
ME5024 - Baie de disques DELL - Notice d'utilisation et mode d'emploi gratuit
Retrouvez gratuitement la notice de l'appareil ME5024 DELL au format PDF.
| Type de produit | Baie de disques (enclosure de stockage) |
| Modèle | Dell PowerVault ME5024 |
| Format | 2U (rack 19 pouces, 2 unités EIA) |
| Dimensions (H x L x P) | 87,9 mm x 483 mm x 547,8 mm |
| Poids (vide) | 4,8 kg |
| Poids (max configuré) | 30 kg (boîtier RBOD) |
| Capacité de disques | Jusqu'à 24 disques 2,5 pouces (SFF) en orientation verticale |
| Types de disques supportés | SAS 12 Gbit/s (HDD, SSD) |
| Modules de contrôleur | 1 ou 2 modules de contrôleur (redondance active-active), emplacements A et B |
| Ports hôte (selon module) | 4 ports FC 32 Gbit/s, ou 4 ports iSCSI 25 GbE, ou 4 ports iSCSI 10Gbase-T, ou 4 ports mini-SAS HD 12 Gbit/s |
| Port de gestion | 1 port Ethernet 1 GbE (RJ45) |
| Port CLI | 1 port micro-USB (115200 bauds, 8N1) |
| Alimentation | 2 modules PCM redondants (hot-swap), 580 W chacun |
| Tension d'entrée | 100-240 V CA, 50/60 Hz (auto-sensing) |
| Ventilation | Ventilateurs intégrés dans les PCM, flux d'air avant-arrière |
| Température de fonctionnement | 5 °C à 35 °C (boîtier contrôleur) |
| Humidité de fonctionnement | 20 % à 80 % (sans condensation) |
| Interface de gestion | PowerVault Manager (web), CLI (USB/série) |
| LED de diagnostic | Panneau OPS avant, LED d'état des contrôleurs, disques, PCM |
| Hot-swap | Disques, PCM, modules de contrôleur (avec préparation) |
| Conformité | FCC Classe A, CE, UL 60950-1, UL 62368-1 |
FOIRE AUX QUESTIONS - ME5024 DELL
Questions des utilisateurs sur ME5024 DELL
0 question sur cet appareil. Repondez a celles que vous connaissez ou posez la votre.
Poser une nouvelle question sur cet appareil
Téléchargez la notice de votre Baie de disques au format PDF gratuitement ! Retrouvez votre notice ME5024 - DELL et reprennez votre appareil électronique en main. Sur cette page sont publiés tous les documents nécessaires à l'utilisation de votre appareil ME5024 de la marque DELL.
MODE D'EMPLOI ME5024 DELL
Système de stockage dell powervault série ME5
Manuel du propriétaire
Remarques, précautions et avertissements
i REMARQUE : Une REMARQUE indique des informations importantes qui peuvent vous aider a mieux utiliser votre produit. PRECAUTION: ATTENTION you avertit d'un risque de dommage matériel ou de perte de données et you indique comment éviter le problème. A VERTISSEMENT : un AVERTISSEMENT signale un risque d'endommagement du matériel, de blessure corporelle, voire de décès.
Chapitre 1: matériel du système de stockage. 6
Reprenez le numéro de série. 6
Configurations du boîtier 6
Mise à jour vers une configuration à deux contrôleurs. 7
Retrait du deuxième contrôle. 7
Gestion du boîtier 7
Fonctionnement 8
Variantes de boîtiers 10
Produit de base du boîtier 2U. 12
Panneau avant du boîtier 2U. 12
Panneau arrière du boîtier 2U. 12
Produit de base du boîtier 5U84. 14
Panneau avant du boîtier 5U84. 15
Panneau arrière du boîtier 5U84. 15
Chassis de boîtier 5U84. 18
Tiroirs du boîtier 5U84. 18
Voyants du panneau OPS. 19
Panneau OPS du boitier 2U. 19
Panneau des opérations du boîtier 5U. 20
Modules de contrôle 21
Voyants du module de contrôleur 12 Gbit/s. 21
Description des LED d'état de la mémoire cache. 24
Panne de contrôle lorsqu'un seul contrôle est opérationnel. 25
Chapitre 2: dépannage et résolution des problèmes 26
Méthodologie de localisation des pannes. 26
Options disponibles pour l'exécution des étapes de base. 26
Exécution des étapes de base. 27
E/S hote. 28
Les LED du boîtier 2U. 28
Panneau OPS du boitier 2U. 28
LED PCM du boîtier 2U. 29
LED du panneau OPS du boîtier 2U. 29
Les LED du module support de lecteur de disque du boîtier 2U. 30
Voyants du module d'E/S. 31
Voyants du module de contrôleur 12 Gbit/s. 32
Voyants LED du boîtier 5U84. 34
Panneau des opérations du boîtier 5U. 35
Voyants LED du bloc d'alimentation ME5084 35
Voyants LED du module FCM ME5084. 36
Voyants LED du panneau OPS ME5084. 36
Voyants LED du tiroir ME5084 37
Voyants DDIC ME5084. 37 Voyants LED des modules de contrôle 5U84 et d'E/S. 38
Problèmes de démarrage initiaux 38
Dépannage des boîtiers 2U. 38 Dépannage des boîtiers 5U. 40 Si le boîtier ne démarre pas. 41 Correction des ID du boîtier 41 Dépannage des pannes matérielles 41
Chapitre 3: retrait et remplacement d'un module. 44
Mises en garde concernant les décharges électrostatiques (ESD). 44 Traitement des pannes matérielles. 45 Mises à jour de firmware 45
Mise à jour du firmware partenaire 45 Installation d'une offre groupée de firmwares. 46 Activation d'une offre groupée de firmwares 46
Arrêt des hôtes rattachés 47 Arrêt d'un module de contrôle 47
Utilisation de PowerVault Manager. 47 A l'aide de la CLI. 47
Vérification de l'échéance d'un composant 47 Unités remplaçables par l'utilisateur (CRU). 48
Fixation ou retrait du panneau avant d'un boîtier 2U. 48 Remplacement d'un module support de lecteur dans un boîtier 2U. 49 Remplacement d'un support DDIC dans un boîtier 5U. 54 Remplacement d'un module de contrôle ou d'un module d'E/S. 62
Remplacement d'un module de refroidissement de l'alimentation (PCM) dans un boitier 2U. 67 Remplacement d'un bloc d'alimentation dans un boitier 5U. 69 Remplacement d'un module de refroidissement par ventilateur (FCM) dans un boitier 5U. 71 Exécution du processus d'installation des composants. 72
Vérification du bon fonctionnement du composant. 72
Utilisation des LED. 73 Utilisation des interfaces de gestion. 73
Exécution de mises à jour dans PowerVault Manager après le remplacement d'un adaptateur HBA
Fibre Channel ou SAS. 73
Chapitre 4: événements et messages d'événement. 74
Description des événements 74 Événements 75
Annexe a: connexion à l'interface de ligne de commande 139
Connexion de périphérique micro-USB. 139
Pilotes Microsoft Windows 140
Pilotes Linux 140
Annexe c: normes et réglementations 145
Ce guide décrit les fonctionnalités et les caractéristiques techniques des systèmes de stockage Série ME5.
Les informations fournies dans ce guide sont destinées aux administrateurs de stockage ou réseau et au personnel de déploiement.
Publications connexes
La documentation suivante fournit des informations supplémentaires sur les systèmes de stockage Série ME5 :
- Dell PowerVault série ME5 Guide de l'administrateur Dell PowerVault série ME5
- Dell PowerVault série ME5 Guide de mise en route des systèmes Dell PowerVault série ME5, ME5012 et ME5024 (ME5 Series ME5012 and ME5024 Getting Started Guide)
- Dell PowerVault série ME5 Guide de mise en route Dell PowerVault série ME5 ME5084 (ME5 Series ME5084 Getting Started Guide)
- Dell PowerVault série ME5 Guide de déploiement Dell PowerVault série ME5 (ME5 Series Deployment Guide)
Matériel du système de stockage
Ce chapitre décrit les composants avant et arrière des boitiers Série ME5.
Certains des modules au sein du boîtier sont replacables sur site comme décrit dans Retrait et remplacement des modules. Les types de modules et autres composants qui peuvent être remplacés sont définis ci-dessous:
- CRU: Pièces replacables par le client
- FRU: Unités remplaçables sur site (experts en maintenance)
Les termes CRU et FRU sont utilisés dans ce document.
Ce document peut contenir du contenu tiers ne relevant pas de Dell. Le langage du contenu tiers peut ne pas respecter les consignes en vigueur concernant le contenu Dell. Dell se réserve le droit de mettre à jour ce document après la mise à jour du contenu par les tiers compétents.
- Repérez le numéro de série
- Configurations du boîtier Gestion du boîtier -Fonctionnement
- Variantes de boîtiers - Produit de base du boîtier 2U Produit de base du boîtier 5U84 Châssis de boîtier 5U84 Voyants du panneau OPS
- Modules de contrôle
Repérez le numéro de série
Vos systèmes de stockage Série ME5 sont identifiés par un numéro de série et un code de service express uniques.
Ces données figurent à l'avant du système et sont accessibles en tirant la plaquette d'information. Elles peuvent également se couvrir sur un autocollant placé à l'arrière du chassis du système de stockage. Ces informations servent à diriger les appeals de support vers le personnel compétent.

REMARQUE : Quick Resource Locator (GRL - localisateur de ressources rapide) :
Le code QRL contient des informations propres à votre système. Il se trouve dans la plaquette d'informations et le document Configuration du système de stockage Dell PowerVault série ME5 (Setting Up Your Dell PowerVault ME5 Series Storage System) fourni avec votre boîtier série ME5. - Scannez le GRL pour obtaining un accès immédiat aux informations concernant votre système à l'aide de votre Smartphone ou de cette tablette.
Configurations du boîtier
Le système de stockage prend en charge trois configurations de boîtiers de contrôleur.
Le boîtier de contrôleur 2U12 contient jusqu'à 12 disques 3,5 pouces profil bas en orientation horizontale. Le boîtier de contrôleur 2U24 contient jusqu'à 24 disques 2,5 pouces profil bas en orientation verticale. Le boîtier de contrôleur 5U84 contient jusqu'à 84 disques 3,5 pouces profil bas en orientation verticale au sein d'un tiroir de disques. Le boîtier de contrôleur 5U84 contient deux tiroirs qui contiennent chacun 42 disques. Si des disques de 2,5 pouces sont utilisés, un adaptateur 3,5 pouces est requis.
Les boîtiers 2U12 et 2U24 prennent en charge des configurations à un ou deux modules de contrôleur, mais le boîtier 5U84 ne prend en charge que les configurations à deux modules de contrôleur. Si un module de contrôleur partenaire tombe en panne, le système de
stockage bascule et s'exécute sur un seul module de contrôleur jusqu'à ce que la redondance soit restaurée. Pour les boîtiers 2U, un module de contrôleur doit être installé dans le logement A, et un module de contrôleur ou un cache de module doit être installé dans le logement B pour assurer une circulation suffisante de l'air via le boitier lors du fonctionnement. Pour les boitiers 5U84, un module de contrôleur doit être installé à la fois dans le logement A et le logement B.
Ces mêmes formats de boîtier 2U et 5U sont utilisés pour les boîtiers d'extension pris en charge, mais avec des modules d'E/S à la place des modules de contrôleur.
Mise à jour vers une configuration à deux contrôleurs
Vous pouvez mettre à niveau une configuration à un seul module contrôleur 2U par l'ajout d'un second module contrôleur dans le logement B.
Le module contrôleur B peut être ajouté pendant que le module contrôleur A continue de traiter les exigences d'E/S de l'hôte. Cependant, nous vous recommendons de programmer les changements de configuration pendant les périodes de maintenance impliquant peu ou pas d'E/S.
Les données ne sont pas affectées lorsqu'un module contrôleur B est inséré dans le boîtier. Toutefois, il est vivement recommandé d'effectuer une sauvegarde complète des données avant de continuer.
- Lorsqu'un module contrôleur B est inséré, le paramètre de redondance passe automatiquement de Single Controller à Active-Active ULP (présentation LUN unifiée). Aucune modification manuelle n'est nécessaire. Si la fonction PFU (mise à
- Saisissez la commande CLI suivante pour vérifier que la redondance est configurée comme Single Controller Mode:
Cette étape permet de s'assurer que le module contrôleur A ne signale pas le module contrôleur B comme étant manquant.
- Retirez le cache du contrôleur du logement B.
- Saisissez le module de contrôle des deux mains, et avec le loquet en position ouverte, orientez le module et alignez-le pour l'insérer dans le logement B.
- En vous assurant que le module de contrôleur est à niveau, faites-le glisser complètement dans le boîtier. Un module de contrôleur qui n'est que partiellement en place nuit aux performances du boîtier du contrôleur. Vérifiez que le module de contrôleur est correctement installé avant de continuer.
- Mettez le module en position en fermant manuellement le loquet. Vous devez entendre un click lorsque le loquet de verrouillage se met en place et sécurise le module de contrôleur sur son connecteur à l'arrête du fond de panier central.
- Connectez les câbles.
- Mapez les ports hôte sur le module contrôleur B.
Retrait du deuxième contrôleur
Pour retirer le module de contrôle B et revenir à une configuration à un seul contrôleur, procédez comme suit :
- Arrêtez le module de contrôleur B à l'aide de PowerVault Manager ou de l'interface de ligne de commande.
- Retirez le module de contrôleur du boîtier.
- Saisissez la commande CLI suivante pour définir les paramètres de redondance sur Single Controller Mode:
- Installez un cache de module de contrôle dans le logement B.
Gestion du boîtier
Le boîtier est mécanique et électrique conforme à la Specification Storage Bridge Bay (SBB) v2.1.
Les modules SBB gèrent activement le boîtier. Chacun d'eux possède un module d'extension SAS avec son propre processeur de boîtier de stockage (SEP). Ce dernier offre une cible SES avec laquelle un hôte peut communiquer en utilisant la norme ANSI SES (SCSI Enclosure Services) standard. Si l'un de ces modules tombe en panne, l'autre module continue à fonctionner.
Interfaces de gestion
Une fois l'installation matérielle terminée, utilisez PowerVault Manager pour configurer, surveiller et gérer le système de stockage. Le module de contrôleur prend également en charge une interface de ligne de commande (CLI) pour l'entrée de ligne de commande et la réduction de scripts. Pour plus d'informations, reportez-vous au Guide de l'interface de ligne de commande du système de stockage Dell PowerVault série ME5 (Dell PowerVault ME5 Series Storage System CLI Guide) pour votre système.
Fonctionnement

PRECAUTION: Le fonctionnement d'un boîtier avec des modules CRU perturbe la circulation d'air et empêche le boîtier de se refroidir suffisamment. Tous les logements d'un boîtier doivent contérer des modules lors de son utilisation, y compris les caches de support de disque dans les logements de disque vides pour les boîtiers 2U.
- Lisez l'étiquette d'avertissement de baie modulaire collée sur les modules en cours de remplacement.
- Remplacez le module de refroidissement de l'alimentation (PCM) defectueux par un PCM complètement opérationnel dans les 24 heures. Ne retirez pas un PCM defectueux à moins d'avoir en votre possession un modèle de remplacement correct prêt à être inséré.
- Débranche l'alimentation d'un module de refroidissement de l'alimentation (PCM) ou d'un bloc d'alimentation (PSU) à remplacer avant de retirer le module PCM ou le bloc d'alimentation. Lisez l'étiquette d'avertissement de tension dangereuse apposée sur les modules de refroidissement de l'alimentation (PCM).

PRECAUTION: Boitiers 5U84 uniquement
Pour éviter tout retournement, le verrouillage des tiroirs empêche les utilisateurs d'ouvrir deux tiroirs simultanément. N'essayez pas de forcer l'ouverture d'un tiroir lorsque l'autre tiroir du boîtier est déjà ouvert. Dans un rack qui contient plus d'un boîtier 5U84, n'ouvre pas plus d'un tiroir à la fois par rack. - Lisez l'étiquette apposée sur le tiroir. Les températures à l'intérieur des tiroirs d'un boîtier peuvent atteindre 60° C. Faites attention lors de l'ouverture des tiroirs et du retrait des supports DDIC. - En raison de l'acoustique du produit, une protection auditive devrait être utilisée lors d'une exposition prolongée au produit en fonctionnement. N'utilise pas les tiroirs ouverts pour prendre en charge tout autre objet ou équipement.

REMARQUE: Reportez-vous à Variantes de boîtiers pour obtenir plus de détails sur les options de boîtiers.
Figure 1. Système de boîtier 2U12 : orientation avant
Le boîtier du contrôleur 2U12 est équipé de deux contrôleurs.
Figure 2. Système de boîtier 2U12 : orientation arrêté
Figure 3. Système de boîtier 2U24 : orientation avant
Le boîtier du contrôle 2U24 est équipé de deux contrôleurs.
Figure 4. Système de boîtier 2U24 : orientation arrêté
Figure 5. Système de boîtier 5U84 : orientation avant
Le boîtier du contrôle 5U84 est équipé de deux contrôleurs.
Figure 6. Système de boîtier 5U84 : orientation arrière
Variantes de boîtiers
Le boitier 2U peut être configuré en tant que boitier de contrôleur ME5012/ME5024 ou boitier d'extension ME412/ME424. Le boitier 5U peut être configuré en tant que boitier de contrôleur ME5084 ou boitier d'extension ME484.

REMARQUE : Les principaux composants des boîtiers 2U et 5U sont décrits dans les sections suivantes.
Bien que de nombreux composants replacables par l'utilisateur (CRU) diffèrent d'un format à l'autre, les modules de contrôleur et IOM sont communs aux boîtiers 2U12, 2U24 et 5U84. Les modules de contrôleur et IOM sont introduits dans le produit de base du boîtier 2U et référencés à partir du produit de base du boîtier 5U84.
Les boîtiers 2U12 se composent de 12 disques LFF (grand format).
Tableau 1. Variantes de boîtiers 2U12
| Produit Configuration | PCMs | 1 | Modules de contrôleur et IOM2,3 |
| ME5012 Disques SAS | avec station d'accueil directe de 12 Gbit/s | 2 | 2 |
Tableau 1. Variantes de boîtiers 2U12 (suite)
| Produit Configuration | PCMs | 1 | Modules de contrôleur et IOM2,3 |
| Disques SAS avec station d'accueil directe de 12 Gbit/s | 2 | 1 | |
| ME412 Disques SAS avèc station d'accueil directe de 12 Gbit/s | 2 | 2 | |
1 Les PCM redondants doivent être des modules compatibles du même type. 2 Les modules de contrôle pris en charge sont dotés de 4 ports FC SFP+, 4 ports iSCSI SFP28, 4 ports 10Gbase-T iSCSI, 4 ports mini-SAS HD. Les modules IOM pris en charge sont utilisés dans les boîtiers d'extension pour l'ajout de stockage supplémentaire. 3 Dans les configurations à un seul module de contrôleur, le module de contrôleur est installé dans le logement A, et un contrôleur vide est installé dans le logement B.
2U24
Les boîtiers 2U24 comportent 24 lecteurs SFF (format compact).
Tableau 2. Variantes de boîtiers 2U24
| Produit Configuration | PCMs | 1 | Modules de contrôleur ou IOM2,3 |
| ME5024 Disques SAS | avec station d'accueil directe de 12 Gbit/s | 2 | 2 |
| Disques SAS avec station d'accueil directe de 12 Gbit/s | 2 | 1 | |
| ME424 Disques SAS | avec station d'accueil directe de 12 Gbit/s | 2 | 2 |
1 Les PCM redondants doivent être des modules compatibles du même type. 2 Les modules de contrôle pris en charge sont dotés de 4 ports FC SFP+, 4 ports iSCSI SFP28, 4 ports 10Gbase-T iSCSI, 4 ports mini-SAS HD. Les modules IOM pris en charge sont utilisés dans les boîtiers d'extension pour l'ajout de stockage supplémentaire. 3 Dans les configurations à un seul module de contrôleur, le module de contrôleur est installé dans le logement A, et un module de contrôleur vierge est installé dans le logement B.
Les boitiers 5U84 comportent 84 disques LFF ou SFF logés dans deux tiroirs dotés de 42 logements.
Tableau 3. Variantes de boîtiers 5U84
| Produit Configuration | Blocs | d'alimentati on1 | FCMs2 | Modules de contrôle ou modules IOM3 |
| ME5084 Disques SAS | S avec station d'accueil directe de 12 Gbit/s | 2 5 2 | ||
| ME484 Disques SAS | avec station d'accueil directe de 12 Gbit/s | 2 5 2 |
1 Les PCM redondants doivent être des modules compatibles du même type (tous deux AC). 2 Le module de commande de ventilateur (FCM) est un CRU séparé (non intégré dans un PCM). 3 Les modules de contrôle pris en charge sont dotés de 4 ports FC SFP+, 4 ports iSCSI SFP28, 4 ports 10Gbase-T iSCSI, 4 ports mini-SAS HD. Les modules IOM pris en charge sont utilisés dans les boîtiers d'extension pour l'ajout de stockage supplémentaire.
Produit de base du boîtier 2U
La conception est basée sur un sous-système de boîtier accompagné d'un ensemble de modules de plug-in.
Les figures suivantes montrent les emplacements des composants, ainsi que l'indexation des logements des composants remplaçables par l'utilisateur, par rapport aux panneaux avant et arrière du boîtier 2U.
Panneau avant du boîtier 2U
Dans les figures suivantes, des nombres entiers sur les disques indiquent la séquence de numérotation des logements de disque.
Figure 7. Système du boîtier 2U12 : composants du panneau avant
Figure 8. Système du boîtier 2U24 : composants du panneau avant
Pour plus d'informations sur les voyants du panneau avant du boîtier, reportez-vous à la section Panneau OPS du boîtier 2U. Pour plus d'informations sur les voyants des modules de disque LFF et SFF, reportez-vous à la section Utilisation des LED. Pour plus d'informations sur le cadre avant du boîtier 2U (en option), reportez-vous à la section Fixation ou retrait du panneau avant d'un boîtier 2U.
Panneau arrêté du boîtier 2U
Les modules de contrôle et d'E/S utilisent des identifiants alphabétiques, tandis que les modules de refroidissement de l'alimentation (PCM) utilisent des identifiants numériques pour identifier les logements dans un boîtier 2U.
Figure 9. Boîtier de contrôleur 2U : composants du panneau arrêté
- PCM02. Module de contrôle A PCM14. Module de contrôle B
Figure 10. Boîtier d'extension 2U : composants du panneau arrêté
- PCM 02. IOM A 3. PCM14 - module d'E/S B
Composants du panneau arrière du boîtier 2U
Cette section décrit les composants du module de contrôleur, du module d'E/S du boîtier d'extension et du module de refroidissement de l'alimentation pour les boîtiers 2U.
Module de contrôleur
Le logement supérieur pour maintenir les modules de contrôleur est désigné logement A, et le logement inférieur est désigné logement B. Les détails de la plaque avant des modules de contrôleur indiquent un module aligné pour une utilisation dans le logement A. Dans cette orientation, le loquet du module de contrôleur s'affiche en bas du module et se trouve en position fermée/verrouillée. Reportez-vous à la section Voyants LED du module de contrôleur 12 Gbit/s pour plus d'informations sur les voyants du module de contrôleur.
Figure 11. Détails du module de contrôleur
- Ports hôte 2. Port série USB (service uniquement)
- Port série USB (CLI) 4. Port Ethernet pour le réseau de gestion
- Port d'extension SAS
Module IOM du boîtier d'extension
La figure suivante présente le module d'E/S utilisé dans les boîtiers d'extension pris en charge pour l'ajout de stockage. Ports A/B/C livrés configurés avec des connecteurs externes mini-SAS HD (SFF-8644) de 12 Gbit/s. Reportez-vous à la section Voyants LED du module d'E/S pour plus d'informations sur le comportement des voyants LED du boîtier.
Figure 12. Détails des modules d'E/S des boîtiers d'extension
- Port série 3,5 mm (maintenance uniquement) 2. Port d'extension SAS A
- Port Ethernet (désactivé)
Module de refroidissement de l'alimentation
La figure suivante illustre le module de refroidissement de l'alimentation (PCM) utilisé dans les boîtiers de contrôleur et les boîtiers d'extension en option. Le PCM comprend des ventilateurs de refroidissement intégrés. L'exemple montre un PCM orienté pour utilisation dans le logement de gauche du panneau arrêté du boîtier.
Figure 13. Module de refroidissement de l'alimentation (PCM)
- Voyant PCM OK (vert) 2. Voyant erreur alimentation (orange/orange clignotant)
- Voyant erreur ventilateur (orange/orange clignotant) 4. Erreur alimentation CC (orange/orange clignotant)
- Interrupteur marche/arrêt 6. Port d'alimentation
- Loquet de déverrouillage
Comportement du voyant :
Si l'un des voyants du PCM s'allume en orange, une erreur ou une panne s'est produite. Pour obtenir une description détaillée du comportement des voyants LED du module PCM, reportez-vous à la section Voyants LED du module PCM du boîtier 2U.
Produit de base du boîtier 5U84
Les figures suivantes montrent l'emplacement des composants et l'indexation des logements CRU sur le panneau avant du boîtier 5U84 avec tiroirs et sur le panneau arrière.
Le boîtier 5U84 prend en charge jusqu'à 84 modules DDIC répartis dans deux tiroirs (42 modules DDIC par tiroir; 14 modules DDIC par rangée).

Remarque:
Le boîtier 5U84 n'est pas livré avec des modules DDIC installés. Ils sont livrés dans un conteneur séparé et doivent être installés dans les tiroirs du boîtier lors de l'installation et de la configuration du produit. - Afin de garantir une circulation et un refroidissement suffisants dans le boîtier, tous les logements de bloc d'alimentation, de module de refroidissement et IOM doivent contenir un composant remplaçable par l'utilisateur en fonctionnement. Ne remplacez pas de composant remplaçable en panne tant que vous n'avez pas la pièce de rechange à disposition.
Panneau avant du boîtier 5U84
Figure 14. Boîtier 5U84 : composants du panneau avant
- Tiroir du boitier 5U84 (emplacement 0 = tiroir supérieur)
- Tiroir du boîtier 5U84 (emplacement 1 = tiroir inférieur)

REMARQUE: Reportez-vous à Voyants LED du DDIC ME5084 pour obtenir le comportement des voyants LED du DDIC sur le boîtier 5U84 (disques LFF).
Figure 15. Système du boîtier 5U84 : vue à plat du tiroir
- Panneau avant du tiroir (présenté comme bord dans vue à plat)
- Orientation dans le logement du tiroir du boîtier (logement 0 ou 1)
Panneau arrêté du boîtier 5U84
Les modules de contrôleur et modules d'E/S utilisent des identifiants alphabétiques, tandis que les blocs d'alimentation (PSU) et les modules FCM utilisent des identifiants numériques pour identifier les logements dans un boîtier 5U84.

REMARQUE : Les modules de contrôle, les modules d'E/S, les blocs d'alimentation et les modules FCM sont disponibles en tant que CRU.
Les boîtiers de contrôleur 5U84 prennent uniquement en charge les configurations à deux modules de contrôleur. Si un module de contrôleur partenaire tombe en panne, le stockage bascule et s'exécute sur un seul module de contrôleur jusqu'à ce que la redondance soit restaurée. Les deux logements de module de contrôleur doivent être occupés pour assurer une circulation d'air suffisante via le contrôleur en fonctionnement.
Figure 16. Boîtier de contrôleur 5U84 : composants du panneau arrêté
- Module de contrôleur A Module de contrôleur B
- FCM 04. FCM 4
- Bloc d'alimentation 0 6. Bloc d'alimentation électrique 1
Figure 17. Boîtier d'extension 5U84 : composants du panneau arrêté
- IOM A 2. Module d'E/S B
- FCM 04. FCM 4
- Bloc d'alimentation 0 6. Bloc d'alimentation électrique 1
Composants du panneau arrêté 5U84
Cette section décrit les modules de contrôleur du panneau arrière, le module d'extension, le bloc d'alimentation et le module de refroidissement par ventilateur.
Modules de contrôleur
Le boîtier de contrôleur 5U84 utilise les mêmes modules de contrôleur que ceux utilisés par les boîtiers 2U12 et 2U24.
Le logement supérieur pour maintenir les modules de contrôleur est désigné logement A, et le logement inférieur est désigné logement B. Les détails de la plaque avant des modules de contrôleur indiquent un module aligné pour une utilisation dans le logement A. Dans cette orientation, le loquet du module de contrôleur s'affiche en bas du module et il est en position fermée/verrouillée. Reportez-vous à la section Voyants LED du module de contrôleur 12 Gbit/s pour plus d'informations sur les voyants du module de contrôleur.
Figure 18. Détails du module de contrôleur
- Ports hôte 2. Port série USB (service uniquement)
- Port série USB (CLI) 4. Port Ethernet pour le réseau de gestion
- Port d'extension SAS
Module d'extension
Le boîtier d'extension 5U84 utilise les mêmes IOM que ceux utilisés par les boîtiers 2U12 et 2U24.
La figure suivante présente le module d'E/S utilisé dans les boîtiers d'extension pris en charge pour l'ajout de stockage. Ports A/B/C livrés configurés avec des connecteurs externes mini-SAS HD (SFF-8644) de 12 Gbit/s. Reportez-vous à la section Voyants LED du module d'E/S pour plus d'informations sur les voyants du boîtier.
Figure 19. Détails des modules d'E/S des boîtiers d'extension
- Port série 3,5 mm (maintenance uniquement) 2. Port d'extension SAS A
- Port Ethernet (désactivé)
Module d'alimentation
Cette figure présente le bloc d'alimentation utilisé dans les boîtiers de contrôle 5U et les boîtiers d'extension 5U84 (en option).
Figure 20. Bloc d'alimentation (PSU)
- Loquet de déverouillage du module 2. Poignée
- Fault LED du bloc d'alimentation (orange fixe ou clignotant) 4. Voyant erreur alimentation (orange/orange clignotant)
- Voyant indiquant une alimentation sans problème (vert) 6. Connecteur d'alimentation
- Bouton d'alimentation
Comportement du voyant :
Si un des voyants LED du bloc d'alimentation est orange, une anomalie ou une erreur affecte le module. Pour obtenir la description détaillée des voyants LED du bloc d'alimentation, reportez-vous à la section Voyants LED du bloc d'alimentation ME5084.
Les boîtiers 5U84 utilisent différents modules CRU pour l'alimentation et le refroidissement ou la circulation, respectivement. Le module d'alimentation, qui fournit le boîtier avec une connexion électrique et un commutateur d'alimentation. Le module de refroidissement par ventilateur est plus petit que le module PCM, et cinq d'entre eux sont utilisés au sein du boîtier 5U pour assurer une ventilation suffisante dans ce dernier.
Module de refroidissement par ventilateur
La figure suivante illustre le module de refroidissement par ventilateur (FCM) utilisé dans les boîtiers de contrôle 5U et dans les boîtiers d'extension 5U (en option).
Figure 21. Module de refroidissement par ventilateur (FCM)
- Loquet de déverrouillage du module 2. Poignée
- Voyant indiquant un fonctionnement sans problème (vert) 4. Fault LED du ventilateur (orange fixe ou clignotant)
Comportement du voyant :
Si un des voyageurs LED du module FCM est orange, une anomalie ou une défaillance affecte le module. Pour obtenir une description détaillée des voyants LED du module FCM, reportez-vous à la section Voyants LED du module FCM ME5084.
Chassis de boîtier 5U84
Le boîtier 5U84 contient les éléments suivants :
Boîtier 5U84 configuré avec jusqu'à 84 disques LFF dans les supports DDIC. Chassis 5U84 SFF configuré avec disques SFF dans adaptateur de support de lecteur hybride de 2,5 pouces à 3,5 pouces. Chassis 5U84 vide avec fond de panier central, système de canaux de module et tiroirs.
Le chassis comporte un montage avec racks de 19 pouces qui lui permet d'être installé sur des racks au format standard de 19 pouces et utilise cinq unités EIA d'espace de racks (8,75 pouces).
À l'avant du boîtier, deux tiroirs peuvent être ouverts et fermés. Chaque tiroir fournit l'accès à 42 logements pour modules DDIC (Disk Drive In Carrier). Les DDIC sont montés au-dessus dans les tiroirs. L'avant du boîtier comporte également des voyants LED d'état du boîtier ainsi que des voyants LED d'état et d'activité des tiroirs.
L'arrière du boîtier fournit l'accès au panneau arrière des CRU :
-Deux modules de contrôle ou IOM - Deux blocs d'alimentation Six FCM
Tiroirs du boîtier 5U84
Chaque tiroir du boîtier contient 42 logements. Chacun peut accepter un seul DDIC contenant un lecteur de disque LFF de 3,5 pouces ou un lecteur de disque SFF de 2,5 pouces, SFF avec un adaptateur.
L'ouverture d'un tiroir n'interrompt pas le fonctionnement du système de stockage, et les DDIC peuvent être remplacés à chaud pendant que le boitier fonctionne. En revanche, les tiroirs ne doivent pas rester ouverts plus de deux minutes, au risque de compromettre la ventilation et le refroidissement.

