, au bas de la fenêtre, ouvre la boîte de dialogue Colonnes du tableau.
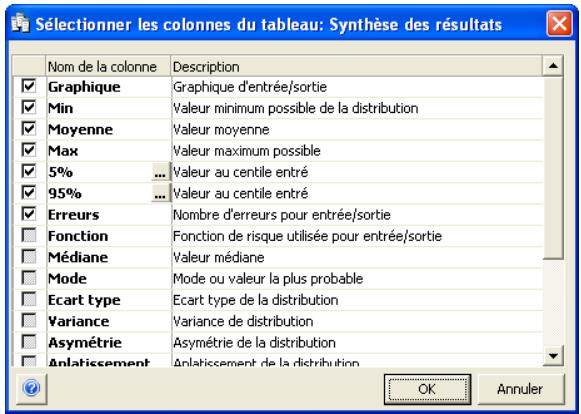
Si vous choisissez d'inclure les valeurs de centile dans le tableau, le centile effectif s'inscrit sur les lignes Valeur au centile entre.
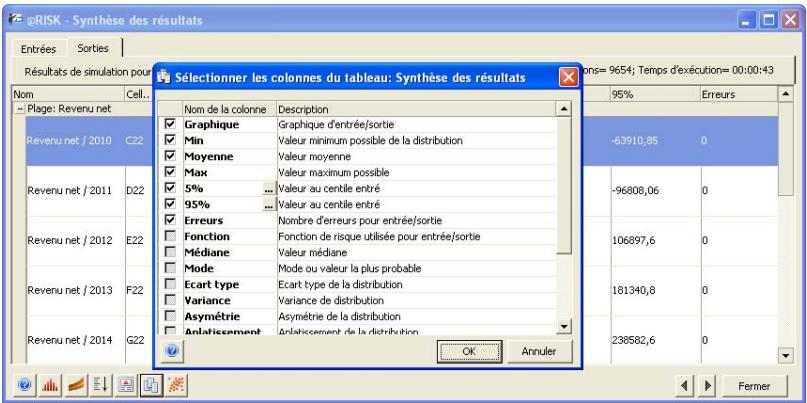
Remarque: Les sélections de colonne opérées sont retenues. Vous pouvez opérer des sélections différentes pour les fenêtres @RISK - Modèle et @RISK - Synthèse des résultats.
Si la surveillance de convergence est activée dans les paramètres de simulation, la colonne d'état s'affiche automatiquement comme première colonne de la fenêtre Synthèse des résultats. Le niveau de convergence de chaque sortie y est indiqué.
Les valeurs modifiables p1, x1 et p2, x2 sont des colonnes modifiables directement dans le tableau. Ces colonnes vous permettent d'entrer des valeurs cibles et/ou probabilités cibles spécifiques directement dans le tableau. Choisissez la commande Recopier vers le bas du menu Édition pour reproduire rapidement les valeurs p ou x pour plusieurs sorties ou entrées.
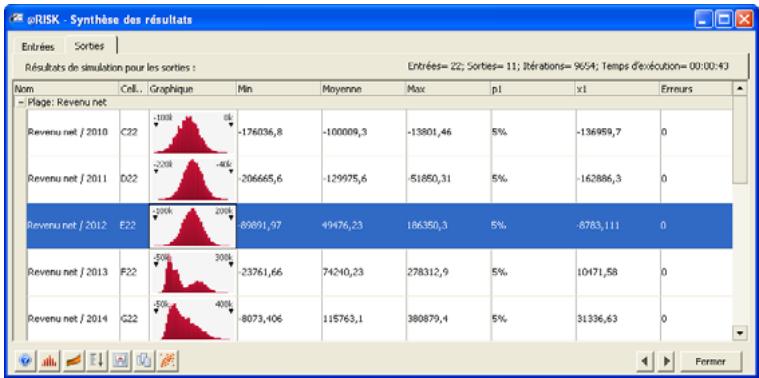
Menu graphique
Pour accéder au menu Graphique, 1) cliquez sur l'icône Graphique au bas de la fenêtre Synthèse des résultats ou 2) cliquez sur le tableau avec le bouton droit de la souris. Les commandes choisies s'exécutent sur les lignes sélectionnées du tableau. Elles permettent la représentation graphique rapide de plusieurs résultats de simulation du modèle. La commande Automatique crée les graphiques en fonction du type par défaut (fréquence relative) des distributions de résultats de simulation.
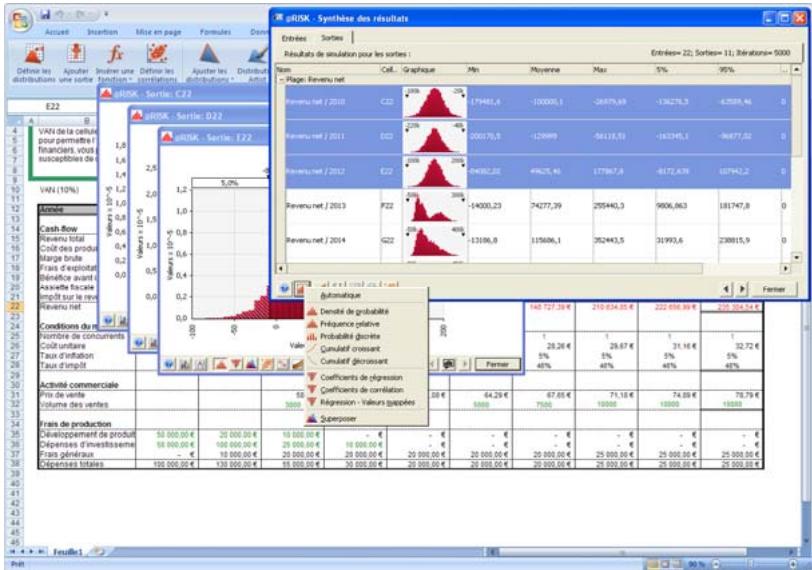
La fenêtre @RISK - Synthèse des résultats peut être copiée dans le Presse-papiers ou exportée vers Excel à travers les commandes du menu Copier et Rapport. Au besoin, il est également possible de recopier vers le bas ou de copier-coller les valeurs du tableau. L'approche permet notamment la reproduction rapide des valeurs P1 et X1 modifiables.
Le menu Édition propose les commandes suivantes :
Rapports Excel. Exporte le tableau vers une nouvelle feuille de calcul Excel. - Copier la sélection. Copie la sélection courante du tableau dans le Presse-papiers. - Copier la grille. Copie toute la grille (texte uniquement, sans vignettes graphiques) dans le Presse-papiers. - Coller, Recopier vers le bas. Colle ou produit les valeurs dans la sélection courante du tableau.
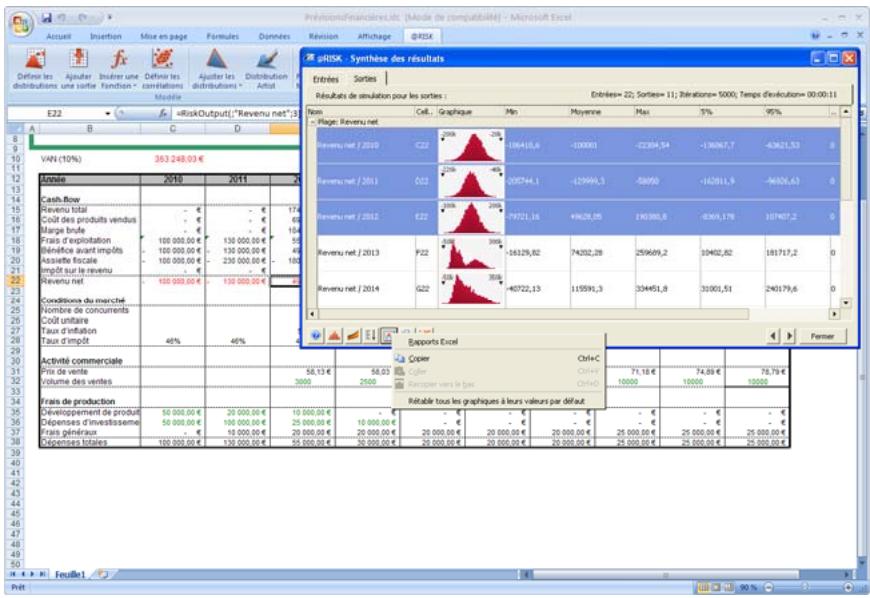
Commande statistiques détaillées
Affiche la fenêtre Statistiques détaillées.
L'icône Statistiques détaillées affiche les statistiques détaillées des résultats de simulation pour les cellules de sortie et les entrées.
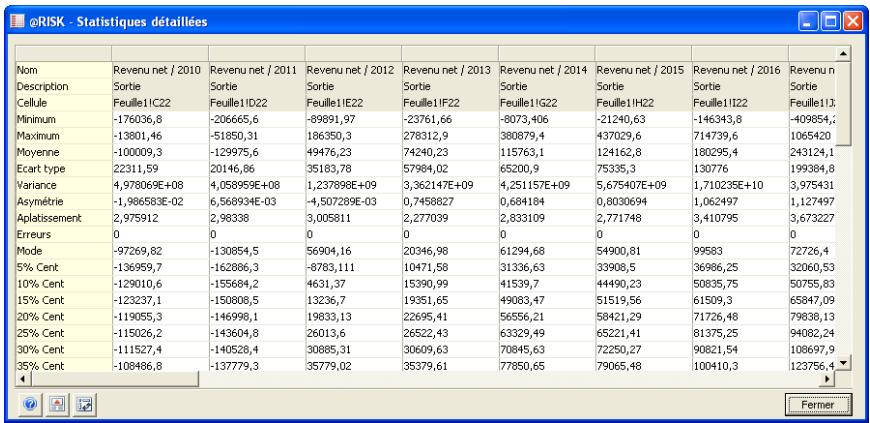
La fenêtre Statistiques détaillées affiche les statistiques calculées pour toutes les cellules de sortie et les distributions en entrée échantillonnées. Les valeurs de centile (par pas de 5 centiles) sont également représentées, de même que les informations de filtrage et jusqu'à 10 valeurs cibles et probabilités.
Vous pouvez faire pivoter la fenêtre Statistiques détaillées de sorte que les statistiques s'affichent dans les colonnes et les sorties et entrées sur les lignes. Pour ce faire, cliquez sur l'icône Faire pivoter, au bas de la fenêtre.
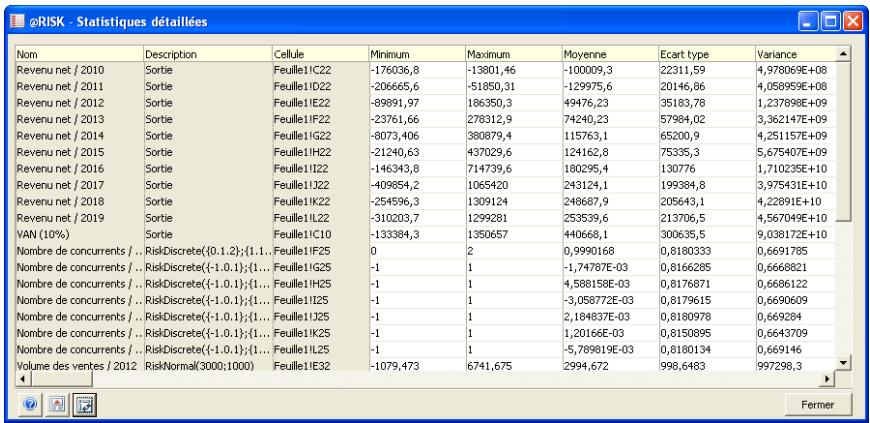
Entrée de valeurs cibles dans la fenêtre Statistiques détaillées
Dans @RISK, des cibles peuvent être calculées pour n'importe quel résultat de simulation, qu'il s'agisse d'une distribution de probabilités pour une cellule de sortie ou d'une distribution pour une distribution en entrée échantillonnée. Ces cibles identifient la probabilité d'obtenir un résultat spécifique ou la valeur associée à un niveau de probabilité donné. La zone d'entrée des cibles, au bas de la fenêtre Statistiques détaillées (ou à droite de la fenêtre, si vous l'avez fait pivoter), admet l'entrée de valeurs ou de probabilités.
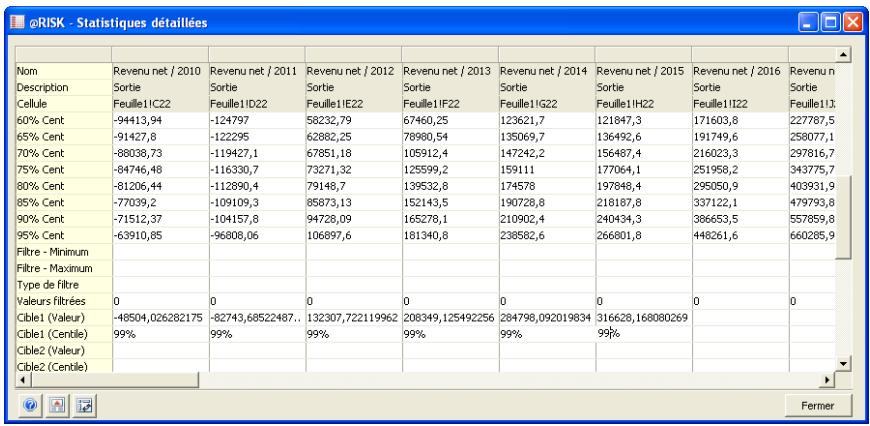
Pour accéder à la zone d'entrée des cibles, faites défiler la fenêtre Statistiques détaillées jusqu'aux lignes des cibles et entrez-y les valeurs ou probabilités considérées. Si vous entrez une valeur, @RISK calcule la probabilité d'une valeur inférieure ou égale à la valeur entrée. Si l'option Afficher les centiles cumulatifs décroissants du menu Daut @RISK est sélectionnée, la probabilité cible rapportée l'est en termes de dépassement de la valeur cible entrée.
Si vous entrez une probabilité, @RISK calcule la valeur de la distribution dont la probabilité cumulative associée est égale à la probabilité entrée.
Une fois entrée, la valeur ou probabilité cible peut être reproduite rapidement sur une plage de résultats de simulation : il suffit de la « glisser » sur la plage de cellules destinataires. Ainsi, par exemple, la cible de 99% entrée pour chaque cellule de sortie de la fenêtre Statistiques détaillées illustrée plus haut. Pour reproduire des cibles :
1) Entre la valeur ou probabilité cible désirée dans une cellule des lignes de cibles de la fenêtre Statistiques détaillées. 2) Sélectionnez la plage de cellules voisines où reproductive la cible en y faisant glisser la souris. 3) Cliquez avec le bouton droit et choisissez la commande Recopier à droite du menu Edition. La même cible se calcule pour chaque résultat de simulation compris dans la plage sélectionnée.
Rapports excel.
À l'image des autres fenêtres de rapport @RISK, celle des Statistiques détaillées peut être exportée vers une feuille de calcul Excel. Pour exporter la fenêtre, cliquez sur l'icône Copier et Rapport, au bas de la fenêtre, et sélectionnez Rapport Excel.
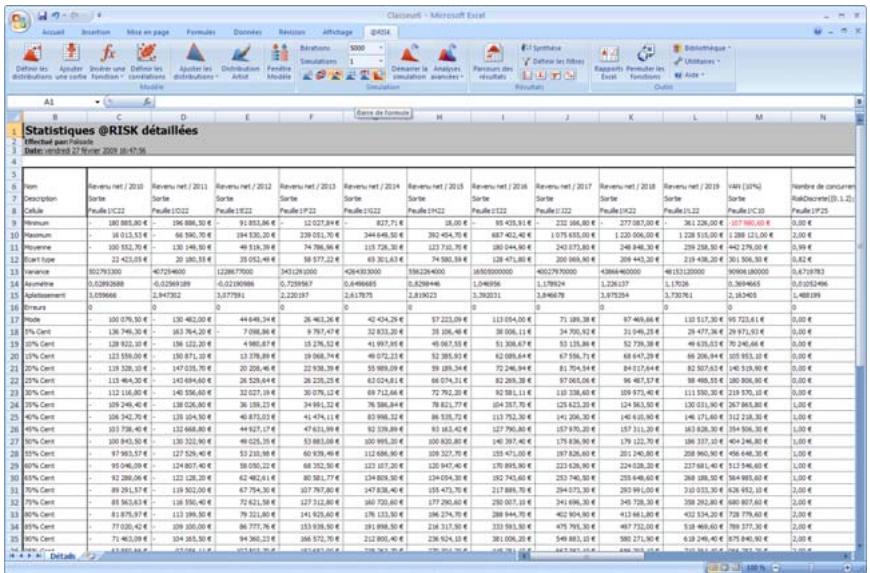
Affiche la fenêtre données.
L'icône Données affiche les valeurs de données, calculées pour les cellules de sortie et les distributions en entrée échantillonnées. Une simulation génère un nouvel ensemble de données à chaque itération. À chaque itération, une valeur est échantillonnée pour chaque distribution en entrée et une valeur est calculée pour chaque cellule de sortie. La fenêtre Données affiche les données de la simulation dans une feuille de calcul, en vue de leur analyse ou de leur exportation (à travers les commandes du menu Édition) vers une autre application.
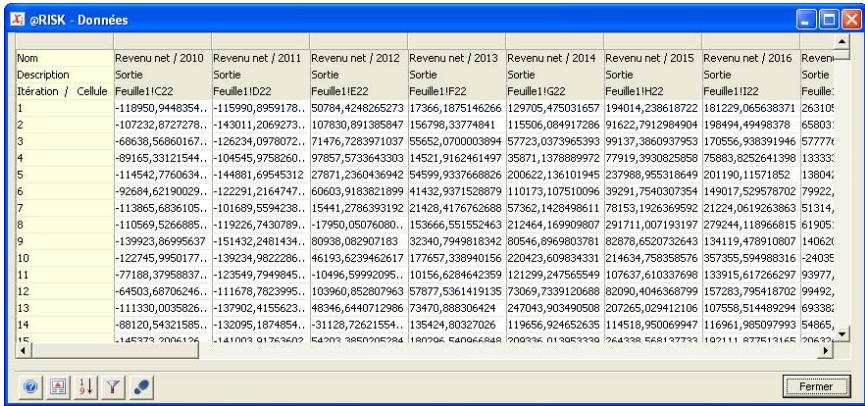
Les données sont affichées, par itération, pour chaque cellule de sortie et distribution en entrée échantillonnée. Chaque ligne de la fenêtre Données révèle la combinaison exacte des échantillons en entrée ayant mené à la sortie indiquée pour l'itération correspondante.
Tri de la fenêtre données
Les données d'une simulation peuvent être triées en fonction des valeurs clés qui vous intéressent : pour afficher les iterations où une erreur s'est produite, par exemple. Les valeurs de résultats peuvent aussi être triées en ordre croissant ou décroissant. Facultativement, vous pouvez masquer les valeurs filtrées ou les erreurs. La combinaison du tri avec l'option Pas d'iteration configure la présentation Excel en fonction des valeurs d'iteration qui vous intéressent.
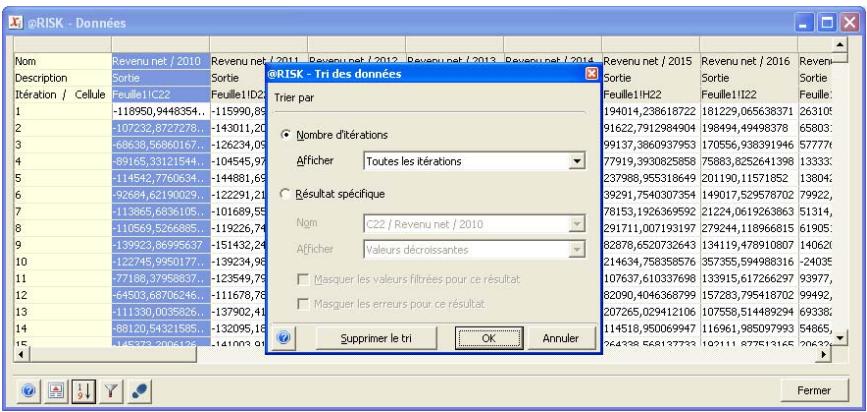
La boîte de dialogue Tri des données définit les paramètres de tri dans la fenêtre Données.
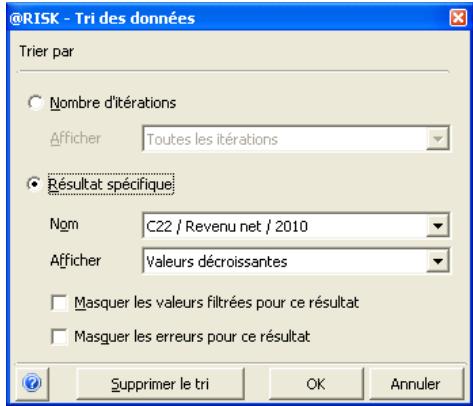
Les options Trier par suivantes sont proposées :
- Nombre d'itérations. Vous pouvez afficher Toutes les itérations (paramètre par défaut), les Itérations où une erreur s'est produite ou les Itérations restantes après application des filtres. Pour plus de détails sur les filtres d'ité e est utile au débogage d'un modèle. Commencez par trier de manière à identifier les itérations où une erreur s'est produite. Choisissez ensuite la commande Pas d'itération pour régler Excel sur les valeurs calculées pour ces itérations. Parcourez enfin le classeur dans Excel pour examiner les conditions du modèle ayant mené à l'erreur.
- Résultat spécifique. Chaque colonne de la fenêtre Données (représentant les données d'une sortie ou d'une entrée de la simulation) peut être triée individuellement. Sélectionnez cette option pour afficher les valeurs supérieures ou inférieures d'un résultat. L'option Masquer les valeurs filtrées pour ce résultat ou Masquer les valeurs erronées pour ce résultat masque les iterations pour lesquelles le résultat contient une erreur ou une valeur filtrée.
Les itérations affichées dans la fenêtre Données peuvent être passées en revue, avec actualisation dans Excel des valeurs échantillonnées et calculées. L'approche est utile à la recherche des iterations erronées et des itérations ayant mené à certains scénarios de sortie.
Pour passer en revue les itérations :
1) Cliquez sur l'icône Pas d'itération au bas de la fenêtre Données. 2) Cliquez sur la ligne de la fenêtre Données associée au n° d'itération dont vous désirez actualiser les valeurs dans Excel. Les valeurs échantillonnées pour toutes les entrées de cette itération se placent dans Excel et le classeur se recalcule. 3) Dans la fenêtre Données, un clic dans la cellule contenant la valeur d'une sortie ou d'une entrée d'itération sélectionne la cellule de sortie ou d'entrée correspondante dans Excel.
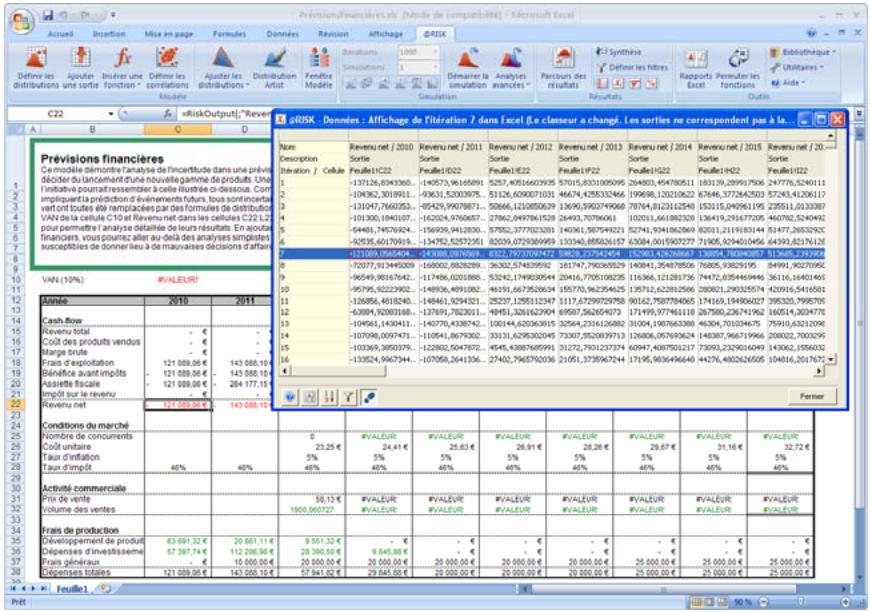
Remarque: Si des modifications ont été apportées au classeur Excel depuis l'exécution de la simulation, les valeurs d'itération calculées lors de la simulation ne correspondent plus nécessairement à celles calculées au pas d'itération. Ce type d'erreur est signalé dans la barre de titre de la fenêtre Données.
Commande sensibilités
Affiche la fenêtre Analyse de sensibilité.
L'icône Analyse de sensibilité renvoie les résultats de l'analyse de sensibilité des cellules de sortie. Ces résultats indiquent la sensibilité de chaque variable de sortie à ses variables d'entrée.
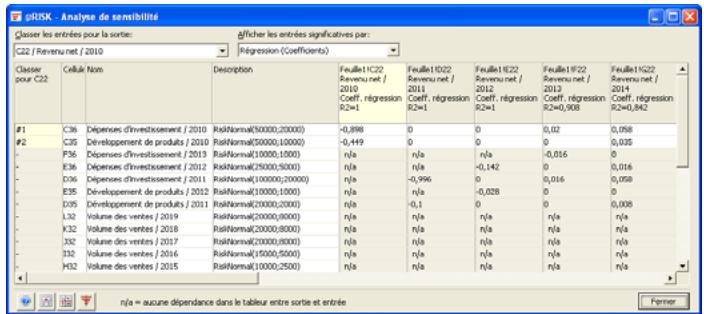
L'analyse de sensibilité effectuée sur les variables de sortie, et leurs entrées correspondantes, font appel à la régression multidimensionnelle en escalier ou à la corrélation des rangs. Les distributions en entrée du modèle sont classées en fonction de leur incidence sur la sortie dont le nom est sélectionné dans la zone de liste déroulante Classer les entrées pour la sortie. Le type de données affiché dans le tableau - Régression (Coefficients), Corrélation (Valeurs mappées) ou Régression et Corrélation (Coefficients) - se sélectionne dans la zone de liste déroulante Afficher les entrées significatives par. Cliquez sur l'icône Tornado pour afficher un graphique tornado des valeurs de la colonne sélectionnée.
Remarque: Un clic sur l'en-tête d'une colonne classe les entrées de la sortie dans la colonne sélectionnée.
Analyse de sensibilité intelligente
Par défaut, @RISK propose une analyse de sensibilité intelligente, par pré-sélection des entrées en fonction de leur précédence dans les formules par rapport aux sorties. Les entrées des formules sans lien (à travers les formules du module) aux cellules de sortie sont éliminées de l'analyse de sensibilité, pour éviter les résultats parasites. Dans la fenêtre Analyse de sensibilité, ces entrées sans rapport sont indiquées par la mention n/a.
L'analyse de sensibilité intelligente trouve son utilisation dans le fait qu'il est possible que les données de simulation doivent une corrélation entre une entrée et une sortie alors qu'en réalité, l'entrée est sans effet sur la sortie du modèle. Sans l'analyse de sensibilité intelligente, le graphique tornado pourrait inclure des barres pour ces entrées pourtant sans rapport.
Il existe quelques cas isolés où il convient de désactiver l'analyse de sensibilité intelligente sous l'onglet Échantillonnage de la boîte de dialogue Paramètres de simulation, pour améliorer la performance et les résultats de l'analyse de sensibilité :
1) La durée de configuration de l'analyse intelligente en début de simulation prolonge considérablement le temps d'exécution d'un modèle particulièrement volumineux et l'apparition de résultats (ou barres de graphique tornado) relatifs à des entrées sans rapport avec les sorties vous importe peu. 2) Vous utilisez une macro ou DLL qui effectue des calculs faisant appel à des valeurs en entrée @RISK de cellules sans rapport, à travers les formules du classeur, avec la sortie. Cette macro ou DLL renvoie ensuite un résultat à une cellule utilisée dans le calcul de la valeur de sortie. Il n'est en l'occurrence aucun lien dans les formules du classeur entre la sortie et les distributions @RRISK et l'analyse de sensibilité intelligente doit être désactivée. Pour éviter ce type de situation, la création de macro-fonctions (fonctions définies par l'utilisateur) faisant explicitement référence à toutes les cellules en entrée utilisées dans leurs listes d'arguments est recommandée.
Les versions antérieures de @RISK ne pratiquaient pas l'analyse de sensibilité intelligente. Cela revient à désactiver l'option Analyse de sensibilité intelligente de la commande Paramètres de simulation du menu Paramètres.
Régression et correlation
Il existe deux méthodes de calcul des résultats de l'analyse de sensibilité : la régression multidimensionnelle en escalier et la corrélation des rangs.
Le terme régression désigne tout simplement l'ajustement des données à une équation théorique. Dans le cas de la régression linéaire, les données en entrée sont ajustées sur une ligne. Vous avez peut-être entendu parler de la méthode « des moindres carrés », qui représente un type de régression linéaire.
La régression multiple tente d'ajuster des ensembles de données en entrée multiples à une équation plane susceptible de produire l'ensemble des données de sortie. Les valeurs de sensibilité renvoyées par @RISK sont des variations normalisées des coefficients de régression.
Définition de la régression multidimensionnelle en escalier
La régression en escalier est une technique de calcul de valeurs de régression à valeurs d'entrée multiples. Il existe d'autres techniques, mais la régression en escalier est préféable en présence d'un grand nombre d'entrées, car elle supprime toutes les variables dont la contribution au modèle est insignifiante.
Les coefficients répertoriés dans le rapport de sensibilité @RISK sont les coefficients de régression normalisés de chaque entrée. Une valeur de régression de 0 indique qu'il n'est pas de relation significative entre l'entrée et la sortie, tandis qu'une valeur de régression de 1 ou -1 indique une modification de l'écart type de 1 ou -1 dans la sortie pour un changement d'écart type de 1 dans l'entrée.
La valeur R2 affichée en haut de la colonne représente simplement une mesure du pourcentage de variation expliquée par la relation linéaire. Si ce nombre est inférieur à 60%, la régression linéaire n'explique pas suffisamment la relation entre les entrées et les sorties et il convient de recourir à une autre méthode d'analyse.
Même dans les cas où l'analyse de sensibilité produit une relation représentée par une valeur R2 élevée, ne manquez pas d'examiner la pertinence des résultats. Existe-t-il des coefficients dont la grandeur ou le signe sont imprévus?
Définition des valeurs mappées
Les valeurs mappées représentent tout simplement une transformation du coefficient bêta de la régression (coefficient) en valeurs réelles. Le coefficient bêta indique le nombre d'écarts types de variation de la sortie sous l'effet d'un changement d'un écart type au niveau de l'entrée (toutes autres variables restant égales).
Définition de la corrélation
La corrélation est une mesure quantitative de la force d'une relation entre deux variables. Le type de corrélation le plus courant est la corrélation linéaire, qui mesure la relation linéaire entre deux variables.
La valeur de corrélation des rangs renvoyée par @RISK peut varier entre -1 et 1. La valeur 0 indique l'absence de corrélation entre les deux variables, qui sont donc indépendantes l'une de l'autre. La valeur 1 représente une corrélation positive complète entre les deux variables : lorsque la valeur échantillonnée pour une entrée est « élevé », celle échantillonnée pour l'autre l'est aussi. La valeur -1 représente une corrélation inverse complète entre les deux variables : lorsque la valeur échantillonnée pour une entrée est « élevé », celle échantillonnée pour l'autre est « faible ». Les autres valeurs représentent une corrélation partielle : les changements de l'entrée sélectionnée affectent la sortie, mais d'autres variables peuvent aussi l'influencer.
Définition de la corrélation des rangs
La corrélation des rangs calcule la relation entre deux ensembles de données en comparant le rang de chaque valeur. Pour calculer le rang, les données sont classées en ordre croissant et reçoivent un numéro (rang) correspondant à leur position dans la séquence.
Cette méthode est préférible à la corrélation linéaire quand on ne connait pas nécessairement les fonctions de distribution de probabilités dont sont prélevées les données. Si, par exemple, un ensemble de données A était normalement distribué et qu'un ensemble de données B était distribué selon la loi gauss-logarithmique, la corrélation des rangs produit une meilleure représentation de la relation entre les deux ensembles.
Comparaison des méthodes
Quelle mesure de sensibilité convient-il donc d'utiliser ? Dans la plupart des cas, l'analyse de régression est la mesure préférée. Il est vrai que « la corrélation n'implique pas la causalité » : une entrée corrélée à une sortie peut être sans effet significatif sur la sortie.
Cependant, dans les cas où la valeur R2 renvoyée par la régression en escalier est faible, vous pouvez conclure que la relation entre les variables d'entrée et de sortie n'est pas linéaire. Il convient dans ce cas de recourir à la corrélation des rangs pour l'analyse de sensibilité du modèle.
En revanche, si la valeur R2 renvoyée par la régression en escalier est élevée, vous pouvez aisément conclure que la relation est linéaire. Mais, comme nous l'avons mentionné plus haut, veillez toujours à vérifier la vraisemblance des variables de régression. @RISK pourrait en effet rapporter une relation positive significative entre deux variables dans l'analyse de régression et une corrélation négative significative dans l'analyse des rangs. Cet effet est appelé multicollinéarité.
La multicollinéarité se produit lorsque les variables indépendantes d'un modèle sont corrélées entre elles ainsi qu'à la sortie.
Malheureusement, la réduction de l'impact de la multicollinéarité est un problème complexe à gérer; vous pouvez toutefois envisager de supprimer de votre analyse de sensibilité la variable responsable de la multicollinéarité.
Matrice de diagrammes de dispersion
Les résultats de l'analyse de sensibilité peuvent s'afficher dans une matrice de diagrammes de dispersion. Un diagramme de dispersion est un graphique x-y qui présente la valeur en entrée échantillonnée par rapport à la valeur de sortie calculée pour chaque iteration de la simulation. Dans la matrice des diagrammes de dispersion, les résultats classés de l'analyse de sensibilité sont affichés avec leurs diagrammes de dispersion. Pour afficher la matrice, cliquez sur l'icone Dispersion dans le coin inférieur gauche de la fenêtre Sensibilité.
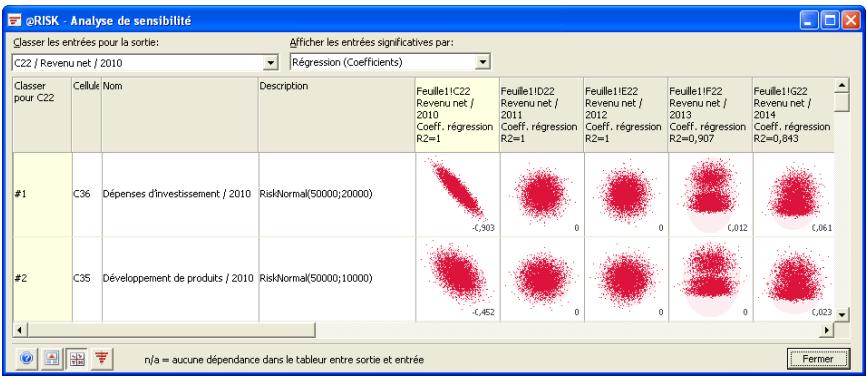
En glissant-déplaçant une vignette de diagramme de dispersion hors de la matrice, vous pouvez l'étendre à une fenêtre graphique plein format. Il est également possible de superposer plusieurs diagrammes de dispersion par glissement-déplacement d'autres vignettes de la matrice sur un diagramme existant.
Affiche la fenêtre analyse de scénario.
L'icone Scénarios renvoie les résultats de l'analyse de scénario pour les cellules de sortie. Trois scénarios peuvent être entrés par variable de sortie. Les scénarios s'affichent sur la ligne du haut (intitulée Scenario=) de la fenêtre d'analyse de scénario ou dans la section Scénarios de la fenêtre Statistiques détaillées. Elles sont précédées de l'opérateur > ou < et peuvent être exprimées en centiles ou en valeurs réelles.
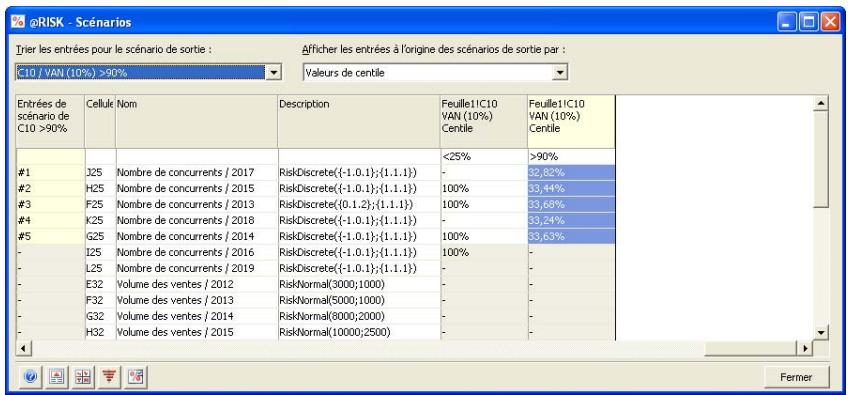
Définition de l'analyse de scénario
L'analyse de scénario permet de déterminer les variables en entrée qui contribuent de façon significative à la réalisation d'un but. Par exemple, quelles sont les variables qui contribuent à un niveau de vente exceptionnellement élevé ? Ou quelles sont les variables qui contribuent à la réalisation de bénéfices inférieurs à 1 million d'euros ?
@RISK permet la définition de scénarios cibles pour chaque sortie. Si votre intérêt porte, par exemple, sur le quartile le plus élevé de la sortie Total des ventes ou sur la valeur de moins de 1 million dans la sortie des bénéfices nets, il vous suffit d'entrer ces valeurs sur la ligne Scénarios de la fenêtre d'analyse de scénario @RISK.
Dans la fenêtre des scénarios, le programme considère les données créées par la simulation @RISK. Pour chaque sortie, l'approche se présente comme suit :
1) La médiane et l'écart type des échantillons de chaque distribution en entrée sont calculés pour la simulation toute entière. 2) Un « sous-ensemble » des seules itérations dans lesquelles la sortie atteint la cible définie se crée.
Interprétation des résultats
3) La médiane de chaque entrée se calcule pour ce sous-ensemble de données. 4) Pour chaque entrée, la différence entre la médiane de la simulation (étape 1) et celle du sous-ensemble (étape 3) est calculée et comparée à l'écart type des données en entrée (étape 1). Si la valeur absolue de la différence entre les médianes est supérieure à 1/2 écart type, l'entrée est considérée significative; sinon, elle est omise de l'analyse de scénario. 5) Chaque entrée significative identifiée à l'étape 4 figure dans le rapport de scénario.
Comme indiqué plus haut, le rapport de scenario présente toutes les variables en entrée jugées « significatives » à l'accès à une cible définie pour une variable de sortie. Cela peut dire,
par exemple, que @RISK peut vous indiquer que l'entrée Prix de détail est significative lors de l'étude du quartile le plus élevé de l'entrée Total des ventes. Vous savez donc que lorsque les ventes totales sont élevées, le prix au détail médian est significativement différent que pour l'ensemble de la simulation.
@RISK calcule trois statistiques pour chaque distribution en entrée significative dans un scénario :
- Médiane réelle des échantillons dans les iterations conformes à la cible, soit la médiane du sous-ensemble d'itérations pour l'entrée sélectionnée (calculée ci-dessus à l'étape 3). Vous pouvez la comparer à la Médiane de la sortie sélectionnée pour l'ensemble de la simulation (le centile 50% rapporté dans le rapport de statistiques).
- Centile de la médiane des échantillons dans les iterations conformes à la cible, soit le centile de la médiane du sous-ensemble dans la distribution générée pour la simulation complète (revenant à entrer la médiane du sous-ensemble comme valeur cible dans le rapport de statistiques @RISK). Si cette valeur est inférieure à 50%, la médiane du sous-ensemble est inférieure à la médiane de la simulation complète; si elle est supérieure à 50%, la médiane du sous-ensemble est supérieure à celle de la simulation complète.
Il se peut que la médiane du sous-ensemble du Prix au détail soit inférieure à celle de l'ensemble de la simulation (le centile étant inférieur à 50%). Cela indique qu'un Prix au détail bas peut vous aider à atteindre le but d'un Total de ventes élevé.
- Médiane réalisante par rapport à l'écart type original, ou différence entre la Médiane du sous-ensemble et celle de l'ensemble de la simulation, divisée par l'écart type de l'entrée pour l'ensemble de la simulation. Un nombre négatif indique que la Médiane du sous-ensemble est inférieure à celle de la simulation au complet, et un nombre positif, qu'elle est supérieure à celle de la simulation au complet. Plus ce rapport est grand, plus la variable est importante à la réalisation de la cible définie.
Peut-être qu'une autre variable en entrée, telle que le Nombre de vendeurs, est significative dans la réalisation de la cible Total de ventes élevé, mais son rapport médiane/écart type ne représente que la moitié de la grandeur du rapport pour l'entrée Prix au détail. Vous pouvez en conclure que, si la variable Nombre de vendeurs a une incidence sur le but Total de ventes élevé, le Prix au détail est plus significatif et peut nécessiter plus d'attention.
Attention! Le plus grand danger représenté par l'analyse de scénario est que les résultats de l'analyse risquent d'être trompeurs si le sous-ensemble contient un petit nombre de points de données. Par exemple, dans le cas d'une simulation de 100 iterations et d'une cible de scénario « >90% », le sous-ensemble ne contient que 10 points de données!
Modifier les scénarios
Pour changer les scénarios par défaut, on clique sur l'icône Modifier les scénarios (dans une fenêtre graphique ou dans la fenêtre Scénarios). On peut aussi cliquer deux fois sur un scenario - tel que >90% - affiché sur la première ligne de la fenêtre Scénarios.
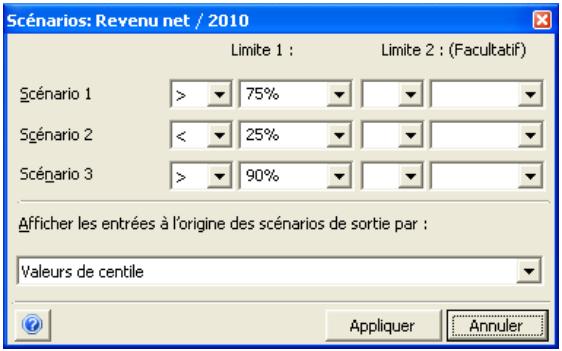
Trois scénarios sont admis par sortie de simulation. Chaque scénario peut avoir une ou deux limites. L'entrée de deux limites spécifie un scénario à plage min-max de sortie : > 90 % et < 99 %, par exemple. Chaque limite peut être spécifiée sous forme de centile ou de valeur réelle : > 1000000, par exemple.
Si vous ne désirez pas de deuxième limite, laissez simplement les valeurs blanches. On précise ainsi que la seconde limite est soit la valeur de sortie minimum (l'opérateur < est utilisé: < 5%, par exemple), soit la valeur de sortie maximum (l'opérateur est >, comme dans >90% ).
Remarque: les paramètres de scénario par défaut peuvent être configurés sous paramètres d'application.
Matrice de diagrammes de dispersion dans la fenêtre de scénarios
Un diagramme de dispersion, dans la fenêtre de scénarios, est un diagramme de dispersion x-y superposé. Ce graphique présente :
1) la valeur en entrée échantillonnée par rapport à la valeur de sortie calculée à chaque iteration de la simulation, 2) superposée d'un graphique de dispersion de la valeur en entrée échantillonnée par rapport à la valeur de sortie calculée lorsque la valeur de sortie correspond au scenario entré.
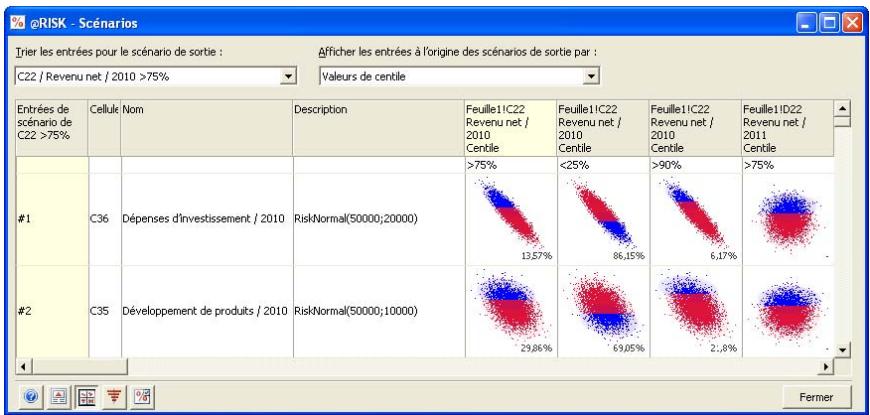
Dans la matrice des diagrammes de dispersion, les résultats classés de l'analyse de scénario sont affichés avec leurs diagrammes de dispersion. Pour afficher la matrice, cliquez sur l'icône Dispersion dans le coin inférieur gauche de la fenêtre Scénarios.
Remarque: Vous ne pouvez superposer que la même entrée et sortie, sous différents scénarios, dans un diagramme de dispersion des résultats d'analyse de scénario.
Graphique tornado de scénarios
Les résultats d'analyse de scénario s'affichent, graphiquement, dans des graphiques de type « tornado ». Pour produire un graphique tornado, cliquez sur l'icône Tornado de la fenêtre Scénarios ou sur l'icône Scénarios d'une fenêtre graphique. Le graphique tornado illustré ici présente les entrées clés qui affectent la sortie lorsque celle-ci correspond au scénario entre - quand la sortie est supérieure au 90e centile, par exemple.
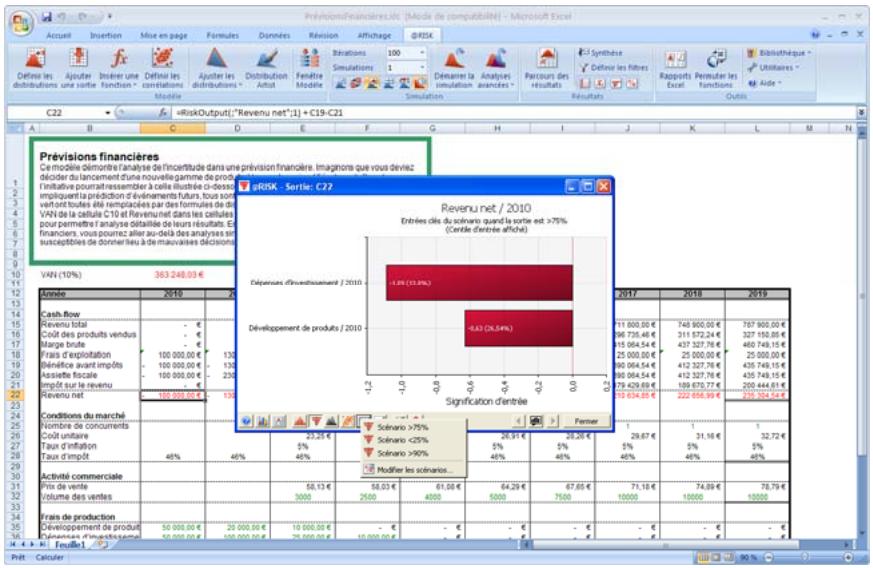
Filtre les valeurs des calculs statistiques et graphiques de simulation.
Des filtres peuvent être définis pour chaque cellule de sortie sélectionnée ou distribution de probabilités en entrée échantillonnée. Ces filtres permettent de supprimer les valeurs indésirables des calculs statistiques et des graphiques générés par @RISK. Les filtres se définissent en cliquant sur l'icône Filtre de la barre d'outils ou sur l'icône Filtre du graphique d'un résultat de simulation ou de la fenêtre Données.
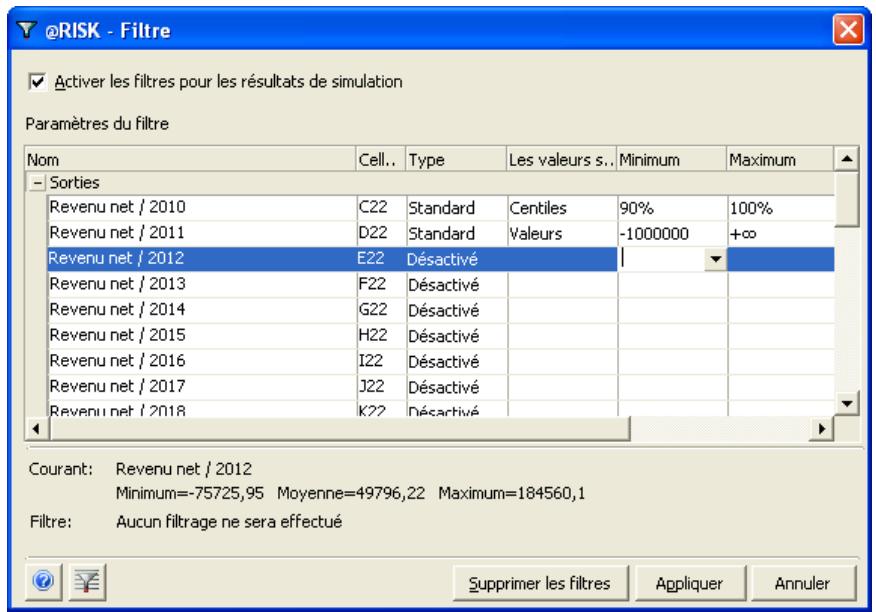
Un filtre peut être défini pour une sortie de simulation ou distribution en entrée échantillonnée, comme indiqué dans la colonne Nom du tableau Paramètres du filtre. Lors de la définition d'un filtre, vous pouvez entrer un type, un type de valeur (centiles ou valeurs), une valeur minimum admise, une valeur maximum admise ou une plage minimum-maximum. Si l'entrée Minimum ou Maximum est laissée en blanc, le filtre n'est limité que du côté définit, ce qui permet, par exemple, de « ne traiter que les valeurs supérieures ou égales à un minimum de 0 »
La boîte de dialogue Filtres propose les icônes et options suivantes :
- N'afficher que les sorties ou entrées avec filtres — Dans la boîte de dialogue Filtre, n'affiche que les sorties ou entrées pour lesquelles des filtres ont été définis.
- Même filtré pour toutes les simulations - Si plusieurs simulations ont été exécutées, cette option copie et applique le premier filtré entre pour une entrée ou une sortie aux résultats, pour la même entrée ou sortie, de toutes les autres simulations.
- Appliquer - Les filtres s'appliquent aussitôt que vous cliquez sur le bouton Appliquer de la boîte de dialogue Filtre.
- Effacer les filtres - Pour supprimer tous les filtres courants, cliquez sur le bouton Effacer les filtres pour supprimer les filtres des lignes sélectionnées du tableau, puis cliquez sur Appliquer. Pour désactiver un filtre sans le supprimer de la liste entrée, régalez son Type sur Désactivé.
Les types de filtrage suivants sont proposés :
- Filtre standard — Ce type de filtrage ne s'applique qu'à la cellule de sortie ou distribution en entrée échantillonnée pour laquelle il a été défini. Les valeurs inférieures au minimum ou supérieures au maximum sont supprimées des calculs de statistiques, de sensibilité et de scénario et exclues des graphiques générés pour le résultat de simulation.
- Filtre d'itération - Ce type de filtrage affecte tous les résultats d'une simulation. Lors du traitement d'un filtrage d'itération global, @RISK commence par l'appliquer à la cellule de sortie ou à la distribution de probabilités en entrée échantillonnée pour laquelle il a été défini. Les valeurs inférieures au minimum ou supérieures au maximum entrées sont supprimées des calculs de statistiques, de sensibilité et de scénario et exclues des graphiques générés pour le résultat de simulation. Les itérations conformes aux conditions du filtrage sont ensuite « marquées » et toutes les autres cellules de sortie ou distributions en entrée échantillonnées sont filtrées de manière à n'inclure que les valeurs générées dans ces itérations. Ce type de filtrage est particulièrement utile lorsque vous souhaitez n'examiner les résultats de simulation (pour l'ensemble des sorties et des entrées) que pour les itérations qui répondent à une condition de filtrage spécifique (quand Bénéfice>0, par exemple).
Filtrer depuis une fenêtre graphique
Quand vous cliquez sur l'icône Filtre du graphique d'un résultat de simulation, une boîte de dialogue de filtrage rapide s'ouvre et vous permet de définir un filtrage pour le seul résultat affiché dans le graphique.
Définissez simplement le Type de filtré et le type de valeur à entrainer, la plage minimum-maximum, et cliquez sur Appliquer. Le graphique se réaffiche (avec de nouvelles statistiques) et le nombre de valeurs utilisées (non filtrées) est indiqué au bas du graphique. Comme pour tout autre filtré, les valeurs inférieures au minimum ou supérieures au maximum entre sont supprimées des calculs de statistiques, de sensibilité et de scenario et exclues des graphiques générs pour le résultat de simulation.
Pour afficher la boîte de dialogue Filtre intégrale, avec la liste de tous les filtres actifs, cliquez sur le bouton Tous les filtres...
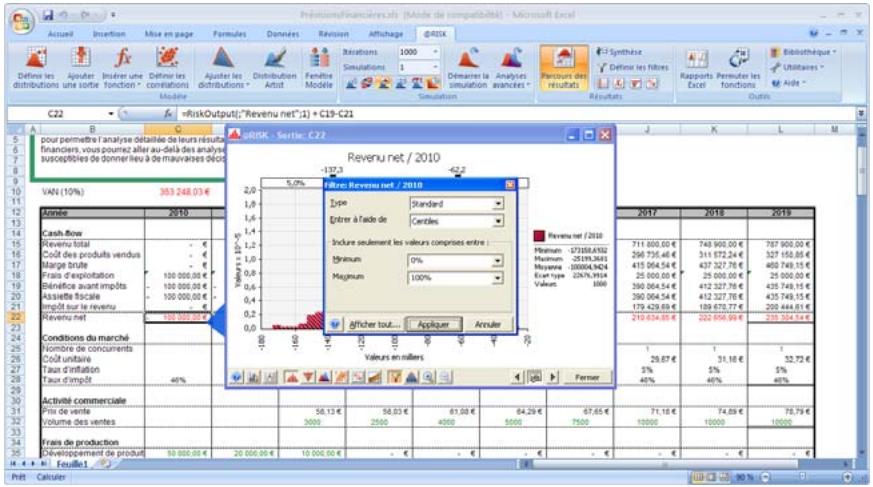
Commande rapports excel
Sélectionne les rapports de résultats de simulation à produire dans Excel.
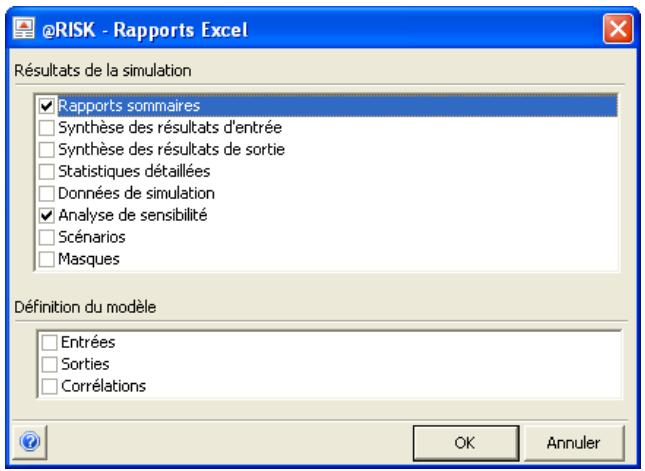
La commande @RISK - Rapports Excel permet de sélectionner les rapports à produire sur les résultats de simulation actifs ou la définition du modèle courant.
Plusieurs rapports de simulation prédéfinis peuvent être générés directement dans Excel en fin de simulation. Le rapport sommaire est un rapport de résultats de simulation destiné à l'impression. Il présente un rapport d'une page pour chaque sortie de simulation. Les autres rapports disponibles, à commencer par Synthèse des résultats d'entrée, contiennent les mêmes informations que les rapports équivalents de la fenêtre Synthèse des résultats ou autres fenêtres de rapport.
L'emplacement des rapports se configure à l'aide de la commande Paramètres d'application du menu Utilitaires. Deux options sont proposées concernant l'emplacement des rapports dans Excel :
- Nouveau classeur. Place les rapports de simulation dans un nouveau classeur à chaque génération de rapports.
- Classeur actif. Place les rapports de simulation sur de nouvelles feuilles du classeur actif à chaque génération de rapports.
Pour plus de détails sur ces paramètres et autres valeurs par défaut, voir la section de ce chapitre consacrée à la commande Paramètres d'application.
Vous pouvez vous servir des masques proposés pour créer vos propres rapports de simulation personnalisés. Les statistiques de simulation et les graphiques se placent dans un masque à l'aide des fonctions statistiques @RISK (RiskMean, par exemple) ou de la fonction graphique RiskResultsGraph. Lorsqu'une fonction statistique ou graphique est définie dans un masque, les statistiques et graphiques désirés s'insèrent, en fin de simulation, dans une copie du masque pour produire le rapport voulu. Le masque original porteur des fonctions @RISK reste intact, prêt à servir aux rapports de la simulation suivante.
Les masques sont définis au format de feuilles Excel ordinaires. Leur nom commence par RiskTemplate_, pour leur identification @RISK. Leurs fichiers peuvent aussi Contenir des formules Excel standard, pour permettre l'execution de calculs personnalisés sur les résultats de simulation.
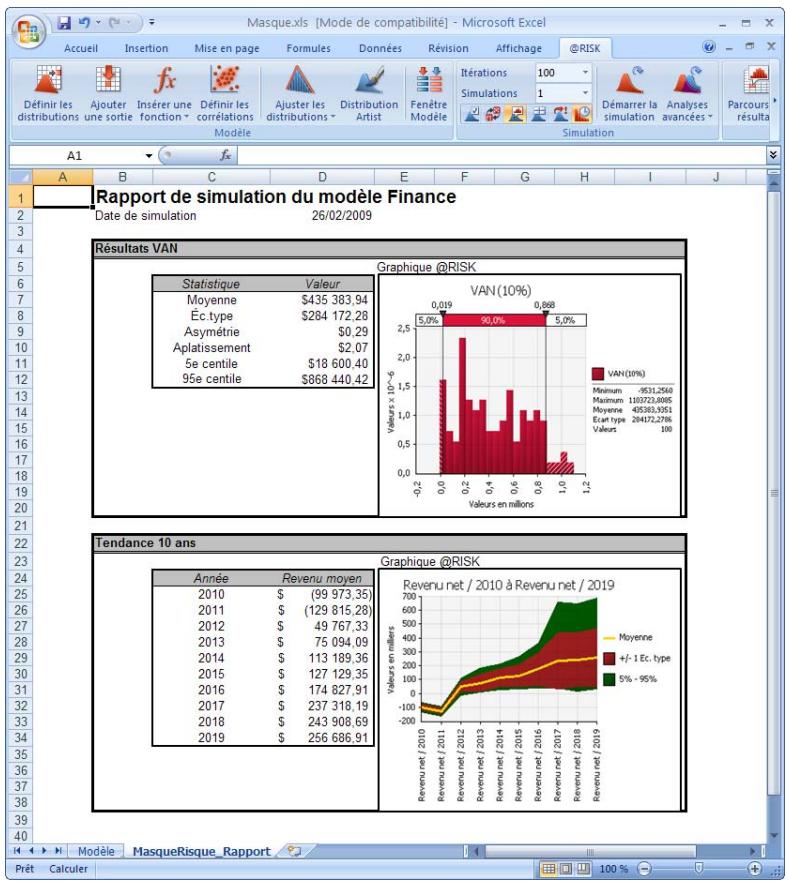
Le fichier type, Masque.XLS, illustré ci-dessus contient un masque. Référez-vous-y pour configurer vos propres rapports et masques personnalisés.
Commande permuter les fonctions @RISK
Active ou déactive les fonctions @RISK par permutation dans les formules des cellules.
La commande Permuter les fonctions @RISK active ou désactive les fonctions @RISK dans vos classeurs. Elle facilite ainsi l'échange de vos modèles avec vos collègues qui ne disposent pas de @RISK. Si le modèle change alors que les fonctions @RISK sont désactivées, @RISK actualise leurs emplacements et valeurs statiques lors de leur réactivation.
La nouvelle fonction de propriété RiskStatic facilite l'opération. RiskStatic conserve la valeur appelée à remplacer la fonction lors de sa désactivation. Elle précise aussi la valeur que @RISK renverra pour la distribution dans un recalcul Excel standard.
Lorsque vous cliquez sur l'icône Permuter les fonctions @RISK, l'option vous est donnée de permuter immédiatement les fonctions conformément aux paramètres de permutation actifs ou de changer les paramètres à utiliser.
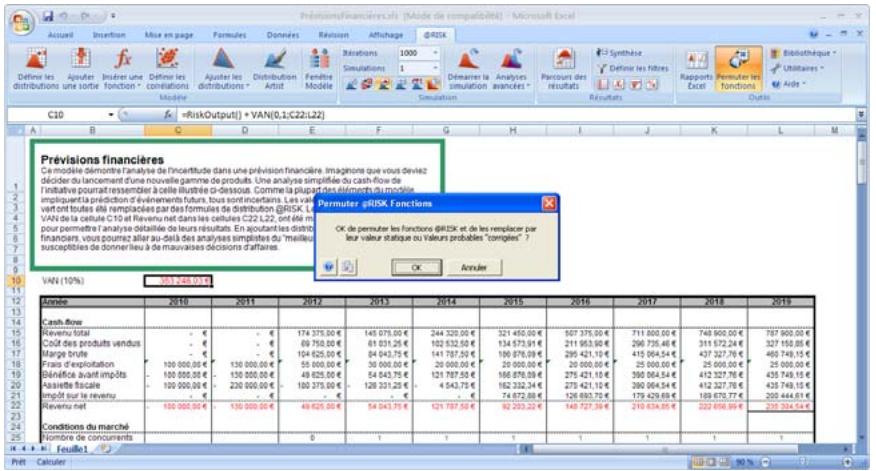
Lorsque les fonctions sont désactivées par permutation, la barre d'outils @RISK se désactive aussi et les fonctions @RISK éventuelles entrées ne sont pas reconnues.
Le mode d'opération de @RISK lors de la permutation des fonctions se définit dans la boîte d'options de permutation. En cas de changements apportés au classeur alors que les fonctions @RISK sont désactivées, @RISK peut vous signaler comment il procédera à la réinsertion des fonctions @RISK dans le modèle modifié. Dans la plupart des cas, @RISK peut : gérer automatiquement les changements apportés au classeur lorsque les fonctions sont désactivées.
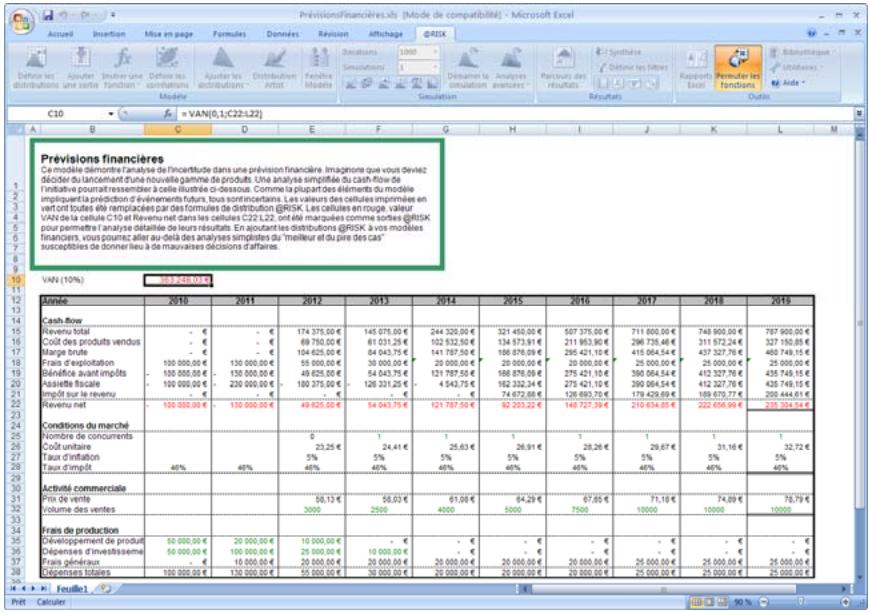
Options de permutation
L'icône Options de permutation (à côté de l'icône d'Aide dans la boîte de dialogue Permuter les fonctions @RISK) ouvre la boîte de dialogue Options de permutation.
Différents volets y sont proposés :
- Désactivation (retrait des fonctions @RISK par permutation) Activation (réinsertion des fonctions @RISK dans le classeur)
Lors de la désactivation par permutation, la valeur primaire utilisée pour remplacer la fonction @RISK est sa valeur statique. Il s'agit généralement de la valeur d'une formule du modèle que vous avez remplacée par une fonction @RISK. Cette valeur se stocke dans une distribution @RISK sous la fonction de propriété RiskStatic.
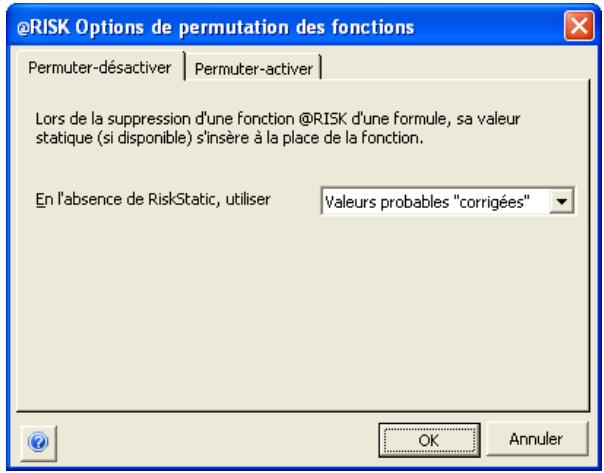
Si vous entrez une nouvelle distribution dans la fenêtre Définir une distribution, @RISK peut stocker automatiquement la valeur remplacée par une distribution dans la fonction de propriété RiskStatic. Supposons par exemple que la cellule C10 contienne la valeur 1000, comme indiqué dans la formule
C10:
Si, dans la fenêtre Définir une distribution, vous remplacez cette valeur par une distribution normale à moyenne de 990 et écart type de 100, la formule Excel devient :
C 1 0: = RiskNormal (9 9 0; 1 0 0; RiskStatic (1 0 0 0))
Remarquez que la valeur originale de la cellule (1000) est conservée dans la fonction de propriété RiskStatic.
Si la valeur statique n'est pas définie (en l'absence de fonction RiskStatic), différentes valeurs peuvent remplacer celles des fonctions @RISK permutes. Ces valeurs se sélectionnent sous les options En l'absence de RiskStatic, utiliser :
Valeur probable « corrigée » — la valeur probable ou moyenne d'une distribution, sauf pour les distributions discrètes. Pour les distributions discrètes, le paramètre Valeur probable « corrigée » renvoie comme valeur permutée la valeur discrète de la distribution la plus proche de la vraie valeur probable. Vraie valeur probable - les valeurs permutées sont identiques à celles de l'option Valeur probable « corrigée », sauf dans le cas des distributions discrètes telles que DISCRETE, POISSON, etc. Pour ces distributions, la vraie valeur probable est renvoyée comme valeur permutée même si la valeur probable est impossible pour la distribution entrée (s'il ne s'agit pas de l'un des points discrets de la distribution, notamment). Mode - la valeur mode d'une distribution. - Centile — la valeur de centile entrée pour chaque distribution.
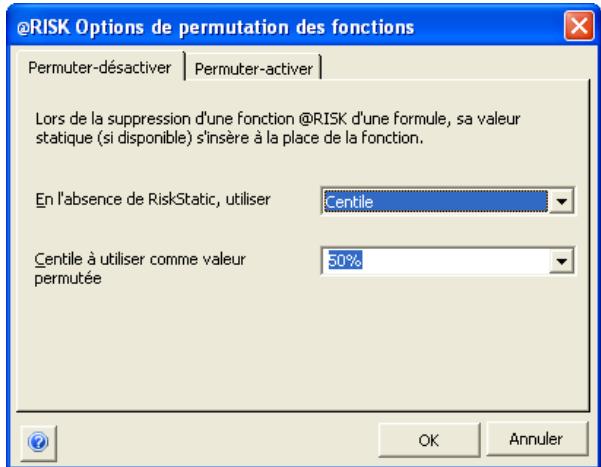
Options de permutation - activation
Les options d'activation déterminent la manière dont @RISK signalera les changements qu'il apportera au tableau avant la réinsertion des fonctions de distribution dans les formules. Les formules et valeurs du tableau sont en effet susceptibles de changer alors que les fonctions @RISK sont désactivées. Lors de la permutation de réactivation, @RISK identifie les endroits où ses fonctions doivent être réinsérées. Si vous le désirez, @RISK peut vous montrer tous les changements qu'il apportera à vos formules. Vous pouvez ainsi vérifier ces changements et vous assurer que les fonctions @RISK sont bien rétablies comme vous le désirez. Dans la plupart des cas, la permutation – activation est automatique : @RISK capture simplement les changements apportés aux valeurs statiques alors que les fonctions étaient désactivées. @RISK gère aussi automatiquement les formules déplacées et les lignes et colonnes insérées. Cependant, si les formules substituées aux fonctions @RISK ont été supprimées après la permutation – désactivation des fonctions, @RISK vous en avise avant de réinsérer les fonctions.
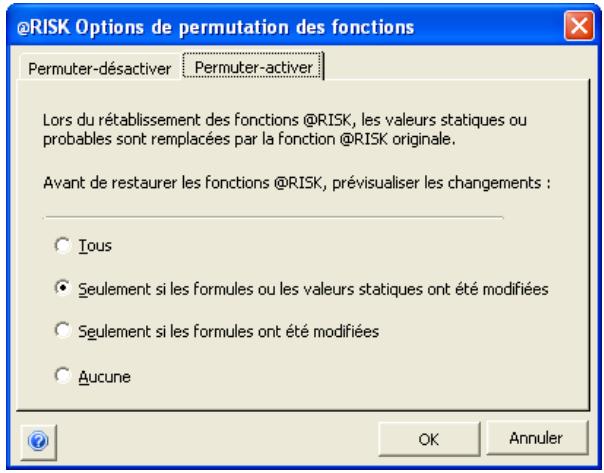
Les options suivantes sont proposées dans le volet Avant la restauration des fonctions @RISK, prévisualiser les changements :
- Tous. Sous cette option, tous les changements apportés au modèle sont signalés, même en l'absence de modifications aux formules et valeurs permutées pendant la désactivation des fonctions @RISK.
- Seulement si les formules et valeurs statiques ont été modifiées. Sous cette option, les seuls changements signalés sont ceux affectés par un changement de valeur statique ou de formule. Par exemple, si la distribution @RISK initiale était :
C 1 0: = RiskNormal (9 9 0; 1 0 0; RiskStatic (1 0 0 0))
Après la permutation - déactivation, la formule serait :
C10:
Si, pendant la permutation - désactivation des fonctions, la valeur de C10 devenait
C10:
@RISK actualiserait la valeur statique et réinsérerait la fonction suivante lors de la permutation - activation :
C 1 0: = RiskNormal (9 9 0; 1 0 0; RiskStatic (2 0 0 0))
Si l'option Seulément si les formules et valeurs statiques ont été modifiées était sélectionnée, @RISK signalerait ce changement avant de réactiver la fonction.
- Seulement si les formules ont été modifiées. Sous cette option, les seuls changements signalés sont ceux affectés par un changement de formule. Par exemple, si la distribution @RISK initiale se trouvait dans la formule
C 1 0: = 1, 1 2 + RiskNormal (9 9 0; 1 0 0; RiskStatic (1 0 0 0))
Après la permutation - déactivation, la formule serait :
C10:
Si, pendant la permutation - désactivation des fonctions, la formule de C10 revenait
C10:
@RISK réinsérerait la formule et fonction suivante lors de la permutation - activation :
C 1 0: = RiskNormal (9 9 0; 1 0 0; RiskStatic (1 0 0 0))
Si l'option Seulement si les formules et valeurs statiques ont été modifiées ou Seulement si les formules ont été modifiées était sélectionnée, @RISK signalerait ce changement avant de réactiver la fonction.
- Aucun. Aucun changement à apporter au modèle n'est signalé. @RISK insère automatiquement les changements recommandés.
Prévisualisation des changements avant la permutation — activation des fonctions @RISK
@RISK crée un rapport qui vous permet de prévisualiser les changements qui seront apportés au classeur lors de la permutation - réactivation des fonctions. Ce rapport présente la formule originale (avant permutation), originale (après permutation), courante et recommandée lors de la permutation - activation.
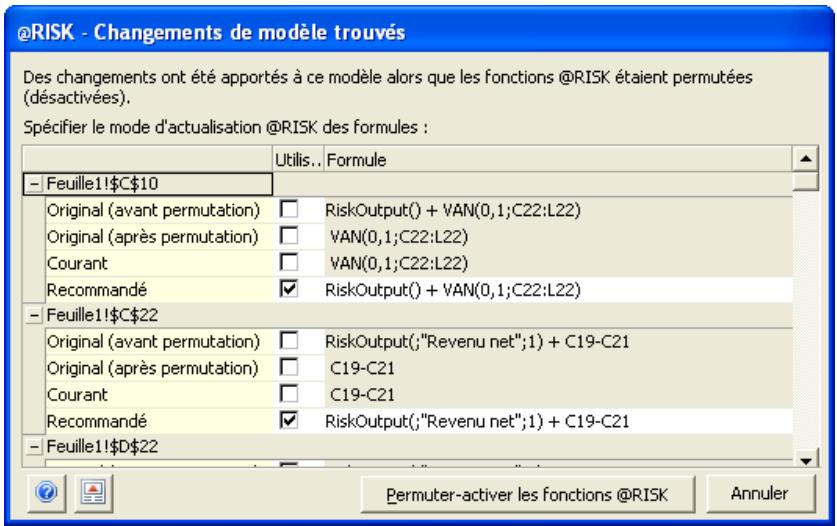
Permutation-activation des fonctions à l'ouverture d'un classeur
Au besoin, vous pouvez modifier la formule recommandée à réinsérer lors de la permutation, ou bien sélectionner l'une des autres formules affichées. En sélectionnant la commande Créer un rapport Excel de l'icône Édition, au bas de la fenêtre, vous pouvez créer un rapport Excel des changements apportés au modèle.
Si @RISK tourne, la permutation-réactivation des fonctions est proposée automatiquement à l'ouverture d'un classeur dont elles ont été « permutees-désactivées ». La réactivation n'est cependant pas proposée si le classeur est ouvert alors que la barre d'outils de @RISK est désactivée pour cause de fonctions permutees (désactivées).
Commande paramètres d'application
Affiche la boîte de dialogue Paramètres d'application, où se définissent les paramètres par défaut.
De nombreux paramètres @RISK peuvent être configurés par défaut et appliqués à chaque execution du programme. Ces paramètres concernent, notamment, les couleurs des graphiques, les statistiques affichées, la coloration des cellules @RISK dans Excel, etc.
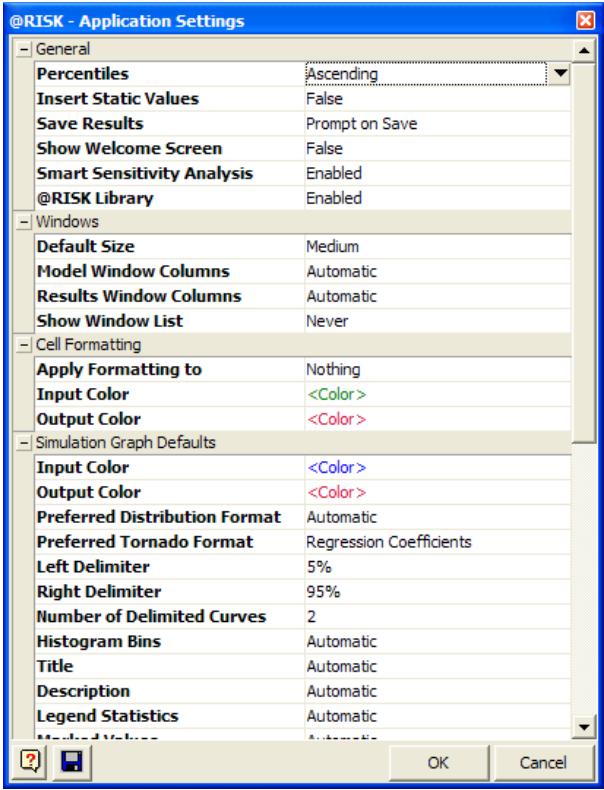
Toutes les fenêtres et tous les graphiques @RISK s'actualisent en cas de changement des paramètres d'application. Paramètres d'application offre donc un moyen aisé d'application de changements à toutes les fenêtres et tous les graphiques ouverts pendant une session @RISK.
Beaucoup de ces paramètres par défaut n'ont guère besoin d'explication. La plupart reflètent les paramètres proposés dans les autres boîtes de dialogue et écrans @RISK. Ceux décrits ici méritent quelque clarification :
- Centiles - Croissants ou Décroissants. La sélection du paramètre par défaut Décroissants pour les Centiles change tous les rapports statistiques @RISK, cibles et valeurs graphiques x et p de manière à partager les centiles cumulatifs décroissants. Par défaut, @RRISK rapporte les valeurs de centile en termes de centiles cumulatifs croissants, soit la probabilité qu'une valeur soit inférieure ou égale à une valeur x. Lorsque l'option Centiles décroissants est sélectionnée, @RISK rapporte les centiles cumulatifs décroissants, c.-à-d. la probabilité qu'une valeur soit supérieure à une valeur x.
Cette sélection se traduit aussi par l'entrée par défaut de centiles cumulatifs décroissants lors de l'entrée de distributions à paramètres secondaires dans la fenêtre Définir une distribution. Dans ce cas, le pourcentage de probabilité d'une valeur supérieure à la valeur entrée est spécifique.
- Insérer les valeurs statiques. Si ce paramètre est régé sur Vrai, une fonction RiskStatic s'insère automatiquement dans les distributions @RISK entrées dans la fenêtre Définir une distribution. Dans ce cas, lorsqu'une distribution @RISK remplace une valeur existante dans une formule de cellule, la valeur remplacee s'inscrit dans une fonction RiskStatic.
- Analyse de sensibilité intelligente Active ou désactive l'analyse de sensibilité intelligente. Pour plus de détails sur l'analyse de sensibilité intelligente et les situations où il convient de la désactiver, voir la commande Sensibilités.
- Afficher la liste des fenêtres. Par défaut, la liste des fenêtres @RISK (affichée en réponse à la commande Fenêtres du menu Utilitaires) s'affiche automatiquement quand plus de cinq fenêtres @RISK sont ouvertes à l'écran. Ce paramètre peut être configuré pour supprimer la liste des fenêtres, pour qu'elle s'affiche en permanence ou pour qu'elle s'affiche automatiquement.
- Formatage des cellules. Si vous le désirez, vous pouvez sélectionner le format à appliquer aux cellules du classeur porteuses d'entrées et de sorties @RISK. Vous pouvez sélectionner une couleur de police, cordure ou arrêtre-plan.
- Format de distribution préfééré. Spécifie le format à utiliser pour les graphiques de distribution @RISK, pour les entrées de modulo et les résultats de simulation. Si un graphique particulier ne peut pas être affiché au format préfééré, ce paramètre ne s'applique pas.
- Nombre de courbes délimitées. Fixe le nombre maximum de barres de délimiteurs affichées en haut de la fenêtre graphique, chaque barre étant associée à une courbe du graphique.
- Valeurs marquées. Définit les marqueurs par défaut à afficher sur les graphiques.
- Format numérique. Définit le format des chiffres affichés dans les graphiques et les marqueurs. Quantités unitaires fait référence aux valeurs rapportées, telles que la moyenne et l'écart type, basées sur les unités du graphique. Quantités non unitaires fait référence aux statistiques, telles que la symétrie et l'aplatissement, indépendantes des unités du graphique. Remarque : Si le format Devise est sélectionné, il ne s'applique que lorsque la cellule Excel de la sortie ou de l'entrée représentée graphiquement est au format devise.
Paramètres d'application à l'exportation et à l'importation
Les paramètres d'application @RISK peuvent être enregistrés dans un fichier RiskSettings. RSF. Ce fichier peut servir à la définition des Paramètres d'application à utiliser dans une autre installation de @RISK.
1) Choisissez la commande Exporter vers un fichier après avoir cliqué sur la seconde icône, au bas de la fenêtre des Paramètres d'application. 2) Enregistrez le fichier RiskSettings. RSF. 3) Placez le fichier RiskSettings. rsf dans le dossier RISK5 sous Program Files\Palisade du système dont vous pouvez définir les Paramètres d'application @RISK. Vous introduirez généralement le fichier RiskSettings. rsf dans ce dossier après une nouvelle installation de @RISK.
Si le fichier RiskSettings. rsf est présent à l'exécution de @RISK, les paramètres d'application qui s'y trouvent sont utilisés et l'utilisateur ne peut pas les changer. (Il peut cependant toujours modifier les paramètres de simulation.) Pour changer les paramètres d'application, l'utilisateur devra supprimer le fichier RiskSettings. rsf après la fermeture de @RISK.
La commande Importer depuis un fichier peut servir à charger les Paramètres d'application d'un fichier RiskSettings. RSF enregistré dans un dossier autre que RISK5. Contrairement aux paramètres d'un fichier RiskSettings. RSF enregistré dans le dossier RISK5 sous Program Files\Palisade, les paramètres importés sont modifiables à loisir.
Commande fenêtres
Affiche la liste des fenêtres @RISK.
La boîte de dialogue Fenêtres @RISK affiche la liste de toutes les fenêtres @RISK ouvertes et permet l'activation, la réorganisation et la fermeture de ces fenêtres.
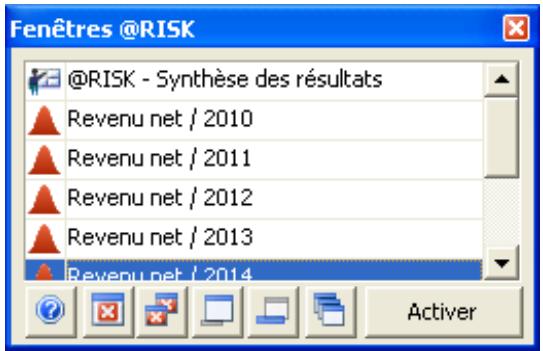
Il suffit de cliquer deux fois sur une fenêtre de la liste pour l'activer. Pour fermer une fenêtre, cliquez sur l'icône de fermeture rouge.
Commande ouvrir un fichier de simulation
Ouvrir les résultats et graphiques de simulation d'un fichier. RSK5.
Il peut arriver que vous désiriez stocker vos résultats de simulation dans un fichier. RSK5 extérieur, comme sous les versions antérieures de @RISK. L'approche peut être bonne quand la simulation est particulièrement volumineuse et que vous ne désirez pas intégrer ces données à votre classeur. Si vous enregistrez un fichier. RSK5 dans le même dossier, sous le même nom que le classeur, il s'ouvrira automatiquement à l'ouverture du classeur. Il faudra sinon passer par la commande Ouvrir un fichier de simulation du menu Utilitaires pour ouvrir le fichier. RSK5 enregistré ailleurs.
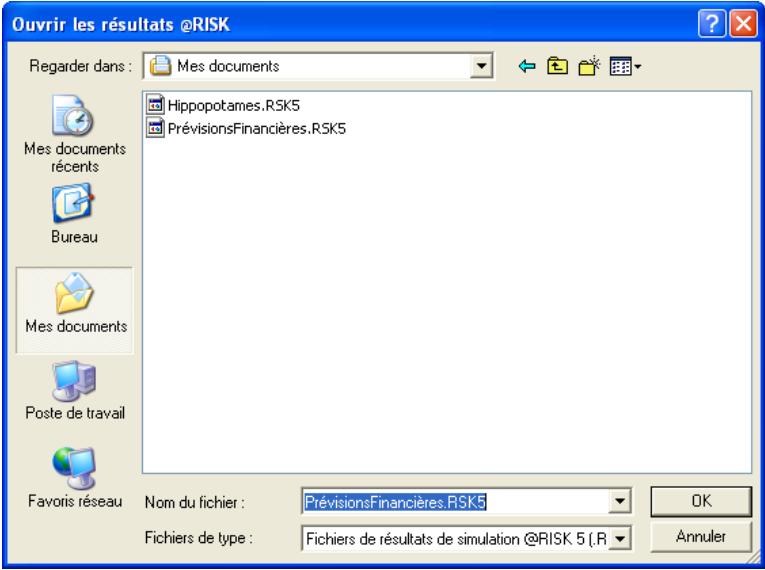
Pour plus de détails sur l'enregistrement et l'ouverture de résultats et graphiques de simulation, voir la section de ce manuel consacrée à l'Enregistrement et à l'ouverture de simulations @RISK.
Commande supprimer les données @RISK
Supprime des classeurs ouverts les données @RISK sélectionnées.
La commande Supprimer les données @RISK efface les données @RISK sélectionnées des classeurs ouverts.
Les données suivantes peuvent être supprimées :
- Résultats de simulation. Supprime les résultats de la simulation courante de @RISK, tels qu'affichés dans les fenêtres @RISK actives.
- Paramètres. Supprime tous les paramètres @RISK et les noms Excel qui leur sont associés. Les noms entrés pour les fonctions @RISK ne sont pas supprimés : ils se stockent dans les formules de cellule et pas dans la liste des noms définis d'un classeur Excel.
- Définitions d'ajustement de distributions. Supprime toutes les définitions de distributions ajustées telles qu'affichées dans le Gestionnaire d'ajustement.
- Fonctions du tableau. Supprime toutes les fonctions @RISK des classeurs ouverts et les remplace par leur valeur statique ou, à défaut, par la valeur de permutation spécifique dans les Options de permutation. Il ne s'agit cependant pas ici d'une permutation : les fonctions ne pourront pas être rétablies et toute l'information du modèle aura disparu.
Pour supprimer toute l'information @RISK de vos classeurs ouverts, sélectionnez toutes ces options.
Commande décharger le compagnon @RISK
Décharge le compagnon @RISK d'Excel.
La commande Décharger le compagnon @RISK décharge @RISK et ferme toutes les fenêtres @RISK.
Ouvrez et enregistrez les résultats et graphiques de simulation.
Les résultats des simulations (graphiques compris) peuvent s'enregistrer directement dans le classeur, dans un fichier. RSK5 extérieur ou dans la Bibliothèque @RISK. La commande Paramètres d'application du menu Utilitaires permet de configurer @RISK pour que les résultats de simulation s'enregistrent automatiquement dans le classeur, ou pour qu'ils ne s'y enregistrent jamais. Il importe de remarquer que le modèle - y compris les fonctions de distribution et les paramètres de simulation - s'enregistre toujours en même temps que le classeur. Les rapports Excel de @RISK placés dans les feuilles de calcul d'Excel s'enregistrent aussi avec leur classeur Excel correspondant. Les options d'enregistrement de simulation n'affectent que les résultats de simulation et les graphiques affichés dans les fenêtres @RRISK telles que les fenêtres graphiques, la fenêtre Données ou la fenêtre Synthèse des résultats.
Si vous le désirez, @RISK peut vous inviter à enregistrer vos résultats de simulation à chaque enregistrement du classeur, comme illustré ci-dessous:
Le bouton Options d'enregistrement (2e bouton en partant de la gauche) permet de sélectionner l'emplacement d'enregistrement des résultats.
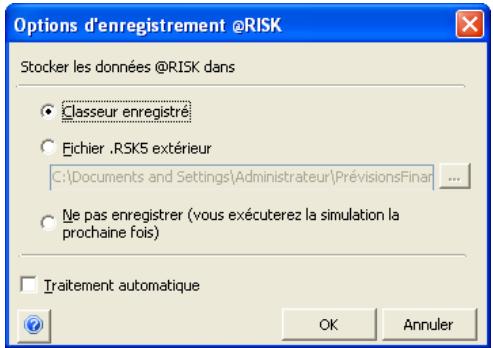
La boîte de dialogue Enregistrer les résultats @RISK propose les options suivantes :
- Classeur enregistré. Sous cette option, @RISK enregistre toutes les données de la simulation executée, y compris les fenêtres et graphiques ouverts, dans le classeur enregistré. Si les paramètres d'application définis sous le menu Utilitaires spécifient l'enregistrement automatique des simulations dans le classeur (ou si la case Traitement automatique est cochée), les données et graphiques @RISK s'enregistrent et s'ouvrent automatiquement, en même temps que le classeur.
- Fichier. RSK5 extérieur. Il est cependant parfois utile de stocker les résultats de simulation dans un fichier. RSK5 extérieur, comme sous les versions antérieures de @RISK. L'approche peut être bonne quand la simulation est particulièrement volumineuse et que vous ne désirez pas intégrer ces données à votre classeur. En cliquant sur le bouton d'option, en regard du nom de fichier, vous pouvez spécifier le nom et l'emplacement de votre fichier. RSK5. Si vous enregistrez ce fichier dans le même dossier, sous le même nom racine que le classeur, il s'ouvrira automatiquement à l'ouverture du classeur. Il faudra sinon passer par la commande Ouvrir un fichier de simulation du menu Utilitaires pour ouvrir le fichier. RSK5 enregistré ailleurs.
- Ne pas enregistrer. Sous cette option, @RISK n'enregistre pas les résultats de la simulation. Vous pourrez toujours réexéc
- Traitement automatique. Cette option spécifie que vous enregistrerez toujours vos données dans le classeur, ou que vous n'enregistrerez jamais vos résultats. Son effet est identique à celui de la sélection de l'option de commande Paramètres d'application correspondante, sous le menu Utilitaires.
Commandes bibliothèque
La commande Utilitaires Bibliothèque affiche la Bibliothèque @RISK. Les versions @RISK 5.5 Professional et Industrial sont assorties de la Bibliothèque @RISK, application de base de données distincte utile au partage des distributions de probabilités en entrée de @RISK et à la comparaison des résultats de différentes simulations. La Bibliothèque @RISK repose sur SQL Server pour le stockage des données @RISK. Au sein d'une organisation, une bibliothèque @RISK partagée donne accès
aux distributions de probabilités en entrée communes, prédéfinies pour les modèles de risque de l'organisation et aux résultats de simulation de différents utilisateurs.
Pour plus de détails sur la Bibliothèque @RISK, voir le chapitre Référence : Bibliothèque @RISK de ce manuel.
Ajouter les résultats à la bibliothèque
Ajoutez les résultats de simulation dans la Bibliothèque @RISK.
Pour stocker vos résultats de simulation dans la Bibliothèque @RISK, désélectionnez la commande Ajouter les résultats à la Bibliothèque, sous l'icône Bibliothèque de la barre d'outils @RISK pour Excel.
Sélectionnez ensuite les sorties des résultats courants à afficher dans la Bibliothèque.
Pour plus de détails sur le stockage de résultats dans la Bibliothèque @RISK, voir le chapitre Récurrence : Bibliothèque @RISK de ce manuel.
Afficher la bibliothèque
Affiche la Bibliothèque @RISK.
L'icône Bibliothèque de la barre d'outils @RISK ouvre la fenêtre Bibliothèque @RISK. Vous pouvez y consulter les distributions courantes, ainsi que les résultats de simulation stockés dans la bibliothèque.
Aide @RISK
Ouvre le fichier d'aide en ligne de @RISK.
La commande Aide @RISK du menu Aide ouvre le fichier d'aide principal de @RISK. Toutes les fonctionnalités et commandes @RISK y sont décrites.
Manuel en ligne
Ouvre le manuel en ligne de @RISK.
La commande Manuel en ligne du menu Aide ouvre l'exemplaire en ligne de ce manuel, au format PDF. Adobe Acrobat Reader doit être installé pour permettre la consultation de ce manuel en ligne.
Commande d'activation de licence
Affiche les informations de licence @RISK et permet l'autorisation des versions d'essai.
La commande Activation de licence du menu Aide affiche la boîte de dialogue Activation de licence, indiquant la version et les informations de licence de votre exemplaire de @RISK. La conversion des versions d'essai de @RISK en copie autorisée s'effectue aussi dans cette boîte de dialogue.
Pour plus de détails sur l'autorisation de votre exemplaire de @RISK, voir le Chapitre 1 : Mise en route.
Commande à propos
Affiche la version et les informations de copyright relatives à @RISK.
La commande À propos du menu Aide affiche la boîte de dialogue À propos, indiquant la version et les mentions relatives aux droits d'auteur de votre exemplaire de @RISK.
Référence : graphiques @RISK
Les entrées et les résultats d'une simulation s'expriment aisément sous forme graphique. @RISK présente de nombreux graphiques. La fenêtre Synthèse des résultats affiche notamment des vignettes graphiques des résultats de simulation de toutes les sorties et entrées. Il suffit de glisser-déplacer une vignette hors de la fenêtre de synthèse pour afficher un graphique grand format des résultats de la simulation, pour la sortie ou l'entrée désirée. En mode Parcours des résultats, les graphiques s'affichent aussi d'un simple clic sur une cellule de sortie ou d'entrée de la feuille de calcul.
Fenêtres flottantes et légendes
Les graphiques @RISK s'affichent dans deux types de fenêtres :
- Les fenêtres flottantes se disposent, de manière autonome, par-dessus Excel. Elles sont permanentes et ne se ferment qu'en réponse à une commande spécifique.
- Les fenêtres légendes sont, elles, attachées à une cellule. Il s'agit du type de fenêtre utilisé en mode Parcours. Une seule de ces fenêtres peut être ouverte à la fois, et le graphique change à chaque sélection de cellule dans Excel.
Les icônes du graphique permettent de détacher une fenêtre légende et de la transformer en fenêtre flottante, ou de rattachier une fenêtre flottante à la cellule qu'elle représenté.
Les icônes du bas de la fenêtre graphique permettent aussi de changer le type de graphique affiché. Un clic droit dans une fenêtre de graphique affiche par ailleurs un menu contextuel des commandes de format, échelle, couleur, titres et autres caractéristiques.
Statistiques et rapports
Chaque graphique @RISK s'accompagne des statistiques relatives à la sortie ou à l'entrée représentée. Chaque graphique et ses statistiques peuvent être copiés dans le Presse-papiers puis collés dans le tableau. Comme le transfert se fait par métadonnées Windows, les graphiques peuvent être redimensionnés et annotés dans le tableau.
La commande Graphique Excel permet de tracer les graphiques au format graphique naturel d'Excel. À l'image des autres graphiques Excel, ils sont modifiables et personnalisables à loisir.
Toutes les fenêtres graphiques @RISK proposent une série d'icônes, dans le coin inférieur gauche. Ces icônes régissent le type, le format et la disposition des graphiques affichés. L'icône Zoom permet une concentration rapide, en gros plan, sur une région du graphique.
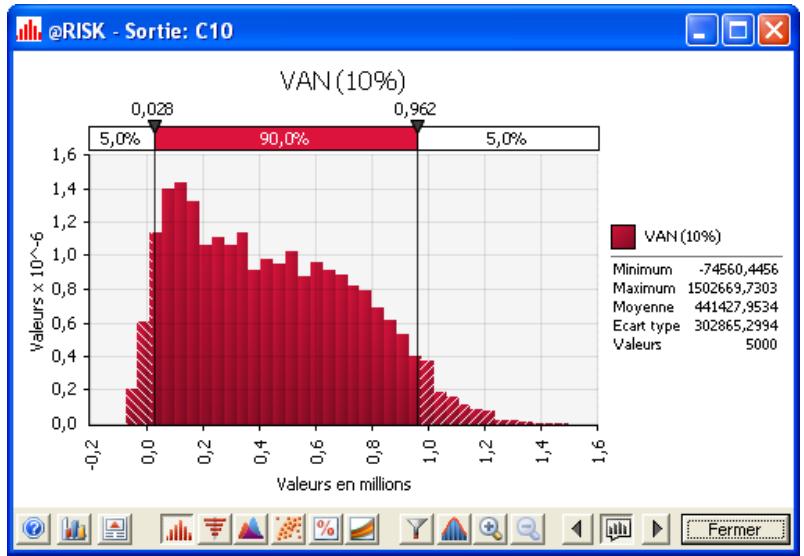
Les graphiques @RISK bénéficient d'un moteur graphique spécialement conçu pour le traitement des données de simulation. Ils peuvent être personnalisés et améliorés, souvent d'un simple clic sur l'objet approprié du graphique. Par exemple, pour changer le titre d'un graphique, il suffit de cliquer dessus et de taper le nouveau texte.
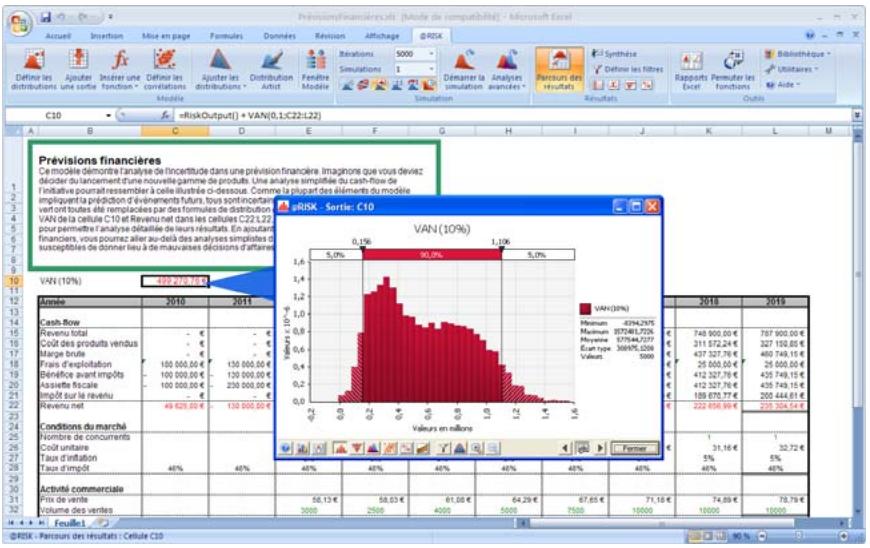
La personnalisation d'un graphique affiché peut aussi s'effectuer à travers la boîte de dialogue Options graphiques. La personnalisation concerne les couleurs, l'échelle, les polices et les statistiques affichées. La boîte de dialogue Options graphiques s'ouvre d'un clic droit sur un graphique et sélection de la commande Options graphiques, ou d'un clic sur l'icône Options graphiques, dans le coin inférieur gauche de la fenêtre graphique.
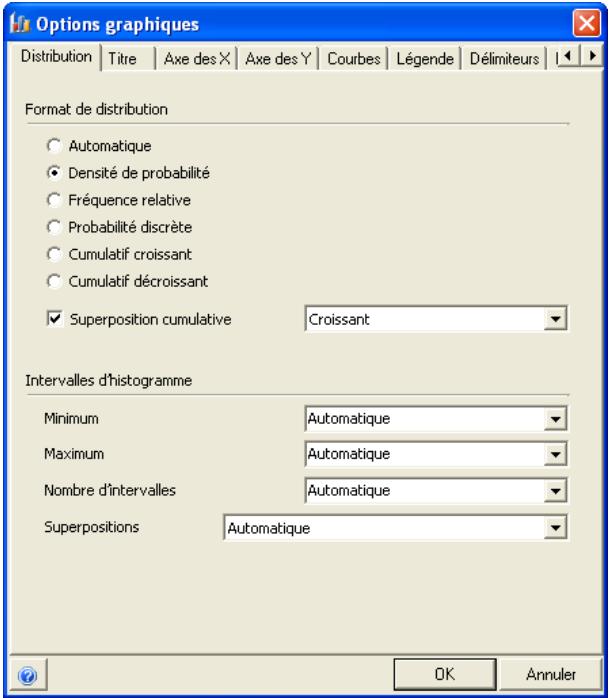
Les options peuvent varier suivant le type de graphique à personnaliser. Les options particulières à chaque type de graphique sont décrites dans la section de référence relative à ce type.
Graphiques des simulations multiples
Lors de l'exécution de simulations multiples, un graphique peut représenter les distributions de résultats de chaque simulation. Il est souvent utile de comparer les graphiques créés pour un même résultat dans des simulations différentes. Cette comparaison révèle la variation du risque par simulation.
Pour créer un graphique qui compare les résultats d'une même cellule dans des simulations multiples :
1) Exécutez plusieurs simulations en donnant une valeur supérieure à 1 au paramètre Nombre de simulations dans la boîte de dialogue Paramètres de simulation. À l'aide de la fonction RiskSimtable, changez les valeurs de la feuille de calcul par simulation. 2) Cliquez sur l'icône de sélection du numéro de simulation à afficher au bas de la fenêtre de parcours affichée. 3) Sélectionnez Toutes les simulations pour superposer les graphiques de toutes les simulations de la cellule sélectionnée.
Pour créer un graphique qui compare les résultats d'une cellule différente dans des simulations multiples :
4) Cliquez sur l'icône Superposer, au bas d'une fenêtre de parcours affichée, après l'exécution de simulations multiples. 5) Sélectionnez les cellules Excel dont vous désirez ajouter les résultats au graphique. 6) Sélectionnez le numéro de simulation des cellules à superposer.
La boîte de dialogue Sélectionner une simulation est aussi accessible dans les fenêtres de rapport, pour filtrer le rapport et n'afficher que les résultats d'une simulation particulière.
Histogrammes et graphiques cumulatifs
Un histogramme ou graphique cumulatif indique la plage des issues possibles et leur probabilité relative. Ce type de graphique peut être présenté sous forme d'histogramme standard ou de distribution de fréquence. Les distributions d'issues possibles peuvent aussi être affichées sous forme cumulative.
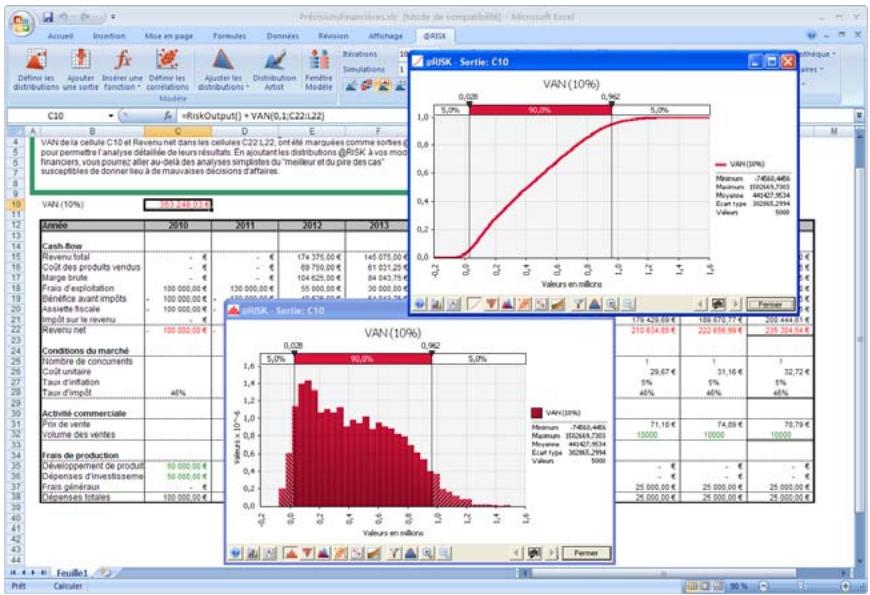
Délimiteurs
Faites glisser les délimiteurs d'un historiagramme ou d'un graphique cumulatif pour calculer différentes probabilités cibles. Les probabilités calculées s'affichent dans la barre des délimiteurs, au-dessus du graphique. L'approche permet de représenter graphiquement les réponses aux questions du type : « Quelle est la probabilité d'obtenir un résultat compris entre 1 et 2 millions ? » ou « Quelle est la mesure du risque d'un résultat négatif ? »
Les délimiteurs peuvent être affichés pour un nombre quelconque de superpositions. Le nombre de barres de délimiteurs affichées se définit dans la boîte de dialogue Options graphiques.
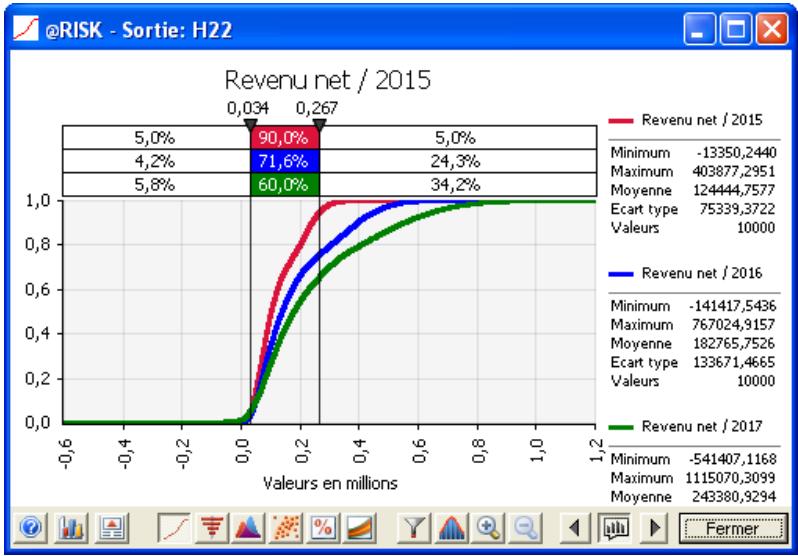
La comparaison graphique de plusieurs distributions est souvent utile. Il suffit, pour ce faire, de superposer les graphiques.
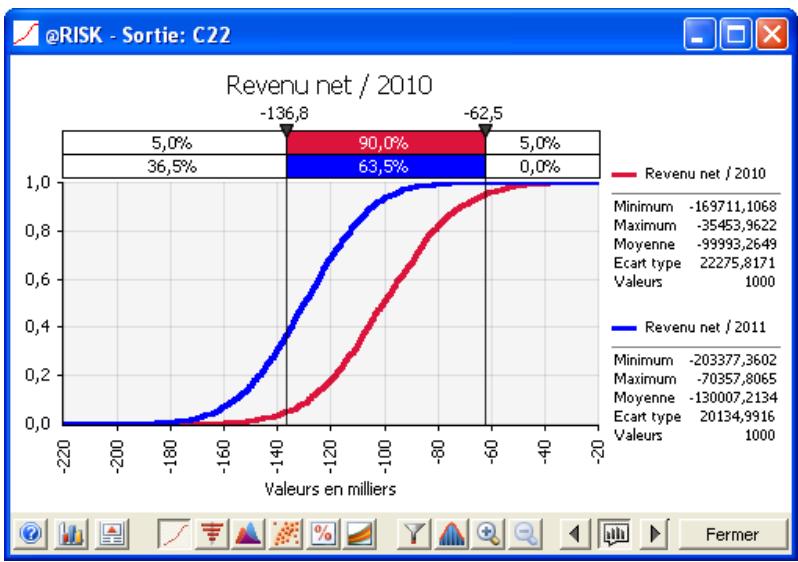
Pour ajouter un graphique superposé :
- Cliquez sur l'icône Superposer d'un graphique affiché et sélectionnez la ou les cellules Excel dont les résultats doivent être inclus dans le diagramme.
- Glissez-déplacez un graphique par-dessus un autre, ou glissez-déplacez une vignette graphique de la fenêtre Modèle ou Synthèse des résultats par-dessus un graphique ouvert. Cela fait, les statistiques des délimiteurs représentent les probabilités relatives à toutes les distributions inclues dans les graphiques superposés.
Remarque : Pour supprimer rapidement une courbe superposée, cliquez avec le bouton droit sur la légende couleur de la courbe à supprimer et choisissez la commande Supprimer la courbe.
Superposition d'histogrammes et de courbes cumulatives sur un même graphique
Il est parfois utile d'afficher un histogramme et une courbe cumulative d'une sortie ou d'une entrée donnée sur un même graphique. Ce type de graphique comporte deux axes Y : un à gauche pour l'histogramme et un deuxième, à droite, pour la courbe cumulative.
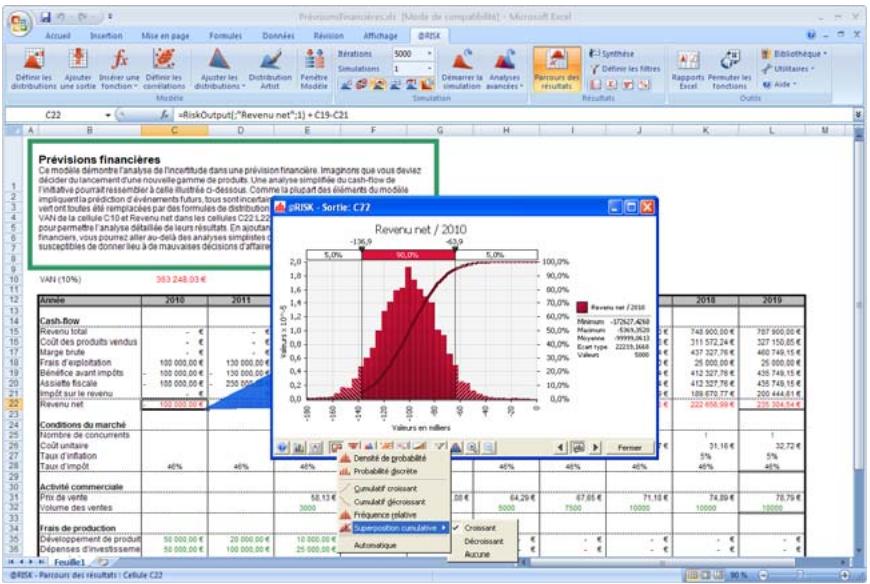
Pour ajouter une superposition cumulative à un graphique de densité de probabilité ou de fréquence relative, sélectionnez l'option Graphique cumulatif superposé après avoir cliqué sur l'icône Type de graphique dans une fenêtre graphique.
La boîte de dialogue Options graphiques s'ouvre d'un clic droit sur un graphique et sélection de la commande Options graphiques, ou d'un clic sur l'icône Options graphiques, dans le coin inférieur gauche de la fenêtre graphique. Pour les histogrammes et graphiques cumulatifs, la fenêtre Options graphiques - Onglet Distribution définit le type de courbe affichée et les options d'intervalle.
Les options suivantes sont proposées :
- Format de distribution. Modifie le format de la distribution affichée. Les paramètres suivants sont proposés :
- Automatique. Sélectionne automatiquement Fréquence relative pour les graphiques de résultats de simulation et Densité de probabilité pour les graphiques de distributions en entrée théoriques.
- Densité de probabilité et Fréquence relative. Pour les histograms, ces paramètres représentent l'unité de mesure de l'axe des Y. La fréquence relative représente la probabilité d'une valeur comprise dans la plage d'un intervalle (observations d'intervalle/observations totales). La densité de probabilité représente la valeur de fréquence relative divisée par la largeur de l'intervalle, assurant la constance des valeurs de l'axe Y tandis que le nombre d'intervalles varie.
- Probabilité discrète. Indique graphiquement la probabilité de chaque valeur de la plage minimum-maximum. Ce paramètre s'applique aux graphiques de distributions discrètes, représentant un ensemble limite de valeurs.
- Cumulatif croissant et Cumulatif décroissant. Affiche les probabilités cumulatives croissantes ou décroissantes (l'axe Y)
indique, respectivement, la probabilité d'une valeur inférieure ou supérieure aux valeurs de l'axe X.
- Intervalles d'histogramme. Ces paramètres spécifiques définissent le mode de répartition des intervalles de données dans un histogramme affiché. Les paramètres suivants sont proposés :
- Minimum. Définit la valeur minimum appelée à marquer le point de départ de l'histogramme. Sous Automatique, @RISK se refère à la valeur minimum des données représentées graphiquement. Maximum. Définit la valeur maximum appelée à marquer la fin de l'histogramme. Sous Automatique, @RISK se refère à la valeur maximum des données représentées graphiquement.
- Nombre d'intervalles. Définit le nombre d'intervalles d'histogramme calculés sur l'étendue d'un graphique. La valeur entrée doit être comprise entre 2 et 200. Sous l'option Automatique, le nombre optimal d'intervalles est calculé par méthode heuristique interne.
- Superpositions. Ce paramètre spécifie la manière dont @RISK va aligner les intervalles des distributions en présence de graphiques superposés. Les options suivantes sont proposées :
1) Simple histogramme - Sous cette option, la plage min-max compte de données des courbes (superpositions comprises) est répartie en intervalles, utilisés par chaque courbe du graphique. Cette approche facilite les comparaisons d'intervalles entre les courbes. 2) Simple histogramme à limites ajustées – Cette option est identique à la précédente, sauf aux extrémités de chaque courbe. De plus petits ou plus grands intervalles assurent, aux extrémités de chaque courbe, qu'elle n'outrepasse pas sa valeur minimum ou maximum. 3) Histogrammes indépendants - Sous cette option, chaque courbe suit ses propres intervalles, en fonction de ses valeurs de données minimum et maximum. 4) Automatique - Cette option sélectionne soit Simple histogramme à limites ajustées, soit Histogrammes indépendants, selon le chevauchement des données d'une courbe à l'autre. Si le chevauchement est suffisant, le paramètre Simple histogramme à limites ajustées est utilisé.
Options graphiques - Onglet Delimiteurs
Pour les historiques et graphiques cumulatifs, la fenêtre Options graphiques - Onglet Délimiteurs définit l'affichage des délimiteurs dans la fenêtre graphique.
Les probabilités calculées s'affichent dans la barre des délimiteurs, au-dessus du graphique. Les délimiteurs peuvent être affichés pour certaines courbes du graphique ou pour toutes.
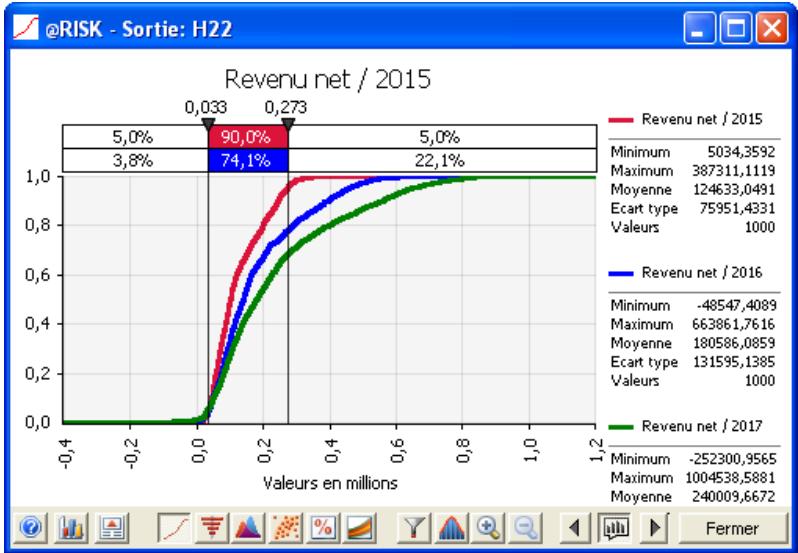
Options graphiques - Onglet Marqueurs
Pour les historiques et graphiques cumulatifs, la fenêtre Options graphiques - Onglet Marqueurs définit l'affichage des marqueurs dans la fenêtre graphique. Les marqueurs servent à annoter les valeurs clés d'un graphique.
Quand les marqueurs sont affichés, ils accompagnent les graphiques copiés dans un rapport.
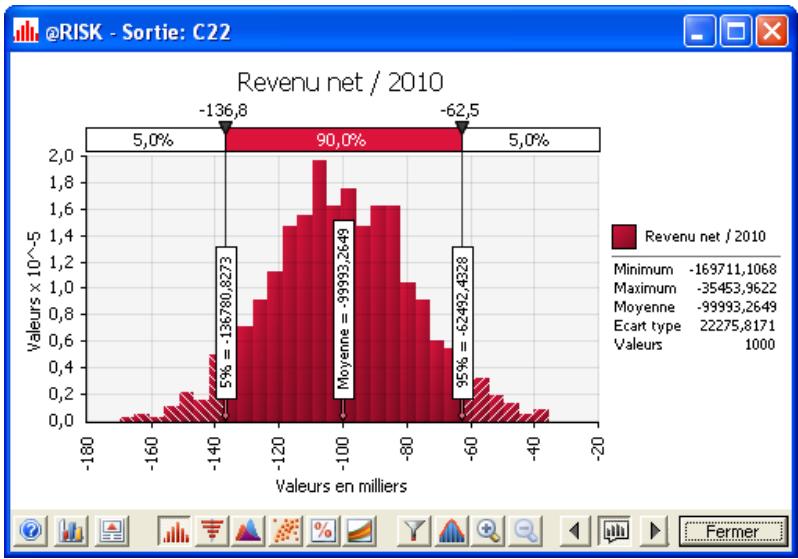
Ajuster une distribution à un résultat simulé.
L'icone Ajuster les distributions aux données, dans le coin inférieur gauche de la fenêtre graphique, ajuste les distributions de probabilités aux données d'un résultat simulé. Toutes les options d'ajustement des distributions aux données d'une feuille de calcul Excel sont également disponibles à l'ajustement à un résultat simulé. Pour plus de détails sur ces options, voir le Chapitre 6 : Ajustement de distributions.
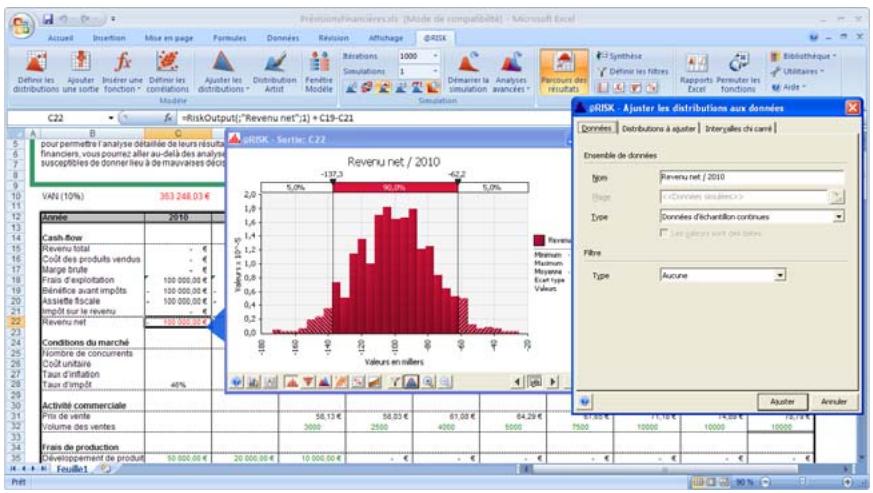
Graphiques « tornadoes
Les graphiques tornades d'une analyse de sensibilité affichent le classement des distributions en entrée qui affectent une sortie. Les entrées qui produisent le plus gros impact sur la distribution de la sortie sont représentées par les plus longues barres du graphique. Dans @RISK, les graphiques tornades peuvent s'afficher selon trois méthodes : coefficients de régression, régression (valeurs mappées) et coefficients de corrélation.
Les graphiques tornades d'une sortie s'affichent par sélection d'une ou plusieurs lignes dans la fenêtre @RISK - Synthèse des résultats, clic sur l'icône Tornado au bas de la fenêtre et sélection de l'une des trois options de graphique tornado proposées. Le graphique de distribution d'une sortie simulée peut aussi être changé en graphique tornado d'un clic sur l'icône Tornado dans le coin inférieur gauche du graphique, puis sélection d'un graphique tornado.
Types de graphiques tornadoes
@RISK propose trois types de graphique tornado : Coefficients de régression, Coefficients de corrélation et Régression - Valeurs mappées. Pour plus de détails sur la manière dont les valeurs affichées pour chaque type sont calculées, voir la section Commande Sensibilités du chapitre Référence : Commandes @RISK.
Pour les graphiques tornado de type Coefficients de régression et Coefficients de corrélation, la longueur de la barre affichée pour chaque distribution en entrée dépend de la valeur de coefficient calculée pour l'entrée. Les valeurs affichées sur chaque barre représentent la valeur de coefficient.
Un autre graphique tornado est disponible pour les résultats d'analyse de scénario. Pour produire ce graphique tornado, cliquez sur l'icône Tornado de la fenêtre Scenarios ou sur l'icône Scenarios d'une fenêtre graphique. Le graphique présente les entrées clés qui affectent la sortie lorsque celle-ci correspond au scénario entre - quand la sortie est supérieure au 90e centile, par exemple.
Pour les graphiques tornades de type Regression - Valeurs mappées, la longueur de la barre affichée pour chaque distribution en entrée représente la quantité de changement de la sortie imputable à une variation de +1 écart type au niveau de l'entrée. Les valeurs affichées sur chaque barre représentent la valeur de sortie associée à la variation +1 écart type de l'entrée. Ainsi, quand l'entrée varie de +1 écart type, la sortie varie de la valeur X associée à la longueur de la barre.
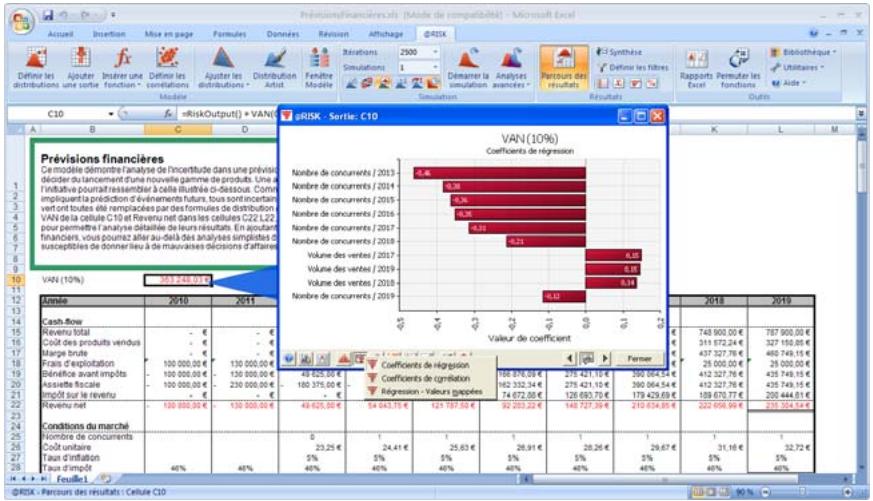
Un nombre maximum de 16 barres peut être affiché sur un graphique tornado. Pour afficher moins de barres, définissez le Nombre maximum de barres dans la boîte de dialogue Options graphiques. Le nombre maximum de barres par défaut se définit sous le paramètre Nbre max barres tornado de la boîte de dialogue Paramètres d'application.
Remarque: En présence de nombreuses barres, il n'y a pas toujours suffisamment de place pour afficher les étiquettes de chacune. Aggrandissez le graphique en faisant glisser un coin.
Graphique tornado de scénarios
Les résultats d'analyse de scénario s'affichent, graphiquement, dans des graphiques de type « tornado ». Pour produire un graphique tornado, cliquez sur l'icône Tornado de la fenêtre Scénarios ou sur l'icône Scénarios d'une fenêtre graphique. Le graphique tornado illustré ici présente les entrées clés qui affectent la sortie lorsque celle-ci correspond au scénario entre - quand la sortie est supérieure au 90e centile, par exemple.
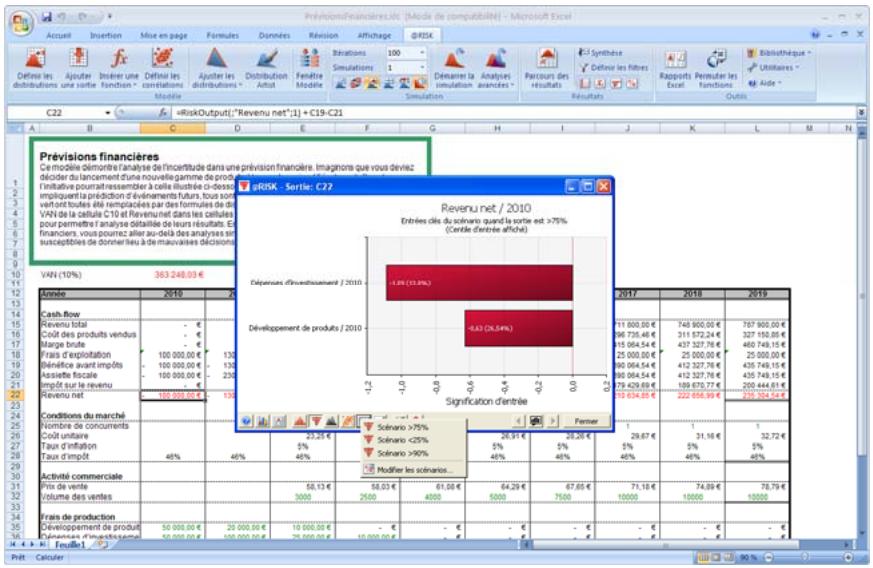
Diagrammes de dispersion
Les diagrammes de dispersion de @RISK affichent le rapport entre une sortie simulée et les échantillons de la distribution en entrée. Pour créer un diagramme de dispersion :
- Cliquez sur l'icône Dispersion d'un graphique affiché et sélectionnez la ou les cellules Excel dont les résultats doivent être inclus dans le diagramme.
- Sélectionnez une ou plusieurs sorties ou entrées dans la fenêtre Synthèse des résultats et cliquez sur l'icône Diagramme de dispersion.
- Glissez-déplacez une barre (l'entrée à représenter dans le diagramme de dispersion) du graphique tornado.
- Affichez une matrice de diagrammes de dispersion dans la fenêtre Analyse de sensibilité (voir la section de ce chapitre consacrée à la commande Sensibilités).
- Cliquez sur une matrice de corrélation en mode Parcours pour afficher une matrice de diagrammes de dispersion représentant les correlations simulées entre les entrées corréclées dans la matrice.
À l'image des autres graphiques @RISK, les diagrammes de dispersion s'actualisent en temps réel en cours de simulation.
Un diagramme de dispersion est un graphique x-y qui présente la valeur en entrée échantillonnée par rapport à la valeur de sortie calculée à chaque iteration de la simulation. L'ellipse de confiance identifie la région où tombent, à un niveau de confiance donné, les valeurs x-y. Les diagrammes de dispersion peuvent aussi être normalisés de sorte que les valeurs de plusieurs entrées soient plus facilement comparables sur un même diagramme.
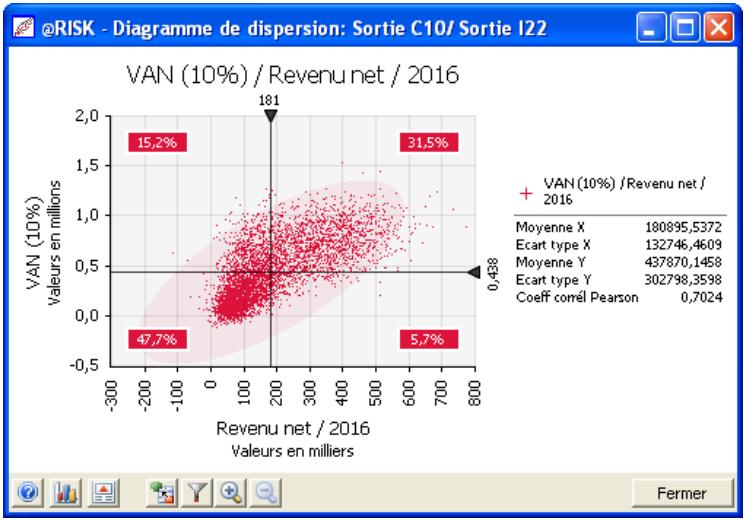
Remarque : Les diagrammes de dispersion s'affichent toujours dans des fenêtres flottantes (par opposition aux fenêtres légendes)
À l'image de nombreux autres graphiques @RISK, plusieurs diagrammes de dispersion peuvent être superposés pour indiquer le rapport entre les valeurs de deux (ou plusieurs) entrées et celle d'une sortie.
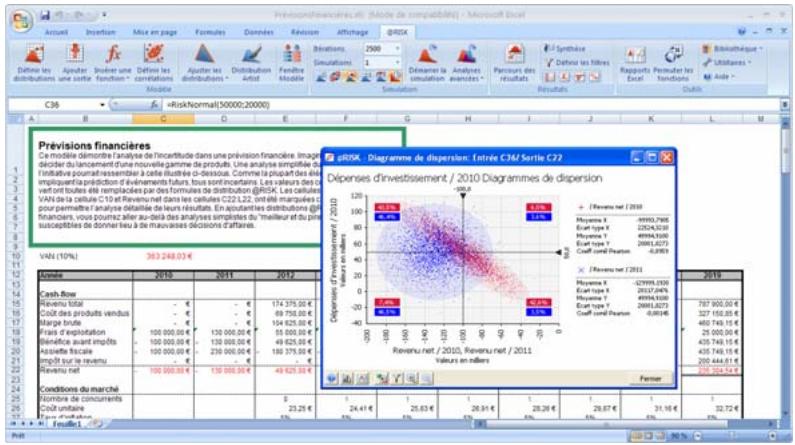
Plusieurs sorties peuvent aussi être inclues dans une superposition de diagrammes de dispersion. L'approche est utile à l'examen de la manière dont une même entrée affecte différentes sorties de simulation.
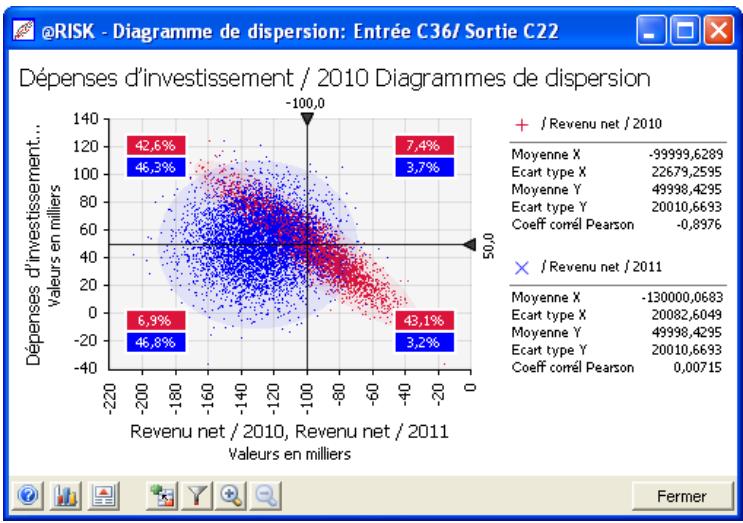
Dans le diagramme de dispersion ci-dessus, l'entrée affecte largement la sortie Revenu net / 2010 mais elle est sans effet sur la sortie Revenu net / 2011.
Remarque: L'icône Ajouter (signe +), au bas de la fenêtre graphique, permet de superposer des diagrammes de dispersion.
Pour les diagrammes de dispersion, la fenêtre Options graphiques - Onglet Dispersion spécifique si les valeurs affichées doivent être normalisées. Les paramètres de cette fenêtre définit essent les ellipses de confiance.
La fenêtre Options graphiques - Onglet Dispersion propose les options suivantes :
- Normalisation. Ce paramètre détermine si les valeurs affichées dans le diagramme de dispersion doivent être normalisées ou non. Les valeurs normalisées s'affichent en termes de variation d'écart type par rapport à la moyenne (plutôt qu'en valeurs réelles). La normalisation est particulièrement utile lors de la superposition de diagrammes de plusieurs distributions en entrée distinctes. Elle établit une échelle commune entre les entrées et facilite ainsi les comparaisons d'impact sur les sorties. La normalisation Valeurs Y normalise les valeurs en entrées et la normalisation Valeurs X, celles de sortie. Ellipses de confiance (sous normale bivariate). Une ellipse de confiance s'obtient par ajustement de la meilleure distribution normale bivariate aux données x-y représentées sur le diagramme de dispersion. La région indiquée par l'ellipsoid est celle où, compte tenu du niveau de confiance paramétré, un échantillon de cette distribution doit tomber. Ainsi, sous niveau de confiance de 99%, on peut supposer avec 99% de certitude qu'un échantillon de la meilleure distribution normale bivariate ajustée tombera dans l'ellipse affichée.