REMARQ : En fonctionnement normal, les tiroirs doivent être fermés pour assurer une ventilation et un refroidissement corrects à l'intérieur du boîtier.
Un tiroir est conçu pour supporter son propre poids, en plus du poids des DDIC installés, lorsqu'il est ouvert entièrement.

PRECAUTION: Les fonds de panier lateraux sur les tiroirs de boitier ne sont pas échangeables à chaud et ne peuvent pas faire l'objet de maintenance par le service clientèle.
Fonctionnalités de sécurité
Pour éviter tout basculement du rack, ne faites glisser qu'un seul boîtier hors du rack à la fois. Le tiroir se verrouille lorsqu'il est complètement ouvert et sorti. Afin d'éviter les risques de pincement, deux loquets doivent être relâchés avant que le tiroir puisse être repoussé dans son logement à l'intérieur du boîtier.
Chaque tiroir peut être bloqué en position fermée en tournant les verrous de sécurité dans le sens des aiguilles d'une montre à l'aide d'un tournevis à embout Torx T20 (inclus dans la livraison). Les verrous de sécurité sont placés symétriquement sur les côtés gauche et droit de l'encadrement du tiroir. Les LED d'état et d'activité du tiroir peuvent être surveillées via deux panneaux LED situés à côté des encoches à gauche et à droite de chaque tiroir.
Figure 22. Détails sur l'encadrement des tiroirs
- Côté gauche 2. Côté droit
- Verrou de sécurité 4. Fond de panier létal OK/Alimentation OK
- Panne du tiroir 6. Panne logique
- Câble défectueux 8. Activité du tiroir
- Poignée de tirage du tiroir

REMARQUE : Pour obtenir des descriptions du comportement des voyants LED du tiroir, reportez-vous à la section Voyants LED du tiroir ME5084.
Voyants du panneau OPS
Chaque boîtier Serie ME5 comprend un panneau d'opérateurs (OPS) situé sur la bride du côté gauche du châssis. Cette section décrit le panneau OPS pour les boîtiers 2U et 5U.
Panneau OPS du boîtier 2U
Le panneau OPS se trouve à l'avant du boîtier, sur la bride de la anse gauche du boîtier 2U. Ce panneau fait partie du châssis du boîtier, mais il n'est pas remplaçable sur site.
Figure 23. Voyants du panneau OPS : panneau avant du boîtier 2U
Tableau 4. Fonctions du panneau OPS : panneau avant du boîtier 2U
| Indicator(Voyant) | Description : Couleur Statut | |
| Alimentation du système | Vert Allumé en coontinu : au moins un PCM fournit une alimentationÉteint : le système n'est pas sous tension, indépendamment de la présence de CA | |
| État/Intégrité Bleu Allumé | en continu : le système est sous tension et le contrôleur est prétsClignotant (2 Hz) : la gestion du boîtier est occuée (par exemple, lors du démarriage ou de l'exécution d'une mise à jour du firmware) | |
| Orange Allumé en continu : panne de module présente (peut être associée à une FaultLED sur un module de contrôleur, un module d'E/S ou un PCM)Clignotant : panne logique (2 secondes allumé, 1 seconde éteint) | ||
| Affichage de l'identification de l'unité(UID) | Vert L'UID se présente sur un double affichage à sept segments qui indique la position numérique du boîtier dans la séquence de câblage. Il est également désigné sous le nom d'ID de boîtier. L'ID de boîtier du contrôleur est 0. | |
| Identité Bleu Clignotant (0,25 Hz) : le localisateur d'ID système est activé pour aider àlocaliser le boîtier dans un datacenter.Eteint : état normal |
Panneau des opérations du boîtier 5U
Le panneau OPS se trouve à l'avant du boîtier, sur la bride de la anse gauche du boîtier 5U. Ce panneau fait partie intégrante du châssis du boîtier, mais il n'est pas remplaçable sur site.
Figure 24. Voyants du panneau OPS : panneau avant du boîtier 5U
Tableau 5. Fonctions du panneau OPS : panneau avant du boîtier 5U
| Indicator(Voyant) | Description: Couleur | Statut | |
| Affichage de l'identification de l'unité (UID) | Vert L'UID se présente sur un double affichage à sept segments qui indique la position numérique du boîtier dans la série de câblage. Il est également désigné sous le nom d'ID de boîtier. L'ID de boîtier du contrôleur est 0. | ||
| Système Allumé/Veille | Vert Allumé en continu: l'alimentation du système est disponible (opérationnelle) | ||
| Orange Orange fixe: système en veille (non opérationnel) | |||
| Panne de module Orange | Constante ou clignotante: panne matérielle du système. Levoyant LED de défaillance du module peut être associé à une Fault LED sur un module de contrôleur, un module D'E/S, un bloc d'alimentation, un module FCM, un DDIC ou un tiroir. | ||
| Voyant LED d'état logique | Orange Constante ou clignotante: présence d'une défaillance ne provenant pas du système de gestion du boîtier. Le voyant LED d'état logique peut être initiai depuis le module du contrôleur ou un adaptateur HBA externe. L'indication est généralement associée à un module DDIC et à des voyants LED à chaque position de disque au sein du tiroir, ce qui vous permet d'identifier le module DDIC affecté. | ||
| Panne du tiroir supérieur | Orange Constante ou clignotante: présence d'une panne au niveau du lecteur, d'un cable ou du panier latéral (tiroir 0) | ||
| Panne du tiroir inférieur | Orange Constante ou clignotante: présence d'une panne au niveau du lecteur, d'un cable ou du panier latéral (tiroir 10) | ||
Modules de contrôleur
Cette section décrit les modules de contrôle utilisés dans les boîtiers de stockage 12 Gbit/s. Ils sont mécaniquement et électriquement conformes à la première Specification SBB v2.1.
La figure suivante présente un module de contrôle SAS à 4 ports aligné pour être utilisé dans le logement supérieur situé sur le panneau arrière du boîtier 2U. Le module de contrôle est également correctement aligné pour une utilisation dans l'un des logements situés sur le panneau arrière du boîtier 5U84.
Figure 25. Module de contrôle : orientation arrêté
Chaque module de contrôleur conserve les données vitales du produit (VPD) dans des périphériques EEPROM. Dans un système à deux modules de contrôleur, ces derniers sont reliés par des bus I2C SBB sur le fond de panier central. De cette manière, le module SBB est en mesure de détecter le type et les capacités du module SBB partenaire, et vice versa, au sein du boîtier.
Voyants du module de contrôleur 12 gbit/s
Les diagrammes et les tableaux qui suivent immédiatement fournissent des descriptions concernant les différents modules de contrôle qui peuvent être installés dans le panneau arrière des boîtiers de contrôleurs.

REMARQUE : Tenez compte des éléments suivants lorsque vous consulterez les diagrammes de modules de contrôleur sur les pages suivantes :
- Dans chaque diagramme, le module de contrôle est orienté pour insertion dans le logement supérieur (A) des boîtiers 2U. Lorsqu'ils sont orientés pour utilisation dans le logement inférieur (B) des boîtiers 2U, les étiquettes des modules de contrôle apparaissent à l'envers.
- Dans chaque diagramme, le module de contrôleur est orienté pour insertion dans l'un des logements des boîtiers 5U84.
- Veuillez également configurer le boîtier de contrôleur 2U avec un seul module de contrôleur. Installez le module de contrôleur dans le logement A, puis installez un cache dans le logement B.
Figure 26. Module de contrôle Série ME5
Tableau 6. Voyants LED des modules de contrôleurs courants
| Voyant Description | tion : Couleur Statut | ||
| ✓ | Matériel normal Vert Allumé : | le module de contrôleur | fonctionne correctement |
| Clignotant : fait partie de la série de veille lorsque le module de contrôleur est mis en ligne | |||
| Éteint : le module de contrôleur est hors tension, le module de contrôleur est hors ligne ou le module de contrôleur présente une panne | |||
| Δ | Panne matérielle Orange Allumé : | panne matérielle du | module de contrôleur |
| Éteint : le module de contrôleur fonctionne correctement | |||
| OK pour-retirer Blanc Allumé : | préts pour le retrait, le | cache est effacé | |
| Éteint : ne retirez pas le module de contrôleur, le cache contient toujours des données non écrites | |||
| Identifier Bleu Allumé : l'identifi cation de l'unité (UID) | est active | ||
| Éteint : état normal, l'UID n'est pas actif | |||
| ache | État du cache Vert Allumé : le | cache contient des do | nées non écrites, le module de contrôleur fonctionne correctement |
| Flash rapide (1 s:1 s) : le cache est actif, le vidage du cache est en cours | |||
| Flash lent (3 s:1 s) :actualisation automatique du cache en cours après le vidage du cache | |||
| Éteint : le cache est vide ou le système est en ligne | |||
| Vitesse du port de gestion Ethernet | Orange Allumé : taux | hégocié 1000 Base-T | |
| Éteint : taux négocié 10/100Base-T | |||
| ACT Activité de liaison du port de gestion Ethernet | Vert Allumé : la liaison | Ethernet est active | |
| Éteint : la liaison Ethernet est hors service | |||
| État du port d'extension SAS 12 Gbit/s | Vert Allumé : connecté, la liaison est active | ||
| Vert ou orange Clignotant : activité de liaison | |||
| Orange Allumé : connexion, liaison partielle activée | |||
| Aucun Éteint : non connecté ou liaison hors service | |||
La figure suivante présente les voyants LED du port hôte sur un module de contrôle Fibre Channel 32 Gbit/s :
Figure 27. Ports Fibre Channel 32 Gbit/s
| Voyant Description | tion : Couleur Statut | ||
| ® | Activité de liaison Fibre Channel | Vert Allumé : connecté, la liaison est active | |
| Clignotant : activité de liaison | |||
| Éteint : non connecté ou liaison hors service | |||
La figure suivante présente les voyants LED du port hôte sur un module de contrôle iSCSI 25 GbE :
Figure 28. Ports iSCSI 25 GbE
| Voyant | Description : Couleur Statut | ||
| # | Activité de liaison iSCSI Vert Allumé : connecté, la liaison est active | ||
La figure suivante présente les voyants LED du port hôte sur un module de contrôle iSCSI 10Gbase-T :
Figure 29. Ports iSCSI 10Gbase-T
| Voyant | Description : Couleur Statut | ||
| ® | Vitesse de liaison iSCSI 10Gbase-T | Vert Allumé : vitesse de liaison 10 GbE | |
| Orange Allumé : vitesse de liaison 1 GbE | |||
| Aucun Éteint : non connecté ou liaison hors service | |||
| ACT Activité de liaison iSCSI 10Gbase-T | Vert Allumé : connecté, la liaison est active | ||
La figure suivante présente les voyants LED du port hôte sur un module de contrôle SAS 12 Gbit/s :
Figure 30. Ports SAS 12 Gbit/s
| Voyant Description : Couleur Statut | |||
| Δθ | État du port SAS Vert Allumé | connecté, la liaison est active | |
| Vert ou orange Clignotant : activités de liaison | |||
| Orange Allumé : connexion, liaison partielle activée | |||
| Aucun Éteint : non connecté ou liaison hors service | |||
Description des LED d'état de la mémoire cache
Ce t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t t d.
Comportement pendant la mise sous/hors tension
Pendant la mise sous tension, la séquence distincte des états de mise sous tension des composants internes est indiquée par différents schémas de clignotement des LED d'état de la mémoire cache.
Tableau 7. LED d'état de la mémoire cache : comportement de mise sous tension
| Élement États afficiés | hés rapportés par les LED d'état de la mémoire cache pendant la séquence de mise sous tension | |||||||
| État affché 0123456 Série | ||||||||
| Composant VP SC SA | S BE ASIC Hôte Boot | (démarrage) | Normal Réinitialiser | |||||
| Séquence de clignotation | Allumé 1/Éteint 7 | Allumé 2/Éteint 6 | Allumé 3/Éteint 5 | Allumé 4/Éteint 4 | Allumé 5/Éteint 3 | Allumé 6/Éteint 2 | Fixe/Allumé Fixe | |
Une fois la séquence de mise sous tension terminée sur le boîtier, le voyant d'état de la mémoire cache est allumé et fixe (normal), avant de se trouver à l'état « en cours de fonctionnement » pour les opérations de mise en cache.
Comportement : état de la mémoire cache
Si le voyant LED clignote uniformement, le vidage du cache est en cours. Lorsqu'un module de contrôleur subit une perte d'alimentation et que le cache en écriture n'a pas été nettoyé (contient des données qui n'ont pas été écrites sur le disque), le supercondensateur fournit une alimentation de secours pour vider (copier) les données du cache en écriture vers la mémoire. Une fois le vidage du cache terminé, ce dernier passe en mode d'actualisation automatique.
Si le voyant LED clignote lentement momentanément, la mémoire cache est en mode d'actualisation automatique. Dans ce mode, si l'alimentation principale est rétablie avant l'épuration de l'alimentation de secours (3 à 30 minutes, en fonction de différents facteurs), le système démarre, recherche les données conservées dans le cache et les écrit sur le disque. Cela signifie que le système peut être opérationnel dans les 30 secondes, avant le début habituel de 60 secondes correspondant à l'expiration des E/S : à ce stade la panne du système entraînerait celle des applications de l'hôte. Si l'alimentation principale est rétablie après que l'alimentation de secours est épuisée, le système démarre et restaure les données dans le cache depuis le système eMMC, ce qui peut prendre environ 90 secondes. Le mécanisme de vidage du cache et d'actualisation automatique constitue une fonction importante de protection des données. Quatre copies des données utilisateurs sont conservées : une dans le cache du contrôleur et une dans la carte eMMC de chaque contrôleur. Le voyant d'état de la mémoire cache s'allume en vert fixe pendant le processus de démarrage. Ce comportement indique que le cache consigne tous les POST, qui seront transférés vers la carte eMMC la prochaine fois que le contrôleur s'arrête.
Si le voyant LED d'état de la mémoire cache est vert fixe et si vous souhaitez arrêter le contrôleur, faites-le à partir de l'interface utilisateur, de sorte que les données non écrites puissent être transférées sur la carte eMMC.
Panne de contrôle lorsqu'un seul contrôle est opérationnel
Les informations suivantes s'appliquent aux boîtiers à deux contrôleurs 2U et 5U lorsque l'un des contrôleurs est arrêté et que l'autre contrôleur tombe en panne.
La mémoire cache est vidée sur la carte eMMC en cas de défaillance du contrôleur ou de perte d'alimentation. Au cours du processus d'écriture sur la carte eMMC, seuls les composants nécessaires pour écrire le contenu du cache sur la carte eMMC sont alimentés par le supercondensateur. Une fois le cache copié dans la carte eMMC, l'alimentation restante dans le supercondensateur est utilisée pour actualiser la mémoire du cache. Pendant que le cache est maintenu par le supercondensateur, le voyant LED d'état du cache clignote à une vitesse de 1/10 seconde allumée sur on (allumé) et 9/10 seconde sur off (éteint).
Voyant LED d'état de la mémoire cache : action corrective
Si le contrôleur est en panne ou ne démarre pas, vérifiez si le voyant LED d'état de la mémoire cache est allumé ou clignote.
Tableau 8. Voyants : état de la mémoire cache sur le panneau arrêté
| Statut Action | |
| Levoyant LED d'etat de la mémoire cache est étéint, et le contrôleur ne démarre pas. | Si le problème persiste, remplacez le module du contrôleur. |
| Levoyant LED d'etat de la mémoire cache est étéint, et le contrôleur démarre. | Le système a transféré les données sur les disques. Si le problème persiste, remplacez le module du contrôleur. |
| Levoyant LED d'etat de la mémoire cache clignote à une vitesse 1:10, à 1 Hz, et le contrôleur ne démarre pas. | Vous devrez peut-être remplancer le module de contrôleur. |
| Levoyant LED d'etat de la mémoire cache clignote à une vitesse 1:10, à 1 Hz, et le contrôleur démarre. | Le système transfère les données sur la CompactFlash. Si le problème persiste, remplacez le module du contrôleur. |
| Levoyant LED d'etat de la mémoire cache clignote à une vitesse 1:1, à 2 Hz, et le contrôleur ne démarre pas. | Vous devrez peut-être remplancer le module de contrôleur. |
| Levoyant LED d'etat de la mémoire cache clignote à une vitesse 1:1, à 1 Hz, et le contrôleur démarre. | Le système est en mode d'actualisation automatique. Si le problème persiste, remplacez le module du contrôleur. |
Dépannage et résolution des problèmes
Ces procédures doivent être utilisées uniquement pendant la configuration initiale. Elles ont pour but de vérifier que le matériel a été correctement configuré. Elles ne sont pas destinées à être utilisées comme procédures de dépannage des systèmes configurés utilisant des données de production et des E/S.

REMARQUE : Pour plus d'informations sur la résolution des problèmes après la configuration et lorsque des données sont présentes, rendez-vous sur la page dell.com/support.
- Méthodologie de localisation des pannes
- Les LED du boîtier 2U Voyants LED du boîtier 5U84
- Problèmes de démarrage initiaux
Méthodologie de localisation des pannes
Les systèmes de stockage Série ME5 offrent de nombreuses méthodes de localisation des pannes. Cette section présente la méthode de base permettant de localiser les pannes sur un système de stockage et d'identifier les unités CRU concernées.
Utilisez le logiciel PowerVault Manager pour configurer et provisionner le système à l'issue de l'installation du matériel. Configurez et activez les notifications d’événements pour être informé lorsqu’un problème d’une gravité égale ou supérieure à celle configurée survient. Pour plus d’informations, reportez-vous au guide de l’administrateur du système de stockage Dell PowerVault série ME5 (Dell PowerVault ME5 Series Storage System Administrator's Guide).
Lorsque vous recevez une notification d'événement, suivez les actions recommandées dans le message de notification pour résoudre le problème. En outre, reportez-vous aux rubriques suivantes pour obtenir des conseils de dépannage :
- Options disponibles pour l'exécution des étapes de base
- Exécution des étapes de base E/S hôte
Le câblage des systèmes pour répliquer les volumes est un autre facteur important d'isolation des pannes à prendre en compte lors de l'installation initiale du système. Reportez-vous au guide de déploiement des systèmes de stockage Série ME5 (ME5 Series Storage Systems Deployment Guide) pour plus d'informations sur le dépannage lors de la configuration initiale.
Options disponibles pour l'exécution des étapes de base
Lors de l'exécution des étapes de dépannage et de localisation des pannes, sélectionnez la ou les options qui conviennent le mieux pour votre environnement de site.
Vous pouvez PowerVault Manager pour vérifier les indicateurs d'intégrité du système ou pour examiner un composant problématique. Si vous détectez un problème, PowerVault Manager ou l'interface CLI fournit un texte en ligne indiquant l'action recommandée. Les options d'exécution des étapes de base sont répertoriées en fonction de la fréquence d'utilisation :
- Utilisez PowerVault Manager Utilisez le CLI
- Vérifiez les notifications d'événements - Vérifiez les LED du boîtier
Utilisez powervault manager
Utilisez PowerVault Manager pour surveiller l'intégrité du système et de ses composants. Si un composant présente un problème, PowerVault Manager indique que l'intégrité du système est Dégradée, Défaillante ou Inconnue. Utilisez PowerVault Manager pour trouver les composants défectueux et suivez les actions du champ Recommandation pour le composant afin de résoudre le problème.
Utilisez le CLI
Comme une alternative à l'utilisation de PowerVault Manager, vous pouvez exécuter la commande CLI show system pour afficher l'intégrité du système et de ses composants. Si un composant a un problème, l'interface de ligne de commande indique que l'intégrité du système est Dégradée, Défaillante ou Inconnue et ces composants seront répertoriés comme défectueux. Suivez les actions recommandées dans le champ recommandation d'intégrité des composants pour résoudre le problème.
Vérifiez les notifications d'événements
Une fois la notification d'événements configurée et activée, vous pouvez afficher les journaux d'événements pour surveiller l'intégrité du système et de ses composants. Si un message vous indique de vérifier si un événement a été consigné ou d'afficher des informations sur un événement, utilisez PowerVault Manager ou l'interface de ligne de commande.
- A l'aide de PowerVault Manager, affichez le journal des événements, puis cliquez sur le message d'événement pour afficher les détails de cet événement.
- À l'aide de l'interface de ligne de commande, exécutez la commande show events detail pour afficher les détails d'un événement.
Vérifiez les LED du boîtier
Veuillez afficher les voyants du matériel pour identifier l'état des composants. Si un problème empêche l'accès à
PowerVault Manager ou à l'interface de ligne de commande, l'affichage des voyants du boîtier est la seule option disponible.
Exécution des étapes de base
Vous pouvez utiliser n'importe laquelle des options disponibles décrites dans les sections ci-dessus pour exécuter les étapes de base pour la localisation des pannes.
Recueil des informations liées à la panne
Lorsqu'une panne survient, recueillez le plus d'informations possible. Cela vous aidera à déterminer l'action correcte nécessaire pour la réparer.
Commencez en examinant la panne signalée :
La panne se rapporte-t-elle à un chemin interne de données ou un chemin de données externes? La panne se rapporte-t-elle à un composant matériel, par exemple, un lecteur de disque module, module de contrôle ou bloc d'alimentation?
En localisant la panne sur l'un des composants du système de stockage, vous pouvez déterminer plus rapidement l'action corrective à préprendre.
Determinez où la panne se produit
Lorsqu'une panne a lieu, la Fault LED du module s'allume. Vérifiez les voyants situés à l'arrière du boîtier pour identifier l'unité remplaçable par le client (CRU) et/ou la connexion sur laquelle la panne a eu lieu. Les voyants aident également à identifier l'emplacement d'une unité CRU qui signale une panne.
Utilisez PowerVault Manager pour vérifier les éventuelles défaillances détectées pendant l'affichage des voyants LED ou si les voyants LED ne peuvent pas être affichés en raison de l'emplacement du système. La vue Maintenance > Matériel fournit une représentation visuelle du système et présente les pannes lorsqu'elles se produisent. PowerVault Manager fournit également des informations plus détaillées sur les composants remplaçables par l'utilisateur, les données et les pannes.
Vérification des journaux d'événements
Le journal des événements enregistre tous les événements système. Chaque événement a un code numérique qui identifie le type d'événement qui s'est produit et identifie la gravité :
- Critique : une panne pouvant entraîner l'arrêt d'un contrôleur s'est produite. Corrigez le problème immédiatement.
Erreur : une panne pouvant entraver l'intégrité des données ou la stabilité du système s'est produite. Corrigez le problème dès que possible. - Avertissement : un problème qui peut avoir un impact négatif sur la stabilité du système, mais pas sur l'intégrité des données est survenu. Évaluez-le et corriguez-le si nécessaire. - Informatif : un changement de configuration ou d'état a eu lieu ou un problème qui a été résolu par le système est survenu. Aucune intervention immédiate n'est requise.
Les journaux d'événements enregistrent tous les événements système. Examinez-les pour localiser les pannes ainsi que leur cause. Par exemple, un hôte peut perdre la connectivité à un groupe de disques si un utilisateur modifie les paramètres de canal sans prendre en compte les ressources de stockage qui lui sont affectées. De plus, le type de panne peut vous aider à localiser le problème au niveau du matériel ou des logiciels.
Identifier la panne
Il s'avère parfois nécessaire de localiser une panne en raison des chemins d'accès des données et du nombre de composants qu'ils incluent. Par exemple, l'un des composants du chemin d'accès des données peut provoquer une erreur de données côté hôte : module contrôleur, câble ou hôte de données.
E/s hôte
Afin de protéger les données, arrêtez les E/S en direction des groupes de disques concernés et en provenance de tous les hôtesses lors de la correction des pannes de lecteur de disque et de connectivité.
Par mesure de précaution supplémentaire en matière de protection des données, il est utile d'effectuer régulièrement des sauvegardes programmes de vos données.
Les LED du boîtier 2U
Utilisez les voyants situés sur le boîtier 2U pour résoudre les problèmes liés au démarrage initial.
Panneau OPS du boîtier 2U
Le panneau OPS se trouve à l'avant du boîtier, sur la bride de la anse gauche du boîtier 2U. Ce panneau fait partie du châssis du boîtier, mais il n'est pas replacable sur site.
Figure 31. Voyants du panneau OPS : panneau avant du boîtier 2U
Tableau 9. Fonctions du panneau OPS : panneau avant du boîtier 2U
| Indicator(Voyant) | Description: Couleur Statut | |
| Alimentation du système | Vert Allumé en coontinu: au moins un PCM fournit une alimentationÉteint: le système n'est pas sous tension, indépendamment de la présence de CA |
Tableau 9. Fonctions du panneau OPS : panneau avant du boîtier 2U (suite)
| Indicator(Voyant) | Description: Couleur Statut | |
| État/Intégrité Bleu Allumé | en continu: le système est sous tension et le contrôleur est prétsClignotant (2 Hz): la gestion du boîtier est occupée (par exemple, lors du démarriage ou de l'exécution d'une mise à jour du firmware) | |
| Orange Allumé en continu: panne de module présente (peut être associée à une Fault LED sur un module de contrôleur, un module d'E/S ou un PCM)Clignotant: panne logique (2 secondes allumé, 1 seconde éteint) | ||
| Affichage de l'identification de l'unité(UID) | Vert L'UID se présente sur un double affichage à sept segments qui indique la position numérique du boîtier dans la série de câblage. Il est également désigné sous le nom d'ID de boîtier. L'ID de boîtier du contrôleur est 0. | |
| Identité Bleu Clignotant (0,25 Hz): le localiseateur d'ID système est activé pour aider àlocaliser le boîtier dans un datacenter.Eteint: état normal |
LED PCM du boîtier 2U
Dans des conditions normales, les LED OK du module de refroidissement de l'alimentation (PCM) seront d'un vert fixe.
Tableau 10. États des LED PCM
| PCM OK (vert) | Panne du ventilateur (orange) | Panne CA (orange) | Panne CC (orange) | Statut |
| Éteint Éteint Éteint Éteint Pas d'alimentation | CA sur aucun des PCM | |||
| Éteint Éteint Allumé Allumé Pas d'alimentation | CA sur ce PCM seulement | |||
| Allumé Éteint Éteint Alimentation CA présente : PCM en état de fonctionnement | ||||
| Allumé Éteint Éteint Allumé La vitesse du ventilateur du PCM est en dehors des limites acceptables | ||||
| Éteint Allumé Éteint Éteint Le ventilateur du PCM est en panche | ||||
| Éteint Allumé Allumé Allumé Panne du PCM (température excessive, tension excessive, courant excessif) | ||||
| Éteint Clignotant Clignotant Clignotant Le téléchargement du firmware du PCM est en cours | ||||
LED du panneau OPS du boîtier 2U
Le panneau OPS affiche l'état agrégé de tous les modules. Le tableau suivant décrit les états des voyants LED du panneau OPS.
Tableau 11. États des voyants du panneau OPS
| Alimentation du système (vert/orange) | Panne de module (orange) | Identité (bleu) | Affichage duvoyant | Voyants/Alarmes associés | Statut |
| Allumé | Éteint | Éteint | -- | -- | Alimentation en mode veille 5 V, panne ou extinction de l'alimentation générale |
| Allumé | Allumé | Allumé | Allumé | -- | Alimentation du panneau des opérations en phase test (5 s) |
| Allumé | Éteint | Éteint | -- | -- | Mise sous tension, toutes les fonctions sont bonnes |
Tableau 11. États des voyants du panneau OPS (suite)
| Alimentation du système (vert/orange) | Panne de module (orange) | Identité (bleu) | Affichage duvoyant | Voyants/Alarmes associés | Statut |
| Allumé Allumé -- -- | Voyants de panne | du PCM, voyants de panne du ventilateur | Toute défaillance du PCM, du ventilateur, température au-dessus ou en-dessous | ||
| Allumé Allumé -- -- | Voyants du module | SBB | Toute panne du module SBB | ||
| Allumé Allumé -- -- Pas de voyants de | module | Panne logique du boîtier | |||
| Allumé Clignotant -- | -- Voyant d' état du | module sur module SBB | Type de module SBB installé inconnu (non valide ou mixte), panne de bus 12C (communications inter SBB). Erreur de configuration VPD DEBATS | ||
| Allumé Clignotant -- | -- Voyants de panne | du PCM, voyants de panne duventilateur | Type de PCM installé inconnu (non valide ou mixte) ou panne de bus 12C (communications PCM) | ||
| --- -- -- Clignotant -- | Identifiant de boîtier | ou ID non valde | s'électionné | ||
Actions:
Si la Fault LED du module du panneau des opérations est allumée, vérifie les voyants du module sur le panneau arrêté du boîtier pour limiter la panne à un CRU, à une connexion ou les deux. - Recherche dans le journal des événements toute information spécifique concernant la panne et suivez les actions recommandées. - Si vous installez un CRU d'IOM :
Retirez et reinsérez la carte du module d'E/S.
Recherche des erreurs dans le journal des événements.
Si la Fault LED CRU est allumée, une panne est détectée.
Redémarrez ce contrôleur à partir du contrôleur partenaire à l'aide du gestionnaire PowerVault Manager ou de l'interface CLI. Si le redémarrage ne résout pas l'incident, retirez l'IOM et réinsérez-le.
Les LED du module support de lecteur de disque du boîtier 2U
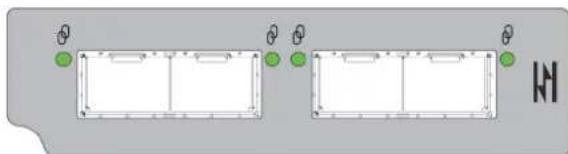
L'état du lecteur de disque est surveillé à l'aide d'une LED verte et d'une LED orange placées à l'avant de chaque module support de lecteur, comme illustré sur la figure suivante.
La figure suivante permet d'identifier les LED du module support de lecteur et le tableau explique le comportement de chacune des LED.
En fonctionnement normal, la LED verte s'allume et se met à clignoter lorsque le lecteur est en fonctionnement. - En fonctionnement normal, la LED orange s'allume :
oHors tension s'il n'y a un lecteur présent.
Hors tension tant que le lecteur fonctionne.
En fonctionnement, s'il y a une panne de lecteur.