Délimiteurs de diagramme de dispersion
Les diagrammes de dispersion comportent, sur les deux axes, des délimiteurs qui permettent d'afficher le pourcentage de points du graphique tombant dans chaque quadrant délimité. En présence de courbes superposées, une couleur différente est attribuée à la valeur de % de chaque tracé.
Comme pour les graphiques de distribution, le nombre de tracés d'un graphique superposé pour lequel les pourcentages sont indiqués peut être configuré sous l'onglet Délimiteurs de la boîte de dialogue Options graphiques.
En cas de zoom avant sur une région du diagramme de dispersion, la valeur % indiquée dans chaque quadrant représente le % du total de points graphiques présents dans le quadrant visible (total points graphiques = nombre total de points du graphique original sans zoom).
Remarque: Le point d'intersection des délimiteurs des axes X et Y permet d'ajuster les deux délimiteurs en même temps.
Graphiques de synthèse
@RISK propose deux types de graphiques de synthèse des tendances d'un groupe de sorties simulées (ou d'entrées) : tendance et boîte de synthèse. Pour créer l'un ou l'autre de ces graphiques:
- Cliquez sur l'icone Graphique de synthèse au bas d'une fenêtre graphique et Sélectionnez la ou les cellules Excel dont les résultats doivent être inclus dans le diagramme.
- Dans la fenêtre @RISK - Synthèse des résultats, sélectionnez les lignes des sorties, ou entrées, à inclure dans le graphique de synthèse, puis cliquez sur l'icône Graphique de synthèse au bas de la fenêtre (ou cliquez droit dans le tableau) et sélectionnez Tendance ou Boîte de synthèse.
Pour une plage de sortie, vous pouvez aussi cliquer sur l'en-tête Nom de plage et sélectionner Graphique de synthèse.
Les graphiques Tendance et Boîte de synthèse sont interchangeables. Pour changer le type affiché, cliquez simplement sur l'icône appropriée au bas de la fenêtre graphique et sélectionnez le nouveau type de graphique désiré.
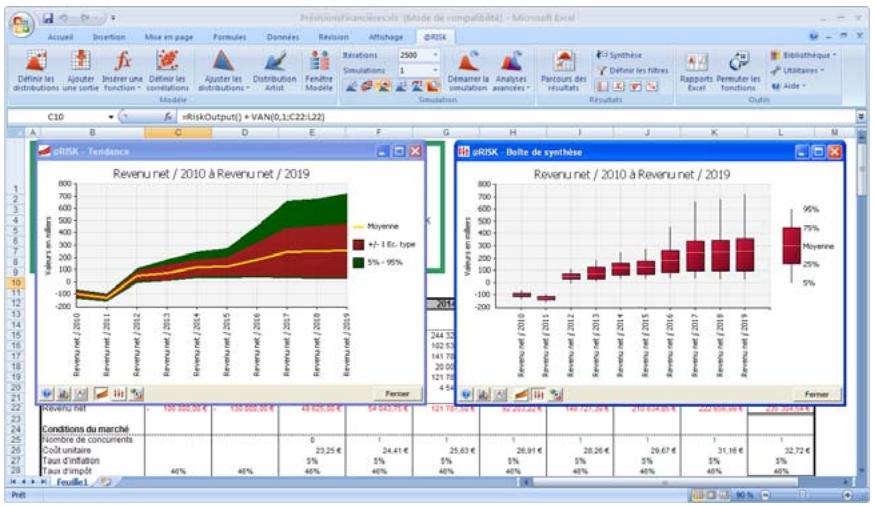
Remarque: L'icône Ajouter (signe +), au bas de la fenêtre graphique, permet d'ajouter des éléments au graphique de synthèse.
Le graphique Tendance récapitule les changements de distributions de probabilités multiples ou d'une plage de sortie. Le graphique de synthèse prend cinq paramètres dans chaque distribution sélectionnée (la moyenne plus deux valeurs de bande supérieure et deux valeurs de bande inférieure) et représente graphiquement la variation de ces cinq paramètres sur la plage de sortie. Les valeurs de la bande supérieure sont définies par défaut à +1 écart type et 95e centile de chaque distribution, et les deux valeurs de la bande supérieure, à -1 écart type et 5e centile de chaque distribution. Ces valeurs peuvent être modifiées à travers les options de l'onglet Tendance de la boîte de dialogue Options graphiques.
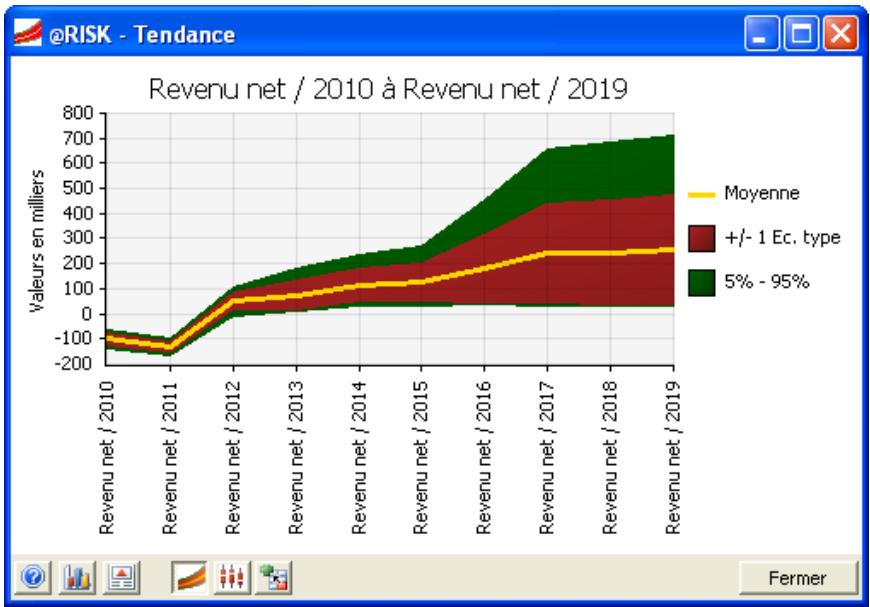
Le graphique de synthèse est particulièrement utile à l'affichage de la variation du risque dans le temps. Ainsi, une plage de sortie peut représenter toute une ligne de feuille de calcul (Bénéfices annuels, par exemple). Le graphique de synthèse afficherait dans ce cas les tendances des distributions de bénéfices d'une année à l'autre. Plus la bande est large autour de la moyenne, plus les résultats possibles sont variables.
Lors de la génération d'un graphique de synthèse, @RISK calcule la moyenne et les quatre valeurs de bande (5e et 95e centile, par exemple) pour chaque cellule de la plage de sortie représentée. Ces points sont représentés graphiquement par des lignes supérieure et inférieure. Les motifs intermédiaires sont ensuite ajoutés. La moyenne et les valeurs des deux bandes des points ajoutés sont calculées par interpolation.
La fenêtre Options graphiques - Onglet Tendance spécifie les valeurs affichées dans chaque bande du graphique Tendance, ainsi que les couleurs de ces bandes.
Les options suivantes sont proposées :
- Statistiques. Ces paramètres déterminent les valeurs affichées pour la ligne centrale, bande interne et bande externe du graphique Tendance. Les paramètres suivants sont proposés : Ligne centrale: Moyenne, Médiane ou Mode.
- Bande interne, Bande externe : plage décrivie par chaque bande. La bande interne doit toujours être « plus étroite » que la bande externe. Veillez donc à choisir un ensemble de statistiques complétant une plus large plage de la distribution pour la bande externe, par rapport à la bande interne.
- Formatage. Ces paramètres régissent la couleur et l'ombrage de chacune des trois bandes du graphique Tendance.
Boîte de synthèse
La forme graphique Boîte de synthèse présente un diagramme en boîte par distribution sélectionnée pour le graphique de tendance. Un graphique en boîte (ou « boîte à moustaches ») affiche une « boîte » représentant la plage interne définie d'une distribution et des « moustaches » représentatives des limites extérieures de la distribution. La ligne interne, dans la boîte, marque l'emplacement de la moyenne, médiane ou du mode de la distribution.
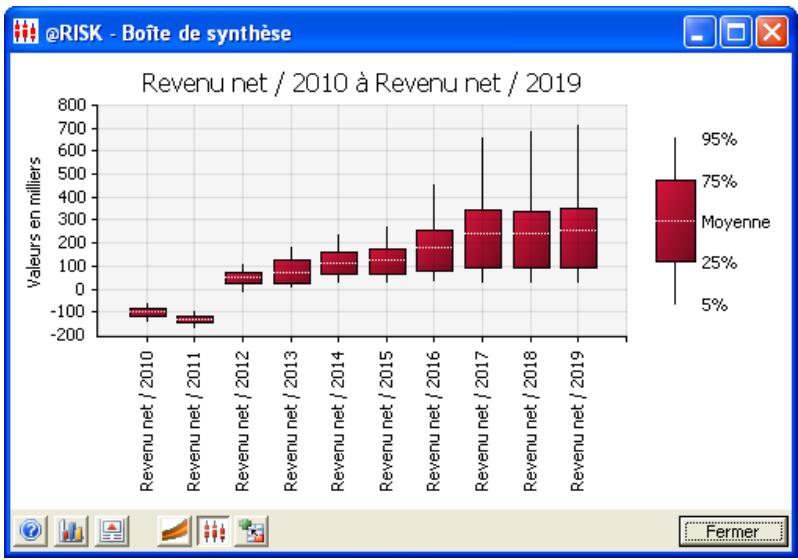
La fenêtre Options graphiques - Onglet Boîte à moustaches spécifie les valeurs utilisées pour la ligne centrale, la boîte et les moustaches de chaque boîte du graphique, ainsi que les couleurs des boîtes.
Les options suivantes sont proposées :
- Statistiques. Ces paramètres déterminent les valeurs affichées pour la ligne centrale, la boîte et les moustaches du graphique Boîte à moustaches. Les paramètres suivants sont proposés : Ligne centrale : Moyenne, Médiane ou Mode.
- Boîte : plage désignée par chaque boîte. La plage de la boîte doit toujours être « plus étroite » que les moustaches. Veillez donc à choisir un ensemble de statistiques complétant une plus large plage de la distribution pour les moustaches, par rapport à la boîte.
- Moustaches : points extrêmes des moustaches.
- Formatage. Ces paramètres régissent la couleur et l'ombrage de la boîte.
Lors de l'exécution de simulations multiples, un graphique de synthèse peut représenter les ensembles de distributions de résultats de chaque simulation. Il est souvent utile de comparer les graphiques de synthèse créés pour les mêmes distributions dans des simulations différentes. Cette comparaison fait apparaître les variations par simulation de la tendance de la valeur probable et du risque pour les distributions.
Pour créer un graphique de synthèse qui compare les résultats d'une même plaque de cellules dans des simulations multiples :
1) Exécutez plusieurs simulations en donnant une valeur supérieure à 1 au paramètre Nombre de simulations dans la boîte de dialogue Paramètres de simulation. À l'aide de la fonction RiskSimtable, changez les valeurs de la feuille de calcul par simulation. 2) Cliquez sur l'icône Graphique de synthèse, au bas de la fenêtre de parcours affichée pour la première cellule à ajouter au graphique de synthèse. 3) Sélectionnez les cellules Excel dont vous désirez ajouter les résultats au graphique. 4) Sélectionnez Toutes les simulations dans la boîte de dialogue.
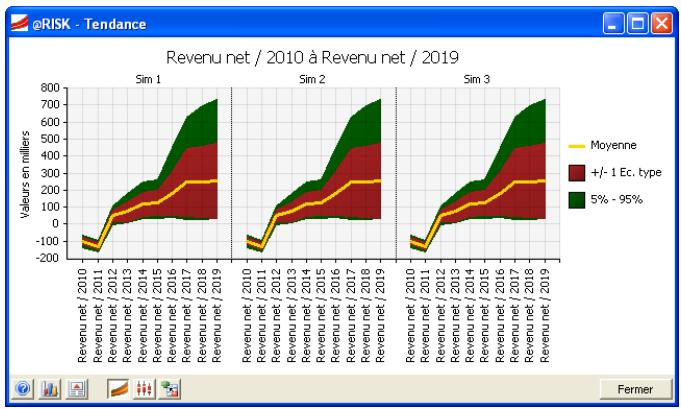
Graphique de synthèse d'un même résultat sur plusieurs simulations
Pour créer un graphique de synthèse comparant les résultats d'une même cellule sur plusieurs simulations, suivez les étapes énoncées ci-dessus en ne sélectionnant cependant, au point 3, qu'une cellule Excel à inclure dans le graphique de synthèse. Le graphique affiché présente les cinq paramètres de la distribution de la cellule (la moyenne plus deux valeurs de bande supérieure et deux valeurs de bande inférieure) pour chaque simulation. Il représente ainsi la synthèse de variation de la distribution de la cellule par simulation.
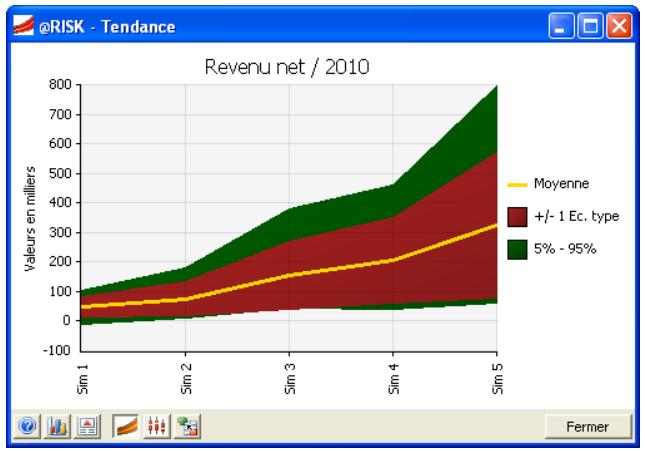
Des graphiques de synthèse de simulations multiples peuvent aussi être produits par sélection des lignes de la fenêtre @RISK - Synthèse des résultats relatives aux sorties ou aux entrées (par simulation) à inclure dans le graphique de synthèse. On clique ensuite sur l'icône Graphique de synthèse au bas de la fenêtre (ou clic droit sur le tableau) et on sélectionne Tendance ou Boîte de synthèse.
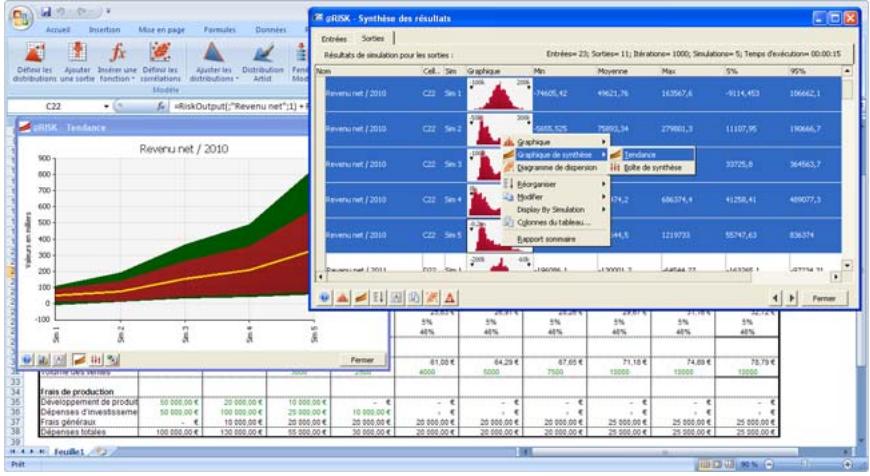
Formatage des graphiques
Les graphiques @RISK bénéficient d'un moteur graphique spécialement conçu pour le traitement des données de simulation. Les graphiques peuvent être personnalisés et améliorés à loisir. Les titres, légendes, couleurs, échelles et autres paramètres se configurent tous à travers les sélections de la boîte de dialogue Options graphiques. Cette boîte de dialogue s'ouvre d'un clic droit sur un graphique et en sélectionnant la commande Options graphiques, ou d'un clic sur l'icône Options graphiques, dans le coin inférieur gauche de la fenêtre graphique.
Les options proposées sous les onglets de la boîte de dialogue Options graphiques sont décrites ici. Remarque : Toutes les options ne sont pas disponibles pour tous les types de graphiques. Les options disponibles peuvent varier en fonction du type de graphique considéré.
Options graphiques - Onglet Titre
Les options de la fenêtre Options graphiques - onglet Titre définissant les titres à afficher sur le graphique. Le titre principal du graphique et sa description se configurent ici. Si vous ne définissez pas de titre, @RISK en affecte automatiquement un, en fonction du nom des cellules de sortie ou d'entrée représentées.
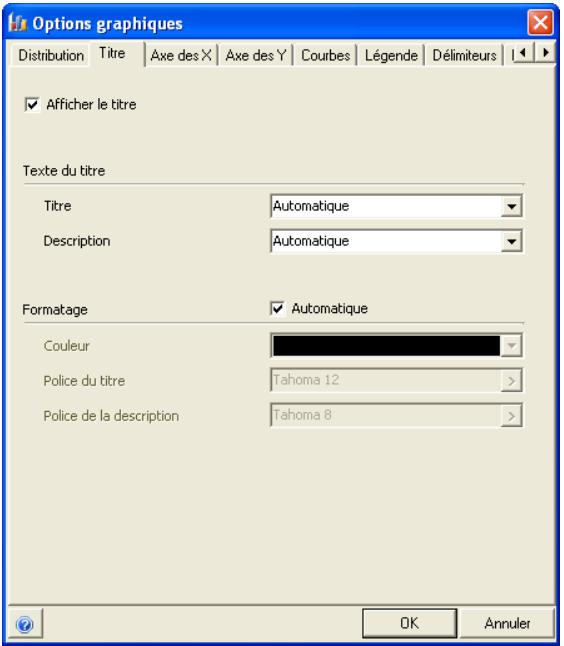
Options graphiques - Onglets Axe X et Axe Y
Les options de la fenêtre Options graphiques - onglets Axe X et Axe Y définissant l'échelle et les titres des axes du graphique. Un facteur d'échelle (tel que milliers ou millions) peut être appliqué aux valeurs minimum et maximum d'axe et le nombre de graduations des axes peut être modifié. Les valeurs d'échelle des axes peuvent aussi être modifiées directement sur le graphique par glissement-déplacement des limites de l'axe vers un nouveau minimum ou maximum. La fenêtre Options graphiques - onglet Axe X d'un graphique de distribution est illustré ici.
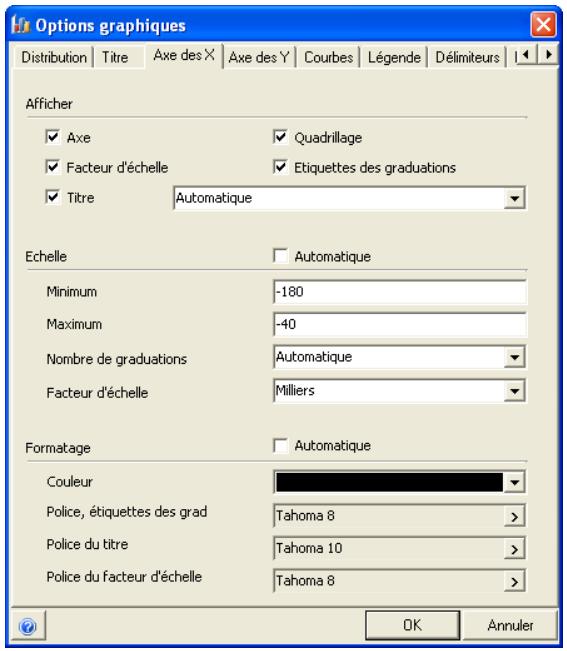
Remarque: Suivant le type de graphique utilisé, les options proposées sur les onglets des axes X et Y peuvent être différentes. Différentes options d'échelle sont en effet disponibles pour différents types de graphiques (récapitulatif, distribution, dispersion, etc.)
Les options de la fenêtre Options graphiques - onglet Courbes définissent la couleur, le style et l'interpolation de valeur de chaque courbe du graphique. La définition de la «courbe» varie selon le type de graphique représenté. Par exemple, dans un historisme ou graphique cumulatif, la courbe est associée au graphique primaire de chaque superposition. Dans un diagramme de dispersion, elle l'est à l'ensemble de données X-Y représenté sur le graphique. Cliquez sur une courbe proposée dans la liste Courbes pour en afficher les options disponibles.
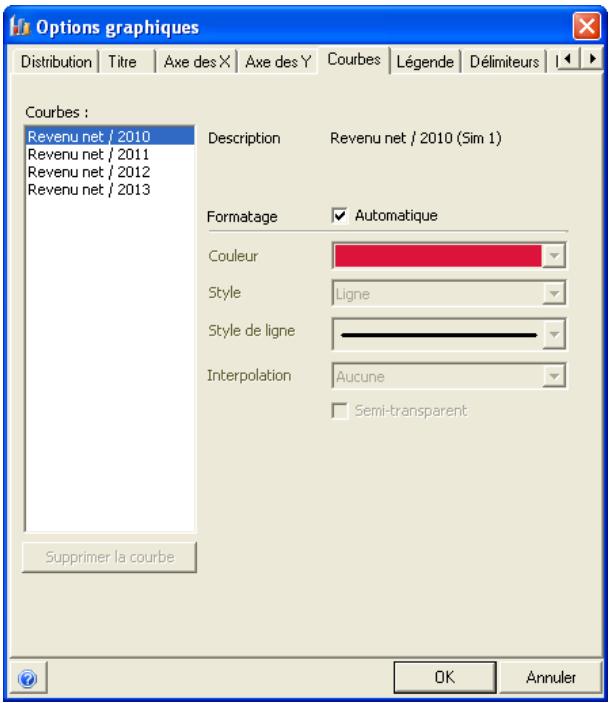
Les options de la fenêtre Options graphiques - onglet Légende définissant les statistiques à afficher avec le graphique.
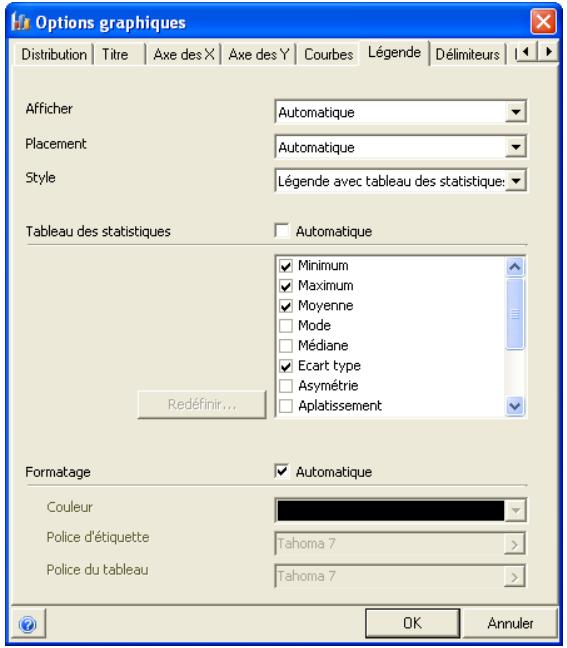
Plusieurs statistiques peuvent être affichées pour chaque courbe représentée dans un graphique. Les statistiques disponibles varient suivant le type de graphique représenté. Ces statistiques se copient avec le graphique lors de son insertion dans un rapport. Elles s'actualisent aussi lors de l'exécution d'une simulation. Pour changer les statistiques affichées avec un graphique :
1) Désélectionnez le paramètre Automatique pour permettre la personnalisation des statistiques affichées. 2) Cochez les cases des statistiques désirées. 3) Cliquez sur Redéfinir pour changer les valeurs de centile à rapporter.
Pour supprimer les statistiques d'un graphique:
- Remplacez l'option Style affichée par Simple légende.
Pour supprimer la légende et les statistiques d'un graphique :
- Remplacez l'option Afficher sélectionné par Jamais.
Les options de la fenêtre Options graphiques - onglet Autre définissent les autres paramètres disponibles pour le graphique affiché : couleurs de base et formatting numérique et des dates.
Les chiffres affichés sur un graphique peuvent être formatés en fonction du degré de précision désiré à l'aide des options Formats numériques. Les options numériques disponibles varient suivant le type de graphique représenté.
Les dates affichées sur un graphique peuvent être formatées en fonction du degré de précision désiré à l'aide des options de format de date proposées. Les formats disponibles varient suivant le type de graphique représenté.
Pour les graphiques de distribution, Statistiques (non unitaires) fait référence aux statistiques, telles que la symétrie et l'aplatissement, indépendantes des unités du graphique. Statistiques (unitaires) fait référence aux valeurs rapportées, telles que la moyenne et l'écart type, basées sur les unités du graphique.
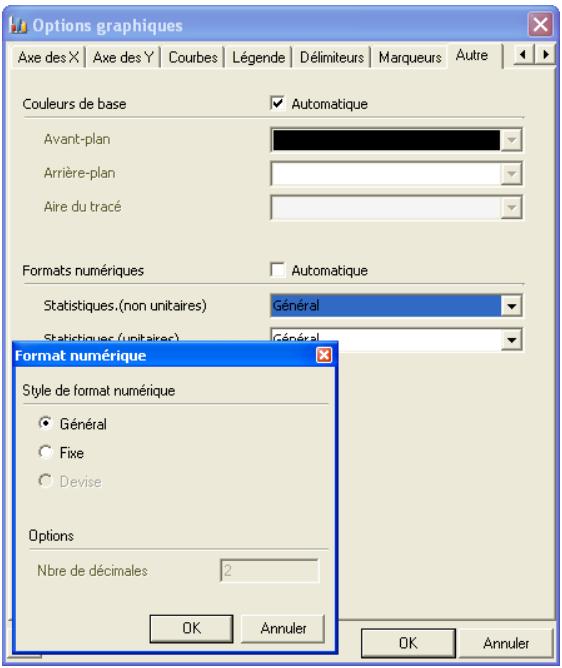
Clics de formatage graphique
Les graphiques peuvent souvent être formatés d'un simple clic sur l'élément approprié du graphique. Par exemple, pour changer le titre d'un graphique, il suffit de cliquer dessus et de taper le nouveau titre désiré.
Les éléments suivants peuvent être formatés de cette manière :
- Titres - Cliquez simplement sur le titre du graphique et tapez le nouveau texte désiré.
- Échelle X - Sélectionnez la ligne terminale de l'axe et déplacez-la pour redéfinir l'échelle du graphique.
- Suppression de superposition - Cliquez avec le bouton droit sur la légende couleur de la courbe à supprimer et choisissez Supprimer la courbe.
Le menu contextuel qui s'affiche en réponse à un clic droit opéré sur un graphique donne également directement accès aux éléments de formatage associés à l'emplacement du clic.
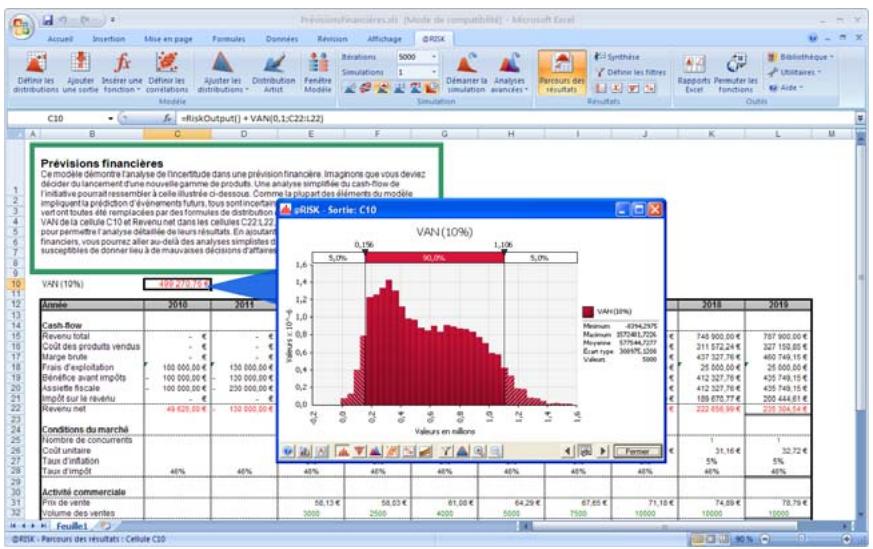
Référence : fonctions @RISK
@RISK propose des fonctions personnalisées admises dans les cellules et les formules d'Excel. Ces fonctions seront à :
1) Définir les distributions de probabilités (fonctions de distribution @RISK et fonctions de propriété des distributions). 2) Définir les sorties de simulation (fonction RiskOutput). 3) Renvoyer les résultats de simulation à la feuille de calcul (fonctions @RISK statistiques et graphiques).
Ce chapitre de référence est consacré à la description des différents types de fonction @RISK et des arguments obligatoires et facultatifs de chacune.
Fonctions de distribution
Les fonctions de distribution de probabilités seront à ajouter un facteur d'incertitude – sous la forme de distributions de probabilités – aux cellules et équations de vos feuilles de calcul Excel. Par exemple, la fonction RiskUniform(10;20), dans une cellule de feuille de calcul, spécifie que les valeurs de la cellule seront générées par une distribution uniforme à valeur minimum de 10 et valeur maximum de 20. Cette plage de valeurs remplace la simple valeur « fixe » requise par Excel.
@RISK utilise les fonctions de distribution au cours d'une simulation pour échantillonner les ensembles de valeurs possibles. Chaque iteration d'une simulation utilise un nouvel ensemble de valeurs échantillonnées dans chaque fonction de distribution de la feuille de calcul. Ces valeurs servent ensuite à recalculer la feuille de calcul et à générer un nouvel ensemble de résultats possibles.
Comme les fonctions Excel, les fonctions de distribution se composent de deux éléments : le nom de la fonction et, entre parenthèses, les valeurs d'argument. Une fonction de distribution typique est illustrée ci-dessous : Renvoie uniquement la version corrigée du passage, en respectant les règles. N'ajoute aucun mot qui ne soit pas déjà présent ou clairement tronqué.
RiskNormal(100;10)
Une fonction de distribution différente est utilisée pour chaque type de distribution de probabilités. Le type de distribution à échantillonner est indiqué par le nom de la fonction. Les paramètres spécifiques de la distribution sont indiqués par les arguments de la fonction.
Le nombre et le type d'arguments requis pour une fonction de distribution varient d'une fonction à l'autre. Dans l'exemple suivant :
un nombre fixe d'arguments doit être spécifique à chaque utilisation de la fonction. Dans d'autres fonctions (DISCRETE, par exemple), le nombre d'arguments varie suivant la situation considérée. Une fonction DISCRETE peut par exemple spécifier deux ou trois issues, ou même davantage, suivant les besoins.
Comme pour les fonctions Excel, les arguments des fonctions de distribution peuvent être des références de cellule ou des expressions. Par exemple:
Dans ce cas, la valeur de la cellule serait spécifiée par une distribution triangulaire à valeur minimum prélevée dans la cellule B1, valeur la plus probable calculée sur la base de la valeur de la cellule B2 multipliée par 1,5 et valeur maximum prélevée dans la cellule B3.
Les fonctions de distribution sont aussi admises dans les formules de cellule, comme les fonctions Excel. Par exemple :
Toutes les commandes d'édition Excel standard sont disponibles à l'entrée des fonctions de distribution. @RISK doit cependant être chargé pour permettre l'échantillonnage des fonctions de distribution par Excel.
Pour entrer des fonctions de distribution de probabilités :
- Examinez votre feuille de calcul et identifiez les cellules qui vous paraissent contenir des valeurs incertaines.
Recherchez les cellules dont les valeurs réelles sont susceptibles de varier par rapport à celles indiquées dans la feuille de calcul. Commencez par identifier les variables importantes, dont les valeurs de cellule sont susceptibles de partager la plus grande variation. Avec l'expérience, vous pourrez étendre de davantage vos recours aux fonctions de distribution.
- Sélectionnez les fonctions de distribution à appliquer aux cellules identifiées. Dans Excel, désélectionnez la commande
Fonction du menu Insertion pour entrer les fonctions sélectionnées dans les formules.
@RISK propose plus de 30 types de distributions. À moins que vous ne sachiez spécifiquement comment les valeurs incertaines sont distribuées, il vaut mieux commencer par les types de distribution les plus simples (uniforme, triangulaire ou normale). Si possible, spécifiez, comme point de départ, la valeur de la cellule courante comme valeur moyenne, ou la plus probable, de la fonction de distribution. La plage de la fonction utilisée peut ainsi refléter la variation possible autour de cette valeur moyenne ou la plus probable.
Les fonctions de distribution simples peuvent être très puissantes, car elles permettent de décrire l'incertitude avec quelques valeurs ou arguments seulement. Par exemple :
- RiskUniform(Minimum; Maximum) utilise seulement deux valeurs pour décrire la plage complète de la distribution et définir les probabilités de toutes les valeurs de cette plage.
- RiskTriang(Minimum; Valeur la plus probable; Maximum) utilise trois valeurs facilement identifiables pour décrire une distribution complète.
Avec l'augmentation du degré de complexité de vos modèles, vous aurez probablement besoin de types de distribution plus complexes pour répondre aux besoins propres de vos modèles. Référez-vous à la liste représentée plus loin dans cette section pour vous guider dans la sélection et la comparaison des différents types de distribution.
Définition graphique des distributions
Un graphique de la distribution est souvent utile à la sélection et spécification des fonctions de distribution. La fenêtre @RISK Définir une distribution permet d'afficher des graphiques de distribution et d'ajouter des fonctions de distribution aux formules des cellules. Pour y accéder, sélectionnez la cellule dans laquelle vous désirez ajouter une fonction de distribution et cliquez sur l'icône Définir une distribution ou choisissez la commande Modèle - Définir une distribution dans le menu du compagnon @RISK. Le fichier en ligne présente aussi des illustrations graphiques de différentes fonctions aux valeurs d'argument sélectionnées. Pour plus de détails sur la fenêtre Définir une distribution, voir les commandes Modèle : Définir une distribution dans la section Commandes @RISK de ce manuel.
Il est souvent utile de recourir, dans une première fois, à la fenêtre Définir une distribution pour la définition des fonctions. Elle permet en effet de comprendre comment affecter les valeurs
Ajustement des données aux distributions
appropriées aux arguments. Lorsque vous maîtriserez la syntaxe de ces arguments, vous pourrez les définir directement dans Excel, sans passer par la fenêtre de définition.
@RISK (versions Professional et Industrial uniquement) permet l'ajustement de distributions de probabilités à vos données existantes. Les distributions réalisantes sont ensuite disponibles comme distributions en entrée et peuvent être ajoutées à votre modèle de calcul. Pour plus de détails sur l'ajustement des distributions, voir la section de ce manuel consacrée à la commande Ajuster les distributions aux données.
Fonctions de propriété des distributions
Les arguments facultatifs des fonctions de distribution peuvent être définis à l'aide des fonctions de propriété de distribution. Ces arguments facultatifs permettent de nommer une distribution en entrée pour les rapports et les graphiques, de tronquer l'échantillonnage d'une distribution, de corréler cet échantillonnage avec d'autres distributions et d'empêcher l'échantillonnage d'une distribution lors d'une simulation. Ces arguments ne sont pas obligatoires. Ils peuvent être ajoutés selon les besoins rencontrés.
Les arguments facultatifs spécifiés à l'aide des fonctions de propriété de distribution @RISK s'incorporent dans une fonction de distribution. Les fonctions de propriété se définissent de la même manière que les fonctions Excel standard. Elles peuvent inclure des références de cellule et des expressions mathématiques comme arguments.
Par exemple, la fonction ci-dessous tronque la distribution normale entre une plage limitée par la valeur minimum 0 et la valeur maximum 20 :
= RiskNormal (1 0; 5; RiskTruncate (0; 2 0))
Aucun échantillon ne sera prélevé en dehors de cette plage minimum-maximum.
Troncation dans les versions antérieures de @RISK
Les fonctions supplémentaires telles que RiskTNormal, RiskTEXpon et RiskTLognorm servaient, dans les versions @RISK antérieures à la version 4.0, à tronquer les distributions normales, exponentielles et normales logarithmiques. Ces fonctions de distribution sont toujours reconnues dans les versions plus récentes de @RISK. Leur fonctionnalité a toutefois été remplacée par la fonction de propriété de distribution RiskTruncate, plus souple et compatible avec toutes les distributions de probabilités. Les graphiques de ces anciennes fonctions ne s'affichent pas dans la fenêtre Définir une distribution. Ils apparaissent cependant dans la fenêtre Modèle et peuvent être utilisés dans les simulations.
Paramètres secondaires
Beaucoup de fonctions de distribution peuvent être définies en spécifiant les valeurs de centile de la distribution désirée. Il se peut par exemple, pour une distribution de forme normale dont le 10e centile serait égal à 20 et le 90e centile, égal à 50, que vous ne connaissiez que ces valeurs de centile et que la moyenne et l'écart type nécessaires à la définition d'une distribution normale traditionnelle vous soient inconnus.
Les paramètres secondaires peuvent être utilisés à la place des arguments standard de la distribution (ou en combinaison avec ces arguments standard). Lors de l'entrée des arguments de centiles, la forme Alt de la fonction de distribution est utilisée : RiskNormalAlt ou RiskGammaAlt, par exemple.
Chaque paramètre de fonction de distribution à paramètres secondaires exige une paire d'arguments, spécifique chacune :
1) le type de paramètre entré et 2) la valeur du paramètre.
Chaque argument de paire se définit directement dans la fonction Alt: RiskNormalAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2). Par exemple :
- RiskNormalAlt(5%; 67,10; 95%; 132,89) - spécifie une distribution normale dont le 5e centile aurait la valeur 67,10 et le 95e, la valeur 132,89.
Types de paramètres secondaires
Les paramètres secondaires se définissent sous forme de centiles ou d'arguments de distribution standard. Si l'argument d'un type de paramètre est défini entre guillemets ("mu", par exemple), le paramètre spécifique est l'argument de distribution standard du nom entré. Les centiles peuvent ainsi être combinés avec les arguments de distribution ordinaires. Par exemple :
- RiskNormalAlt("mu"; 100; 95%; 132,89) - spécifie une distribution normale avec une moyenne de 100 et dont le 95e centile aurait la valeur 132,89.
Les noms reconnus pour les arguments standard de chaque distribution sont indiqués dans le titre de chaque fonction de ce chapitre, dans l'Assistant Fonction d'Excel, catégorie Distrib @RISK (param. sec.), ou dans la fenêtre Définir une distribution.
Remarque : Vous pouvez spécifier vos paramètres secondaires sous l'option Paramètres d'une distribution particulière dans la fenêtre Définir une distribution. Si vos paramètres incluent un argument standard et que vous cliquez sur OK, @RISK entre le nom approprié de l'argument standard entre guillemets dans la fonction inscrite sur la barre de formule de la fenêtre Définir une distribution.
Paramètres d'emplacement ("loc")
Si un argument de type de paramètre est une valeur comprise entre 0 et 1 (ou 0% et 100%), le paramètre spécifique est le centile pour la distribution.
Lorsqu'elles sont assorties de paramètres secondaires, certaines distributions ont un paramètre supplémentaire d'emplacement. Ce paramètre est généralement disponible pour les distributions sans valeur d'emplacement spécifique dans leurs arguments standard. L'emplacement équivaut au minimum ou centile 0 de la distribution. Ainsi, aucune valeur d'emplacement n'est spécifique dans les arguments standard de la distribution Gamma : un paramètre d'emplacement est donc disponible. En revanche, la distribution normale comporte un paramètre d'emplacement parmi ses arguments standard : la moyenne ou mu. Elle ne dispose par conséquent pas d'un paramètre d'emplacement distinct dans sa définition sous paramètres secondaires. Le but de ce paramètre « supplémentaire » est de permettre la spécification de centiles pour les distributions décalées (par exemple, une distribution Gamma à trois paramètres, avec emplacement 10 et deux centiles).
Échantillonnage des distributions à paramètres secondaires
Lors d'une simulation, @RISK calcule la distribution appropriée dont les valeurs de centile correspondant à celles des paramètres secondaires entrés. Il échantillonne ensuite cette distribution. Comme pour toutes les fonctions @RISK et à l'image de toute fonction Excel, les arguments définis peuvent être des références à d'autres cellules ou formules, et les valeurs d'argument peuvent changer d'itération en itération lors d'une simulation.
Centiles cumulatifs décroissants
Les paramètres centiles secondaires des distributions de probabilités peuvent être spécifiés en tant que centiles cumulatifs décroissants aussi bien que cumulatifs croissants standard. À chaque forme de fonction de distribution de probabilités Alt (telle que RiskNormalAlt) correspond une forme AltD (telle que RiskNormalAltD). Si la forme AltD est utilisée, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée.
Si vous sélectionnez l'option Centiles décroissants de la commande Paramètres d'application sous le menu Utilitaires, tous vos rapports @RISK présenteront des valeurs de centiles cumulatifs décroissants. De plus, si vous sélectionnez l'option Paramètres secondaires dans la fenêtre Définir une distribution pour entrer vos distributions sous paramètres secondaires, les centiles cumulatifs décroissants s'afficheront automatiquement et les formes de fonctions de distribution de probabilités AltD seront entées.
Outre les centiles cumulatifs décroissants pour les distributions à paramètres secondaires, la distribution cumulative @RISK (RiskCumul) peut également être spécifiée au moyen de centiles cumulatifs décroissants, sous la forme RiskCumulD.
Entrée d'arguments dans les fonctions @RISK
Les directives d'entrée des fonctions Excel présentées dans le Guide de l'utilisateur pertinent s'appliquent aussi à l'entrée des fonctions @RISK. Il en existe toutefois d'autres propres aux fonctions @RISK :
- Si un argument entier est requis pour une fonction de distribution, les valeurs non entières sont tronquées et soumises comme valeurs entières.
- Pour les fonctions de distribution compteant un nombre variable d'arguments (HISTOGRM, DISCRETE et CUMUL), les arguments du même type doivent être entrés sous forme de matrices. Les matrices Excel sont dénotées soit en mettant les valeurs de la matrice entre accolades {}, soit par référence à une plage de cellules contiguës (A1: C1, par exemple). Pour les fonctions assorties d'un nombre variable de paires de valeur et probabilité, les valeurs et les probabilités forment chacune une matrice distincte. À la première valeur de la matrice de valeurs correspond la première probabilité de la matrice de probabilités, et ainsi de suite.
Dates dans les fonctions @RISK
@RISK gère l'entrée de dates dans les fonctions de distribution, ainsi que l'affichage de graphiques et statistiques au format date. La fonction de propriété RiskIsDate(VRAI) commande l'affichage des graphiques et statistiques @RISK au format date. @RISK affiche aussi des dates dans le volet des arguments de la fenêtre Définir une distribution lorsque le formatage de date est activé. Vous pouvez spécifier le format date pour une distribution en sélectionnant Formatage de date dans la fenêtre Paramètres du volet des arguments de distribution, ou en l'activant dans la boîte de dialogue Propriétés d'entrée. Dans les deux cas, une fonction de propriété RiskIsDate s'introduit dans la distribution.
Les arguments de date des fonctions de distribution @RISK se définissent généralement par référence aux cellules qui contiennent les dates désirées. Par exemple : =RiskTriang(A1; B1; C1; RiskIsDate(VRAI))
pourrait faire référence au 1/10/2009 dans la cellule A1, 1/1/2010 dans la cellule B1 et 10/10/2010 dans la cellule C1.
Les arguments de date entrés directement dans les fonctions de distribution @RISK doivent l’être au moyen d’une fonction Excel de conversion de date en valeur. Plusieurs fonctions Excel permettent cette conversion. Par exemple, la fonction d’une distribution triangulaire à valeur minimum de 1/10/2009, valeur probable de 1/1/2010 et valeur maximum de 10/10/2010 s’exprimerait comme suit :
=RiskTriang(VALEURDATE("1/10/2009"); VALEURDATE("1/1/2010"); VALEURDATE("10/10/2010"); RiskIsDate(VRAI))
Ici, la fonction Excel VALEURDATE sert à convertir les dates entrées en valeurs. La fonction =RiskTriang(DATE(2009;10;4)+HEURE(2;27;13); DATE(2009;12;29)+HEURE(2;25;4); DATE(2010;10;10)+HEURE(11;46;30); RiskIsDate(VRAI))
fait appel aux fonctions Excel DATE et HEURE pour convertir les dates et les heures entrées en valeurs. L'avantage de cette approche est que les dates et les heures entrées se convertiront ajustement si le classeur est déplacé vers un système à format jj/mm/aa différent. Tous les arguments de toutes les fonctions ne peuvent pas être spécifiés de manière logique par des dates. Par exemple, les fonctions telles que RiskNormal(moyenne; ec_type) gèrent une moyenne entrée sous forme de date mais pas l'ecart type. Le volet des arguments de la fenêtre Définir une distribution indique le type de données (dates ou numériques) ADMIS pour chaque type de distribution lorsque le formatage de date est activé.
Arguments facultatifs
Certaines fonctions @RISK peuvent être assorties d'arguments facultatifs. Les arguments de la fonction RiskOutput, par exemple, sont tous facultatifs. Cette fonction admet 0, 1 ou 3 arguments, suivant les informations à inclure concernant la cellule de sortie correspondante. Vous pouvez :
1) simplement identifier la cellule en tant que sortie et laisser @RISK la nommer automatiquement (=RiskOutput()); 2) donner à la sortie le nom de votre choix (=RiskOutput("Profit 1999"));
3) donner à la sortie le nom de votre choix et la localiser dans une plage de sortie (=RiskOutput("Profit 1999";"Profit annuel";1)).
Ces trois formes de la fonction RiskOutput sont admises, car tous ses arguments sont facultatifs.
Pour les fonctions @RISK dont les arguments sont facultatifs, vous pouvez ajouter ceux qui vous intéressent et omettre les autres. Vous devez toutefois inclure tous les arguments obligatoires. Par exemple, pour la fonction RiskNormal, deux arguments (moyenne et écart type) sont obligatoires. Tous ceux susceptibles d'être ajoutés à RiskNormal par l'intermédiaire de fonctions de propriété de distribution sont facultatifs et peuvent être entrés dans n'importe quel ordre.
Remarque importante sur les matrices excel
Dans Excel, vous ne pouvez pas lister de références et noms de cellules dans les matrices de la même manière que les constantes. Vous ne pouvez, par exemple, pas utiliser {A1: B1: C1} pour représenter la matrice contenant les valeurs des cellules A1, B1 et C1. Vous devez utiliser à la place la référence de plage de cellules A1: C1 ou bien entrer les valeurs des cellules directement dans les matrices en tant que constantes - par exemple, {10;20;30}.
- Les fonctions de distribution requérant un nombre d'arguments fixe renvoient une valeur d'erreur si les arguments entrés sont insuffisants et omettent l'excess d'arguments s'ils sont trop différents.
- Les fonctions de distribution renvoient une valeur d'erreur si les arguments ne sont pas introduits au format attendu (nombre, matrice ou texte).
Informations complémentaires
Cette section décrit brièvement chaque fonction de distribution de probabilités disponible et les arguments requis pour chacune. Le fichier d'aide en ligne décrit en outre les caractéristiques techniques de chaque fonction. Les annexes comprennent les formules de densité, distribution, moyenne, mode, paramètres de distribution et graphiques des distributions de probabilités générées à l'aide de valeurs d'arguments typiques.
Fonctions de sortie de simulation
Les cellules de sortie se définissent à l'aide des fonctions RiskOutput. Ces fonctions permettent de copier, coller et déplacer les cellules de sortie en toute simplicité. Elles s'ajoutent automatiquement à la feuille de calcul sur invocation de l'icône @RISK Ajouter une sortie. Elles permettent facultativement de nommer les sorties de simulation et d'ajouter des cellules de sortie aux plages de sortie. Par exemple :
= RiskOutput("Profit") + VAN(0, 1; H1:H10)
Avant d'être sélectionnée comme sortie de simulation, la cellule contenait simplement la formule
= VAN (0, 1; H 1: H 1 0)
La fonction RiskOutput ajoutée fait de la cellule une sortie de simulation intitulée « Profit ».
Fonctions statistiques de simulation
Les fonctions statistiques @RISK renvoient les statistiques désirées sur les résultats de la simulation ou une distribution en entrée. Par exemple, la fonction RiskMean(A10) renvoie la moyenne de la distribution simulée pour la cellule A10. Ces fonctions s'actualisent en temps réel, en cours d'exécution de la simulation.
Les fonctions statistiques @RISK incluent toutes les statistiques standard plus les centiles et les cibles. (Par exemple, =RiskPercentile(A10;0,99) renvoie le 99e centile de la distribution simulée.) Elles s'utilisent de la même manière que les fonctions Excel ordinaires.
Statistiques d'une distribution en entrée
Les fonctions statistiques @RISK qui renvoient une statistique désirée sur une distribution en entrée de simulation incluent l'identificateur Theo dans leur nom. Par exemple, la fonction RiskTheoMean(A10) renvoie la moyenne de la distribution de probabilités de la cellule A10. En présence de plusieurs fonctions de distribution dans la formule d'une cellule référencée dans une fonction statistique RiskTheo, @RISK renvoie la statistique désirée relative à la dernière fonction calculée de la formule. Par exemple, pour la formule de la cellule A10
= RiskNormal (1 0; 1) + RiskTriang (1; 2; 3)
la fonction RiskTheoMean(A10) renvoie la moyenne de RiskTriang(1;2;3). Pour cette autre formule A10,
= RiskNormal (1 0; RiskTriang (1; 2; 3))
La fonction RiskTheoMean(A10) renverrait la moyenne de RiskNormal(10; RiskTriang(1;2;3)), étant donné que la fonction RiskTriang(1;2;3) est imbriquée dans la fonction RiskNormal.
Calculs statistiques sur un sous-ensemble de distribution
Les fonctions statistiques @RISK peuvent inclure une fonction de propriété RiskTruncate ou RiskTruncateP. Le calcul de la statistique se limite alors à la plage min-max spécifique par les limites de troncation. Remarque : Les valeurs renvoyées par les fonctions statistiques @RISK ne reflètent que la plage définie au moyen d'une fonction de propriété RiskTruncate ou RiskTruncateP introduite dans la fonction statistique elle-même. Les filtres configurés pour les résultats de simulation et représentés dans les graphiques et les rapports @RISK n'affectent pas les valeurs renvoyées par les fonctions statistiques @RISK.
Statistiques dans les masques de rapport
Les fonctions statistiques peuvent aussi faire référence à une sortie de simulation ou à une entrée nommée. Vous pouvez par conséquent les inclure dans les masques de rapport préformatés Excel de vos résultats de simulation. Par exemple, la fonction = RiskMean("Profit") renverrait la moyenne de la distribution simulée pour la cellule de sortie Profit définie dans un modèle.
Remarque: Une référence de cellule introduite dans une fonction statistique ne doit pas nécessairement être une sortie de simulation identifiée par une fonction RiskOutput.
Fonction graphique
La fonction @RISK spéciale RiskResultsGraph insère automatiquement une représentation graphique des résultats de la simulation à l'endroit de son inclusion dans la feuille de calcul. Ainsi,
= RiskResultsGraph(A10) introduisait une représentation graphique de la distribution simulée pour la cellule A10, directement dans le tableau, à l'emplacement de la fonction en fin de simulation. Les arguments facultatifs de RiskResultsGraph régissant le type de graphique à créer, son format, son échelle et d'autres options encore.
Fonctions supplémentaires
D'autres fonctions encore - CurrentIter, CurrentSim et StopSimulation - peuvent servir au développement d'applications à base de macros tirant parti de @RISK. Les deux premières renvoient, respectivement, l'itération et la simulation courantes d'une simulation en cours d'exécution. La troisième interrompt une simulation.
Tableau des fonctions disponibles
Le tableau ci-dessous répertorie les fonctions personnalisées que @RISK ajoute à Excel.
| Fonction de distribution | Description |
| RiskBeta(alpha1; alpha2) | Distribution bêta avec paramètres de forme alpha1 et alpha2. |
| RiskBetaGeneral(alpha1; alpha2; minimum; maximum) | Distribution bêta avec valeurs minimum, maximum et paramètres de forme alpha1 et alpha2 définis. |
| RiskBetaGeneralAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3; type_arg4; valeur_arg4) | Distribution bêta à quatre paramètres nommés, type_arg1 à type_arg4, représentant soit un centile de 0 à 1, soit "alpha1", "alpha2", "min" ou "max". |
| RiskBetaSubj(minimum; valeur la plus probable; moyenne; maximum) | Distribution bêta avec valeurs minimum, maximum, la plus probable et moyenne définies. |
| RiskBinomial(n; p) | Distribution binomiale avec n tirages et p probabilités de réussite à chaque tirage. |
| RiskChiSq(v) | Distribution chi carré à v degrés de liberté. |
| RiskCompound(dist1 ou valeur ou ref_cell; dist2; franchise; limite) | Somme d'un nombre d'échantillons de dist2 où le nombre d'échantillons prélevés dans dist2 est donné par la valeur échantillonnée dans dist1 ou par la valeur. Facultativement, la valeur franchise est soustraite de chaque échantillon dist2 et si (échantillon dist2-franchise) excède la limite, l'échantillon dist2 est réglé sur égal à limite. |
| RiskCumul(minimum; maximum; {X1; X2; ..., Xn}; {p1; p2; ..., pn}) | Distribution cumulative avec n points entre les valeurs minimum et maximum et probabilité cumulative croissant p à chaque point. |
| RiskCumulD(minimum; maximum; {X1; X2; ..., Xn}; {p1; p2; ..., pn}) | Distribution cumulative avec n points entre les valeurs minimum et maximum et probabilité cumulative décroissant p à chaque point. |
| RiskDiscrete({X1; X2; ..., Xn}; {p1; p2; ..., pn}) | Distribution discrète à n issues possibles, avec valeur X et poids de probabilité p pour chaque issue. |
| RiskSimtable({X1; X2; ..., Xn}) | Distribution uniforme discrète avec n issues évaluées de X1 à Xn. |
| RiskErf(h) | Distribution de fonction d'erreur avec paramètre de variance h. |
| RiskErlang(m; bêta) | Distribution M-Erlang avec paramètre de forme entier m et paramètre de forme bêta. |
| RiskExpon(bêta) | Distribution exponentielle avec constante de décroissance bêta. |
| RiskExponAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2) | Distribution exponentielle à deux paramètres nommés, type_arg1 et type_arg2, représentant soit un centile de 0 à 1, soit “beta” ou “loc”. |
| RiskExtvalue(alpha; bêta) | Distribution de valeurs extrêmes (ou Gumbel) avec paramètre d'emplacement alpha et paramètre d'échelle bêta. |
| RiskExtvalueAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2) | Distribution de valeurs extrêmes (ou Gumbel) à deux paramètres nommés, type_arg1 et type_arg2, représentant soit un centile de 0 à 1, soit “alpha” ou “beta”. |
| RiskGamma(alpha; bêta) | Distribution gamma avec paramètre de forme alpha et paramètre d'échelle bêta. |
| RiskGammaAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3) | Distribution gamma à trois paramètres nommés, type_arg1, type_arg2 et type_arg3, représentant soit un centile de 0 à 1, soit “alpha”, “beta” ou “loc”. |
| RiskGeneral(minimum; maximum; {X1; X2; ...; Xn}; {p1; p2; ...; pn}) | Fonction de densité générale pour une distribution de probabilités s'échéonnant entre un minimum et un maximum, avec n paires (x,p) et valeur X et poids de probabilité p pour chaque point. |
| RiskGeometric(p) | Distribution géométrique avec probabilité p. |
| RiskHistogramm(minimum; maximum; {p1; p2; ...; pn}) | Distribution d Histogramme avec n classes entre le minimum et le maximum et poids de probabilité p pour chaque classe. |
| RiskHypergeo(n; D; M) | Distribution hypergéométrique avec taille d'échantillon n, nombre d'éléments D et effectif de population M. |
| RiskIntUniform(minimum; maximum) | Distribution uniforme renvoyant des valeurs entières seulement entre minimum et maximum. |
| RiskInvGauss(mu; lambda) | Distribution de Gauss inverse (ou de Wald) avec moyenne mu et paramètre de forme lambda. |
| RiskInvGaussAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3) | Distribution de Gauss inverse (ou Wald) à trois paramètres nommés, type_arg1, type_arg2 et type_arg3, représentant soit un centile de 0 à 1, soit “mu”, “lambda” ou “loc”. |
| RiskJohnsonSB(alpha1; alpha2; a; b) | Distribution SB (« system bounded ») de Johnson à valeurs entrées alpha1, alpha2, a et b. |
| RiskJohnsonSU(alpha1; alpha2; gamma; bêta) | Distribution SU (« system unbounded ») de Johnson à valeurs entrées alpha1, alpha2, gamma et bêta. |
| RiskJohnsonMoments(moyenne; écart_type; asymétrie; aplatissement) | Distribution du groupe Johnson (normale, normale logarithmique, JohnsonSB et JohnsonSU) avec, pour moments, les paramètres moyenne, écart_type, asymétrie et aplatissement entrés. |
| RiskLoglogisticAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3) | Distribution logistique logarithmicque à trois paramètres nommés, type_arg1, type_arg2 et type_arg3, représentant soit un centile de 0 à 1, soit “gamma”, “beta” ou “alpha”. |
| RiskLognorm(moyenne; écart type) | Distribution normale logarithmicque avec moyenne et écart type spécifiés. |
| RiskLognormAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3) | Distribution normale logarithmicque à trois paramètres nommés, type_arg1, type_arg2 et type_arg3, représentant soit un centile de 0 à 1, soit “mu”, “sigma” ou “loc”. |
| RiskLognorm2(moyenne; écart type) | Distribution normale logarithmicque généraè à partir du « logarithme » d'une distribution normale avec moyenne et écart type spécifiés. |
| RiskMakelInput(formule) | Spécifie que la valeur calculée de formule doit être traitée comme une entrée de simulation, au même titre qu'une fonction de distribution. |
| RiskNegbin(s; p) | Distribution binomiale négative avec s succès et probabilité de succès p à chaque essai. |
| RiskNormal(moyenne; écart type) | Distribution normale avec moyenne et écart type disponibles. |
| RiskNormalAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2) | Distribution normale à deux paramètres nominés, type_arg1 et type_arg2, représentant soit un centile de 0 à 1, soit “mu” ou “sigma”. |
| RiskPareto(thèta; alpha) | Distribution de Pareto. |
| RiskParetoAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2) | Distribution de Pareto à deux paramètres nominés, type_arg1 et type_arg2, représentant soit un centile de 0 à 1, soit “theta” ou “alpha”. |
| RiskPareto2(b; q) | Distribution de Pareto. |
| RiskPareto2Alt(type_arg1; valeur_arg1; type_arg2; valeur_arg2) | Distribution de Pareto à deux paramètres nommés, type_arg1 et type_arg2, représentant soit un centile de 0 à 1, soit “b” ou “q”. |
| RiskPearson5(alpha; bêta) | Distribution de Pearson du type V (ou gamma inverse) avec paramètre de forme alpha et paramètre d'échelle bêta. |
| RiskPearson5Alt(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3) | Distribution de Pearson du type V (ou gamma inverse) à trois paramètres nommés, type_arg1, type_arg2 et type_arg3, représentant soit un centile de 0 à 1, soit “alpha”, “beta” ou “loc”. |
| RiskPearson6(bêta; alpha1; alpha2) | Distribution de Pearson du type VI avec paramètre d'échelle bêta et paramètres de forme alpha1 et alpha2. |
| RiskPert(minimum; valeur la plus probable; maximum) | Distribution de Pert avec valeurs minimum, la plus probable et maximum spécifiées. |
| RiskPertAl(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3) | Distribution de Pert à trois paramètres nommés, type_arg1, type_arg2 et type_arg3, représentant soit un centile de 0 à 1, soit “min”, “max” ou “m.likely”. |
| RiskPoisson( lambda) | Distribution de Poisson. |
| RiskRayleigh(bêta) | Distribution de Rayleigh avec paramètre d'échelle bêta. |
| RiskRayleighAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2) | Distribution de Rayleigh à deux paramètres nommés, type_arg1 et type_arg2, représentant soit un centile de 0 à 1, soit “beta” ou “loc”. |
| RiskResample(Méthode échant; {X1; X2; ...Xn}) | Échantillonne selon Méthode échant dans un ensemble de données à n issues possibles et probabilité égale de réalisation de chacune. |
| RiskSimtable({X1; X2; ...Xn}) | Liste les valeurs à utiliser dans chacune d'une série de simulations. |
| RiskSplice(dist1 ou ref_cell; dist2 ou ref_cell; point de jonation) | Spécifie une distribution créée par jonation de dist1 et dist2 à la valeur x donnée par le point de jonation. |
| RiskStudent(nu) | Distribution de Student avec degrès de liberté nu. |
| RiskTriang(minimum; valeur la plus probable; maximum) | Distribution triangulaire avec valeurs minimum, la plus probable et maximum définies. |
| RiskTriangAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3) | Distribution triangulaire à trois paramètres nommés, type_arg1, type_arg2 et type_arg3, représentant soit un centile de 0 à 1, soit “min”, “max” ou “m.likely”. |
| RiskTrigenInf.; la plus probable; sup.; cent.inf.; cent.sup.) | Distribution triangulaire à trois points représentant la valeur au centile inférieur, la plus probable et la valeur au centile supérieur. |
| RiskUniform(minimum; maximum) | Distribution uniforme entre les valeurs minimum et maximum. |
| RiskUniformAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2) | Distribution uniforme à deux paramètres nommés, type_arg1 et type_arg2, représentant soit un centile de 0 à 1, soit “min” ou “max”. |
| RiskWeibull(alpha; bêta) | Distribution de Weibull avec paramètre de forme alpha et paramètre d'échelle bêta. |
| RiskWeibullAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3) | Distribution de Weibull à trois paramètres nommés, type_arg1, type_arg2 et type_arg3, représentant soit un centile de 0 à 1, soit “alpha”, “beta” ou “loc”. |
| Fonctions de propriété de distribution | Description |
| RiskCategory(Nom catégorie) | Désigne la catégorie à utiliser à l'affichage d'une distribution en entrée. |
| RiskCollect() | Entraîne la collecte d'échantillons, en cours de simulation, pour la distribution dans laquelle la fonction est incluse ( quand les paramètres de simulation spécifique la collecte d'échantillons pour les distributions marquées de la propriétéés Collect seulement). |
| RiskConvergence(tolerance; Type_tolerance; Niveau_confiance; utiliserMoyenne; utiliserÉcart_type; utiliserCentile; centile) | Spécifie les paramètres de surveillance de convergence d'une sortie. |
| RiskCorrmat( plaque matrice; position; instance) | Identifie une matrice de coefficients de corrélation de ranges et une position dans la matrice pour la distribution dans laquelle la fonction est incluse. instance spécifique l'instance de la matrice à la plage de cellules de la matrice à utiliser pour la corrélation de cette distribution. |
| RiskDepC(ID; coefficient) | Identifie une variable dépendante dans une paire d'échantillonnage corrélée avec coefficient de corrélation de rang et chaîne d'identification ID. |
| RiskFit(IDProj; IDAjust; résultat d'ajustement sélectionné) | Lie un ensemble de données identifié par IDProj et IDAjust et ses résultats d'ajustement à la distribution en entrée qui peut ainsi être actualisée en cas de changement affectant les données. |
| RiskIndepC(ID) | Identifie une distribution indépendante dans une paire d'échantillonnage corrélée par rang — ID représentée la chaîne d'identification. |
| RisksDate(VRAI) | Spécifie que les valeurs de l'entrée ou de la sortie doivent être affichées en tant que valeurs de date dans les graphiques et les rapports. |
| RisksDiscrete(VRAI) | Spécifie qu'une sortie doit être traitée comme une distribution discrète lors de l'affichage des graphiques de résultats de simulation et le calcul des statistiques. |
| RiskLibrary(position; ID) | Spécifie qu'une distribution est liée à une distribution de la Bibliothèque @RISK à la position et sous l'ID individuels. |
| RiskLock() | Bloque l'échantillonnage de la distribution dans laquelle la fonction de verrouillage Lock est incluse. |
| RiskName(nom d'entrée) | Nom d'entrée de la distribution dans laquelle la fonction de désignation Name est incluse. |
| RiskSeed(type de générateur de nombres aléatoires; racine) | Spécifie qu'une entrée utilisera son propre générateur de nombres aléatoires, du type indiqué, à partir de la valeur racine indiquée. |
| RiskShift(décalage) | Décale de la valeur décalage le domaine de la distribution dans laquelle la fonction de décalage Shift est incluse. |
| RiskSixSigma(LSI; LSS; cible; Décal. long terme; Nombre d'écarts types) | Spécifie la limite de specifications inférieure, la limite de specifications supérieure, la valeur cible, le décalage à long terme et le nombre d'écarts types à considérer dans les calculs six sigma d'une sortie. |
| RiskStatic(valeur statique) | Définit la valeur statique 1) renvoyée par la fonction de distribution lors d'un recalcul Excel standard et 2) qui remplace la fonction @RISK désactivée par permutation. |
| RiskTruncate(minimum; maximum) | Plage minimum-maximum admise pour les échantillons tirés de la distribution dans laquelle la fonction Truncate est incluse. |
| RiskTruncateP(centile minimum; centile maximum) | Plage minimum-maximum admise (définie en centiles) pour les échantillons tirés de la distribution dans laquelle la fonction TruncateP est incluse. |
| RiskUnits(unités) | Nom des unités à utiliser dans l'étiquetage d'une distribution en entrée ou d'une sortie. |
| Fonction de sortie | Description |
| RiskOutput(nom; nom de plage de sortie; position dans la plage) | Cellule de sortie de simulation avec nom, nom de plage de sortie à laquelle la sortie apparait et position dans la plage. (Remarque : Tous les arguments de cette fonction sont facultatifs.) |
| Fonctions statistiques | Description |
| RiskConvergenceLevel(réf_cell ou nom sortie; n° sim) | Renvoie le niveau de convergence (0 à 100) d'une sortie au n° sim. La convergence renvoie VRAI. |
| RiskCorrel(réf_cell1 ou nom de sortie/entree1; réf_cell2 ou nom de sortie/entree2; type_corrélation; n° sim) | Renvoie le coefficient de correlation selon type_corrélation pour les données des distributions simulées de réf_cell1 ou nom de sortie/entree1 et réf_cell2 ou nom de sortie/entree2 à la simulation n° sim.Type_corrélation est soit Pearson, soit Ranges de Spearman. |
| RiskKurtosis(réf_cell ou nom sortie/entree; n° sim) | Aplâtissement de la distribution simulée pour réf_cell ou nom sortie/entree, à la simulation n° sim. |
| RiskMax(réf_cell ou nom sortie/entree; n° sim) | Valeur maximum de la distribution simulée pour réf_cell ou nom sortie/entree, à la simulation n° sim. |
| RiskMean(réf_cell ou nomsortie/entree; n° sim) | Moyenne de la distribution simulée pour réf_cell ou nom sortie/entree, à la simulation n° sim. |
| RiskMin(réf_cell ou nomsortie/entree; n° sim) | Valeur minimum de la distribution simulée pour réf_cell ou nom sortie/entree, à la simulation n° sim. |
| RiskMode(réf_cell ou nomsortie/entree; n° sim) | Mode de la distribution simulée pour réf_cell ou nom sortie/entree, à la simulation n° sim. |
| RiskPercentile(réf_cell ou nomsortie/entree; centile; n° sim) | Centile de la distribution simulée pour réf_cell ou nom sortie/entree, à la simulation n° sim. |
| RiskPtoX(réf_cell ou nomsortie/entree; centile; n° sim) | |
| RiskPercentileD(réf_cell ou nomsortie/entree; centile; n° sim) | Centile de la distribution simulée pour réf_cell ou nom sortie/entree, à la simulation n° sim (centile est un centile cumulatif décroissant). |
| RiskQtoX(réf_cell ou nomsortie/entree; centile; n° sim) | |
| RiskRange(réf_cell ou nomsortie/entree; n° sim) | Plage de la distribution simulée pour réf_cell ou nom sortie/entree, à la simulation n° sim. |
| RiskSensitivity(réf_cell ou nomsortie/entree; n° sim; rang; Type analyse; Type valeur renvoi) | Renvoise l'information relative à l'analyse de sensibilité de la distribution simulée pour réf_cell ou nom de sortie/entree. |
| RiskSkewness(réf_cell ou nomsortie/entree; n° sim) | Asymétrie de la distribution simulée pour réf_cell ou nom sortie/entree, à la simulation n° sim. |
| RiskStdDev(réf_cell ou nomsortie/entree; n° sim) | Écart type de la distribution simulée pour la référence de cellule réf_cell ou le nom sortie/entree, à la simulation n° sim. |
| RiskTarget(₹f_cell ou nom sortie/entree; valeur cible; n° sim) RiskXtoP(₹f_cell ou nom sortie/entree; valeur cible; n° sim) | Probabilitécumulative croissant de valeur cible dans la distribution simulée pour ₹f_cell ou nom sortie/entree à la simulation n° sim. |
| RiskTargetD(₹f_cell ou nom sortie/entree; valeur cible; n° sim) RiskXtoQ(₹f_cell ou nom sortie/entree; valeur cible; n° sim) | Probabilitécumulative décroissant de valeur cible dans la distribution simulée pour ₹f_cell ou nom sortie/entree à la simulation n° sim. |
| RiskVariance(₹f_cell ou nom sortie/entree; n° sim) | Variance de la distribution simulée pour ₹f_cell ou nom sortie/entree, à la simulation n° sim. |
| RiskTheoKurtosis(₹f_cell ou fonction de distribution) | Aplâtissement de la distribution pour ₹fCel ou fonction de distribution. |
| RiskTheoMax(₹f_cell ou fonction de distribution) | Valeur maximum de la distribution pour ₹fCel ou fonction de distribution. |
| RiskTheoMean(₹f_cell ou fonction de distribution) | Moyenne de la distribution pour ₹fCel ou fonction de distribution. |
| RiskTheoMin(₹f_cell ou fonction de distribution) | Valeur minimum de la distribution pour ₹fCel ou fonction de distribution. |
| RiskTheoMode(₹f_cell ou fonction de distribution) | Mode de la distribution pour ₹fCel ou fonction de distribution. |
| RiskTheoPtoX(₹f_cell ou fonction de distribution; centile) | Centile de la distribution pour ₹fCel ou fonction de distribution. |
| RiskTheoPtoXD(₹f_cell ou fonction de distribution; centile) | Centile de la distribution pour ₹f_cell ou fonction de distribution (centile est un centile cumulatif décroissant). |
| RiskTheoRange(₹f_cell ou fonction de distribution) | Plage de la distribution pour ₹fCel ou fonction de distribution. |
| RiskTheoSkewness(₹f_cell ou fonction de distribution) | Asymétrie de la distribution pour ₹fCel ou fonction de distribution. |
| RiskTheoStdDev(₹f_cell ou fonction de distribution) | Écart type de la distribution pour ₹fCel ou fonction de distribution. |
| RiskTheoXtoP(₹f_cell ou fonction de distribution; valeur cible) | Probabilitécumulative croissant de valeur cible dans la distribution la distribution pour ₹fCel ou fonction de distribution. |
| RiskTheoXtoQ(₹f_cell ou fonction de distribution; valeur cible) | Probabilitécumulative décroissant de valeur cible dans la distribution pour ₹fCel ou fonction de distribution. |
| RiskTheoVariance(₹f_cell ou fonction de distribution) | Variance de la distribution pour ₹f cel ou fonction de distribution. |
| Fonctions statistiques Six Sigma | Description |
| RiskCp(rik_cell ou nom de sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) | Calculé la capacité de processus pourrik_cell ou nom de sortie à la simulation n°sim, en fonction, facultativement, des LSI et LSS de la fonction de propriétéRiskSixSigma incluse. |
| RiskCPM(rik_cell ou nom de sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) | Calculé l'indice de capacité Taguchi pourrik_cell ou nom de sortie à la simulation n°sim, en fonction, facultativement, des LSI, LSS et Décalage long terme de la fonction de propriété RiskSixSigma incluse. |
| RiskCpk(rik_cell ou nom de sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) | Calculé l'indice de capacité de processusrik_cell ou nom de sortie à la simulation n°sim, en fonction, facultativement, des LSI et LSS de la fonction de propriétéRiskSixSigma incluse. |
| RiskCpkLower(rik_cell ou nom de sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) | Calculé l'indice de capacité unilatéral en fonction de la limite de specificationsupérieure pourrik_cell ou nom de sortie à la simulation n° sim, en fonction, facultativement, de la LSI de la fonction de propriété RiskSixSigma. |
| RiskCpkUpper(rik_cell ou nom de sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) | Calculé l'indice de capacité unilatéral en fonction de la limite de specificationsupérieure pourrik_cell ou nom de sortie à la simulation n° sim, en fonction, facultativement, de la LSS de la fonction de propriété RiskSixSigma incluse. |
| RiskDPM(rik_cell ou nom de sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) | Calculé les parties par million défectueuses pourrik_cell ou nom de sortie à la simulation n° sim, en fonction, facultativement, des LSI et LSS de la fonction de propriétéRiskSixSigma incluse. |
| RiskK(rik_cell ou nom de sortie; n°sim; RiskSixSigma(LSI; LSS; Cible;Décalage long terme; Nombre d'écarts types)) | Cette fonction calculée une mesure de centre de processus pourrik_cell ou nom de sortie à la simulation n° sim, en fonction, facultativement, des LSI et LSS de la fonction de propriété RiskSixSigma incluse. |
| RiskLowerXBound(rik_cell ou nom de sortie; n°sim; RiskSixSigma(LSI; LSS; Cible;Décalage long terme; Nombre d'écarts types)) | Renvoie la valeur X inférieure d'un nombredonné d'écarts types par rapport à la moyenne pourrik_cell ou nom de sortie à la simulation n° sim, en fonction, facultativement, du nombre d'écarts types de la fonction de propriété RiskSixSigma incluse. |
| RiskPNC(réf_cell ou nom de sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) | Calculée la probabilité totale de défectuosité en dehors des limites de spécification inférieure et supérieure pour réf_cell ou nom de sortie à la simulation n° sim, en fonction, facultativement, des LSI, LSS et Décalage long terme de la fonction de propriété RiskSixSigma incluse. |
| RiskPNCLower(réf_cell ou nom de sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) | Calculée la probabilité de défectuosité en dehors de la limite de spécification inférieure pour réf_cell ou nom de sortie à la simulation n° sim, en fonction, facultativement, des LSI et Décalage long terme de la fonction de propriété RiskSixSigma incluse. |
| RiskPNCUpper(réf_cell ou nom de sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) | Calculée la probabilité de défectuosité en dehors de la limite de spécification supérieure pour réf_cell ou nom de sortie à la simulation n° sim, en fonction, facultativement, des LSS et Décalage long terme de la fonction de propriété RiskSixSigma incluse. |
| RiskPPMLower(réf_cell ou nom de sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) | Calculée le nombre de défauts en-deçà de la limite de spécification inférieure pour réf_cell ou nom de sortie à la simulation n° sim, en fonction, facultativement, des LSI et Décalage long terme de la fonction de propriété RiskSixSigma incluse. |
| RiskPPMLower(réf_cell ou nom de sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) | Calculée le nombre de défauts au-delà de la limite de spécification supérieure pour réf_cell ou nom de sortie à la simulation n° sim, en fonction, facultativement, des LSS et Décalage long terme de la fonction de propriété RiskSixSigma incluse. |
| RiskSigmaLevel(réf_cell ou nom de sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) | Calculée le niveau Sigma de processus pour cellule réf_cell ou nom de sortie à la simulation n° sim, en fonction, facultativement, des LSI, LSS et Décalage long terme de la fonction de propriété RiskSixSigma incluse. (Remarque: Cette fonction présume que la sortie est distribuée normalement et centrefee dans les limites de spécification.) |
| RiskUpperXBound(réf_cell ou nom de sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) | Renvoie la valeur X supérieure d'un nombre donné d'écarts types par rapport à la moyenne pour réf_cell ou nom de sortie à la simulation n° sim, en fonction, facultativement, du nombre d'écarts types de la fonction de propriété RiskSixSigma. |
| RiskYV(Longrightarrow cell ou nom de sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) | Calcule le produit ou le pourcentage du processus sans défauts pour réf_cell ou nom de sortie à la simulation n° sim, en fonction, facultativement, des LSI, LSS et Décalage long terme de la fonction de propriété de RiskSixSigma incluse. |
| RiskZlower(Longrightarrow cell ou nom de sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) | Calcule le nombre d'écarts types qui séparent la limite de specifications inférieure de la moyenne pour réf_cell ou nom de sortie à la simulation n° sim, en fonction, facultativement, de la LSI de la fonction de propriété de RiskSixSigma incluse. |
| RiskZMin(Longrightarrow cell ou nom de sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) | Calcule le minimum de Z-inf et Z-sup pour réf_cell ou nom de sortie à la simulation n° sim, en fonction, facultativement, des LSS et LSI de la fonction de propriété de RiskSixSigma incluse. |
| RiskCpkUpper(Longrightarrow cell ou nom de sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) | Calcule le nombre d'écarts types qui séparent la limite de specifications supérieure de la moyenne pour réf_cell ou nom de sortie à la simulation n° sim, en fonction, facultativement, de la LSS de la fonction de propriété de RiskSixSigma incluse. |
| Fonctions supplémentaires | Description |
| RiskCorrectCorrmat(plate_matrie_e_corrélation; plaque_matrie_pondérations_d'ajus tement) | Renvoie la matrice de corrélation corrigée pour la matrice située dans plateau_matrie_corrélation en fonction de la matrice des pondérations d'ajustement située dans plateau_matrie_pondérations_d'ajustement. |
| RiskCurrentIter() | Renvoie le numéro de l'itération courante d'une simulation en cours d'exécution. |
| RiskCurrentSim() | Renvoie le numéro de simulation courant d'une simulation en cours d'exécution. |
| RiskStopRun(lef_cell ou formule) | Arrête une simulation quand la valeur de réf_cell renvoie VRAI ou que la formule s'avéré (VRAI). |
| Fonction graphique | Description |
| RiskResultsGraph(lef_cell ou nom de sortie/entrée; plaque_cell_emplacement; Type_graph; FormatExcel;délim_gauche; délim_droit; MinX; MaxX; ÉchelleX; titre; n° sim) | Ajoute un graphique des résultats de simulation à une feuille de calcul. |
Référence : fonctions de distribution
Les fonctions de distribution sont listées dans cette section avec leurs arguments obligatoires. Les arguments facultatifs s'ajoutent aux arguments obligatoires au moyen des fonctions de propriété de distribution @RISK décrites dans la section suivante.
RiskBeta
| Description | RiskBeta(alpha1; alpha2) spécifique une distribution bêta avec paramètres de forme alpha1 et alpha2. Ces deux arguments générent une distribution bêta à valeur minimum de 0 et valeur maximum de 1. La distribution bêta sert souvent de point de départ à la dérivation d'autres distributions (bêta générale, PERT et bêta subjective). Étroitement liée à la distribution binomiale, elle représentée la distribution de l'incertitude de la probabilité d'un processus binomial sur base d'un certain nombre d'observations de ce processus. |
| Exemples | RiskBeta(1;2) spécifique une distribution bêta avec paramètres de forme 1 et 2. RiskBeta(C12;C13) spécifique une distribution bêta avec paramètre de forme alpha1 tiré de la cellule C12 et paramètre de forme alpha2 tiré de la cellule C13. |
| Directives | α1 paramètre de forme continu α1>0 α2 paramètre de forme continu α2>0 |
| Domaine | 0≤x≤1 continu |
| Fonctions de distribution de densité et cumulatives | f(x)=xα1-1(1-x)α2-1/B(α1,α2) F(x)=Bx(α1,α2)/B(α1,α2)=Ix(α1,α2)ou B représentée la fonction Bêta et Bx,la fonction Bêta incomplète. |
| Moyenne | α1/α1+α2 |
| Variance | α1α2/(α1+α2)2(α1+α2+1) |
| Asymétrie | 2α2-α1/α1+α2+2√(α1+α2+1)/α1α2 |
| Aplissement | 3(α1+α2+1)(2(α1+α2)2+α1α2(α1+α2-6))/α1α2(α1+α2+2)(α1+α2+3) |
| Mode | α1-1/α1+α2-2α1>1, α2>10 α1<1, α2≥1 ou α1=1, α2>11 α1≥1, α2<1 ou α1>1, α2=1 |
| Examples | CDF - Beta(2,3)1.00.80.60.40.30.20.10.70.50.40.30.20.10.70.50.40.30.20.10.70.50.40.30.20.10.70.50.40.30.20.10.70.50.40.30.20.10.70.50.40.30.2 |
| PDF - Beta(2,3)2.01.81.61.41.21.00.80.60.40.31.00.70.51.2 |
RiskBetaGeneral
| Description | RiskBetaGeneral(alpha1; alpha2; minimum; maximum) spécifique une distribution bêta à valeurs minimum et maximum définitions et avec paramètres de forme alpha1 et alpha2. La distribution bêta générale est directement dérivée de la distribution bêta, par réduction de la plage [0,1] à une valeur minimum et maximum pour définir la plage. La distribution PERT peut être dérivée comme cas spécial de la distribution bêta générale. | |
| Exemples | RiskBetaGeneral(1;2;0;100) spécifique une distribution bêta avec paramètres de forme 1 et 2, valeur minimum 0 et valeur maximum 100. RiskBetaGeneral(C12;C13;D12;D13) spécifique une distribution bêta dont le paramètre de forme alpha1 est tiré de la cellule C12, le paramètre de forme alpha2, de la cellule C13 et les valeurs minimum et maximum, des cellules D12 et D13, respectivement. | |
| Directives | α1 paramètre de forme continu α1 > 0 α2 paramètre de forme continu α2 > 0 min paramètre de limite continu min < max max paramètre de limite continu | continue |
| Domaine | min ≤ x ≤ max | continue |
| Fonctions de distribution de densité et cumulatives | f(x) = (x - min)^α1-1(max - x)^α2-1 / B(α1, α2)(max - min)^α1 + α2 - 1 F(x) = Bz(α1, α2) / B(α1, α2) ≈ Iz(α1, α2) z ∈ x - min / max - min ou B représentée la fonction Bêta et Bz, la fonction Bêta incomplete. | |
| Moyenne | min + α1 / α1 + α2 (max - min) | |
| Variance | α1α2 / (α1 + α2)^2 (α1 + α2 + 1) (max - min)^2 | |
| Asymétrie | 2α2-α1/α1+α2+2√α1+α2+1/α1α2 | |
| Aplatissement | 3(α1+α2+1)(2(α1+α2)2+α1α2(α1+α2-6))/α1α2(α1+α2+2)(α1+α2+3) | |
| Mode | min+α1-1/α1+α2-2(max-min) α1>1, α2>1min α1<1, α2≥1 ou α1=1, α2>1max α1≥1, α2<1 ou α1>1, α2=1 | |
| Exemples | PDF - BetaGeneral(2,3,0,5) | |
| Description | RiskBetaGeneralAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3; type_arg4; valeur_arg4) spécifique une distribution bêta assortedie de quatre arguments de type type_arg1 à type_arg4. Ces arguments peuvent représentater un centile de 0 à 1 ou alpha1, alpha2, min ou max. |
| Exemples | RiskBetaGeneralAlt("min";0;10%;1;50%;20;"max";50) spécifique une distribution bêta avec une valeur minimum de 0, une valeur maximum de 50, une valeur de 1 au 10e centile et une valeur de 20 au 50e centile. |
| Directives | Les paramètres alpha1 et alpha2 doivent être tous deux supérieurs à zéro et max > min.Si la fonction RiskBetaGeneralAltD est utilisé, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée. |
RiskBetaSubj
| Description | RiskBetaSubj(minimum; la plus probable; moyenne; maximum) spécifique une distribution bêta à valeurs minimum et maximum spécifiées. Les paramètres de forme sont calculés à partir des valeurs la plus probable et moyenne spécifiées. La distribution bêta subjective se rapproche de la bêta générale dans la mesure où la plage de la distribution bêta sous-jacente est ramenée à une échelle. Son paramétrage permet cependant de l'utiliser dans les cas où les paramètres désirables sont non seulement les valeurs minimum-la plus probable-maximum ( comme dans la distribution PERT), mais où ils incluent aussi la moyenne de la distribution. |
| Exemples | RiskBetaSubj(0;1;2;10) spécifique une distribution bêta avec une valeur minimum de 0, une valeur maximum de 10, une valeur plus probable de 1 et une valeur moyenne de 2. RiskBetaSubj(A1;A2;A3;A4) spécifique une distribution bêta avec une valeur minimum tirée de la cellule A1, une valeur maximum tirée de la cellule A4, la valeur la plus probable tirée de la cellule A2 et la valeur moyenne tirée de la cellule A3. |
| Définitions | mid = min+max/2 α1 ≈ 2(mean - min)(mid - mlikely)/(mean - mlikely)(max - min) α2 ≈ α1 max - mean / mean - min |
| Paramètres | min paramètre de limite continu min < max m. likely paramètre continu min < m. likely < max moyenne paramètre continu min < moyenne < max max paramètre de limite continu moyenne > milieu si m. likely > moyenne moyenne < milieu si m. likely < moyenne moyenne = milieu si m. likely = moyenne |
| Domaine | min ≤ x ≤ max continu |
| Fonctions de distribution de densité et cumulatives | f(x) = (x - min)^α1-1(max - x)^α2-1 B(α1, α2)(max - min)^α1+α2-1 F(x) = Bz(α1, α2)/B(α1, α2) ≡ Iz(α1, α2) z ∈ max - min où B représentée la fonction Bêta et Bz, la fonction Bêta incomplète. |
| Moyenne | moyenne |
| Variance | (mean - min)(max - mean)(mean - mlikely) 2 · mid + mean - 3 · mlikely |
| Asymétrie | 2(mid - mean)/|mean + mid - 2 · mlikely|√(mean - mlikely)(2 · mid + mean - 3 · mlikely)/(mean - min)(max - mean) |
| Aplissement | 3(α1 + α2 + 1)(2(α1 + α2)^2 + α1α2(α1 + α2 - 6)) α1α2(α1 + α2 + 2)(α1 + α2 + 3) |
| Mode | mlikely |
Examples
PDF - BetaSubj(0,1,2,5)
| Description | RiskBinomial(n; p) spécifique une distribution binomiale avec n essais et p probabilités de réussite à chaque essai. Le nombre d'essais est souvent qualifié de nombre de tirages ou d'échantillons réalisés. La distribution binomiale est une distribution discrète ne renvoyant que des valeurs entières supérieures ou égales à zéro. Cette distribution correspond au nombre d'événements survenant dans un essai d'un ensemble d'événements indépendants à probabilité égale. Par exemple, RiskBinomial(10;20%) représentait le nombre de découvertes de pérole dans un portefeuille de 10 puits de prospection représentant chacun une chance de 20 % de découverte. L'application de modélisation la plus importante se présente quand n=1, de sorte qu'il existe deux issues possibles (0 ou 1), où 1 présente une probabilité spécifique p et 0, une probabilité 1-p. Quand p=0,5, on a l'équivalent d'un pile ou face équilibré. Pour les autres valeurs de p, la distribution peut servir à modéliser le risque exceptionnel, c.-à-d. la réalisation ou non d'un événement, et à transformer les registres de risques en modèles de simulation pour totaliser les risques. |
| Examples | RiskBinomial(5;0,25) spécifique une distribution binomiale généraee à partir de 5 essais ou « tirages » avec une probabilité de réussite de 25 % à chaque tirage. RiskBinomial(C10*3;B10) spécifique une distribution binomiale généraee à partir des essais ou « tirages » définis par la valeur de la cellule C10 multipliée par 3. La probabilité de succès à chaque tirage est indiquée dans la cellule B10. |
| Directives | Le nombre d'essais n doit être un entier positif supérieur à zéro et inférieur ou égal à 32 767. La probabilité p doit être supérieur ou égale à zéro et inférieur ou égale à 1. |
| Paramètres | n paramètre de « nombre » discret n > 0* p probabilité de « succès » continue 0 < p < 1* *n = 0, p = 0 et p = 1 sont gérés pour la commodité de la modélisation mais produit des distributions dégénéées. |
| Domaine | 0 ≤ x ≤ n entiers discrets |
| Fonctions de masse et cumulatives | f(x) = (n/x)p^x(1-p)^n-x F(x) = ∑_{i=0}^{x} (n/i)p^i(1-p)^n-i |
| Moyenne | np |
| Variance | np(1-p) |
| Asymétrie | (1-2p)/√np(1-p) |
| Aplissement | 3-6/n+1/np(1-p) |
| Mode | (bimodal) p(n+1)-1 et p(n+1) si p(n+1) est un entier (unimodal) plus grand entier inférieur à p(n+1) sinon |
| Exemples | PMF - Binomial(8,.4) |
RiskChiSq
| Description | RiskChiSq(v) spécifique une distribution chi carré à v degrés de liberté. |
| Exemples | RiskChiSq(5) génére une distribution chi carré à 5 degrés de liberté.RiskChisq(A7) génére une distribution chi carré dont le paramètre de liberté est tiré de la cellule A7. |
| Directives | Le nombre de degrés de liberté v doit être un entier positif. |
| Paramètres | v paramètre de forme discret v > 0 |
| Domaine | 0 ≤ x < +∞ continu |
| Fonctions de distribution de densité et cumulatives | f(x) = 1/2v/2Γ(v/2)e-x/2x(v/2)-1F(x) = Γx/2(v/2)/Γ(v/2)ou Γ représentée la fonction Gamma et Γx, la fonction Gamma incomplète. |
| Moyenne | v |
| Variance | 2v |
| Asymétrie | √8/v |
| Aplissement | 3+12/v |
| Mode | v-2 si v ≥ 20 si v = 1 |
Examples
CDF - ChiSq(5)
RiskCompound
| Description | RiskCompound(dist1 ou valeur ou ref_cell; dist2 ou ref_cell; franchise; limite) renvoie la somme d'un nombre d'échantillons de dist2 ou le nombre d'échantillons prélevés dans dist2 est donné par la valeur échantillonnée dans dist1 ou valeur. dis1 représentée généralement la distribution de fréquence et dist2, la distribution de gravité. Facultativement, franchise est soustraite de chaque échantillon dist2 et si (échantillon dist2-franchise) excède limite, l'échantillon dist2 est régle sur limite.RiskCompound s'évalue à chaque itération d'une simulation. La valeur du premier argument se calculé à l'aide d'un échantillon de dist1 ou d'une valeur de ref_cell. Un nombre d'échantillons égal à la valeur du premier argument est ensuite prélevé dans dist2 et totalisé. Cette somme est la valeur renvoyée pour la fonction RiskCompound. |
| Examples | RiskCompound(RiskPoisson(5);RiskLognorm(10000;10000)) totalise un nombre d'échantillons tirés de RiskLognorm(10000;10000) où le nombre d'échantillons à totaliser est donné par la valeur échantillonnée dans RiskPoisson(5). |
| Directives | dist1, mais pas dist2, peut être corrélée. RiskCompound elle-même peut être corrélée.franchise et limite sont des arguments facultatifs.Si (échantillon dist2-franchise) dépasse limite, l'échantillon de dist2 est régle sur limite.dist1, dist2 et RiskCompound peuvent inclure des fonctions de propriété, à l'exception de RiskCormat comme indiqué ci-dessus.Les fonctions de distribution en entrée dist1 ou dist2, de même que les fonctions de distribution des cellules référencées dans la fonction RiskCompound, ne s'affichent pas dans les résultats d'analyse de sensibilité des sorties affectées par la fonction RiskCompound. La fonction RiskCompound même inclut cependant les résultats d'analyse de sensibilité, soit les effets de dist1, dist2 et des fonctions de distribution des cellules référencées dans une fonction RiskCompound.dist2 peut être une référence à une ref_cell contenant une fonction de distribution ou une formule. Si une formule est entrée, cette formule sera recalculée chaque fois qu'une valeur de gravité sera nécessaire. Par exemple, la formule de gravité de la cellule A10 et la fonction de composition dans A11 pourrait être entrées comme suit :A10: =RiskLognorm(10000;1000)/(1,1^RiskWeibull(2;1))A11:= RiskCompound(RiskPoisson(5);A10)Dans ce cas, l'« échantillon » de la distribution de gravité serait généra par évaluation de la formule d'A10. À chaque itération, cette formule serait évaluée le nombre de fois spécifique par l'échantillon tiré de la distribution de fréquence.Remarque: La formule entrée doit compter <256 caractères. Si des calculs plus complexes sont requis, une fonction définie par l'utilisateur peut être entrée comme formule à évaluer. De plus, toutes les distributions @RISK à échantillonner dans le calcul de gravité doivent être entrées dans la formule de la cellule (A10 dans l'exemple ci-dessus) et non référencées dans d'autres cellules. |
| Il faut noter qu'une seule distribution de résultats de simulation n'est pas disponible pour la distribution de gravité ou le calcul de gravité après exécution. La fenêtre Synthèse des résultats ne compte aucune entrée relative à la distribution de gravité et:aucun graphique ne s'affiche pour elle dans la fenêtre de parcours. La raison en est que la distribution de gravité peut être échantillonnée une nombrequelconque de fois lors d'une simple itération, alors que toutes les autres distributions en entrée ne peuvent l'être qu'une fois. |
RiskCumul
| Description | RiskCumul(minimum; maximum; {X1; X2; ..., Xn}; {p1; p2; ..., pn}) spécifique une distribution cumulative à n points. La plage de la courbe cumulative est définie par les arguments minimum et maximum. Chaque point de la courbe cumulative est doté d'une valeur X et d'une probabilité p. Les valeurs et les probabilités vont en s'accroissant. Le nombre de points admis est illimité. |
| Examples | RiskCumul(0;10;{1;5;9};{0,1;0,7;0,9}) spécifique une courbe cumulative à 3 points de données sur une plage de 0 à 10. Le premier point, 1, est assorted d'une probabilité cumulative de 0,1 (10 % des valeurs de la distribution sont inférieures ou égales à 1, et 90 % sont supérieures à 1). Le deuxième point de la courbe est 5, avec une probabilité cumulative de 0,7 (70 % des valeurs de la distribution sont inférieures ou égales à 5, 30 % y sont supérieures). Le troisième point de la courbe est 9, avec une probabilité cumulative de 0,9 (90 % des valeurs de la distribution sont inférieures ou égales à 9, 10 % y sont supérieures). RiskCumul(100;200;A1:C1;A2:C2) spécifique une distribution cumulative à 3 points de données sur une plage de 100 à 200. La ligne 1 de la feuille de calcul — A1 à C1 — contient les valeurs de chaque point de données et la ligne 2 — A2 à C2 —, la probabilité cumulative à chacun des 3 points de la distribution. Dans Excel, les accelides ne sont pas obligatoires lorsque les entrées de la fonction sont des plages de cellules. |
| Directives | Les points de la courbe doivent être spécifique par ordre de valeur croissantante (X1<X2<X3;,...;<Xn). Les probabilités cumulatives p pour les points de la courbe doivent être spécifique par ordre de probabilité croissantante (p1<=p2<=p3;,...;<=pn). Les probabilités cumulatives p pour les points de la courbe doivent être supérieures ou égales à 0 et inférieures ou égales à 1. minimum doit être inférieur à maximum. minimum doit être inférieur à X1 et maximum doit être supérieur à Xn. |
| Paramètres | min paramètre continuin min < max |
| max paramètre continuin | |
| {x} = {x1; x2; ...; xN} série de paramètres continus min ≤ x1 ≤ max | |
| {p} = {p1; p2; ...; pN} série de paramètres continus 0 ≤ p1 ≤ 1 | |
| Domaine | min ≤ x ≤ max continu |
| Fonctions de distribution de densité et cumulatives | f(x) = pi+1 - pi/(xi+1 - xi) pour xi ≤ x < xi+1 |
| F(x) = pi + (pi+1 - pi)(x - xi)/xi+1 - xi) pour xi ≤ x ≤ xi+1 | |
| Pourvu que: Les séries suivant un ordre de gauche à droite. L'index i aille de 0 à N+1, avec deux éléments supplémentaires: x0 ≤ min, p0 ≤ 0 et xN+1 ≤ max, pN+1 ≤ 1. | |
| Moyenne | Pas de forme fermée |
| Variance | Pas de forme fermée |
| Asymétrie | Pas de forme fermée |
| Aplatissement | Pas de forme fermée |
| Mode | Pas de forme fermée |
Examples CDF-Cumul(0,5,{1,2,3,4},{2.,3.,7.,8.})
PDF-Cumul(0,5,{1,2,3,4},{2.,3.,7.8})
RiskCumulD
| Description | RiskCumulD(minimum;maximum;\{X1; X2;...; Xn}; \{p1; p2;...; pn\}) spécifique une distribution cumulative à n points. La plage de la corbe cumulative est définie par les arguments minimum et maximum. Chaque point de la corbe cumulative est doté d'une valeur X et d'une probabilité p. Les valeurs sont croissantes et les probabilités, décroissantes. Les probabilités entrées sont des probabilités cumulatives décroissantes, représentant la probabilité d'une valeur supérieure à la valeur X entée. Le nombre de points admis est illimité. |
| Exemples | RiskCumulD(0;10;\{1;5;9\};\{0,9;0,3;..,0,1\}) spécifique une corbe cumulative à 3 points de données sur une plage de 0 à 10. Le premier point, 1, est assorti d'une probabilité cumulative décroissantante de 0,9 (10 % des valeurs de la distribution sont inférieures ou égales à 1 et 90 % sont supérieures à 1). Le deuxième point de la corbe est 5, avec une probabilité cumulative décroissantante de 0,3 (70 % des valeurs de la distribution sont inférieures ou égales à 5, 30 % y sont supérieures). Le troisième point de la corbe est 9, avec une probabilité cumulative décroissantante de 0,1 (90 % des valeurs de la distribution sont inférieures ou égales à 9, 10 % y sont supérieures). RiskCumul(100;200;A1:C1;A2:C2) spécifique une distribution cumulative à 3 points de données sur une plage de 100 à 200. La ligne 1 de la feuille de calcul — A1 à C1 — contient les valeurs de chaque point de données et la ligne 2 — A2 à C2 — , la probabilité cumulative à chacun des 3 points de la distribution. Dans Excel, les accolades ne sont pas obligatoires lorsque les entrées de la fonction sont des plages de cellules. |
| Directives | Les points de la corbe doivent être spécifiés par ordre de valeur croissantante (X1<X2<X3;,...;<Xn). Les probabilités cumulatives p des points de la corbe doivent être spécifiées par ordre de probabilité cumulative décroissantante (p1>=p2>=p3;,...;>=pn). Les probabilités cumulatives décroissantantes p des points de la corbe doivent être supérieures ou égales à 0 et inférieures ou égales à 1. minimum doit être inférieur à maximum. minimum doit être inférieur à X1 et maximum doit être supérieur à Xn. |
| Paramètres | min paramètre continu min < max |
| max paramètre continu | |
| {x} = {x1; x2; ...; xN} série de paramètres continus min ≤ xi ≤ max | |
| {p} = {p1; p2; ...; pN} série de paramètres continus 0 ≤ pi ≤ 1 | |
| Domaine | min ≤ x ≤ max continu |
| Fonctions de distribution de densité et cumulatives | f(x) = p_i - p_{i+1} / x_{i+1} - x_i | pour x_i ≤ x < x_{i+1} |
| F(x) = 1 - p_i + (p_i - p_{i+1})\left(\frac{x - x_i}{x_{i+1} - x_i}\right) | pour x_i ≤ x ≤ x_{i+1} | |
| Pourvu que : Les séries suivant un ordre de gauche à droite. L'index i aille de 0 à N+1, avec deux éléments supplémentaires : x_0 ≧ min, p_0 ≧ 1 et x_{N+1} ≧ max, p_{N+1} ≧ 0. | ||
| Moyenne | Pas de forme fermée | |
| Variance | Pas de forme fermée | |
| Asymétrie | Pas de forme fermée | |
| Aplissement | Pas de forme fermée | |
| Mode | Pas de forme fermée | |
| Exemples | CDF - CumulD(0,5,{1,2,3,4},{.8,.7,.3,.2}) | |
PDF-CumulD(0,5,{1,2,3,4},{.8.,7.,3.,2})
RiskDiscrete
| Description | RiskDiscrete(\{X1; X2; ..., Xn\}; \{p1; p2; ..., pn\}) spécifique une distribution discrète assorted d'un nombre d'issues égal à n. Un nombre d'issues quelconque peut être définii. Chaque issue compte une valeur X et un poids p qui spécifique sa probabilité. Comme pour la fonction RiskHistogramm, la somme des poids est indifférente — @RISK en assure la normalisation aux probabilités. Il s'agit ici d'une distribution définie par l'utilisateur dans laquelle ce dernier spécifique toutes les issues possibles et leurs probabilités. Elle peut être utile quand plusieurs issues discrètes sont envisageables (« pire des cas- résultat probable-meilleur des cas », par exemple), pour réproduire d'autres distributions discrètes (la distribution binomiale, par exemple) et pour modéliser des scénarios discrets. |
| Examples | RiskDiscrete(\{0;0,5\};\{1;1\}) spécifique une distribution discrète à 2 issues de valeur 0 et 0,5. Chaque issue présente une probabilité égale (poids de 1 pour chacune). La probabilité de l'issue 0 et celle de l'issue 0,5 sont toutes deux de 50 % (1/2). RiskDiscrete(A1:C1;A2:C2) spécifique une distribution discrète à trois issues. La première ligne de la feuille de calcul (A1 à C1) contient les valeurs de chaque issue tandis que la deuxieme ligne (A2 à C2) contient le « poids » de probabilité de chaque valeur. |
| Directives | Les valeurs de poids p doivent être supérieures ou égales à zéro, et la somme de tous les poids doit être supérieure à zéro. |
| Paramètres | {x} = {x1; x2; ..., xN} série de paramètres continus {p} = {p1; p2; ..., pN} série de paramètres continus |
| Domaine | x ∈ {x} discret |
| Fonctions de masse etcumulatives | f(x)=pi pour x=x1 |
| f(x)=0 pour x∉{x} | |
| F(x)=0 pour x<x1 | |
| F(x)=∑s i=1 pi pour xs≤x<Xs+1, s<N | |
| F(x)=1 pour x≥xN | |
| Pourvu que:Les séries suivant un ordre de gauche à droite.La série p soit normalisée à 1. | |
| Moyenne | ΣNxi pi ≈ μi=1 |
| Variance | ΣN(xi - μ)2 pi ∈ Vi=1 |
| Asymétrie | 1/V3/2 ∑Nxi - μ)3 pi |
| Aplatissement | 1/V2 ∑Nxi - μ)4 pi |
| Mode | La valeur x correspondant à la plus haute valeur p. |
Examples
RiskUniform
| Description | RiskDuniform(\{X1; X2; ..., Xn\}) spécifique une distribution uniforme discrète à n issues possibles et probabilité égale de réalisation de chacune. La valeur de chaque issue possible est indiquée par sa valeur X respective. Chaque valeur présente une probabilité égale de réalisation. Pour générer une distribution uniforme discrète pour laquelle chaque valeur entière d'une plage représentée une issue possible, utilisez la fonction RiskIntUniform. | |
| Exemples | RiskDuniform(\{1;2,1;4.45;99\}) spécifique une distribution uniforme discrète à 4 issues possibles. Les issues possibles sont les valeurs 1 ; 2,1 ; 4,45 et 99. RiskDuniform(A1:A5) spécifique une distribution uniforme discrète à 5 issues possibles. Les issues possibles sont les valeurs tirées des cellules A1 à A5. | |
| Directives | Aucune. | |
| Paramètres | {x} = {x1; x1; ...; xN} | série de paramètres continus |
| Domaine | x ∈ {x} | discret |
| Fonctions de masse et cumulatives | f(x) = 1/N | pour x ∈ {x} |
| f(x) = 0 | pour x∉{x} | |
| F(x) = 0 | pour x < x1 | |
| F(x) = i/N | pour x1 ≤ x < xi+1 | |
| F(x) = 1 | pour x ≥ xN | |
| pourvu que la série {x} soit classée en ordre. | ||
| Moyenne | 1/N ∑i=1N xi ≈ μ | |
| Variance | 1/N ∑N i=1 (xi - μ)2 ≡ V | |
| Asymétrie | 1/NV3/2 ∑N i=1 (xi - μ)3 | |
| Aplissemment | 1/NV2 ∑N i=1 (xi - μ)4 | |
| Mode | Non défini de manière unique | |
| Exemples | CDF - DUniform{1,5,8,11,12} | |
PMF - DUniform({1,5,8,11,12})
RiskErf
| Description | RiskErf(h) spécifique une fonction d'erreur avec un paramètre de variance h. La distribution de fonction d'erreur est dérivée d'une distribution normale. |
| Exemples | RiskErf(5) génére une fonction d'erreur avec un paramètre de variance 5. RiskErf(A7) génére une fonction d'erreur avec un paramètre de variance tiré de la cellule A7. |
| Directives | Le paramètre de variance h doit être supérieur à 0. |
| Paramètres | h paramètre d'échelle inverse continu h > 0 |
| Domaine | -∞ < x < +∞ continu |
| Fonctions de distribution de densité et cumulatives | f(x) = h / √π e-(hx)2 F(x) ≈ Φ(√2 hx) = (1 + erf(hx)/2 où Φ représentée l'intégrale Laplace-Gauss et erf, la fonction d'erreur. |
| Moyenne | 0 |
| Variance | 1/2h2 |
| Asymétrie | 0 |
| Aplissemment | 3 |
| Mode | 0 |
Examples
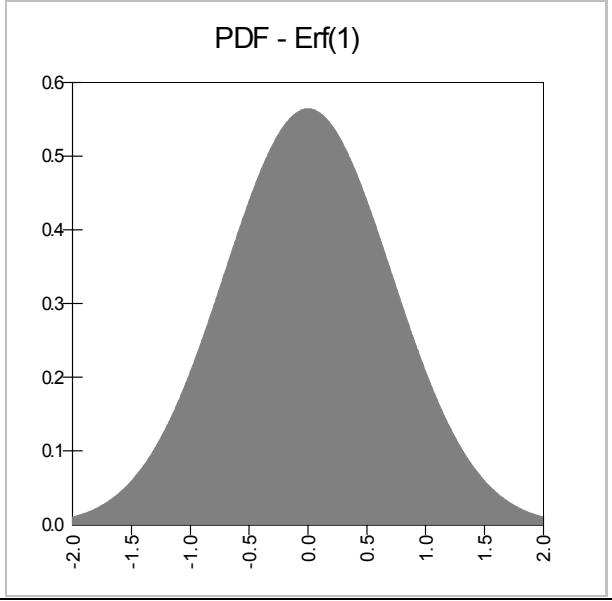
RiskErlang
| Description | RiskErlang(m; bêta) génére une distribution M-Erlang assorted des valeurs spécifiées m et bêta. m est un argument entier de distribution gamma et bêta, un paramètre d'échelle. |
| Exemples | RiskErlang(5;10) spécifique une distribution de M-Erlang avec une valeur m de 5 et un paramètre d'échelle de 10.RiskErlang(A1;A2/6,76) spécifique une distribution de M-Erlang avec une valeur m tirée de la cellule A1 et un paramètre d'échelle égal à la valeur de la cellule A2 divisée par 6,76. |
| Directives | m doit être un entier positif.La valeur bêta doit être supérieure à zéro. |
| Paramètres | m paramètre de forme intégral m > 0β paramètre d'échelle continu β > 0 |
| Domaine | 0 ≤ x < +∞ continu |
| Fonctions de distribution de densité et cumulatives | f(x) = 1/β (m-1)! (x/β) m-1 e-x/βF(x) = Γx/β(m)/Γ(m) = 1 - e-x/β ∑i=0m-1 (x/β)i i!où Γ représentée la fonction Gamma et Γx, la fonction Gamma incomplète. |
| Moyenne | mβ |
| Variance | mβ2 |
| Asymétrie | 2/√m |
| Aplissement | 3 + 6/m |
| Mode | β(m-1) |
Examples
PDF - Erlang(2,1)
RiskExpon
| Description | RiskExpon(bêta) spécifique une distribution exponentielle avec la valeur bêta spécifique. La moyenne de la distribution est égale à bêta. Cette distribution est l'équivalent en temps continu de la distribution géométrique. Elle représentée la durée d'atte et de première réalisation d'un processus continu dans le temps et d'intensité constante. Elle pourrait être utilisée dans des applications similaires à la distribution géométrique (modélisation de files d'atte, maintenance et pannes), bien que le principe d'intensité constante lui soit nuisible dans certaines applications pratiques. | |
| Exemples | RiskExpon(5) spécifique une distribution exponentielle avec une valeur bêta de 5. RiskExpon(A1) spécifique une distribution exponentielle avec une valeur bêta tirée de la cellule A1. | |
| Directives | La valeur bêta doit être supérieure à zéro. | |
| Paramètres | β paramètre d'échelle continu β > 0 | |
| Domaine | 0 ≤ x < +∞ | continu |
| Fonctions de distribution de densité et cumulatives | f(x) = e-x/β F(x) = 1 - e-x/β | |
| Moyenne | β | |
| Variance | β² | |
| Asymétrie | 2 | |
| Aplissemment | 9 | |
| Mode | 0 | |
Examples CDF - Expon(1)
PDF - Expon(1)
RiskExponAlt, RiskExponAltD
| Description | RiskExponAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2) spécifique une distribution exponentielle assortie de deux arguments de type type_arg1 et type_arg2. Ces arguments peuvent représentier soit un centile de 0 à 1, soit beta ou loc. |
| Examples | RiskExponAlt("beta";1;95%;10) spécifique une distribution exponentielle à valeur bêta égale à 1 et 95° centile égal à 10. |
| Directives | La valeur bêta doit être supérieure à zéro.Si la fonction RiskExponAltD est utilisée, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée. |
RiskExtValue
| Description | RiskExtValue(alpha; bêta) spécifique une distribution de valeurs extrêmes avec paramètre d'emplacement alpha et paramètre de forme bêta. | |
| Exemples | RiskExtvalue(1;2) spécifique une distribution de valeurs extrêmes avec une valeur alpha de 1 et une valeur bêta de 2.RiskExtvalue(A1;B1) spécifique une distribution de valeurs extrêmes avec une valeur alpha tirée de la cellule A1 et une valeur bêta tirée de la cellule B1. | |
| Directives | bêta doit être supérieur à zéro. | |
| Paramètres | alpha paramètre d'emplacement continubêta paramètre d'échelle continu | bêta > 0 |
| Domaine | -∞ < x < +∞ | continu |
| Fonctions de distribution de densité et cumulatives | f(x) = 1/b(1/(e^z+exp(-z)))F(x) = 1/e^exp(-z) | ou z ≈ (x - a)/b |
| où a= alpha, b=bêta | ||
| Moyenne | a - bΓ'(1) ≈ a + .577bou Γ'(x) est la dérivée de la fonction Gamma. | |
| Variance | π2b2/6 | |
| Asymétrie | 12√6/π3ζ(3)≈1.139547 | |
| Aplissement | 5,4 | |
| Mode | alpha | |
| Exemples | PDF - ExtValue(0,1) | |
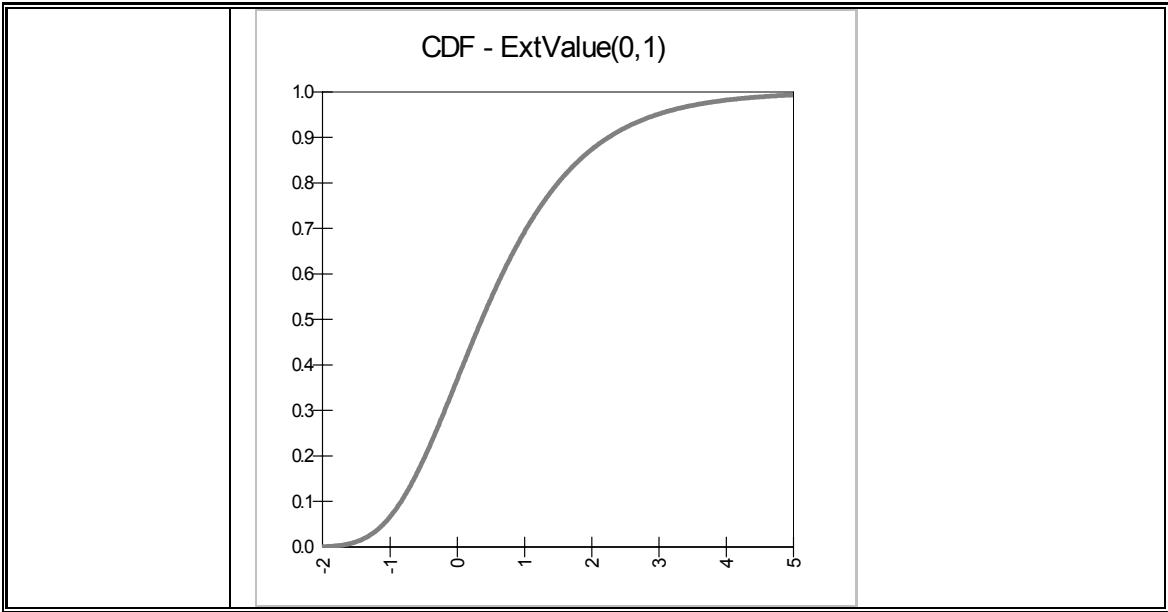
| Description | RiskExtValueAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2) spécifique une distribution de valeurs extrêmes assortie de deux arguments de type type_arg1 et type_arg2. Ces arguments peuvent représentier soit un centile de 0 à 1, soit alpha ou beta. |
| Exemples | RiskExtvalueAlt(5%;10;95%;100) spécifique une distribution de valeurs extrêmes à valeur 10 au 5e centile et 100 au 95e centile. |
| Directives | La valeur bêta doit être supérieure à zéro. Si la fonction RiskExtValueAltD est utilisé, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée. |
RiskGamma
| Description | RiskGamma(alpha; bêta) spécifique une distribution gamma avec le paramètre de forme alpha et le paramètre d'échelle bêta. La distribution gamma est l'équivalent en temps continu de la binomiale négative : elle représentée la distribution des durées entre arrivées de plusieurs événements de processus Poisson. Elle peut aussi servir à représentater la distribution des valeurs possibles quant à l'intensité d'un processus Poisson, après observations du processus. | |
| Exemples | RiskGamma(1;1) spécifique une distribution gamma dans laquelle le paramètre de forme a pour valeur 1 et le paramètre d'échelle, 1. RiskGamma(C12;C13) spécifique une distribution gamma dans laquelle la valeur du paramètre de forme est tirée de la cellule C12 et celle du paramètre d'échelle, de la cellule C13. | |
| Directives | Les valeurs alpha et bêta doivent toutes deux être supérieures à zéro. | |
| Paramètres | α paramètre de forme continu α > 0β paramètre d'échelle continu β > 0 | |
| Domaine | 0 < x < +∞ | continu |
| Fonctions de distribution de densité et cumulatives | f(x) = 1/β Γ(α) (x/β)α-1 e-x/βF(x) = Γx/β (α)/Γ(α)ou Γ représentée la fonction Gamma et Γx, la fonction Gamma incomplète. | |
| Moyenne | βα | |
| Variance | β2α | |
| Asymétrie | 2/√α | |
| Aplissemment | 3 + 6/α | |
| Mode | β(α - 1) 0 | si α ≥ 1 si α < 1 |
Examples
PDF - Gamma(4,1)
RiskGammaAlt, RiskGammaAltD
| Description | RiskGammaAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3) spécifique une distribution gamma assortedie de trois arguments de type type_arg1 à type_arg3. Ces arguments peuvent representatione soit un centile de 0 à 1, soit alpha, beta ou loc. |
| Examples | RiskGammaAlt("alpha";1;"beta";5;95%;10) spécifique une distribution gamma dont le paramètre de forme a pour valeur 1, le paramètre d'échelle, 5, et le 95° centile, 10. |
| Directives | Les valeurs alpha et bêta doivent toutes deux être supérieures à zéro. Si la fonction RiskGammaAltD est utilisé, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée. |
RiskGeneral
| Description | RiskGeneral(minimum; maximum; {X1; X2; ..., Xn}; {p1; p2; ..., pn}) génére une distribution de probabilités généralisée fondée sur une courbe de densité aux paires (X,p) spécifiées. Chaque paire se compose d'une valeur X et d'un poids de probabilité p, spécifique à la hauteur relative de la courbe au niveau de cette valeur X. @RISK normalise les valeurs p lors de la détermination des probabilités effectivement appliquées à l'échantillonnage. | |
| Exemples | RiskGeneral(0;10;{2;5;7;9};{1;2;3;1}) spécifique une fonction de densité de distribution de probabilités générale à quatre points. La distribution s'échelonne de 0 à 10, avec quatre points (2, 5, 7 et 9) spécifique sur la courbe. La hauteur de la courbe au point 2 est 1 ; au point 5, 2 ; au point 7, 3 et au point 9, 1. La courbe coupe l'axe X aux points 0 et 10.RiskGeneral(100;200;A1:C1;A2:C2) spécifique une distribution de probabilités générale à trois points de données sur une plage de 100 à 200. La ligne 1 de la feuille de calcul — A1 à C1 — contient la valeur X de chaque point de données, et la ligne 2 — A2 à C2 —, la valeur p à chacun des 3 points de la distribution. Il convient de noter que les accelades ne sont pas requisées quand des plages de cellules sont utilisées en tant qu'entrées de matrice dans la fonction. | |
| Directives | Le poids de probabilité p doit être supérieur ou égal à zéro. La somme de tous les poids doit être supérieure à zéro.Les valeurs X doivent être entrées en ordre croissant et se situer dans la plage minimum-maximum de la distribution.La valeur minimum doit être inférieure à la valeur maximum. | |
| Paramètres | min paramètre continumin< maxmax{x} = {x1; x2; ...; xN} {p} = {p1; p2; ...; pN} {p} = {p1; p2; ...; pN} {p} = {p1; p2; ...; pN} {p} = {p1; p2; ...; pN} {p} = {p1; p2; ...; pN} {p} = {p1; p2; ...; pN} {p} = {p1; p2; ...; pN} {P} = {p1; p2; ...; pN} {p} = {p1; p2; ...; pN} {p} = {p1; p2; ...; pN} {p} = {p1; p2; ...; pN} {p} = {p1; p2; ...; pN} {p} = {p1; p2; ...; pN} {p} = {P} | |
| Domaine | min ≤ x ≤ max continu | |
| Fonctions de distribution de densité et cumulatives | f(x) = pi + [X - Xi/Xi+1 - Xi](pi+1 - pi) pour xi ≤ x ≤ xi+1 F(x) = F(xi) + (x - xi) [pi + (pi+1 - pi)(x - xi)/2(xi+1 - xi)] pour xi ≤ x ≤ xi+1 Pourvu que: Les séries suivant un ordre de gauche à droite. La série {p} ait été normalisée pour produit la zone d'unité de la distribution générale. L'index i aille de 0 à N+1, avec deux éléments supplémentaires: x0 ≦ min, p0 ≦ 0 et xN+1 ≦ max, pN+1 ≦ 0. | |
| Moyenne | Pas de forme fermée | |
| Variance | Pas de forme fermée | |
| Asymétrie | Pas de forme fermée | |
| Aplissement | Pas de forme fermée | |
| Mode | Pas de forme fermée | |
CDF - General(0,5,{1,2,3,4},{2,1,2,1})
PDF - General(0,5,{1,2,3,4},{2,1,2,1})
RiskGeomet
| Description | RiskGeomet(p) génére une distribution géométrique assortedie d'une probabilité p. La valeur renvoyée représenté le nombre d'échecs survenus avant l'enregistrement d'un succès sur une série d'essais indépendants. Il existe une probabilité de succès p à chaque essai. La distribution géométrique est une distribution discrète ne renvoyant que des valeurs entières supérieures ou égales à zéro. Cette distribution correspond à l'incertitude quant au nombre d'essais de distribution binomialles nécessaires à la première réalisation d'un événement de probabilité donnée : par exemple, la distribution du nombre de fois qu'une piece doit être lancée avant d'obtenir pile, ou le nombre de mises successives nécessaires, à la roulette, avant que ne sorte le numéro sélectionné. La distribution peut aussi servir aux modèles d'entretien de base, pour représentier, par exemple, le nombre de mois susceptibles de s'écouler avant qu'une voiture ne tombe en panne. Comme la distribution requiert cependant une probabilité constante de panne par essai, d'autres modèles sont souvent utilisés, où la probabilité de panne augmente avec l'âge. |
| Exemples | RiskGeomet(0,25) spécifique une distribution géométrique avec une probabilité de succès à chaque essai de 25 %. RiskGeomet(A18) spécifique une distribution géométrique avec une probabilité de succès à chaque essai tirée de la cellule A18. |
| Directives | La probabilité p doit être supérieure à zéro et inférieure ou égale à un. |
| Paramètres | p probabilité de « succès » continue 0< p ≤ 1 |
| Domaine | 0 ≤ x < +∞ entiers discrets |
| Fonctions de masse et cumulatives | f(x) = p(1 - p)x F(x) = 1 - (1 - p)x+1 |
| Moyenne | 1/1 - 1/p |
| Variance | 1-p/p2 |
| Asymétrie | (2-p)/√1-p pour p < 1 Non défini pour p = 1 |
| Aplissement | 9 + p2/1 - p pour p < 1 Non définir pour p = 1 |
| Mode | 0 |
| Exemples | CDF - Geomet(.5) 1.0 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0.0 1 2 3 4 5 6 7 PMF - Geomet(.5) |
RiskHistogramm
| Description | RiskHistogram(minimum; maximum; {p1; p2; ..., pn}) spécifique une distribution de type historogramme définie par l'utilisateur, sur une plage définie par les valeurs minimum et maximum. Cette plage est divisée en n classes. Chaque classe possède un poids p reflétant la probabilité d'une valeur comprise dans la classe. Peu importe la valeur des poids : le seul facteur important est le poids d'une classe par rapport aux autres. Ainsi, la somme des poids ne doit pas nécessairement être égale à 100 %. @RISK normalise automatiquement les probabilités de classe : le total des poids spécifiés est calculé, et chaque poids est divisé par la somme obtenue. | |
| Exemples | RiskHistogram(10;20;{1;2;3;2;1}) spécifique un historogramme à valeur minimum de 10 et valeur maximum de 20. Cette plage est divisée en 5 classes de longueur égale, car il existe 5 valeurs de probabilité. Les poids de probabilité pour les cinq classes sont les arguments 1, 2, 3, 2 et 1. Les probabilités réelles correspondant à ces poids seraient 11,1 % (1/9) ; 22,2 % (2/9) ; 33,3 % (3/9) ; 22,2 % (2/9) et 11,1 % (1/9). Il suffit de divisor par 9 pour normaliser ces valeurs de façon à ce que leur somme soit égale à 100 %. RiskHistogram(A1;A2;B1:B3) spécifique un historogramme à valeur minimum tirée de la cellule A1 et valeur maximum tirée de la cellule A2. Cette plage est divisée en 3 classes de longueur égale, car il existe 3 valeurs de probabilité. Les poids de probabilité sont tirés des cellules B1 à B3. | |
| Directives | Les valeurs de poids p doivent être supérieures ou égales à zéro, et la somme de tous les poids doit être supérieure à zéro. | |
| Paramètres | min paramètre continuin min < max * | |
| max paramètre continuin | ||
| {p} = {p1; p2; ..., pn} série de paramètres continus pi≥0 | ||
| * min = max est géré pour la commodité de la modélisation mais produit une distribution dégénérente. | ||
| Domaine | min ≤ x ≤ max continu | |
| Fonctions de distribution de densité et cumulatives | f(x) = p_i pour xi ≤ x < xi+1 | |
| F(x) = F(xi) + pi(x - xi)/xi+1 - xi pour xi ≤ x ≤ xi+1 | ||
| xi ≈ min + i(max - min/N) | ||
| où la série {p} a été normalisée pour produit la zone d'unité de l'histogramme. | ||
| Moyenne | Pas de forme fermée | |
| Variance | Pas de forme fermée | |
| Asymétrie | Pas de forme fermée | |
| Aplissement | Pas de forme fermée | |
| Mode | Non défini de manière unique. | |
Examples
PDF - Histogram(0,5,{6,5,3,4,5})
RiskHypergeo
| Description | RiskHypergeo(n; D; M) spécifique une distribution hypergéométrique avec taillée de l'échantillon n, nombre d'éléments d'un certain type D et effectif de population M. La distribution hypergéométrique est une distribution discrète renvoyant uniquement des valeurs entières non négatives. | |
| Exemples | RiskHypergeo(50;10;1000) revoie une distribution hypergéométrique généraee en utilisant une taillée d'échantillon de 50, 10 éléments du type pertinent et une population de 1 000. RiskHypergeo(A6;A7;A8) revoie une distribution hypergéométrique généraee en utilisant une taillée d'échantillon tirée de la cellule A6, un nombre d'éléments tiré de la cellule A7 et une population tirée de la cellule A8. | |
| Directives | Tous les arguments (n, D et M) doivent être des valeurs entières positives. La valeur de la taillée de l'échantillon n doit être inférieure ou égale à la population M. La valeur du nombre d'éléments D doit être inférieure ou égale à la population M. | |
| Paramètres | n nombre de tirages entier 0 ≤ n ≤ M | |
| D nombre d'éléments « marqués » entier 0 ≤ D ≤ M | ||
| M nombre total d'éléments entier M ≥ 0 | ||
| Domaine | max(0,n+D-M) ≤ x ≤ min(n,D) | entiers discrets |
| Fonctions de masse et cumulatives | f(x) = (D/x)(M-D-n-x)/(M/n) | F(x) = ∑i=1x(D/x)(M-D-n-x)/(M/n) |
| Moyenne | nDM pour M > 0 | |
| 0 pour M = 0 | ||
| Variance | nD[(M-D)(M-n)]/M2[(M-1)] pour M>1 0 pour M=1 | |
| Asymétrie | (M-2D)(M-2n)/M-2√(M-1/nD(M-D)(M-n)) pour M>2, M>D>0, M>n>0 Non défini sinon | |
| Aplissemment | M2(M-1)/n(M-2)(M-3)(M-n) [M(M+1)-6n(M-n)+3n(M-n)(M+6)/D(M-D) - 6] pour M>3, M>D>0, M>n>0 Non défini sinon | |
| Mode | (bimodal) xm et xm-1 si xm est un entier (unimodal) plus grand entier inférieur à xm sinon x_m ≈ (n+1)(D+1)/M+2 où | |
Examples
RiskIntUniform
| Description | RisiklntUniform(minimum; maximum) spécifique une distribution de probabilités uniforme assorted des valeurs minimum et maximum spécifiées. Seules les valeurs entières de la plage définie sont possibles et chacune a les mêmes chances de se produit. | |
| Exemples | RisiklntUniform(10;20) spécifique une distribution uniforme avec une valeur minimum de 10 et une valeur maximum de 20.RisiklntUniform(A1+90;B1) spécifique une distribution uniforme avec une valeur minimum égale à la valeur de la cellule A1 plus 90 et une valeur maximum tirée de la cellule B1. | |
| Directives | La valeur minimum doit être inférieure à la valeur maximum. | |
| Paramètres | min paramètre de limite discreté min < maxmax probabilité de limite discrète | |
| Domaine | min ≤ x ≤ max entiers discrets | |
| Fonctions de masse etcumulatives | f(x) = 1/ max - min + 1F(x) = x - min + 1/ max - min + 1 | |
| Moyenne | min+ max2 | |
| Variance | Δ(Δ+2)/12 where Δ=(max-min) | |
| Asymétrie | 0 | |
| Aplissement | \(\left(\frac{9}{5}\right)\cdot\left(\frac{n^2-7/3}{n^2-1}\right)\) where n=(max-min+1) | |
| Mode | Non défini de manière unique | |
Examples
PMF - IntUniform(0,8)
RiskInvgauss
| Description | RisikInvgauss(mu; lambda) spécifique une distribution de Gauss inverse avec moyenne mu et paramètre de forme lambda |
| Exemples | RisikInvgauss(5;2) renvoie une distribution de Gauss inverse avec une valeur mu de 5 et une valeur lambda de 2.RisikInvgauss(B5;B6) renvoie une distribution de Gauss inverse avec une valeur mu tirée de la cellule B5 et une valeur lambda tirée de la cellule B6. |
| Directives | La valeur mu doit être supérieure à zéro.La valeur lambda doit être supérieure à zéro. |
| Paramètres | μ paramètre continu μ > 0λ paramètre continu λ > 0 |
| Domaine | x > 0 continu |
| Fonctions de distribution de densité et cumulatives | f(x) = √λ/2πx3 e-(λ(x-μ)2/2μ2x)F(x) = Φ[√λ/x(x/μ-1)] + e2λ/μ Φ[-√λ/x(x/μ+1)]ou Φ(z) représentée la fonction de distribution cumulative d'une distribution Normal(0;1), également appelée Intégrale Laplace-Gauss. |
| Moyenne | μ |
| Variance | μ3/λ |
| Asymétrie | 3√μ/λ |
| Aplissement | 3+15μ/λ |
| Mode | μ[√1+9μ2/4λ2-3μ/2λ] |
Examples
CDF - InvGauss(1,2)
RiskInvgaussAlt, RiskInvgaussAltD
| Description | RisikInvgaussAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3) spécifique une distribution de Gauss inverse assortedie de trois arguments de type type_arg1 à type_arg3. Ces arguments peuvent representationder soit un centile de 0 à 1, soit mu, lambda ou loc. |
| Exemples | RisikInvgaussAlt("mu";10;5%;1;95%;25) renvoie une distribution de Gauss inverse à valeur mu égale à 10, 5° centile égal à 1 et 95° centile égal à 25. |
| Directives | La valeur mu doit être supérieure à zéro.La valeur lambda doit être supérieure à zéro.Si la fonction RisikInvgaussAltD est utilisé, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée. |
RiskJohnsonMoments
| Description | RiskJohnsonMoments(moyenne,étcart_type,asymétrie,aplâtissement) désisit l'une de quatre fonctions de distribution (toutes membres du système dit « de Johnson ») correspondant aux valeurs moyenne,étcart type,asymétrie et aplâtissement spécifique. La distribution réalisante est une distribution JohnsonSU, JohnsonSB, normale logarithmique ou normale. |
| Examples | RiskJohnsonMoments(10;20;4;41) renvoie une distribution du groupe Johnson dont la valeur de moyenne est 10, la valeur d'étcart type,20, la valeur d'asymétrie,4 et la valeur d'aplâtissement,41.RiskJohnsonMoments(A6;A7;A8;A9) renvoie une distribution du groupe Johnson dont la valeur de moyenne est tirée de la cellule A6,la valeur d'étcart type,de la cellule A7,la valeur d'asymétrie,de la cellule A8 et la valeur d'aplâtissement,de la cellule A9. |
| Guidelines | La valeur étcart type doit être une valeur positive. La valeur aplâtissement doit être supérieure à 1. |
| Parameters | μ paramètre d'emplacement continuσ paramètre d'échelle continu σ > 0s paramètre de forme continuk paramètre de forme continu k > 1k - s2 ≥ 1 |
| Domain | -∞ < x < +∞ continu |
| Density and Cumulative Distribution Functions | Voir les entrées pour chaque distribution du système Johnson |
| Mean | μ |
| Variance | σ2 |
| Skewness | s |
| Kurtosis | k |
| Mode | Pas de forme fermée |
Examples
RiskJohnsonSB
| Description | RiskJohnsonSB(alpha1,alpha2;a,b) spécifique une distribution SB (« system bounded ») de Johnson à valeurs entrées alpha1, alpha2, a et b. |
| Examples | RiskJohnsonSB(10;20;1;2) renvoie une distribution SB de Johnson à valeur alpha = 10, alpha2 = 20, a = 1 et b = 2.RiskJohnsonSB(A6;A7;A8;A9) renvoie une distribution SB de Johnson à valeur alpha tirée de la cellule A6, alpha2 tirée de la cellule A7, a tirée de la cellule A8 et b tirée de la cellule A9. |
| Guidelines | La valeur b doit être une valeur positive.b doit être supérieur à a. |
| Parameters | alpha1 paramètre de forme continualpha2 paramètre de forme continu \( \alpha_{\text{pha2}} > 0 \)a paramètre d'emplacement continub paramètre d'échelle continu\( b > a \) |
| Domain | a ≤ x ≤ bcontinu |
| Density and Cumulative Distribution Functions | f(x) = α2(b-a)/√2π(x-a)(b-x)×e-1/2[α1+α2ln(x-a/b-x)]F(x)=Φ[α1+α2ln(x-a/b-x)]ou Φ est la fonction de distribution cumulative d'une distribution Normal(0;1). |
| Mean | La forme fermée existe mais est extrémement compliquée. |
| Variance | La forme fermée existe mais est extrémement compliquée. |
| Skewness | La forme fermée existe mais est extrémement compliquée. |
| Kurtosis | La forme fermée existe mais est extrémement compliquée. |
| Mode | Pas de forme fermée. |
Examples
RiskJohnsonSU
| Description | RiskJohnsonSU(alpha1,alpha2;gamma,bêta) spécifique une distribution SU (« system unbounded ») de Johnson à valeurs entrées alpha1, alpha2, gamma et bêta. |
| Examples | RiskJohnsonSU(10;20;1;2) renvoie une distribution SU de Johnson à valeur alpha = 10, alpha2 = 20, gamma = 1 et bêta = 2.RiskJohnsonSU(A6;A7;A8;A9) renvoie une distribution SU de Johnson à valeur alpha tirée de la cellule A6, alpha2 tirée de la cellule A7, gamma tirée de la cellule A8 et bêta tirée de la cellule A9. |
| Guidelines | La valeur alpha2 doit être une valeur positive.La valeur bêta doit être une valeur positive. |
| Parameters | alpha1 paramètre de forme continualpha2 paramètre de forme continu \(\begin{array}{c}\alpha_{\texttt{p}}=0\\ \gamma\quad\mathrm{parametre~d'emplacement~continu}\\ \beta\quad\mathrm{parametre~d'echelle~continu}\end{array}\)\(\begin{array}{c}\beta>0\\ \beta>0\end{array}\) |
| Domain | \(-\infty < x < +\infty\) \(\begin{array}{c}\text{continue}\\ \text{continue}\end{array}\) |