Figure 32. LED : les LED du support de lecteur (modules SFF et LFF) utilisées dans les boîtiers 2U
- LED d'activité du disque 2. LED de panne du disque
- LED de panne du disque 4. LED d'activité du disque
Tableau 12. États des LED du support de disque
| LED d'activité (vert) Voyant LED de panne | te (orange) État/condition* | |
| Éteint Éteint Éteint (module de disque/boîtier) | ||
| Éteint Éteint Absent | ||
| Clignotant quand actif Clignotant : 1 s allumé | 1 s éteint Identifier | |
| •1 vers le bas : clignotant quand actif •2 vers le bas : éteint | Allumé Liaison du lecteur (voie PHY) en panne | |
| Allumé Allumé Panne (restant/èchec/verrouille) | ||
| Clignotant quand actif Éteint Disponible | ||
| Clignotant quand actif Éteint Système de stockage : initiaisation | ||
| Clignotant quand actif Éteint Système de stockage : tolérant aux pannes | ||
| Clignotant quand actif Éteint Système de stockage : dégradé (non | critique) | |
| Clignotant quand actif Clignotant : 3 s allumé | 1 s éteint Système de stockage : dégradé (critique) | |
| Allumé Éteint Système de stockage : mis en quarantaine | ||
| Clignotant quand actif Clignotant : 3 s allumé | 1 s éteint Système de stockage : hors ligne (fin de la quarantaine) | |
| Clignotant quand actif Éteint Système de stockage : relance | ||
| Clignotant quand actif Éteint Traitement des E/S (qu'elles proviennent | de l'hôte ou d'une activités interne) | |
| *Si plusieurs conditions se produit simultanément, la LED se comporte suivant la condition indiquée dans le tableau, les lignes étant lues de haut en bas. | ||
Voyants du module d'e/s
L'état du module d'E/S est surveillé par les voyants LED situés sur la plaque frontale. Le tableau suivant décrit les comportements des voyants LED des modules d'E/S du boîtier d'extension.
Tableau 13. Voyants LED du module IOM du boîtier d'extension
| Voyant Description : Couleur Statut | ||
| X | Panne de module Orange Allumé | •Panneau OPS en cours de test 5 s |
Tableau 13. Voyants LED du module IOM du boîtier d'extension (suite)
| Voyant Description : Couleur Statut | |||
| Défaillance du module de la zone du panneau arrêté : module d'E/S,ventilateur, bloc d'alimentation, lorsqu'il est associé auvoyant LED de défaillance du moduleDéfaillance matérielle du module de disque, lorsqu'il est associé auvoyant LED de défaillance du lecteur de disque | |||
| Clignotant• Type de module inconnu, non valide ou mixte, tel que module de lecteurde disque ou bloc d'alimentationErreur de configuration des données de produit vitales (VPD) oudéfaillance du bus I2C | |||
| Éteint : le module d'E/S fonctionne correctement | |||
| Mise sous tension ou en veille | Vert Allumé : le moduole d'E/S est sous tension | ||
| Orange Allumé : faitpartie de la série de veille lorsque le module d'E/S est mis en ligne | |||
| Aucun Éteint : l'alimentation du module d'E/S est hors tension | |||
| ID | Identification de l'unité (UID) | Blanc Allumé : voyageant UID actif pour localiser ou identifier l'activité de maintenance | |
| Éteint :voyant UID non actif | |||
| 12Gbit/s | Port SAS12 Gbit/s | Vert Allumé : connecté, la liaison est active | |
| Éteint :non connecté ou liaison hors service | |||
| Orange Allumé : défaillance critique du cable SAS | |||
| Flash rapide (1s:1s):voyant UID SAS actif | |||
| Flash lent (3s:1s):panne de cable SAS non critique | |||
| Éteint :le port d'extension SAS fonctionne correctement | |||
| Port Ethernet --- Le port Ethernet est désactivé | |||
Voyants du module de contrôleur 12 gbit/s
Les diagrammes et les tableaux qui suivent immédiatement fournissent des descriptions concernant les différents modules de contrôle qui peuvent être installés dans le panneau arrière des boîtiers de contrôleurs.

REMARQUE : Tenez compte des éléments suivants lorsque vous consulterez les diagrammes de modules de contrôleur sur les pages suivantes :
- Dans chaque diagramme, le module de contrôleur est orienté pour insertion dans le logement supérieur (A) des boîtiers 2U. Lorsqu'ils sont orientés pour utilisation dans le logement inférieur (B) des boîtiers 2U, les étiquettes des modules de contrôleur apparaissent à l'envers.
- 'un des logements des boîtiers 5U84.
- Veuillez également configurer le boitier de contrôleur 2U avec un seul module de contrôleur. Installez le module de contrôleur dans le logement A, puis installez un cache dans le logement B.
Figure 33. Module de contrôle Série ME5
Tableau 14. Voyants LED des modules de contrôleur courants
| Voyant Description : Couleur Statut | |||
| ✓ | Matériel normal Vert Allumé : | le module de contrôleur | fonctionne correctement |
| Clignotant : fait partie de la série de veille lorsque le module de contrôleur est mis en ligne | |||
| Éteint : le module de contrôleur est hors tension, le module de contrôleur est hors ligne ou le module de contrôleur présente une panne | |||
| A | Panne matérielle Orange Allumé : | panne matérielle du | module de contrôleur |
| Éteint : le module de contrôleur fonctionne correctement | |||
| B | OK pour-retirer Blanc Allumé : | préts pour le retrait, le cache est effacé | cache est effacé |
| Éteint : ne retirez pas le module de contrôleur, le cache contient toujours des données non écrites | |||
| C | Identifier Bleu Allumé : l'identifi cation de l'unité (UID) | est active | |
| Éteint : état normal, l'UID n'est pas actif | |||
| COBE | État du cache Vert Allumé : le cache contient des do | nées non écrites, le module de contrôleur fonctionne correctement | |
| Flash rapide (1 s:1 s) : le cache est actif, le vidage du cache est en cours | |||
| Flash lent (3 s:1 s) :actualisation automatique du cache en cours après le vidage du cache | |||
| Éteint : le cache est vide ou le système est en ligne | |||
| θ | Vitesse du port de gestion Ethernet | Orange Allumé : taux | hégocié 1000 Base-T |
| Éteint : taux négocié 10/100Base-T | |||
| ACT Activité de liaison du port de gestion Ethernet | Vert Allumé : la liaison | Ethernet est active | |
| Éteint : la liaison Ethernet est hors service | |||
| θ | État du port d'extension SAS 12 Gbit/s | Vert Allumé : connecté, la liaison est active | |
| Vert ou orange Clignodant : activité de liaison | |||
| Orange Allumé : connexion, liaison partielle activée | |||
| Aucun Éteint : non connecté ou liaison hors service | |||
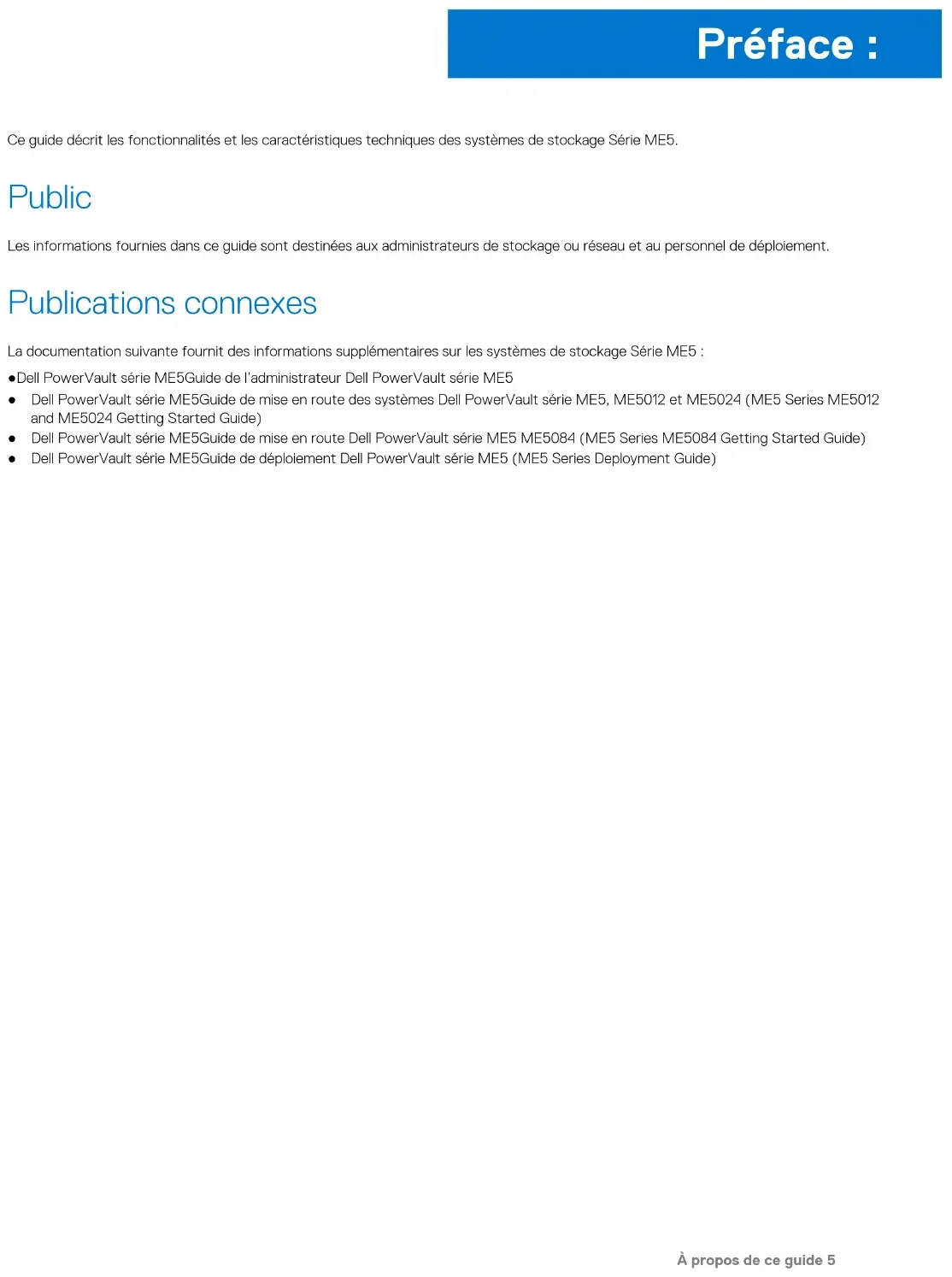
La figure suivante présente les voyants LED du port hôte sur un module de contrôleur Fibre Channel 32 Gbit/s :
| Voyant | Description : Couleur Statut | ||
| ® | Activité de liaison Fibre Channel | Vert Allumé : connecté, la liaison est active | |
| Clignotant : activités de liaison | |||
| Éteint : non connecté ou liaison hors service | |||
La figure suivante présente les voyants LED du port hôte sur un module de contrôle iSCSI 25 GbE :
Figure 35. Ports iSCSI 25 GbE
| Voyant Description : Couleur Statut | |||
| ® | Activité de liaison iSCSI Vert Allumé : connecté, la liaison est active | ||
La figure suivante présente les voyants LED du port hôte sur un module de contrôle iSCSI 10Gbase-T :
Figure 36. Ports iSCSI 10Gbase-T
| Voyant Description : Couleur Statut | |||
| ® | Vitesse de liaison ISCSI 10Gbase-T | Vert Allumé : vitesse de liaison 10 GbE | |
| Orange Allumé : vitesse de liaison 1 GbE | |||
| Aucun Éteint : non connecté ou liaison hors service | |||
| ACT Activité de liaison ISCSI 10Gbase-T | Vert Allumé : connecté, la liaison est active | ||
La figure suivante présente les voyants LED du port hôte sur un module de contrôle SAS 12 Gbit/s :
Figure 37. Ports SAS 12 Gbit/s
| Voyant | Description : Couleur Statut | ||
| Δθ | État du port SAS Vert Allumé | connecté, la liaison est active | |
| Vert ou orange Clignant : activités de liaison | |||
| Orange Allumé : connexion, liaison partielle activée | |||
| Aucun Éteint : non connecté ou liaison hors service | |||
Voyants LED du boîtier 5U84
Lorsque le boîtier 5U84 est sous tension, tous les voyants LED s'allument brievement pour vérifier qu'ils fonctionnent.
REMARQUE : Ce comportement n'indique pas de panne, sauf si les voyants LED restent allumés après plusieurs secondes.
Panneau des opérations du boîtier 5U
Le panneau OPS se trouve à l'avant du boîtier, sur la bride de la anse gauche du boîtier 5U. Ce panneau fait partie intégrante du châssis du boîtier, mais il n'est pas replacable sur site.
Figure 38. Voyants du panneau OPS : panneau avant du boîtier 5U
Tableau 15. Fonctions du panneau OPS : panneau avant du boîtier 5U
| Indicator(Voyant) | Description: Couleur | Statut | |
| Affichage de l'identification de l'unité (UID) | Vert L'UID se presenta sur un double affichage à sept segments qui indique la position numérique du boîtier dans la série de câblage. Il est également désigné sous le nom d'ID de boîtier. L'ID de boîtier du contrôleur est 0. | ||
| Système Allumé/Veille | Vert Allumé en con tinu : l'alimentation du système est disponible (opérationnelle) | ||
| Orange Orange fixe : système en veille (non opérationnel) | |||
| Panne de module Orange | Constante ou clignotante : panne matérielle du système. Le voyant LED de défaillance du module peut être associé à une Fault LED sur un module de contrôleur, un module D'E/S, un bloc d'alimentation, un module FCM, un DDIC ou un tiroir. | ||
| Voyant LED d'état logique | Orange Constante ou clignotante : présence d'une défaillance ne provenant pas du système de gestion du boîtier. Le voyage LED d'état logique peut être initiaè depuis le module du contrôleur ou un adaptateur HBA externe. L'indication est généralement associée à un module DDIC et à des voyants LED à chaque position de disque au sein du tiroir, ce qui vous permet d'identifier le module DDIC affecté. | ||
| Panne du tiroir supérieur | Orange Constante ou clignotante : présence d'une panne au niveau du lecteur, d'un cable ou du panier latéral (tiroir 0) | ||
| Panne du tiroir inférieur | Orange Constante ou clignotante : présence d'une panne au niveau du lecteur, d'un cable ou du panier latéral (tiroir 10) | ||
Voyants LED du bloc d'alimentation ME5084
Le tableau suivant décrit les états des voyants du module PSU.
Tableau 16. États des voyants du bloc d'alimentation
| Panne du CRU (orange) | CA absent (orange) | Alimentatio n (vert) | Statut |
| Allumé Éteint Éteint Pas d'alimentation secteur vers l'un ou l'autre bloc | |||
| Allumé Allumé Éteint PSU préSENT, mais ne foiturnissant pas l'alimentation ou l'état d'alerte du PSU.(généralement en raison de la température critique) | |||
| Éteint Éteint Allumé Présence secteur CA, mise sous tension. Ce PSU fournit l'alimentation. | |||
Tableau 16. États des voyants du bloc d'alimentation (suite)
| Panne du CRU (orange) | CA absent (orange) | Alimentatio n (vert) | Statut |
| Éteint Éteint Clignotant Alimentation secteur | Présente, PSU en veille (l'autre PSU fournit l'alimentation). | ||
| Clignotant Clignotant Éteint Tél'échéancement | du micrologiciel du PSU en cours | ||
| Éteint Allumé Éteint Alimentation secteur mar | quante, PSU en veille (l'autre PSU fournit l'alimentation). | ||
| Allumé Allumé Allumé Le micrologiciel a perdu | la communication avec le module du PSU. | ||
| Allumé | -- Éteint | Le bloc d'alimentation est en panne. Suivez la procédure désrite dans la section Remise en place d'un bloc d'alimentation. | |
Voyants LED du module FCM ME5084
Le tableau suivant décrit les voyants situés sur la plaque avant du module de refroidissement du ventilateur (FCM) :
Tableau 17. États des LED du module FCM
| Voyant État/ | description |
| Module OK | Unvoyant vert fixe indique que le module FCM fonctionne correctement. Unvoyant étéint indique que le module de ventilation est en panne. Suivez la procédure décrite dans la section Remplacement d'un module de refroidissement par ventilateur. |
| Défaillanceduventilateur | Unvoyant orange indique que le module de ventilation est en panne. Suivez la procédure décrite dans la sectionRemplacement d'un module de refroidissement par ventilateur. |
Voyants LED du panneau OPS ME5084
Le panneau OPS affiche l'état agrégé de tous les modules.
Tableau 18. États des voyageurs du panneau OPS
| Voyant État/ | description |
| Affichage de l'ID d'unité | Indique généralement le nombre d'identification du boîtier, mais peut être utilisé à d'autres fins, par exemple, en clignotant pour localiser le boîtier. |
| Sous tension/Veille | Ambre si le système est en mode veille. Vert si le système a sa puissance maximale. |
| Panne de module | Un voyage orange indique une erreur dans un module de contrôleur, un IOM, un PSU ou un FCM. Vérifiez que les voyants du tiroir n'indiquent pas une défaillance du disque. |
| État logique Ambre indique une panne provenant d'autre chose qu'un micrologiciel (généralement un disque, un HBA, ou un contrôleur RAID interne ou externe). Vérifiez les LED du tiroir pour avoir une indication sur une panne de disque.. Reportez-vous à la section Voyants LED du tiroir ME5084. | |
| Erreur du tiroir 0 | La couleur orange indique une panne de disque, de cable ou de fond de panier latéral dans le tiroir 0. Ouvrez le tiroir et vérifiez si les DDIC sont défectueux. |
| Erreur du tiroir 1 | La couleur orange indique une panne de disque, de cable ou de fond de panier latéral dans le tiroir 1. Ouvrez le tiroir et vérifiez si les DDIC sont défectueux. |

PRECAUTION : Les fonds de panier lateraux sur les tiroirs de boitier ne sont pas échangeables à chaud et ne peuvent pas faire l'objet de maintenance par le service clientèle.
Voyants LED du tiroir ME5084
Le tableau suivant décrit les voyants des tiroirs.
Tableau 19. États des LED de tiroir
| Voyant État/description | |
| Fond de panier létal OK/Alimentation OK | En vert si le fond de panier létal fonctionne, et qu'il n'y a pas de problèmes d'alimentation. |
| Panne du tiroir | En orange si un composant du tiroir est défectueux. Si le composant défectueux est un disque, levoyant du support DDIC défectueux s'allume en orange. Suivez la procédure décrite dans la section Remplacement d'un support DDIC dans un boîtier 5U. Si les disques sont en bon état, contactez votre prestataire de services pour identifier la cause de la panne et résoudre le problème.PRECATION : Les fonds de panier latéraux sur les tiroirs de boîtier ne sont pas échéangeables à chaud et ne peuvent pas faire l'objet de maintenance par le service clientèle. |
| Panne logique | Orange (fixe) indique une erreur de disque. Orange (clignotant) indique qu'un ou plusieurs systèmes de stockage sont impactés. |
| Câble défectueux | Orange indique que le câblage entre le tiroir et l'arrière du boîtier est défectueux. Contactez votre prestataire de services pour résoudre le problème. |
| Diagramme à barres d'activité | Affiche la quantité d'E/S de données à partir du segment zéro allumé (pas d'E/S) jusqu'àux six segments allumés (E/S maximum). |
Voyants DDIC ME5084
Le DDIC prend en charge les disques LFF 3,5" et SFF 2,5". La figure suivante montre le panneau supérieur du DDIC tel qu'il est vu lorsque le disque est aligné pour insertion dans un logement de tiroir.
Figure 39. LED : DDIC, logement de disque de boîtier 5U dans le tiroir
- Faites glisser le loquet (sur la gauche)
- Bouton du loquet (illustré en position de verrouillage)
- Fault LED de lecteur
Tableau 20. États des LED de module DDIC
| Fault LED (orange) État/description* | |
| Éteint Éteint (module de disque/boîtier) | |
| Éteint Absent | |
| Clignotant : 1 s allumé / 1 s éteint | Identifier |
| Toutes liaisons en panne : allumé | Liaison du lecteur (voie PHY) en panne |
| Allumé Panne (restant/étrched | /verrouillé) |
| Éteint Disponible | |
| Éteint Système de stockage : | initialisation |
Tableau 20. États des LED de module DDIC (suite)
| Fault LED (orange) État/description* | |
| Éteint Système de stockage : | tolerant aux pannes |
| Éteint Système de stockage : | dégradé (non critique) |
| Clignotant : 3 s allumé / 1 s éteint | Système de stockage : dégradé (critique) |
| Éteint Système de stockage : | mis en quarantaine |
| Clignotant : 3 s allumé / 1 s éteint | Système de stockage : hors ligne (fin de la quarantaine) |
| Éteint Système de stockage : | reliance |
| Éteint Traitément des E/S (qu'elles proviennent de l'hôte ou d'une activités interne) | |
| *Si plusieurs conditions se produit simultanément, l'état de la LED se comporte comme indiqué par la condition indiquée dans le tableau, les lignes étant lues de haut en bas. | |
Chaque DDIC dispose d'une seule Fault LED de disque. Une défaillance de disque est indiquée si cette Fault LED s'allume en orange. En cas de panne de disque, effectuez le remplacement.
Voyants LED des modules de contrôleur 5U84 et d'e/s
Les CRU des modules de contrôle et des IOM sont communs aux boîtiers 2U et 5U84.
Pour plus d'informations sur les voyants LED du module de contrôleur, reportez-vous à la section Voyants LED du module de contrôleur 12 Gbit/s. Pour plus d'informations sur les voyants LED du module d'E/S, reportez-vous à la section Voyants LED du module d'E/S.
Problèmes de démarrage initiaux
Les sections suivantes décrivent la procédure à suivre pour résoudre les problèmes liés au démarrage initial.
Dépannage des boîtiers 2U
Problèmes fréquents au niveau du système de boîtier 2U.
La Fault LED du module du panneau OPS passe en orange pour indiquer une panne correspondant à l'un des problèmes répertoriés dans le tableau suivant :

REMARQUE : Toutes les alarmes sont également signalées via le SES.
Tableau 21. Dépannage des conditions d'alarme 2U
| Statut Gravité Alarme | ||
| Alerte PCM : perte d'alimentation en courant continu à partir d'un seul module PCM | Panne : perte de redondance S1 | |
| Défaillance du ventilateur PCM Panne : perte de redondance S1 | Panne PCM détectée dans le module SBB Panne S1 | |
| PCM retire Erreur de configuration Aucun | ||
| Erreur de configuration du boîtier (VPD) Panne : critique S1 | Alerte de température basse Avertissement S1 | |
| Alerte de température haute Avertissement S1 | Alerte de température haute Avertissement S1 | |
| Alerte de surchauffe Panne : critique S4 |
Tableau 21. Dépannage des conditions d'alarme 2U (suite)
| Statut Gravité Alarme | ||
| Défaillance du bus l'2C Panne : perte de redondance S1 | ||
| Erreur de communication du panneau OPS (l'2C) Panne : c | critique S1 | |
| Erreur RAID Panne : critique S1 | ||
| Panne du module de l'interface SBB Panne : critique S1 | ||
| Module d'interface SBB retireé Avertissement Aucun | ||
| Panne du bouton d'alimentation du disque Avertissement : | pas de perte de puissance disque S1 | |
| Panne du bouton d'alimentation du disque Panne : critique | : perte de puissance disque S1 | |
| Disque retireé Avertissement Aucun | ||
| Puisance disponible insuffisante Avertissement Aucun |
Pannes du PCM
Tableau 22. Actions recommandées en cas de pannes du PCM
| Symptôme Cause Action recommendée | ||
| La Fault LED de panne du module du panneau OPS est orange. | Toute panne d'alimentation | Vérifiez que les connexions secteur CA du PCM sont sous tension. |
| Le voyant LED de panne du ventilateur s'allume sur le PCM. | Défaillance du ventilateur | Remplacer le PCM |
Surveillance et contrôle thermique
Le système de boîtier de stockage utilise une surveillance thermique approfondie et prend un certain nombre de mesures pour s'assurer que la température des composants reste basse et minimiser le bruit. La circulation d'air s'effectue de l'avant vers l'arrière du boîtier.
Tableau 23. Actions de surveillance thermique recommandées
| Symptôme | Cause | Action recommendée |
| Si l'air Ambient est inférieur à 25 °C (77 °F) et que la vitesse des ventilateurs augmente, une certaine restriction de la circulation d'air peut entraîner une augmentation supplémentaire de la température interne. REMARQUÉ: Ce n'est pas une panne. | La première étapé du processus de régulation thermique consiste à augmenter automatiquement la vitesse des ventilateurs lorsqu'un seul thermique est atteint. Ceci peut être causé par des Températures ambientes plus élevées dans l'environnement local, et peut être parfaitement normal. REMARQUÉ: Ce seuil change en fonction du nombre de disques et de blocs d'alimentation installés. | 1. Vérifiez si l'installation présente des restrictions de la circulation d'air à l'avant ou à l'arrière du boîtier. Il est recommendé de laisser un espace minimum de 25 mm (1") à l'avant et de 50 mm (2") à l'arrière.2. Vérifiez s'il y a des restrictions dues à l'accumulation de poussière. Nettoyez le cas échéant.3. Vérifiez la recirculation excessive de l'air chauffé de l'arrière vers l'avant. Il n'est pas recommandé d'utiliser le boîtier dans un rack entière fermé.4. Vérifiez que tous les modules vides sont en place.5. Réduisez la température ambiente. |
Alarme thermique
Tableau 24. Actions recommandées en cas d'alarme thermique
| Symptôme Cause Action recommendée | ||
| 1. La LED de panne du module du panneau OPS est orange.2. La LED de panne du ventilateur s'allume sur un ou plusieurs PCM. | La température interne dépasse le seuil prédéfini pour le boîtier. | 1. Vérifiez que la température de l'environnement ambient local est comprise dans la plage acceptable.2. Vérifiez si l'installation présente des restrictions de la circulation d'air à l'avant ou à l'arrière du boîtier. Il est recommendé de laisser un espace minimum de 25 mm (1") à l'avant et de 50 mm (2") à l'arrière.3. Vérifiez s'il y a des restrictions dues à l'accumulation de poussière. Nettoyez le cas échéant.4. Vérifiez la recirculation excessive de l'air chauffé de l'arrière vers l'avant. Il n'est pas recommandé d'utiliser le boîtier dans un rack entièrement fermé.5. Si possible, arrêtez le boîtier et analysez le problème avant de continuer. |
Dépannage des boîtiers 5U
Problèmes fréquents au niveau du système de boîtier 5U.
La Fault LED du module du panneau OPS passe en orange pour indiquer une panne correspondant à l'un des problèmes répertoriés dans le tableau suivant :

REMARQUE : Toutes les alarmes sont également signalées via le SES.
Tableau 25. Conditions d'alertes 5U
| Statut Gravité | |
| Alerte PSU : perte d'alimentation en courant continu à partir d'un seul module PSU | Panne : perte de redondance |
| Panne du module de refroidissement du ventilateur Panne : perte de redondance | |
| Panne détectée du PSU du module d'E/S SBB Panne | |
| PSU retiree Erreur de configuration | |
| Erreur de configuration du boîtier (VPD) Panne : critique | |
| Alerte de température basse Avertissement | |
| Avertissement concernant la température Avertissement | |
| Alerte de surchauffe Panne : critique | |
| Alerte de sous chauffe Panne : critique | |
| Défaillance du bus l'2C Panne : perte de redondance | |
| Erreur de communication du panneau OPS (l'2C) Panne : critique | |
| Erreur RAID | Panne : critique |
| Panne du module d'E/S SBB | Panne : critique |
| Le module d'E/S SBB a été retire | Avertissement |
| Panne du bouton d'alimentation du disque | Alerte : aucune perte de transmission d'alimentation |
| Panne du bouton d'alimentation du disque | Panne critique : perte de l'alimentation du lecteur |
| Puisance disponible insuffisante | Avertissement |
REMARQUE : Utilisez le logiciel PowerVault Manager pour consulter les événements relatifs au boîtier consignés dans les journaux d'événements du système de stockage et pour déterminer les actions nécessaires.
Considérations thermiques
Les capteurs thermiques du boîtier 5U84 et ses composants surveillent l'état thermique du système de stockage.
Le dépassement des limites des valeurs critiques déclenchera l'alarme de surchauffe. Pour plus d'informations sur les alertes du boîtier 5U84, reportez-vous à Conditions d'alertes 5U.
Si le boîtier ne démarre pas
L'initialisation de tous les boîtiers peut prendre jusqu'à deux minutes.
Si un boitier ne s'initialise pas :
- Relancez l'analyse
- Soumettre le système à un cycle d'alimentation. Assurez-vous que le câble d'alimentation est correctement connecté et vérifiez la source d'alimentation à laquelle il est connecté. Vérifiez le journal des événements pour afficher les erreurs.
Correction des ID du boîtier
Lors de l'installation d'un système auxquels sont connectés des boîtiers d'extension, les ID de boîtier peuvent ne pas correspondre à l'ordre de câblage physique. Ce problème survient lorsque le contrôleur a été précédemment relié à des boîtiers dans une autre configuration et que le contrôleur tente de conserver les ID de boîtier précédents.
Pour le contourner, veillez à allumer les deux contrôleurs, puis effectuez une nouvelle analyse à l'aide du logiciel PowerVault Manager ou de l'interface de ligne de commande. La nouvelle analyse réorganise les boîtiers, mais la correction des ID de boîtier peut prendre jusqu'à deux minutes.
REMARQUE : L'action de reorganisation des ID de boîtier s'applique uniquement au mode à deux contrôleurs. Si plusieurs contrôleurs sont disponibles en raison d'une panne de contrôleur, la nouvelle analyse manuelle ne reorganise pas les ID des boîtiers d'extension.
- Pour relancer l'analyse avec le PowerVault Manager :
a. Vérifiez que les deux contrôleurs fonctionnent normalement. b. Sélectionnez Maintenance > Matériel c. Sélectionnez Actions > Relancer l'analyse de tous les disques d. Cliquez sur Rescan (Analyser de nouveau).
- Pour relancer l'analyse avec le CLI, tapez la commande suivante : rescan
Dépannage des pannes matérielles
Assurez-vous que vous disposez d'un module de remplacement du même type avant de retirer tout module défectueux.
REMARQUE: Si le système de boîtier est sous tension et que vous retirez un module, remplacez-le immédiatement. En effet, si le système est utilisé avec des modules manquants pendant plusieurs secondes, les boîtiers peuvent surchauffer, provoquant une panne de courant et une perte potentielle de données. Une telle action peut entraîner l'annulation de la garantie du produit. REMARQUE : Observez les précautions appropriées et conventionnelles relatives aux décharges électrostatiques lors de la manipulation des modules et des composants. Évitez tout contact avec les composants du fond de panier central, les connecteurs de module, les câbles, les broches et les circuits exposés.
Identification d'une panne de connexion côté hôte
En fonctionnement normal, lorsqu'un port hôte d'un module contrôleur est connecté à un hôte de données, le voyant d'état de la liaison hôte/activité de liaison du port est vert. En cas d'activité d'E/S, le voyant d'activité de l'hôte clignote en vert. Si les hôttes de données ont des problèmes d'accès au système de stockage et que vous ne pouvez pas localiser une panne spécifique ou accéder aux journaux d'événements, suivez les procédures ci-dessous. Ces procédures nécessitent un temps d'arrêt programme.