| Definitions | \(\theta\equiv\exp\left(\left(\frac{1}{\alpha_2}\right)^2\right)\qquad\mathrm{r}\equiv\frac{\alpha_1}{\alpha_2}\) |
| Density and Cumulative Distribution Functions | f(x)=\(\frac{\alpha_2}{\beta\sqrt{2\pi(1+z^2)}}\)\(\begin{array}{l} -\frac{1}{2}\left[\alpha_1+\alpha_2\sinh^{-1}(z)\right]^2\\ \Phi\left(\alpha_1+\alpha_2\sinh^{-1}(z)\right)\end{array}\)F(x)=\(\Phi\left(\alpha_1+\alpha_2\sinh^{-1}(z)\right)\)Où et Φ est la fonction de distribution cumulative d'une distribution Normal(0;1). |
| Mean | \(\gamma-\beta\sqrt{\theta}\sinh(r)\) |
| Variance | \(\frac{\beta^2}{2}\left(\theta-1\right)\left(\theta\cosh(2r)+1\right)\) |
| Skewness | \(-\frac{1}{4}\sqrt{\theta}\left(\theta-1\right)^2\left[\theta\left(\theta+2\right)\sinh(3r)+3\sinh(r)\right]\)\(\left[\frac{1}{2}\left(\theta-1\right)\left(\theta\cosh(2r)+1\right)\right]\frac{3}{2}\) |
| Kurtosis | 1/8(θ-1)2[θ2(θ4+2θ3+3θ2-3)cosh(4r)+4θ2(θ+2)cosh(2r)+3(2θ+1)]/[(1/2(θ-1)(θcosh(2r)+1))2] |
| Mode | Pas de forme fermée. |
| Examples | PDF - JohnsonSU(2,2,0,1) 0.6 0.5 0.4 0.3 0.2 0.1 0.0 4.5 -4.0 -3.5 -3.0 -2.5 -2.0 -1.5 -1.0 -0.5 0.5 CDF - JohnsonSU(2,2,0,1) 1.0 0.8 0.6 0.4 0.2 0.0 -4.5 -4.0 -3.5 -3.0 -2.5 -2.0 -1.5 -1.0 -0.5 0.0 0.5 |
RiskLogistic
| Description | RiskLogistic(alpha; bêta) spécifique une distribution logistique assorted des valeurs alpha et bêta spécifiées. |
| Exemples | RiskLogistic(10;20) renvoie une distribution logistique générale à l'aide d'une valeur alpha de 10 et d'une valeur bêta de 20.RiskLogistic(A6;A7) renvoie une distribution logistique générale à l'aide d'une valeur alpha tirée de la cellule A6 et d'une valeur bêta tirée de la cellule A7. |
| Directives | La valeur bêta doit être une valeur positive. |
| Paramètres | α paramètre d'emplacement continuβ paramètre d'échelle continu β > 0 |
| Domaine | -∞ < x < +∞ continu |
| Fonctions de distribution de densité et cumulatives | f(x) = sec h2(1/2(x - α)/β)4β1 + tanh(1/2(x - α)/β)2où « sech » représentée la fonction sécante hyperbolique et « tanh », la fonction tangente hyperbolique. |
| Moyenne | α |
| Variance | π2β23 |
| Asymétrie | 0 |
| Aplissement | 4.2 |
| Mode | α |
Examples
CDF - Logistic(0,1)
RiskLogisticAlt, RiskLogisticAltD
| Description | RiskLogisticAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2) spécifique une distribution logistique assortedie de deux arguments de type type_arg1 et type_arg2. Ces arguments peuvent representatione soit un centile de 0 à 1, soit alpha ou beta. |
| Exemples | RiskLogisticAlt(5%;1;95%;100) renvoie une distribution logistique à valeur 1 au 5° centile et 100 au 95° centile. |
| Directives | La valeur bêta doit être une valeur positive.Si la fonction RiskLogisticAltD est utilisé, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée. |
RiskLogLogistic
| Description | RiskLoglogistic(gamma; bêta; alpha) spécifique une distribution logistique logarithmique avec paramètre d'emplacement gamma, paramètre de forme alpha et paramètre d'échelle bêta. | |
| Exemples | RiskLoglogistic(-5;2;3) renvoie une distribution logistique logarithmique généraee à l'aide d'une valeur gamma de -5, d'une valeur bêta de 2, et d'une valeur alpha de 3.RiskLoglogistic(A1;A2;A3) renvoie une distribution logistique logarithmique généraee à l'aide d'une valeur gamma tirée de la cellule A1, d'une valeur bêta tirée de la cellule A2 et d'une valeur alpha tirée de la cellule A3. | |
| Directives | La valeur alpha doit être supérieure à zéro.La valeur bêta doit être supérieure à zéro. | |
| Paramètres | γ paramètre d'emplacement continuβ paramètre d'échelle continuα paramètre de forme continu | β > 0α > 0 |
| Définitions | θ ≈ π/α | |
| Domaine | γ ≤ x < +∞ | continu |
| Fonctions de distribution de densité et cumulatives | f(x) = α tα-1/β(1+tα)2F(x) = 1/1+(1/t)αt | t ∈ X - γ/β |
| Moyenne | βθ csc(θ) + γ pour α > 1 | |
| Variance | β2θ [2csc(2θ) - θcsc2(θ)] pour α > 2 | |
| Asymétrie | 3csc(3θ) - 6θcsc(2θ)csc(θ) + 2θ2csc3(θ)/√θ[2csc(2θ) - θcsc2(θ)]3/2 | pour α > 3 |
| Aplissement | 4csc(4θ)-120csc(3θ)csc(θ)+1202csc(2θ)csc2(θ)-303csc4(θ)θ[2csc(2θ)-θcsc2(θ)]2pour α>4 |
| Mode | γ+β[α-1/α]1/αpour α>1γpour α≤1 |
| Exemples | PDF - LogLogistic(0,1,5) |
| Description | RiskLogLogisticAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3) spécifique une distribution logistique logarithmique assortedie de trois arguments de type type_arg1 à type_arg3. Ces arguments peuvent représentater soit un centile de 0 à 1, soit gamma, beta ou alpha. |
| Examples | RiskLogLogisticAlt("gamma";5;"beta";2;90%;10) renvoie une distribution logistique logarithmique généraee à l'aide d'une valeur gamma de 5, d'une valeur bêta de 2, et d'un 90° centile de 10. |
| Directives | La valeur alpha doit être supérieure à zéro. La valeur bêta doit être supérieure à zéro. Si la fonction RiskLogLogisticAltD est utilisé, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée. |
RiskLognorm
| Description | RiskLognorm(moyenne; écart type) spécifique une distribution normale logarithmique assorted des valeurs moyenne et écart type spécifiées Les arguments de cette forme de distribution normale logarithmique spécifique la moyenne et l'écart type réels de la distribution de probabilités normale logarithmique généree.À l'image de la distribution normale, la normale logarithmique a deux paramètres ( , , ) correspondant à la moyenne et à l'écart type. Tout comme la distribution normale résultat de l'addition de nombreux processus aléatoires, la normale logarithmique est le produit de la multiplication d'un grand nombre de processus aléatoires. D'un point de vue technique, il s'agit d'une extension directe des résultats précédents en ce que le logarithme du produit de nombres aléatoires est égal à la somme des logarithmes. Dans la pratique, il s'agit souvent d'une représentation de la valeur future d'un élément dont la valeur en termes de pourcentage varie de manière aléatoire et indépendante. Cette distribution sert souvent dans l'industrie pétrolière, comme modèle de réserves après études géologiques dont les résultats sont incertains. Elle présente plusieurs propriétés désirables de processus réels : elle est notamment asymétrique, et elle présente une plage positive non limitée, de 0 à l'infini. Autre propriété utile, quand ' est faible par rapport à , l'asymétrie est faible et la distribution se rapproche d'une distribution normale. Ainsi, une distribution normale logarithmique peut approxcher une distribution normale en utilisant le même écart type mais en augmentant la moyenne (de sorte que le rapport / soit faible) puis en décalant la distribution par l'ajout d'une constante decke que les moyennes correspondent. |
| Exemples | RiskLognorm(10;20) spécifique une distribution normale logarithmique à moyenne de 10 et écart type de 20.RiskLognorm(C10*3,14;B10) spécifique une distribution normale logarithmique à moyenne égale à la valeur de la cellule C10 multiplée par 3,14 et écart type égal à la valeur de la cellule B10. |
| Directives | La moyenne et l'écart type doivent être supérieurs à 0. |
| Paramètres | μ paramètre continu μ > 0σ paramètre continu σ > 0 |
| Domaine | 0 ≤ x < +∞ continu |
| Fonctions de distribution de densité et cumulatives | f(x) = 1/x√2πσ' e-1/2[ln x - μ']^2 F(x) = Φ(ln x - μ') / σ' μ' ≈ ln[μ^2/√σ^2 + μ^2] et σ' ≈ √ln[1 + (σ/μ)^2] où Φ(z) représentée la fonction de distribution cumulative d'une distribution Normal(0;1), également appelée Intégrale Laplace-Gauss. |
| Moyenne | μ |
| Variance | σ^2 |
| Asymétrie | (σ/μ)^3 + 3(σ/μ) |
| Aplissement | ω^4 + 2ω^3 + 3ω^2 - 3 avec ω ≈ 1 + (σ/μ)^2 |
| Mode | μ^4/(σ^2 + μ^2)^3/2 |
Examples
RiskLognormAlt, RiskLognormAltD
| Description | RiskLognormAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3) spécifique une fonction de distribution normale logarithmique assortie de trois arguments de type type_arg1 à type_arg3. Ces arguments peuvent représentier soit un centile de 0 à 1, soit mu, sigma ou loc. |
| Examples | RiskLognormAlt("mu";2;"sigma";5;95%;30) spécifique une distribution normale logarithmique avec une moyenne de 2, un écart type de 5 et un 95e centile égal à 30. |
| Directives | Les valeurs mu et sigma doivent être supérieures à 0. Si la fonction RiskLognormAltD est utilisé, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée. |
RiskLognorm2
| Description | RiskLognorm2(moyenne de la dist. normale correspondante; écart type de dist. normale) spécifique une distribution normale logarithmique dont les valeurs moyenne et écart type entrées sont égales à la moyenne et à l'écart type de la distribution normale correspondante. Les arguments entrés sont la moyenne et l'écart type de la distribution normale pour laquelle l'exponentielle des valeurs de la distribution a été prise pour générer la fonction Lognormal souhaitée. |
| Exemples | RiskLognorm2(10;0,5) spécifique une distribution normale logarithmique générée ennant l'exponentielle des valeurs d'une distribution normale à moyenne de 10 et écart type de 0,5.RiskLognorm2(C10*3,14;B10) spécifique une distribution normale logarithmique générée ennant l'exponentielle des valeurs d'une distribution normale à moyenne égale à la valeur de la cellule C10 multipliée par 3,14 et écart type égal à la valeur de la cellule B10. |
| Directives | L'écart type doit être supérieur à 0. |
| Paramètres | μ paramètre continuσparamètre continu σ > 0 |
| Domaine | 0 ≤ x < +∞ continu |
| Fonctions de distribution de densité et cumulatives | f(x) = 1/x√2πσf(x) = Φ(x - μ)/σ ou Φ(z) représentée la fonction de distribution cumulative d'une distribution Normal(0;1), également appelée Intégrale Laplace-Gauss. |
| Moyenne | e μ+σ2/2 |
| Variance | e2μω(ω-1) avec ω ≈ eσ2 |
| Asymétrie | (ω+2)√ω-1 avec ω ≈ eσ2 |
| Aplissement | ω4+2ω3+3ω2-3 avec ω≡eσ2 |
| Mode | eμ-σ2 |
| Exemples | CDF - Lognorm2(0,1) |
| PDF - Lognorm2(0,1) |
RiskMakeInput
| Description | RiskMakeInput(formule) spécifique que la valeur calculée de formule doit être traitée comme une entrée de simulation, au même titre qu'une fonction de distribution. Grçé à cette fonction, les résultats de calculs Excel (ou d'une combinaison de fonctions de distribution) peuvent être traités comme une simple « entrée » dans une analyse de sensibilité. |
| Examples | RiskMakeInput (RiskNormal(10;1)+RiskTriang(1;2;3)+A5) spécifique que @RISK doitTRAiter la somme des échantillons des distributions RiskNormal(10;1) et RiskTriang(1;2;3) plus la valeur de la cellule A5 comme une entrée de simulation. Une entrée figurera sur l'onglet Entrées de la fenêtre Synthese des résultats pour la distribution de cette formule. Elle servira aux analyses de sensibilité des résultats qu'elle affecte. |
| Directives | Les distributions qui précèdent ou « alimentent » la fonction RiskMakeInput sont exclues de l'analyse de sensibilitité des sorties qu'elles affectent pour éviter le redoublement de leur impact. Leur impact est mesuré dans l'analyse de sensibilitité à travers la fonction RiskMakeInput.La fonction RiskMakeInput ne doit pas être l'antécédent d'une sortie pour être incluse dans son analyse de sensibilité : seules les distributions qui la précèdent doivent l'être. Ainsi, vous pouvez ajouter une simple fonction RiskMakeInput représentant la moyenne d'un ensemble de distributions. Chaque distribution comprend dans cet ensemble peut être l'antécédent d'une sortie. Ces distributions sont replacées dans l'analyse de sensibilité de cette sortie par la fonction RiskMakeInput.La fonction RiskMakeInput peut être assortedie de fonctions de propriété. Aucune correlation par RiskCormat n'est cependant admises car l'échantillonnage est différent de celui des fonctions de distribution standard.Aucun graphique n'est disponible pour la fonction RiskMakeInput, avant la simulation, dans les fenêtres Définir une distribution ou Modèle. |
RiskNegbin
| Description | RiskNegbin(s; p) spécifique une distribution binomiale négative à s succès et p probabilités de réussite à chaque tirage La distribution binomiale négative est une distribution discrète renvoyant uniquement les valeurs entières supérieures ou égales à zéro. Cette distribution représentée le nombre d'échecs avant plusieurs succès de distribution binomiale, de sorte que NegBin(1;p) = Geomet(p). Elle s'utilise parfois dans les modèles de contrôle de qualité et d'essai de production, de panne et de maintenance. | |
| Exemples | RiskNegbin(5;0,25) spécifique une distribution binomiale négative représentant 5 succès et une probabilité de succès à chaque essai de 25 %. RiskNegbin(A6;A7) spécifique une distribution binomiale négative représentant le nombre de succès tiré de la cellule A6 et une probabilité de succès tirée de la cellule A7. | |
| Directives | Le nombre de succès s doit être un entier positif inférieur ou égal à 32 767. La probabilité p doit être supérieure à zéro et inférieure ou égale à un. | |
| Paramètres | S nombre de succès paramètre discret s ≥ 0 p probabilité d'un succès paramètre continu 0 < p ≤ 1 | |
| Domaine | 0 ≤ x < +∞ entiers discrets | |
| Fonctions de masse et cumulatives | f(x) = (s + x - 1)/x p^s (1 - p)^x F(x) = p^s ∑i=0^x (s + i - 1)/i (1 - p)^i où() représenté le coefficient binomial. | |
| Moyenne | s(1 - p)/p | |
| Variance | s(1 - p)/p^2 | |
| Asymétrie | 2 - p/√s(1 - p) pour s > 0, p < 1 | |
| Aplissement | 3 + 6 / s + p2 / (1 - p) pour s > 0, p < 1 | |
| Mode | (bimodal) z et z + 1 entier z > 0 (unimodal) 0 z < 0 (unimodal) plus petit entier supérieur à z sinon z ≈ s(1 - p) - 1 où P | |
| Exemples | PDF - NegBin(3,.6) | |
| CDF - NegBin(3,.6) | ||
| Description | RiskNormal(moyenne; écart type) spécifique une distribution normale assortie des valeurs moyenne et écart type spécifiées. Il s'agit de la courbe « en cloche » traditionnelle applicable aux distributions des issues de nombreux ensembles de données.La distribution normale est une distribution continue symétrique non limitée d'un côte ni de l'autre et désrite par deux paramètres ( et , représentatifs de la moyenne et de l'écart type). Son usage se justifie souvent par référence à un résultat mathématique dit « théorème limite central » selon lequel, en quelles sorte, l'addition de nombreuses distributions indépendantes donne lieu à une distribution approximativement normale. La distribution se présente donc souvent dans la réalité comme l'effet composé de processus aléatoires (non observés) plus détaillés. Ce résultat s'aupliqué indépendamment de la forme des distributions initiales additionnées.La distribution peut servir à représentater l'incertitude d'une entrée de modèle quand on croit que l'entrée est en soit le résultat de nombreux autres processus aléatoires similaires qui se combinent de manière cumulative (mais qu'il peut paraître inutil, inefficace ou peu pratique de modéliser tous ces facteurs de manière individuelle). Par exemple : nombre total de buts marqués pendant uneaison de football ; quantité de pétrole dans le monde, si l'on considère la tailleapproximativement égale de nombreux réservoirs mais la quantité de pétrole incertaine de chacun. Dans les cas où la moyenne est beaucoup plus grandeque l'écart type (4 fois ou plus), les valeurs d'échantillon négatives de la distribution sont rares (de sorte que le nombre de buts ne serait généralementpas échantillonné négativement dans la praticque). Plus généralement, la sortie de nombreux modèles est approximativement normalément distributée, car de nombreux modèles ont une sortie qui résultat de l'addition de nombreux autresprocessus incertains. Par exemple : la distribution d'une valeur actualisée nette dans les modèles de série à long terme, consistant à additionner celles des années individuelles. |
| Examples | RiskNormal(10;2) spécifique une distribution normale à moyenne de 10 et écart type de 2.RiskNormal(RC(C101);B10) spécifique une distribution normale à moyenne égaleà la racine carrée de la valeur de la cellule C101 et écart type tiré de la celluleB10. |
| Directives | L'écart type doit être supérieur à 0. |
| Paramètres | μ paramètre d'emplacement continuσ paramètre d'échelle continu σ > 0 *= 0 est géré pour la commodité de la modélisation mais produit unedistribution dégénérate où x = . |
| Domaine | -∞ < x < +∞ continu |
| Fonctions de distribution de densité et cumulatives | f(x) = 1/√2πσe-1/2(x-μ)/σ2F(x) ≈ Φ(x-μ)/σ = 1/2[erf(x-μ)/√2σ)+1]où Φ représentée l'intégrale Laplace-Gauss et erf, la fonction d'erreur. |
| Moyenne | μ |
| Variance | σ2 |
| Asymétrie | 0 |
| Aplissement | 3 |
| Mode | μ |
| Exemples | PDF - Normal(0,1) |
CDF - Normal(0,1)
RiskNormalAlt, RiskNormalAltD
| Description | RiskNormaAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2) spécifique une distribution normale assortedie de deux arguments de type type_arg1 et type_arg2. Ces arguments peuvent représentater soit un centile de 0 à 1, soit mu ou sigma. |
| Exemples | RiskNormalAlt(5%;1;95%;10) spécifique une distribution normale à valeur 1 au 5e centile et 10 au 95e centile. |
| Directives | La valeur sigma doit être supérieure à zéro. Si la fonction RiskNormalAltD est utilisé, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée. |
RiskPareto
| Description | RiskPareto(thêta; alpha) spécifique une distribution de Pareto assorted des valeurs thêta et alpha spécifiées. | |
| Exemples | RiskPareto(5;5) spécifique une distribution de Pareto avec une valeur thêta de 5 et une valeur alpha de 5.RiskPareto(A10;A11+A12) spécifique une distribution de Pareto avec une valeur thêta tirée de la cellule A10 et une valeur alpha donnée par le résultat de l'expression A11+A12. | |
| Directives | La valeur thêta doit être supérieure à 0.La valeur alpha doit être supérieure à zéro. | |
| Paramètres | θ paramètre de forme continu | θ > 0 |
| alpha paramètre d'échelle continu | alpha > 0 | |
| Domaine | alpha ≤ x < +∞ | continu |
| Fonctions de distribution de densité et cumulatives | f(x) = θaθ/xθ+1F(x) = 1-(a/x)θou a = alpha | |
| Moyenne | aθ/θ-1 | pour θ > 1 |
| Variance | θa2/(θ-1)2(θ-2) | pour θ > 2 |
| Asymétrie | 2θ+1/θ-3√θ/θ | pour θ > 3 |
| Aplissement | 3(θ-2)(3θ2+θ+2)/θ(θ-3)(θ-4) | pour θ > 4 |
| Mode | alpha | |
| Examples | PDF - Pareto(2,1) |
| CDF - Pareto(2,1) |
RiskParetoAlt, RiskParetoAltD
| Description | RiskParetoAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2) spécifique une distribution de Pareto assortedie de deux arguments de type type_arg1 et type_arg2. Ces arguments peuvent représentater soit un centile de 0 à 1, soit theta ou alpha. |
| Examples | RiskParetoAlt(5%;1;95%;4) spécifique une distribution de Pareto à valeur 1 au 5e centile et 4 au 95e centile. |
| Directives | La valeur thèta doit être supérieure à 0. La valeur alpha doit être supérieure à zéro. Si la fonction RiskParetoAltD est utilisé, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée. |
RiskPareto2
| Description | RiskPareto2(b; q) spécifique une distribution de Pareto assorted des valeurs b et q spécifiées. | |
| Exemples | RiskPareto2(5;5) spécifique une distribution de Pareto avec une valeur b de 5 et une valeur q de 5.RiskPareto2(A10;A11+A12) spécifique une distribution de Pareto avec une valeur b tirée de la cellule A10 et une valeur q donnée par le résultat de l'expression A11+A12. | |
| Directives | La valeur b doit être supérieure à zéro.La valeur q doit être supérieure à zéro. | |
| Paramètres | b paramètre d'échelle continu | b > 0 |
| q paramètre de forme continu | q > 0 | |
| Domaine | 0 ≤ x < +∞ | continu |
| Fonctions de distribution de densité et cumulatives | f(x) = qb^q/(x + b)^{q+1}F(x) = 1 - b^q/(x + b)^q | |
| Moyenne | b/q-1 | pour q > 1 |
| Variance | b^2q/(q-1)^2(q-2) | pour q > 2 |
| Asymétrie | 2[q+1]/[q-3]√q/q | pour q > 3 |
| Aplissemment | 3(q-2)(3q^2 + q + 2)/q(q-3)(q-4) | pour q > 4 |
| Mode | 0 | |
Exemples PDF - Pareto2(3,3)
CDF - Pareto2(3,3)
RiskPareto2Alt, RiskPareto2AltD
| Description | RiskPareto2Alt(type_arg1; valeur_arg1; type_arg2; valeur_arg2) spécifique une distribution de Pareto assortedie de deux arguments de type type_arg1 et type_arg2. Ces arguments peuvent représentater soit un centile de 0 à 1, soit b ou q. |
| Exemples | RiskPareto2Alt(5%;0,05;95%;5) spécifique une distribution de Pareto à valeur 0,05 au 5° centile et 5 au 95° centile. |
| Directives | La valeur b doit être supérieure à zéro. La valeur q doit être supérieure à zéro. Si la fonction RiskPareto2AltD est utilisé, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée. |
RiskPearson5
| Description | RiskPearson5(alpha; bêta) spécifique une distribution de Pearson du type V avec le paramètre de forme alpha et le paramètre d'échelle bêta. | |
| Exemples | RiskPearson5(1;1) spécifique une distribution de Pearson de type V dans laquelle le paramètre de forme et le paramètre d'échelle ont tous deux la valeur 1. RiskPearson5(C12;C13) spécifique une distribution de Pearson de type V dans laquelle la valeur du paramètre de forme est tirée de la cellule C12 et celle du paramètre d'échelle, de la cellule C13. | |
| Directives | La valeur alpha doit être supérieure à zéro. La valeur bêta doit être supérieure à zéro. | |
| Paramètres | α paramètre de forme continu β paramètre d'échelle continu | α > 0 β > 0 |
| Domaine | 0 ≤ x < +∞ | continu |
| Fonctions de distribution de densité et cumulatives | f(x) = 1/βΓ(α) · (e-β/x/(x/β)α+1) F(x) n'a pas de forme fermée | |
| Moyenne | β/α - 1 | pour α > 1 |
| Variance | β2/(α - 1)2(α - 2) | pour α > 2 |
| Asymétrie | 4√α - 2/α - 3 | pour α > 3 |
| Aplissemment | 3(α + 5)(α - 2)/(α - 3)(α - 4) | pour α > 4 |
| Mode | β/α + 1 | |
Examples
CDF - Pearson5(3,1)
RiskPearson5Alt, RiskPearson5AltD
| Description | RiskPearson5Alt(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3) spécifique une distribution de Pearson de type V assortedie de trois arguments de type type_arg1 à type_arg3. Ces arguments peuvent représentier soit un centile de 0 à 1, soit alpha, beta ou loc. |
| Examples | RiskPearson5Alt("alpha";2;"beta";5;95%;30) spécifique une distribution de Pearson de type V à valeur alpha égale à 2, bêta égale à 5 et 95° centile égal à 30. |
| Directives | La valeur alpha doit être supérieure à zéro. La valeur bêta doit être supérieure à zéro. Si la fonction RiskPearson5AltD est utilisée, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée. |
RiskPearson6
| Description | RiskPearson6(alpha1; alpha2; bêta) spécifique une distribution de Pearson du type VI avec paramètre d'échelle bêta et paramètres de forme alpha1 et alpha2. | |
| Exemples | RiskPearson6(5;1;2) spécifique une distribution de Pearson de type VI dans laquelle les valeurs bêta, alpha2 et alpha1 sont, respectivement, 2, 1 et 5. RiskPearson6(E3;F3;D3) spécifique une distribution de Pearson de type VI dans laquelle les valeurs bêta, alpha1 et alpha2 sont tirées, respectivement, des cellules D3, E3 et F3. | |
| Directives | La valeur alpha1 doit être supérieure à zéro. La valeur alpha2 doit être supérieure à zéro. La valeur bêta doit être supérieure à zéro. | |
| Paramètres | α1 paramètre de forme continu α1 > 0 | |
| α2 paramètre de forme continu α2 > 0 | ||
| β paramètre d'échelle continu β > 0 | ||
| Domaine | 0 ≤ x < +∞ | continu |
| Fonctions de distribution de densité et cumulatives | f(x) = 1/βB(α1, α2) × (x/β)α1-1/(1 + x/β)α1+α2 | |
| F(x) n'a pas de forme fermée. ou B représentée la fonction Bêta. | ||
| Moyenne | βα1/α2 - 1 | pour α2 > 1 |
| Variance | β2α1(α1 + α2 - 1)/(α2 - 1)2(α2 - 2) | pour α2 > 2 |
| Asymétrie | 2√(α2 - 2)/α1(α1 + α2 - 1) [2α1 + α2 - 1/α2 - 3] | pour α2 > 3 |
| Aplissement | 3(α2-2)/(α2-3)(α2-4)[(2(α2-1)2/α1(α1+α2-1)+(α2+5)] pour α2>4 |
| Mode | β(α1-1)/α2+1 pour α1>10 sinon |
| Exemples | PDF - Pearson6(3,3,1) |
| CDF - Pearson6(3,3,1) |
| Description | RiskPert(minimum; plus probable; maximum) spécifique une distribution PERT (forme spéciale de distribution bêta) assorted des valeurs minimum et maximum spécifiées. Le paramètre de forme est calculé à partir de la valeur la plus probable définie.La distribution PERT (« Program Evaluation and Review Technique ») est aussi similaire à la distribution triangulaire en ce qu'elle présente le même jeu de trois paramètres. Il s'agit, techniquement parlant, d'un cas spécial de distribution bêta (ou bêta générale) normée. Elle représentée, en ce sens, une distribution pragmatique et facile à comprendre. On peut généralement la qualifier de supérieure à la distribution triangulaire lorsque les paramètres produit une distribution asymétrique : la forme lisse de la courbe atténue en effet l'accentuation dans le sens de l'asymétrie. comme la distribution triangulaire, la distribution PERT est limitée des deux côts et ne convient donc pas nécessairement dans les cas où la capture des événements extrêmes ou de queue est souhaitable. | |
| Exemples | RiskPert(0;2;10) spécifique une distribution bêta avec un minimum de 0, un maximum de 10 et une valeur la plus probable 2.RiskPert (A1;A2;A3) spécifique une distribution de Pert avec une valeur minimum tirée de la cellule A1, une valeur maximum tirée de la cellule A3, et une valeur la plus probable tirée de la cellule A2. | |
| Directives | La valeur minimum doit être inférieure à la valeur maximum.La valeur la plus probable doit être supérieure à la valeur minimum et inférieure à la valeur maximum. | |
| Définitions | μ ≈ min+4·m. likely + max6α1 ≡ 6[μ - min/max - min]α2 ≡ 6[max-μ/max-min] | |
| Paramètres | min paramètre de limite continumin < maxm. likely paramètre continumin < m. likely < maxmax paramètre de limite continu | |
| Domaine | min ≤ x ≤ maxcontinu | |
| Fonctions de distribution de densité et cumulatives | f(x) = (x - min)^α1-1(max - x)^α2-1 B(α1, α2)(max - min)^α1 + α2 - 1 F(x) = Bz(α1, α2)/B(α1, α2) ≡ Iz(α1, α2) z ∈ max - min où B représentée la fonction Bêta et Bz, la fonction Bêta incomplète. | |
| Moyenne | μ ≈ min+4·mlikely + max/6 | |
| Variance | (μ - min)(max - μ)/7 | |
| Asymétrie | min+max-2μ√7/4 (μ - min)(max - μ) | |
| Aplissement | 3(α1 + α2 + 1)(2(α1 + α2)^2 + α1α2(α1 + α2 - 6)) / α1α2(α1 + α2 + 2)(α1 + α2 + 3) | |
| Mode | m. likely | |
| Exemples | PDF - Pert(0,1,3) | |
| Description | RiskPertAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3) spécifique une distribution de Pert assortedie de trois arguments de type type_arg1 à type_arg3. Ces arguments peuvent représententer soit un centile de 0 à 1, soit min, m. likely ou max. |
| Examples | RiskPertAlt("min";2;"m. likely";5;95%;30) spécifique une distribution de Pert à valeur minimum égale à 2, valeur m. likely égale à 5 et un 95° centile égal à 30. |
| Directives | La valeur min doit être inférieure ou égale à la valeur m. likely. La valeur m. likely doit être inférieure ou égale à la valeur max. La valeur min doit être inférieure à la valeur max. Si la fonction RiskPertAltD est utilisée, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée. |
RiskPoisson
| Description | RiskPoisson( lambda) spécifie une distribution de Poisson avec une valeur lambda spécifiée. L'argument lambda représentée aussi la moyenne de la distribution de Poisson. La distribution de Poisson est une distribution discrète renvoyant uniquement des valeurs entières supérieures ou égales à zéro. La distribution de Poisson est un modèle du nombre d'événements survenant pendant une période donnée, avec intensité de processus constante (elle peut également s'appliquer aux processus d'autres domaines — spatial, par exemple). La distribution peut être considérée comme une extension de la distribution binomiale (dont le domaine est discret). Elle s'utilise souvent dans la modélisation d'assurance et sur les marchés financiers, comme distribution du nombre d'événements (tremblements de terre, incendies, krach boursier, etc.) susceptibles de se produit pendant une période donnée. | |
| Exemples | RiskPoisson(5) spécifie une distribution de Poisson avec une valeur lambda de 5. RiskPoisson(A6) spécifie une distribution de Poisson avec une valeur lambda tirée de la cellule A6. | |
| Directives | La valeur lambda doit être supérieure à zéro. | |
| Paramètres | λ nombre moyen de succès continu λ > 0* * = 0 est géné pour la commodité de la modélisation mais produit une distribution dégénérae où x = 0. | |
| Domaine | 0 ≤ x < +∞ entiers discrets | |
| Fonctions de masse et cumulatives | f(x) = λx e-λ/x! F(x) = e-λ ∑n=0x n/ n! | |
| Moyenne | λ | |
| Variance | λ | |
| Asymétrie | 1 /√λ | |
| Aplissement | 3 + 1/λ | |
| Mode | (bimodal) λ et λ-1 (bimodal) si λ est un entier | |
| (unimodal) plus grand entier inférieur à λ sinon | ||
| Exemples | CDF - Poisson(3) | |
| PMF - Poisson(3) | ||
RiskRayleigh
| Description | RiskRayleigh(bêta) spécifique une distribution de Rayleigh au mode bêta. | |
| Exemples | RiskRayleigh(3) spécifique une distribution de Rayleigh au mode 3.RiskRayleigh(C7) spécifique une distribution de Rayleigh au mode tiré de la valeur de la cellule C7. | |
| Directives | bêta doit être supérieur à zéro. | |
| Paramètres | bêta paramètre d'échelle continu | bêta > 0 |
| Domaine | 0 ≤ x < +∞ | continu |
| Fonctions de distribution de densité et cumulatives | f(x) = x/x2e-1/2(x/b)^2b^2F(x) = 1 - e^-1/2(x/b)^2où b = bêta | |
| Moyenne | b√π/2 | |
| Variance | b^2(2 - π/2) | |
| Asymétrie | 2(π - 3)√π/(4 - π)^3/2≈0.6311 | |
| Aplissement | 32 - 3π^2/(4 - π)^2≈3.2451 | |
| Mode | bêta | |
Exemples PDF - Rayleigh(1)
CDF - Rayleigh(1)
RiskRayleighAlt, RiskRayleighAltD
| Description | RiskRayleighAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2) spécifique une distribution de Rayleigh assortedie de deux arguments de type type_arg1 et type_arg2. Ces arguments peuvent representatione soit un centile de 0 à 1, soit beta ou loc. |
| Exemples | RiskRayleighAlt(5%;1;95%;10) spécifie une distribution de Rayleigh à valeur 1 au 5° centile et 10 au 95° centile. |
| Directives | La valeur beta doit être supérieure à zéro.Si la fonction RiskRayleighAltD est utilisé, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée. |
RiskResample
| Description | RiskResample(Méthode_ échant; {X1;X2;....;Xn}) échantillonne dans un ensemble de données à n issues possibles et probabilité égale de réalisation de chacune. La valeur de chaque issue possible est indiquée par sa valeur X respective. Chaque valeur présente une probabilité égale de réalisation. @RISK procèle à l'échantillonnage des valeurs X selon la méthode Méthode_ échant. Les méthodes disponibles sont : en ordre, aléatoire avec remplacement et aléatoire sans remplacement. |
| Examples | RiskResample(2;{1;2,1;4,45;99}) désigné un ensemble de données à 4 issues possibles. Les issues possibles sont les valeurs 1 ; 2,1 ; 4,45 et 99. Les échantillons sont prélevés aléatoirement avec remplacement au départ de ces 4 valeurs. RiskResample(1;A1:A500) désigné un ensemble de données à 500 valeurs possibles. Les valeurs possibles proviennent des cellules A1 à A500. Lors de la simulation, les valeurs sont échantillonnées en ordre dans cette plage. |
| Guidelines | Méthode_ échant peut être : 1-en ordre ; 2-aléatoire, avec remplacement ; ou 3-aléatoire, sans remplacement. Si Méthode_ échant est 1 (en ordre) ou 3 (aléatoire, sans remplacement), la fonction renvoie N° VALEUR quand le nombre d'iterations dépasse le nombre de valeurs comprises dans l'ensemble de données. Une fonction de propriété RiskLibrary peut être jointe à la fonction Resample pourlier les données X à une sortie de simulation stockée dans la Bibliothèque @RISK. En présence d'une fonction de propriété RiskLibrary, @RISKactualise les données de ré-echantillonnage X en fonction des données courantes stockées pour la sortie de simulation au début de chaque simulation. Ainsi, si une nouvelle version de la simulation contenant la sortie a été enregistrée dans la Bibliothèque @RISK, @RISKactualise automatiquement la fonction RiskResample en fonction des nouvelles données de cette sortie avant la simulation. |
RiskSimtable
| Description | RiskSimtable( {val1; val2; ...; valn}) spécifie une liste des valeurs à utiliser successivement dans les simulations individuelles d'une analyse de sensibilité. Dans une simulation de sensibilité, le nombre de simulations définài à l'aide de la commande Simulations Itérations est supérieur à un. Dans une simple simulation ou un recalcul normal, RiskSimtable renvoie la première valeur de la liste. Un nombre illimité de fonctions RiskSimtable peut être inclus dans une même feuille de calcul. À l'image des autres fonctions, les arguments de RiskSimtable peuvent inclure des fonctions de distribution. |
| Examples | RiskSimtable( {10; 20; 30; 40}) spécifie quatre valeurs à utiliser dans quatre simulations. Dans la simulation n° 1, la fonction SIMTABLE renvoie la valeur 10, dans la simulation n° 2, la valeur 20, et ainsi de suite. RiskSimtable(A1:A3) spécifie une liste de trois valeurs destinées à trois simulations. Dans la simulation n° 1, la valeur tirée de la cellule A1 est renvoyée. Dans la simulation n° 2, la valeur tirée de la cellule A2 est renvoyée. Dans la simulation n° 3, la valeur tirée de la cellule A3 est renvoyée. |
| Directives | Un nombre d'arguments quelconque peut être définii. Le nombre de simulations executées doit être inférieur ou égal au nombre d'arguments. Si ce dernier est inférieur au numéro d'une simulation en cours d'exécution, la fonction renvoie une erreur (ERR) pour cette simulation. |
RiskSplice
| Description | RiskSplice(dist1 ou réf_cell;dist2 ou réf_cell;point de jonction) spécifique une distribution créée par jonction de dist1 et dist2 à la valeur x donnée par le point de jonction. En développé du point de jonction, les échantillons proviennent de dist1. Au-delà, ils proviennent de dist2. La distribution réalisante est traitée comme une simple distribution en entrée ordinaire lors d'une simulation et peut être corrélée. |
| Examples | RiskSplice(RiskNormal(1;1);RiskPareto(1;1);2) joint une distribution normale à valeur moyenne = 1 et écart type = 1 à une distribution de Pareto à valeur théta =1 et a = 1 au point de jonction 2. |
| Guidelines | dist1 et dist2 ne peuvent pas être corrélées. La fonction RiskSplice elle-même peut être corrélée. dist1, dist2 et même RiskSplice peuvent inclure des fonctions de propriété, à l'exception de RiskCorrmat comme indiqué plus haut. dist1 et dist2 peuvent faire référence à une réf_cell contenant une fonction de distribution. |
RiskStudent
| Description | RiskStudent(nu) spécifique une distribution de Student à nu degrés de liberté. |
| Exemples | RiskStudent(10) spécifique une distribution de Student à 10 degrés de liberté.RiskStudent(J2) spécifique une distribution de Student à degrés de liberté tirésde la valeur de la cellule J2. |
| Directives | nu doit être un entier positif. |
| Paramètres | v degrés de liberté entier v > 0 |
| Domaine | -∞ < x < +∞ continu |
| Fonctions dedistribution dedensité etcumulatives | f(x) = 1/√πv Γ(v+1)/2 Γ(v/2) [v/(v+x2)]v+1/2F(x) = 1/2[1 + Is(1/2, v/2)]s ≈ x2v + x2avec ou Γ représentée la fonction Gamma et Ix, la fonction Béta incomplète. |
| Moyenne | 0 pour v > 1* |
| *bien que la moyenne ne soit pas définie pour v = 1, la distribution restesymétrique à environ 0. | |
| Variance | v/pour v > 2 |
| Asymétrie | 0 pour v > 3* |
| *bien que l'asymétrie ne soit pas définie pour v ≤ 3, la distribution restesymétrique à environ 0. | |
| Aplissemment | 3(v-2)/(v-4) pour v > 4 |
| Mode | 0 |
Examples
RiskTriang
| Description | RiskTriang(minimum; plus probable; maximum) spécifique une distribution triangulaire à trois points — minimum, valeur la plus probable et maximum. La direction de l'« asymétrie » de la distribution triangulaire est définie par l'importance de la valeur la plus probable par rapport aux points minimum et maximum. Cette distribution est peut-être la plus pragmatique et la plus facile à comprendre pour les modèles de risque élémentaires. Elle présente un certain nombre de propriétés désirables, y compris un simple ensemble de paramètres avec valeur module, représentant le cas le plus probable. La distribution triangulaire présente cependant deux grands inconvenients. D'abord, lorsque les paramètres produit une distribution asymétrique, il peut y avoir surestimation des issues dans la direction de l'asymétrie. Ensuite, la distribution est limitée des deux côts, alors que beaucoup de processus réels ne le sont que d'un. |
| Exemples | RiskTriang(100;200;300) spécifique une distribution triangulaire avec une valeur minimum de 100, une valeur la plus probable de 200 et une valeur maximum de 300. RiskTriang(A10/90;B10;500) spécifique une distribution triangulaire avec une valeur minimum égale à la valeur de la cellule A10 divisée par 90, une valeur la plus probable tirée de la cellule B10 et une valeur maximum de 500. |
| Directives | La valeur minimum doit être inférieure ou égale à la valeur la plus probable. La valeur la plus probable doit être inférieure ou égale à la valeur maximum. La valeur minimum doit être inférieure à la valeur maximum. |
| Paramètres | min paramètre de limite continu min < max * |
| m.likely paramètre de mode continu min ≤ m.likely ≤ max | |
| max paramètre de limite continu * min = max est géré pour la commodité de la modélisation mais produit une distribution dégénélée. | |
| Domaine | min ≤ x ≤ max continu |
| Fonctions de distribution de densité et cumulatives | f(x) = 2(x - min)/(m.likely - min)(max - min) | min ≤ x ≤ m. likely |
| f(x) = 2(max - x)/(max - m.likely)(max - min) | m. likely ≤ x ≤ max | |
| F(x) = (x - min)2/(m.likely - min)(max - min) | min ≤ x ≤ m. likely | |
| F(x) = 1 - (max - x)2/(max - m.likely)(max - min) | m. likely ≤ x ≤ max | |
| Moyenne | min + m. likely + max/3 | |
| Variance | min2 + m. likely2 + max2 - (max)(m. likely) - (m. likely)(min) - (max)(min)/18 | |
| Asymétrie | 2√2/5 f(f2-9)/(f2+3)3/2 | où f ≈ 2(m. likely - min)/max - min - 1 |
| Aplissement | 2,4 | |
| Mode | m. likely |
Exemples PDF - Triang(0,3,5)
CDF - Triang(0,3,5)
| Description | RiskTriangAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3) spécifique une distribution triangulaire assortie de trois arguments de type type_arg1 à type_arg3. Ces arguments peuvent représentater soit un centile de 0 à 1, soit min, m. likely ou max. |
| Exemples | RiskTriangAlt("min";2;"m.likely";5;95%;30) spécifique une distribution triangulaire à valeur minimum égale à 2, valeur la m. likely égale à 5 et 95° centile égal à 30. |
| Directives | La valeur min doit être inférieure ou égale à la valeur m. likely. La valeur m. likely doit être inférieure ou égale à la valeur max. La valeur min doit être inférieure à la valeur max. Si la fonction RiskTriangAltD est utilisée, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée. |
RiskTrigen
| Description | RiskTrigen(valeur inférieure; plus probable; valeur supérieure; cent. inf.; cent.sup.) spécifie une distribution triangulaire à trois points, dont un à la valeur la plus probable et deux aux centiles inférieur et supérieur spécifiés. Le centile inférieur et le centile supérieur sont des valeurs comprises entre 0 et 100. Chaque valeur de centile indique le pourcentage de la surface totale sous le triangle, à gauche du point entré. La fonction RiskTrigen évite le problème des valeurs minimum et maximum impossibles de la fonction RiskTriang ordinaire, ces points représentant les points d'intersection de la distribution avec l'axe X, de probabilité nulle. |
| Examples | RiskTrigen(100;200;300;10;90) spécifie une distribution triangulaire avec une valeur de 100 au 10e centile, une valeur la plus probable de 200 et une valeur de 300 au 90e centile. RiskTrigen(A10/90;B10;500;30;70) spécifie une distribution triangulaire avec une valeur au 30e centile égale à la valeur de la cellule A10 divisée par 90, une valeur la plus probable tirée de la cellule B10 et une valeur au 70e centile de 500. |
| Directives | La valeur cent. Inf. doit être inférieure ou égale à la valeur la plus probable. La valeur la plus probable doit être inférieure ou égale à la valeur cent. sup. La valeur cent.inf. doit être inférieure à la valeur cent.sup. |
RiskUniform
| Description | RiskUniform(minimum;maximum) spécifique une distribution de probabilités uniforme assorted des valeurs minimum et maximum spécifiées. Chaque valeur de la plage définie à les mêmes chances de se produit. Cette distribution est parfois qualifiée de « parfaite inconnue ». Elle s'applique, par exemple, à la position d'une molécule d'air particulière dans une piece, ou au prochain point de crevaison d'un pneu. Dans de nombreux cas d'incertitude, il existe en fait une valeur de base ou module et la probabilité relative d'autres issues diminue à mesure qu'on s'éloigne de cette valeur de base. Les circonstances réelles où cette distribution capture vérablement toute la connaissance relative à la situation sont par conséquent rares. La distribution n'en est pas moins extrémement importante, dans la mesure, notamment, où elle sert souvent, pour les algorithmès de nombres aléatoires, de point de départ à la génération d'échantillons d'autres distributions. |
| Exemples | RiskUniform(10;20) spécifique une distribution uniforme avec une valeur minimum de 10 et une valeur maximum de 20. RiskUniform(A1+90;B1) spécifique une distribution uniforme avec une valeur minimum égale à la valeur de la cellule A1 plus 90 et une valeur maximum tirée de la cellule B1. |
| Directives | La valeur minimum doit être inférieure à la valeur maximum. |
| Paramètres | min paramètre de limite continu min < max* max paramètre de limite continu * min = max est géré pour la commodité de la modélisation mais produit une distribution dégénéraée. |
| Domaine | min ≤ x ≤ max continu |
| Fonctions de distribution de densité et cumulatives | f(x) = 1/ max - min F(x) = x - min/ max - min |
| Moyenne | max-min 2 |
| Variance | (max-min)^2 12 |
| Asymétrie | 0 |
| Aplissement | 1,8 |
| Mode | Non défini de manière unique |
Examples
CDF - Uniform(0,1)
RiskUniformAlt, RiskUniformAltD
| Description | RiskUniformAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2) spécifique une distribution.uniforme assortedie de deux arguments de type type_arg1 et type_arg2. Ces arguments peuvent représentater soit un centile de 0 à 1, soit min ou max. |
| Exemples | RiskUniformAlt(5%;1;95%;10) spécifique une distribution.uniforme à valeur 1 au 5° centile et 10 au 95° centile. |
| Directives | La valeur min doit être inférieure à la valeur max.Si la fonction RiskUniformAltD est utilisé, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée. |
RiskWeibull
| Description | RiskWeibull(alpha; bêta) génére une distribution de Weilbull assortedu paramètre de forme alpha et du paramètre d'échelle bêta. La distribution deWeilbull est une distribution continue dont la forme et l'échelle varientgrandement en fonction des valeurs des arguments entrés.Cette distribution sert souvent de distribution du temps jusqu'à première réalisation d'autres processus en durée continue, quand une intensité deréalisation non constante est désirée. Elle est suffisamment touple pourpermettre une supposition implicite d'intensité constante, croissantoudécroissantee, selon le choix du paramètre ( <1, =1 et >1 représentent,respectivement, les processus d'intensité croissante, constante oudécroissantee ; un processus d'intensité constante équivaut à une distribution exponentielle). Dans les modèles de maintenance ou durée de vie, parexample, <1 représentée que plus une chose est ancienne, plus elle présentede risque de défaillance. |
| Exemples | RiskWeibull(10;20) génére une distribution de Weilbull avec le paramètre de forme 10 et le paramètre d'échelle 20.RiskWeibull(D1;D2) génére une distribution de Weilbull avec un paramètre deforme tiré de la cellule D1 et un paramètre d'échelle tiré de la cellule D2. |
| Directives | Les paramètres de forme alpha et d'échelle bêta doivent tous deux être supérieurs à zéro. |
| Paramètres | α paramètre de forme continu α > 0β paramètre d'échelle continu β > 0 |
| Domaine | 0 ≤ x < +∞ continu |
| Fonctions dedistribution dedensité cumulatives | f(x) = αxα-1/βe-(x/β)αF(x) = 1 - e-(x/β)α |
| Moyenne | βΓ(1+1/α)ou Γ représentée la fonction Gamma. |
| Variance | β2[Γ(1+2/α)-Γ2(1+1/α)]ou Γ représentée la fonction Gamma. |
| Asymétrie | Γ(1+3/α)-3Γ(1+2/α)Γ(1+1/α)+2Γ3(1+1/α) |
| [Γ(1+2/α)-Γ2(1+1/α)]3/2 | |
| où Γ représentée la fonction Gamma. | |
| Aplissemment | Γ(1+4/α)-4Γ(1+3/α)Γ(1+1/α)+6Γ(1+2/α)Γ2(1+1/α)-3Γ4(1+1/α) |
| [Γ(1+2/α)-Γ2(1+1/α)]2 | |
| où Γ représentée la fonction Gamma. | |
| Mode | β(1-1/α)1/α pour α>1 |
| 0 pour α≤1 |
Examples
CDF - Weibull(2,1)
RiskWeibullAlt, RiskWeibullAltD
| Description | RiskWeibullAlt(type_arg1; valeur_arg1; type_arg2; valeur_arg2; type_arg3; valeur_arg3) spécifique une distribution de Weibull assortedie de trois arguments de type type_arg1 à type_arg3. Ces arguments peuvent représentater soit un centile de 0 à 1, soit alpha, beta ou loc. |
| Exemples | RiskWeibullAlt("alpha";1;"beta";1;95%;3) spécifique une distribution de Weibull à valeur alpha égale à 1, beta égale à 1 et 95° centile égal à 3. |
| Directives | Les paramètres de forme alpha et d'échelle beta doivent tous deux être supérieurs à zéro.Si la fonction RiskWeibullAltD est utilisé, les valeurs de centile entrées sont des centiles cumulatifs décroissants : le centile spécifique la probabilité d'une valeur supérieure ou égale à la valeur entrée. |
Référence : fonctions de propriété des distributions
Les fonctions décrites ci-dessous permettent l'ajout d'arguments facultatifs aux fonctions de distribution. Ces arguments ne sont pas obligatoires. Ils peuvent être ajoutés selon les besoins rencontrés.
Les arguments facultatifs se définissent à l'aide des fonctions de propriété de distribution @RISK, incorporées dans une fonction de distribution.
RiskCategory
| Description | RiskCategory(nom de la catégorie) désigne la catégorie à utiliser à l'affchage d'une distribution en entrée. Le nom indiqué définit le groupe dans lequel l'entrée doit figurer, dans la liste Entrées de la fenêtre @RISK — Modèle, ainsi que dans tous les rapports incluant les résultats de simulation de l'entrée. |
| Exemples | RiskTriang(10;20;30;RiskCategory("Prix")) place la distribution de probabilités RiskTriang(10;20;30) dans la catégorie « Prix » . |
| Directives | Le nom de la catégorie doit être indiqué entre guillemets. Le nom peut être définir par une ↔quence de cellule valable. |
| Description | RiskCollect() identifie les fonctions de distribution spécifique dont les échantillons sont recueillis en cours de simulation et dont • les statistiques sont affichées, • les points de données sont disponibles, • les valeurs de sensibilité et de scenario sont calculées. Lorsque la fonction RiskCollect est utilisé et que l'option de collecte Entrées marquées de la propriété Collect est sélectionnée dans la zone Collecte d'échantillons de distribution de la boîte de dialogue Paramètres de simulation, seules les fonctions identifiées par RiskCollect s'affichtant dans la liste d'exploration de la fenêtre Synthese des résultats. Dans les versions antérieures de @RISK, la fonction RiskCollect se plaçait dans la formule de la cellule, juste avant la fonction de distribution pour laquelle les échantillons doivent être recueillis. Par exemple : =RiskCollect()+RiskNormal(10;10) RiskCollect s'utilise généralement en présence de nombreuses fonctions de distribution dans une feuille de calcul, lorsque les analyses de sensibilité et de scenario ne sont désirées que pour un sous-ensemble prédéfini de distributions importantes. Elle permet aussi de contourner les restrictions de mémoire Windows qui empêchent l'exécution des analyses de sensibilité et de scenario sur toutes les fonctions dans une simulation importante. |
| Exemples | RiskNormal(10;2;RiskCollect()) recueilles échantillons de la distribution de probabilités RiskNormal(10;2). |
| Directives | La case Entrées marquées de la propriété Collect doit être cochée dans la boîte de dialogue Paramètres de simulation pour que les fonctions COLLECT prennant effet. |
RiskConvergence
| Description | RiskConvergence(tolérance; Type_tolérance; Niveau_confiance; utiliserMoyenne; utiliserÉcart_type; utiliserCentile; centile) spécifique les paramètres de surveillance de convergence d'une sortie. tolérance représentée la quantité de tolérance +/- désirée ; Type_tolérance spécifique le type de valeur de tolérance entré (1 pour valeurs +/- réelles, 2 pourcentage ou valeurs +/- relatives) ; Niveau_confiance spécifique le niveau de confiance de votre estimation ; utiliserMoyenne, utiliserÉcart_type, utiliserCentile se réglient sur VRAI pour sélectionner la statistique désirée ; et centile définit le centile à surveiller lorsqu' utiliserCentile est VRAI. RiskConvergence renvoie FAUX si la sortie n'a pas converged et VRAI si elle a convergé. |
| Exemples | RiskOutput(;;;RiskConvergence(3%;2;95%;VRAI)) spécifique une tolérance de +/- 3 % avec un niveau de confiance de 95 % et surveillance de la statistique Moyenne. |
| Directives | Cette fonction de propriété l'emporte sur la surveillance de convergence par défaut éventuellesment configurée dans la boîte de dialogue Paramètres de simulation. La fonction de propriété RiskConvergence n'est disponible que pour les sorties de simulation. |
| Description | RiskCormat(plate de cellules de la matrice; position; instance) identifie une fonction de distribution appartenant à un ensemble de fonctions corréclées. Elle spécifie une corrélation multidimensionnelle. RiskCormat identifie 1) une matrice de coefficients de corrélation des rangs et 2) l'emplacement dans la matrice des coefficients de corrélation de la fonction de distribution qui suit la fonction RiskCormat.Les fonctions de distribution corréclées se définissent généralement à travers la commande @RISK Définir les correlations. Il est cependant possible de définir directement ces correlations dans le tableau, à l'aide de la fonction RiskCormat.La matrice identifiée par la plage de cellules de la matrice est une matrice de coefficients de corrélation des rangs. Chaque élément (ou cellule) de la matrice contient un coefficient de corrélation. Le nombre de fonctions de distribution corréclées par la matrice est égal au nombre de lignes ou colonnes de la matrice. L'argument position spécifique la colonne (ou la ligne) de la matrice à utiliser lors de la corrélation de la fonction de distribution qui suit RiskCormat.Les coefficients situés dans la colonne (ou la ligne) identifiée par position régissant la corrélation de la fonction de distribution identifiée avec chacune des autres fonctions de distribution corréclées représentées par la matrice. La valeur contenue dans une cellule de la matrice indique le coefficient de corrélation entre 1) la fonction de distribution dont la position RiskCormat représentée la coordonnée de colonne de la cellule et 2) la fonction de distribution dont la position RiskCormat représentée la coordonnée de ligne de la cellule. Les positions (et coordonnées) peuvent varier entre 1 et N, où N représentée le nombre de colonnes ou de lignes de la matrice.L'argument instance est facultatif. Il s'utilise lorsque plusieurs groupes d'entrées corréclées appliquent la même matrice de coefficients de corrélation. L'argument instance est un nombre entier ou une chaine. Toutes les entrées d'un groupe corrélé partagert la valeur ou chaine d'instance. Les chânes représentant l'argument instance doivent être introduites entre guillemets.La fonction RiskCormat générale des ensembles de nombres aléatoires corréclés à utiliser dans l'échantillonnage de chacune des fonctions de distribution corréclées. La matrice de coefficients de corrélation des rangs type calculée sur l'ensemble de nombres aléatoires corréclés se rapproche autant que possible, par approximation, de la matrice de coefficients de corrélation cible entrée dans la feuille de calcul.Les ensembles de nombres aléatoires corréclés spécifiés par la fonction RiskCormat sont générés à l'appoint de la première fonction RiskCormat en cours de simulation, généralement au cours de la première iteration. Il peut en résultat un certain décalimable imputable au tri et à la corrélation des valeurs. Le décalin nécessaire est proportionnel au nombre d'iterations et au nombre de variables corréclées.La méthode utilisée pour générer des fonctions de distribution corréclées par rangs multiples repose sur celle des fonctions DEPC et INDEPC. Pour tous détails relatifs à ces fonctions, reportez-vous à la section Étude des valeurs de coefficient de corrélation des rangs sous la fonction DEPC dans cette section.L'entrée de fonctions CORRMAT en dehors d'une fonction de distribution (sous |
| la forme RiskCorrmat+fonction de distribution), selon la méthode applicable aux versions antérieures de @RISK, est always mise en charge. Ces fonctions sont toutes déplacées à l'intérieur de la fonction de distribution qu'elles affectent lors de la révision de la formule ou de la distribution corréilée dans la fenêtre @RISK — Modèle. | |
| Exemples | RiskNormal(10;10; RiskCorrmat(C10:G14;1;"Matrice 1")) spécifie que l'échantillonnage de la distribution Normal(10;10) sera régi par la première colonne de la matrice 5 x 5 des valeurs de coefficients de corrélation définie dans la plage de cellules C10:G14. La matrice représentée cinq distributions corrélées, car elle compte cinq colonnes. Les coefficients utilisés dans la corrélation de la fonction Normal(10;10) avec les quatre autres distributions corrélées se trouvent sur la ligne 1 de la matrice. La distribution — Normal(10;10) — sera corrélée avec les autres distributions dont les fonctions RiskCorrmat incorporeés stipulent l'instance Matrice 1. |
| Directives | Plusieurs matrices de coefficients de corrélation sont admises dans une même feuille de calcul.La matrice de coefficients de corrélation type (calculée sur les nombres aléatoires corrélés généres par @RISK) se rapproche autant que possible, par approximation, de la matrice de coefficients de corrélation cible entrée dans la plage de cellules de la matrice. Il se peut que les coefficients cibles soient incohérients et que l'approximation ne puisse pas été exécutée. Le cas échéant, @RISK en envisage leutilisateur.Toutes les cellules ou étiquettes vierges de la plage de cellules de la matrice spécifique un coefficient de corrélation nul (zéro).La position peut être une valeur comprise entre 1 et N, où N représentée le nombre de colonnes de la matrice.La plage de cellules de la matrice doit être carrée : elle doit comprendre un nombre égal de lignes et de colonnes.Par défaut, @RISK utilise les coefficients de corrélation de la plage de cellules de la matrice sur la base des lignes. Par conséquent, seule la « moitié » supérieure de la matrice — la partie supérieure droite de la matrice quand elle est fractionnée sur la diagonale — doit être entrée.Les coefficients de corrélation doivent être inférieurs ou égaux à 1 et supérieurs ou égaux à -1. Les coefficients de la diagonale de la matrice doivent être égaux à 1.Une matrice de pondérations d'ajustement peut être définie dans Excel pour gérer l'ajustement des coefficients au cas où une matrice de corrélation entrée serait incohérique. Cette matrice (1) reçoit un nom de plage Excel identique à celui de la matrice de corrélation correspondante, plus l'extension _Pondérations et (2) comporte le même nombre d'éléments que la matrice de corrélation correspondante. Les cellules de la matrice des pondérations d'ajustement admettant les valeurs 0 à 100 (une cellule blanche = 0). La pondération 0 indique que le coefficient de la matrice de corrélation correspondante peut être ajusté autant que nécessaire lors de la correction de la matrice, et la pondération 100 signifie que le coefficient correspondant est fixe. Les valeurs comprises entre ces deux extrêmes permettent une variation proportionnelle du coefficient. |
| Description | RiskDepC(ID; coefficient) désigne une variable dépendante dans une paire d'échantillonnage corrélée. ID représentée la chaîne d'identification de la variable indépendante de correlation. La chaîne doit être entre guillemets. Il s'agit du même identificateur ID que celui utilisé dans la fonction RiskIndepC pour la variable indépendante. Le coefficient entre est le coefficient de corrélation des rangs qui déscrit la relation entre les valeurs échantillonnées pour les distributions identifiées par les fonctions RiskDepC et RiskIndepC. La fonction RiskDepC est utilisée avec la fonction de distribution qui spécifie les valeurs possibles de la variable dépendante. Étude des valeurs de coefficient de corrélation des rangs La notion de coefficient de corrélation des rangs a été conçue par C. Spearman au début des années 1900. Ce coefficient se calcule par classements des valeurs, et non au moyen des valeurs propres (contrairement au coefficient de corrélation linéaire). Le « rang » d'une valeur est déterminé par sa position dans la plage min-max des valeurs possibles de la variable. Le coefficient est une valeur comprise entre -1 et 1 ; il représenté le degré de corrélation désiré entre les deux variables lors de l'échantillonnage. Les valeurs de coefficient positives indiquent une relation positive entre les deux variables : quand la valeur échantillonnée pour l'une est élevé, celle échantillonnée pour l'autre l'est généralement aussi. Les valeurs de coefficient négatives indiquent une relation inverse entre les deux variables : quand la valeur échantillonnée pour l'une est élevé, celle échantillonnée pour l'autre est généralement faible. @RISK générale des paires de valeurs échantillonnées corréclées par rang en un processus à deux étapes. Dans un premier temps, un ensemble de « cotes de rang » distribuées au hasard est généré pour chaque variable. Si, par exemple, 100 itérations doivent être exécutées, 100 cotes sont générées pour chaque variable. (Les cotes de rang sont simplement des valeurs de grandeur variant entre un minimum et un maximum. @RISK utilise les cotes de Van Der Waerden basées sur la fonction inverse de la distribution normale). Ces cotes de rang sont ensuite réorganises pour développer des paires de cotes qui générent le coefficient de corrélation des rangs souhaïte. Il existe une paire de cotes pour chaque iteration, avec une cote pour chaque variable. Dans un deuxième temps, un ensemble de nombres aléatoires (compris entre 0 et 1) à utiliser dans l'échantillonnage est généré pour chaque variable. L'à encore, si 100 itérations doivent être exécutées, 100 nombres aléatoires sont générés pour chaque variable. Ces nombres aléatoires sont ensuite classés par ordre de rang croissant. Pour chaque variable, le plus petit nombre aléatoire est utilisé dans l'iteration associée à la plus petite cote de rang, le plus petit nombre aléatoire suivant est utilisé dans l'iteration associée à la plus petite cote de rang suivante, et ainsi de suite. Cet arrangement basé sur le classement par ordre de rang continue pour tous les nombres aléatoires, jusqu'à ce que le plus grand soit utilisé dans l'iteration dotée de la plus grande cote de rang. Dans @RISK, ce processus de réorganisation des nombres aléatoires se produit avant la simulation. Il donne pour résultat un ensemble de paires de nombres aléatoires pouvant être utilisés dans l'échantillonnage des valeurs des distributions corréclées à chaque itération de la simulation. Cette méthode de corrélation est qualifiée d'approche « indépendante de la distribution», car tous les types de distribution peuvent être corrélés. Bien que |
| les échantillons tirés pour les deux distributions soient corrélés, l'intégrité des distributions originales est conservée. Les échantillons qui en résultat pour chaque distribution reflèvent la fonction de distribution en entrée dont ils sont tirés.Dans les versions antérieures de @RISK, la fonction RiskDepC se plaçait dans la formule de la cellule, juste avant la fonction de distribution à corréler. Par exemple :=RiskDepC("Prix 1";0,9)+RiskNormal(10;10)Les fonctions entées sous cette forme sont toujours reconnues. Ces fonctions sont toutes déplacées à l'intérieur de la fonction de distribution qu'elles affectent lors de la révision de la formule ou de la distribution corrélée dans la fenêtre @RISK — Modèle.Le coefficient de correlation généra le aide des fonctions RiskDepC et RiskIndepC est approximatif. Le degré d'approximation du coefficient généra par rapport au coefficient désiré est directement proportionnel au nombre d'iterations exécutées. Un retard peut survenir au début de la simulation lorsque les fonctions RiskDepC et RiskIndepC sont utilisées pour corréler des distributions. Sa durée est proportionnelle au nombre de fonctions RiskDepC de la feuille de calcul et au nombre d'iterations à exéctuer. Reportez-vous au chapitre Techniques de modélisation @RISK pour un exemple détaillé des relations de dépendance. | |
| Exemples | RiskNormal(100;10; RiskDepC("Prix";0,5)) spécifique que l'échantillonnage de la distribution RiskNormal(100;10) sera corréle à celui de la distribution identifiée par la fonction RiskDepC("Prix";0,5). L'échantillonnage de la distribution RiskNormal(100;10) sera positivement corréle à celui de la distribution identifiée par la fonctionRiskIndepC("Prix")car le coefficient est supérieur à 0. |
| Directives | Le coefficient doit être une valeur supérieure ou égale à -1 et inférieure ou égale à 1. ID doit être la même chaine de caractères que celle utilisée pour identifier la variable indépendante dans la fonction RiskIndepC. ID peut être la référence de la cellule qui contient la chaine d'identification. |
| Description | RiskFit(nom de l'ajustement, résultat d'ajustement sélectionné) lie un ensemble de données et les résultats de son ajustement à la distribution en entrée dans laquelle la fonction RiskFit est utilisée. Le nom de l'ajustementl, entre guillemets, est le nom donné au moment de l'ajustement aux données par la commande Ajuster les distributions aux données. La châne résultat d'ajustement sélectionné, entre guillemets, identifie le type de résultat d'ajustement à Sélectionner. La fonction RiskFit sert àlier une entrée aux résultats d'ajustement d'un ensemble de données, pour permettre la mise à jour de la distribution en entrée sélectionnée en cas de changement affectant ces données.La châne résultat d'ajustement sélectionné peut représentier l'une des entrées suivantes :Meilleure chi carré, pour désigner la(Meilleure distribution identifiée par le test chi carré.Meilleure A-D, pour désigner la excellence distribution identifiée par le test Anderson-Darling.Meilleure K-S, pour désigner la excellence distribution identifiée par le test Kolmogorov-Smirnov.Meilleure Err moy quad, pour désigner la excellence distribution identifiée par le test d'erreur de la moyenne quadratique.Un nom de distribution ("Normal", par exemple), pour désigner la excellence distribution ajustée du type spécifique.RiskFit et changements affectant les donnéesLe fonction RiskFit établit un lien direct entre une fonction de distribution, un ensemble de données et l'ajustement à cet ensemble. Les données utilisées pour l'ajustement sont celles d'une plage Excel. Lorsque les données soumises à l'ajustement changent et qu'une simulation est exécutée, il se produit ceci :@RISK réexécute l'ajustement conformément aux paramètres courants de l'onglet d'ajustement de l'ajustement original.La fonction de distribution assortedie de la fonction RiskFit de référence à l'ajustement reflète les résultats du nouvelajustement. La fonction ainsi modifiée remplace la fonction originale dans Excel. Par exemple, si l'argument RiskFit de la fonction de distribution spécifique Meilleure chi carré comme résultat d'ajustement sélectionné, la nouvelle distribution identifiée comme optimale par le test Chi carré viendrait replacer la distribution originale. Cette nouvelle fonction incluait aussi la même fonction RiskFit que la distribution originale.Examples | RiskFit(nom de l'ajustement, résultat d'ajustement sélectionné) lie un ensemble de données et les résultats de son ajustement à la distribution en entrée dans laquelle la fonction RiskFit est utilisée. Le nom de l'ajustementl, entre guillemets, est le nom donné au moment de l'ajustement aux données par la commande Ajuster les distributions aux données. La châne résultat d'ajussement, entre guillemets, identifie le type de résultat d'ajustement à Sélectionner. La fonction RiskFit sert àlier une entrée aux résultats d'ajustement d'un ensemble de données, pour permettre la mise à jour de la distribution en entrée sélectionnée en cas de changement affectant ces données.La châne résultat d'ajustement sélectionné peut représentier l'une des entrées suivantes :MeilleURE chi carré, pour désigner la excellence distribution identifiée par le test chi carré.Meilleure A-D, pour désigner la excellence distribution identifiée par le test Anderson-Darling.Meilleure K-S, pour désigner la excellence distribution identifiée par le test Kolmogorov-Smirnov.Meilleure Err moy quad, pour désigner la excellence distribution identifiée par le test d'erreur de la moyenne quadratique.Un nom de distribution ("Normal", par exemple), pour désigner la excellence distribution ajustée du type spécifique.RiskFit et changements affectant les donnéesLe fonction RiskFit établit un lien direct entre une fonction de distribution, un ensemble de données et l'ajustement à cet ensemble. Les données utilisées pour l'ajustement sont celles d'une plage Excel. Lorsque les données soumises à l'ajustement changent et qu'une simulation est exécutée, il se produit ceci :©RISK réexécute l'ajustement conformément aux paramètres courants de l'onglet d'ajustement de l'ajustement original.La fonction de distribution assortedie de la fonction RiskFit de référence à l'ajustement reflète les résultats du nouvelajustement. La fonction ainsi modifiée remplace la fonction originale dans Excel. Par exemple, si l'argument RiskFit de la fonction de distribution spécifique Meilleure chi carré comme résultat d'ajustement sélectionné, la nouvelle distribution identifiée comoeme optimale par le test Chi carré viendrait replacer la distribution originale. Cette nouvelle fonction incluait aussi la même fonction RiskFit que la distribution originale.RiskNormal(2,5; 1; RiskFit("Données de prix"; "Meilleure A-D")) spécifique que la excellente distribution identifiée par le test Anderson-Darling pour les données associées à l'ajustement « Données de prix » est une distribution normale à moyenne de 2,5 et écart type de 1. |
| Directives | Aucune. |
RiskIndepC
| Description | RisikIndepC(ID) désigne la variable indépendante d'une paire d'échantillonnage corrélée par rang. ID représentée la chaîne d'identification de la variable indépendante. La fonction RisikIndepC s'utilise avec la fonction de distribution qui spécifie les valeurs possibles de la variable indépendante. RisikIndepC est simplement un identificateur. Dans les versions antérieures de @RISK, la fonction RisikIndepC se plaçait dans la formule de la cellule, juste avant la fonction de distribution à corréler. Par exemple : =RisikIndepC("Prix 1")+RiskNormal(10;10) Les fonctions entrées sous cette forme sont toujours reconnues. Ces fonctions sont toute fois déplacées à l'intérieur de la fonction de distribution qu'elles affectent lors de la révision de la formule ou de la distribution corrélée dans la fenêtre @RISK — Modèle. |
| Examples | RiskNormal(10;10; RisikIndepC("Prix")) identifie la fonction NORMAL(10;10) comme variable indépendante "Prix". Cette fonction sort de variable indépendante à chaque utilisation d'une fonction DEPC assorted de la chaîne ID "Prix". |
| Directives | ID doit être identique à la chaîne de caractères utilisée pour identifier la variable dépendante dans la fonction DEPC. ID doit être identique à la chaîne de caractères utilisée pour identifier la variable indépendante dans la fonction INDEPC. ID peut être la référence de la cellule qui contient la chaîne d'identification. Un maximum de 64 fonctions INDEPC individuelles est admis dans une feuille de calcul. Un nombrequelconque de fonctions DEPC peuvent être dépendantes de ces fonctions INDEPC. Voir le chapitre Techniques de modélisation @RISK pour un exemple détaillé des relations de dépendance. |
RiskIsDiscrete
| Description | RisksDiscrete(VRAI) Spécifie que la sortie pour laquelle cette fonction est définie doit être traitée comme une distribution discrète lors de l'affichage des graphiques de résultats de simulation et le calcul des statistiques. En l'absence de RisksDiscrete, @RISK essaire de détecter quand une sortie représentée une distribution de valeurs discrètes. |
| Examples | RiskOutput(;;;RisksDiscrete(VRAI))+VAN(0,1;C1:C10) spécifie que la distribution de sortie de VAN sera une distribution discrète. |
| Directives | Aucune. |
RiskIsDate
| Description | RisksDate(VRAI ou FAUX) spécifique que l'entrée ou la sortie pour laquelle cette fonction est définie doit être traitée comme une distribution de dates lors de l'affichage des graphiques de résultats de simulation et le calcul des statistiques. En l'absence de RisksDate, @RISK se refère au format de la cellule Excel de l'entrée ou de la sortie pour identifier les distributions de dates. |
| Examples | RiskOutput(;;;RiskIsDate(VRAI)) spécifique que la distribution de sortie s'affichera au format dates, indépendamment du formatage Excel. |
| Guidelines | RisksDate(FAUX) fait afficher les graphiques et rapportes de l'entrée ou de la sortie sous forme de valeurs, pas de dates, même si la cellule Excel correspondante est au format date. |
RiskLibrary
| Description | RiskLibrary(position; ID) spécifique que la distribution pour laquelle elle est entrée est liée à une distribution de la Bibliothèque @RISK à la position et sous l'ID indiqués. À chaque simulation, la fonction de distribution s'actualisa en fonction de la définition courante de la distribution dans la Bibliothèque @RISK sous l'ID indiqué. |
| Examples | RiskNormal(5000;1000;RiskName("Volume des ventes / 2010");RiskLibrary(2,"LV6W59J5");RiskStatic(0,46)) spécifique que la distribution entree provient de la Bibliothèque @RISK, à la position 2 et sous l'ID LV6W59J5. La définition courante de cette distribution de bibliothèque est RiskNormal(10;10;RiskName("Volume des ventes / 2010"). Cette définition pourrait cependant changer si la distribution change dans la bibliothèque. |
| Directives | Les valeurs RiskStatic ne s'actualisent pas depuis la Bibliothèque @RISK : elles sont uniques au modèle où la distribution de bibliothèque est utilisée. |
RiskLock
| Description | RiskLock() empêche l'échantillonnage d'une distribution lors d'une simulation. La distribution en entrée ainsi verrouillée renvoie la valeur définie à travers les options de recalcul standard des Paramètres de simulation. |
| Examples | RiskNormal(10;2;RiskLock()) empêche l'échantillonnage de la distribution de probabilités RiskNormal(10;2). |
| Directives | L'argument facultatif Mode_verrouillage est un argument @RISK interne non accessible aux utilisateurs dans la fenêtre @RISK Définir une distribution. |
RiskName
| Description | RiskName(nom d'entrée) nomme la distribution en entrée dans laquelle elle est introduite comme argument. Le nom indiqué figurera dans les listes de sorties et d'entrées de la fenêtre @RISK — Modèle, ainsi que dans tous les rapports et graphiques incluant les résultats de simulation de l'entrée. |
| Exemples | RiskTriang(10;20;30;RiskName("Prix")) donne le nom Prix à l'entrée décrite par la distribution de probabilités RiskTriang(10;20;30).RiskTriang(10;20;30;RiskName(A10)) donne le nom contenu dans la cellule A10 à l'entrée décrite par la distribution de probabilités RiskTriang(10;20;30). |
| Directives | Le nom d'entrée doit être définie entre guillemets. Le nom peut être définie par une référence de cellule valable. |
RiskSeed
| Description | RiskSeed(type de générateur de nombres aléatoires; valeur de départ) spécifique qu'une entrée utiliser sa propre générateur de nombres aléatoires, du type indiqué, à partir de la valeur de départ indiquée. La désignation de la racine d'une entrée individuelle est utile quand plusieurs modèles partagent une même distribution de la Bibliothèque @RISK et qu'un ensemble d'échantillons reproductible est désiré pour l'entrée de chaque modèle. |
| Exemples | RiskBeta(10;2;RiskSeed(1;100)) spécifique que l'entrée RiskBeta(10;2) va utiliser son propre générateur de nombres aléatoires Mersenne Twister avec, comme valeur de départ, la racine 100. |
| Directives | Les distributions en entrée assorties de RiskSeed ont toujours leur propre flux reproductible de nombres aléatoires. La valeur de départ initiale configurée sous l'onget Échantillonnage des Paramètres de simulation n'acte que les nombres aléatoires générés pour les distributions en entrée sans racine indépendante spécifique par la fonction de propriété RiskSeed. Le type de générateur de nombres aléatoires se spécifique par une valeur comprise entre 1 et 8, où 1=MersenneTwister, 2=MRG32k3a, 3=MWC, 4=KISS, 5=LFIB4, 6=SWB, 7=KISS_SWB et 8=RAN3I. Pour plus de détails sur les générateurs de nombres aléatoires, voir la commande Paramètres de simulation. La valeur de départ doit être un entier compris entre 1 et 2 147 483 647. |
RiskShift
| Description | La fonction RiskShift(décalage) décale le domaine de la distribution dans laquelle elle est définie de la valeur décalage spécifique. Elle se définit automatiquement lorsqu'un résultat d'ajustement inclut un facteur de décalage. |
| Examples | RiskBeta(10;2;RiskShift(100)) décale le domaine de la distribution RiskBeta(10;2) de 100 . |
| Directives | Aucune . |
RiskSixSigma
| Description | RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types) spécifique la limite de specifications inférieure, la limite de specifications supérieure, la valeur cible, le décalage à long terme et le nombre d'écarts types à considérer dans les calculs six sigma d'une sortie. Ces valeurs seront au calcul des statistiques six sigma affichées dans la fenêtre des résultats et sur les graphiques de la sortie. |
| Exemples | RiskOutput(A10;;;RiskSixSigma(0,88;0,95;0,915;1,5;6)) spécifique une LSI de 0,88, une LSS de 0,95, une valeur cible de 0,915, un décalage à long terme de 1,5 et un nombre d'écarts types de 6 pour la sortie situées dans la cellule A10. |
| Directives | Par défaut, les fonctions statistiques six sigma @RISK dans Excel utilisant les valeurs LSI, LSS, cible, de décalage à long terme et de nombre d'écarts types entrées dans la fonction de propriété RiskSixSigma pour une entrée ( quand la fonction statistique fait ↔reference à la sortie). Ces valeurs peuvent être replacées par l'entrée directe des LSI, LSS, cible, décalage long terme et nombre d'écarts types dans la fonction statistique. Les valeurs entrées pour une sortie dans la fonction de propriété RiskSixSigma sont lues au démarrage d'une simulation. Si vous changez les valeurs de la fonction de propriété, il vous faudra réexécuter la simulation pouractualiser les statistiques six sigma affichées dans la fenêtre des résultats et sur les graphiques de la sortie. |
RiskStatic
| Description | RiskStatic(valeur statique) définit la valeur statique 1) renvoyée par la fonction de distribution lors d'un recalcul Excel standard et 2) qui remplace la fonction @RISK désactivée par permutation. |
| Examples | RiskBeta(10;2;RiskStatic(9,5)) spécifique que la valeur statique de la fonction de distribution RiskBeta(10;2) sera 9,5. |
| Directives | Aucune. |
| Description | La fonction RiskTruncate(minimum; maximum) tronque la distribution en entrée dans laquelle elle est introduite comme argument. L'échantillonnage de la distribution est ainsi limité à la plage minimum-maximum spécifique. Les formules de distribution tronquées utilisées dans les versions antérieures de @RISK (RiskTnormal et RiskTlognorm, par exemple) sont toujours reconnues. |
| Exemples | RiskTriang(10;20;30;RiskTruncate(13;27)) limite l'échantillonnage de la distribution de probabilités RiskTriang(10;20;30) à une valeur minimum possible de 13 et une valeur maximum possible de 27. RiskTriang(10;20;30;RiskTruncate(D11;D12)) limite l'échantillonnage de la distribution de probabilités RiskTriang(10;20;30) à la valeur minimum possible définie dans la cellule D11 et à la valeur maximum possible définie dans la cellule D12. |
| Directives | La valeur minimum doit être inférieure ou égale à la valeur maximum. Pour entraître une distribution tronquée d'un côte seulement, lissez l'argument du côte non limité blanc, comme dans RiskNormal(10;1;RiskTruncate(5:)). La valeur minimum est ainsi fixée à 5, tandis que la valeur maximum est illimitée. |
| Description | RiskTruncateP(centile minimum; centile maximum) tronque la distribution en entrée dans laquelle la fonction est introduite comme argument. L'échantillonnage de la distribution est ainsi limité à la plage minimum-maximum spécifique. Les formules de distribution tronquées utilisées dans les versions antérieures de @RISK (RiskTnormal et RiskTlognorm, par exemple) sont toujours reconnues. |
| Examples | RiskTriang(10;20;30;RiskTruncate(0,01;0,99)) limite l'échantillonnage de la distribution de probabilités RiskTriang(10;20;30) à la valeur minimum possible du 1er centile de la distribution et la valeur maximum possible du 99e centile. RiskTriang(10;20;30;RiskTruncate(D11;D12)) limite l'échantillonnage de la distribution de probabilités RiskTriang(10;20;30) à la valeur de centile minimum possible de la cellule D11 et à la valeur de centile maximum possible de la cellule D12. |
| Directives | La valeur centile minimum doit être inférieure ou égale à la valeur centile maximum. Les valeurs centile minimum et centile maximum doivent être comprises dans la plage 0<=centile<=1. Les fonctions de distribution qui contiennent la fonction de propriété RiskTruncateP ne s'affichent pas dans la fenêtre Définir une distribution. Comme dans le cas de RiskTruncate, pour entrer une distribution tronquée d'un côte seulement, il suffit de laisser l'argument du côte non limité blanc. |
RiskUnits
| Description | RiskUnits(unités) désigne les unités à utiliser dans l'étiquetage d'une distribution en entrée ou d'une sortie. Le nom indiqué figurera dans les listedes de sorties et d'entrées de la fenêtre @RISK — Modèle, ainsi que dans tous les rapports et graphiques incluant les résultats de simulation de l'entrée ou de la sortie. |
| Examples | RiskTriang(10;20;30;RiskUnits("Euros")) donne le nom Euros à l'entrée décrite par la distribution de probabilités RiskTriang(10;20;30). RiskTriang(10;20;30;RiskUnits(A10)) donne le nom contenu dans la cellule A10 aux unités décrites par la distribution de probabilités RiskTriang(10;20;30). |
| Directives | Le paramètre unités doit être définie entre guillemets. Le nom unités peut être définie par une reférence de cellule valable. Si RiskUnits est introduite comme fonction de propriété d'une fonction RiskOutput, elle doit l'être après les trois arguments possibles de RiskOutput. Ainsi, si vous introduisez une fonction RiskOutput sans arguments de nom, plage ou position, ne manque pas de suivre la syntaxe RiskOutput(;;RiskUnits("MesUnités")) |
Référence : fonctions de sortie
Les cellules de sortie se définissent à l'aide des fonctions RiskOutput. Ces fonctions permettent de copier, coller et déplacer les cellules de sortie en toute simplicité. Elles s'ajoutent automatiquement à la feuille de calcul sur invocation de l'icône @RISK Ajouter une sortie. Elles permettent facultativement de nommer les sorties de simulation et d'ajouter des cellules de sortie individuelles aux plages de sortie.
Les fonctions RiskOutput peuvent être associées aux fonctions de propriété RiskUnits, RiskConvergence, RiskSixSigma et RiskIsDiscrete.
RiskOutput
| Description | La fonction RiskOutput sortà identifier les cellules de sortie sélectionnées dans la feuille de calcul. Elle admet les trois arguments suivants :=RiskOutput ("nom de la cellule de sortie"; "nom de la plage de sortie"; n° d'élement dans la plage) Ces arguments sont facultatifs. La simple formule =RiskOutput() suffit à l'entrée d'une plage de sortie à élément unique dont @RISK définit automatiquement le nom de sortie. Sous la forme à argument unique =RiskOutput ("nom de la cellule de sortie") RiskOutput spécifique une plage de sortie à élément unique dont vous définissez vous-même le nom. Si une plage de sortie à éléments multiples est identifiée, la formule =RiskOutput ("nom de la cellule de sortie"); "nom de la plage de sortie"; position dans la plage)s'imposer. Le nom de la cellule de sortie peut toutes être omis si vous préférez que @RISK nomme automatiquement chaque cellule de la plage. Les fonctions RiskOutput se générent automatiquement à la sélection de sorties au moyen de l'icône @RISK Ajouter une sortie. Comme pour les autres fonctions @RISK, vous pouvez cependant taper directement RiskOutput dans les cellules dont vous désirez faire une sortie de simulation. Il suffit d'ajouter la fonction RiskOutput à la formule déjà présente dans la cellule. Par exemple, une cellule contenant la formule=VAN(0,1;G1...G10)deviendrait=RiskOutput()+VAN(0,1;G1...G10)une fois sélectionnée comme sortie. |
| Examples | =RiskOutput("Profit 1999"; "Bénéfices annuels"); 1)+VAN(0,1;G1...G10) fait de la cellule dans laquelle la fonction RiskOutput est introduite une sortie de simulation intituatede Profit 1999, qu'elle désigne ensuite comme première cellule d'une plage intitulée Bénéficies annuels. |
| Directives | Les noms de cellule et de plage de sortie définis directement dans la fonction RiskOutput doivent l'être entre guillemets. Ces noms peuvent aussi être inclus par référence aux cellules d'étiquettes correspondantes.L'argument Position doit être un nombre entier supérieur ou égal à 1.Les fonctions de propriété évientuèlement introduites doivent l'être après les trois premiers arguments de la fonction RiskOutput. Ainsi, pour ajouter la fonction de propriété RiskUnits à une fonction RiskOutput par défaut, voirlez à suivre la syntaxe =RiskOutput(;;RiskUnits("MesUnités"))Si vous utilisez RiskOutput avec une fonction de propriété telle que RiskSixSigma, les arguments de la fonction de propriété utilisée sont décrit sous le titre Fonctions de propriété de cette section du guide de réseau. Si la commande d'insertion de fonction @RISK est utilisée pour entrer RiskOutput au format Six Sigma, cliquez simplement sur la barre de formule de la fonction de propriété RiskSixSigma affichée pour entrer ses arguments ou pour consulter l'aide relative à cette fonction. |
Référence : fonctions statistiques
Les fonctions statistiques reçoivent la statistique demandée sur les résultats d'une simulation, pour 1) une cellule spécifiée ou 2) une sortie ou une entrée de simulation. Ces fonctions s'actualisent en temps réel, en cours d'exécution de la simulation. Les fonctions statistiques définies dans les masques de rapports de résultats personnalisés ne s'actualisent qu'en fin de simulation.
Si une référence de cellule est spécifiée comme premier argument, la cellule ne doit pas être une sortie de simulation identifiée par une fonction RiskOutput.
Si un nom particulier est entré au lieu d'une référence de cellule, @RISK commence par rechercher une sortie désignée par ce nom. En l'absence d'une telle sortie, @RISK recherche une distribution de probabilités en entrée désignée sous ce nom et renvoie, le cas échéant, la statistique demandée pour les échantillons tirés de cette entrée. Il vous incombe d'assurer la désignation sous un nom unique des sorties et entrées référencées dans les fonctions statistiques.
L'argument Sim sélectionne la simulation pour laquelle la statistique est renvoyée lors de l'exécution de simulations multiples. Cet argument est facultatif. Il peut être omis pour les exécutions à simulation unique.
Calculs statistiques sur un sous-ensemble de distribution
Les fonctions statistiques qui calculent une statistique sur une distribution pour un résultat de simulation peuvent être assorties d'une fonction de propriété RiskTruncate ou RiskTruncateP. Le calcul de la statistique se limite alors à la plage min-max spécifique par les limites de troncation.
Actualiser les fonctions statistiques
Les fonctions statistiques de @RISK peuvent être actualisées soit 1) en fin de simulation, soit 2) à chaque iteration d'une simulation. Dans la plupart des cas, il n'est pas nécessaire d'actualiser les statistiques avant la fin de la simulation et l'affichage des statistiques finales dans Excel. Si les calculs du modèle exigent cependant le renvoi d'une nouvelle statistique à chaque iteration (pour un calcul de convergence défini à l'aide de formules Excel, par exemple), il convient de sélectionner l'option À chaque iteration. Cette option se configure dans la boîte de dialogue Paramètres de simulation, sous le titre Actualiser les fonctions statistiques de l'onglet Echantillonnage.
Remarque: À partir de la version @RISK 5.5, le paramètre d'actualisation des fonctions statistiques est réglé, par défaut, sur fin de simulation.
| Description | RiskConvergenceLevel(réf_cell ou nom sortie; n°sim) renvoie le niveau de convergence (0 à100) pour réf_cell ou nom sortie. La convergence renvoie VRAI. |
| Examples | RiskConvergenceLevel(A10) renvoie le niveau de convergence pour la cellule A10. |
| Directives | Une fonction de propriété RiskConvergence doit être définie pour réf_cell ou nom sortie, ou la surveillance de convergence doit être activée dans la boîte de dialogue Paramètres de simulation pour que cette fonction renvoie un niveau de convergence. |
| Description | RiskCorrel( ref_cell1 ou nom de sortie/entree1; ref_cell2 ou nom de sortie/entree2; type_corrélation; n° sim) renvoie le coefficient de correlation selon le type de corrélation type_corrélation pour les données des distributions simulées de ref_cell1 ou nom de sortie/entree1 et ref_cell2 ou nom de sortie/entree2 à la simulation n° sim. Type_corrélation est soit Pearson, soit Ranges de Spearman. |
| Examples | RiskCorrel(A10;A11;1) renvoie le coefficient de correlation Pearson pour les données de simulation recueillies pour la sortie ou l'entrée des cellules A10 et A11.RiskCorrel("Profit"; "Ventes", 2) renvoie le coefficient de correlation Ranges de Spearman pour les données de simulation recueillies pour la sortie ou l'entrée des cellules « Profit » et « Ventes » . |
| Guidelines | L'argument Type_corrélation est 1 pour la correlation Pearson ou 2 pour Ranges de Spearman.Toutes les iterations contenant ERR ou filtrées dans ref_cell1 ou nom de sortie/entree1 et ref_cell2 ou nom de sortie/entree2 sont éliminées. Le coefficient de correlation est calculé en fonction des données restantes.Pour calculator les correlations d'un sous-ensemble des données recueillies pour les distributions simulées, entrez une fonction de propriété RiskTruncate ou RiskTruncateP pour chaque distribution dont les données doivent être tronquées. La première fonction RiskTruncate entée s'applique aux données de ref_cell1 ou nom de sortie/entree1, et la seconde, à celles de ref_cell2 ou nom de sortie/entree2 . |
RiskData
| Description | RiskData(rik_cell ou nom sortie/entree; n°它是ation; n°sim) renvoie le/s point/s de données de la distribution simulée pourrik_cell à l'iteration n°它是ation et à la simulation n° sim. RiskData peut, facultativement, êtredéfinie sous forme de formule matricielle ou n°它是ration désigné la première itération à renvoyer dans la première cellule de la plage de la formule matricielle. Les points de données de chaque它是ration ultérieure s'inscrivent dans les cellules de la plage occupée par la formule matricielle. |
| Examples | RiskData(A10;1) renvoie le point de données de la distribution simulée pour la cellule A10 à l'iteration n° 1 d'une simulation.RiskData("Profit";100;2) renvoie le point de données de la distribution simulée pour la cellule de sortie intitulée « Profit » dans le modèle courant, à la 100e itération de la deuxieme simulation exécutée en présence de plusieurs simulations. |
| Directives | Aucune. |
RiskKurtosis
| Description | RiskKurtosis( ref_cell ou nom sortie/entree; n° sim) renvoie l'aplaitissement de la distribution simulée pour la cellule ref_cell. La fonction de propriété RiskTruncate permet, facultativement, de spécifique la plage de la distribution simulée sur laquelle la statistique doit être calculée. |
| Examples | RiskKurtosis(A10) renvoie l'aplaitissement de la distribution simulée pour la cellule A10. RiskKurtosis("Profit";2) renvoie l'aplaitissement de la distribution simulée pour la cellule de sortie intitulée « Profit » dans le modele courant, à la deuxieme simulation d'une série de simulations multiples. |
| Directives | Aucune. |
RiskMax
| Description | RiskMax(rik_cell ou nom sortie/entree; n° sim) renvoie la valeur maximum de la distribution simulée pour la cellulerik_cell. La fonction de propriété RiskTruncate permet, facultativement, de spécifique la plage de la distribution simulée sur laquelle la statistique doit être calculée. |
| Examples | RiskMax(A10) renvoie la valeur maximum de la distribution simulée pour la cellule A10.RiskMax("profit") renvoie la valeur maximum de la distribution simulée pour la cellule de sortie intitulée « Profit » dans le modele courant. |
| Directives | Aucune. |
RiskMean
| Description | RiskMean(rik_cell ou nom sortie/entree; n° sim) renvoie la valeur moyenne de la distribution simulée pour la cellulerik_cell. La fonction de propriété RiskTruncate permet, facultativement, de spécifique la plage de la distribution simulée sur laquelle la statistique doit être calculée. |
| Examples | RiskMean(A10) renvoie la valeur moyenne de la distribution simulée pour la cellule A10.RiskMean("Prix") renvoie la valeur moyenne de la distribution simulée pour la cellule de sortie intitulée « Prix » . |
| Directives | Aucune . |
RiskMin
| Description | RiskMin( réf_cell ou nom sortie/entree; n° sim) renvoie la valeur minimum de la distribution simulée pour la cellule réf_cell. La fonction de propriété RiskTruncate permet, facultativement, de spécifique la plage de la distribution simulée sur laquelle la statistique doit être calculée. |
| Examples | RiskMin(A10) renvoie la valeur minimum de la distribution simulée pour la cellule A10. RiskMin("Ventes") renvoie la valeur minimum de la distribution simulée pour la cellule de sortie intitulée « Ventes » dans le modele courant. |
| Directives | Aucune. |
RiskMode
| Description | RiskMode( refin_cell ou nom sortie/entrée; n° sim) renvoie le mode de la distribution simulée pour la cellule refin_cell. La fonction de propriété RiskTruncate permet, facultativement, de spécifique la plage de la distribution simulée sur laquelle la statistique doit être calculée. |
| Examples | RiskMode(A10) renvoie le mode de la distribution simulée pour la cellule A10. RiskMode("Ventes") renvoie le mode de la distribution simulée pour la cellule de sortie intitulée « Ventes » dans le modèle courant. |
| Directives | Aucune. |
| Description | RiskPercentile(réf_cell ou nom sortie/entree; centile; n° sim) ou RiskPtoX(réf_cell ou nom sortie/entree; centile; n° sim) renvoie la valeur du centile spécifique de la distribution simulée pour la cellule réf_cell. La fonction de propriété RiskTruncate permet, facultativement, de spécifique la plage de la distribution simulée sur laquelle la statistique doit être calculée. |
| Exemples | RiskPercentile(C10;0,99) renvoie le 99e centile de la distribution simulée pour la cellule C10. RiskPercentile(C10;A10) renvoie la valeur de centile de la cellule A10 de la distribution simulée pour la cellule C10. |
| Directives | Le centile spécifique doit être une valeur supérieure ou égale à 0 et inférieure ou égale à 1. RiskPercentileD et RiskQtoX prenant une valeur de centile cumulative décroissant. RiskPercentile et RiskPtoX (de même que RiskPercentileD et RiskQtoX) représentent simplement deux appellations différentes d'une même fonction. |
RiskRange
| Description | RiskRange( refin_cell ou nom sortie/entree; n° sim) renvoie la plage minimum-maximum de la distribution simulée pour la cellule refin_cell. La fonction de propriété RiskTruncate permet, facultativement, de spécifique la plage de la distribution simulée sur laquelle la statistique doit être calculée. |
| Examples | RiskRange(A10) renvoie la plage de la distribution simulée pour la cellule A10. |
| Directives | Aucune. |
RiskSensitivity
| Description | RiskSensitivity( refin_cell ou nom sortie/entree; n° sim;rang; type analyse; type Valeur renvoi) revoie l'information relative à l'analyse de sensibilité de la distribution simulée pour refin_cell ou nom sortie/entree. L'argument rang spécifique le rang, dans l'analyse de sensibilité, de l'entrée dont les résultats sont désirés : 1 représenté l'entrée la plus importante, du premier rang. L'argument type analyse sélectionne le type d'analyse désiré : 1 pour régression, 2 pour régression — valeurs mappées et 3 pour corrélation. L'argument type Valeur renvoi détermine le type de données à renvoyer : 1 pour nom d'entrée/référence de cellule/fonction de distribution, 2 pour coefficient ou valeur de sensibilité et 3 pour coefficient d'équation (régression seulement). |
| Examples | RiskSensitivity(A10;1;1;1;1) revoie une description de l'entrée de premier rang pour une analyse de sensibilité par régression exécutée sur les résultats de simulation de la cellule A10. |
| Directives | Aucune. |
RiskSkewness
| Description | RiskSkewness(REF_CELL ou nom sortie/entree; n° sim) renvoie l'asymétrie de la distribution simulée pour la cellule REF_CELL. La fonction de propriété RiskTruncate permet, facultativement, de spécifique la plage de la distribution simulée sur laquelle la statistique doit être calculée. |
| Exemples | RiskSkewness(A10) renvoie l'asymétrie de la distribution simulée pour la cellule A10. |
| Directives | Aucune. |
RiskStdDev
| Description | RiskStdDev( réf_cell ou nom sortie/entree; n° sim) renvoie l'écart type de la distribution simulée pour la cellule réf_cell. La fonction de propriété RiskTruncate permet, facultativement, de spécifique la plage de la distribution simulée sur laquelle la statistique doit être calculée. |
| Examples | RiskStdDev(A10) renvoie l'écart type de la distribution simulée pour la cellule A10. |
| Directives | Aucune. |
| Description | RiskTarget(rik_cell ou nom sortie/entree; valeur cible; n° sim) ou RikXtoP(rik_cell ou nom sortie/entree; valeur cible; n° sim) renvoie la probabilité cumulative de valeur cible dans la distribution simulée pour la cellule rik_cell. La probabilité cumulative renvoyée représenté la probabilité de réalisation d'une valeur inférieure ou égale à Valeur cible. La fonction de propriété RiskTruncate permet, facultativement, de spécifique la plage de la distribution simulée sur laquelle la statistique doit être calculée. |
| Exemples | RiskTarget(C10;100000) renvoie la probabilité cumulative de la valeur 100 000, celle que calculée à travers la distribution simulée pour la cellule C10. |
| Directives | Valeur cible peut être une valeurquelconque. RiskTargetD et RiskXtoQ renvoient une probabilité cumulative décroissantante. RiskTarget et RiskXtoP (de même que RiskTargetD et RiskXtoQ) représentent simplement deux appellations différentes d'une même fonction. |
RiskVariance
| Description | RiskVariance(REF_CELL ou nom sortie/entree; n° sim) renvoie la variance de la distribution simulée pour la cellule REF_CELL. La fonction de propriété RiskTruncate permet, facultativement, de spécifique la plage de la distribution simulée sur laquelle la statistique doit être calculée. |
| Examples | RiskVariance(A10) renvoie la variance de la distribution simulée pour la cellule A10. |
| Directives | Aucune. |
RiskTheoKurtosis
| Description | RiskTheoKurtosis( ref_cell ou fonction de distribution) renvoie l'aplaisissement de la première fonction de distribution de la formule contue dans la cellule réf_cell ou la fonction de distribution entrée. |
| Exemples | RiskTheoKurtosis(A10) renvoie l'aplaisissement de la fonction de distribution contue dans la cellule A10. RiskTheoKurtosis(RiskNormal(10;1)) renvoie l'aplaisissement de la distribution RiskNormal(10;1). |
| Directives | Aucune. |
RiskTheoMax
| Description | RiskTheoMax( réf_cell ou fonction de distribution) renvoie la valeur maximum de la première fonction de distribution de la formule contene dans la cellule réf_cell ou de la fonction de distribution entrée. |
| Examples | RiskTheoMax(A10) renvoie la valeur maximum de la fonction de distribution contene dans la cellule A10. RiskTheoMax(RiskNormal(10;1)) renvoie la valeur maximum de la distribution RiskNormal(10;1). |
| Directives | Aucune. |
RiskTheoMean
| Description | RiskyTheoMean(rik_cell ou fonction de distribution) renvoie la valeur moyenne de la première fonction de distribution de la formule contene dans la cellulerik_cell ou de la fonction de distribution entrée. |
| Examples | RiskTheoMean(A10) renvoie la moyenne de la fonction de distribution contene dans la cellule A10.RiskyTheoMean(RiskNormal(10;1)) renvoie la moyenne de la distribution RiskNormal(10;1). |
| Directives | Aucune. |
RiskTheoMin
| Description | RiskTheoMin(rik_cell ou fonction de distribution) renvoie la valeur minimum de la première fonction de distribution de la formule contue dans la cellulerik_cell ou de la fonction de distribution entrée. |
| Examples | RiskTheoMin(A10) renvoie la valeur minimum de la fonction de distribution contue dans la cellule A10.RiskTheoMin(RiskNormal(10;1)) renvoie la valeur minimum de la distribution RiskNormal(10;1). |
| Directives | Aucune. |
RiskTheoMode
| Description | RiskTheoMode( réf_cell ou fonction de distribution) renvoie le mode de la première fonction de distribution de la formule contenue dans la cellule réf_cell ou de la fonction de distribution entrée. |
| Examples | RiskTheoMode(A10) renvoie le mode de la fonction de distribution contenue dans la cellule A10. RiskTheoMode(RiskNormal(10;1)) renvoie le mode de la distribution RiskNormal(10;1). |
| Directives | Aucune. |
| Description | RiskTheoPercentile( ref_cell ou fonction de distribution; centile) ou RiskTheoPtoX( ref_cell ou fonction de distribution; centile) renvoie la valeur au centile spécifique de la première fonction de distribution de la formule containue dans la cellule ref_cell ou de la fonction de distribution entrée. |
| Examples | RiskTheoPtoX(C10;0,99) renvoie le 99° centile de la distribution contenue dans la cellule C10. RiskTheoPtoX(C10;A10) renvoie la valeur de centile de la cellule A10 de la distribution contenue dans la cellule C10. |
| Directives | centile doit être une valeur supérieure ou égale à 0 et inférieure ou égale à 1. RiskTheoXtoQ est équivalente à RiskTheoPtoX (et RiskTheoPercentile à RiskTheoPercentileD) si ce n'est que centile y représentée une valeur cumulative décroissant. RiskTheoPercentile et RiskTheoPtoX (de même que RiskTheoPercentileD et RiskTheoQtoX) représentent simplement deux appellations différentes d'une même fonction. |
| Description | RiskTheoRange(rés_f_cell ou fonction de distribution) renvoie la plage minimum-maximum de la première fonction de distribution de la formule contene dans la cellule rés_f_cell ou de la fonction de distribution entrée. |
| Examples | RiskTheoRange(A10) renvoie la plage de la fonction de distribution contene dans la cellule A10. |
| Directives | Aucune. |
| Description | RiskTheoSkewness( réf_cell ou fonction de distribution) renvoie l'asymétrie de la première fonction de distribution de la formule contue dans la cellule réf_cell ou de la fonction de distribution entrée. |
| Examples | RiskTheoSkewness(A10) renvoie la symétrie de la fonction de distribution contue dans la cellule A10. |
| Directives | Aucune. |
| Description | RiskTheoStdDev( réf_cell ou fonction de distribution) renvoie l'écart type de la première fonction de distribution de la formule contene dans la cellule réf_cell ou de la fonction de distribution entrée. |
| Examples | RiskTheoStdDev(A10) renvoie l'écart type de la fonction de distribution contene dans la cellule A10. |
| Directives | Aucune. |
| Description | RiskTheoTarget( réf_cell ou fonction de distribution; Valeur cible) ou RiskTheoXtoP( réf_cell ou fonction de distribution; valeur cible) renvoie la probabilité cumulative de valeur cible dans la première fonction de distribution de la formule contenue dans la cellule réf_cell ou dans la fonction de distribution entrée. La probabilité cumulative renvoyée représentée la probabilité de réalisation d'une valeur inférieure ou égale à valeur cible. |
| Examples | RiskTheoXtoP(C10;100000) renvoie la probabilité cumulative de la valeur 100 000 telle que calculée à travers la distribution de la cellule C10. |
| Directives | Valeur cible peut être une valeurquelconque.RiskTheoTargetD et RiskTheoXtoQ renvoient une probabilité cumulative décroissanté.RiskTheoTarget et RiskTheoXtoP (de même que RiskTheoTargetD et RiskTheoXtoQ) représentent simplement deux appellations différentes d'une même fonction. |
| Description | RiskTheoVariance(réf_cell ou fonction de distribution) renvoie la variance de la première fonction de distribution de la formule contue dans la cellule réf_cell ou de la fonction de distribution entrée. |
| Examples | RiskTheoVariance(A10) renvoie la variance de la fonction de distribution contue dans la cellule A10. |
| Directives | Aucune. |
Référence : fonctions six sigma
Les fonctions Six Sigma renvoient la statistique Six Sigma désirée sur les résultats d'une simulation pour 1) une cellule spécifiée ou 2) une sortie de simulation. Ces fonctions s'actualisent en temps réel, en cours d'exécution de la simulation. Les fonctions statistiques définies dans les masques de rapports de résultats personnalisés ne s'actualisent qu'en fin de simulation.
Si une référence de cellule est spécifiée comme premier argument, la cellule ne doit pas être une sortie de simulation identifiée par une fonction RiskOutput.
Si un nom particulier est entré au lieu d'une référence de cellule, @RISK commence par rechercher une sortie désignée par ce nom, avant de déduire les paramètres de fonction de propriété RiskSixSigma. Il incombe à l'utilisateur d'assurer la désignation sous un nom unique des sorties référencées dans les fonctions statistiques.
L'argument Sim sélectionne la simulation pour laquelle la statistique est renvoyée lors de l'exécution de simulations multiples. Cet argument est facultatif. Il peut être omis pour les exécutions à simulation unique.
Pour toutes les fonctions statistiques Six Sigma, une fonction de propriété RiskSixSigma facultative peut être introduite directement dans la fonction. @RISK ignore ainsi les paramètres Six Sigma spécifiés dans la fonction de propriété RiskSixSigma entrée dans la sortie de simulation référencée par la fonction statistique, ce qui permet de calculer les statistiques Six Sigma à différentes valeurs LSI, LSS, Cible, Décalage long terme et Nombre d'écarts types pour une même sortie.
Quand une fonction de propriété RiskSixSigma facultative est introduite directement dans une fonction statistiques Six Sigma, différents arguments sont utilisés suivant le calcul effectué.
Pour plus de détails sur @RISK et Six Sigma, consultez le guide spécial installé avec votre exemplaire de @RISK.
| Description | RiskCp( refin_cell ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) calcule la capacité de processus pour refl_cell ou nom sortie à la simulation n° sim, en fonction, facultativement, des LSI et LSS de la fonction de propriété RiskSixSigma incluse. Cette fonction calcule le niveau de qualité de la sortie spécifique et ce qu'elle est potentiellement capable de produitre. |
| Exemples | RiskCP(A10) renvoie la capacité de processus de la cellule de sortie A10. Une fonction de propriété RiskSixSigma doit être entrée dans la fonction RiskOutput de la cellule A10.RiskCP(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie la capacité de processus de la cellule de sortie A10, en fonction d'une LSI de 100 et d'une LSS de 120. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pour refl_cell ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
| Description | RiskCpm( refin_cell ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) renvoie l'indice de capacité Taguchi pour refin_cell ou nom sortie à la simulation n° sim, en fonction, facultativement, des LSI, LSS et Cible de la fonction de propriété RiskSixSigma. Cette fonction est essentiellement identique à Cpk, si ce n'est qu'elle incorpore la valeur cible, parfois extérieur aux limites de specifications. |
| Exemples | RiskCpm(A10) renvoie l'indice de capacité Taguchi pour la cellule A10. RiskCpm(A10; ;RiskSixSigma(100;120;110;0;6)) renvoie l'indice de capacité Taguchi de la cellule de sortie A10, en fonction d'une LSS de 120, d'une LSI de 100 et d'une Cible de 110. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pour refin_cell ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
| Description | RiskCpk( refin_cell ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) calcule l'indice de capacité de processus pour refin_cell ou nom sortie à la simulation n° sim, en fonction, facultativement, des LSI et LSS de la fonction de propriété RiskSixSigma incluse. Cette fonction est similaire à la fonction Cp, si ce n'est qu'elle prend en considération un ajustement de la Cp pour tener compte de l'effect d'une distribution décentrée. Comme formule, Cpk = la plus petite des valeurs (LLS-Moyenne) / (3 x sigma) ou (Moyenne-LSI) / (3 x sigma). |
| Examples | RiskCpk(A10) renvoie l'indice de capacité de processus de la cellule de sortie A10. Une fonction de propriété RiskSixSigma doit être entrée dans la fonction RiskOutput de la cellule A10.RiskCpk(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie l'indice de capacité de processus de la cellule de sortie A10, en fonction d'une LSI de 100 et d'une LSS de 120. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pour refin_cell ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
| Description | RiskCpkLower(réf_cell ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible;Décalage long terme; Nombre d'écarts types)) calcule l'indice de capacitéunilatéral en fonction de la limite de spécification inférieure de réf_cell ou nomsortie à la simulation n° sim, en fonction, facultativement de la LSI spécifiée dans la fonction de propriété RiskSixSigma. |
| Examples | RiskCpkLower(A10) renvoie l'indice de capacité unilatéral basé sur la limite def spécification inférieure de la cellule de sortie A10. Une fonction de propriétéRiskSixSigma doit être entrée dans la fonction RiskOutput de la cellule A10.RiskCpkLower(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie l'indice defcapacité unilatéral de la cellule de sortie A10, en fonction d'une LSI de 100. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pour réf_cell ou nomsortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
| Description | RiskCpkUpper(rik_cell ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Decalage long terme; Nombre d'écarts types)) calcule l'indice de capacité unilatéral en fonction de la limite de specifications supérieure derik_cell ou nom sortie à la simulation n° sim, en fonction, facultativement de la LSS spécifiée dans la fonction de propriété RiskSixSigma incluse. |
| Examples | RiskCpkUpper(A10) renvoie l'indice de capacité unilatéral basé sur la limite de specifications supérieure de la cellule de sortie A10. Une fonction de propriété RiskSixSigma doit être entrée dans la fonction RiskOutput de la cellule A10.RiskCpkUpper(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie l'indice de capacité unilatéral de la cellule de sortie A10, en fonction d'une LSS de 100. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pourrik_cell ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
| Description | RiskDPM(rés_f_cell ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) calcule les parties par million défectueuses pour rés_f_cell ou nom sortie à la simulation n° sim, en fonction, facultativement, des LSI et LSS de la fonction de propriété RiskSixSigma incluse. |
| Exemples | RiskDPM(A10) renvoie les parties par million défectueuses pour la cellule de sortie A10. Une fonction de propriété RiskSixSigma doit être entrée dans la fonction RiskOutput de la cellule A10.RiskDPM(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie les parties par million défectueuses pour la cellule de sortie A10, en fonction d'une LSI de 100 et d'une LSS de 120. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pour rés_f_cell ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
| Description | RiskK(rik_cell ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) calcule une mesure de centre de processus pourrik_cell ou nom sortie à la simulation n° sim, en fonction, facultativement, des LSI et LSS de la fonction de propriété RiskSixSigma incluse. |
| Examples | RiskK(A10) renvoie une mesure de centre de processus pour la cellule de sortie A10. Une fonction de propriété RiskSixSigma doit être entrée dans la fonction RiskOutput de la cellule A10.RiskK(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie une mesure de centre de processus pour la cellule de sortie A10, en fonction d'une LSI de 100 et d'une LSS de 120. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pourrik_cell ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
| Description | RiskLowerXBound(réf_cell ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) renvoie la valeur X inférieure d'un nombre spécifique d'écarts type par rapport à la moyenne pour réf_cell ou nom sortie à la simulation n° sim, en fonction, facultativement, du nombre d'écarts types spécifique dans la fonction de propriété RiskSixSigma. |
| Examples | RiskLowerXBound(A10) renvoie la valeur X inférieure d'un nombre d'écarts types spécifique par rapport à la moyenne pour la cellule A10.RiskLowerXBound(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie la valeur X inférieure de -6 écarts types par rapport à la moyenne pour la cellule de sortie A10, en fonction d'un nombre d'écarts types égal à 6. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pour réf_cell ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
RiskPNC
| Description | RiskPNC( refin_cell ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) calcule la probabilité totale de défectuosité en dehors des limites de specifications inférieure et supérieure pour refin_cell ou nom sortie à la simulation n° sim, en fonction, facultativement, des LSI, LSS et Décalage long terme spécifique dans la fonction de propriété de RiskSixSigma incluse. |
| Exemples | RiskPNC(A10) renvoie la probabilité de défectuosité en dehors des limites de specifications inférieure et supérieure pour la cellule de sortie A10. Une fonction de propriété RiskSixSigma doit être entrée dans la fonction RiskOutput de la cellule A10.RiskPNC(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie la probabilité de défectuosité en dehors des limites de specifications inférieure et supérieure pour la cellule de sortie A10, en fonction d'une LSI de 100, d'une LSS de 120 et d'un décalage long terme de 1,5. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pour refin_cell ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
| Description | RiskPNCLower( réf_cell ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Decalage long terme; Nombre d'écarts types)) calcule la probabilité de défectuosité en dehors de la limite de specifications inférieure pour réf_cell ou nom sortie à la simulation n° sim, en fonction, facultativement, des LSI, LSS et Decalage long terme spécifique dans la fonction de propriété RiskSixSigma incluse. |
| Examples | RiskPNCLower (A10) renvoie la probabilité de défectuosité en dehors de la limite de specifications inférieure pour la cellule de sortie A10. Une fonction de propriété RiskSixSigma doit être entrée dans la fonction RiskOutput de la cellule A10.RiskPNCLower(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie la probabilité de défectuosité en dehors de la limite de specifications inférieure pour la cellule de sortie A10, en fonction d'une LSI de 100, d'une LSS de 120 et d'un décalage long terme de 1,5. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pour réf_cell ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
| Description | RiskPNCUpper( refin_cell ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) calcule la probabilité de défectuosité en dehors de la limite de specifications supérieure pour refl_cell ou nom sortie à la simulation n° sim, en fonction, facultativement, des LSI, LSS et Décalage long terme spécifiés dans la fonction de propriété RiskSixSigma incluse. |
| Examples | RiskPNCUpper(A10) renvoie la probabilité de défectuosité en dehors de la limite de specifications supérieure pour la cellule de sortie A10. Une fonction de propriété RiskSixSigma doit être entrée dans la fonction RiskOutput de la cellule A10.RiskPNCUpper(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie la probabilité de défectuosité en dehors de la limite de specifications supérieure pour la cellule de sortie A10, en fonction d'une LSI de 100, d'une LSS de 120 et d'un décalage long terme de 1,5. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pour refl_cell ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
| Description | RiskPPMLower( réf_cell ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) calcule le nombre de défauts en-deçà de la limite de specifications inférieure pour réf_cell ou nom sortie à la simulation n° sim, en fonction, facultativement, des LSI et Décalage long terme spécifique dans la fonction de propriété RiskSixSigma incluse. |
| Exemples | RiskPPMLower(A10) renvoie le nombre de défauts en-deçà de la limite de specifications inférieure pour la cellule de sortie A10. Une fonction de propriété RiskSixSigma doit être entrée dans la fonction RiskOutput de la cellule A10. RiskPPMLower(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie le nombre de défauts en-deçà de la limite de specifications inférieure pour la cellule de sortie A10, en fonction d'une LSI de 100 et d'un décalage long terme de 1,5. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pour réf_cell ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
| Description | RiskPPMUpper( réf_cell ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) calcule le nombre de défauts au-delà de la limite de specifications supérieure pour réf_cell ou nom sortie à la simulation n° sim, en fonction, facultativement, des LSS et Décalage long terme spécifiés dans la fonction de propriété RiskSixSigma incluse. |
| Exemples | RiskPPMUpper(A10) renvoie le nombre de défauts au-delà de la limite de specifications supérieure pour la cellule de sortie A10. Une fonction de propriété RiskSixSigma doit être entrée dans la fonction RiskOutput de la cellule A10. RiskPPMUpper(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie le nombre de défauts au-delà de la limite de specifications supérieure pour la cellule de sortie A10, en fonction d'une LSS de 120 et d'un décalage long terme de 1,5. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pour réf_cell ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
| Description | RiskSigmaLevel(吵架 ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) calcule le niveau Sigma de processus pour吵架 ou nom sortie à la simulation n° sim, en fonction, facultativement, des LSS, LSI et Décalage long terme spécifiés dans la fonction de propriété RiskSixSigma incluse. (Remarque: Cette fonction présume que la sortie est distribuée normalement et centrefe dans les limites de Specification.) |
| Examples | RiskSigmaLevel(A10) renvoie le niveau Sigma de processus de la cellule de sortie A10. Une fonction de propriété RiskSixSigma doit être entrée dans la fonction RiskOutput de la cellule A10.RiskSigmaLevel(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie le niveau Sigma de processus pour la cellule de sortie A10, en fonction d'une LSS de 120, d'une LSI de 100 et d'une Décalage long terme de 1,5. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pour吵架 ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
| Description | RiskUpperXBound(吵架 ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) renvoie la valeur X supérieure d'un nombre spécifique d'écarts type par rapport à la moyenne pour ref_cell ou nom sortie à la simulation n° sim, en fonction, facultativement, du nombre d'écarts types spécifique dans la fonction de propriété RiskSixSigma. |
| Examples | RiskUpperXBound(A10) renvoie la valeur X supérieure d'un nombre d'écarts types spécifique par rapport à la moyenne pour la cellule A10.RiskUpperXBound(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie la valeur X supérieure de -6 écarts types par rapport à la moyenne pour la cellule de sortie A10, en fonction d'un nombre d'écarts types égal à 6. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pour ref_cell ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
| Description | RiskYV(Longrightarrow ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) calcule le produit ou le pourcentage du processus sans défaut pour réf_cell ou nom sortie à la simulation n° sim, en fonction, facultativement, des LSI, LSS et Décalage long terme spécifique dans la fonction de propriété RiskSixSigma incluse. |
| Exemples | RiskYV(A10) renvoie le produit ou le pourcentage du processus sans défaut pour la cellule de sortie A10. Une fonction de propriété RiskSixSigma doit être entrée dans la fonction RiskOutput de la cellule A10.RiskYV(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie le produit ou le pourcentage du processus sans défaut pour la cellule de sortie A10, en fonction d'une LSI de 100, d'une LSS de 120 et d'un décalage long terme de 1,5. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pour réf_cell ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
| Description | RiskZlower( refin_cell ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) calcule le nombre d'écarts types qui séparent la limite de specifications inférieure de la moyenne pour refl_cell ou nom sortie à la simulation n° sim, en fonction, facultativement, de la LSI spécifique dans la fonction de propriété RiskSixSigma incluse. |
| Examples | RiskZlower(A10) renvoie le nombre d'écarts types qui séparent la limite de specifications inférieure de la moyenne pour la cellule de sortie A10. Une fonction de propriété RiskSixSigma doit être entrée dans la fonction RiskOutput de la cellule A10.RiskZlower(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie le nombre d'écarts types qui séparent la limite de specifications inférieure de la moyenne pour la cellule de sortie A10, en fonction d'une LSI de 100. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pour refl_cell ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
| Description | RiskZMin( refin_cell ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) calcule le minimum Z-inf et Z-sup pour refin_cell ou nom sortie à la simulation n° sim, en fonction, facultativement, des LSS et LSI spécifiées dans la fonction de propriété RiskSixSigma incluse. |
| Examples | RiskZMin(A10) renvoie le minimum Z-inf et Z-sup pour la cellule de sortie A10. Une fonction de propriété RiskSixSigma doit être entrée dans la fonction RiskOutput de la cellule A10. RiskZMin(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie le minimum Z-inf et Z-sup pour la cellule de sortie A10, en fonction d'une LSS de 120 et d'une LSI de 100. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pour refin_cell ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
| Description | RiskZUpper(řef_cell ou nom sortie; n° sim; RiskSixSigma(LSI; LSS; Cible; Décalage long terme; Nombre d'écarts types)) calcule le nombre d'écarts types qui séparent la limite de specifications supérieure de la moyenne pour réf_cell ou nom sortie à la simulation n° sim, en fonction, facultativement, de la LSS spécifique dans la fonction de propriété RiskSixSigma incluse. |
| Examples | RiskZUpper(A10) renvoie le nombre d'écarts types qui séparent la limite de specifications supérieure de la moyenne pour la cellule de sortie A10. Une fonction de propriété RiskSixSigma doit être entrée dans la fonction RiskOutput de la cellule A10.RiskZUpper(A10; ;RiskSixSigma(100;120;110;1,5;6)) renvoie le nombre d'écarts types qui séparent la limite de specifications supérieure de la moyenne pour la cellule de sortie A10, en fonction d'une LSS de 120. |
| Directives | Une fonction de propriété RiskSixSigma doit être entrée pour réf_cell ou nom sortie, ou une fonction de propriété RiskSixSigma doit être incluse. |
Référence : fonctions supplémentaires
Les fonctions suivantes renvoient une information sur l'état d'une simulation en cours d'exécution ou sur les corrélations employées lors d'une corrélation.
| Description | RiskCorrectCorrmat( plaque_matrice-corrélation; plaque_matrice_pondérations_d'ajustement) renvoie la matrice de corrélation corrugée pour la matrice située dans plaque_matrice-corrélation en fonction de la matrice des pondérations d'ajustement située dans plaque_matrice_pondérations_d'ajustement. Une matrice incorrecte spécifique des rapports simultanés incompatible entre trois entrées ou plus et doit être rectifiée avant la simulation. La matrice renvoyée est une matrice de corrélation correcte : toutes les entrées diagonales sont 1, les entrées hors diagonale sont comprises dans la plage de -1 à 1 et la matrice est définie positive (la plus petite valeur propre est >0 et les correlations sont cohérentes). Si plaque_matrice_pondérations_d'ajustement est précisée dans la fonction, les correlations sont optimisées de manière à rester aussi proches que possible de celles initialement spécifiées, compte tenu des pondérations. |
| Examples | RiskCorrectCorrmat(A1:C3:E1:G3) renvoie la matrice de corrélation corrugée pour la matrice définie dans la plage A1:C3, avec la matrice des pondérations d'ajustement dans la plage E1:G3 |
| Guidelines | L'argument plaque_matrice_pondérations_d'ajustement est facultatif. Il s'agit d'une formule matricielle qui renvoie la matrice de corrélation corrugée. Pour la définitir, 1) sélectionnez une plage contenant le même nombre de lignes et colonnes que la matrice de corrélation originale, 2) entrez la fonction =RiskCorrectCorrmat(Plage_matrice_de_corrélation;Plage_matrice_pondérations_d'ajustement) 3) appuyez simultanément sur <Ctrl><Maj><Entrée> pour saisir la formule sous forme de formule matricielle. |
| Description | RiskCurrentIter() renvoie le numéro de l'itération courante d'une simulation en cours d'exécution. Aucun argument n'est requis. |
| Examples | Aucune. |
| Directives | Aucune. |
| Description | RiskCurrentSim() renvoie le numéro de la simulation courante. Aucun argument n'est requis. |
| Examples | Aucune. |
| Directives | Aucune. |
| Description | RiskStopRun( réf_cell ou formule) arrête une simulation quand la valeur de réf_cell renvoie VRAI ou que la formule s'avère (VRAI). Servez-vous de cette fonction en combinaison avec RiskConvergenceLevel pour arrêter une simulation quand les résultats de réf_cell ont convergé. |
| Examples | RiskStopRun(A1) arrête la simulation quand la valeur de A1 est VRAI. |
| Directives | Aucune. |
Référence : fonction graphique
La fonction @RISK RiskResultsGraph insère automatiquement une représentation graphique des résultats de la simulation à l'endroit de son inclusion dans la feuille de calcul. Ainsi, =RiskResultsGraph(A10) introduira une représentation graphique de la distribution simulée pour la cellule A10, directement dans le tableau, à l'emplacement de la fonction en fin de simulation. Les arguments facultatifs de RiskResultsGraph régissant le type de graphique à créer, son format, son échelle et d'autres options encore.
Cette fonction peut aussi être invoquée depuis le langage macro @RISK pour la génération de graphiques Excel dans les applications @RISK personnalisées.
RiskResultsGraph
| Description | RiskResultsGraph(rik_cell ou nom sortie/entree; plage d'emplacement; Type_graphique; FormatExcel; délim_gauche; délim_droit; MinX; MaxX; ÉchelleX; Titre; n° sim) ajoute un graphique des résultats de la simulation à une feuille de calcul. Les graphiques générés sontidentiques à ceux de la fenêtre @RISK — Synthese des résultats. Beaucoup des arguments de cette fonction sont facultatifs. Si les arguments facultatifs ne sont pas définis, RiskResultsGraph create un graphique conforme, pour les arguments omis, aux paramètres par défaut de la fenêtre @RISK — Synthese des résultats. |
| Exemples | RiskResultsGraph(A10) généreneu graphique des résultats de la simulation pour la cellule A10, au format Excel à l'emplacement de la fonction, conforme au type défini par défaut (histogramme, courbe cumulative croissante oucourbecumulative décroissantante). RiskResultsGraph(A10;C10:M30;1;VRAI;1;99) génereu graphique des résultats de simulation pour la cellule A10, dans la plage C10:M30, au format Excel sous le type histogramme, avec délimiteurs gauche et droit aux valeurs 1% et 99%, respectivement. |
| Directives | réf_cell doit représentera une référence de cellule(s) Excel valable. Un argument réf_cell ou nom de sortie/entree doit être inclus dans une fonction RiskResultsGraph. Si l'argument réf_cell est entré, les résultats à représenté dépendant des éléments suivants : En présence d'une fonction RiskOutput dans réf_cell, le graphique représentée les résultats de la simulation de cette sortie. En présence non d'une fonction RiskOutput mais d'une fonction de distribution dans réf_cell, RiskResultsGraph représentée les échantillons recueillis pour cette entrée. En l'absence de fonction RiskOutput ou de fonction de distribution dans réf_cell, une fonction RiskOutput s'ajoute automatiquement et RiskResultsGraph en représentée le graphique. Si réf_cell compte plusieurs cellules, un graphique se superpose pour les |
| résultats de simulation de chaque cellule. Tous les graphiques superposés sont du même type. plage_d'emplacement représentée une plage de cellules Excel valable. Le graphique se place et se dimensionne en fonction de la plage indiquée. Type_graphique (facultatif) représentée l'une des constantes suivantes : 0 pour un histogramme 1 pour une courbe cumulative croissantante 2 pour une courbe cumulative décroissantante 3 pour un graphique tornade des résultats de sensibilité par régression 4 pour un graphique tornade des résultats de sensibilité par corrélation 5 pour un graphique de synthèse de 1) la plage de sortie incluant ref_cell ou 2) les résultats de chaque cellule comprise dans ref_cell ( quand ref_cell représentée une plage de plusieurs cellules) 6 pour un graphique en boîte de 1) la plage de sortie incluant ref_cell ou 2) des résultats de chaque cellule comprise dans ref_cell ( quand ref_cell représentée une plage de plusieurs cellules) 7 pour un graphique de fonction de distribution théorique 8 pour un histogramme d'entrée simulée superposée de sa distribution théorique FormatExcel (facultatif) spécifique si le graphique doit être créé au format Excel. Si ouï, entrez VRAI ; entrez FAUX ou laissez blanc pour le format @RISK. délim_gauche (facultatif) spécifique l'emplacement du délimiter gauche du graphique, en %, pour les graphiammes et les graphiques cumulatifs. Sa valeur doit être comprise entre 0 et 100. délim_droit (facultatif) spécifique l'emplacement du délimiter droit du graphique, en %, pour les graphiammes et les graphiques cumulatifs. Sa valeur doit être comprise entre 0 et 100. MinX (facultatif) spécifique la valeur minimum de l'axe X en unités hors échelle pour les graphiammes et les graphiques cumulatifs. MaxX (facultatif) spécifique la valeur maximum de l'axe X en unités hors échelle pour les graphiammes et les graphiques cumulatifs. ÉchelleX (facultatif) spécifique le facteur d'échelle de l'axe X pour les graphiammes et les graphiques cumulatifs. Sa valeur est un entier représentant la puissance de 10 utilisée pour convertir les valeurs de l'axe X à l'étiquetage de l'axe. Par exemple, la valeur ÉchelleX 3 spécifierait des valeurs affichées en milliers. Titre (facultatif) spécifique le titre à afficher pour le graphique. Une chaîne entre guillemets ou une ↔équence de cellule contenant le titre peut être entrée. n° sim (facultatif) spécifique le nombre de la simulation dont les résultats doivent être représentés, lorsque plusieurs simulations sont exécutées. |
Les versions @RISK 5.5 Professional et Industrial s'accompagnent de la Bibliothèque @RISK, application de base de données distincte utile au partage des distributions de probabilités en entrée de @RISK et à la comparaison des résultats de différentes simulations. La Bibliothèque @RISK repose sur SQL Server pour le stockage des données @RISK.
Au sein d'une organisation, une bibliothèque @RISK partagée donne accès
aux distributions de probabilités en entrée communes, prédéfinies pour les modèles de risque de l'organisation, aux résultats de simulation de différents utilisateurs et aux archives des simulations exécutées sur différentes versions d'un modèle.