REMARQUE : N'effectuez pas plus d'une étape à la fois. Changer plus d'une variable à la fois peut compliquer le processus de dépannage.
Dépannage de connexion côte hôte avec ports hôtes 10gbase-t et SAS
La procédure suivante s'applique aux boîtiers de contrôleur SERE ME5 utilisant des connecteurs externes dans les ports d'interface hôte.
Parmi les connecteurs externes figurent les connecteurs 10Gbase-T dans les ports hôte iSCSI et les connecteurs SFF-8644 12 Gbit/s dans les ports hôte mini-SAS HD.
- Arrêtez toutes les E/S du système de stockage.
- Vérifiez la LED d'activité de l'hôte.
En cas d'activité, arrêtez toutes les applications qui accèdent au système de stockage.
- Vérifiez la LED de l'état de la mémoire cache pour vérifier que les données mises en cache par le contrôle sont évacuées vers les disques durs.
Fixe : la mémoire cache contient des données qui n'ont pas encore été écrites sur le disque. - Clignotant : les données du cache sont en cours d'écriture dans le module de contrôleur. - Clignotant à 1/10 de seconde et 9/10 seconde sur off (Désactivé) : le cache est en cours de régénération par le supercondensateur. - Off (Désactivé) : le cache est propre (aucune données non écrites).
- Retirez le câble d'hôte et vérifiez qu'il n'est pas endommagé.
- Repositionnez le câble d'hôte.
Est-ce que la LED d'état de la liaison de l'hôte est sous tension ?
Oui: surveillez l'état pour s'assurer qu'il n'y a pas d'erreur intermittente. Si la panne se reproduit, nettoyez les connexions pour vous assurer qu'un connecteur sale n'interfère pas avec le chemin d'accès des données. Non: passez à l'étape suivante.
- Déplacez le cable hôte sur un port ayant un état de liaison en bon état.
Cette étape permet d'identifier le problème pour le chemin d'accès des données externes (cable de l'hote et périhériques cote hote) ou vers le port du module de contrôleur.
Est-ce que la LED d'état de la liaison de l'hôte est sous tension ?
Oui : vous savez à présent que le câble hôte et les périphériques côté hôte fonctionnent correctement. Reinstallez le câble sur le port d'origine. Si le voyant d'état de liaison reste éteint, vous avez identifié la panne sur le port du module de contrôleur. Remettez en place le module de contrôleur. Non: passez à l'étape suivante.
- Vérifiez que le commutateur, le cas échéant, fonctionne correctement. Si possible, testez avec un autre port.
- Vérifiez que le HBA est bien en place et que l'emplacement PCI est sous tension et opérationnel.
- Remplacez le HBA par un HBA fonctionnel reconnu, ou déplacez le câble côte hôte à une bonne HBA.
Est-ce que la LED d'état de la liaison de l'hôte est sous tension ?
- Oui : vous avez identifié que la panne provenait du HBA. Remplacez le HBA. Non : il est probable que le module de contrôle doive être remplacé.
- Déplacez le câble hôte vers son port d'origine.
Est-ce que la LED d'état de la liaison de l'hôte est sous tension ?
Oui: surveillez la liaison sur une période donnée. Il s'agit peut-être un problème intermittent, ce qui peut se produire avec des câbles et des HBA endommagés. - Non: le port du module contrôleur est défectueux. Remplacer le module contrôleur.
Identification d'une panne de connexion du port d'extension d'un module contrôleur
En mode de fonctionnement normal, lorsque le port d'extension d'un module de contrôleur est connecté à un boîtier d'extension, le voyant d'état du port d'extension est vert. S'il est éteint, cela signifie que la liaison est interrompue.
Utilisez la procédure ci-après pour localiser la panne. Cette procédure nécessite un temps d'arrêt programme.

REMARQUE : N'effectuez pas plus d'une étape à la fois. Changer plus d'une variable à la fois peut compliquer le processus de dépannage.
- Arrêtez toutes les E/S du système de stockage.
- Vérifiez la LED d'activité de l'hôte.
En cas d'activité, arrêtez toutes les applications qui accèdent au système de stockage.
- Vérifiez la LED de l'état de la mémoire cache pour vérifier que les données mises en cache par le contrôle sont évacuées vers les disques durs.
Fixe : la mémoire cache contient des données qui n'ont pas encore été écrites sur le disque. - Clignotant : les données du cache sont en cours d'écriture dans le module de contrôleur. - Clignotant à 1/10 de seconde et 9/10 seconde sur off (Désactivé) : le cache est en cours de régénération par le supercondensateur. - Off (Désactivé) : le cache est propre (aucune données non écrites).
- Retirez le câble d'extension et vérifiez qu'il n'est pas endommagé.
- Repositionnez le câble d'extension.
La LED d'état du port d'extension est-elle sous tension?
Oui : surveillez l'état pour s'assurer qu'il n'y a pas d'erreur intermittente. Si la panne se reproduit, nettoyez les connexions pour vous assurer qu'un connecteur sale n'interfère pas avec le chemin d'accès des données. Non : passez à l'étape suivante.
- Déplacez le cable d'extension sur un port du boîtier de contrôle ayant une liaison en bon état.
Cette étape permet de localiser le problème sur le cable d'extension ou le port d'extension du module de contrôleur.
La LED d'état du port d'extension est-elle sous tension?
Oui : vous savez maintenant que le cable d'extension n'est pas defectueux. Repositionnez le cable dans le port d'origine. Si le voyant d'état du port d'extension reste éteint, vous avez localisé la panne sur le port d'extension du module de contrôleur. Vous nevez alors remplacer le module de contrôleur. Non: passez à l'étape suivante.
- Déplacez le cable d'extension arrière sur le port d'origine du boîtier de contrôleur.
- Déplacez le cable d'extension du boîtier d'extension vers un port d'extension en bon état sur le boîtier d'extension.
Est-ce que la LED d'état de la liaison de l'hôte est sous tension ?
Oui : vous avez localisé la panne sur le port du boîtier d'extension. Vous devez aussi remplacer le module IOM dans le boîtier d'extension. Non: passez à l'étape suivante.
- Remplacez le câble par un câble réputé fiable, en vous assurant que les câbles d'origine sont reliés aux ports utilisés par le câble précédent.
Est-ce que la LED d'état de la liaison de l'hôte est sous tension ?
Oui : remplacez le câble d'origine. La panne a été isolée. Non : il est probable que le module de contrôle doit être remplacé.
Retrait et remplacement d'un module
Ce chapitre contient les instructions de substitution des pièces remplaçables par le client (également appelées unités CRU), y compris des consignes de précaution, les instructions de retrait, les instructions d'installation et la vérification de l'installation. Chaque procédure se concentre sur une tâche particulière.
- Mises en garde concernant les décharges électrostatiques (ESD)
- Traitement des pannes matérielles Mises à jour de firmware - Arrêt des hôtes rattachés
- Arrêt d'un module de contrôleur
- Vérification de l'échec d'un composant - Unités remplaçables par l'utilisateur (CRU)
- Verification du bon fonctionnement du composant
- Exécution de mises à jour dans PowerVault Manager après le remplacement d'un adaptateur HBA Fibre Channel ou SAS.
Mises en garde concernant les décharges électrostatiques (ESD)
Avant de commencer toute procédure, passez en revue les mises en garde et mesures préventives suivantes.
Prévention contre les décharges électrostatiques
Pour empêcher que des décharges électrostatiques (ESD) endommagent le système, prenez les précautions nécessaires lorsque vous configurez le système ou que vous manipulez des pièces. Une décharge d'électricité statique provenant de votre doigt ou de tout autre conducteur peut endommager les cartes système ou les autres périphériques sensibles. Ce type de dommage peut réduire la durée de vie du périphérique.

PRECAUTION : Les décharges électrostatiques peuvent endommager les pièces. Prenez les précautions suivantes :
- Évitez tout contact avec les produits en les transportant et en les stockant dans des emballages antistatiques.
- Conservez les pièces sensibles dans leur emballage jusqu'à ce qu'elles se trouvent sur des stations de travail protégées contre les décharges électrostatiques.
- Placez les pièces dans une zone antistatique avant de les sortir de leur emballage.
- Evitez de toucher les broches, les fils et les circuits. Veillez à vous mettre à la terre avant de toucher un composant ou un assemblage sensible à l'électricité statique.
- Retirez tous les matériaux pouvant encercler la station de travail antistatique (plastique, vinyle, mousse).
Méthodes de mise à la terre pour empêcher les décharges électrostatiques
Il existe plusieurs méthodes de mise à la terre. Respectez les précautions suivantes lorsque vous manipulez ou que vous installez des pièces sensibles à l'électricité statique.

PRECAUTION : Les décharges électrostatiques peuvent endommager les pieces. Utilisez une protection antistatique adaptée :
- Conservez l'unité CRU de rechange dans le sachet antistatique jusqu'à ce que vous en ayez besoin, et lorsque vous retirez une unité CRU du boîtier, placez-la immédiatement dans le sachet et l'emballage antistatique.
- Portez un bracelet antistatique relié par un fil de terre à une station de travail mise à la terre ou à une surface sans peinture du châssis de l'ordinateur. Les bracelets antistatiques sont des bandes couples avec un minimum de 1 mègohm (± 10 %) de résistance dans les fils de terre. Pour assurer une bonne mise à la terre, portez le bracelet bien serré contre la peau.
- Si vous n'avez pas de bracelet antistatique à disposition, touchez une surface non peinte du châssis avant de manipuler le composant.
- Utilisez des sangles de mise à la terre pour les talons, les orteils ou les bottes lorsque vous travailliez debout à la station de travail. Portez les sangles sur les deux chaussures lorsque vous vous tenez debout sur des sols conducteurs ou des tapis dissipatifs.
- Utilisez des outils d'entretien sur le terrain conducteurs. Utilisez un kit portable d'entretien sur le terrain avec un tapis de travail pliant dissipant les décharges électrostatiques.
Si vous ne disposez pas de l'un des équipements conseillés pour une mise à la terre correcte, demandez à un technicien autorisé d'installer la pièce. Pour plus d'informations sur l'électricité statique ou pour obtenir une assistance pour l'installation du produit, contactez le support technique. Pour plus d'informations, consultez le site www.dell.com/support.
Traitement des pannes matérielles
Assurez-vous que vous avez un module de remplacement du même type avant de retirer tout module defectueux.

Precaution:
- Si le boîtier est sous tension et que vous enlevez un module, remettez-le en place immédiatement. Si le boîtier fonctionne trop longtemps avec un module retiré, il risque de surchauffer, provoquant une coupure d'alimentation et une perte potentielle de données. Une telle utilisation peut invalider la garantie du produit.
- Observez les précautions appropriées et conventionnelles relatives aux décharges électrostatiques lors de la manipulation des modules et des composants, comme décrit dans Mises en garde concernant les décharges électrostatiques (ESD). Évitez tout contact avec les composants du fond de panier central, les connecteurs de module, les câbles, les broches et les circuits exposés.
Mises à jour de firmware
Après l'installation du matériel et la première mise sous tension des composants du système de stockage, assurez-vous que les modules de contrôleur, d'extension et les lecteurs de disque utilisent la version actuelle du firmware. Assurez-vous régulièrement que les versions de firmware utilisées dans les modules du boîtier sont compatibles.
Mise à jour du firmware partenaire
La mise à jour du firmware partenaire (PFU) est activée sur le système par défaut. Avec la mise à jour PFU activée, lorsque vous mettez à jour le firmware d'un contrôleur ou remplacez un contrôleur, le système met automatiquement à jour le contrôleur partenaire. Désactivez la mise à jour PFU uniquement si vous y êtes invités par un technicien de maintenance. Utilisez PowerVault Manager ou l'interface de ligne de commande pour modifier les options PFU.
Pour un système à deux contrôleurs, le paramètre de mise à jour du firmware partenaire (PFU) (Paramètres > Système > Propriétés > Propriétés du firmware) contrôle l'impact des mises à jour sur le contrôleur partenaire :
- Automatique : l'option PFU est activée (valeur par défaut). Lorsque vous activé le firmware du module de contrôleur sur un contrôleur, le firmware est automatiquement copé et activé sur le contrôleur partenaire, puis activé sur le contrôleur actuel. l'option PFU permet de mettre à jour le firmware du module d'extension de la même manière.
- Manuel : l'option PFU est désactivée. Lorsque vous mettez à jour le firmware du module de contrôleur ou du module d'E/S du boîtier sur un contrôleur, vous devez acceder au contrôleur partenaire et effectuer manuellement les mêmes mises à jour.
Lorsqu'un module de contrôleur est installé dans un boîtier en usine, le numéro de série du fond de panier central du boîtier et l'horodatage de mise à jour du firmware sont enregistrés pour chaque composant du firmware dans la mémoire Flash du contrôleur et ne sont pas effacés lorsque la configuration est modifiée ou rétablit les valeurs par défaut. Ces deux données ne sont pas présentes dans les modules de contrôleur qui ne sont pas installés en usine et qui sont utilisés pour le remplacement.
La mise à jour du firmware du contrôleur avec l'option PFU activée garantit que la même version du firmware est installée dans les deux modules de contrôleur. L'option PFU utilise l'algorithme suivant pour déterminer quel module de contrôleur met à jour son partenaire :
Si les deux contrôleurs exécutent la même version du firmware, aucune modification n'est apportée. Le contrôleur installé en premier envoie sa configuration et ses paramètres au contrôleur partenaire. De même, si un contrôleur est remplacé, il reçoit les informations de configuration du contrôleur partenaire. Dans les deux cas, le comportement de mise à jour du firmware suivant pour les deux contrôleurs est déterminé par le paramètre PFU unifié du système. Si les deux contrôleurs ont déjà été installés dans le système, le contrôleur dont le firmware est installé en premier envoie sa configuration et ses paramètres au contrôleur partenaire. Si les deux contrôleurs sont nouvellement installés, le contrôleur A est transféré vers le contrôleur B.
Installation d'une offre groupée de firmwares
Dans PowerVault Manager, utilisez l'onglet Maintenance > Firmware > Système pour installer les offres groupées de firmwares obtenues auprès de Dell, puis activez une offre groupée particulière.
Passez en revue les points suivants avant de mettre à jour le firmware du système :
- La mise à jour du firmware prend généralement 5 minutes pour un contrôleur doté du firmware CPLD actuel, ou jusqu'à 20 minutes pour un contrôleur doté d'un firmware CPLD de niveau inférieur. Développez la ligne du firmware pour afficher la version du CPLD (Maintenance > Firmware). Si le contrôleur de stockage ne peut pas être mis à jour, l'opération de mise à jour est annulée. Verifiez que vous avez spécifié le bon fichier de firmware et répétez la mise à jour. Exécutez l'interface de ligne de commande check firmware-upgrade-health pour déterminer si un problème doit être résolu avant de tenter de mettre à jour le firmware. Si ce problème persiste, contactez le support technique. Lorsque la mise à jour du firmware sur le contrôleur local est terminée, les utilisateurs sont automatiquement disconnected et le contrôleur de gestion redémarre. Tant que le redémarrage n'est pas terminé, des pages de connexion s'affichent pour informer que le système est actuellement indisponible. Lorsque ce message disparaît, vous pouvez vous reconnecter. Si la fonctionnalité de mise à jour de firmware partenaire (PFU) est activée, la durée de mise à jour des deux contrôleurs est inférieure à 10 minutes. Si la fonctionnalité de mise à jour de firmware partenaire (PFU) est activée pour le système (Paramètres > Système > Propriétés > Propriétés du firmware > case Mise à jour du firmware partenaire), une fois la mise à jour du firmware terminée sur les deux contrôleurs, vérifiez l'intégrité du système. Si l'intégrité du système est dégradée et que le motif de l'intégrité indique que la version du firmware est incorrecte, vérifiez que vous avez spécifié le bon fichier de firmware et répétez la mise à jour. Si ce problème persiste, contactez le support technique.
Si la fonctionnalité PFU est désactivée, vous devez localiser, installer et activer le firmware compatible sur le module d'extension de remplacement.
- Téléchargez le firmware à partir de Dell.com.
- Accédez à Maintenance > Firmware > Système.
- Cliquez sur Rechercher un fichier et accédez à l'offre groupée de firmwares téléchargée
- Suivez les instructions qui s'affichent à l'écran pour installer le firmware.
Activation d'une offre groupée de firmwares
Une fois qu'une offre groupée de firmware est disponible pour le système, activez le firmware pour terminer sa mise à jour.
- Accédez à Maintenance > Firmware > Système, puis cliquez sur son lien Activer cette version pour afficher la boîte de dialogue Activer le firmware.
- Suivez les instructions qui s'affichent à l'écran pour démarrer l'activation.
Dans le cadre du processus d'activation, le système effectue les étapes suivantes : vérifier l'intégrité de l'offre groupée, vérifier l'intégrité du système, mettre à jour le firmware sur le module de contrôleur partenaire, redémarrer le module de contrôleur partenaire, mettre à jour le firmware sur le module de contrôleur local et redémarrer le module de contrôleur local. Une fois le module de contrôleur local redémarré, l'écran de connexion à PowerVault Manager s'affiche. Reconnectez-vous et accédez au panneau Maintenance > Firmware et vérifiez que le nouveau firmware est actif sur le système. Une alerte est également générée pour vous informer que le firmware a été mis à niveau.
Si l'activation du firmware échoue, accédez à Maintenance > Support > Collector les journaux, renseignez les champs nécessaires et collectez les journaux. Ces journales seront nécessaires pour toute demande de support générale par cette défaillance.
Arrêt des hôtes rattachés
Pour remplacer des modules dans un boîtier de contrôleur 2U doté d'un module de contrôleur, vous devez arrêter tous les hôtes rattachés avant d'arrêter le module de contrôleur.
Arrêt d'un module de contrôleur
L'arrêt du module de contrôleur dans un boîtier garantit l'utilisation d'une série de basculements correcte, y compris l'arrêt de toutes les opérations d'E/S et l'écriture de toutes les données depuis le cache en écriture vers le disque. Arrêtez le module de contrôleur avant de le retirer d'un boîtier ou avant la mise hors tension d'un boîtier pour des raisons de maintenance, de réparation ou de transport.
Utilisation de powervault manager
- Connectez-vous au logiciel PowerVault Manager.
- Accédez à Maintenance > Matériel.
- Sous Boîtier>Actions, sélectionnez Redémarrer/Arrêter le système. Le panneau Redémarrage et arrêt du contrôleur s'affiche.
- Sélectionnez l'opération Arrêt.
- Sélectionnez le module de contrôle à arrêté : A, B ou both (les deux).
- Cliquez sur Appliquer. Un volet de confirmation s'affiche.
- Cliquez sur Yes (Oui) pour continuer. Sinon, cliquez sur No (Non). Si vous avez cliqué sur Yes (Oui), un message décrit l'activité d'arrêt.
Si un port iSCSI est connecté à un hôte Microsoft Windows, l'événement suivant est enregistré dans le journal des événements Windows : Échec de connexion de l'initiateur à la cible. Pour plus d'informations, reportez-vous au document Dell PowerVault série ME5 Storage System Administrator's Guide (Guide d'administration du système de stockage Dell EMC PowerVault ME5 Series).
- Connectez-vous à la CLI.
- Dans votre système à double contrôleur, vérifiez que le contrôleur partenaire est en ligne en exécutant la commande : show controllers
- Arrêtez le contrôleur en panne (A ou B) à l'aide de la commande : shutdown a ou shutdown b
Le voyant bleu OK to Remove (OK pour retarder) à l'arrière du boîtier s'allume pour indiquer que le module de contrôleur peut être retardé en toute sécurité.
- Allumez le voyant LED d'identification blanc du boitier contenant le module de contrôleur à retarder en exécutant la commande : set led enclosure 0 on
Le voyant LED d'affichage du panneau OPS situé sur l'oreille gauche du boîtier clignote en vert à l'exécution de la commande set led enclosure 0 on.

REMARQUE : Pour plus d'informations, reportez-vous au document Dell PowerVault series ME5 Storage System CLI Guide (Guide d'interface CLI du système de stockage Dell EMC PowerVault ME5 Series).
Vérification de l'échéance d'un composant
Sélectionnez l'une des méthodes suivantes pour constater l'échec d'un composant :
- é, Panne ou Inconnu pour le système et de ses composants. Si vous découvrez un composant problème, suivez les actions dans son champ de commandes pour résoudre le problème.
- avez découvert un composant problématique, suivez les recommendations pour résoudre le problème. Surveillance de la notification d'événement : une fois la notification d'événement configurée et activée, utilisez le PowerVault Manager pour afficher le journal des événements, ou exécutez la commande de la CLI pour afficher les détails pour les événements. Vérifiez le voyant de défaillance (arrière du boîtier sur le module de contrôleur ou plaque avant de l'IOM) : orange = panne.
- Vérifiez que la LED OK (arrière du boîtier) est éteinte.
Unités remplaçables par l'utilisateur (CRU)
Les tableaux suivants décrivent les types de boîtiers de contrôle de la gamme Série ME5 :

REMARQUE: Reportez-vous aux sections Produit de base du boîtier 2U et Produit de base du boîtier 5U pour voir les unités CRU des modules de contrôleur et d'E/S utilisées dans les différents encombrements de boîtiers pris en charge par les systèmes de stockage Série ME5.
Tableau 26. Modèles de boîtiers de contrôle 2U Série ME5
| Modèle Description | n : Format Disques | ||
| ME5012 Fibre Channel | nel (32 Gbit/s) SFP 2U12 Jusqu'à 12 disques 3,5 pouces | (LFF) | |
| ME5012 iSCSI (25 GbE) SFP 2U12 Jusqu'à 12 disques 3,5 pouces (LFF) | |||
| ME5012 iSCSI 10Gbase-T (10 Gbit/s ou 1 Gbit/s)1 | 2U12 Jusqu'à 12 disques 3,5 pouces (LFF) | ||
| ME5012 HD mini-SAS (12 Gbit/s)2 | 2U12 Jusqu'à 12 disques 3,5 pouces (LFF) | ||
| ME5024 Fibre Channel | nel (32 Gbit/s) SFP 2U24 Jusqu'à 24 disques 2,5 pouces | (SFF) | |
| ME5024 iSCSI (25 GbE) SFP 2U24 Jusqu'à 24 disques 2,5 pouces (SFF) | |||
| ME5024 iSCSI 10Gbase-T (10 Gbit/s ou 1 Gbit/s)1 | 2U24 Jusqu'à 24 disques 2,5 pouces (SFF) | ||
| ME5024 HD mini-SAS (12 Gbit/s)2 | 2U24 Jusqu'à 24 disques 2,5 pouces (SFF) | ||
Ce modèle prend en charge des vitesses de 10 Gbit/s ou 1 Gbit/s (utilisé pour les connexions hôtes iSCSI). Ce modèle utilise des connecteurs SFF-8644 et des options de câble qualifiées pour les connexions hôtes.
Tableau 27. Modèles de boîtiers de contrôle 5U haute densité Série ME5
| Modèle Description | n : Format Disques | ||
| ME5084 Fibre Chan | nel (32 Gbit/s) SFP 5U84 Jusqu'à 84 disques 2,5 pouces | es (SFF) | ou 3,5 pouces (LFF) |
| ME5084 iSCSI (25 GbE) SFP1 | 5U84 Jusqu'à 84 disques | ques 2,5 pouces (SFF)ou 3,5 pouces (LFF) | |
| ME5084 iSCSI 10Gbase-T (10 Gbit/s ou 1 Gbit/s)1 | 5U84 Jusqu'à 84 disques | ques 2,5 pouces (SFF)ou 3,5 pouces (LFF) | |
| ME5084 HD mini-SAS (12 Gbit/s)2 | 5U84 Jusqu'à 84 disques | ques 2,5 pouces (SFF)ou 3,5 pouces (LFF) | |
Ce modèle prend en charge des vitesses de 10 Gbit/s ou 1 Gbit/s (utilise pour la connexion hôte iSCSI). Ce modèle utilise des connecteurs SFF-8644 et des options de câble qualifiées pour la connexion hôte.
Fixation ou retrait du panneau avant d'un boîtier 2U
La figure ci-dessous présente une vue partielle d'un boîtier 2U12 :
Figure 40. Connexion ou retrait du panneau avant du boîtier 2U
Pour fixer le panneau avant au boîtier 2U :
- Repérez le panneau et, en le tenant fermement avec vos deux mains, placez le panneau avant face au boîtier 2U12 ou 2U24.
- Accrochez l'extrémité droite du panneau au cache de l'anse droite du système de stockage.
- Insérez l'extrémité gauche du panneau dans le logement de fixation jusqu'à ce que le loquet de déverrouillage s'enclenche.
- Fixez le cadre à l'aide du verrouillage à clé.
Pour retirer le panneau du boîtier 2U, inversez l'ordre des étapes précédentes.

REMARQUE: Reportez-vous à Variantes de boitiers pour obtenir plus de détails sur différentes options de boitiers.
Remplacement d'un module support de lecteur dans un boîtier 2U
Cette section décrit la procédure de remplacement d'un module support de lecteur dans un boîtier 2U.
Un module support de lecteur est un lecteur de disque installé dans un module support. Les modules support de lecteur sont échangeables à chaud, ce qui signifie qu'ils peuvent être remplacés sans interrompre les E/S vers les groupes de disques ni mettre le boîtier hors tension. Le nouveau lecteur de disque doit être du même type, et sa capacité doit être supérieure ou égale à celle du lecteur en cours de remplacement. Dans le cas contraire, le système de stockage ne pourrait pas utiliser le nouveau lecteur de disque pour reconstruire le groupe de disques.

Precaution:
Le retrait d'un module support de disque a un impact sur la capacité de circulation d'air et de refroidissement du boîtier. Si la température interne dépasse les limites acceptables, le boîtier peut surchauffer et s'arrêter ou redémarrer automatiquement. Lors du retrait d'un module support de disque, attendez 30 secondes après la déinstallation du module pour permettre au lecteur de s'arrêter de tourner.

Remarque:
Familiarisez-vous avec les considérations FDE (Full Disk Encryption) relatives à l'installation et au remplacement d'un lecteur de disque. Lorsque vous déplacez des lecteurs de disque compatibles FDE pour un groupe de disques, arrêtez les E/S vers le groupe de disques avant de retirer les modules support de lecteur. Importez les clés des lecteurs de disque de façon à ce que leur contenu soit disponible. Pour plus d'informations, reportez-vous au Guide de l'administrateur du système de stockage Dell PowerVault série ME5 ou au Guide d'interface de ligne de commande du système de stockage Dell PowerVault série ME5.
Avant de commencer l'une de ces procédures, consultez la section Mises en garde concernant les décharges électrostatiques (ESD).
Remplacement d'un module support de lecteur LFF
Les procédures de remplacement des modules support de lecteur LFF sont les mêmes que pour les modules SFF, sauf que les modules support de lecteur LFF sont montés horizontalement.
Retrait d'un module support de lecteur LFF
Pour retirer un module support de lecteur LFF d'un boîtier 2U, procédez comme suit :
- Appuyez sur le loquet situé sur le module support de lecteur pour ouvrir la poignée.
Figure 41. Retrait d'un module support de lecteur LFF (1 sur 2)
- Déplacez délicatement le module support de lecteur d'environ 25 mm (1 pouce), puis attendez 30 secondes que le lecteur arrête de tourner.
Figure 42. Retrait d'un module support de lecteur LFF (2 sur 2)
- Retirez le module support de lecteur de son logement.

PRECAUTION : Pour assurer un refroidissement optimal dans le boitier, vous devez installer des modules support de cache de lecteur dans tous les logements de lecteurs inutilisés.
Installation d'un module support de lecteur LFF
Pour installer un module support de lecteur LFF dans un boîtier 2U, procédez comme suit :
- Appuyez sur le loquet situé sur le module support de lecteur pour ouvrir la poignée.
Figure 43. Module support de lecteur LFF en position ouverte
- Insérez le module support de lecteur dans le boîtier.
- Faites glisser délicatement le module support de lecteur dans le boîtier jusqu'à ce qu'il soit bloqué.
Figure 44. Installation d'un module de support de lecteur LFF (1 sur 2)
- Poussez le module support de lecteur dans le boîtier jusqu'à ce que le loquet commence à s'enclencher.
- Continuez à le pousser fermement jusqu'à ce que le loquet s'enclenche complètement. Vous devez entendre un déclic lorsque le loquet s'enclenche et se verrouille.
Figure 45. Installation d'un module de support de lecteur LFF (2 sur 2)
- Utilisez PowerVault Manager ou l'interface de ligne de commande (CLI) pour vérifier les éléments suivants:
si le nouveau lecteur de disque est intégré, si le voyant LED vert d'activité du disque est allumé ou clignote - si le panneau Ops ne présente aucune défaillance du module, représentée par une couleur orange
Remplacement d'un module support de lecteur SFF
Les procédures de remplacement des modules support de lecteur SFF sont les mêmes que pour les modules LFF, sauf que les modules support de lecteur SFF sont montés verticalement.
Retrait d'un module support de lecteur SFF
Pour retirer un module support de lecteur SFF d'un boîtier 2U, procédez comme suit :
- Appuyez sur le loquet situé sur le module support de lecteur pour ouvrir la poignée.
Figure 46. Retrait d'un module support de lecteur SFF (1 sur 2)
- Déplacez délicatement le module support de lecteur d'environ 25 mm (1 pouce), puis attendez 30 secondes que le lecteur arrête de tourner.
Figure 47. Retrait d'un module support de lecteur SFF (2 sur 2)
- Retirez le module support de lecteur de son logement.

PRECAUTION : Pour assurer un refroidissement optimal dans le boitier, vous devez installer des modules support de cache de lecteur dans tous les logements de lecteurs inutilisés.
Installation d'un module support de lecteur SFF
Pour installer un module support de lecteur SFF dans un boîtier 2U, procédez comme suit :
- Appuyez sur le loquet situé sur le module support de lecteur pour ouvrir la poignée.
Figure 48. Module support de lecteur SFF en position ouverte
- Insérez le module support de lecteur dans le boîtier.
- Faites glisser délicatement le module support de lecteur dans le boîtier jusqu'à ce qu'il soit bloqué.
Figure 49. Installation d'un module support de lecteur SFF (1 sur 2)
- Poussez le module support de lecteur dans le boîtier jusqu'à ce que le loquet commence à s'enclencher.
- Continuez à le pousser fermement jusqu'à ce que le loquet s'enclenche complètement. Vous devez entendre un déclic lorsque le loquet s'enclenche et se verrouille.
Figure 50. Installation d'un module support de lecteur SFF (2 sur 2)
- Utilisez PowerVault Manager ou l'interface de ligne de commande (CLI) pour vérifier les éléments suivants :
• si le nouveau lecteur de disque est intégré - si le voyant LED vert d'activité du disque est allumé ou clignote - si le panneau Ops ne présente aucune défaillance du module, représentée par une couleur orange
Remise en place d'un module support de cache de lecteur
Installez des modules support de cache dans tous les logements de lecteurs non utilisés pour assurer un refroidissement optimal sur l'ensemble du boîtier.
Pour retirer un module support de cache, appuyez sur le loquet situé sur le module et retirez-le du logement du lecteur.
Pour installer un module support de cache, inserez le module dans le logement de lecteur et enclenchez le module dans le logement de lecteur pour l'enclencher.
Remplacement d'un support DDIC dans un boîtier 5U
Cette section décrit la procédure de retrait et d'installation d'un DDIC (Disk Drive in Carrier) dans un boîtier 5U.
Un DDIC est composé d'un lecteur de disque installé dans un module support. Les modules support de lecteur sont échangeables à chaud, ce qui signifie qu'ils peuvent être remplacés sans interrompre les E/S vers les groupes de disques ni mettre le boîtier hors tension. Le nouveau lecteur de disque doit être du même type, et sa capacité doit être supérieure ou égale à celle du lecteur en cours de remplacement. Dans le cas contraire, le système de stockage ne pourrait pas utiliser le nouveau lecteur de disque pour reconstruire le groupe de disques.
Precaution:
- Le retrait d'un DDIC a un impact sur la capacité de circulation d'air et de refroidissement du boîtier. Si la température interne dépasse les limites acceptables, le boîtier peut surchauffer et s'arrêter ou redémarrer automatiquement. Lors du retrait d'un DDIC, patientez 30 secondes après avoir dégagé le support de sa position assise pour permettre au lecteur d'arrêt de tourner.
Familiarisez-vous avec les considérations FDE (Full Disk Encryption) relatives à l'installation et au remplacement d'un lecteur de disque. Lorsque vous déplacez des lecteurs de disque compatibles FDE pour un groupe de disques, arrêtez les E/S vers le groupe de disques avant de retirer les DDIC. Importez les clés des lecteurs de disque de façon que leur contenu soit disponible. Pour plus d'informations, reportez-vous au guide de l'administrateur du système de stockage Dell PowerVault série ME5 (Dell PowerVault ME4 Series Storage System Administrator's Guide) ou au guide d'interface de ligne de commande du système de stockage Dell PowerVault série ME5 (Dell PowerVault ME4 Series Storage System CLI Guide).
Avant de commencer l'une de ces procédures, consultez la section Mises en garde concernant les décharges électrostatiques (ESD).
Installation d'un lecteur de disque de remplacement 2,5 pouces dans un DDIC (disk drive in carrier)
Chaque lecteur de disque de remplacement est expédé avec un nouveau DDIC.
Avant d'ouvrir le tiroir du boîtier pour retirer le lecteur défaillant, installez le lecteur de remplacement dans le DDIC.
- Installez le lecteur de disque de remplacement 2,5 pouces dans le support de montage 3,5 pouces.
- Insérez le connecteur SAS dans l'interface SAS sur le lecteur de disque.

- Insérez le support de montage de 3,5 pouces avec le lecteur de disque 2,5 pouces dans l'assemblage inférieur.

- Retirez le film protecteur de l'assemblage supérieur du DDIC.
- Faites glisser l'assemblage supérieur du DDIC sur le support de montage avec le lecteur de disque 2,5 pouces.

- Fixez l'assemblage supérieur au support de montage à l'aide des vis fournies.
- Collez l'étiquette de taille de disque appropriée à l'emplacement de l'étiquette sur la partie supérieure de l'assemblage.
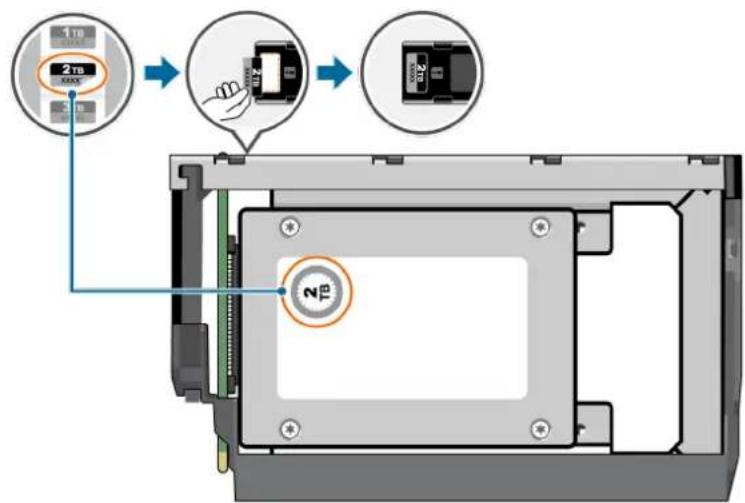
Installation d'un lecteur de disque de remplacement 3,5 pouces dans un DDIC (disk drive in carrier)
Chaque lecteur de disque de remplacement est expédié avec un nouveau DDIC.
Avant d'ouvrir le tiroir du boîtier pour retirer le lecteur défaillant, installez le lecteur de remplacement dans le DDIC.
- Insérez le connecteur SAS dans l'interface SAS sur le lecteur de disque.
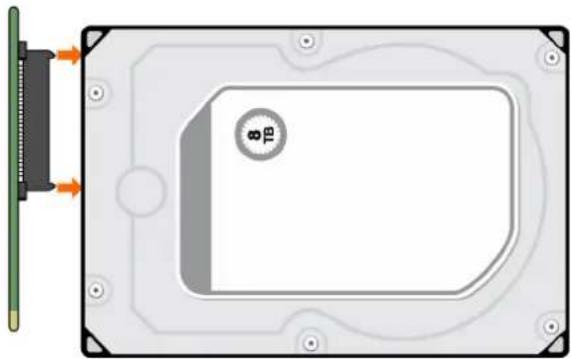
- Faites glisser le lecteur de disque dans l'assemblage inférieur du DDIC.

- Retirez le film protecteur de l'assemblage supérieur du DDIC.
- Faites glisser l'assemblage supérieur du DDIC sur le lecteur de disque.
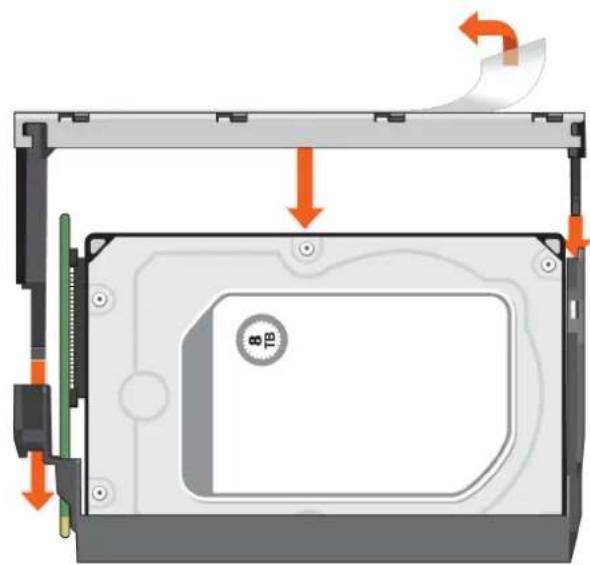
- Fixez l'assemblage supérieur au lecteur de disque à l'aide des vis fournies.
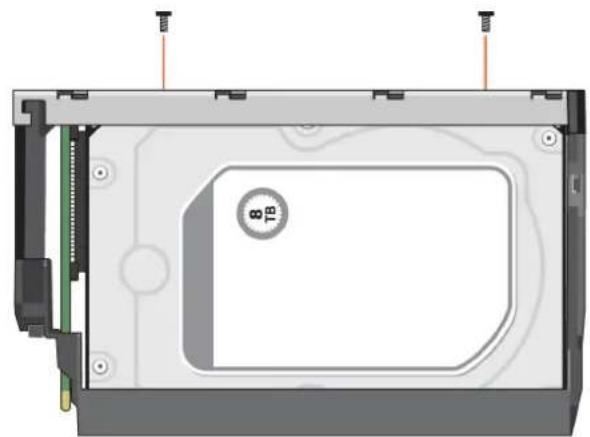
- Collez l'étiquette de taille de disque appropriée à l'emplacement de l'étiquette sur la partie supérieure de l'assemblage.
Accès aux tiroirs d'un chassin 5U84
La procédure de remplacement des DDIC doit être effectuée dans les deux minutes qui suivent l'ouverture d'un tiroir.
Ouverture d'un tiroir.
- Assurez-vous que les verrous antieffraction ne sont pas enclenchés. Les flèches rouges des verrous pointent vers l'intérieur si les verrous ne sont pas enclenchés, comme illustré sur la figure suivante. Déverrouillez-les si nécessaire en les faisant pivoter dans le sens contraire des aiguilles d'une montre à l'aide d'un tournevis Torx T20.
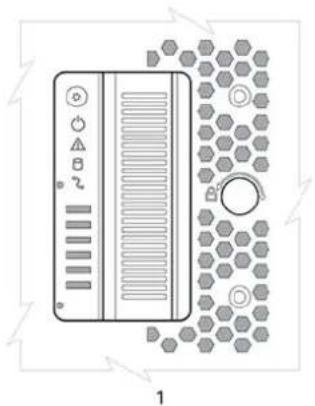
Figure 51. Détails du panneau avant du tiroir
1 Côte gauche 2 Côte droit 3 Verrou de sécurité 4 Fond de panier latéral OK/Alimentation OK 5 Panne du tiroir 6 Parne logique 7 Câble défectueux 8 Activité du tiroir 9 Poignée de tirage du tiroir
- Poussez les loquets du tiroir vers l'intérieur et tenez-les comme indiqué sur la figure suivante.
Figure 52. Ouverture d'un tiroir (1 sur 2)
- Tirez le tiroir vers l'extérieur jusqu'à ce qu'il s'enclenche dans le tiroir, comme le montre la figure suivante. Le tiroir s'affiche vide, ce qui correspond à la façon dont le boîtier est livré. Un loquet de verrouillage du rail coulissant est inséré dans le tiroir.
Figure 53. Ouverture d'un tiroir (2 sur 2)

REMARQUE : Le tiroir ne doit pas rester ouvert pendant plus de deux minutes lorsque le boîtier est sous tension.
Fermeture d'un tiroir
- Appuyez de façon prolongée sur les loquets noirs situés sur les côtés du tiroir ouvert sur chaque rail supérieur.
Le schéma précédent est une représentation agrandie d'un loquet de fixation, qui se situe sur les glissières gauche et droite du tiroir.
- Poussez légèrement le tiroir vers l'intérieur.
- Relâchez les loquets du tiroir.
- Poussez le tiroir jusqu'au fond du boîtier, en veillant à ce qu'il s'enclenche.
Retrait d'un support DDIC à partir d'un boîtier 5U
Retirez un support DDIC uniquement si un support DDIC de remplacement est disponible.

REMARQUE : Toute fermeture d'un tiroir dans lequel il manquerait un ou plusieurs supports DDIC pourrait entraîner des problèmes de refroidissement. Reportez-vous à la section Remplissage des tiroirs.
- Identifiez le tiroir qui contient le lecteur de disque à retarder.
Si le lecteur de disque est en panne, un voyant LED de défaillance s'allume sur le panneau avant du tiroir concerné. - Si le lecteur de disque est défaillant, la Fault LED de disque du support DDIC s'allume en orange.
- Ouvrez le tiroir qui contient le support DDIC à dégager.
- Déverrouillez le support DDIC pour le dégager de son logement en appuyant sur le loquet dans le sens indiqué sur la figure suivante :
Figure 54. Retrait d'un support de disque (1 sur 2)
- Tirez le support de disque vers le haut pour le sortir de l'emplacement du tiroir.
Figure 55. Retrait d'un support de disque (2 sur 2)
Installation d'un support DDIC dans un boîtier 5U
Les lecteurs de disque défaillants doivent être remplacés par des lecteurs de disque agréés. Pour en savoir plus, contactez votre prestataire de services.
- Alignez le support DDIC avec le logement de lecteur cible, puis insérez le support DDIC dans le logement du lecteur.
- Insérez le support DDIC dans son logement en l'inclinant vers le bas.
a. Poussez le DDIC vers le bas et maintenez-le. b. Faites glisser le loquet dans la direction indiquée dans la figure suivante :

Figure 56. installation d'un DDIC
- Faites glisser le loquet (sur la gauche)
- Loquet (illustré en position de verrouillage)
- Fault LED de lecteur
- Vérifiez les points suivants:
a. Le loquet est en position verrouillée. b. La Fault LED de disque n'est pas allumée.
- Fermez le tiroir.
Remplissage des tiroirs
Les consignes générales d'ajout de supports DDIC dans un tiroir sont fournies dans le guide de déploiement du système de stockage Dell PowerVault série ME5 (Dell PowerVault ME5 Series Storage System Deployment Guide). Des consignes supplémentaires sont indiquées pour remplacer les lecteurs de disque dans les tiroirs déjà occupés ou pour remplir les boîtiers équipés de l'option de configuration de type semi-rempli.
Préparation
Les lecteurs de disque sont fournis dans des packages d'extension de 42 lecteurs. Les clients utilisant plusieurs boitiers peuvent répartir les 42 lecteurs de disque d'un package d'extension dans plusieurs boitiers, sous réserve que 14 supports DDIC soient installés à la fois pour remplir complètement les rangées vides. Le modèle d'installation optimal en matière d'aération et de performances thermiques est décrit dans cette section.
Les tiroirs doivent contenir des supports DDIC dans toutes leurs rangées. Chaque tiroir contient 3 rangées de 14 supports DDIC. Voici les règles et hypothèses à prendre en compte :
Le nombre minimal de supports DDIC dans un boîtier est de 28.
Le nombre de rangées entre les tiroirs supérieurs et inférieurs ne doit pas être supérieur à 1. Le remplissage des rangées doit commencer par l'avant du tiroir, puis continuer vers l'arrière du tiroir. Si un second package d'extension de lecteurs de disque est livré à un client, ces lecteurs doivent correspondre à ceux qui ont été fournis à l'origine avec le boîtier 5U84. Les deux groupes de lecteurs de disque doivent partager le même type de modèle et la même capacité.

REMARK: Les références des packages d'extension ne sont pas répertoriées, car elles changent au fil du temps lorsque des lecteurs de disque sont livrés avec un nouveau firmware ou lorsque de nouveaux modèles de lecteurs de disque sont disponibles. Contactez notre ingénieur commercial pour connaître les références.
Si les deux groupes de lecteurs de disque ont des firmwares différents, tous les lecteurs de disque doivent être mis à jour avec le firmware actuel ou un firmware compatible. Reportez-vous au guide de l'administrateur du système de stockage Dell PowerVault series ME5 (Dell PowerVault ME5 Series Storage System Administrator's Guide) ou à l'aide en ligne pour en savoir plus sur la mise à jour du firmware.
Consignes d'installation
L'ordre recommandé pour installer partiellement les lecteurs de disque dans le boitier 5U84 permet d'optimiser la circulation d'air au sein du boitier. La vue à plat du tiroir du boitier 5U84 indique l'emplacement et l'indexation des tiroirs accessibles depuis le panneau avant du boitier.
Le boitier 5U84 est livré avec les tiroirs installés dans le châssis. Cependant, pour éviter tout choc électrique et tout problème de vibrations au cours du transport, le boitier n'est pas livré avec les supports DDIC installés dans les tiroirs. Un boitier est configuré avec 42 lecteurs de disque (semi-rempli) ou 84 lecteurs de disque (entièrement rempli) pour la livraison client. S'il est semi-rempli, les rangées contenant des lecteurs de disque doivent être remplies avec un ensemble complet de supports DDIC (aucun logement vide dans la rangée). La liste suivante identifie les rangées des tiroirs qui doivent contenir des supports DDIC lorsque le boitier est configuré comme semi-rempli :
Tiroir supérieur: rangée avant Tiroir supérieur: rangée du milieu Tiroir inférieur: rangée avant
Si des lecteurs de disque supplémentaires sont progressivement installés dans un boîtier semi-rempli, les supports DDIC doivent être ajoutés une rangée à la fois (en veillant à remplir tous les logements de chaque rangée) dans l'ordre indiqué :
Tiroir inférieur : rangée du milieu Tiroir supérieur : rangée arrière Tiroir inférieur : rangée arrière
Remplacement d'un module de contrôle ou d'un module d'e/s
Cet titre 10 10 10 10 10 10 10
Les boitiers 2U prennent en charge les configurations à un ou deux modules de contrôle. Les boitiers 5U84 prennent en charge uniquement configurations à deux modules de contrôle.
Si un module de contrôle partenaire tombe en panne, le contrôle bascule et s'exécute sur un seul module de contrôle jusqu'à ce que la redondance soit restaurée. Pour les boitiers 2U, un module de contrôle doit être installé dans le logement A, et un module de contrôle ou un cache de module doit être installé dans le logement B pour assurer une circulation suffisante de l'air via le boitier lors du fonctionnement. Pour les boitiers 5U84, un module de contrôle doit être installé à la fois dans le logement A et le logement B.
Dans une configuration à deux modules de contrôleur, les modules de contrôleur et les modules d'E/S sont échangeables à chaud. En d'autres termes, vous pouvez remplacer un module sans interrompre les E/S dans les groupes de disques ou sans mettre hors tension le boîtier. Dans ce cas, le second module de contrôleur prend le relais du système de stockage jusqu'à ce que vous ayez installé le nouveau module.
Voici les circonstances pouvant justifier le remplacement d'un module de contrôle ou d'un module d'E/S :
La Fault LED est allumée. Le rapport d'état d'intégrité dans PowerVault Manager indique qu'il y a un problème avec le module. Les événements dans PowerVault Manager indiquent un problème au niveau du module. Le dépannage indique qu'il y a un problème avec le module.
La figure des sections suivantes présente le remplacement du module de contrôleur pour le logement supérieur (A) du boîtier. Pour remplacer un module de contrôleur ou un module d'E/S dans le logement inférieur (B), faites pivoter le module afin de l'aligner correctement avec les connecteurs situés à l'arrière du fond de panier central.
Remplacement d'un module de contrôleurs dans un boîtier de module à deux contrôleurs
Lorsque deux modules de contrôleurs sont installés dans un boîtier, les modules de contrôleurs doivent être du même type de modèle.
Le retrait d'un module de contrôleur d'un boitier opérationnel modifie la circulation d'air dans le boitier. Laissez les modules de contrôleur dans le boitier jusqu'à ce que vous soyez prêt à installer un module de contrôleur de remplacement.

PRECAUTION : Lorsqu'un module de contrôleur est retired d'un boitier 2U, il doit etre remplace dans les cinq minutes pour eviter que le boitier ne surchauffe. Lorsqu'un module de contrôleur est retired d'un boitier 5U, il doit etre remplace dans les sept minutes pour eviter que le boitier ne surchauffe.
Suivez les consignes suivantes pour le remplacement d'un module de contrôleurs dans un boîtier opérationnel :
- Enregistrez les paramètres du module de contrôle dans PowerVault Manager avant de remplacer les modules de contrôle.
- Retirez le module de contrôle du boîtier.
- Placez le module de contrôleur de remplacement dans le boîtier.
- Patientez 30 minutes, puis utilisez PowerVault Manager ou l'interface de ligne de commande (CLI) pour vérifier l'état du système et les journaux d'événements afin de vous assurer que le système est stable.
REMARQUE: Si la fonctionnalité de mise à jour de firmware partenaire (PFU) n'est pas activée, mettez à jour le firmware du module de contrôleur de remplacement.
Suivez les consignes suivantes lors du remplacement des deux modules de contrôle dans un boîtier opérationnel :
- Enregistrez les paramètres du module de contrôleurs dans PowerVault Manager avant de remplacer les modules de contrôleur.
- Retirez l'un des deux modules de contrôle du boîtier.
- Placez le module de contrôleur de remplacement dans le boîtier.
- Patientez 30 minutes, puis utilisez PowerVault Manager ou l'interface de ligne de commande (CLI) pour vérifier l'état du système et les journaux d'événements afin de vous assurer que le système est stable.

REMARKUE: Si la fonctionnalité de mise à jour de firmware partenaire (PFU) n'est pas activée, mettez à jour le firmware du module de contrôleur de remplacement. Pour plus d'informations sur la mise à jour du firmware, reportez-vous au guide de l'administrateur du système de stockage Dell PowerVault série ME5 (Dell PowerVault ME5 Series Storage System Administrator's Guide).
- Retirez le deuxième module de contrôle du boîtier.
- Placez le module de contrôleur de remplacement dans le boîtier.
- Patientez 30 minutes, puis utilisez PowerVault Manager ou l'interface de ligne de commande (CLI) pour vérifier l'état du système et les journaux d'événements afin de vous assurer que le système est stable.

REMARQUE : Si la fonctionnalité de mise à jour de firmware partenaire (PFU) n'est pas activée, mettez à jour le firmware du module de contrôleur de remplacement. Pour plus d'informations sur la mise à jour du firmware, reportez-vous au guide de l'administrateur du système de stockage Dell PowerVault série ME5 (Dell PowerVault ME5 Series Storage System Administrator's Guide).
Retrait d'un module de contrôle d'un boîtier de module à deux contrôleurs
Suivez les étapes suivantes pour retirer un module de contrôle d'un boîtier de module à deux contrôleurs :
Avant de commencer toute procédure, voir la partie Précautions concernant les ESD.
- Vous ne pouvez échanger à chaud qu'un seul module de contrôleur dans un boî ueux à l'aide de PowerVault Manager ou de l'interface de ligne de commande.
- Ne retirez pas un module de contrôle défectueux à moins que vous ne disposiez d'un module de remplacement. Tous les modules de contrôle doivent être en place lorsque le système est en service.
- Vérifie que vous avez correctement arrêté le module de contrôleur à l'aide de PowerVault Manager ou de l'interface de ligne de commande.
- Localisez le boîtier dont le voyant LED d'identification d'unité (UID) est allumé.
- Dans le boîtier, localisez le module de contrôleur à retarder et assurez-vous que le voyant LED Ok pour retarder est allumé.
- Débranchez tous les câbles connectés au module de contrôleur. Étiquetez chaque câble pour faciliter le raccordement au nouveau module de contrôleur.
- Saisissez le loquet du module entre le pouce et l'index, et rapprochez la bride de la poignée afin de libérer le loquet, puis faites pivoter le loquet vers l'extérieur pour dégager le module de contrôleur.
- Faites pivoter la poignée du loquet pour l'ouvrir, puis saisissez-le et faites glisser doucement vers l'avant le module de contrôleur de son logement.

Figure 57. Retrait d'un module de contrôle installé dans un boîtier
REMARQUE: Cette figure présente un module de contrôle SAS à 4 ports. Toutefois, tous les modules de contrôle utilisent le même mécanisme de verrouillage.
- Placez les deux mains sur le corps du module de contrôleur, puis sortez-le directement du boîtier en veillant à ce que le module de contrôleur reste à niveau lors de son retrait.
Installation d'un module de contrôleur de remplacement dans un boîtier de module à deux contrôleurs
Suivez les étapes suivantes pour installer :
Avant de commencer toute procédure, voir la partie Précautions concernant les ESD.
- ez pas le module de contrôleur si les broches sont tordues.
- Saisissez le module de contrôle à l'aide des deux mains, et avec le loquet en position ouverte, orientez le module et alignez-le pour insertion dans le logement cible.
Figure 58. Installation d'un module de contrôleur
REMARQUE : Cette figure présente un module de contrôle SAS à 4 ports. Toutefois, tous les modules de contrôle utilisent le même mécanisme de verrouillage.
- En vous assurant que le module de contrôle est à niveau, faites-le glisser entièrement dans le boîtier.
Un module de contrôleur qui n'est que partiellement en place empêche le boîtier du contrôleur de produire des performances optimales. Vérifie que le module du contrôleur soit correctement installé avant de continuer.
- Fixez le module de contrôleur en position en fermant manuellement le loquet.
Vous entendez un clic lorsque la poignée de verrouillage se met en place et sécurise le module de contrôleur sur son connecteur à l'arrière du fond de panier central.
- Reconnectez les cables au module de contrôleur,

PRECAUTION : Si des cables en cuivre passifs sont branchés au module de contrôle, ils ne doivent pas etre reliés a un socle ou a un point de terre commun.
- Mettez à jour le firmware du module de contrôleur de remplacement vers la même version que l'autre module de contrôleur.
REMARQUE : Dans un système à deux modules de contrôleur sur lequel la mise à jour du firmware partenaire est activée, le système met automatiquement à jour le firmware sur un module de contrôleur de remplacement.
Remplacement d'un module de contrôleurs dans un boîtier de module à contrôleur unique
Suivez les consignes suivantes lors du remplacement du module de contrôleurs dans un boîtier de module à contrôleur unique :
- Si le module de contrôle est toujours opérationnel, consignez les adresses IP et les paramètres du système de stockage dans la feuille de calcul des informations système, qui se trouve dans le guide de déploiement du système de stockage Dell PowerVault série ME5 (Dell PowerVault ME5 Series Storage System Deployment Guide).
- Utilisez PowerVault Manager ou l'interface de ligne de commande (CLI) pour mettre hors tension le système de stockage.
- Retirez le module de contrôleur du boîtier du système de stockage.
- Installez le module de contrôleur de remplacement dans le boîtier du système de stockage et configurez le module de contrôleur de remplacement.
Retrait d'un module de contrôle d'un boîtier de module à contrôle unique
Procédez comme suit pour retirer un module de contrôle d'un boîtier de module à contrôle unique :
Avant de commencer toute procédure, voir la partie Précautions concernant les ESD.
- Arrêtez le système de stockage à l'aide de PowerVault Manager ou de l'interface de ligne de commande.
- Débranchez tous les câbles connectés au module de contrôle. Étiquetez chaque câble pour faciliter le raccordement au nouveau module de contrôle.
- Saisissez le loquet du module entre le pouce et l'index, et rapprochez la bride de la poignée afin de libérer le loquet, puis faites pivoter le loquet vers l'extérieur pour dégager le module de contrôleur.
- Faites pivoter la poignée du loquet pour l'ouvrir, puis saisissez-le et faites glisser doucement vers l'avant le module de contrôleur de son logement.
Figure 59. Retrait d'un module de contrôleur installé dans un boîtier
REMARQUE : Cette figure présente un module de contrôle SAS à 4 ports. Toutefois, tous les modules de contrôle utilisent le même mécanisme de verrouillage.
- Placez les deux mains sur le corps du module de contrôleur, puis sortez-le directement du boîtier en veillant à ce que le module de contrôleur reste à niveau lors de son retrait.
Installation et configuration d'un module de contrôleur de remplacement dans un boîtier de module à contrôleur unique
Procédez comme suit pour installer et configurer :
Avant de commencer toute procédure, voir la partie Précautions concernant les ESD.
REMARQUE : Pour obtenir des instructions sur l'exécution des étapes suivantes, reportez-vous au guide de déploiement du système de stockage Dell PowerVault série ME5 (Dell PowerVault ME5 Series Storage System Deployment Guide).
- Examinez que le module de contrôleur n'est pas endommagé et inspectez soigneusement le connecteur d'interface. N'installez pas le module de contrôleur si les broches sont tordues.
- Avec le loquet en position ouverte, saisissez le module de contrôleur à deux mains et alignez-le pour l'insérer dans le logement de destination.
- En vous assurant que le module de contrôleur est à niveau, faites-le glisser entièrement dans le boîtier. Un module de contrôleur qui n'est que partiellement en place nuit aux performances du boîtier du contrôleur. Vérifiez que le module de contrôleur est correctement installé avant de continuer.
- Fixez le module de contrôleur en position en fermant manuellement le loquet. Vous devez entendre un clic lorsque la poignée de verrouillage se met en place et sécurise le module de contrôleur sur son connecteur à l'arrière du fond de panier central.
- Reconnectez les cables au module de contrôleur.
PRECAUTION: Si des cables en cuivre passifs sont branchés au module de contrôle, ils ne doivent pas etre reliés a un point de mise à la terre commun.
- Mettez à jour le firmware du module de contrôleur vers la même version que celle du firmware du module de contrôleur défaillant.
- Configurez les paramètres du système et procédez à la configuration du stockage.
PRECAUTION: Si les groupes de disques passent en mode quarantaine lors de la configuration du stockage, contactez le support technique avant de passer à l'étape suivante.
- Reconfigurez les connexions aux systèmes hôtes et remappez les volumes.
- Configure les réplications entre les systèmes de stockage.
Retrait d'un module IOM
Avant de commencer toute procédure, voir la partie Précautions concernant les ESD.