Pour accéder à la bibliothèque @RISK :
- Cliquez sur l'icône Bibliothèque de la barre d'outils @RISK et désélectionnez la commande Afficher la Bibliothèque @RISK pour en ouvrir la fenêtre. Vous pouvez y consulter les distributions courantes ainsi que les résultats de simulation stockés dans la bibliothèque. La commande Ajouter les résultats à la Bibliothèque y ajoute un résultat de simulation courante.
- Cliquez sur l'icône Ajouter une distribution à la Bibliothèque dans la fenêtre Définir une distribution. Les distributions ajoutées à la bibliothèque sont disponibles à ses autres utilisateurs.
Différents serveurs SQL peuvent donner accès à plusieurs bibliothèques. Il peut notamment être utile de garder une bibliothèque locale à l'endroit où vous conservez les simulations et distributions réservées à votre usage personnel. Une autre bibliothèque pourrait être configurée pour le partage des distributions et résultats entre les utilisateurs @RISK d'un groupe de travail ou d'une division. Enfin, une bibliothèque générale d'entreprise pourrait recueillir les distributions relatives aux hypothèses communes de l'entreprise : les taux d'intérêt à venir, les prix, etc.
La Bibliothèque @RISK comporte deux types d'information stockée pour les modèles @RISK : Distributions et Résultats. Les deux onglets de la fenêtre principale de la bibliothèque leur sont consacrés.
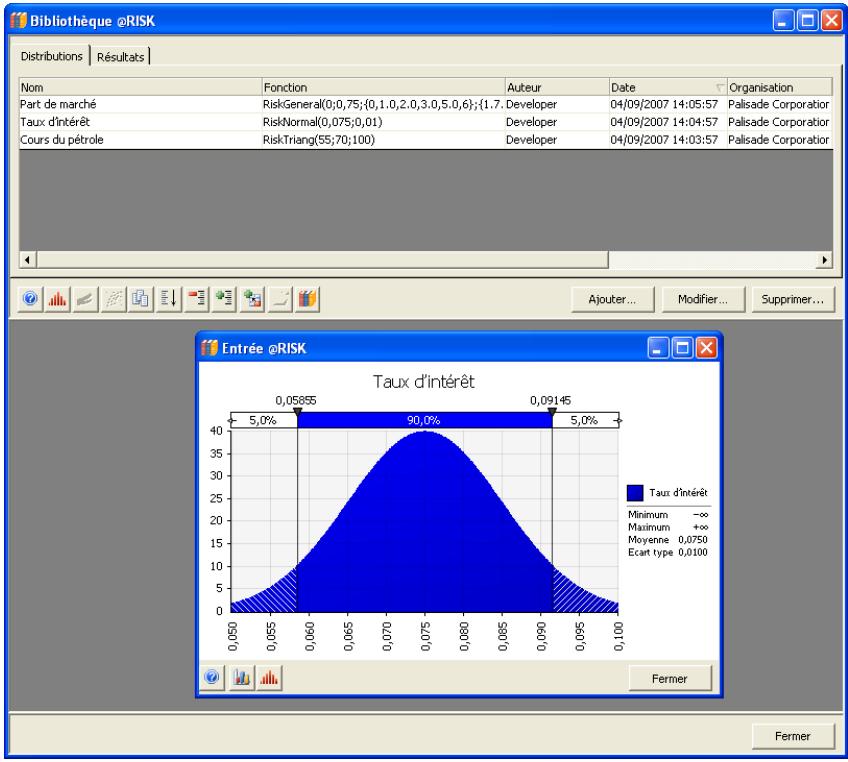
Distributions dans la bibliothèque @RISK
La Bibliothèque @RISK permet le partage de distributions de probabilités entre différents utilisateurs @RISK. Ce partage assure que tous les utilisateurs @RISK d'une même organisation utilisent la même définition, et la plus courante, pour leurs entrées de risque communes utilisées dans différents modèles. Par le recours aux mêmes définitions pour ses entrées clés, l'organisation s'assure que tous les modèles s'exécutent sous les mêmes hypothèses communes. Les résultats peuvent ainsi être comparés de modèle en modèle.
@RISK actualise automatiquement toutes les distributions de bibliothèque présentes dans un modèle à chaque simulation, à travers la fonction de propriété RiskLibrary dont sont assorties toutes les fonctions de distribution en entrée ajoutées depuis la Bibliothèque @RISK. La fonction de propriété RiskLibrary comporte un identificateur spécial grâce auquel @RISK récupère la dernière définition en date de la distribution dans la bibliothèque et ajuste, au besoin, la fonction. Par exemple, si le service de planification de l'entreprise a mis à jour la distribution relative au prix du pétrole pour l'année prochaine, votre modèle utilisera automatiquement cette distribution lors de votre prochaine simulation.
Ajout de distributions dans la Bibliothèque
Il existe deux méthodes d'ajout de distributions de probabilités dans la Bibliothèque @RISK :
- Ajout depuis la fenêtre Définir une distribution. Toutes les distributions affichées dans la fenêtre Définir une distribution peuvent être ajoutées à la Bibliothèque @RISK. L'icône Ajouter une entrée dans la bibliothèque ajoute la distribution affichée dans la bibliothèque @RRISK.
- Entrée directe dans la Bibliothèque @RISK. Cliquez sur le bouton Ajouter de l'onglet Distributions de la Bibliothèque @RISK pour définir une nouvelle distribution et la mettre à la disposition des utilisateurs qui accèdent à votre bibliothèque.
La Bibliothèque @RISK admet l'entrée des propriétés suivantes de la distribution ajoutée :
- Nom. Le nom de la distribution.
- Description. Une description personnalisée de la distribution.
- Fonction. La définition fonctionnelle de la distribution. Cette définition peut être modifiée à tout moment sous accès en écriture à la base de données.
- Révisions. Suit les révisions apportées aux distributions stockées dans la bibliothèque.
Références aux cellules dans les distributions de la bibliothèque
Racines des distributions de bibliothèque
Les fonctions de distribution qui incluent des références à des cellules Excel sont admises dans la Bibliothèque @RISK, mais il convient de procéder avec prudence. L'approche est généralement limitée aux situations où la distribution doit être utilisée localement, dans le classeur de sa définition originale. L'insertion d'une distribution de bibliothèque avec références de cellules dans un autre modèle risque de ne pas résoudre ajustement les valeurs d'argument. La structure du modèle peut en effet être différente et les références spécifiées ne contiennent pas nécessairement les valeurs attendues.
Une distribution de bibliothèque contient généralement une fonction de propriété RiskSeed définissant la racine de son flux de nombres aléatoires. Cette propriété assure que chaque modèle dans lequel la distribution est utilisée suive la même série de valeurs échantillonnées pour la distribution de bibliothèque. Les résultats de différents modèles faisant appel à la distribution de bibliothèque peuvent ainsi être comparés en toute validité.
Représentation graphique d'une distribution
La représentation graphique d'une distribution de bibliothèque est fort similaire à celle des distributions en entrée dans les fenêtres Définir une distribution et Modèle de @RISK. Un clic sur l'icone Graphique au bas de l'onglet Distributions permet de sélectionner le type de graphique à afficher pour les distributions (lignes) sélectionnées dans la liste. Glisser-déplacer une entrée de la liste vers le bas de la fenêtre Bibliothèque @RISK génère aussi le graphique. Un clic droit, sur un graphique, ouvre la boîte de dialogue Options graphiques, pour la définition des paramètres du graphique. La définition d'une distribution de bibliothèque peut être modifiée en cliquant sur le bouton Édition, dans le volet des arguments d'un graphique affiché.
Les colonnes de l'onglet Distributions peuvent être personnalisées en fonction des statistiques et autres informations à afficher sur les distributions en entrée de la bibliothèque. L'icône Colonnes, au bas de la fenêtre, ouvre la boîte de dialogue Colonnes du tableau.
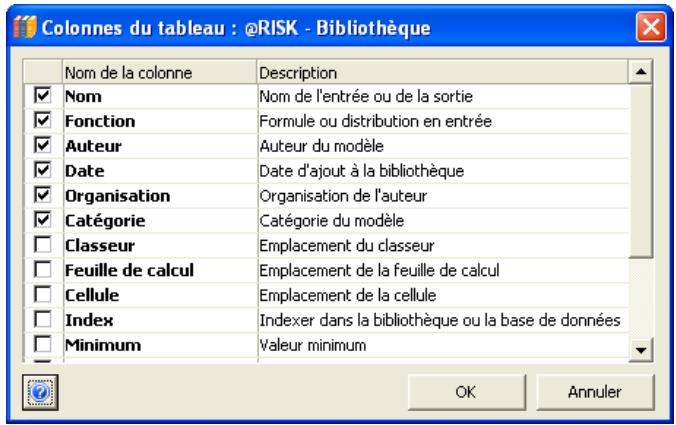
Utilisation d'une distribution de bibliothèque dans un réseau
Les distributions de bibliothèque s'ajoutent à un modèle Excel à travers la fenêtre Définir une distribution ou dans la Bibliothèque @RISK elle-même.
La palette de distributions comporte un onglet intitulé Bibliothèque @RISK, où sont listées toutes les distributions disponibles dans la bibliothèque. Il suffit de cliquer sur l'une de ces distributions pour la sélectionner et l'ajouter à la formule de la cellule affichée.
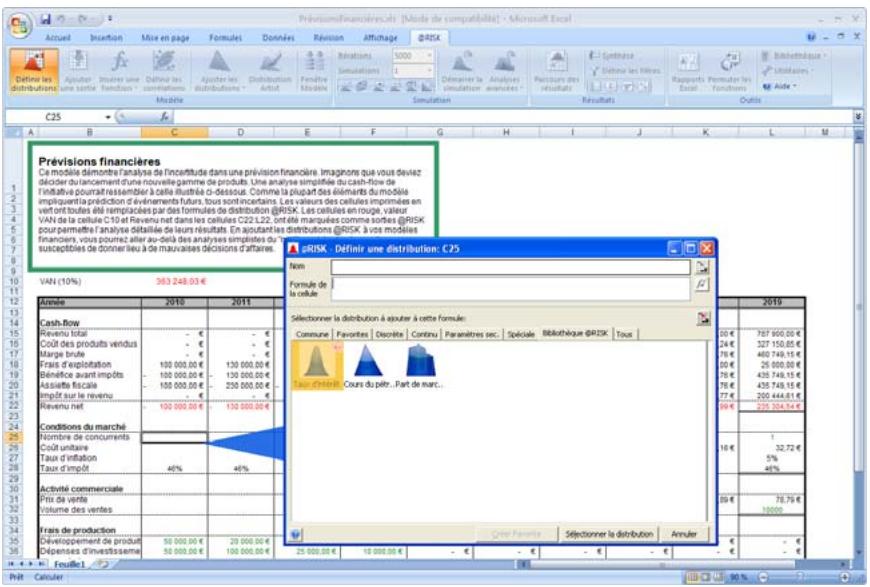
Pour ajouter une distribution à un modèle Excel depuis l'onglet Distributions de la Bibliothèque @RISK elle-même, sélectionnez la distribution désirée dans la liste Distributions et cliquez sur l'icône Ajouter à une cellule. Sélectionnez ensuite la cellule Excel dans laquelle la fonction doit s'inscrire.
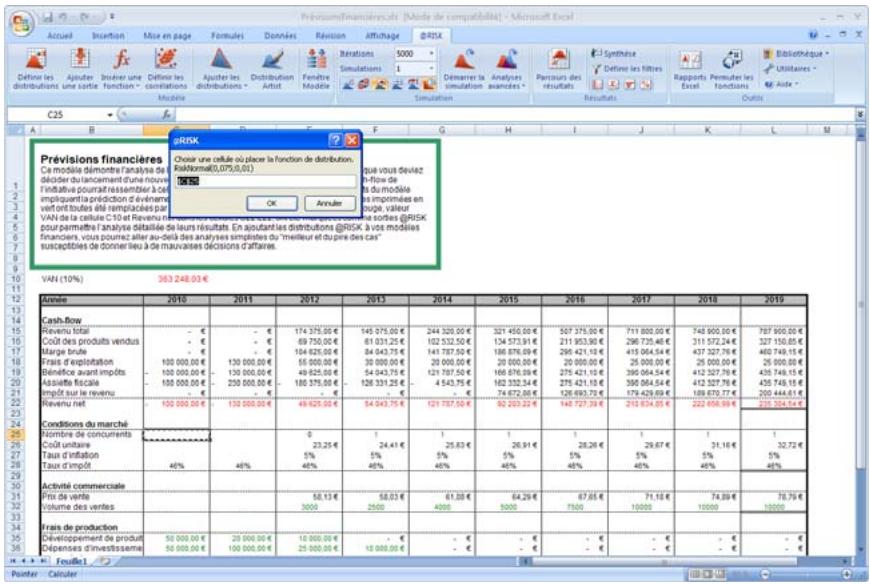
Actualisation des distributions
@RISK actualise automatiquement toutes les distributions de bibliothèque générées dans un module à chaque simulation, à travers la fonction de propriété RiskLibrary dont sont assorties les entrées ajoutées depuis la Bibliothèque @RISK. Par exemple :
=RiskNormal(50000;10000; RiskName("Développement Produit/2010"), RiskLibrary(5, "8RENDCKN"))
instruit @RISK d'actualiser la définition de cette fonction depuis la bibliothèque identifiée par « 8RENDCKN » au début de la simulation. Cet identificateur établit le lien à une bibliothèque unique du système. Si la bibliothèque n'est pas disponible, @RISK applique la définition courante du modèle (en l'occurrence, RiskNormal(50000;10000)).
Résultats dans la bibliothèque @RISK
La Bibliothèque @RISK permet le stockage et la comparaison des résultats de différents modèles et simulations. Dans la Bibliothèque @RISK, les résultats de simulations @RISK multiples peuvent être actifs à tout moment par rapport à ceux d'une seule simulation @RISK dans Excel.
Une fois les résultats stockés dans la Bibliothèque, leurs graphiques peuvent être superposés pour comparer les résultats de différentes simulations. Par exemple, vous pouvez exécuter une simulation sous un ensemble initial de paramètres et en stocker le résultat dans la Bibliothèque @RISK. Vous pouvez ensuite modifier le modèle dans Excel, réexécuter l'analyse et stocker le second résultat dans la bibliothèque. La superposition des graphiques des sorties de chaque simulation révèle la différence entre les résultats.
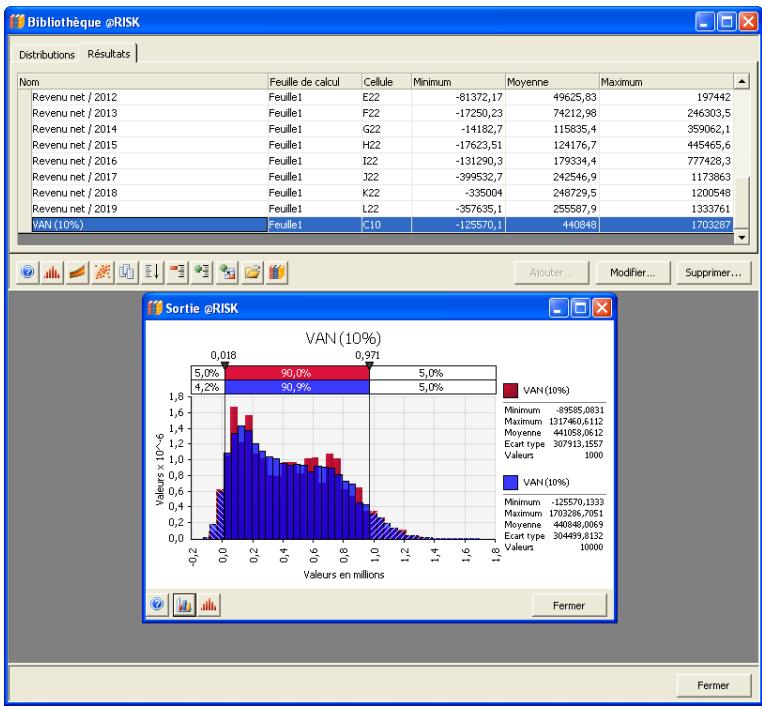
Vous pouvez aussi procéder à l'échantillonnage depuis une sortie stockée dans la Bibliothèque @RISK lors d'une nouvelle simulation dans Excel. La Bibliothèque @RISK peut placer une fonction RiskResample dans Excel, pour faire référence aux données recueillies pour la sortie et stockées dans la bibliothèque. L'approche est utile si l'on veut combiner les résultats de plusieurs modèles distincts en une simple nouvelle simulation ou optimisation de portefeuille.
Placement d'un résultat de simulation dans la Bibliothèque @RISK
Pour stocker vos résultats de simulation dans la Bibliothèque @RISK, désélectionnez la commande Ajouter les résultats à la Bibliothèque, sous l'icone Bibliothèque de la barre d'outils @RISK pour Excel. Vous pouvez sélectionner de stocker une nouvelle simulation dans la bibliothèque ou d'y remplacer une simulation déjà stockée.
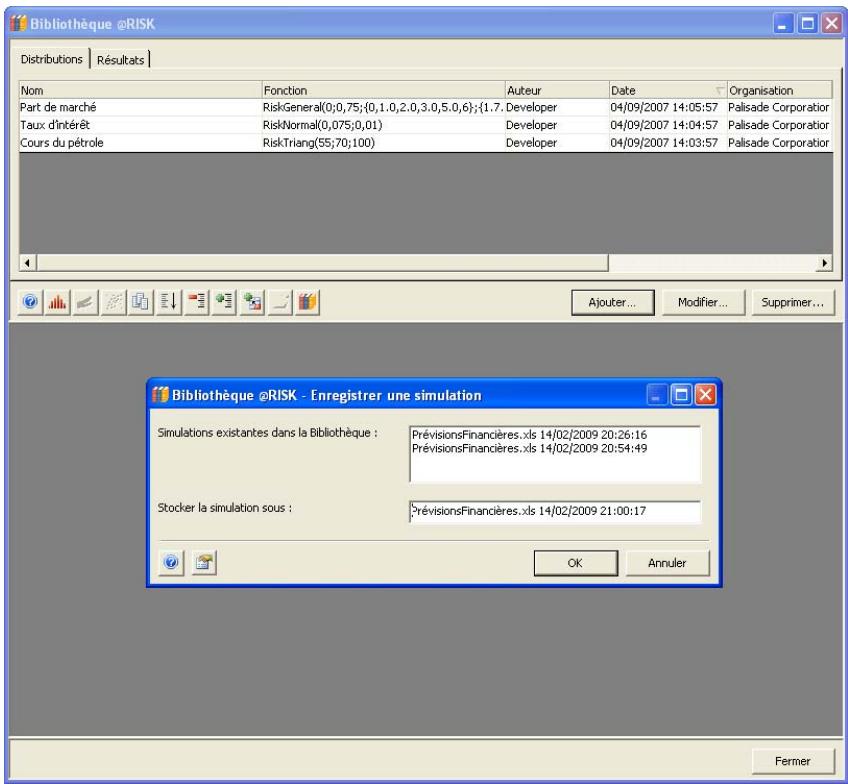
Lorsqu'une simulation est placée dans la Bibliothèque, les données de simulation et les classeurs Excel associés se placent automatiquement dans la Bibliothèque @RISK. Grâce à l'icône Ouvrir un modèle (le « dossier » jaune au bas de l'onglet Résultats), vous pouvez rouvrir une simulation stockée (et les classeurs utilisés lors de cette simulation) dans Excel. Vous pouvez ainsi revenir aisément à une simulation et un modèle antérieurs.
Remarque : Pour revenir rapidement à une simulation antérieure et à ses classeurs dans Excel, cliquez avec le bouton droit sur la liste de l'onglet Résultats et choisissez la commande Ouvrir un modèle.
Représentation graphique d'un résultat dans la bibliothèque
La représentation graphique d'un résultat de simulation dans la bibliothèque est fort similaire à celle des résultats dans la fenêtre Synthèse des résultats de @RISK. Un clic sur l'icône Graphique au bas de l'onglet Résultats permet de sélectionner le type de graphique à afficher pour les sorties (lignes) sélectionnées dans la liste. Glisser-déplacer un résultat de la liste vers le bas de la fenêtre Bibliothèque @RISK en génère aussi le graphique. Un clic droit, sur un graphique, ouvre la boîte de dialogue Options graphiques, pour la définition des paramètres du graphique.
Pour superposer différents résultats, glissez-déplacez un résultat de la liste par-dessus un graphique existant.
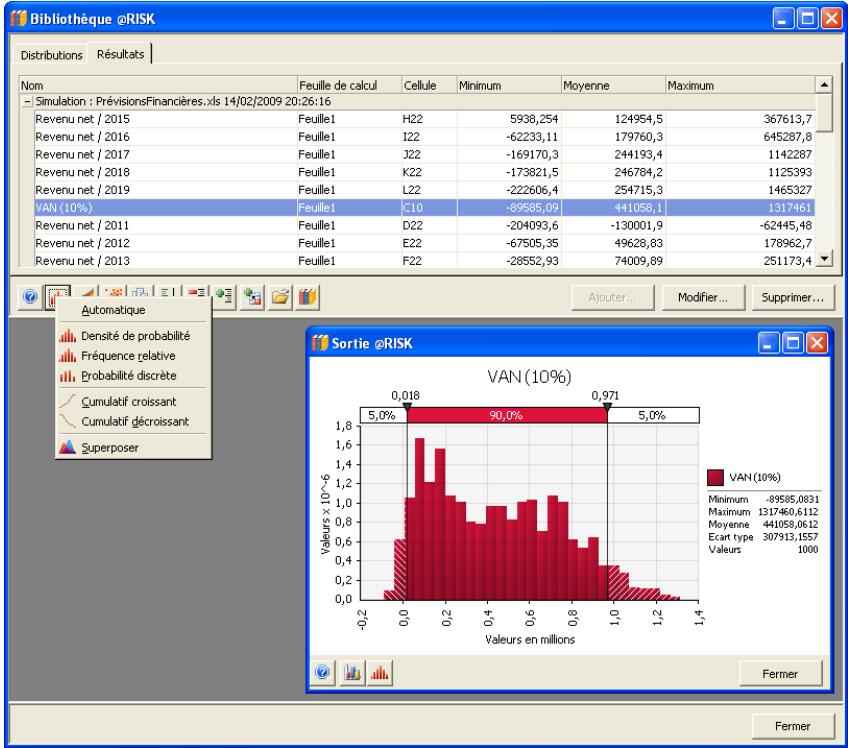
Ré-échantillonnage de résultats de simulation stockés dans la Bibliothèque
Vous pouvez procéder à l'échantillonnage au départ d'une sortie stockée dans la Bibliothèque @RISK, dans le cadre d'une nouvelle simulation Excel. Il peut arriver que vous désiriez utiliser les distributions de sortie de nombreuses simulations différentes comme entrées d'une nouvelle simulation dans Excel : pour créer, par exemple, un modèle d'optimisation de portefeuille qui fasse appel aux distributions de sortie d'un ensemble de modèles distincts pour sélectionner une formule optimale de projets ou d'investissements. Chaque projet ou investissement possible est associé à une simulation individuelle stockée dans la Bibliothèque @RISK. Le modèle d'optimisation de portefeuille fait ainsi référence à ces distributions de sortie individuelles. Il y prévoit ses échantillons à chaque itération tout en calculant les résultats pour le portefeuille dans son ensemble.
La distribution de sortie de chaque projet ou investissement devient une entrée échantillonnable à travers la fonction RiskResample. Vous pouvez placer une sortie de la bibliothèque dans un classeur d'Excel au moyen de la commande Ajouter au modèle comme entrée rééchantillonnée. Les données recueillies et stockées pour la sortie forment ainsi l'ensemble de données soumises à l'échantillonnage lors de la simulation du portefeuille. Ces données se stockent dans le classeur avec la simulation du portefeuille.
Ré-échantillonnage des données de sortie en une simulation combinée
La fonction RiskResample qui fait d'une sortie une distribution en entrée propose différentes options d'échantillonnage du jeu de données référencé. Il est possible d'échantillonner les données en ordre, aléatoirement avec remplacement ou aléatoirement sans remplacement. Pour le ré-échantillonnage de sorties de simulation, l'option En ordre est généralement utilisée. Elle préserve l'ordre des données iteratives des simulations stockées lors de la simulation combinée.
Cet ordre est important lorsque les simulations individuelles partagent des distributions en entrée communes. Ces distributions communes doivent en effet souvent une fonction de propriété RiskSeed, qui régit le renvoi des mêmes valeurs d'échantillon, dans le même ordre, à chaque utilisation. Ainsi, chaque simulation d'un projet ou investissement individuel utilise les mêmes valeurs échantillonnées pour les distributions communes de chaque itération.
Si l'option En ordre n'est pas sélectionnée, des combinaisons inexactes des valeurs de sortie des projets ou investissements individuels peuvent être introduites dans la simulation combinée. Supposons, par exemple, une simulation d'un portefeuille de projets individuels de gaz et pétrole, sous l'option de ré-échantillonnage aléatoire. Une itération donnée pourrait ré-échantillonner une valeur de la distribution de sortie d'un projet associé à un cours élevé du pétrole puis, aléatoirement, une valeur de la distribution de sortie d'un autre projet associé à un cours faible du pétrole. Il s'agirait là d'une combinaison impossible, donnant lieu à des résultats de simulation inexacts pour le portefeuille.
Entrée d'une sortie de la bibliothèque comme entrée rééchantillonnée
Pour entrer une sortie de la bibliothèque comme entrée rééchantillonnée :
1) Sélectionnez la distribution de sortie à soumettre au rééchantillonnage sous l'onglet Résultats de la Bibliothèque @RISK. 2) Cliquez sur l'icône Ajouter au modèle comme entrée rééchantillonnée ou cliquez droit et choisissez la commande Ajouter au modèle comme entrée rééchantillonnée.
3) Sélectionnez la méthode d'échantillonnage désirée : En ordre, Aléatoirement, avec remplacement ou Aléatoirement, sans remplacement. 4) Sélectionnez Actualiser au début de chaque simulation si vous désirez actualiser les données de la sortie au début de chaque simulation. @RISK vérifie dans ce cas la Bibliothèque @RISK au début de chaque simulation, afin de déterminer si la simulation stockée pour la sortie a été actualisée et présente des résultats plus récents. Cela se produit si vous avez remplacé la simulation originale stockée dans la bibliothèque par une version plus récente.
L'actualisation s'effectue à travers la fonction de propriété RiskLibrary dont sont assorties les sorties ré-échantillonnées ajoutées depuis la Bibliothèque @RISK quand l'option Actualiser au début de chaque simulation est sélectionnée. Par exemple :
instruit @RISK d'actualiser les données de la sortie depuis la bibliothèque identifiée par « TB8GKF8C » au début de la simulation. Cet identificateur établit le lien à une bibliothèque unique du système. Si la bibliothèque n'est pas disponible, @RISK utilise les données de la sortie stockée dans le classeur lors de la dernière actualisation des données et du dernier enregistrement du classeur.
5) Sélectionnez Représenter graphiquement comme distribution continue si vous désirez que les données ré-échantillonnées soient représentées en continu (comme dans la distribution de sortie et les statistiques de la simulation stockée), par opposition à une distribution discrète. Cette option se traduit par l'introduction d'une fonction de propriété RiskIsDiscrete(FAUX) dans la fonction RiskResample. La distribution RiskResample est une distribution discrète en ce que seules les valeurs de l'ensemble de données référencé peuvent être échantillonnées. La représentation graphique continue présente cependant un format plus facile à comprendre. Remarque : La sélection de Représenter graphiquement comme distribution continue est sans effet sur les valeurs ré-échantillonnées et les résultats de la simulation.
6) Sélectionnez la cellule Excel dans laquelle la sortie rééchantillonnée doit s'inscrire.
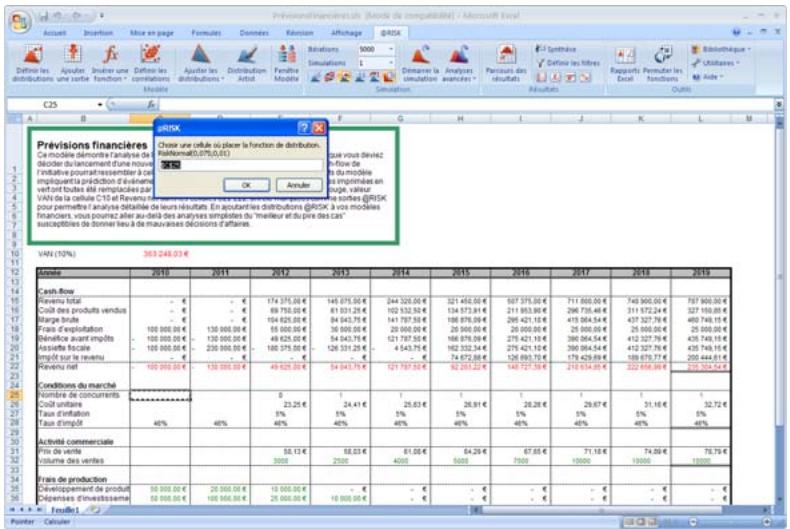
Notes techniques
La Bibliothèque @RISK repose sur Microsoft SQL Server pour le stockage des simulations et classeurs enregistrés. L'accès à un fichier de Bibliothèque @RISK se fait de la même manière qu'à une base de données SQL. Plusieurs bases de données de la Bibliothèque @RISK peuvent être ouvertes en même temps. En cliquant sur l'icône Bibliothèque, au bas de la fenêtre Bibliothèque @RISK, les connexions aux bases de données existantes peuvent être établies et de nouvelles bases de données peuvent être créées.
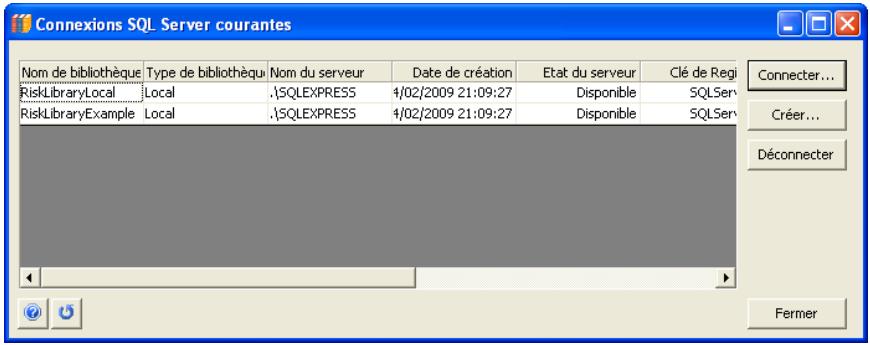
Connexion à une bibliothèque existante
Cliquez sur le bouton Connecter pour accéder à un serveur où SQL est installé et où une base de données de Bibliothèque @RISK est disponible. Un clic sur le nom d'un serveur y vérifie la disponibilité de bases de données.
Création d'une nouvelle bibliothèque
Cliquez sur le bouton Créer pour accéder à un serveur où SQL est installé. Entrez le nom de la nouvelle bibliothèque dans le champ Nom de bibliothèque et cliquez sur Créer. La nouvelle bibliothèque créée sera disponible au stockage de distributions et de résultats de simulation @RISK.
Autres détails sur SQL server express
La Bibliothèque @RISK utilise SQL Server Express comme plate-forme de stockage et récupération des fonctions RiskLibrary et des résultats de simulation. Produit de base de données Microsoft gratuit reposant sur la technologie SQL Server 2005,
SQL Server Express recourt au même moteur de base de données que les autres versions de SQL Server 2005 mais est soumis aux limitations de 1 UC, 1 Go RAM et 4 Go de taille de base de données.
Bien que SQL Server Express puisse servir de produit serveur, @RISK s'en sert aussi comme magasin de données client local où la fonctionnalité d'accès aux données de la Bibliothèque @RISK ne dépend pas du réseau.
SQL Server Express peut être installé et exécuté sur une architecture multiprocesseur mais une seule UC peut être utilisée à la fois. La limite de taille de base de données de 4 Go s'applique à tous les fichiers de données. Le nombre de bases de données rattachables au serveur est cependant illimité et les utilisateurs de la Bibliothèque @RISK peuvent créer plusieurs bases de données ou s'y connecter.
Plusieurs installations SQL Server 2005 Express peuvent coexister sur un même ordinateur, aux côtés d'autres installations de SQL Server 2000 et de SQL Server 2005.
SQL Server Express s'installe par défaut comme instance nommée SQLEXPRESS. L'utilisation de cette instance est recommandée à moins que d'autres applications ne présentent de besoin de configuration spéciaux.
Vous remarquerez, lors de la connexion aux bases de données, de leur création ou de la modification des fonctions RiskLibrary, l'existence d'options d'authentication SQL Server. Pour la plupart des utilisateurs et pour toutes les instances locales de SQL Server Express, l'authentication Windows est probablement adaptée.
L'authentication Windows fait appel à vos justificatifs d'identité réseau pour établir la connexion à SQL Server. Lorsque vous vous connectez à votre poste de travail, votre mot de passe est authentifié par Windows. Ce justificatif vous donne accès à SQL Server, ainsi qu'à d'autres applications de votre poste ou réseau. Cela ne vous donne pas automatiquement accès à une base de données de Bibliothèque @RISK, mais vous devriez pouvoir vous connecter au serveur.
Sous authentication SQL Server, un nom d'accès et un mot de passe sont stockés dans SQL Server Express. Lorsque vous essayez de vous connecter sous authentification SQL Server, ce nom d'accès est vérifié. Si la correspondance est établie, le mot de passe est vérifié par rapport à la valeur stockée. S'il correspond aussi, l'accès vous est donné au serveur.
L'authentication SQL Server vous permet de protégérer votre base de données moyennant l'accord ou le refus de permissions à des utilisateurs ou groupes d'utilisateurs particuliers. Les détails de configuration et gestion de ces permissions sont généralement traités par un administrateur de base de données ou de réseau et ne sont pas expliqués ici. Ils vous permettront cependant d'accorder ou de refuser les permissions voulues à certains utilisateurs ou groupes d'utilisateurs.
Le compte Admin Système est désactivé par défaut sous authentification Windows. Les utilisateurs ordinaires de l'ordinateur ne disposent de pratiquement aucun privilège sur l'instance SQL Server Express. Un administrateur local du serveur doit accorder explicitement les permissions pertinentes pour que les utilisateurs ordinaires puissent utiliser la fonctionnalité SQL.
Capacité de la bibliothèque
Sous SQL Server Express, une simple base de données de bibliothèque peut recevoir environ 2000 simulations représentatives de 10 sorties, 100 entrées et 1000 iterations. Les différents volumes de simulation représentent des exigences de stockage différentes. Le nombre de bases de données rattachables au serveur est illimité et les utilisateurs de la Bibliothèque @RISK peuvent créer plusieurs bases de données ou s'y connecter.
Référence : kit de développement @RISK pour excel (XDK)
@RISK pour Excel s'accompagne d'une puissante interface de programmation API utile à l'automatisation de @RISK et à l'élaboration d'applications personnalisées en VBA, VB, C ou autres langages de programmation. Pour plus de détails sur cette interface de programmation, voir le fichier d'aide spécial du Kit du développement @RISK pour Excel (XDK) fourni avec votre exemplaire de @RISK.
Annexe a : méthodes d'échantillonnage
L'échantillonnage sert, dans une simulation @RISK, à générer les valeurs possibles à partir des fonctions de distribution de probabilités. Ces ensembles de valeurs possibles seront ensuite à évaluer la feuille de calcul Excel. Ainsi, l'échantillonnage constitue la base des centaines ou milliers de scénarios hypothétiques que @RISK calcul pour la feuille de calcul. Chaque ensemble d'échantillons représentée une combinaison possible des valeurs d'entrée susceptibles de se produire. Le choix d'une méthode d'échantillonnage affecte à la fois la qualité des résultats obtenus et la durée nécessaire à la simulation de la feuille de calcul.
Définition de l'échantillonnage
L'échantillonnage est la procédure de prélèvement de valeurs aléatoires dans les distributions de probabilités en entrée. Dans @RISK, les distributions de probabilités sont représentées par les fonctions de distribution de probabilités et l'échantillonnage est effectué par le programme. L'échantillonnage d'une simulation est un processus répétitif, avec prélèvement, à chaque itération, d'un échantillon dans chaque distribution de probabilités en entrée. Lorsque suffisamment d'itérations sont effectuées, la distribution des valeurs échantillonnées pour une distribution de probabilités se rapproche de la distribution en entrée connue. Les statistiques de la distribution échantillonnée (moyenne, écart type et moments élevés) se rapprochent de l'entrée statistique vraie de la distribution. Le graphique de la distribution échantillonnée ressemble même au graphique de la vraie distribution en entrée.
Les statisticiens et praticiens ont mis au point diverses techniques d'échantillonnage aléatoire. Le facteur important, lors de l'évaluation des techniques d'échantillonnage, est le nombre d'iterations nécessaires à la reconstitution précise d'une distribution en entrée. La précision des résultats de sortie dépend d'un échantillonnage complet des distributions en entrée. Une méthode d'échantillonnage est d'autant moins efficace qu'elle requiert plus d'iterations et de plus longues durées d'exécution pour produire son approximation des distributions en entrée.
Les deux méthodes d'échantillonnage utilisées dans @RISK - Monte Carlo et Hypercube latin - différent par le nombre d'iterations nécessaires à l'approximation des distributions en entrée.
L'échantillonnage Monte Carlo nécessite souvent un grand nombre d'échantillons, surtout lorsque la distribution en entrée est très asymétrique ou présente des issues peu probables. L'échantillonnage Hypercube latin, nouvelle technique utilisée dans @RISK, impose une correspondance plus étroite entre les échantillons et la distribution en entrée, permettant une convergence plus rapide sur les vraies statistiques de la distribution en entrée.
Distribution cumulative
Il est souvent utile, avant de choisir une méthode d'échantillonnage, de bien comprendre le concept de la distribution cumulative. Toute distribution de probabilités peut être exprimée sous forme cumulative. Une courbe cumulative est généralement échelonnée de 0 à 1 sur l'axe Y, dont les valeurs représentent la probabilité cumulative jusqu'à la valeur correspondante sur l'axe X.
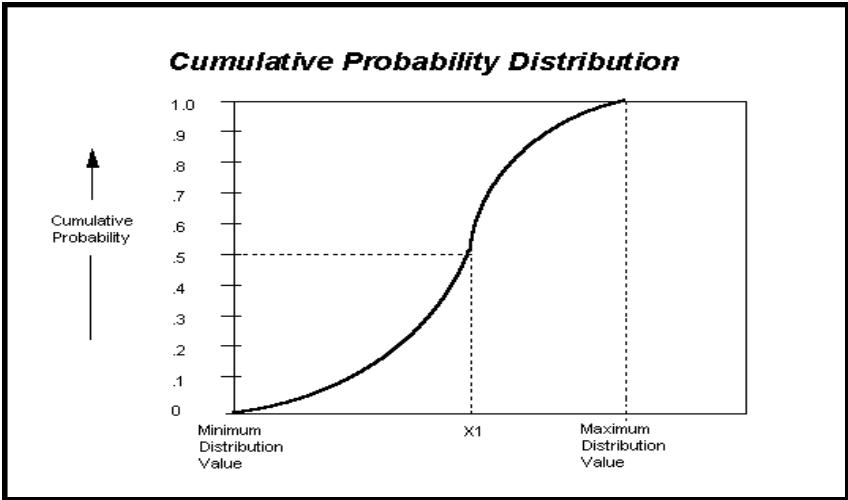
Dans la courbe cumulative ci-dessus, la valeur cumulative 0,5 représente le point de probabilité cumulative de 50% (0,5 = 50%) : 50% des valeurs de la distribution se situant au-dessous de cette valeur médiane, et 50% au-dessus. La valeur cumulative 0 représente la valeur minimum (0% des valeurs se situant au-dessous de ce point) et la valeur cumulative 1 représente la valeur maximum (100% des valeurs se situant au-dessous de ce point).
L'importance de cette courbe cumulative à la compréhension de l'échantillonnage s'explique comme suit. L'échelle de 0 à 1,0 de la courbe cumulative représentée la plage des nombres aléatoires possibles générés à l'échantillonnage. Dans une série d'échantillonnage Monte Carlo typique, l'ordinateur génère un nombre aléatoire compris entre 0 et 1, chaque nombre de la plage ayant les mêmes chances de se produire. Ce nombre sert alors à la sélection d'une valeur dans la courbe cumulative. Dans l'exemple ci-dessus, la valeur échantillonnée pour la distribution illustrée serait X1 si le nombre aléatoire 0,5 était généré à l'échantillonnage. La forme de la courbe cumulative étant fonction de celle de la distribution de probabilités en entrée, les issues plus probables sont plus susceptibles d'être échantillonnées. Ces issues correspondant à la partie la plus « raide » de la courbe.
Échantillonnage monte carlo
L'échantillonnage Monte Carlo désigne la technique traditionnelle de recours aux nombres aléatoires ou pseudo-aléatoires pour l'échantillonnage d'une distribution de probabilités. Le choix du terme Monte Carlo remonte à la Deuxième Guerre mondiale, lorsqu'il était utilisé comme nom de code associé à la simulation des problèmes liés au développement de la bombe atomique. Les techniques Monte Carlo sont actuellement appliquées à une grande diversité de problèmes complexes dans lesquels intervenent un comportement aléatoire. Une grande variété d'algorithmes permet la génération d'échantillons aléatoires à partir des différents types de distributions de probabilités.
Les techniques d'échantillonnage Monte Carlo sont entièrement aléatoires : un échantillon donné peut tomber n'importe où dans la plage de la distribution en entrée. Il va de soi que les échantillons ont plus de chances d'être prélevés dans les zones de la distribution associées à une plus grande probabilité. Dans la distribution cumulative représentée plus haut, chaque échantillon Monte Carlo utilise un nouveau nombre aléatoire compris entre 0 et 1. Avec un nombre suffisant d'iterations, l'échantillonnage Monte Carlo « recreate » les distributions en entrée par l'échantillonnage. Un problème de groupement apparait toutefois lorsque le nombre d'iterations est faible.
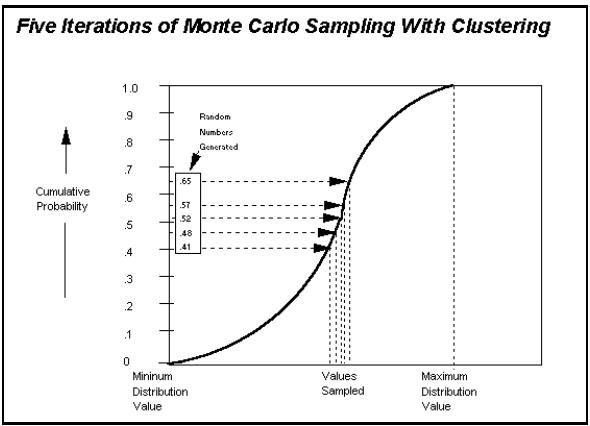
Dans l'illustration ci-dessus, les 5 échantillons prélevés se situent tous au centre de la distribution. Les valeurs des plages extérieures de la distribution ne sont pas représentées dans les échantillons; leur impact sur les résultats n'est donc pas inclus dans la sortie de la simulation.
Le groupement devient particulièrement prononcé lorsqu'une distribution comprend des issues de probabilité faible susceptibles d'avoir un impact substantiel sur les résultats. Ces issues doivent impératifement être échantillonnées pour assurer l'inclusion de leurs effets dans les résultats. Cependant, si leur probabilité est suffisamment faible, un nombre réduit d'iterations Monte Carlo risquerait de ne pas les échantillonner en quantités suffisantes pour en représenter avec précision la probabilité. Ce problème a conduit à la mise au point des techniques d'échantillonnage stratifié tel l'échantillonnage Hypercube latin utilisé dans @RISK.
Échantillonnage hypercube latin
L'échantillonnage Hypercube latin est une technique d'échantillonnage récente conçue pour recréer avec précision la distribution en entrée par un échantillonnage requérant moins d'iterations que la méthode Monte Carlo. La clé de l'échantillonnage Hypercube latin est la stratification des distributions de probabilités en entrée. Cette stratification divise la courbe cumulative en intervals égaux sur l'échelle cumulative des probabilités (de 0 à 1,0). Un échantillon est alors prélevé au hasard dans chaque intervalle ou « strate » de la distribution en entrée. L'échantillonnage représenté ainsi obligatoirement les valeurs de chaque intervalle, recréant ainsi la distribution de probabilités en entrée.
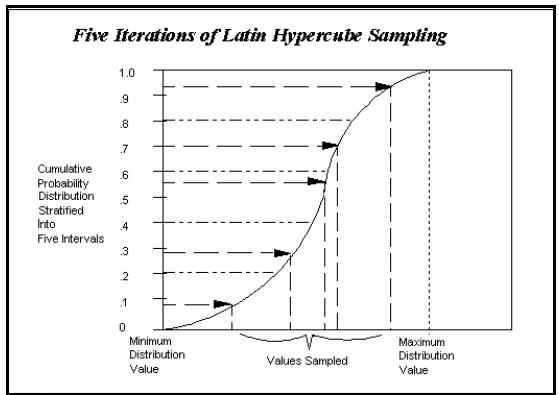
Dans l'illustration ci-dessus, la courbe cumulative est divisée en 5 intervalles. Lors de l'échantillonnage, un échantillon est prélevé dans chaque intervalle. Comparons la situation avec les 5 échantillons groupés de la méthode Monte Carlo. Sous la méthode Hypercube latin, les échantillons représentent plus précisément la distribution de valeurs de la distribution de probabilités en entrée.
La technique de l'échantillonnage Hypercube latin est celle de « l'échantillonnage sans remise ». Le nombre de stratifications de la distribution cumulative est égal au nombre d'iterations. Dans l'exemple ci-dessus, cinq iterations ont été executées, et cinq stratifications ont donc été appliquées à la distribution cumulative. Un échantillon est prélevé dans chaque stratification. Cela fait, la stratification n'est cependant plus échantillonnée : sa valeur est déjà représentée dans l'ensemble échantillonné.
L'échantillonnage d'une stratification s'effectue comme suit. @RISK désigne en fait la stratification à échantillonner avant d'y déterminer une valeur aléatoire.
Approche Hypercube latin et issues à faible probabilité
Lors de l'utilisation de la technique Hypercube latin en présence de plusieurs variables, il importe de maintenir l'indépendance entre les variables. Les valeurs échantillonnées pour l'une doit être indépendantes de celles échantillonnées pour une autre (sauf bien sûr, si leur corrélation est explicitement demandée). Cette indépendance est assurée par la sélection aléatoire de l'intervalle de prélèvement de l'échantillon de chaque variable. Dans une itération donnée, la variable n°1 peut être échantillonnée dans la stratification n°4, la variable n°2, dans la stratification n°22, et ainsi de suite. Le caractère aléatoire et l'indépendance sont ainsi préservés, et les corrélations indésirables entre les variables sont évitées.
Méthode d’échantillonnage efficace, la technique Hypercube latin offre de gros avantages en termes d’efficacité de l’échantillonnage et d’accelération des durées d’exécution (en raison du nombre inférieur d’iterations). Ces avantages sont particulièrement notables dans un environnement de simulation sur PC tel que @RISK. La méthode facilite aussi l’analyse des situations dans lesquelles des issues à faible probabilité sont représentées dans les distributions en entrée. En l’inclusion des événements peu probables dans l’échantillonnage, l’approche Hypercube latin assure leur représentation ajustée dans les sorties de simulation.
Lorsque les issues à faible probabilité sont très importantes, il est souvent utile d'effectuer une analyse limitée à la simulation de la contribution des événements à faible probabilité à la distribution de sortie. Le modèle ne simule dans ce cas que la réalisation des issues à faible probabilité, dont la probabilité est fixée à 100% pour l'occasion. Cet isolement des issues en question permet ainsi l'étude directe de leurs résultats.
Test des techniques
La « convergence » est le meilleur test d'une méthode d'échantillonnage. Au point de convergence, les distributions de sortie sont stables (les itérations supplémentaires ne modifient de façon notable ni la forme ni les statistiques de la distribution échantillonnée). La moyenne d'échantillon, par rapport à la vraie moyenne, est généralement une mesure de la convergence, mais l'asymétrie, les probabilités par centiles et autres statistiques sont également souvent utilisées.
@RISK fournit un environnement favorable au test de la vitesse de convergence vers une distribution en entrée des deux techniques d'échantillonnage disponibles. Sélectionnez une fonction @RISK de distribution en entrée comme sortie de simulation et executez un nombre égal d'iterations avec chaque technique d'échantillonnage. À l'aide de la fonction de surveillance de convergence intégrée de @RISK, observez le nombre d'iterations nécessaires à la stabilisation des centiles, de la moyenne et de l'écart type. Il devrait être clair que l'échantillonnage Hypercube latin converge plus rapidement sur les distributions vraies que l'échantillonnage Monte Carlo.
Informations supplémentaires sur les techniques d'échantillonnage
Les techniques d'échantillonnage Monte Carlo et Hypercube latin sont toutes deux abordées dans la documentation théorique et technique. Tous les ouvrages sur la simulation proposés dans la section Lectures recommandées représentent une introduction à l'échantillonnage Monte Carlo. Les ouvrages faisant référence à l'échantillonnage Hypercube latin font l'objet d'une section distincte.
Annexe b : utilisation de @RISK avec d'autres outils decisiontools®
Les outils DecisionTools de Palisade offrent des solutions d'analyse de décision complètes pour Microsoft Windows. Avec l'introduction de DecisionTools, Palisade vous propose un ensemble d'outils dont les éléments se combinent pour tirer pleinement parti de la puissance de votre tableau.
Decision Tools Suite offre des outils d'assistance experte à la décision, de l'analyse de risque à l'analyse de sensibilité et à l'ajustement de distributions. DecisionTools Suite comprend les logiciels suivants :
- @RISK - analyse de risque par simulation Monte Carlo
- TopRank® - analyse de sensibilité
- PrecisionTree® - analyse de décision avec arbres décisionnels et diagrammes d'influence
- NeuralTools® - réseaux neuronaux dans Excel
- Evolver® - optimisation génétique dans Excel StatTools - statistiques dans Excel
Bien que tous ces outils puissants seront achetés et utilisés séparément, leur combinaison en multiplie la puissance, de l'analyse de données historiques et d'ajustement pour les besoins d'un modèle @RISK au recours à TopRank pour l'identification des variables à définir dans le modèle.
Ce chapitre présente différents modes d'interaction entre les éléments de DecisionTools Suite, au service d’un processus décisionnel optimal.
Remarque: Palisade offre aussi une version de @RISK pour Microsoft Project. @RISK pour Project permet l'exécution d'analyses de risque sur des plans créés dans Microsoft Project, le principal progiciel de gestion de projets. Prenez contact avec Palisade pour tous renseignements complémentaires sur cette application fascinante de @RISK!
Achat des produits palisade
Tous les logiciels mentionnés ici, y compris DecisionTools Suite, peuvent être achetés directement auprès de Palisade Corporation. Pour passer commande ou pour tous renseignements complémentaires, prenez contact avec le service des ventes techniques de Palisade Corporation :
- Téléphone: +1-607-277-8000, du lundi au vendredi, de 8 h 30 à 17 heures, heures de l'Est des États-Unis
- Fax : Courriel: sales@palisade.com
- Adresse Web : http://www.palisade.com Adresse postale : Technical Sales Palisade Corporation 798 Cascadilla St Ithaca, NY 14850 USA
Courriel: sales@palisade-europe.com - Téléphone: +44 1895 425050 (UK) - Fax: +44 1895 425051 (UK) - Adresse postale : Palisade Europe 31 The Green West Drayton Middlesex UB7 7PN Royaume-Uni
Palisade Asie-Pacifique :
Courriel: sales@palisade.com.au - Téléphone: +61 2 9929 9799 (Australie) - Fax: +61 2 9954 3882 (Australia) - Adresse postale: Palisade Asia-Pacific Pty Limited Suite 101, Level 1 8 Cliff Street Milsons Point NSW 2061 AUSTRALIA
Decisiontools — étude de cas
| La société Excelsior Electronics fabrique des ordinateurs de bureau. Elle envisage l'introduction d'un ordinateur portable, l'Excelsior 5000, dont elle désire évaluer la rentabilité. Elle create un modele de feuille de calcul portant sur les deux années à partir, en affectant une colonne à chaque mois. Le modele tient compte des coûts de production, de la commercialisation, des frais d'expédition, du prix unitaire, des unités vendues, etc. Le bénéfice est calculé sur laforthème ligne de chaque mois. Excelsior prévoit quelques difficultés de départ, mais tant qu'elles ne sont pas trop importantes et que les bénéfices paraissent à la hausse vers la fin de la deuxième année, elle entend lancer la production du E5000. | |
| TopRank d'abord, puis @RISK | TopRank identifie les variables critiques du modele. Les cellules « Profit » sont sélectionnées comme sorties, et une analyse d'hypothèse automatique est executée. Les résultats indiquentrapidement que cinq variables (parmi beaucoup d'autres) exercent la plus forté incidence sur les bénéfices : le prix unitaire, les coûts de commercialisation, la durée de construction, le prix de la mémoire et le prix des circuits intégrés de l'unité centrale. Excelsior decide de se concentrer sur ces variables. |
| Évaluer les probabilités | Les cinq variables du modele doivent maintainant être exprimées par des fonctions de distribution. Les distributions normales sont utilisées pour le prix unitaire et la durée de construction, en fonction des décisions et informations internes du service de production d'Excelsior. |
| Ajustement de distributions | Les fluctuations hebdomadaires du prix des mémoires et des UC sont recherchées sur les deux années antérieures. Le produit de cette recherche est soumis à l'ajustement de distributions @RISK et les distributions sont ajustées aux données. Les informations de niveau de confiance en confirmant le bon ajustement et les fonctions de distribution @RISK réalisantes sont collées dans le modele. |
| Simulation avec @RISK | Une fois toutes les fonctions @RISK en place, les cellules « Profit » sont sélectionnées comme sorties et une simulation est executée. Dans l'ensemble, les résultats paraissent promuteurs. En dépôt de quelques pertes initiales, il y a 85 % de chance de réaliser des bénéfices acceptables, et 25 % de chance de réaliser plus de revenus que ceux initialement anticipés. Le projet Excelsior 5000 reçoit le feu vert. |
Décision à l'aide de precisiontree
Excelsior Electronics avait envisagé d'assurer elle-même la vente et la distribution de l'Excelsior 5000. Le recours à différents catalogues et entreprises informatiques pourrait toutefois être considéré. Un modèle d'arbre décisionnel est créé à l'aide de PrecisionTree, en tenant compte des prix unitaires, du volume des ventes et d'autres facteurs critiques de comparaison de la vente directe à la vente par catalogue. Une analyse de décision est exécutée et PrecisionTree suggère le recours aux catalogues et magasins. Excelsior Electronics met le plan en œuvre.
TopRank est l'outil d'analyse d'hypothèses par excellence de Palisade Corporation. TopRank améliore considérablement les capacités d'hypothèses standard et des tables de données du tableau. Mieux encore, le passage à @RISK et à la puissance supérieure de l'analyse de risque ne pourrait être plus aisé.
Toprank et l'analyse d'hypothèses
TopRank facilite l'identification, dans une feuille de calcul, de la ou des valeurs ou variables qui exercent la plus grande incidence sur les résultats : une analyse automatique d'hypothèse ou de sensibilité, en somme. TopRank peut aussi essayer automatiquement un nombre indéfini de valeurs pour une variable (une table de données) et indiquer les résultats calculés pour chacune. TopRank essaie aussi toutes les combinaisons de valeurs possibles pour un ensemble de variables (analyse d'hypothèse multivoie) et indique les résultats calculés pour chaque combinaison.
L'analyse d'hypothèse ou de sensibilité est un élément clé de la prise de décision basée sur une feuille de calcul. Cette analyse identifie les variables dont l'incidence sur les résultats est la plus importante. Elle révèle les facteurs auxquels il convient d'accorder la plus grande importance lors 1) de la collecte de données et du raffinement du modèle et 2) de la gestion et de la mise en œuvre de la situation décrite dans le modèle.
Compagnon de tableau pour Microsoft Excel, TopRank peut être ajouté à n'importe quelle feuille de calcul, préalable ou nouvelle. Pour configurer ses analyses d'hypothèses, TopRank ajoute de nouvelles fonctions de « variation » personnalisées à celles du tableau. Ces fonctions spécifient le mode de variation des valeurs de la feuille de calcul dans une analyse d'hypothèse (+10% et -10%, +1 000 et -500, par exemple, ou en fonction d'une table de valeurs entrée).
TopRank permet aussi les analyses d'hypothèses entièrement automatisées. Il utilise une technologie de vérification puissante pour rechercher toutes les valeurs possibles de la feuille de calcul susceptibles d'affecter les résultats. Il peut ensuite modifier automatiquement toutes ces valeurs possibles et identifier les facteurs les plus décisifs dans la détermination des résultats.
Applications toprank
Les applications de TopRank sont celles du tableau. Si vous pouvez un modèle dans un tableau, vous pouvez utiliser TopRank pour l'analyser. Les entreprises font appel à TopRank pour identifier les facteurs critiques (prix, investissement initial, volume des ventes ou frais généraux) qui affectent le plus le succès de leurs nouveaux produits. Les ingénieurs utilisent TopRank pour identifier les éléments d'un produit dont la qualité affecte le plus les taux de production du produit fini. Un responsable du crédit peut faire exécuter rapidement un modèle sous toute combinaison possible de taux d'intérêt, montant du capital et acompte, et examiner les résultats de chaque scénario possible. Que votre application se situe dans le monde des affaires, de la science, de la technique, de la comptabilité ou ailleurs, TopRank peut vous aider à identifier les variables critiques qui affectent vos résultats.
Fonctions de modélisation
Compagnon de Microsoft Excel, TopRank s'associe directement au tableau pour l'enrichir de ses capacités d'analyse d'hypothèse. Le système TopRank fournit tous les outils nécessaires à la réalisation d'une analyse d'hypothèse sur un modèle de feuille de calcul. Son interface vous sera du reste parfaitement familière, avec ses menus et fonctions de style Excel.
L'analyse d'hypothèse et les tables de données peuvent être exécutées directement dans le tableau, mais uniquement dans un format manuel et sans structure. Le simple changement d'une valeur de cellule et le calcul d'un nouveau résultat constituent une analyse d'hypothèse élémentaire. Une table de données produit le résultat de chaque combinaison de deux valeurs peut aussi être intégrée au tableau.
TopRank exécute ces tâches et en analyse les résultats automatiquement. Il exécute instantanément les analyses hypothétiques sur toutes les valeurs susceptibles d'affecter les résultats, au lieu d'imposer leur modification individuelle et le recalcul de la feuille. Il indique ensuite la valeur la plus significative dans la détermination du résultat.
Analyse d'hypothèse multivoie
TopRank exécute aussi des combinaisons de tables de données automatiques, sans qu'il soit nécessaire de configurer les tables dans le tableau. L'analyse d'hypothèse multivoie permet la combinaison de plus de deux variables (vous pouvez combiner un nombre indéfini de variables) et le classement des combinaisons en fonction de leur effet sur les résultats. Ces analyses automatisées et sophistiquées sont particulièrement rapides, car TopRank « retient » toutes les valeurs et combinaisons essayées et leurs résultats, en dehors de la feuille de calcul. Par son approche automatisée, TopRank offre des résultats d'hypothèse et d'hypothèse multivoie pratiquement instantanés. Même l'utilisateur le moins expérimenté peut obtenir de puissants résultats d'analyse.
Fonctions toprank
TopRank définit ses variations de valeurs au moyen de fonctions. Pour ce faire, TopRank ajoute un ensemble de nouvelles fonctions à celles d'Excel, spécifique chacune un type de variation des valeurs. Ces fonctions sont les suivantes :
les fonctions Vary et AutoVary qui, au cours d'une analyse d'hypothèse, modifient une valeur sur une plage + et - que vous définissez, les fonctions VaryTable qui, au cours d'une analyse d'hypothèse, substituent à une valeur de la feuille de calcul chacune des valeurs d'une table.
TopRank fait appel aux fonctions pour modifier les valeurs d'une feuille de calcul au cours d'une analyse de situation hypothétique et retient les résultats calculés à chaque changement de valeur. Ces résultats sont ensuite classés en fonction de l'importance de la variation par rapport aux résultats initialement anticipés. Les fonctions associées aux plus grandes variations sont identifiées comme les plus critiques du modèle.
Entrée des fonctions toprank
TopRank Pro comprend aussi plus de 30 fonctions de distribution de probabilités générées dans @RISK. Ces fonctions peuvent être combinées aux fonctions Vary pour décrire la variation dans les valeurs de la feuille de calcul.
Les fonctions TopRank sont admises en chaque endroit où il est possible d'essayer différentes valeurs dans une analyse d'hypothèse. Elles peuvent être ajoutées à un nombre indéfini de cellules et comprendre comme arguments des références de cellule et des expressions. Elles offrent ainsi une très grande souplesse de définition de la variation des valeurs dans les modèles de feuilles de calcul.
Vous pouvez ajouter vous-même les fonctions Vary, ou TopRank peut le faire pour vous. Cette entrée automatique offre un outil d'analyse.
Hypothèses automatisées
puissant et rapide, sans identification manuelle des valeurs et entrée manuelle des fonctions.
Lors de l'entrée automatique des fonctions Vary, TopRank explore la feuille de calcul et recherche toutes les valeurs susceptibles d'affecter la cellule de résultat que vous identifiez. Les valeurs identifiées sont remplacées par une fonction « AutoVary » sujette aux paramètres de variation par défaut (+10% et -10%, par exemple) que vous avez sélectionnés. Après avoir inséré ses fonctions AutoVVary, TopRank peut exécuter son analyse d'hypothèse et classer selon leur importance les valeurs susceptibles d'affecter les résultats.
TopRank permet l'examen de ses fonctions Vary et AutoVary et la modification de la variation spécifiée par chacune. Vous pouvez par exemple utiliser, par défaut, une variation de -10 % et +10 %, mais désirer que pour une certaine valeur, un changement de -20 % et +30 % serait possible. Vous pouvez aussi choisir de ne pas faire varier une valeur (si elle est fixe, par exemple, et donc non modifiable).
Exécution d'une analyse d'hypothèse
Au cours de son analyse, TopRank modifie individuellement les valeurs de chaque fonction Vary et recalcule la feuille sur la base de chaque nouvelle valeur. À chaque recalcul, TopRank recueille la nouvelle valeur obtenue dans chaque cellule de résultat. Ce processus de variation et de recalcul est répété pour chaque fonction Vary et VaryTable. Le nombre de recalculs executé dépend du nombre de fonctions Vary entrées, du nombre de pas (nombre de valeurs sur une plage min-max) que TopRank doit essayer pour chaque fonction, du nombre de fonctions VaryTable entrées, et des valeurs de chaque table utilisée.
Résultats toprank
TopRank classe toutes les valeurs variées en fonction de leur impact sur chaque cellule de résultat ou sortie sélectionnée. L'impact se définit comme l'importance du changement de la valeur de sortie calculée sous l'effet de la modification de la valeur d'entrée. Si, par exemple, le modèle produit un résultat de 100 avant la modification des valeurs, et de 150 après la modification d'une entrée, la modification en question entraîne un changement de résultat de +50%.
Les résultats TopRank peuvent être représentés dans un graphique de type Tornade, Spider ou de sensibilité. Ces graphiques effectuent la synthèse des résultats pour représenter clairement les entrées les plus importantes en termes de résultats.
@RISK avec toprank
L'analyse d'hypothèse est souvent la première analyse executée sur une feuille de calcul. Ses résultats mènent à un modèle plus raffiné, à de nouvelles analyses et, enfin, à la prise d'une décision sur la base du modèle optimal. L'analyse de risque, technique analytique puissante offerte par @RISK, le produit compagnon de TopRank, constitue généralement l'étape suivante.
Passage de l'hypothèse à la simulation
L'analyse d'hypothèse identifie, avant tout, les éléments importants du modèle. Vous pouvez ainsi vous concentrer davantage sur ces composants et en estimer plus ajustement les valeurs possibles. Cependant, il existe généralement plusieurs éléments incertains, tous susceptibles, dans la réalité, de varier simultanément. L'analyse d'un tel modèle incertain doit passer par une analyse de risque ou une simulation Monte Carlo. L'analyse de risque fait varier toutes les entrées incertaines simultanément (comme dans la vie réelle) et définit la plage et la distribution de tous les résultats susceptibles de se produire.
Dans l'analyse de risque, les entrées sont décrites par une distribution de probabilités (normale, normale logarithmique, bêta ou binomiale). Il s'agit d'une description du caractère aléatoire de la valeur d'une entrée beaucoup plus détaillée qu'une simple variation + ou - de pourcentage. Une distribution de probabilités indique à la fois la plage des valeurs possibles d'une entrée et la probabilité de chaque valeur de cette plage. La simulation combine les distributions en entrée pour générer la plage des résultats possibles à partir du modèle et la probabilité de chaque résultat.
Utilisation des définitions d'hypothèse dans une analyse de risque
La simple variation + et - définie par une fonction Vary dans une analyse d'hypothèse peut être utilisée directement dans l'analyse de risque. En fait, @RISK échantillonne les fonctions Vary directement dans ses analyses de risque.
Les valeurs échantillonnées par @RISK à partir des fonctions Vary et VaryTable lors d'une simulation dépendent soit de l'argument de distribution entre pour la fonction, soit du paramètre de distribution par défaut utilisé dans TopRank. Par exemple, la fonction TopRank RiskVary(100:-10;+10), sous le paramètre de distribution par défaut Uniform et le type de plage par défaut de pourcentage +/-, s'échantillonne comme la distribution @RISK RiskUniform(90;110). Les fonctions VaryTable de TopRank s'échantillonnent comme les fonctions RiskDuniform de @RISK.