REMARQUÉ : Éléments à prendre en compte pour le retrait des modules IOM :
- Les boîtiers d'extension sont équipés de deux modules IOM. Vous pouvez effectuer l'échange à chaud d'un module IOM dans un boîtier opérationnel. Si vous remplacez les deux modules IOM, et si le boîtier d'extension est en ligne, vous pouvez effectuer l'échange à chaud du module IOM dans l'emplacement A, puis celui du module IOM dans l'emplacement B, en vérifiant que chaque module est reconnu par le contrôleur.
- Ne retirez pas un module IOM défecteurs à moins que vous ne disposiez d'un module de remplacement. Tous les modules IOM doivent être en place lorsque le système est en service.
- z un voyant orange indiquant une défaillance sur le panneau OPS du boitier. Sur le panneau arrière du boitier, recherchez la Fault LED orange indiquant une défaillance du module IOM.
- Débranche les cables connectés au module IOM.
Étiquetez chaque câble pour faciliter la connexion de l'IOM de remplacement.
- Saisissez le loquet du module entre le pouce et l'index, et rapprochez la bride de la poignée afin de libérer le loquet, puis faites pivoter le loquet vers l'extérieur pour dégager le module IOM.
Figure 60. Ouverture du loquet du module
- Faites pivoter le loquet pour l'ouvrir, puis saisissez-le et éloignez doucement le module IOM de son logement.
- Placez les deux mains sur le corps du module IOM, puis tirez-le directement hors du boîtier de telle sorte que le module IOM reste droit pendant le retrait.
Installation d'un IOM
Avant de commencer toute procédure, voir la partie Précautions concernant les ESD.
- Vérifiez que le module IOM n'est pas endommagé et inspectez soigneusement le connecteur d'interface. N'installez pas le module IOM si les broches sont tordues.
- Saisissez le module IOM des deux mains, et avec le loquet en position ouverte, orientez le module IOM et alignez-le pour l'insérer dans le logement cible.
- En vous assurant que le module IOM est droit, faites-le glisser complètement dans le boîtier. Un module IOM qui n'est que partiellement en place nuit aux performances du boîtier d'extension. Vérifiez que le module IOM est correctement installé avant de continuer.
- Fixez le module IOM en position en fermant manuellement le loquet.
Vous entendrez un déclic lorsque le loquet se met en place et sécurise le module IOM sur son connecteur à l'arrière du fond de panier central.
- Reconnectez les câbles.
Remplacement d'un module de refroidissement de l'alimentation (PCM) dans un boîtier 2U
Les images des procédures de retrait et d'installation du module de refroidissement de l'alimentation présentent le panneau arrière du boîtier 2U.
Un seul PCM suffit pour maintenir le boîtier en conditions opérationnelles. Il est inutile d'interrompre les opérations et d'éteindre complètement le boîtier lors du remplacement d'un seul PCM. Cependant, un arrêt normal complet est requis en cas de remplacement simultané des deux unités.

PRECAUTION: Ne retirez pas le cache du PCM en raison du risque d'électrocution. Renvoyez le PCM à votre fournisseur pour réparation.
Avant de commencer une de ces procédures, voir les Précautions concernant les décharges électrostatiques.

REMARQUE : Les illustrations montrent le remplacement du module PCM dans le logement de croite lorsque vous VOYZE le panneau arrriere du boitier. Pour remplacer un PCM dans le logement de gauche, vous nevez d'abord faire pivoter le module de, afin qu'il s'aligne correctement avec ses connecteurs à l'arriere du fond de panier central.
Retrait d'un module de refroidissement de l'alimentation

PRECAUTION: Le retrait d'un bloc d'alimentation perturbe considérablement la circulation d'air du boitier. Ne retirez pas le PCM jusqu'à ce que vous ayez bien reçu le module de remplacement. Il est important que tous les logements soient replis lorsque le boitier est en fonctionnement.
Avant de retirer le module de refroidissement de l'alimentation, débranchez l'alimentation du module de refroidissement de l'alimentation par le commutateur principal (le cas échéant) ou en coupant physiquement la source d'alimentation afin de vous assurer que votre système dispose d'une fonction arrêt de l'alimentation imminente. Assurez-vous d'identifier correctement le module de refroidissement de l'alimentation défectueux avant de commencer la procédure.
- Arrêtez toutes les E/S depuis les hôtes jusqu'au boîtier.

REMARQUE : Cette étape n'est pas nécessaire pour le remplacement à chaud, mais elle l'est lorsque vous remplacez les deux modules de refroidissement de l'alimentation à la fois.
- Utilisez le logiciel de gestion pour arrêter tout autre composant du système nécessaire.

REMARQUE: Cette étape n'est pas nécessaire pour le remplacement à chaud, mais elle l'est lorsque vous remplacez les deux modules de refroidissement de l'alimentation à la fois.
- Mettez hors tension le module de refroidissement de l'alimentation défectueux et débranchez le câble du bloc d'alimentation.
- Si vous échangez un seul module de refroidissement de l'alimentation à chaud, passez à l'étape 6.
- Si vous remplacez les deux modules de refroidissement de l'alimentation, vérifiez que le boîtier a été arrêté à l'aide d'interfaces de gestion, et qu'il est mis hors tension.
- Assurez-vous que le câble d'alimentation est déconnecté.
- Saisissez le loquet et le côté de la poignée du module de refroidissement de l'alimentation entre le pouce et l'index, pincez-les et ouvrez la poignée pour libérer le module de refroidissement de l'alimentation et tirez-le à moitié en dehors du boîtier.
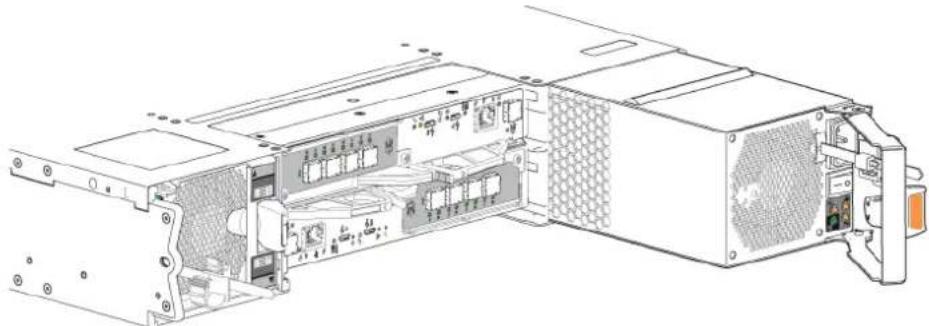
Figure 61. Retrait d'un module de refroidissement de l'alimentation
REMARQUE: Cette figure présente un boîtier de contrôle avec deux modules de contrôle SAS à 4 ports. Toutefois, cette procédure s'applique à tous les boîtiers de contrôle 2U et aux boîtiers d'extension.
- Saisissez la poignée et tirez le module de refroidissement de l'alimentation hors du boîtier, en prenant en charge la base du module à deux mains lorsque vous le retirez du boîtier.
- Si vous remplacez deux modules de refroidissement de l'alimentation, répétez les étapes 5 à 8.
Installation d'un module de refroidissement de l'alimentation
Manipulez le module de refroidissement de l'alimentation avec précaution et évitez d'endommager les broches du connecteur. N'installez pas le module de refroidissement de l'alimentation si des broches semblent tordues.
- Assurez-vous qu'il n'est pas endommagé, en particulier tous les connecteurs du module.
- Placez la poignée du module de refroidissement de l'alimentation en position ouverte.
Figure 62. Installation d'un module de refroidissement de l'alimentation
- Faites glisser le module dans le boîtier en prenant soin de prendre en charge la base et le poids du module à deux mains.
- Fermez la poignée du module de refroidissement de l'alimentation pour fixer le module PCM. Vous devez un clic après que la poignée du loquet s'enclenche et fixe le module de refroidissement de l'alimentation à son connecteur situé à l'arrière du fond de panier central.
- Connectez le câble d'alimentation sur la source d'alimentation et le module de refroidissement de l'alimentation.
- À l'aide des interfaces de gestion (PowerVault Manager ou interface de ligne de commande), vérifie que le nouveau module bloc d'alimentation est intégre. Verifie que le voyant LED OK vert du module PCM est allumé/clignote par États des LED PCM. Verifie que les ventilateurs de refroidissement tournent sans échec et que les états du panneau OPS n'indiquent aucune défaillance de module (orange).
- Si vous remplacez deux modules de refroidissement de l'alimentation, répétez les étapes 1 à 5.
Remplacement d'un bloc d'alimentation dans un boîtier 5U
Cet section fournit les instructions de retrait et d'installation d'un bloc d'alimentation dans un boîtier 5U.
Les images des procédures de retrait et d'installation du bloc d'alimentation présentent le panneau arrière du boitier 5U.
Avant de commencer toute procédure, voir la partie Précautions concernant les ESD.
Retrait d'un bloc d'alimentation
Avant de retirer le bloc d'alimentation (PSU), débranchez l'alimentation du bloc d'alimentation soit par les commutateurs principaux (le cas échéant), soit en reliant physiquement la source d'alimentation afin de confirmer que votre système dispose d'une fonction d'arrêt d'alimentation imminente. Veillez à identifier correctement le bloc d'alimentation défectueux avant de commencer la procédure.

PRECAUTION: Le retrait d'un bloc d'alimentation perturbe considérablement la circulation d'air du boitier. Ne retirez pas le bloc d'alimentation (PSU) tant que vous n'avez pas reçu le module de remplacement. Il est important que tous les logements soient occupés lorsque le boitier est en cours de fonctionnement.
- Arrêtez toutes les E/S depuis les hôtes jusqu'au boîtier.

REMARQUE : Cette étape n'est pas nécessaire pour le remplacement à chaud, mais elle l'est lorsque vous remplacez les deux blocs d'alimentation à la fois.
- Utilisez le logiciel de gestion pour arrêter tout autre composant du système nécessaire.

REMARQUE : Cette étape n'est pas nécessaire pour le remplacement a chaud, mais elle l'est lorsque vous remplacez les deux blocs d'alimentation à la fois.
- Vérifiez que levoyant LED d'alimentation correcte est allumé, puis éteignez le bloc d'alimentation défectueux et débranchez le cable du bloc d'alimentation.
- Si vous échangez un seul bloc d'alimentation à chaud, passez à l'étape 6.
- Si vous remplacez les deux blocs d'alimentation, vérifiez que le boîtier a été mis hors tension à l'aide d'interfaces de gestion, et qu'il est éteint.
- Assurez-vous que le câble d'alimentation est déconnecté.
- Abaissez le loquet de déverrouillage vers la droite et maintenez-le en place.
- De l'autre main, saisissez la poignée et sortez complètement le bloc d'alimentation.
Figure 63. Retrait d'un bloc d'alimentation
- Tout en maintenant le bloc d'alimentation des deux mains, retirez-le du boîtier.
- En cas de remplacement des deux blocs d'alimentation, répétez les étapes 5 à 9.
REMARQUE: Le logement du bloc d'alimentation ne doit pas être vide pendant plus de 2 minutes lorsque le boîtier est sous tension.
Installation d'un bloc d'alimentation
Si vous remplacez les deux blocs d'alimentation (PSU), le boîtier doit être mis hors tension via un arrêt normal à l'aide des interfaces de gestion.
- Assurez-vous que l'interrupteur d'alimentation du bloc d'alimentation (PSU) est sur la position Éteint (Off).
- Orientez le bloc d'alimentation (PSU) pour l'insérer dans le logement cible sur le panneau arrière du boîtier.
Figure 64. Installez un bloc d'alimentation
- Faites glisser le bloc d'alimentation dans le logement jusqu'à ce que le loquet s'enclenche.
- Connectez le cordon d'alimentation.
- Placez le commutateur d'alimentation du bloc d'alimentation en position Allumé (On).
- Attendez que le voyant LED d'alimentation OK du nouveau bloc d'alimentation passe au vert.
Si le voyant LED d'alimentation correcte ne s'allume pas, vérifiez que le bloc d'alimentation est correctement inséré et installé dans son logement. - Si tel est le cas, le module est peut-être défectueux. Vérifiez le PowerVault Manager et les journaux d'événements pour en savoir plus. - À l'aide des interfaces de gestion (PowerVault Manager ou interface de ligne de commande), déterminez si l'état d'intégrité du nouveau module PSU indique qu'il est opérationnel. Vérifiez que le voyant LED OK du module est vert et que les états du panneau OPS ne présentent aucune alerte orange, signe de défaillance du module.
- En cas de remplacement des deux blocs d'alimentation, répétez les étapes 1 à 6.
Remplacement d'un module de refroidissement par ventilateur (FCM) dans un boîtier 5U
Cette section fournit les instructions de retrait et d'installation d'un module de refroidissement par ventilateur (FCM) dans un boîtier 5U.
Les images des procédures de retrait et d'installation du module de refroidissement par ventilateur (FCM) présentent le panneau arrière du boîtier 5U.
Avant de commencer toute procédure, voir la partie Précautions concernant les ESD.
Installation d'un module de refroidissement par ventilateur
Vous pouvez remplacer tous les modules de refroidissement par ventilateur dans la mesure où vous les retirez et les réinsérez uniquement un à la fois. Nous vous recommendons d'arrêter l'unité avant de retirer deux ventilateurs ou plus.

PRECAUTION: Le retrait d'un module de refroidissement par ventilateur perturbe considérablement la circulation d'air du boitier. Ne retirez pas le FCM jusqu'à ce que vous ayez bien reçu le module de remplacement. Il est important que tous les logements soient replis lorsque le boitier est en fonctionnement.
- Identifiez le module de refroidissement par ventilateur (FCM) à retarder. Si le module FCM est en panne, la Fault LED de ventilation s'allume en orange.
- Abaissez le loquet de déverrouillage et maintenez-le en place.
- Avec l'autre main, saisissez la poignée et sortez complètement le module FCM.
Figure 65. Retrait d'une carte FCM
- Tout en maintenant le module FCM avec les deux mains, retirez-le du boîtier.
Installation d'un module de ventilateur
Veuillez effectuer le remplacement à chaud d'un seul module de refroidissement par ventilateur (FCM). Toutefois, si vous remplacez plusieurs modules de refroidissement par ventilateur, le boîtier doit être mis hors tension à l'aide d'un arrêt ordonné par le biais des interfaces de gestion.
- Orientez le module de refroidissement par ventilateur (FCM) pour l'insérer dans le logement cible sur le panneau arrêté du boîtier.
Figure 66. Installation d'une carte FCM
- Faites glisser le FCM dans le logement jusqu'à ce que le loquet s'enclenche.
Le boîtier devrait détecter automatiquement le nouveau module et commencer à l'utiliser.
- Attendez que le voyant LED OK du nouveau module FCM passe au vert.
Si le voyant OK du module ne s'allume pas, vérifiez que le FCM est correctement inséré et installé dans son logement.
- Si tel est le cas, le module est peut-être défectueux. Vérifiez le PowerVault Manager et les journaux d'événements pour en savoir plus.
- ez si l'état d'intégrité du nouveau module FCM indique qu'il est opérationnel. Vérifiez que le voyant LED OK du module est vert et que les états du panneau OPS ne présentent aucune alerte orange, signe de défaillance du module.
- En cas de remplacement de plusieurs modules FCM, répétez les étapes 1 à 3.
Exécution du processus d'installation des composants
Cette section présente la procédure à suivre pour s'assurer que les composants installés dans le chassis du boîtier de contrôle de remplacement fonctionnent correctement.
- Rebranche les cables de données entre les appareils, si nécessaire, pour revenir à la configuration de câblage d'origine :
- Entre les boîtiers de stockage en cascade.
- Entre le contrôleur et les périphériques ou appareils SAN.
- Entre le boîtier de contrôleur et l'hôte.
- Rebranchez les câbles d'alimentation sur les boitiers de stockage.
Vérification du bon fonctionnement du composant
- Redémarrez les appareils système en plaçant le commutateur d'alimentation situé sur le bloc d'alimentation en position Marche, selon l'ordre suivant :
a. En premier, les boîtiers d'extension. b. Ensuite, le boîtier de contrôleur. c. Enfin, l'hôte de données (s'il est hors tension pour des raisons de maintenance).
Patientez jusqu'à ce que chaque appareil effectue ses auto-tests de démarrage (POST) avant de passer à l'étape suivante.
- Si vous ne parvenez pas à connecter le système de stockage, exécutez une commande ping sur les adresses IP de gestion des deux modules de contrôleur. En cas d'échec des pings, vérifiez que les adresses IP de gestion sont définies sur les modules de contrôleur. Si les adresses IP ne sont pas définies, saisissez l'adresse IP de gestion des deux modules de contrôleur.
- Si les modules de contrôleur contiennent des ports iSCSI, exécutez une commande ping sur l'adresse IP des ports iSCSI. En cas d'échec des pings, vérifie que les adresses IP sont définies sur les ports iSCSI des modules de contrôleur. Si l'adresse IP n'est pas définie, saisissez l'adresse IP des ports iSCSI sur les deux modules de contrôleur.
- Relancez l'analyse pour forcer une nouvelle discovery de tous les boîtiers d'extension connectés au boîtier du contrôleur. Cette étape efface les informations relatives à l'organisation interne du SAS, réaffecte les ID du boîtier et s'assure que les boîtiers sont affichés dans l'ordre approprié. Utilisez l'interface de ligne de commande (CLI) ou PowerVault Manager pour relancer l'analyse :
Pour relancer l'analyse à l'aide de l'interface de ligne de commande, saisissez la commande suivante : rescan
Pour relancer l'analyse avec le PowerVault Manager :
a. Vérifiez que les deux contrôleurs fonctionnent normalement. b. Dans la rubrique Système, sélectionnez Action > Relancer l'analyse des canaux des disques. c. Sélectionnez Relancer l'analyse.
Utilisation des LED
Cette section décrit les voyants DEL qui servent à vérifier le fonctionnement d'un composant. Ces voyants sont situés sur les panneaux avant et arrière du boîtier.
- Vérifiez les voyants LED avant. Les voyants LED du panneau avant se trouvent sur le panneau OPS situé sur la bride de la anse gauche. Les voyants LED du lecteur de disque sont situés sur les modules de support.
Vérifiez que le voyant LED sous tension/en veille du système est allumé en vert, et que la Fault LED de module n'est pas allumée. - Vérifiez que la DEL de l'ID du boîtier située sur la anse gauche est allumée en vert. Vérifiez que le voyant du module de disque est vert ou qu'il clignote en vert. Il ne doit pas être orange.
- Vérifiez les voyants LED du panneau arrêté. Les voyants LED du panneau arrêté sont situés sur le module de contrôle, le module d'E/S et les plaques avant du module PCM.
Pour les modules de contrôleur et les IOM, vérifie que le voyant OK est vert, indiquant que le module a terminé l'initialisation et qu'il est actif. - Pour les PCM, vérifie que le voyant OK est vert sur chaque PCM.
Utilisation des interfaces de gestion
Outre la consultation des LED comme décrit précédemment, vous pouvez utiliser les interfaces de gestion pour surveiller l'état d'intégrité du système et de ses composants, à condition d'avoir configuré et provisionné le système, et accepté la notification d'événement.
Sélectionnez l'une des méthodes suivantes pour vérifier le fonctionnement d'un composant :
Utilisez PowerVault Manager pour vérifier l'intégrité des icônes/ Valeurs du système et de ses composants ou pour effectuer une recherche approfondie sur un composant problème. PowerVault Manager utilise les icônes d'intégrité OK, dégradé, panne, ou état inconnu pour le système et de ses composants. Si vous découvrez un composant problème, suivez les actions dans son champ de recommandation pour résoudre le problème. - Comme une alternative à l'utilisation de PowerVault Manager, vous pouvez exécuter la commande show system dans l'interface de ligne de commande (CLI) pour afficher l'intégrité du système et de ses composants. Si un composant a un problème, l'intégrité du système sera Degraded, Fault ou Unknown. Si vous découvrez un composant problème, suivez les actions dans son champ de recommandation pour résoudre le problème. Surveillance de la notification d'événement : une fois la notification d'événement configurée et activée, vous pouvez afficher les journaux des événements pour surveiller l'état d'intégrité du système et de ses composants. Si un message recommande de vérifier si un événement a été consigné, ou d'afficher les informations concernant un événement dans le journal, vous pouvez le faire à l'aide de PowerVault Manager ou de l'interface de ligne de commande (CLI). À l'aide du PowerVault. Manager, affichez le journal d'événements puis passez le pointeur de la souris sur le message d'événement pour connaître les détails concernant cet événement. À l'aide de l'interface de ligne de commande (CLI), exécutez la commande show events detail avec paramètres supplémentaires pour filtrer la sortie et voir le détail pour un événement. Pour plus d'informations sur la syntaxe et les paramètres de commande, consultez le guide de référence de l'interface de ligne de commande (CLI).
Exécution de mises à jour dans powervault manager après le remplacement d'un adaptateur HBA fibre channel ou SAS.
Après avoir remplacé un adaptateur HBA Fibre Channel ou SAS dans un hôte rattaché, exécutez les tâches suivantes :
- Dans le cas d'un adaptateur HBA Fibre Channel, mettez à jour le zonage si un commutateur est utilisé, puis mettez à jour le groupe d'initiateurs/hôtes dans PowerVault Manager.
- Dans le cas d'un adaptateur HBA SAS, mettez à jour le groupe d'initiateurs/hôtes dans PowerVault Manager.
Pour plus d'informations sur la gestion des hôtes et des groupes d'hôtes dans PowerVault Manager, reportez-vous au Dell PowerVault série ME5 Storage System Administrator's Guide (Guide de l'administrateur du système de stockage Dell EMC PowerVault série ME4).
Événements et messages d'événement
Lorsqu'un événement se produit dans un système de stockage, un message d'événement est enregistré dans le journal des événements système. Selon les paramètres de notification d'événements du système, le message d'événement peut également être envoyé aux utilisateurs (à l'aide de la messagerie) et aux applications basées sur l'hôte (à l'aide de SNMP).

REMARQUE : Il est recommandé d'activer l'envoi de notifications pour les événements représentant le niveau de gravité « Avertissement » ou supérieur.
Chaque événement dispose d'un code numérique associé qui identifie le type d'événement qui s'est produit et présente l'un des niveaux de gravité suivants :
- Critique : une panne pouvant entraîner l'arrêt d'un contrôleur s'est produite. Corrigez le problème immédiatement. Erreur : une panne pouvant affecter l'intégrité des données ou la stabilité du système s'est produite. Corrigez le problème dès que possible. Attention : un problème qui peut avoir un impact négatif sur la stabilité du système, mais pas sur l'intégrité des données, est survenu. Évaluez le problème et corrigez-le si nécessaire. Informatif : une configuration ou un changement d'état s'est produit, ou un problème a été corrigé par le système. Aucune mesure immédiate n'est requise. Dans ce document, ce niveau de gravité est désigné par l'abréviation « Info. »
- Résolu : la condition qui a provoqué la journalisation d'un événement a été résolue.
Un message d'événement peut spécifier un code d'erreur ou un code de motif associé qui fournit des informations supplémentaires sur le support technique. Les codes d'erreur et les codes de motif ne sont pas traités dans le cadre de ce guide.
- Description des événements - Événements
Description des événements
Cette section décrit les messages d'événement qui peuvent être signalés lorsque le système est en fonctionnement et indique les actions recommandées en réponse à un événement.
Selon le mode du système et la version du firmware installé, il est possible que certains événements décrits dans le présent document ne s'appliquent pas. Les descriptions d'événement doivent être considérées comme des explications sur les événements que vous voyagez et non comme des descriptions d'événements que vous devriez avoir vus mais pas détectés. Il est très probable que ces événements ne s'appliquent simplement pas à votre système.
Dans cette section :
Le terme groupe de disques fait référence à un disque virtuel pour le stockage linéaire ou à un groupe de disques virtuels pour le stockage virtuel. Le terme pool fait référence à un seul disque virtuel pour le stockage linéaire ou à un pool virtuel pour le stockage virtuel.
Tableau 28. Descriptions des événements et actions recommandées
| Nombre Gravité Descriptio | h/actions recommendées | |
| 1 Critique Ce niveau de gravité de l'événement comaporte les variantes suivantes : | ||
| 1. Le groupe de disques est en ligne et ne peut pas tolérer de panne d'un autre disque, etaucun disque de secours de taille et de type appropriés n'est disponible pour reconstruire automatiquement le groupe de disques.Si le groupe de disques indiqué est de type RAID 6, il fonctionne avec un état dégradé suite à la panne de deux disques.Si le groupe de disques indiqué n'est pas de type RAID 6, il fonctionne avec un état dégradé suite à la panne d'un disque.Pour les groupes de disques linéaires, si un disque disponible de taille et de type appropriés estprésent et que la fonctionnalité de disques de secours dynamique est activée, ce disque est utilisé pour reconstruire automatiquement le groupe de disques et l'événement 37 est signné.2. Le groupe de disques est en ligne et ne peut pas tolérer de panne d'un autre disque. Si le groupe de disques indiqué est de type RAID 6, il fonctionne avec une intégrité dégradée en cas de défaillance de deux disques. Si le groupe de disques indiqué n'est pas de type RAID 6, il fonctionne avec une intégrité dégradée en cas de défaillance d'un disque.Actions recommendées :Si l'événement 37 n'a pas été signné, cela signifie qu'aucun disque de secours de la taille et du type appropriés n'était disponible pour la reconstruction. Remplacez le disque défallant par un disque du même type et de capacité identique ou supérieure, et si nécessaire, désignez-le comme disque de secours. Confirmez cette opération en vérifier que les événements 9 et 37 sont consignés.Dans le cas contraire, la reconstruction a démarré automatiquement et l'événement 37 a été signné. Remplacez le disque défallant et configurer le disque de secours comme disque de secours dédié (linéaire uniquement) ou disque de secours global pour une utilisation ultérieure.Pour des performances d'E/S optimes en continu, le disque de remplacement doit fournir des performances identiques ou supérieures.Confirmez que tous les disques défallants ont été remplacés et qu'il existe suffisamment de disques de secours configurés pour une utilisation ultérieure. | ||
| Avertissement | Le groupe de disques est en ligne, mais il ne peut pas tolérer une autre panne de disque.Si le groupe de disques indiqué est de type RAID 6, il fonctionne avec un état dégradé suite à la panne de deux disques.Si le groupe de disques indiqué n'est pas de type RAID 6, il fonctionne avec un état dégradé suite à la panne d'un disque.Un disque de secours dédié ou global de la taille et du type appropriés est utilisé pour reconstruire automatiquement le groupe de disques. Les événements 9 et 37 sont consignés pour le signalerActions recommendées :Si l'événement 37 n'a pas été signné, cela signifie qu'aucun disque de secours de la taille et du type appropriés n'était disponible pour la reconstruction. Remplacez le disque défallant par un disque du même type et de capacité identique ou supérieure, et si nécessaire, désignez-le comme disque de secours. Confirmez cette opération en vérifier that les événements 9 et 37 sont consignés.Dans le cas contraire, la reconstruction a démarré automatiquement et l'événement 37 a été signné. Remplacez le disque défallant et configurer le disque de secours comme disque de secours dédié (linéaire uniquement) ou disque de secours global pour une utilisation ultérieure.Pour des performances d'E/5 optimes en continu, le disque de remplacement doit fournir des performances identiques ou supérieures.Confirmez que tous les disques défallants ont été remplacés et qu'il existe suffisamment de disques de secours configurés pour une utilisation ultérieure. | |
| 3 Erreur | Le groupe de disques indiqué est passé hors ligne.Un disque (RAID 0 ou NRAID), trois disques (RAID 6) ou deux disques (autres niveaux RAID) sont en panne. Le groupe de disques ne peut pas être reconstruit. Cét état n'est pas normal pour un groupe de disques, sauf si vous ave mis fin à la quarantine manuelle. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Géralde | Gravité Description | h/actions recommendées |
| Avec les groupes de disques virtuels de niveau Performances, lorsqu'un disque tombe en panne, les données du groupe de disques qui l'utilisation sont alors automatiquement migrées vers un autre groupe de disques disponible si l'espace est suffisant, si bien qu'aucune donnée utilisé ne'est perdue. Les données sont perdues uniquement si plusieurs disques tombent en panne successivement dans un court intervalle, ce qui ne laisserait pas suffisamment de temps pour migrer les données, si l'espace est insuffistant pour déplacer les données dans un autre niveau, ou si les disques défaillants ne sont pas replacésrapidement par l'utilitaire.Actions recommendées:La commande CLI trust peut permettre de récapierer certaines des données du groupe de disques. Reportez-vous à l'aide de la CLI pour en savoir plus sur la commande trust. Contactez le support technique si vous avez besoin d'aide pour déterminer si l'opération trust s'applique à votre situation et si vous pouze savoir comment l'exécuter.Si vous choisissez de ne pas utiliser la commande trust, procédéz comme suit :○Remplacez le ou les disques défaillants. (Recherche l'évenement 8 dans le journal des événements pour déterminer quels disques sont en panne et pour obtenir des conscients sur leur remplacement.)○Supprimez le groupe de disques (commande CLI remove disk-groups).○Recrérez le groupe de disques (commande CLI add disk-group).Pour évitier ce problème à l'avvenir, utilisez un niveau de RAID avec tolérance aux pannes, configurerz un ou plusieurs disques comme disques de secours, et remplacez les disques en panne rapidement. | ||
| 4 Info. | Le disque indiqué presenta un bloc défectueux qui a été corrige.Actions recommendées:Surveillance la tendance de cette erreur et déterminez si le nombre d'erreurs est proche du nombre total d' éléments disponibles pour le remplacement des blocs défectueux. | |
| 6 Avertissement Une panne | est survenue lors de l'initialisation du groupe de disques indiqué. Elle a probablelement été causée par la défaillance d'un lecteur de disque. L'initialisation s'est peut-être terminée, mais le groupe de disques présente probablement l'état FTDN (tolerance de panne avec un disque à l'arrêt), CRIT (critique) ou OFFL (hors ligne), en fonction du niveau RAID et du nombre de disques en panne. Actions recommendées:Recherche la présence d'un autre événement consigné à peu près au même moment indiquant une panne de disque, comme l'évenement 55, 58 ou 412. Suivez les actions recommendées pour cet événement. | |
| Info. Effectuez l'une des actions suivantes:La creation du groupe de disques s'est terminée avec succès.La creation du groupe de disques a échoué immidiatement. L'utilitaire reçoit un message dans la foulée lui indiquant l'éché de l'opération au moment de la tentative d'ajout du groupe de disques. Actions recommendées:Aucune action n'est requise. | ||
| Série Erreur Dans un environnement de test, le diagnostic d'un contrôleur échoué et un code de diagnostic propre au produit est rapporté.Actions recommendées:Effectuez une analyse des pannes. | ||
| 8 Avertissement L'une des conditions suivantes s'estroduite:Le disque d'un groupe de disques est en panne. Le disque concerné dans le groupe de disques indiqué est défaillant et le groupe de disques présente probablement l'état FTDN (tolerance aux pannes avec un disque à l'arrêt), CRIT (critique) ou OFFL (hors ligne), en fonction du niveau RAID et du nombre de disques en panne. S'il existe un disque de secours et si le groupe de disques n'est pas hors ligne, le contrôleur utilise automatiquement le disque de secours pour reconstruire le groupe de disques. Les événements suivants indiquent les modifications survenant au niveau du groupe de disques. Lorsque le problème est résolu, l'évenement 9 est consigné.La reconstruction d'un groupe de disques a échoué. Le disque indiqué était utilisée comme disque cible pour la reconstruction du groupe de disques indiqué. Pendant la reconstruction du groupe de | ||
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Gravité Descriptio | h/actions recommendées |
| disques, un autre disque du groupe est tombé en panne et l'état du groupe de disques est passé à OFFL (hors ligne). Le disque indiqué présente l'état LEFTOVR (restant).L'événement indique que le disque SSD d'un groupe de disques est au bout de son cycle de vie. Le disque concerné dans le groupe de disques indiqué est défailleant et le groupe de disques présente probabilité l'état FTDN (tolerance aux pannes avec un disque à l'arrêt), CRIT (critique) ou OFFL (hors ligne), en fonction du niveau RAID et du nombre de disques en panne. S'il existe un disque de secours et si le groupe de disques n'est pas hors ligne, le contrôleur utilise automatiquement le disque de secours pour reconstruire le groupe de disques. Les événements suivants indiquent les modifications survenant au niveau du groupe de disques. Lorsque le problème est résolu, l'événement 9 est consigné.Actions recommendées:Si un disque de groupe de disques est en panne :○Si le disque indiqué est en panne pour l'une de ces raisons : erreurs de support excessives, panne de disque imminente, panne matérielle possible, disque non pris en charge, trop d'erreurs pouvant être corrigées par le contrôleur, demande illégale, état degradé ou lenteur excessive, replacez le disque par un disque de même type (SSD, SAS d'entreprise ou SAS de millieu de gamme) et de capacité égale ou supérieure. Pour des performances d'E/S optimes en continu, le disque de remplacement doit fournir des performances égales ou supérieures par rapport à celui qu'il remplace.OSi le disque indiqué est tombé en panne parce qu'un utilisateur a sorti le disque de force du groupe de disques, parce que l'initialisation RAID 6 a échoué ou pour une raison inconnue :■ Si le groupe de disques associé est hors ligne ou en quarantaine, contactez le support technique.Sinon, effacez les métadonnées du disque afin de le réutiliser.OSi le disque indiqué est tombé en panne en raison de l'absence d'un disque précédemment détecté :■ Réinsérez le disque ou insérez un disque de remplacement du même type (SSD, SAS d'entreprise ou SAS millieu de gamme) et de capacité supérieure ou égale à celui qui se trouvait dans le logement. Pour des performances d'E/S optimes en continu, le disque de remplacement doit fournir des performances identiques ou supérieures à celles du disque qu'il remplace.Si le disque présente ensuite l'état LEFTOVR (restant), effacez les métadonnées afin de réutiliser le disque.Si le groupe de disques associé est hors ligne ou en quarantaine, contactez le support technique.En cas d'échec de reconstruction d'un groupe de disques :○ Si le groupe de disques associé est en ligne, effacez les métadonnées du disque indiqué afin de pouvoir le réutiliser.OSi le groupe de disques associé est hors ligne, la commande CLI trust peut permettre de recupérer une partie ou la totalité des données du groupe de disques. Toutfois, faire confiance à un disque reconstruit seulement partiellement peut entrainer la corruption des données. Reportez-vous à l'aide de la CLI pour en savoir plus sur la commande trust. Contactez le support technique si vous avez besoin d'aide pour déterminer si l'opération trust s'applique à votre situation et si vous pouze savoir comment l'exécuter.OSi le groupe de disques associé est hors ligne et si vous ne souhaitez pas utiliser la commande trust, procédéez comme suit :○Suprimez le groupe de disques (commande CLI remove disk-groups).○ Effacez les métadonnées du disque indiqué afin de pouvoir le réutiliser (commande CLI clear disk-meta data).○Remplacelez le ou les disques défaillants. (Recherche d'autres instances de l'événement 8 dans le journal des événements pour déterminer quels disques sont en panne.)○Recréez le groupe de disques (commande CLI add disk-group).○Si l'événement indique que le disque SSD d'un groupe de disques est au bout de son cycle de vie, remplacez-le par un disque du même type et de capacité égale ou supérieure. Pour des performances d'E/S optimes en continu, le disque de remplacement doit fournir des performances identiques ou supérieures à celles de celui qu'il remplace. |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Groupe | Gravité Description | /actions recommendées |
| 9 Info. | Le disque de secours | Indiqué a été utilisé dans le groupe de disques spécifique pour le ramener à un état detolerance aux pannes.La reconstruction du groupe de disques démarre automatiquement. Cet événement indique qu'un problème signalé par l'événement 8 a été résolu.Actions recommendées:•Aucune action n'est requise. |
| 16 Info. | Le disque indiqué a | été désigné comme disque de remplacement global.Actions recommendées:•Aucune action n'est requise. |
| 18 Erreur | La reconstruction | du groupe de disques s'est terminée avec des erreurs.En cas de panne de disque, la reconstruction est effectuee à l'aide d'un disque de secours. Mais cette operation a échoué. Certaines des données des autres disques du groupe sont illisibles (erreur de support non corrigible), si bien qu'une partie des données ne peut pas être reconstruite.Actions recommendées:•Si vous ne disposez pas d'une copie de sauvegarde des données, effectuez une sauvegarde.•Recherchez la présence d'un autre événement consigné à peu prise au même moment indiquant une panne de disque, comme l'événement 8, 55, 58 ou 412. Suivez les actions recommendées pour cet événement. |
| Info. La reconstruction | Construction du groupe de disques s'est terminée.Pour le groupe de disques ADAPT reconstruit partiellement, soit il n'y a plus d'espace de secours disponible, soit ce dernier ne peut pas être utilisé en raison des besoin en matière de tolération aux pannes des disques ADAPT Actions recommendées:•Aucune action n'est requise. | |
| 19 Info. | Jne nouvelle analyse | s'est terminée.Actions recommendées:•Aucune action n'est requise. |
| 20 Info. | La mise à jour de firmware | firmware du contrôleur de stockage est terminée.Actions recommendées:•Aucune action n'est requise. |
| 21 Erreur | La vérification du | groupe de disques est terminée. Des erreurs ont été détectées, mais pas corrugées.Actions recommendées:•Aucune action n'est requise. |
| Avertissement La | défiant. Si un disque社会发展 en pannes, les données peuvent être exposées à des risques.Actions recommendées:•Résolvez les problèmes matériels ne concernant pas les disques, comme les problèmes de refroidissement ou de module de contrôleur, module d'extension ou bloc d'alimentation défaillant.•Vérifiez si les disques du groupe de disques ont consigné des événements SMART ou erreurs de lecture irrécupérables.O Si c'est le cas, et si le groupe de disquesappeint à un niveau RAID sans tolération aux pannes (RAID 0 ou non RAID), copiez les données sur un autre groupe de disques et remplacez lesdisques défaillants.O Si c'est le cas, et si le groupe de disques appartient à un niveau RAID avec tolération auxpannes, vérifie l'état actuel du groupe de disques. S'il n'est pas à l'état FTOL, sauvagardezles données, car elles pourrait être exposées à des risques. S'il est à l'état FTOL, remplacez |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Descriptio | h/actions recommendées |
| le disque indiqué. Si plusieurs disques d'un même groupe ont consigné un événement SMART, sauvégardez les données et remplacez les disques un à la fois. Dans un système de stockage virtuel, il peut être possible desterolir le groupe de disques affecté, qui videra sesdonnées dans un autre groupe de disques, pour ensuite ajouter de nouveau le groupe. | ||
| Info. La vér | fication du groupe de disques a échoué immidiatement, a été abandonnée par un utilisateur ou a réussi.Actions recommendées:●Aucune action n'est requise. | |
| 23 Info. | La création du grou | upe de disques a commencé.Actions recommendées:●Aucune action n'est requise. |
| 25 Info. | Les statistiques du | groupe de disques ont été réinitialisées.Actions recommendées:●Aucune action n'est requise. |
| 28 Info. | Les paramètres du | contrôleur ont été modifiés.Cet événement est consigné lorsqu vous apportez des modifications générales à la configuration :par exemple, à la priorité des utilisaires, aux paramètres de notification à distance, aux mots de passed'interface utiliseur et aux valeurs IP des ports réseau. Cet événement n'est pas consigné lorsqu desmodifications sont apportées au groupe de disques ou à la configuration des volumes.Actions recommendées:●Aucune action n'est requise. |
| 31 Info. | Le disque indiqué n | est plus désigné comme disque de secours.Actions recommendées:●Aucune action n'est requise. |
| 32 Info. | La vérification du | groupe de disques a commencé.Actions recommendées:●Aucune action n'est requise. |
| 33 Info. | La date/heure du | contrôleur a été modifiée.Cet événement est consigné avant la modification, de sorte que l'horodatage de l'événementcorrespond à l'ancienne heures. Cet événement peut fréquement survenir si le protocole NTP estactivé.Actions recommendées:●Aucune action n'est requise. |
| 34 Info. | La configuration du | contrôleur a été restaurée aux valeurs d'usine par défaut.Actions recommendées:●Aucune action n'est requise. |
| 35 Info. | Une tâche de grou | pe de disques a été abandonnée.Actions recommendées:●Aucune action n'est requise. |
| 37 Info. | la reconstruction | du groupe de disques a démarré. Lorsqu'elle est terminée, l'événement 18 estconsigné.Actions recommendées:●Aucune action n'est requise. |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Gravité Description /actions recommendées |
| 39 Averissement Les capheurs ont relevé une température ou une tension se trouvant dans la plage d'advertissement.Lorsque le problème est résolu, l'évenement 47 est consigné pour le composant ayant consigné l'évenement 39.Si l'évenement concerne un capteur de disque, le comportement de ce dernier peut être imprévisible dans cette plage de températures.Explorez le journal des événements pour déterminer si plusieurs disques ont rapporté cet événement.Si c'est le cas, cette condition pourrait provenir d'un problème dans l'environnement.Si un seul disque signale cette condition, soit il peut s'agir d'un problème dans l'environnement, soit le disque est défaillant.Actions recommendées:Vérifie que les ventilateurs du système de stockage fonctionnel.Vérifie que la température ambiente n'est pas trop élevé. La plage de températures de fonctionnement du boîtier du contrôleur est comprise entre 5 °C et 35 °C (41 °F et 95 °F). La plage de températures de fonctionnement du boîtier d'extension est comprise entre 5 °C et 40 °C (41 °F et 104 °F).Vérifie que la présence d'obstructions à la circulation d'air.Vérifie que chaque logement du boîtier contient un module ou un cache.Si aucune de ces explications ne s'applique, remplaceze le disque ou le module de contrôleur qui a enregistré l'erreur. |
| 40 Erreur Les capteurs ont relevé une température ou une tension se trouvant dans la plage de panne. Lorsque le problème est résolu, l'évenement 47 est consigné pour le composant ayant consigné l'évenement 40.Actions recommendées:Vérifie que les ventilateurs du système de stockage fonctionnel.Vérifie que la température ambiente n'est pas trop élevé. La plage de températures de fonctionnement du boîtier du contrôleur est comprise entre 5 °C et 35 °C (41 °F et 95 °F). La plage de températures de fonctionnement du boîtier d'extension est comprise entre 5 ° C et 40 ° C (41 °F et 104 °F).Vérifie que la présence d'obstructions à la circulation d'air.Vérifie que chaque logement du boîtier contient un module ou un cache.Si aucune de ces explications ne s'applique, remplaceze le disque ou le module de contrôleur qui a enregistré l'erreur. |
| 41 Info. Le disque indiqué a été désigné comme disque de secours pour le groupe de disques indiqué.Actions recommendées:Aucune action n'est requise. |
| 43 Info. Le groupe de disques indiqué a été supprimé.Actions recommendées:Aucune action n'est requise. |
| 44 Averissement Le contrôleur comporte les données de mémoire cache du volume spécifique, mais le groupe de disques correspondant n'est pas en ligne.Actions recommendées:Déterminé pourquoi les disques du groupe ne sont pas en ligne.Si un boîtier est arrêté, déterminé l'action correcte à appliquer.Si le groupe de disques n'est plus nécessaire, vous pouvez effacer les données orphelines. Cela entraînera une perte de données.Si le groupe de disques est manquant et n'a pas été supprimé intentionnellement, reportez-vous à la section Dépannage et résolution des problèmes. |
| 47 Info. Une erreur détectée par les capteurs a été effacée. Cet événement indique qu'un problème signalé par les événements 39, 40 ou 524 a été résolu.Actions recommendées:Aucune action n'est requise. |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Groupe | Gravité Description | /actions recommendées |
| 48 Info. | Le groupe de disques indiqué a été renommé. | Actions recommendées:●Aucune action n'est requise. |
| 49 Info. | Une longue commande de maintenance SCSI s'est terminée. (En règle générale, cela se produit au cours de la mise à jour de firmware de disque.) | Actions recommendées:●Aucune action n'est requise. |
| 50 Erreur | Une erreur ECC corrigible s'est produit dans la mémoire cache plus de 10 fois pendant une période de 24 heures, indiquant une probable panne matérielle. | Actions recommendées:●Remplacez le module de contrôleur ayant consigné cet événement. |
| Avertissement U | Une erreur ECC corrigible s'est produit dans la mémoire cache.Cet événement est consigné avec une gravité de niveau Avertissement afin de fournir des informations pouvant être utilisés au support technique, mais aucune action n'est requise dans l'immédiat. Cét événement sera consigné avec une gravité de niveau Erreur si le remplacement du module de contrôleur est nécessaire.Actions recommendées:●Aucune action n'est requise. | |
| 51 Erreur | Une erreur ECC non corrigible s'est produit dans la mémoire cache plusieurs fois pendant une période de 48 heures, indiquant une probable panne matérielle. | Actions recommendées:●Remplacez le module de contrôleur ayant consigné cet événement. |
| Avertissement U | Une erreur ECC non corrigible s'est produit dans la mémoire cache.Cet événement est consigné avec une gravité de niveau Avertissement afin de fournir des informations pouvant être utilisés au support technique, mais aucune action n'est requise dans l'immédiat. Cét événement sera consigné avec une gravité de niveau Erreur si le remplacement du module de contrôleur est nécessaire.Actions recommendées:●Aucune actionn'est requise. | |
| 52 Info. | L'extension d'un groupe de disques a démarré.Cette opération peut prendre plusieurs jours ou plusieurs semaines dans certains cas. Laissez suffisamment de temps à l'extension pour qu'elle se termine.Lorsque l'opération est terminée, l'événement 53 est consigné.Actions recommendées:●Aucune action n'est requise. | Actions recommendées:●Aucune action n'est requise. |
| 53 Averissement Trop d'eurons se sont produit lors de l'extension du groupe de disques pour que cette dernière se poursuive.Actions recommendées:●En cas d'échec de l'extension en raison d'un problème de disque, remplacez ce dernier par un disque du même type (SSD, SAS d'entreprises ou SAS milieu de gamme) et de capacité égale ou supérieure. Pour des performances d'E/S optimales en continu, le disque de remplacement doit fournir des performances identiques ou supérieures à celles qu'il remplace. Si la reconstruction du groupe de disques démarre, attendez qu'elle soit terminée, puis relancez l'extension. | ||
| Info. L'extension d'un groupe de disques est terminée, a échoué immeditatement, ou a été abandonnée par un utilisateur.Actions recommendées: | ||
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Gravité Descriptio | h/actions recommendées | |
| • En cas d'éché de l'extension en raison d'un problème de disque, remplacece ce dernier par un disque du même type (SSD, SAS d'entreprise ou SAS milieu de gamme) et de capacité égale ou supérieure. Pour des performances d'E/S optimes en continu, le disque de remplacement doit fournir des performances identiques ou supérieures à celles de celui qu'il remplace. Si la reconstruction du groupe de disques démarre, attendez qu'elle soit terminée, puis relancez l'extension. | ||
| 55 Avertissement Le disque | Indiqué a signalé un événement SMART. Un événement SMART indique une panne de disque imminente. Actions recommandées: •Résolvez les problèmes matériels ne concernant pas les disques, en priorité les problèmes de refroidissement ou de bloc d'alimentation défailleant. •Si le disque se trouve dans un groupe appartenant à un niveau RAID sans tolérance aux pannes (RAID 0 ou non RAID), copiez les données sur un autre groupe de disques et remplacez le disque défailleant. •Si le disque se trouve dans un groupe appartenant à un niveau RAID avec tolérance aux pannes, vérifie l'état actuel du groupe de disques. S'il n'est pas à l'état FTOL, sauvagardez les données, car elles pouraient être exposées à des risques. S'il est à l'état FTOL, remplacez le disque indicé. Si plusieurs disques d'un même groupe ont consigné un événement SMART, sauvagardez les données et remplacez les disques un à la fois. Dans un système de stockage virtuel, il peut être possible de-retirer le groupe de disques affecté, qui videra ses données dans un autre groupe de disques, pour ensuite ajouter de nouveau le groupe. | |
| 56 Info. | Un contrôleur a été mis sous tension ou a redémarré. Actions recommandées: •Aucune action n'est requise. | |
| 58 Erreur Un lecteur de disque | Que a détesté une erreur grave comme une erreur de partiré ou une panne de disque matérielle. Actions recommandées: •Remplacez le disque défailleant par un disque du même type (SSD, SAS d'entreprise ou SAS milieu de gamme) et de capacité supérieure ou égale. Pour des performances d'E/S optimes en continu, le disque de remplacement doit fournir des performances identiques ou supérieures à celles du disque qu'il remplace. | |
| Avertissement U | Un lecteur de disque s'est réinitialisé suite à une erreur logique interne. Actions recommandées: •La première fois qu'il survient, cet événement est consigné avec une gravité de niveau Avertissement. Si le disque indiqué n'excute pas la version la plus élevée du firmware, mettez-le à jour. •Si cet événement est consignedé avec une gravité de niveau Avertissement pour le même disque plus de cinq fois en une semaine, et si le disque indiqué exécute la version la plus élevée du firmware, remplacez-le par un disque de même type (SSD, SAS d'entreprise ou SAS milieu de gamme) et de capacité égale ou supérieure. Pour des performances d'E/S optimes en continu, le disque de remplacement doit fournir des performances identiques ou supérieures à celles de celui qu'il remplace. | |
| Info. Un lec | Teur de disque a signalé un événement. Actions recommandées: •Aucune action n'est requise. | |
| 59 Avertissement Le contrôleur | Oulier a détesté un événement de partiré lors de la communication avec l'appareil SCSI spécifique. L'événement a été détesté par le contrôleur, pas par le disque. Actions recommandées: •Si l'événement indique qu'un disque ou qu'un module d'extension est défectueux, remplacez l'appareil indiqué. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Gravité Descriptio | h/actions recommendées | |
| Info. Le conr | trôleur a détecté une erreure de non-pariège lors de la communication avec l'appareil SCSI spécifique.L'erreur a été détectée par le contrôleur, pas par le disque.Actions recommendées:·Aucune action n'est requise. | |
| 61 Erreur | Le contrôleur a r | initialisé un canal de disque pour récapierer d'une erreure de communication. Cét événement est consigné pour identifier une erreur récurrente.Actions recommendées:·Si le contrôleur récapèvre, aucune action n'est requise.Consultez les autres événements consignés pour déterminer une autre action à entreprises. |
| 62 Avertissement Le disque | de secours dédié ou le disque de remplacement global indiqué est en panneActions recommendées:·Remplacez le disque par un disque du même type (SSD, SAS d'entreprises ou SAS milieu de gamme) et de capacité supérieure ou égale. Pour des performances d'E/S optimales en continu, le disque de remplacement doit fournir des performances identiques ou supérieures à celles du disque qu'il remplace.Si le disque défaillant était un disque de remplacement global, configrez le nouveau disque comme un disque de remplacement global.Si le disque défaillant était un disque de secours dédié, configrez le nouveau disque comme un disque de secours dédié pour le même groupe de disque. | |
| 65 Erreur | Une erreur ECC | non corrigible s'est produit dans la mémoire cache au démarrage.Le contrôleur est automatiquement redémarré et ses données de cache sont restaurées à partir du cache du contrôleur partenaire.Actions recommendées:·Remplacez le module de contrôleur ayant consigné cet événement. |
| 68 Info. | Le contrôleur ayant | consigné cet événement est arrêté, ou les deux contrôleurs sont arrêtés.Actions recommendées:·Aucune action n'est requise. |
| 71 Info. | Le contrôleur a dénarré ou a terminé son basculement.Actions recommendées:·Aucune action n'est requise. | |
| 72 Info. | Après le basculerm | ent, la restauration a démarré ou s'est terminée.Actions recommendées:·Aucune action n'est requise. |
| 73 Info. | Les deux contrôleurs | urs communiquent l'un avec l'autre et la redondance du cache est activée.Actions recommendées:·Aucune action n'est requise. |
| 74 Info. | L'ID de boucle FC | du groupe de disques indiqué a été modifié pour rester cohérent avec les ID des autres groupes de disques. Ce peut se conduir lorsque les disques d'un groupe sont insérés à partir d'un boîtier portant un ID de boucle FC différent.Cet événement est également consigné par le nouveau contrôleur propriétaire après la modification de la propriété du groupe de disques.Actions recommendées:·Aucune action n'est requise. |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Groupe | Gravité Descriptio | h/actions recommendées |
| 75 Info. | L'attribution du LU | N (numéro d'unité logique) du volume indiqué a été annulée, car il entre en conflit avec les LUN assignés aux autres volumes. Cela peut se produit lorsque des disques contenant les données d'un volume mappé sont déplacés d'un système de stockage vers un autreActions recommendées:Si vous souhaitez que les hôtes accèdent aux données du volume dans les disques insérés, mapperez le volume avec un LUN différent. |
| 76 Info. | Le contrôleur utilis | les paramètres de configuration par défaut. Cet événement se produit à la première mise sous tension, et peut se produit après la mise à jour de firmware.Actions recommendées:Si vous venez d'effectuer une mise à jour de firmware et si des paramètres de configuration spéciaux doivent être définis pour votre système, vous doivent effectuer ces modifications pour que le système fonctionne comme avant. |
| 77 Info. | Le cache a été initiaI | alisé suite à une opération de mise sous tension ou de basculement.Actions recommendées:Aucune action n'est requise. |
| 78 | Avertissement | Le contrôleur n'a pas pu utiliser le disque de secours attribué à un groupe de disques, car sa capacité est insuffisante.Cela se produit lorsqu'un disque du groupe tombe en panne, qu'aucun disque de secours dédié n'est disponible et que tous les disques de remplacement globaux sont trop petits. Cela peut également se produit lorsque la fonctionnalité de disques de remplacement dynamique est activée, que tous les disques de remplacement globaux et disques disponibles sont trop petits ou qu'il n'existe aucin disque de secours du type approprié. Il y a peut-être plus d'un disque en panne dans le système.Actions recommendées:Remplacez chaque disque défaillant par un disque du même type (SSD, SAS d'entreprise ou SAS milieu de gamme) et de capacité supérieure ou égale. Pour des performances d'E/S optimales en continu, le disque de remplacement doit fournir des performances identiques ou supérieures à celles du disque qu'il remplace.Configuez les disques comme des disques de secours dédiés ou comme des disques de remplacement globaux.Our un disque de secours dédié, le disque doit être du même type que les autres disques du groupe et sa capacité doit être au moins égale à celle du disque de plus petite capacité dans le groupe. En outre, il doit fournir des performances identiques ou supérieures.Our un disque de remplacement global, il vaut mieuxCHOISIR un disque dont la capacité est égale ou supérieure au disque de ce type ayant la plus grande capacité dans le système, avec des performances identiques ou plus élevées. Si le système contient une combinaison de disques de types différents (SSD, SAS d'entreprise ou SAS milieu de gamme), il doit y avoir au moins un disque de remplacement global de chaque type (à moins que des disques de secours dédiés soient utilisés pour protéger chaque groupe de disques d'un type donné). |
| 79 | Info. Une opération trust s'est terminée pour le groupe de disques indiqué.Actions recommendées:Veillez à terminer la procédure trust comme indiqué dans la section de l'aide de la CLI dédiée à la commande trust. | |
| 80 Info. | Le contrôleur a acivé ou désactivé les paramètres indiqués pour un ou plusieurs disques.Actions recommendées:Aucune action n'est requise. | |
| 81 Info. | Le contrôleur actuel a annulé l'arrêt du contrôleur partenaire. L'autre contrôleur redémarrez.Actions recommendées:Aucune action n'est requise. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Gravité Description /actions recommendées | |
| 83 Info. | L'état du contrôleur partenaire est modifié (arrêt ou redémarrage).Actions recommendées:•Aucune action n'est requise. |
| 84 Aver | issemment Le contrôleur actif ayant consigné cet événement aforcé le bascurement du contrôleur partenaire.Actions recommendées:•Téléchargez les logs de déboggage à partir de votre système de stockage et contactez le support technique. Un technicien de maintenance peut utiliser les logs de déboggage pour déterminer la cause du problème. |
| 86 Info. | Les paramètres des ports hôtes ou des canaux de disques ont été modifiés.Actions recommendées:•Aucune action n'est requise. |
| 87 Aver | issemment La configuration en miroir récapuérisée par ce contrôleur à partir du contrôleur partenaire présente un contrôle de redondance cyclique (CRC) défectueux. La configuration Flash locale sera utilisée à la place.Actions recommendées:•Restaurez la configuration par défaut à l'aide de la commande restore defaults, comme indiqué dans le Guide de référence de la CLI. |
| 88 Aver | issemment La configuration en miroir récapuérisée par ce contrôleur à partir du contrôleur partenaire est corrompue. La configuration Flash locale sera utilisée à la place.Actions recommendées:•Restaurez la configuration par défaut à l'aide de la commande restore defaults, comme indiqué dans le Guide de ↔reference de la CLI. |
| 89 Aver | issemment La configuration en miroir récapuérisée par ce contrôleur à partir du contrôleur partenaire présente un niveau de configuration trop élevé pour être traité par le firmware de ce contrôleur. La configuration Flash locale sera utilisée à la place.Actions recommendées:•Le contrôleur actif ayant consigné cet événement est probablement doté d'une version inférieure du firmware. Mettez à jour le firmware du contrôleur concerné. Les deux contrôleurs doivent être dupés de la même version de firmware.Lorsque le problème est résolu, l'événement 20 est consigné. |
| 90 Info. | Le contrôleur partenaire ne possède pas l'image de configuration en miroir du contrôleur actif. Par conséquent, la configuration Flash locale de ce dernier est utilisée.Cet événement est attendu si l'autre contrôleur est nouveau ou si sa configuration a été modifiée.Actions recommendées:•Aucune action n'est requise. |