Différences entre toprank et @RISK
TopRank et @RISK partagent de nombreuses fonctionnalités. On en est parfois tenté de croire qu'ils remplissent les mêmes fonctions. En fait, les deux programmes exécutent des tâches différentes mais complémentaires. Ne vous demandez pas lequel utiliser ; considérez juste d'utiliser les deux.
Similarités
@RISK et TopRank sont tous deux des programmes compagnons d'analyse de modèles conçus dans un tableau. Par leurs formules de tableau spéciales, les deux programmes explorent l'incidence de l'incertitude sur le modèle et, par conséquent, sur la décision prise. Leur interface utilisateur commune garantit une transition transparente entre les deux produits : une seule courbe d'apprentissage au lieu de deux !
Différences
@RISK et TopRank se distinguent l'un de l'autre à trois niveaux :
- Entrées mode de définition de l'incertitude dans le modèle
- Calcul : objet de l'analyse
- Résultat types de réponses fournies par les analyses
Entrées
@RISK définit le caractère aléatoire du modèle à l'aide de fonctions de distribution de probabilités. Ces fonctions définissent toutes les valeurs possibles d'une entrée, avec la probabilité de chacune. Plus de 30 fonctions de distribution de probabilités sont disponibles dans @RISK.
Pour définir l'incertitude dans @RISK, vous devez affecter une fonction de distribution à chaque valeur que vous jugez incertaine. Il vous revient à vous, l'utilisateur, de déterminer les entrées incertaines et la fonction de distribution qui en décrit l'incertitude.
TopRank définit l'incertitude dans le modèle à l'aide des fonctions Vary. Ces fonctions sont simples : elles définissent les valeurs possibles qu'une entrée peut avoir sans leur affecter de probabilités. TopRank ne propose que deux fonctions Vary élémentaires : Vary et VaryTable.
TopRank peut automatiquement définir les cellules variables dans le modèle à chaque sélection de sortie. Il n'est pas nécessaire de savoir quelles cellules sont incertaines ou importantes : TopRank les identifie pour vous.
Calculs
@RISK exécute une simulation de type Monte Carlo ou Hypercube latin. À chaque itération (ou pas), chaque distribution @RISK du modèle prend une nouvelle valeur déterminée par la fonction de distribution de probabilités. Pour que l'analyse soit complète, @RISK doit exécuter des centaines, et parfois même des milliers d'itérations.
TopRank exécute une analyse de sensibilité simple ou multivoie. Au cours de l'analyse, une seule cellule (ou un petit nombre de cellules) varie à la fois selon les valeurs définies dans la fonction Vary. Avec TopRank, quelques itérations seulement suffisent à l'étude d'un grand nombre de cellules incertaines.
Résultats
Pour chaque sortie définie, @RISK produit une distribution de probabilités comme résultat de l'analyse. La distribution décrit les valeurs qu'une sortie (« profit », par exemple) peut prendre, ainsi que le degré de probabilité de certaines issues. Par exemple, @RISK peut indiquer une probabilité de 30% de pertes pour le trimestre à partir.
Pour chaque sortie définie, TopRank identifie les entrées les plus influentes. Les résultats indiquent la variation à anticiper au niveau d'une sortie lorsqu'une entrée donnée est modifiée selon une valeur définie. Par exemple, TopRank peut signaler que les bénéfices d'une entreprise sont plus sensibles au volume des ventes, et que lorsque ce dernier atteint 1000 unités, l'entreprise subit une perte de 1 million d'euros. TopRank indique ainsi que pour réaliser un bénéfice, il faut garder le volume des ventes élevé.
La différence la plus importante entre les deux logiciels tient au fait que @RISK étudie comment l'incertitude combinée de toutes les variables affecte la sortie. TopRank indique seulement comment une entrée individuelle (ou un petit groupe d'entrées) affecte la sortie. Ainsi, si TopRank est plus rapide et plus facile à utiliser, @RISK dresse un tableau plus complet de la situation. Nous recommendons vivement d'utiliser TopRank en premier, pour déterminer les variables les plus importantes. Faites ensuite appel à @RISK pour exécuter une analyse complète du problème en vue de résultats optimaux.
Synthèse
Pour résumer, TopRank identifie les variables les plus importantes d'un modèle. Les résultats d'une analyse d'hypothèse TopRank peuvent contribuer, à eux-seuls, à la prise de décisions. Pour une analyse plus approfondie, utilisez cependant TopRank pour identifier les principales variables d'un modèle, puis faites appel à @RISK pour définir l'incertitude associée à ces variables et exécuter une simulation. TopRank peut vous aider à optimiser vos simulations @RISK en définissant l'incertitude dans les variables les plus importantes seulement. Vos simulations en deviennent plus rapides et plus compactes.
PrecisionTree de Palisade Corporation est un compagnon d'analyse de décision de Microsoft Excel. Le programme offre la capacité jusqu'à ce jour inédite de définir un arbre décisionnel ou un diagramme d'influence directement dans un tableau. PrecisionTree permet d'exécuter une analyse de décision complète sans quitter le programme qui héberge les données : le tableau !
Pourquoi l'analyse de décision et l'arbre décisionnel ?
Vous vous demandez peut-être si les décisions qui vous incombent justifient l'analyse de décision. Si vous recherchez un moyen de structurer vos décisions afin d'en améliorer l'organisation et d'en faciliter l'explication à autrui, le moment est venu d'envisager l'analyse de décision formelle.
Confrontés à la nécessité d'une décision complexe, les décideurs doivent pouvoir organiser efficacement le problème. Il leur faut envisager toutes les options possibles à travers l'analyse de toutes les informations dont ils disposent. Il leur incombe aussi de présenter ces informations à leurs interlocuteurs de manière claire et concise. PrecisionTree leur en donne le moyen, et bien davantage encore!
Quels sont, plus précisément, les avantages de l'analyse de décision ? En tant que décideur, vous pouvez clarifier vos options et leurs avantages, quantifier vos situations sujettes à l'incertitude, peser simultanément vos objectifs multiples et définir vos préférences de risque. Tout cela dans une feuille de calcul Excel.
Fonctions de modélisation
En tant que « compagnon » de Microsoft Excel, PrecisionTree se « lie » à Excel pour y ajouter ses fonctionnalités d'analyse de décision. Le système PrecisionTree fournit tous les outils nécessaires à la configuration et à l'analyse des arbres décisionnels et des diagrammes d'influence. Son interface vous sera du reste parfaitement familière, avec ses menus et barres d'outils de style Excel.
PrecisionTree n'impose aucune limite de taille à l'arbre à définir. Il peut même embrasser plusieurs feuilles de calcul d'un classeur Excel! PrecisionTree réduit l'arbre à un rapport facile à comprendre dans le classeur courant.
Nœuds de precistiontree
PrecisionTree vous permet de définir les nœuds d'un diagramme d'influence et d'un arbre décisionnel dans vos feuilles de calcul Excel. Les types de nœuds suivants sont proposés :
nœuds aléatoires nœuds de décision nœuds finaux nœuds logiques nœuds de référence
Types de modèles
Les valeurs et les probabilités des nœuds s'introduisent directement dans les cellules de la feuille de calcul. La définition et l'édition de vos modèles de décision en est d'autant plus simple.
PrecisionTree crée des arbres décisionnels et des diagrammes d'influence. Les diagrammes d'influence révèlent parfaitement, de manière claire et concise, le rapport entre les événements et la structure générale d'une décision, tandis que les arbres décisionnels en suivent les détails chronologiques et numériques.
Valeurs des modèles
Dans PrecisionTree, toutes les valeurs et probabilités d'un modèle de décision se définissent essentiellement directement dans les cellules du tableau, comme dans tout autre modèle Excel. PrecisionTree peut aussi lier les valeurs d'un modèle de décision directement aux emplacements spécifiés dans un modèle du tableau. Les résultats de ce modèle servent ensuite au règlement de chaque voie de l'arbre décisionnel.
Tous les calculs de règlement s'effectuent en temps réel : lors de la modification de l'arbre, tous les règlements et toutes les valeurs de nœud se recalculent automatiquement.
Analyse de décision
Les analyses de décision de PrecisionTree produisent des rapports clairs de données statistiques, profils des risques et suggestions (version PrecisionTree Pro uniquement). L'analyse de décision peut du reste produire des résultats de nature plus qualitative utiles à une meilleure compréhension des compromis, des conflits d'intérêts et des objectifs importants.
Tous les résultats de l'analyse sont rapportés directement dans Excel pour faciliter les tâches de personnalisation, d'impression et d'enregistrement. Nul besoin d'apprendre de nouvelles commandes de formatage : tous les rapports PrecisionTree se modifient de la même manière que les feuilles de calcul et graphiques Excel.
Analyse de sensibilité
Vous est-il jamais arrivé de vous demander quelles étaient les variables les plus importantes de vos décisions ? Si oui, les options d'analyse de sensibilité de PrecisionTree vous seront utiles. Analyses de sensibilité à simple et double entrée, graphiques tornado et en toile d'araignée, graphiques de région stratégique (PrecisionTree Pro uniquement) : les possibilités sont presque infinies !
Pour les utilisateurs intéressés par des analyses de sensibilité plus sophistiquées, PrecisionTree est directement relié à TopRank, le compagnon de l'analyse de sensibilité de Palisade Corporation.
Réduction d'arbre
Pour gérer le développement des arbres décidentnels à mesure de l'ajout de nouvelles options possibles, PrecisionTree propose un ensemble de fonctions de réduction à des tailles plus abordables. La réduction des nœuds permet de masquer les branches au-delà de ces nœuds. Un même sous-arbre peut être référencé depuis plusieurs nœuds d'autres arbres, évitant ainsi la nécessité d'entrer plusieurs fois le même arbre.
Évaluation utilisateur
Il vous sera parfois utile de recourir à l'assistance de PrecisionTree pour créer une fonction utilitaire apte à introduire votre perception personnelle du risque dans les calculs de vos modèles de décision. Les fonctions de PrecisionTree vous aident à identifier vos perceptions à l'égard du risque et à créer vos propres fonctions utilitaires.
Options d'analyse expertes
PrecisionTree propose également de nombreuses options d'analyse experte :
- fonctions utilisées
- définition d'arbre par feuilles de calcul multiples nœuds logiques
@RISK avec precisiontree
@RISK est le compagnon idéal de PrecisionTree. @RISK vous permet de 1) quantifier l'incertitude des valeurs et probabilités qui définissent vos arbres décisionnels et 2) décrire plus précisément les événements aléatoires sous forme de plage continue d'issues possibles. Sur la base de ces informations, @RISK effectue une simulation Monte Carlo sur votre arbre décisionnel, analysant chaque issue possible et illustrant graphiquement les risques auxquels vous devez faire face.
@RISK pour quantifier l'incertitude
Avec @RISK, toutes les valeurs incertaines et probabilités des branches de vos arbres décisionnels et modèles de tableau correspondants peuvent être définies par des fonctions de distribution. Ainsi, si une branche de nœud aléatoire ou de décision présente une valeur incertaine, vous pouvez décrire cette valeur par une fonction de distribution @RISK. Lors d'une analyse de décision normale, la valeur probable de la fonction de distribution est utilisée comme valeur de la branche. La valeur probable d'une voie de l'arbre est calculée en fonction de cette valeur.
Toutefois, si une simulation @RISK est exécutée, un échantillon est prélevé dans chaque fonction de distribution à chaque itération. La valeur de l'arbre décisionnel et de ses nœuds est ensuite recalculée sur la base du nouvel ensemble d'échantillons et des résultats enregistrés par @RISK, et la plage de valeurs possibles s'affiche pour l'arbre décisionnel. Plutôt qu'un profil de risque assorti d'un ensemble discret d'issues possibles et de probabilités, @RISK génère une distribution continue des issues possibles. La probabilité de chaque résultat est ainsi apparente.
Description d'événements aléatoires sous forme de plage continue d'issues possibles
Dans les arbres décisionnels, les événements aléatoires se décrivent sous forme d'issues discrètes (nœud aléatoire assorti d'un nombre fini de branches de résultat). Dans la réalité, pourtant, beaucoup d'événements incertains sont continus : dans une plage min-max, n'importe quelle valeur est susceptible de se produire.
En combinaison avec PrecisionTree, @RISK facilite la modélisation d'événements continus, à travers ses fonctions de distribution. Les fonctions @RISK peuvent réduire la taille de votre arbre décisionnel et en faciliter la compréhension.
Méthodes de recalcul en cours de simulation
Deux options sont proposées pour le recalcul du modèle décisionnel en cours de simulation @RISK. Sous la première, Expected Values of the Model, @RISK commence par échantillonner toutes les fonctions de distribution du modèle et des feuilles de calcul à chaque itération, avant de recalculer le modèle en fonction des nouvelles valeurs et de générer ainsi une nouvelle valeur probable. La sortie de la simulation est généralement la cellule qui contient la valeur probable du modèle. En fin de simulation, le programme génère une distribution de sortie reflétant la plage possible des valeurs probables du modèle et leur probabilité relative.
Sous la seconde option, Values of One Sampled Path Through the Model, @RISK échantillonne aléatoirement une voie à travers le modèle à chaque iteration de la simulation. La branche à suivre à chaque nœud aléatoire se sélectionne aléatoirement en fonction des probabilités de branche définies. Cette méthode n'exige pas de fonctions de distribution dans le modèle. En leur présence, toutefois, @RISK génère un nouvel échantillon à chaque iteration et l'utilise dans les calculs des valeurs de la voie. La sortie de la simulation est la cellule qui contient la valeur du modèle (la valeur du nœud racine de l'arbre, par exemple). En fin de simulation, le programme génère une distribution de sortie reflétant la plage possible des valeurs de sortie du modèle et leur probabilité relative.
Distributions de probabilités dans les nœuds
Imaginons un nœud aléatoire dans un arbre décisionnel d'une entreprise de forage pétrolier.
Résultats de la décision de forage pour test d'ouverture
Les résultats du forage se répartissent en trois issues discrètes (Sec, Humide et Détrempé). En réalité, la quantité de pétrole découverte devrait être décrire par une distribution continue. Supposons que le produit financier du forage suit une distribution normale logarithmique caractérisée par une moyenne de 22 900 et un écart type de 50 000, soit la distribution @RISK = RiskLognorm(22900;50000).
Décision de forage avec distribution de probabilités
Pour appliquer cette fonction dans le modèle de forage, il faut changer le nœud aléatoire de manière à n'avoir plus qu'une branche, dont la valeur est définie par la fonction @RISK. Le nouveau modèle doit se présenter comme suit :
Décision forcée en cours de simulation
En cours de simulation @RISK, la fonction RiskLognorm renvoie des valeurs aléatoires pour la valeur de règlement du contrôle de résultats, et PrecisionTree calcule la nouvelle valeur probable de l'arbre.
Que dire, cependant, de la décision de forer ou non? Si la valeur probable du nœud Forer change, la décision optimale pourrait changer d'une itération à l'autre, ce qui impliquerait la connaissance de l'issue du forage avant la prise de décision. Pour éviter cette situation, l'option Decisions Follow Current Optimal Path de PrecisionTree permet de forcer les décisions avant l'exécution de la simulation @RISK. Chaque nœud de décision de l'arbre devient un nœud de décision forcée, sélectionnant la décision optimale à l'invocation de la commande. On évite ainsi les changements de décision imputables aux valeurs et probabilités variables d'un arbre décisionnel en cours d'analyse de risque.
Valeur de l'information parfaite
@RISK et analyse des options de décision
Pour connaître l'issue d'un événement aléatoire avant de prendre une décision, il faut connaître la valeur de l'information parfaite.
Avant l'analyse du risque, la valeur probable de la décision de forer ou non est celle du nœud de décision Forer. Si on soumettait le modèle à une analyse du risque sans décisions forcées, la valeur renvoyée du nœud de décision Forer refléterait la valeur probable de la décision si l'on pouvait prédire parfaitement l'issue. La différence entre les deux valeurs représentées de plus haut prix à consentir (par la réalisation d'autres tests, par exemple) à l'obtention d'informations complémentaires avant de prendre une décision.
Sélection de sorties @RISK
L'exécution d'une analyse de risque sur un arbre décisionnel peut produire différents types de résultats, suivant les cellules sélectionnées comme sorties dans le modèle. La vraie valeur probable, la valeur de l'information parfaite et les probabilités de voir peuvent être déterminées.
Nœud de départ
Sélectionnez la valeur d'un nœud de départ d'arbre (ou le début d'un sous-arbre quelconque) pour générer un profil de risque à partir d'une simulation @RISK. Comme les distributions @RISK génèrent une plus vaste plage de variables aléatoires, le graphique résultat est plus lisse et plus complet que le profil de risque discret classique.
Glossaire
| @RISK | @RISK (prononcé « at risk ») est le nom du compagnon Excel d'analyse du risque spécifique dans ce Guide de l'utilisateur. |
| Analyse de risque | Terme général utilisé pour déscrire toute méthode permettant d'étudier et de comprendre le risque inherent à une situation particulière. Les méthodes peuvent être de nature quantitative et (ou) qualitative. @RISK utilise une technique quantitative généralement désignée sous le nom de simulation.Voir Simulation |
| Aplâtissement | Mesure de la forme d'une distribution, plate ou culminante. Plus la valeur d'aplâtissement est élevé, plus la distribution est culminante.Voir Asymétrie |
| Asymétrie | Mesure de la forme d'une distribution. L'asymétrie indique le degré de dissymétrie dans une distribution. Les distributions asymétriques comportent un plus grand nombre de valeurs d'un côté de la valeur culminante ou valeur plus probable : une queue est beaucoup plus longue que l'autre. Une asymétrie nulle (0) indique une distribution symétrique, tandis qu'une asymétrie négative révèle une distribution désaxée vers la gauche et une asymétrie positive, une dissymétrie vers la droite.Voir Aplâtissement |
| Aversion | Voir Peu enclin à courir des risques |
| Centile | Increment des valeurs dans un groupe de données. Les centiles divisent les données en 100 parts égales, contenant chacune un pour cent des valeurs totales. Le 60e centile, par exemple, est la valeur de l'ensemble par rapport à laquelle 60 % des valeurs sont inférieures et 40 %, supérieures. |
| Déterministe | Terme indiquant l'absence d'incertitude dans une valeur ou variable donnée.Voir Stochastique, Risque |
| Distribution continue | Distribution de probabilités dans laquelle n'importe qu'elle valeur comprende entre le minimum et le maximum est possible (comporte une probabilité finie).Voir Distribution discrète |
| Distributioncumulative | Ensemble de points dont chacun représentée une distribution de probabilités intégrale commencing à la valeur minimale etaboutissant à la valeur associée de la variable aléatoire.Voir Distribution cumulative de féquences, Distribution de probabilités |
| Distributioncumulativede féquences | Termé désignant les distributions cumulatives en entrée et de sortie de @RISK. Une distribution cumulative se construit par cumul de la féquence (ajout progressif de hauteurs de barres) sur la plage d'une distribution de féquence. Une distribution cumulative peut être une courbe « à pente inclinée vers le haut », dans laquelle la distribution décrit la probabilité d'une valeur inférieure ou égale à une valeur variablequelconque. Elle peut aussi être « inclinée vers le bas», lorsque la distribution décrit la probabilité d'une valeur supérieure ou égale à une valeur variablequelconque.Voir Distribution cumulative |
| Distribution dedérquence | Termé correct désignant les distributions de probabilités de sortie et les histograms en entrée (HISTOGRM) de @RISK. Une distribution de féquence se construit à partir des données, moyonnant l'organisation des valeurs en classes et la représentation de la féquence de réalisation dans une classe qualconque par la hauteur de la barre. Cette féquence correspond à la probabilité. |
| Distribution dedistributés | Distribution de probabilités ou fonction de densité de probabilité est l'expression statistique correcte désignant une distribution de féquence construite à partir d'un ensemble de valeurs infiniment grand, où la taille des classes est infinitésimale.Voir Distribution de féquence |
| Distributiondiscrète | Distribution de probabilités dans laquelle seul est possible un nombre fini de valeurs discrètes compris entre le minimum et le maximum.Voir Distribution continu |
| Échantillon | Voir Échantillon aléatoire |
| Échantillonaléatoire | Valeur choisis dans une distribution de probabilités décrivant une variable aléatoire. Cet échantillon est prélevé au hasard selon un « algorithme » d'échantillonnage. La distribution de féquence construite à partir d'un grand nombre d'échantillons aléatoires prélevés par un tel algorithme se rapproche étroitement de la distribution de probabilités pour laquelle l'algorithmé a été concu. |
| Écart type | Mesure de la dispersion des valeurs d'une distribution, égale à la racine carrée de la variance. |
| Voir Variance | |
| Essai | Synonyme d'itération.Voir Itération |
| Événement | Termé désignant une issue ou un groupe d'issues susceptibles de résultat d'une action donnée. Si, par exemple, l'action considérée est le lancement d'un ballon de football, les événements possibles peuventporter un but, un corner, une descente, une faute, un hors-jeu, etc. |
| Graphique de synthèse | Graphique de sortie @RISK qui présente les résultats de la simulation pour une plage de cellules de feuille de calcul Excel. Le graphique de synthèse prend les distributions sous-jacentes de chaque cellule, en effectue la synthèse et présente la tendance des moyennes et deux mesures de chaque côte des moyennes. Ces deux mesures représentent par défaut les tendances des 10e et 90e centiles. |
| Hypercube latin | Technique d'échantillonnage stratifié relativement neuve utilisée dans la modélisation par simulation. Contrairement aux techniques de type Monte Carlo, les techniques d'échantillonnage stratifié tendent à forcer la convergence d'une distribution échantillonnée en moins d'échantillons.Voir Monte Carlo |
| Incertitude | Voir Risque |
| Itération | Désigne un recalcul du modele de l'utilisateur durant une simulation. Une simulation comprend de nombreux recalculs ou iterations. À chaque itération, toutes les variables incertaines sont échantillonnées une fois selon leur distribution de probabilités, et le modele est recalculated sur la base des valeurs échantillonnées.Aussi connu sous le terme d'essay de simulation |
| Moments élevés | Les moments élevés sont des statistiques de distribution de probabilités. Le terme désigne généralement l'asymétrie et l'aplaisissement, soit le troisième et le quatrième moment, respectivement. Les premier et deuxieme moments sont, respectivement, la moyenne et l'écart type.Voir Asymétrie, Aplaisissement, Moyenne, Écart type |
| Monte Carlo | Désigne la méthode traditionnelle d'échantillonnage devariables aléatoires dans la modélisation par simulation. Les échantillons sont sélectionnés au hasard sur la plage de la distribution, nécessitant des lors de nombreux échantillons pour la convergence des distributions hautement asymétriques ou à queueuge étalée.Voir Hypercube latin |
| Moyenne | La moyenne d'un ensemble de valeurs est la somme de toutes les valeurs de l'ensemble, divisée par le nombre total des valeurs qu'il contient. Synonyme : valeur probable |
| Peu enclin à courir des risques | Termé désignant une caractéristique générale des individus quant à leurs préférences en matière de risque. Lorsque le risque et l'avantage augmentent, l'individu se montre moins enclin à adopter une ligne de conduite visant à obtenir un avantage plus grand. Les personnes rationnelles sont généralement considérées comme peu enclines à courir des risques, bien que le degré d'aversion pour le risque varie de l'une à l'autre. Il existe des situations ou plages d'avantages dans lesquilles les personnes peuvent partager un comportement contraire, favorable à la prise de risques. |
| Plage | Différence absolue entre les valeurs maximum et minimum d'un ensemble de valeurs. La plage est la mesure la plus simple de la dispersion ou du « risque » d'une distribution. |
| Préférence | Désigne un choix individual face aux nombres attributs d'une décidision ou d'un d'objet. Le risque est une considération importante dans la préférence personnelle. Voir Peu enclin à courir des risques |
| Probabilité | Grandeur par laquelle on mesure la vraisemblance de réalisation d'une valeur ou d'un événement. Elle peut être mesurée à partir de données de simulation, sous forme de fréquence, par le calcul du nombre de réalisations de la valeur ou de l'évenement divisé par le nombre total de réalisations. Ce calcul renvoie une valeur comprise entre 0 et 1 qui, multipliee par 100, est alors convertie en pourcentage. Voir Distribution de fréquence, Distribution de probabilités |
| Racine / Générateur de nombres aléatoires | AlGORITHM régissant le choix des nombres aléatoires, généralement compris entre 0 et 1. Ces nombres aléatoires correspondent aux échantillons prélevés dans une distribution uniforme à valeur minimum de 0 et maximum de 1. Ils constituent la base d'autres sousprogrammes les convertissant en échantillons prélevés des types de distribution spécifique. Voir Échantillon aléatoire, Racine |
| Risque | Caractère incertain ou variable de l'issue d'un événement ou d'une décision. Dans de nombreux cas, la plage des issues possibles peut inclure des issues perçues telle une perte indésirable, et d'autres perçues comme un gain souhaitable. La plage des résultats possibles est souvent associée à différents niveaux de probabilité. |
| Risque objectif | Le risque objectif ou la probabilité objective désigne une valeur ou une distribution de probabilités qui est déterminée par une preuve |
| « objective » ou une théorie acceptée. Les probabilités associées à un risque objectif sont connues avec certitude.Voir Risque subjectif | |
| Risque subjectif | Le risque subjectif ou la probabilité subjective est une valeur ou distribution de probabilités déterminée par la meilleure estimation d'un individu, en fonction de ses connaissances, de son expertise et de son expérience personnelles. De nouvelles informations entraînent souvent la modification de telles estimations. Certains individus, raisonnant différément, peuvent ne pas être d'accord avec de telles estimations.Voir Risque objectif |
| Simulation | Technique selon laquelle un modele, tel qu'une feuille de calcul Excel, est calculé à de nombreuses reprises sur la base de différentes valeurs en entrée, dans le but d'obtenir une représentation complète de tous les scénarios susceptibles de se produit dans une situation incertaine. |
| Stochastique | Synonyme de risqué, incertain.Voir Risque, Déterministe |
| Troncation | Processus par lequel l'utiliseur désit une plage minimum-maximum pour une variable aléatoire différente de celle indiquée par le type de distribution de la variable. Une distribution tronquée comporte une plage plus limite que sa correspondante non tronquée car le minimum de troncation est supérieur au minimum de la distribution et (ou) le maximum de troncation est inférieur au maximum de la distribution. |
| Valeur de départ | Grandeur de départ de la sélection de nombres par un générateur de nombres aléatoires. Soumis à une même valeur de départ, un générateur de nombres aléatoires générera la même série de nombres aléatoires à chaque exécution de la simulation.Voir Générateur de nombres aléatoires |
| Valeur plus probable | La valeur la plus probable, ou mode, représentée la valeur le plus frequentlymment rencontres dans un ensemble de valeurs. Dans un histogramme et une distribution de résultats, il s'agit de la valeur centrale de la classe ou barre indiquant la probabilité la plus elevée. |
| Valeur probable | Voir Moyenne |
| Variable | Composante du modele de base pouvant prendre plusieurs valeurs. Si la valeur réelle n'est pas connue avec certitude, la variable est considérée comme incertaine. Une variable, certaine ou incertaine, peut être dépendante ou indépendante.Voir Variable dépendante, Variable indépendante |
Variable dépendante
Variable tributaire, dans une certaine mesure, des valeurs d'autres variables du modèle considéré. La valeur d'une variable dépendante incertaine peut être calculée dans une équation en tant que fonction d'autres variables incertaines du modèle. Elle peut aussi être tirée d'une distribution en fonction du nombre aléatoire corrélé à un nombre aléatoire utilisé pour prélever un échantillon de variable indépendante.
Voir Variable indépendante
Variable indépendante
Variable non tributaire des valeurs d'aucune autre variable du modèle considéré. La valeur d'une variable indépendante incertaine est déterminée par le prélèvement d'un échantillon dans la distribution de probabilités appropriée. L'échantillon est prélevé indépendamment de tout autre échantillon aléatoire prélevé pour les autres variables du modèle.
Voir Variable dépendante
Variance
Grandeur mesurant la plage de dispersion des valeurs dans une distribution, indiquant ainsi le « risque » de la distribution. Elle représente le carré moyen des écarts à la moyenne arithmétique. La variance donne un poids non proportionnel aux valeurs aberrantes distances de la moyenne. La variance est le carré de l'écart type.
Lectures par catégorie
Le Guide de l'utilisateur @RISK présente les notions élémentaires de l'analyse de risque et de la simulation. Si vous souhaitez approffondir vos connaissances de la technique d'analyse de risque et de la théorie sur laquelle elle s'appuie, les ouvrages et articles suivants en examinent différents aspects.
Introduction à l'analyse de risque
Si vous êtes débutant ou que vous souhaitez approfondir vos connaissances, les ouvrages et articles suivants peuvent se révéler utiles :
Les ouvrages suivants pourront vous renseigner davantage sur la question de l'ajustement des distributions.
Fonctions de distribution
Pour en apprendre davantage sur les fonctions de distribution utilisées par le logiciel d'ajustement BestFit de @RISK, ne manquez pas l'ouvrage suivant :
Références techniques à la simulation et aux techniques monte carlo
Si vous souhaitez approfondir vos connaissances en matière de simulation, techniques d'échantillonnage et théorie statistique, les ouvrages suivants peuvent se révéler utiles :
Iman, R. L., Conover, W. J. "A Distribution-Free Approach To Inducing Rank Correlation Among Input Variables": Commun. Statist.-Simul. Computa. (1982) 11(3), 311-334
Références techniques aux techniques d'échantillonnage hypercube latin
Si vous souhaitez obtenir des informations sur la technique relativement nouvelle de l'échantillonnage Hypercube latin, les sources suivantes peuvent se révéler utiles :
Iman, R. L., Davenport, J. M., et Zeigler, D. K. "Latin Hypercube Sampling (A Program Users Guide)": Technical Report SAND79-1473, Sandia Laboratories, Albuquerque (1980).
Exemples et études de cas faisant appel à l'analyse de risque
Si vous souhaitez examiner des études de cas démontrant l'utilisation de l'analyse de risque dans le cadre de situations réelles, consultez les ouvrages suivants:
Hertz, D. B. and Thomas, H. Practical Risk Analysis - An Approach Through Case Histories: John Wiley et Sons, New York, NY, 1984.
- Ces ouvrages et autres titres concernant l'analyse de risque peuvent être obtenus auprès de Palisade Corporation, par téléphone au +1-607-277-8000, par fax au +1-607-277-8001, ou par correspondance. Le service commercial technique de Palisade peut aussi être contacté par courriel à l'adresse suivante : sales@palisade.com ou sur Internet à l'adresse suivante : http://www.palisade.com.
Ajouter une sortie, commande 241
Ajustement 117, 698
Distributions prédéfinies 187
Données cumulatives 185
Données d'échantillon 183
Données de densité 184
Données en entrée 183,282,285,288,296
Limites de domaine 188
Sélection des distributions 187
Tests de qualité 196
Analyse de contrainte 335
Analyse de scénario 109, 139, 167
Analyse de sensibilité 380
Analyse de sensibilité
Avancée 348-49, 348-49
Standard. 108, 137, 380
Arrêt automatique 126
Étendue ou réduite 403, 407, 415
Bibliothèque @RISK
Actualisation des distributions 647
Racines des distributions 644
Résultats dans la Bibliothèque 649
Centiles
Calcul de cibles 129 Cumulatifs décroissants 374 Fonction de tableau 622 Fonctions du tableau 617
Statistiques 292
Collecte d'échantillons de distribution 318
Commande A propos 417
Commande Afficher la barre d'outils étendue 403, 407, 415
Commande Analyse de sensibilité avancée 349, 350
Commande d'autorisation 417
Commande Définir les corrélations 255
Commande Définir les distributions 225
Commande Démarrer la simulation 323
Commande Données 376
Commande Insérer une fonction 249
Commande Insérer une ligne/colonne 261
Commande Options des données en entrée 282, 285, 288, 296
Commande Paramètres de simulation 305
Commande Paramètres des rapports 281, 300, 365
Commande Scénarios 385, 393
Commande Statistiques détaillées 373
Commande : Vérifier la cohérence de la matrice 263
Commandes d'instance 259
Compagnon @RISK
Barre d'outils 213,217,219,220
Compagnon, @RISK 43, 223
Compatibilité 15
Configuration requise 6
Vérifier la cohérence de la matrice 263
Correlations 255
Cumulatif décroissant Voir Centiles cumulatifs décroissants
Suite 8,669
Définir une distribution, fenêtre 50, 55, 59, 101, 114
Délimiteurs Voir Graphiques, délimiteurs
Désinstallation de @RISK. 7
Didactiel. 13, 99
Distribution
Décalage 606, 607
Fonctions 453, 698
Troncation 608
Distributions
Ajustement. Voir Ajustement
Échantillonnage Hypercube latin 664
Échantillonnage Monte Carlo 663
Entrées
Ajout. 111
Collecte d'échantillons de distribution 596, 597, 614
Noms 595,605,609
Verrouillage 603, 604
Erreur de moyenne quadratique 292
Estimateurs du maximum de vraisemblance (EMV) 189
Études de cas 700
Graphiques. Voir Graphiques, format Excel
Rapports. Voir Rapports, Excel
Fenêtre
Résultats de l'ajustement 291
Définir une distribution
Liaison avec les ajustements 202
Fenêtres
Définir une distribution.... Voir Définir une distribution, fenêtre
Fenêtre Analyse de scénario 385, 393
Fenêtre d'analyse de sensibilité 380
FenêtreDonnées 376
Fenêtre Statistiques détaillées 373
Modèle Voir Modèle, fenêtre
Résultats. Voir Résultats, fenêtre
Résultats d'ajustement 298
Filtres
Données d'entrée 185
Résultat 390
Fonctions de distribution 100
Fonctions de propriété Voir Fonctions de risque, propriété
Fonctions de risque
Décalage 606, 607
Fonctions de propriété 595
Fonctions statistiques 48, 463, 613 120 RiskBeta. 480 RiskBetaGeneral 482 RiskBetaGeneralAlt. 485 RiskBetaSubj 486 RiskBinomial 489 RiskCategory 595 RiskChiSq 492 RiskCollect 318,596,614 RiskCompound 494 RiskConvergence 597 RiskCorrectCorrmat 637 RiskCorrel. 614 RiskCormat. 268, 598 RiskCumul 495 RiskCumulD 498 RiskCurrentIter 464, 637 RiskCurrentSim 464, 638 RiskData 615 RISKData. 472 RiskDepC. 600 RiskDiscrete. 151, 501 RiskDUniform 504 RiskErf. 507 RiskErlang 509 RiskExpon 511 RiskExponAlt 513 RiskExtValue 513 RiskExtValueAlt. 515 RiskFit 602 RiskGamma 516 RiskGammaAlt 518 RiskGeneral 519 RiskGeomet 522 RiskHistogrm 524 RiskHypergeo 527 RiskIndepC 603 RiskIntUniform 530 RiskInvgauss 532 RiskInvgaussAlt. 534 RiskIsDate 604 RiskIsDiscrete 603 RiskKurtosis 615, 620 RiskLibrary 604 RiskLock. 604 RiskLogistic. 541 RiskLogisticAlt. 543 RiskLogLogistic 544
RiskLogLogisticAlt 546
RiskLognorm 547
RiskLognorm2 551
RiskLognormAlt. 550
RiskMakeInput 553
RiskMax 616, 620
RiskMin 616, 621
RiskMode 617, 621
RiskName 605
RISKName 609
RiskNegbin 554
Risque Normal. 556
Risque Normal Alt. 559
RiskOutput 612
Risque Pareto. 560
RisquePareto2. 563
RisquePareto2Alt. 565
RiskParetoAlt 562
Risque Pearson5 566
RiskPearson5Alt 568
RiskPearson6Alt 569
RiskPercentile 617, 622
RiskPert 571
Risque Pert Alt 573
Risque Poisson 574
RiskRange 617, 622
RiskRayleigh 576
RiskRayleighAlt 578
Graphiques 130 Boîte à moustaches 344 Délimiteurs 132 Diagrammes de dispersion 435 Formatage 133 Graphique de synthèse 133 Graphique tornado 138, 167 Graphiques de synthèse 440 Superpositions. 131, 426 Graphiques Graphique tornado 140 Graphiques Graphique tornado 389 Graphiques Graphique tornado 432 Graphiques Graphique tornado 434
Histogrammes. Voir Graphiques, histograms. Hypercube latin 699.
Icones Bureau. 8 Insérer une fonction 249 Installation 6 Instances multiples. Voir Correlation, instances Itération 105, 306
Kolmogorov-Smirnov (K-S) Statistique 292
Masques Voir Rapports, masques
Menus
Menu Aide (Fenêtre Modèle) 417
Menu Modèle (Compagnon @RISK) 225
Menu Résultats (Compagnon @RISK) 365
Menu Simuler (Compagnon @RISK) 323
Menu Simuler (Compagnon @RISK) 281,305
Mise à niveau 38-39
Modèle, fenêtre 120, 270
Modèles types 142-43
CLAIMS. XLS 153
CORRMAT.XLS. 157
DEP. XLS 157
DISCRETE. XLS. 151
ERROR. XLS 155
RATE. XLS 147
VARIABLE. XLS 149
Modélisation 142-43
Événements aléatoires 151
Incertainautauteur d'une tendance fixe 155
Lancement d'un nouveau produit 161
Puits de pétrole 153
Relations de dépendance 157
Sinistres d'assurance 153
Taux d'intérêt 147
Tendances aléatoires 147
Tournoi de la NCAA 175
Trajets aléatoires 148
Valeur à risques (VAR) 171
Variabilité en fonction du temps 149
Moindres carrés, méthode 191
Monte-Carlo 699
Ouvrir des simulations @RISK 408
Palisade Corporation 5
Paramètres
Variables. 157
Paramètres de simulation 122
Pause sur erreur 312
PrecisionTree 674, 682-83
Rapports Excel 141 Masque 142 Paramètres 281, 300, 365
Rapports sommaires. Voir Rapports, rapides Références circulaires 307 Régression 381
Risk Functions RiskJohnsonMoments 535 RiskJohnsonSB 537 RiskJohnsonSU 539 RiskResample 578 RiskSplice 581
Simulation Arrêt 126 Démarrage 124 Démarrer 323
Sorties Ajout. 102,241 Liste. 120
Statistique Chi-carré 292
Statistiques Ajustement 196 Anderson-Darling (A-D) 292 Détailés 373 Erreur de moyenne quadratique 292 Kolmogorov-Smirnov (K-S) 292 Surveillance de convergence 125 Synthèse des résultats, fenêtre 128, 366
TopRank 669, 673, 675 Troncation. 608
UC multiples 308
Valeur cible 327
Valeur de départ, aléatoire 308
Valeurs critiques 198
Valeurs P 198
Version étudiants 6

- VERSION 5.5
- AVIS DE COPYRIGHT
- RISK POUR MICROSOFT EXCEL
- NÉCESSITÉ DE L'ANALYSE DE RISQUE ET DE @RISK
- FONCTIONS DE MODÉLISATION
- ANALYSE DE SIMULATION @RISK
- GRAPHIQUES
- CAPACITÉS DE SIMULATION EXPERTES
- AFFICHAGES GRAPHIQUES À HAUTE RÉSOLUTION
- VITESSE D'EXÉCUTION
- TABLE DES MATIÈRES
- CHAPITRE 1 : MISE EN ROUTE
- INSTALLATION 7
- DÉMARRAGE RAPIDE 13
- CONTENU DU COFFRET
- VOTRE CONTEXTE D'EXPLOITATION
- SI VOUS AVEZ BESOIN D'AIDE
- AVANT D'APPELER
- CONTACTER PALISADE
- CONFIGURATION REQUISE
- GÉNÉRALITÉS
- CONFIGURATION DES ICÔNES OU RACCOURCIS @RISK
- MESSAGES D'AVERTISSEMENT DE SÉCURITÉ DES MACROS AU DÉMARRAGE
- ACTIVATION DU LOGICIEL
- FOIRE AUX QUESTIONS
- DIDACTICIEL EN LIGNE
- POUR DÉMARRER VOUS-MÊME
- DÉMARRAGE RAPIDE AVEC VOS PROPRES FEUILLES DE CALCUL
- FEUILLES DE CALCUL @RISK 5.5 SOUS LES VERSIONS @RISK 3.5 ET ANTÉRIEURES
- FEUILLES DE CALCUL @RISK 5.5 SOUS LA VERSION @RISK 4.0
- FEUILLES DE CALCUL @RISK 5.5 SOUS LA VERSION @RISK 4.5
- CHAPITRE 2: PRÉSENTATION DE L'ANALYSE DE RISQUE
- DÉFINITION DU RISQUE
- CARACTÉRISTIQUES DU RISQUE
- NÉCESSITÉ DE L'ANALYSE DU RISQUE
- ÉVALUATION ET QUANTIFICATION DU RISQUE
- DESCRIPTION DU RISQUE AVEC UNE DISTRIBUTION DE PROBABILITÉS
- DÉFINITION DE L'ANALYSE DE RISQUE
- ÉLABORATION D'UN MODÈLE @RISK
- VARIABLES
- INDÉPENDANTES OU DÉPENDANTES
- VARIABLES DE SORTIE
- ANALYSE D'UN MODÈLE AVEC SIMULATION
- SIMULATION
- FONCTIONNEMENT DE LA SIMULATION
- AUTRE APPROCHE DE LA SIMULATION
- PRISE DE DÉCISION : INTERPRÉTATION DES RÉSULTATS
- INTERPRÉTATION D'UNE ANALYSE TRADITIONNELLE
- PRÉFÉRENCES INDIVIDUELLES
- ÉTALEMENT DE LA DISTRIBUTION
- ASYMÉTRIE
- LIMITES DE L'ANALYSE DE RISQUE
- CHAPITRE 3 : GUIDE DE MISE À NIVEAU
- NOUVELLES BARRES D'OUTILS, ICÔNES ET COMMANDES @RISK
- NOUVELLES ICÔNES
- CONSTRUCTION D'UN MODÈLE @RISK
- NOUVELLES FONCTIONS @RISK ET FONCTIONS AMÉLIORÉES DANS EXCEL
- FONCTIONS DE CONVERGENCE
- FONCTION DE COMMANDE DE SIMULATION
- DÉFINITION DES DISTRIBUTIONS DE PROBABILITÉS DANS LE TABLEAU
- ÉVALUATION GRAPHIQUE DES PROBABILITÉS
- ENTRÉE DE VALEURS D'ARGUMENT
- TYPE DE PARAMÈTRES
- CHANGEMENT DE TYPE DE GRAPHIQUE
- PERSONNALISATION D'UN GRAPHIQUE
- CORRÉLATION DES DISTRIBUTIONS DE PROBABILITÉS
- DIAGRAMMES DE DISPERSION ET CORRÉLATIONS
- PLACEMENT D'UNE MATRICE DANS EXCEL
- PASSAGE EN REVUE DES CORRÉLATIONS SIMULÉES
- SÉRIE TEMPORELLE CORRÉÉE
- DÉFINITION DES SORTIES DE SIMULATION DANS LE TABLEAU
- EXAMEN D'UN MODÈLE DANS LA FENÊTRE @RISK MODÈLE
- PERSONNALISATION DES STATISTIQUES AFFICHÉES
- CATÉGORISATION DES ENTRÉES
- PROPRIÉTÉS DE DISTRIBUTIONS EN ENTRÉES ET SORTIES DE SIMULATION
- PERMUTATION DES FONCTIONS @RISK
- DÉFINITION DE DISTRIBUTIONS À PARTIR DES DONNÉES
- PARAMÈTRES DE SIMULATION
- SIMULATIONS
- RÉSULTATS GRAPHIQUES D'UNE SIMULATION
- MODE PARCOURS
- FENÊTRE @RISK — SYNTHÈSE DES RÉSULTATS
- DÉPLACEMENT DES GRAPHIQUES PAR GLISSEMENT
- MULTIPLICITÉ GRAPHIQUE
- NOUVEAUX GRAPHIQUES @RISK 5.5
- GRAPHIQUES DE SYNTHÈSE
- DIAGRAMMES DE DISPERSION
- DIAGRAMMES DE DISPERSION DE CORRÉLATIONS SIMULÉES
- SUPERPOSITION DE DIAGRAMMES DE DISPERSION
- PERSONNALISATION ET RAPPORT GRAPHIQUES @RISK
- GRAPHIQUE @RISK DANS WORD AVEC STATISTIQUES
- RAPPORTS DE RÉSULTATS DE SIMULATION
- FENÊTRE DONNÉES
- FENÊTRE DE SENSIBILITÉ
- MATRICE DE DIAGRAMMES DE DISPERSION DANS LA FENÊTRE DE SCÉNARIOS
- EXPORTATION DES RAPPORTS VERS EXCEL
- ENREGISTREMENT DES SIMULATIONS
- BIBLIOTHÈQUE @RISK
- PRÉSENTATION RAPIDE DE @RISK. 99
- CONFIGURATION ET SIMULATION D'UN MODÈLE @RISK 111
- PRÉSENTATION RAPIDE DE @RISK
- PROCÉDURE DE L'ANALYSE DE RISQUE
- COMMENT @RISK SE « LIE » À EXCEL
- ENTRÉE DE DISTRIBUTIONS DANS LES FORMULES D'UN CLASSEUR
- SORTIES DE SIMULATION
- FENÊTRE MODÈLE
- EXÉCUTION D'UNE SIMULATION
- RÉSULTATS DE LA SIMULATION
- RAPPORTS EXCEL D'UNE SIMULATION @RISK
- CAPACITÉS ANALYTIQUES EXPERTES
- ANALYSE DE SCÉNARIO
- CONFIGURATION ET SIMULATION D'UN MODÈLE @RISK
- DISTRIBUTIONS DE PROBABILITÉS DANS UNE FEUILLE DE CALCUL
- CORRÉLATION DES VARIABLES EN ENTRÉE
- MATRICE DÉCORRÉLATION
- AJUSTEMENT DE DISTRIBUTIONS AUX DONNÉES
- OPTIONS D'AJUSTEMENT
- RAPPORTS D'AJUSTEMENT
- PLACEMENT D'UN RÉSULTAT D'AJUSTEMENT DANS EXCEL
- GESTIONNAIRE D'AJUSTEMENT
- FENÊTRE @RISK MODÈLE
- FENÊTRE @RISK SYNTHÈSE DES RÉSULTATS
- FENÊTRE STATISTIQUES DÉTAILLÉES
- CIBLES
- RÉPRÉSENTATION GRAPHIQUE DES RÉSULTATS
- SUPERPOSITION DE GRAPHIQUES À COMPARER
- DÉLIMITEURS
- FORMATAGE DES GRAPHIQUES
- BOÎTE DE SYNTHÈSE
- RÉSULTATS DE L'ANALYSE DE SENSIBILITÉ
- RÉSULTATS DE L'ANALYSE DE SCÉNARIO
- RAPPORTS EXCEL
- CHAPITRE 5 : TECHNIQUES DE MODÉLISATION @RISK
- PROJECTION DE TENDANCES
- AUGMENTATION DE L'INCERTITUDE DANS LE TEMPS
- LES INONDATIONS VONT-ELLES SE PRODUIRE OU UN CONCURRENT VA-T-IL ENTRER SUR LE MARCHÉ
- MODÉLISATION D'UN NOMBRE INCERTAIN D'ÉVÉNEMENTS, COMPTANT CHACUN DES PARAMÈTRES INCERTAINS
- JE DOIS UTILISER CETTE PROJECTION MAIS ELLE NE M'INSPIRE PAS CONFIANCE
- UTILISATION D'ARGUMENTS VARIABLES ET DE CORRÉLATIONS - CES VALEURS SERONT AFFECTÉES PAR DES ÉVÉNEMENTS SURVENANT AILLEURS
- ARGUMENTS VARIABLES
- CORRÉLATIONS DANS L'ÉCHANTILLONNAGE
- DANS QUELLE MESURE LES CHANGEMENTS APPORTÉS AUX VARIABLES DU MODÈLE AFFECTENT-ILS LES RÉSULTATS DE LA SIMULATION
- ATTENTION
- ANALYSE DE SENSIBILITÉ AVANCÉE
- L'EXEMPLE « HIPPO
- FIGURE 28.2
- PAS À PAS
- GRAPHIQUES TORNADES ET SCÉNARIOS
- IDENTIFICATION DE LA VALEUR À RISQUES (VAR) D'UN PORTEFEUILLE
- SOLUTION
- SIMULATION D'UN TOURNOI DE LA NCAA
- REMARQUES
- CHAPITRE 6 : AJUSTEMENT DE DISTRIBUTIONS
- DÉFINITION DES DONNÉES EN ENTRÉE
- DONNÉES D'ÉCHANTILLON
- CONDITIONS À REMPLIR
- DONNÉES DE DENSITÉ
- NORMALISATION DES DONNÉES DE DENSITÉ
- DONNÉES CUMULATIVES
- INTERPOLATION
- FILTRAGE DES DONNÉES
- SÉLECTION DES DISTRIBUTIONS À AJUSTER
- DISTRIBUTIONS CONTINUES OU DISCRÈTES
- PARAMÈTRES ESTIMÉS OU DISTRIBUTIONS PRÉDÉFINIES
- LIMITES DE DOMAINE
- LIMITE FIXE
- OUVERTE
- INCERTAINE
- EXÉCUTION DE L'AJUSTEMENT
- DONNÉES D'ÉCHANTILLON — ESTIMATEURS DU MAXIMUM DE VRAISEMBLANCE (EMV)
- DÉFINITION
- PAR EXEMPLE
- ADAPTATIONS DE LA MÉTHODE EMV
- DONNÉES DE COURBE — MÉTHODE DES MOINDRES CARRÉS
- INTERPRÉTATION DES RÉSULTATS
- GRAPHIQUES P-P
- GRAPHIQUES Q-Q
- STATISTIQUES DE BASE ET CENTILES
- STATISTIQUES D'AJUSTEMENT
- STATISTIQUE KOLMOGOROV-SMIRNOV (K-S)
- STATISTIQUE ANDERSON-DARLING (A-D)
- ERREUR DE MOYENNE QUADRATIQUE
- VALEURS P ET VALEURS CRITIQUES
- VALEURS P
- VALEURS CRITIQUES
- EXPORTATION DES GRAPHIQUES ET DES RAPPORTS
- UTILISATION DES DISTRIBUTIONS AJUSTÉES DANS EXCEL
- RÉFÉRENCE : ICONES @RISK 213
- COMMANDES MODÈLE 225
- COMMANDES D'AJUSTEMENT DE DISTRIBUTIONS 281
- COMMANDES DISTRIBUTION ARTIST 301
- COMMANDES PARAMÈTRES 305
- COMMANDES SIMULATION 323
- VALEUR CIBLE 327
- ANALYSE DE CONTRAINTE 335
- ANALYSE DE SENSIBILITÉ AVANCÉE 349
- COMMANDES RÉSULTATS 365
- RÉFÉRENCE : FONCTIONS DE PROPRIÉTÉ DES DISTRIBUTIONS. 595
- RÉFÉRENCE : FONCTIONS DE SORTIE 611
- RÉFÉRENCE : FONCTIONS STATISTIQUES 613
- RÉFÉRENCE : FONCTIONS SIX SIGMA 625
- RÉFÉRENCE : FONCTIONS SUPPLÉMENTAIRES 637
- BARRE D'OUTILS PRINCIPALE @RISK (EXCEL 2003 ET VERSIONS ANTÉRIEURES)
- BARRE DE PARAMÈTRES @RISK (EXCEL 2003 ET VERSIONS ANTÉRIEURES)
- ICÔNES DES FENÊTRES GRAPHIQUES
- RÉFÉRENCE : COMMANDES @RISK
- COMMANDE DÉFINIR LES DISTRIBUTIONS
- DÉFINIR UNE DISTRIBUTION, FENÊTRE
- PALETTE DES DISTRIBUTIONS
- VALEURS PAR DÉFAUT DES DISTRIBUTIONS À PARAMÈTRES SECONDAIRES
- ICÔNES DU VOLET DES ARGUMENTS DE DISTRIBUTION
- PROPRIÉTÉS D'ENTRÉE
- COMMANDE AJOUTER UNE SORTIE
- FONCTIONS RISKOUTPUT
- NOM DE SORTIE
- AJOUT D'UNE PLAQUE DE SORTIE DE SIMULATION
- PROPRIÉTÉS DE SORTIE
- COMMANDE INSÉRER UNE FONCTION
- CATÉGORIES DISPONIBLES DE FONCTIONS @RISK
- GÉRER LES FAVORITES
- BOUTONS DE LA FENÊTRE GRAPHIQUE INSÉRER UNE FONCTION
- PROPRIÉTÉS D'ENTRÉE DANS LA FENÊTRE GRAPHIQUE INSÉRER UNE FONCTION
- COMMANDE DÉFINIR LES CORRÉLATIONS
- ENTRÉE DES COEFFICIENTS DE CORRÉLATION
- INSTANCES DE MATRICE
- VÉRIFIER LA COHÉRENCE DE LA MATRICE
- MATRICE DES PONDÉRATIONS D'AJUSTEMENT DANS EXCEL
- AJOUT D'UNE MATRICE DE CORRÉLATION AU MODÈLE EXCEL
- SPÉCIFICATION DES CORRÉLATIONS AVEC LES FONCTIONS
- COMPRENDRE LES VALEURS DE COEFFICIENT DE CORRÉLATION DES RANGS
- COMMANDE AFFICHER LA FENÊTRE MODÈLE
- FENÊTRE MODÈLE — ONGLET ENTRÉES
- COLONNES AFFICHÉES DANS LA FENÊTRE MODÈLE
- MENU GRAPHIQUE
- FENÊTRE MODÈLE — ONGLET SORTIES
- FENÊTRE MODÈLE — ONGLET CORRÉLATIONS
- COMMANDE AJUSTER LES DISTRIBUTIONS AUX DONNÉES
- ONGLET DONNÉES — COMMANDE AJUSTER LES DISTRIBUTIONS AUX DONNÉES
- OPTIONS TYPE D'ENSEMBLE DE DONNÉES
- OPTIONS FILTRE
- ONGLET DISTRIBUTIONS À AJUSTER — COMMANDE AJUSTER LES DISTRIBUTIONS AUX DONNÉES
- MÉTHODE D'AJUSTEMENT
- ONGLET INTERVALLES CHI CARRÉ — COMMANDE AJUSTER LES DISTRIBUTIONS AUX DONNÉES
- FENÊTRE RÉSULTATS DE L'AJUSTEMENT
- CLASSEMENT
- RÉSULTATS D'AJUSTEMENT — GRAPHIQUES
- GRAPHIQUE Q-Q
- COMMANDE CELLULE — FENÊTRE RÉSULTATS D'AJUSTEMENT
- FENÊTRE DE SYNTHÈSE D'AJUSTEMENT
- COMMANDE GESTIONNAIRE D'AJUSTEMENT
- ÉCRIRE DANS UNE CELLULE
- COMMANDE DES PARAMÈTRES DE SIMULATION
- ONGLET GÉNÉRAL — COMMANDE PARAMÈTRES DE SIMULATION
- SIMULATIONS NOMMÉES
- EN L'ABSENCE DE SIMULATION, LES DISTRIBUTIONS RENVOIENT... OPTIONS
- ONGLET AFFICHAGE — COMMANDE PARAMÈTRES DE SIMULATION
- ONGLET ÉCHANTILLONNAGE — COMMANDE PARAMÈTRES DE SIMULATION
- AUTRES OPTIONS D'ÉCHANTILLONNAGE
- ONGLET MACROS — COMMANDE PARAMÈTRES DE SIMULATION
- ONGLET CONVERGENCE — COMMANDE PARAMÈTRES DE SIMULATION
- COMMANDE DEMARRER LA SIMULATION
- ACTUALISATION EN TEMPS RÉEL
- SIMULATION — ANALYSES AVANCÉES
- PARAMÈTRES DE SIMULATION DES ANALYSES AVANCÉES
- CONFIGURE ET EXÉCUTE UNE ANALYSE VALEUR CIBLE @RISK
- BOÎTE DE DIALOGUE VALEUR CIBLE — COMMANDE VALEUR CIBLE
- BOÎTE DE DIALOGUE OPTIONS DE VALEUR CIBLE — COMMANDE VALEUR CIBLE
- EXÉCUTÉ L'ANALYSE VALEUR CIBLE
- COMMANDE ANALYSE DE CONTRAINTE
- BOÎTE DE DIALOGUE ANALYSE DE CONTRAINTE — COMMANDE ANALYSE DE CONTRAINTE
- BOÎTE DE DIALOGUE DÉFINITION D'ENTRÉE — COMMANDE ANALYSE DE CONTRAINTE
- BOÎTE DE DIALOGUE OPTIONS DE CONTRAINTE — COMMANDE ANALYSE DE CONTRAINTE
- EXÉCUTER UNE ANALYSE DE CONTRAINTE
- RAPPORT DE SYNTHÈSE
- RAPPORT SOMMAIRE
- COMMANDE ANALYSE DE SENSIBILITÉ AVANCÉE
- BOÎTE DE DIALOGUE ANALYSE DE SENSIBILITÉ AVANCÉE — COMMANDE ANALYSE DE SENSIBILITÉ AVANCÉE
- DÉFINITION D'ENTRÉE — COMMANDE ANALYSE DE SENSIBILITÉ AVANCÉE
- OPTIONS — COMMANDE ANALYSE DE SENSIBILITÉ AVANCÉE
- ANALYSER — COMMANDE ANALYSE DE SENSIBILITÉ AVANCÉE
- RAPPORTS
- SYNTHÈSE
- GRAPHIQUES D'ENTRÉE ET BOÎTES À MOUSTACHES
- GRAPHIQUE DES CENTILES
- COMMANDE PARCOURS DES RÉSULTATS
- COMMANDE FENÊTRE SYNTHÈSE DES RÉSULTATS
- COMMANDE STATISTIQUES DÉTAILLÉES
- AFFICHE LA FENÊTRE DONNÉES
- TRI DE LA FENÊTRE DONNÉES
- COMMANDE SENSIBILITÉS
- RÉGRESSION ET CORRELATION
- DÉFINITION DE LA RÉGRESSION MULTIDIMENSIONNELLE EN ESCALIER
- DÉFINITION DES VALEURS MAPPÉES
- DÉFINITION DE LA CORRÉLATION
- DÉFINITION DE LA CORRÉLATION DES RANGS
- COMPARAISON DES MÉTHODES
- MATRICE DE DIAGRAMMES DE DISPERSION
- AFFICHE LA FENÊTRE ANALYSE DE SCÉNARIO
- REMARQUE: LES PARAMÈTRES DE SCÉNARIO PAR DÉFAUT PEUVENT ÊTRE CONFIGURÉS SOUS PARAMÈTRES D'APPLICATION
- GRAPHIQUE TORNADO DE SCÉNARIOS
- FILTRE LES VALEURS DES CALCULS STATISTIQUES ET GRAPHIQUES DE SIMULATION
- FILTRER DEPUIS UNE FENÊTRE GRAPHIQUE
- COMMANDE RAPPORTS EXCEL
- COMMANDE PERMUTER LES FONCTIONS @RISK
- OPTIONS DE PERMUTATION
- OPTIONS DE PERMUTATION - ACTIVATION
- COMMANDE PARAMÈTRES D'APPLICATION
- PARAMÈTRES D'APPLICATION À L'EXPORTATION ET À L'IMPORTATION
- COMMANDE FENÊTRES
- COMMANDE OUVRIR UN FICHIER DE SIMULATION
- COMMANDE SUPPRIMER LES DONNÉES @RISK
- COMMANDE DÉCHARGER LE COMPAGNON @RISK
- OUVREZ ET ENREGISTREZ LES RÉSULTATS ET GRAPHIQUES DE SIMULATION
- COMMANDES BIBLIOTHÈQUE
- AJOUTER LES RÉSULTATS À LA BIBLIOTHÈQUE
- AFFICHER LA BIBLIOTHÈQUE
- AIDE @RISK
- MANUEL EN LIGNE
- COMMANDE D'ACTIVATION DE LICENCE
- COMMANDE À PROPOS
- RÉFÉRENCE : GRAPHIQUES @RISK
- GRAPHIQUES DES SIMULATIONS MULTIPLES
- HISTOGRAMMES ET GRAPHIQUES CUMULATIFS
- AJUSTER UNE DISTRIBUTION À UN RÉSULTAT SIMULÉ
- GRAPHIQUES « TORNADOES
- TYPES DE GRAPHIQUES TORNADOES
- DÉLIMITEURS DE DIAGRAMME DE DISPERSION
- CLICS DE FORMATAGE GRAPHIQUE
- RÉFÉRENCE : FONCTIONS @RISK
- FONCTIONS DE DISTRIBUTION
- AJUSTEMENT DES DONNÉES AUX DISTRIBUTIONS
- FONCTIONS DE PROPRIÉTÉ DES DISTRIBUTIONS
- TRONCATION DANS LES VERSIONS ANTÉRIEURES DE @RISK
- PARAMÈTRES SECONDAIRES
- TYPES DE PARAMÈTRES SECONDAIRES
- ARGUMENTS FACULTATIFS
- REMARQUE IMPORTANTE SUR LES MATRICES EXCEL
- INFORMATIONS COMPLÉMENTAIRES
- FONCTIONS DE SORTIE DE SIMULATION
- FONCTIONS STATISTIQUES DE SIMULATION
- STATISTIQUES DANS LES MASQUES DE RAPPORT
- FONCTION GRAPHIQUE
- FONCTIONS SUPPLÉMENTAIRES
- TABLEAU DES FONCTIONS DISPONIBLES
- RÉFÉRENCE : FONCTIONS DE DISTRIBUTION
- RÉFÉRENCE : FONCTIONS DE PROPRIÉTÉ DES DISTRIBUTIONS
- RÉFÉRENCE : FONCTIONS DE SORTIE
- RÉFÉRENCE : FONCTIONS STATISTIQUES
- RÉFÉRENCE : FONCTIONS SIX SIGMA
- RISKPNC
- RÉFÉRENCE : FONCTIONS SUPPLÉMENTAIRES
- RÉFÉRENCE : FONCTION GRAPHIQUE
- DISTRIBUTIONS DANS LA BIBLIOTHÈQUE @RISK
- REPRÉSENTATION GRAPHIQUE D'UNE DISTRIBUTION
- RÉSULTATS DANS LA BIBLIOTHÈQUE @RISK
- REPRÉSENTATION GRAPHIQUE D'UN RÉSULTAT DANS LA BIBLIOTHÈQUE
- NOTES TECHNIQUES
- CRÉATION D'UNE NOUVELLE BIBLIOTHÈQUE
- AUTRES DÉTAILS SUR SQL SERVER EXPRESS
- CAPACITÉ DE LA BIBLIOTHÈQUE
- RÉFÉRENCE : KIT DE DÉVELOPPEMENT @RISK POUR EXCEL (XDK)
- ANNEXE A : MÉTHODES D'ÉCHANTILLONNAGE
- DÉFINITION DE L'ÉCHANTILLONNAGE
- DISTRIBUTION CUMULATIVE
- ÉCHANTILLONNAGE MONTE CARLO
- ÉCHANTILLONNAGE HYPERCUBE LATIN
- TEST DES TECHNIQUES
- INFORMATIONS SUPPLÉMENTAIRES SUR LES TECHNIQUES D'ÉCHANTILLONNAGE
- ANNEXE B : UTILISATION DE @RISK AVEC D'AUTRES OUTILS DECISIONTOOLS®
- ACHAT DES PRODUITS PALISADE
- DECISIONTOOLS — ÉTUDE DE CAS
- DÉCISION À L'AIDE DE PRECISIONTREE
- TOPRANK ET L'ANALYSE D'HYPOTHÈSES
- APPLICATIONS TOPRANK
- ANALYSE D'HYPOTHÈSE MULTIVOIE
- FONCTIONS TOPRANK
- ENTRÉE DES FONCTIONS TOPRANK
- HYPOTHÈSES AUTOMATISÉES
- EXÉCUTION D'UNE ANALYSE D'HYPOTHÈSE
- RÉSULTATS TOPRANK
- RISK AVEC TOPRANK
- PASSAGE DE L'HYPOTHÈSE À LA SIMULATION
- DIFFÉRENCES ENTRE TOPRANK ET @RISK
- SIMILARITÉS
- DIFFÉRENCES
- ENTRÉES
- CALCULS
- RÉSULTATS
- POURQUOI L'ANALYSE DE DÉCISION ET L'ARBRE DÉCISIONNEL
- NŒUDS DE PRECISTIONTREE
- TYPES DE MODÈLES
- VALEURS DES MODÈLES
- ANALYSE DE DÉCISION
- ANALYSE DE SENSIBILITÉ
- RÉDUCTION D'ARBRE
- ÉVALUATION UTILISATEUR
- OPTIONS D'ANALYSE EXPERTES
- RISK AVEC PRECISIONTREE
- RISK POUR QUANTIFIER L'INCERTITUDE
- MÉTHODES DE RECALCUL EN COURS DE SIMULATION
- DISTRIBUTIONS DE PROBABILITÉS DANS LES NŒUDS
- RISK ET ANALYSE DES OPTIONS DE DÉCISION
- SÉLECTION DE SORTIES @RISK
- NŒUD DE DÉPART
- GLOSSAIRE
- VARIABLE DÉPENDANTE
- VARIABLE INDÉPENDANTE
- VARIANCE
- LECTURES PAR CATÉGORIE
- INTRODUCTION À L'ANALYSE DE RISQUE
- RÉFÉRENCES TECHNIQUES À LA SIMULATION ET AUX TECHNIQUES MONTE CARLO
- RÉFÉRENCES TECHNIQUES AUX TECHNIQUES D'ÉCHANTILLONNAGE HYPERCUBE LATIN
- EXEMPLES ET ÉTUDES DE CAS FAISANT APPEL À L'ANALYSE DE RISQUE
- CENTILES
- COMPAGNON @RISK
- DISTRIBUTION
- DISTRIBUTIONS
- FENÊTRE
- DÉFINIR UNE DISTRIBUTION
- FENÊTRES
- FILTRES
- FONCTIONS DE RISQUE
- MENUS
- PARAMÈTRES
Marque : PALISADE
Modèle : RISK 5.5
Catégorie : Logiciel informatique