| 91 Erreur | Dans un environnement de test, le diagnostic qui vérifie les signaux de réinitialisation matérielle entre les contrôleurs en mode actif/actif a échoué.Actions recommendées:•Effectuez une analyse des pannes. |
| 95 Erreur | Les deux contrôleurs d'une configuration actif/actif ont le même numéro de série. Les numérodes série qui ne sont pas unique peuvent entrainer des problèmes au niveau du système. Par exemple, les adresses WWN sont déterminées par le numéro de série.Actions recommendées:•Suprimez l'un des modules de contrôleur et insérez un module de rechange, puis renvoyez le module retiree pour reprogrammation. |
| 96 Info. | Les modifications de configuration en attente qui prennet effet au démarrage ont été ignorées, car des données de clients peuvent être prises dans le cache. |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| Actions recommendées: • Si les modifications de configuration demandées n'ont pas été appliquées, effectuez-les à nouveau et utilisez une commande d'interface utiliser pour arrêter le contrôleur de stockage et le redémarrer. | ||
| 103 Info. | Le nom du volume | spécifié a été modifié. Actions recommendées: •Aucune action n'est requise. |
| 104 Info. | La taille du volume | spécifié a été modifié. Actions recommendées: •Aucune action n'est requise. |
| 105 Info. | Le LUN (numéro d'unité logique) par défaut du volume spécifique a été modifié. Actions recommendées: •Aucune action n'est requise. | |
| 106 Info. | Le volume spécifique | a été ajouté au pool indiqué. Actions recommendées: •Aucune action n'est requise. |
| 107 Erreur | Une erreur grave | a été détectée par le contrôleur. Dans une configuration à un seul contrôleur, le contrôleur redémarré automatiquement. Dans une configuration actif/actif, le contrôleur partenaire force l'accès du contrôleur ayant retrtré l'erreur. Actions recommendées: •Téléchargez les logs de déboggage à partir de votre système de stockage et contactez le support technique. Un technician de maintenance peut utiliser les logs de déboggage pour déterminer la cause du problème. |
| 108 Info. | Le volume spécifique | a été supprimé du pool indiqué. Actions recommendées: •Aucune action n'est requise. |
| 109 Info. | Les statistiques du | volume spécifique ont été réinitialisées. Actions recommendées: •Aucune action n'est requise. |
| 110 Info. | La propriété du groupe de disques indiqué a été accordée à l'autre contrôleur. Actions recommendées: •Aucune action n'est requise. | |
| 111 Info. | La liaison du port de l'hôte indiqué fonctionne. Cet événement indique qu'un problème signalé par l'événement 112 a été résolu. Pour un système doté de ports FC, cet événement survient également après l'initialisation des boucles. Actions recommendées: •Aucune action n'est requise. | |
| 112 Averissement La liaison | du port de l'hôte indiqué est tombée en panne de manière inattendue. Cela peut affecter le mappage des hôtes. Actions recommendées: •Recherche l'événement 111 correspondant et soyez attentif aux transitions excessives indiquant un problème de connectivité hôte ou de commutateur. Si cet événement se produit plus de 8 fois par heures, il faut pousser les recherches. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| •Cet événement est probablement causé par un élément extérieur au système de stockage, comme un défaut de câblage ou un commutateur défectueux.•Si le problème n'est pas extérieur au système de stockage, remplacez le module de contrôleur ayant consigné cet événement. | ||
| Info. La liaison du port du l'objet indiqué est interrompue, car le contrôleur démarre.Actions recommendées:•Aucune action n'est requise. | ||
| 114 Info. | La liaison du port du canal de disque indiqué est désactivée. Notez que les événements 114 et 211 sont consignés à chaque nouvelle analyse demandée par l'utiliser et qu'ils n'indiquent pas une erreur.Actions recommendées:•Recherchez des événements correspondants de type 211 et surveillez toute transition excessive indiquant des problèmes de disque. Si plus de 8 transitions se produit par heures, reportez-vous à la section Dépannage et résolution des problèmes. | |
| 116 ErreurAprès une récupération, le contrôleur partenaire a été arrêté pendant la mise en miroir des données de la mémoire cache à écriture différée sur le contrôleur ayant consigné cet événement. Ce dernier a redémarré pour éviter de perdre les données du cache du contrôleur partenaire, mais si l'autre contrôleur ne redémarré pas correctement, les données sont perduesActions recommendées:•Pour déterminer si des données peuvent avoir été perdues, vérifie si l'événancement a été immidiatement suivi de l'événancement 56 (contrôleur de stockage démarré), suivi de près par l'événement 71 (basculment démarré). Le basculment indique que le redémarrage a échoué. | ||
| 117 Avertissement Ce module de contrôleur a déetecté ou généra leurre sur le canal hôte indiqué.Actions recommendées:•Redémarrez le contrôleur de stockage ayant consigné cet événement.•Si davantage d'erreurs sont dédictées, vérifie la connectivité entre le contrôleur et l'hôte rattaché.•Si davantage d'erreurs sont générées, arrêtez le contrôleur de stockage et replacez le module de contrôleur. | ||
| 118 Info. | Les paramètres de cache du volume spécifique ont été modifiés.Actions recommendées:•Aucune action n'est requise. | |
| 127 Avertissement Le contôleur a déetecté une connexion de disque à double port non valide. Cet événement indique qu'un port de l'hôte de contrôleur est connecté à un port d'extension, et non au port d'un hôte ou d'un commutateur.Actions recommendées:•Déconnectez le port de l'hôte du port d'extension et connectez-les aux apparciels appropriés. | ||
| 136 Avertissement En raison des erreurs dédictées sur le canal de disque indiqué, le contrôleur a marqué le canal comme dégradé.Actions recommendées:•Determine la source des erreurs sur le canal de disque indiqué et replacez le matériel défectueux. Lorsque le problème est résolu, l'événement 189 est consigné. | ||
| 139 Info. | Le contrôleur de gestion a été mis sous tension ou a redémarré.Actions recommendées:•Aucune action n'est requise. | |
| 140 Info. | Le contrôleur de gestion est sur le point de redémarrer.Actions recommendées: | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Géralde | Gravité Description | h/actions recommendées |
| •Aucune action n'est requise. | ||
| 141 Info. | Cet événement est consigné lorsqu'adresse IP utilisée pour la gestion du système est modifiée par un utilisateur ou par un serveur DHCP (si le protocole DHCP est activé). Cet événement est également consigné durant la mise sous tension ou la reprise après basculément, même lorsqu'lairdesse n'apasété modifiéeActions recommendées: •Aucune action n'est requise. | |
| 152 Aventissement Le context d'éventement Le context d'éventement Le context d'éventement Le context d'éventement L'éventement 156 est ensuite consignéActions recommendées: •Si cet événement est consigné une seule fois avec la gravité de niveau Avertissement, aucune action n'est requise. •Si cet événement est consigné plusieurs fois avec la gravité de niveau Avertissement, procédez comme suit: •Vérifiez la version du firmware du contrôleur et mettez-le à jour vers la version la plus récente le cas échéant. •Si la version la plus récente du firmware est déjà installée, le module de contrôleur ayant consigné cet événement rencontres probablement un problème matériel. Remplaceze-le. •Si vous ne pouvez pas acceder aux interfaces de gestion du contrôleur ayant consigné l'événancement, procédez comme suit: •Arrêtez le contrôleur et replacez le module. •Si vous parvenez ensuite à acceder aux interfaces de gestion, vérifiez la version du firmware du contrôleur et mettez-le à jour vers la version la plus récente le cas échéant. •Si le problème persististe, remplaceze le module. | ||
| Info. Le context d'éventement Le context d'éventement L'éventement 156 est ensuite consigné une seule fois avec la gravité de niveau Avertissement, aucune action n'est requise. Si la communication est restaurée en moins de 15 minutes, l'événement 153 est consigné. Si le problème persististe, cet événement est consigné une deuxième fois avec une gravité de niveau Avertissement. REMARQUÉ : Il est normal que cet événement soit consigné avec une gravité de niveau Informatif au cours de la mise à jour de firmware. Actions recommendées: •Vérifiez la version du firmware du contrôleur et mettez-le à jour vers la version la plus récente le cas échéant. •Si la version la plus récente du firmware est déjà installée, aucune action n'est requise. | ||
| 153 Info. | Le contrôleur de gestion a rétabli la communication avec le contrôleur de stockage. Actions recommendées: •Aucune action n'est requise. | |
| 156 Aventissement Le context d'éventement Le context d'éventement L'éventement 156 est ensuite consigné une seule fois avec la gravité de niveau Avertissement, aucune action n'est requise. | ||
| Info. Le conttext d'éventement Le conttext d'éventement L'éventement 156 est ensuite consigné une另一位 fois avec une gravité de niveau Informatif au cours de la mise à jour de firmware. Actions recommendées: •Consultez les actions recommendées pour l'événement 152, consigné à peu prise au même moment. | ||
| Info. Le conttext d'éventement Le conttext d'éventement L'éventement 156 est ensuite consigné une另一位 fois avec une gravité de niveau Informatif au cours de la mise à jour de firmware. Actions recommendées: •Aucune action n'est requise. | ||
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Gravité Descriptio | h/actions recommendées | |
| 157 Erreur | Un une panne est s' | urvenue pendant une tentative d'écriture sur la puce Flash du contrôleur de stockage. Actions recommendées: •Remplacez le module de contrôleur ayant consigné cet événement. |
| 158 Erreur | Une erreur ECC | corrigrible s'est produit dans la mémoire CPU du contrôleur de stockage plusieurs fois pendant une période de 12 heures, indiquant une probable panne matérielle. Actions recommendées: •Remplacez le module de contrôleur ayant consigné cet événement. |
| Avertissement L | Une erreur ECC corrigible s'est produit dans la mémoire CPU du contrôleur de stockage. Cet événement est consigné avec une gravité de niveau Avertissement afin de fournir des informations pouvant être utiles au support technique, mais aucune action n'est requise dans l'immediat. Cet événement sera consigné avec une gravité de niveau Erreur si le remplacement du module de contrôleur est nécessaire. Actions recommendées: •Aucune action n'est requise. | |
| 161 Info. | Un ou plusieurs bo | tiers n'ont pas de chemin valide vers un processeur de gestion de boîtier (EMP). Tous les EMP de boîtier sont désactivés. Actions recommendées: •Téléchargez les logs de déboggage à partir de votre système de stockage et contactez le support technique. Un technicien de maintenance peut utiliser les logs de déboggage pour déterminer la cause du problème. |
| 162 Avertissement Les adresses | cesses WWN hôtes (nœud et port) précédemment représentées par ce module de contrôleur sont inconnues. Dans un système à double contrôleur, cet événement a deux causes possibles : •Un ou les deux modules de contrôleur ont été replacés ou déplacés pendant que le système était hors tension. •La configuration Flash d'un ou des deux modules de contrôleur a été effacée (c'est à cet emplacement que les adresses WWN utilisées sont stockées). Le module de contrôleur récapèvre de ce problème en générant une adresse WWN basée sur son propre numéro de série. Actions recommendées: •Si le module de contrôleur a été remplaced ou si un utilisateur a reprogrammé ses données d'ID FRU, vérifie les informations WWN concernant ce module de contrôleur sur tous les hôtes qui y'accident. | |
| 163 Avertissement Les adresses | cesses WWN hôtes (nœud et port) précédemment représentées par le module de contrôleur partenaire, qui est actuellement hors ligne, sont inconnues. Cet événement a deux causes possibles : •Le module de contrôleur en ligne signalant l'événement a été remplaced ou déplacependant que le système était hors tension. •La configuration Flash du module de contrôleur en ligne (dans laquelle les adresses WWN précédemment utilisées sont stockées) a été effacée. Le module de contrôleur en ligne récapèvre de ce problème en générant une adresse WWN basée sur son propre numéro de série pour l'autre module de contrôleur. Actions recommendées: •Si le module de contrôleur a été remplaced ou si un utilisateur a reprogrammé ses données d'ID FRU, vérifie les informations WWN concernant l'autre module de contrôleur sur tous les hôtes qui y'accident. | |
| 166 Avertissement Le niveau | au RAID des métadonnées des deux contrôleurs ne correspond pas, ce qui indique que les contrôleurs sont dotés de firmwares de différents niveaux. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Gravité Descriptio | h/actions recommendées | |
| Généralément, le contrôleur doté du firmware de niveau supérieur peut dire les métadonnées écrites par un contrôleur doté d'un firmware de niveau inférieur. L'inverse n'est généralement pas possible. Par consécutif, si le contrôleur avec le firmware supérieur tombe en panne, le contrôleur avec firmware inférieur restant ne peut pas dire les métadonnées des disques défaillantsActions recommendées:Si cela se produit après une mise à jour de firmware, cela indique que le format des métadonnées a changé, ce qui est rare. Mettez à jour le firmware de niveau inférieur pour qu'il corresponde au niveau du firmware de l'autre contrôleur. | ||
| 167 Avertissement Un test | de diagnostic a déetecté une opération anormale au démarrage du contrôleur, ce qui peut nécessiter un cycle de marche/arrêt pour corriger le problème.Actions recommendées:Teléchargez les logs de déboggage à partir de votre système de stockage et contactez le support technique. Un technicien de maintenance peut utiliser les logs de déboggage pour déterminer la cause du problème. | |
| 170 Info. | La dernière réanal | se a déetecté l'ajout du boîtier spécifique au système.Actions recommendées:Aucune action n'est requise. |
| 171 Info. | La dernière réanal | se a déetecté la suppression du boîtier spécifique dans le système.Actions recommendées:Aucune action n'est requise. |
| 172 Erreur ou avertissement | Le groupe de disques indiqué a été mis en quarantaine pour l'une des raisons suivantes:Tous les disques ne sont pas accessibles. Dans le cas d'un stockage linéaire, quand le groupe de disques est en quarantaine, toute tentative d'accès à ses disques à partir d'un hôte échoue. Dans le cas d'un stockage virtuel, tous les volumes du pool sont passés de force en lecture seule. Si tous les disques redeviennent accessibles, le groupe de disques sort de quarantaine automatiquement avec l'état FTOL. Si tous les disques ne dédeviennent pas accessibles, mais qu'un nombre suffisant est disponible pour permettre la lecture à partir du groupe de disques et l'écriture sur ce dernier, alors il est sorti de quarantaine automatiquement avec l'état FTDN ou CRIT. Si un disque de secours est disponible, la reconstruction commence automatiquement. Lorsque le groupe de disques est sorti de sa quarantaine, l'événement 173 est consigné. Pour une discussion plus détaillée sur la sortie de quarantaine, reportez-vous à la documentation du SMC ou à celle de la CLI.PRECATION:Evitez d'avoir recours à la sortie de quarantaine manuelle comme méthode de récapétation lorsque l'événement 172 est consignedé, car cela rend la récapétation des données plus difficile, voire impossible.Si vous effacez les données de cache non écrites pendant qu'un groupe de disques est en quarantaine ou hors ligne, ces données sont définitivement perdues.Les données sont dans un format non pris en charge par ce système. Le contrôleur ne prend pas en charge les groupes de disques linéaires.Actions recommendées:Sisi le groupe de disques a été mis en quarantaine parce que tous ses disques ne sont pas accessibles:Si l'événement 173 a ensuite été consignedé pour le groupe de disques indiqué, aucune action n'est requise. Le groupe de disques a été à été sorti de quarantine.Dans le cas contraire, procédez comme suit :Vérifiez que tous les boîtiers sont sous tension.Vérifiez que tous les disques et modules d'E/S de chaque boîtier sont complètement insérés dans leur logement et que leurs loquets sont verrouillés.Replaces tous les disques du groupe mis en quarantaine signalés comme manquants ou défaillants dans l'interface utilisateur. (NE PAS retirer et réinsérer les disques qui ne sont pas membres du groupe de disques mis en quarantaine.) | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Groupe | Gravité Description | /actions recommendées |
| Vérifiez que les cables d'extension SAS sont connectés entre chaque boîtier du système de stockage et qu'ils sont bien en place. (NE PAS retiret et réinsérer les cables, car cela peut entrainer des problèmes avec d'autres groupes de disques.)Vérifiez qu'aucun disque n'a été retired du système involontairément.Recherchez d'autres événements indiquant des pannes dans le système et suivez les actions recommendées correspondantes. Mais, si l'événement indique qu'un disque est défaillant et si l'action recommendée est de replacer le disque, ne le replacez PAS à ce moment-là, car il pourrait être requis ultérieurement pour la récapération des données.Si le groupe de disques est toujours en quarantaine après avoir suivi les étapes requises, arrêtez les deux contrôleurs et éteignez l'ensemble du système de stockage. Remettez-le sous tension, en commençant par les boîtiers de disques (boîtiers d'extension), puis le boîtier de contrôleur.Si le groupe de disques est toujours en quarantaine après l'exécution de ces actions recommendées, contactez le support technique.Si le groupe de disques a été mis en quarantaine parce qu'il contient des données dans un format non pris en charge par ce système:Rétablissez la pleine prise en charge et la facilité de gestion du groupe de disques et des volumes mis en quarantaine en replacant vos contrôleurs par des contrôleurs prénant en charge ce type de groupe de disques.Si vous étés sur de ne pas avoir besoin des données de ce groupe de disques, supprimez-le simplement, et par la mème les volumes, à l'aide des contrôleurs actuelsment installés. | ||
| 173 Info. | Le groupe de disques indiqué a été sorti de quarantaine.Actions recommendées:•Aucune action n'est requise. | |
| 174 Info. | La mise à jour de firmware du boîtier ou du disque s'est terminée avec succès, a été abandonnée par un utilisateur ou a échoué.En cas d'échec de la mise à jour de firmware, l'utilisateur est averti du problème immédiatement et il doit y remedier dans la fouée. Par conséquent, même en cas de panne, cet événement est consigné avec une gravité de niveau Informatif.Actions recommendées:•Aucune action n'est requise. | |
| 175 Info. | L'état de la liaison Ethernet des ports réseau du contrôleur indiqué a changé (activée ou désactivée).Actions recommendées:•Si l'événement consigné indique que le port réseau est activé peu après le démarrage du contrôleur de gestion (evénement 139), aucune action n'est requise.Sinon, surveillez la recurrencie de cette erreur. Si cet événement se produit plus de 8 fois par heures, il faut pousser les recherches.Ocet événement est probablement causé par un élément extérieur au système de stockage, comme un défaut de câblage ou un commutateur Ethernet défectueux.Osiel cet événement est consigné par un seul contrôleur dans un système à double contrôleur, échangez les cables Ethernet entre les deux contrôleurs. Cela permet de déterminer si le problème vient du système de stockage ou non.Osiel le problème n'est pas extérieur au système de stockage, remplacez le module de contrôleur ayant consigné cet événement. | |
| 176 Info. | Les statistiques d'erreur concernant le disque spécifique ont été réinitialisées.Actions recommendées:•Aucune action n'est requise. | |
| 177 Info. | Les données de cache du volume manquant indiqué ont été purgées.Actions recommendées:•Aucune action n'est requise. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| 181 Info. | Un ou plusieurs par amètres de configuration associés au contrôleur de gestion ont été modifiés, comme la configuration du SNMP, SMI-S, la notification par e-mail et les chaînes système (nom du système, emplacement du système, etc.).Actions recommendées:●Aucune action n'est requise. | |
| 182 Info. | Tous les canaux de disques ont été suspendus. Les E/S ne seront pas effectuées sur les disques tant que tous les canaux ne seront pas de nouveau ouverts.Actions recommendées:●Si cet événement est lié à la mise à jour de firmware de disque, aucune action n'est requise. Lorsque la condition disparait, l'événement 183 est consigné.●Si cet événement se produit et que vous n'effectuez aucune mise à jour de firmware de disque, reportez-vous à la section Dépannage et résolution des problèmes. | |
| 183 Info. | Tous les canaux de disques ont été rouverts, ce qui signifie que les E/S peuvent reprendre. La fin de la suspension déclenchée une nouvelle analyse qui une fois terminée est consignée sous l'événement 19. Cet événement indique que la pause signalée par l'événement 182 a pris fin.Actions recommendées:●Aucune action n'est requise. | |
| 185 Info. | La commande d'écriture d'un proceseur de gestion de boîtier (EMP) s'est terminée.Actions recommendées:●Aucune action n'est requise. | |
| 186 Info. | Les paramètres du boîtier ont été modifiés par un utilisateur.Actions recommendées:●Aucune action n'est requise. | |
| 187 Info. | La mémoire cache à écriture différée a été activée.L'événement 188 est consigné lorsque la mémoire cache à écriture différée est désactivée.Actions recommendées:●Aucune action n'est requise. | |
| 188 Info. | La mémoire cache à écriture différée a été désactivée.L'événement 187 est consigné lorsque la mémoire cache à écriture différée est activée.Actions recommendées:●Aucune action n'est requise. | |
| 189 Info. | Un canal de disque précedemment dégradé ou défaillant est maintainant en bon état.Actions recommendées:●Aucune action n'est requise. | |
| 190 Info. | Le pack superconduensateur du module de contrôleur a commencé le chargement.Cette modification a rempli une condition justifiant l'activation de la fonctionnalité de double écriture automatique, ce qui a déactivé la mémoire cache à écriture différée et place le système en mode double écriture. Lorsque le problème est résolu, l'événement 191 est consigné pour indiquer le rétablissement du mode écriture différée.Actions recommendées:●Si l'événement 191 n'est consigné dans les 5 minutes après cet événement, le supercondensateur est probablement en panne et le module de contrôleur doit être remplaçé. | |
| 191 Info. | L'événement déclencheur de la double écriture automatique à l'origine de l'événement 190 a été résolu.Actions recommendées: |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| •Aucune action n'est requise. | ||
| 192 Info. | La température du | module de contrôleur a dépassé la plage de fonctionnement normale.Cette modification a repli une condition justifient l'activation de la fonctionnalité de double écriture automatique, ce qui a déactivé la mémoire cache à écriture différée et place le système en mode double écriture. Lorsque le problème est résolu, l'événancement 193 est consigné pour indiquer le rétablissement du mode écriture différée.Actions recommendées: • Si l'événement 193 n'a pas été consigned depuis la survenue duprésent événement, la surchauffe est probablement toujours présente et sa cause devrait être identifiée. Un autre événement de surchauffe a probablement été consigned à peu pres au même moment ( comme l'événancement 39, 40, 168, 307, 469, 476 ou 477). Reportez-vous aux actions recommendées correspondantes. |
| 193 Info. | L'événement déclencheur de la double écriture automatique à l'origine de l'événement 192 a été résolu.Actions recommendées: •Aucune action n'est requise. | |
| 194 Info. | Le contrôleur de stockage du module de contrôleur partenaire n'est pas activé.Cela induque qu'une condition a déclenché l'activation de la fonctionnalité de double écriture automatique, ce qui a déactivé la mémoire cache à écriture différée et place le système en mode double écriture. Lorsque le problème est résolu, l'événancement 195 est consigned pour indiquer le rétablissement du mode écriture différée.Actions recommendées: •Si l'événement 195 n'a pas été consigned depuis leprésent événement, l'autre contrôleur de stockage est probablement encore arrêté et la cause du problème doit être identifiée. D'autres événements ont probablement été consignés à peu pres au même moment. Reportez-vous aux actions recommendées correspondantes. | |
| 195 Info. | L'événement déclencheur de la double écriture automatique à l'origine de l'événement 194 a été résolu.Actions recommendées: •Aucune action n'est requise. | |
| 198 Info. | Un bloc d'alimentation est tombé en panne.Cela induque qu'une condition a déclenché l'activation de la fonctionnalité de double écriture automatique, ce qui a déactivé la mémoire cache à écriture différée et place le système en mode double écriture. Lorsque le problème est résolu, l'événancement 199 est consigned pour indiquer le rétablissement du mode écriture différée.Actions recommendées: •Si l'événement 199 n'a pas été consigned depuis leprésent événement, l'intégrité du bloc d'alimentation n'est probablement pas bonne et la cause du problème doit être identifiée. Un autre événement relatif au bloc d'alimentation a probablement été consigned à peu pres au même moment ( comme l'événancement 168). Reportez-vous aux actions recommendées correspondantes. | |
| 199 Info. | L'événement déclencheur de la double écriture automatique à l'origine de l'événement 198 a été résolu.Actions recommendées: •Aucune action n'est requise. | |
| 200 Info. | Un ventilateur est en panne.Cela induque qu'une condition a déclenché l'activation de la fonctionnalité de double écriture automatique, ce qui a déactivé la mémoire cache à écriture différée et place le système en mode double écriture. Lorsque le problème est résolu, l'événancement 201 est consigned pour indiquer le rétablissement du mode écriture différée.Actions recommendées: •Si l'événement 201 n'a pas été consigned depuis leprésent événement, l'intégrité du ventilateur n'est probablement pas bonne et la cause du problème doit être identifiée. Un autre événement relatif auvent | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| ventilateur a probablement été consigné à peuès au même moment ( comme l'événement 168). Reportez-vous aux actions recommendées correspondantes. | ||
| 201 Info. | L'événement déclencheur de la double écriture automatique à l'origine de l'événement 200 a été résolu. | Actions recommendées:●Aucune action n'est requise. |
| 202 Info. | Une condition ayant déclenché la double écriture automatique a été résolue, entraînant la réactivation de la mémoire cache à écriture différée. Le changement dans l'environnement est également consigné à peuès au même moment ( événement 191, 193, 195, 199, 201 et 241.) | Actions recommendées:●Aucune action n'est requise. |
| 203 Avec | tississement Un changement dans l'environnement a permis l'activation de la mémoire cache à écriture différée, mais la préférence de double écriture automatique n'est pas définie. Le changement dans l'environnement est également consigné à peuès au même moment ( événement 191, 193, 195, 199, 201 ou 241). | Actions recommendées:●Activez manuelle le mémoire cache à écriture différée. |
| 204 Erreur | Une erreur s'est produit au niveau de l'appareil NV lui-même ou au niveau du mécanisme de transport. | Le système peut tenter de récapierer lui-même de cette erreur. |
| La carte eMMC est utilisée pour la sauvégarde des données de cache non écrites lorsqu'un contrôleur s'arrête inopinément, par exemple en cas de coupure d'alimentation. Cet événement est général lorsque le contrôleur de stockage détecte un problème lié à la carte eMMC lors de son démarrage. | ||
| Actions recommendées:●Redémarrez le contrôleur de stockage ayant consigné cet événement.●Si cet événement est consigné à nouveau, arrêtez le contrôleur de stockage et remplacez la carte eMMC.●Si cet événement est consigné à nouveau, arrêtez le contrôleur de stockage et remplacez le module de contrôleur. | ||
| Avertissement | Le système a démarré et a détecté un problème au niveau de l'appareil NV. Le système va tenter de récapierer lui-même. | |
| La carte eMMC est utilisée pour la sauvégarde des données de cache non écrites lorsqu'un contrôleur s'arrête inopinément, par exemple en cas de coupure d'alimentation. Cet événement est général lorsque le contrôleur de stockage détecte un problème lié à la carte eMMC lors de son démarrage. | ||
| Actions recommendées :●Redémarrez le contrôleur de stockage ayant consigné cet événement.●Si cet événement est consigné à nouveau, arrêtez le contrôleur de stockage et remplacez le module de contrôleur. | ||
| Info. Le système s'est allumé normalement et l'appareil NV se trouve à l'état normal attendu. | Cet événement sera consigné avec la gravité de niveau Erreur ou Avertissement si une action est requise de la part de l'utilisateur. | |
| Actions recommendées:●Aucune action n'est requise. | ||
| 205 Info. | Le volume indiqué a été mappé ou son mappage a été annulé. | Actions recommendées:●Aucune action n'est requise. |
| 206 Info. | Le nettoyage du groupe de disques a démarré. | Le nettoyage recherche les types d'erreurs suivants dans les disques du groupe :●Les erreurs de parité des données pour un groupe de disques RAID 3, 5, 6 ou 50. |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| • Les erreurs Verify de mise en miroir pour un groupe de disques RAID 1 ou 10. • Les erreurs de support pour tous les niveaux RAID, y compris les groupes de disques RAID 0 et non RAID. Lorsque des erreurs sont dédictées, elles sont corrigées automatiquement. Lorsque le nettoyage est terminé, l'événement 207 est consigné. Actions recommendées: • Aucune action n'est requise. | ||
| 207 Erreur | Le nettoyage du | groupe de disques s'est terminé et a dédicté un nombre excessif d'erreurs dans le groupe de disques indiqué. Cet événement est consigné avec une gravité de niveau Erreur lorsque plus de 100 incohérences de partir ou de mise en miroir sont dédictées et corrigées pendant un nettoyage ou lorsque 1 à 99 incohérences de ce type sont dédictées et corrigées pendant 10 opérations de nettoyage distinctes sur le même groupe de disques. Pour les niveaux RAID sans tolérance aux pannes (RAID 0 et non RAID), les erreurs de support peuvent indiquer une perte de données. Actions recommendées: • Résolvez les problèmes matériels ne concernant pas les disques, comme les problèmes de refroidissement ou de module de contrôleur, module d'extension ou bloc d'alimentation défauillant. • Vérifiez si les disques du groupe de disques ont consigné des événements SMART ou erreurs de lecture irrécapérables. ○ Si c'est le cas, et si le groupe de disques appartient à un niveau RAID sans tolérance aux pannes (RAID 0 ou non RAID), copiez les données sur un autre groupe de disques et remplacez les disques défaillants. ○Si c'est le cas, et si le groupe de disques appartient à un niveau RAID avec tolérance aux pannes, vérifie l'état actuel du groupe de disques. S'il n'est pas à l'état FTOL, sauvagardez les données, car elles pouraient être exposées à des risques. S'il est à l'état FTOL, remplacez le disque indiqué. Si plusieurs disques d'un même groupe ont consigné un événement SMART, sauvagardez les données et remplacez les disques un à la fois. Dans un système de stockage virtuel, il peut être possible de retarder le groupe de disques affecté, qui videra ses données dans un autre groupe de disques, pour ensuite ajouter de nouveau le groupe. |
| Avertissement | Le nettoyage du groupe de disques ne s'est pas terminé en raison d'une condition détectée en interne telle qu'un disque défaillant. Si un disque tombe en panne, les données peuvent être exposées à des risques. Actions recommendées: • Résolvez les problèmes matériels ne concernant pas les disques, comme les problèmes de refroidissement ou de module de contrôleur, module d'extension ou bloc d'alimentation défauillant. ○ Si c'est le cas, et si le groupe de disques appartient à un niveau RAID sans tolérance aux pannes (RAID 0 ou non RAID), copiez les données sur un autre groupe de disques et remplacez les disques défaillants. ○Si c'est le cas, et si le groupe de disques appartient à un niveau RAID avec tolérance aux pannes, vérifie l'état actuel du groupede disques. S'il n'est pas à l'état FTOL, sauvagardez les données, car elles pouraient être exposées à des risques. S'il est à l'état FTOL, remplacez le disque indiqué. Si plusieurs disques d'un même groupe ont consigné un événement SMART, sauvagardez les données et remplacez les disques un à la fois. Dans un système de stockage virtual, il peut être possible de retarder le groupe de disques affecté, qui videra ses données dans un autre groupe de disques, pour ensuite ajouter de nouveau le groupe. | |
| Info. Le nettoyage d'un groupe de disques est terminé ou a été abandonné par un utilisateur. Cet événement est consigné avec une gravité de niveau Informatif lorsque moins de 100 incohérences de partir ou de mise en miroir sont dédictées et corrigées pendant un nettoyage. Pour les niveaux RAID sans tolérance aux pannes (RAID 0 et non RAID), les erreurs de support peuvent indiquer une perte de données. Actions recommendées: | ||
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gaïveté Description | /actions recommendées |
| •Aucune action n'est requise. | ||
| 208 Info | Le nettoyage du disque indiqué a commencé. Le résultat sera consigné sous l'événement 209. Actions recommendées : •Aucune action n'est requise. | |
| 209 Erreur | Un nettoyage de disque signé sous l'événement 208 s'est terminé et a déetecté une ou plusieurs erreurs de support, des événements SMART, ou des erreurs matérielles (hors support). Si ce disque est utilisé dans un groupe de disques sans tolérance aux pannes, des données peuvent avoir été perdues. Actions recommendées : •Remplacez le disque par un disque du même type (SSD, SAS d'entreprise ou SAS milieu de gamme) et de capacité supérieure ou égale. Pour des performances d'E/S optimales en continu, le disque de remplacement doit fournir des performances identiques ou supérieures à celles du disque qu'il remplace. | |
| Avertissement Un nettoyage de disque signé sous l'événement 208 a été abandonné par un utilisateur ou a réattribué un bloc de disque. Ces replacements de blocs défectueux sont signalés comme « autres erreurs » . Si ce disque est utilisé dans un groupe de disques sans tolérance aux pannes, des données peuvent avoir été perdues. Actions recommendées : •Surveillance la tendance de cette erreur et déterminez si le nombre d'erreurs est proche du nombre total d'éléments disponibles pour le remplacement des blocs défectueux. | ||
| Info. Un nettoyage de disque signé sous l'événement 208 s'est terminé et n'a déetecté aucune erreur, ou un disque nettoyé (sans erreur déetectée) a été ajouté à un groupe de disques, ou un utilisateur a abandonné la tâche. Actions recommendées : •Aucune action n'est requise. | ||
| 210 Info. | Dans un système de stockage virtuel, tous les snapshots ont été supprimés pour le volume parent indiqué. Actions recommendées : •Aucune action n'est requise. | |
| 211 Averissement La topologie SAS a été modifiée. Aucun élément n'est déetecté dans le mappyage SAS. Ce message indique le nombre d'éléments du mappyage SAS, le nombre de modules d'extension déetectés, le nombre de niveaux d'extension côté natif (contrôleur local) et côté partenaire (contrôleur partenaire), et le nombre de couches PHY d'appareils. Actions recommendées : •Effectuez une nouvelle analyse pour réalimer le mappyage SAS. •Si une nouvelle analyse ne résout pas le problème, arrêtez et redémarrez les deux contrôleurs de stockage. •Si le problème persiste, reportez-vous à la section Dépannage et résolution des problèmes. | ||
| Info. La topologie SAS a été modifiée. Le nombre de modules d'extension SAS a augmenté ou diminué. Le message indique le nombre d'éléments du mappyage SAS, le nombre de modules d'extension déetectés, le nombre de niveaux d'extension côté natif (contrôleur local) et côté partenaire (contrôleur partenaire), et le nombre de couches PHY d'appareils. Actions recommendées : •Aucune action n'est requise. | ||
| 214 Info. | La création de snapshots est terminée et le nombre de snapshots créé est indiqué. Des événements supplémentaires fournissant plus d'informations pour chaque snapshot. Actions recommendées : •Aucune action n'est requise. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| 216 Info. | Un snapshot non | validé a été supprimé. La suppression du snapshot spécifique s'est terminée avec succèsActions recommendées:●Aucune action n'est requise. |
| 217 Erreur | Une panne est survenue au niveau du supercondensateur dans le contrôleur.Actions recommendées:●Remplacez le module de contrôleur ayant consigné cet événement. | Actions recommendées:●Remplacez le module de contrôleur ayant consigné cet événement. |
| 218 Avertissemment Le pack | supercondensateur est en fin de vie.Actions recommendées:●Remplacez le module de contrôleur ayant consigné cet événement. | Actions recommendées:●Remplacez le module de contrôleur ayant consigné cet événement. |
| 219 Info. | La priorité des utilisaires a été modifiée par un utiliseur.Actions recommendées:●Aucune action n'est requise. | Actions recommendées:●Aucune action n'est requise. |
| 220 Info. | Un utiliseur a démarré la restauration des données du volume indiqué dans le snapshot spécifique.Actions recommendées:●Aucune action n'est requise. | Actions recommendées:●Aucune action n'est requise. |
| 221 Info. | La réinitialisation des snapshots est terminée.Actions recommendées:●Aucune action n'est requise. | Actions recommendées:●Aucune action n'est requise. |
| 224 Info. | La restauration des données du volume indiqué dans le snapshot spécifique est terminée.Actions recommendées:●Aucune action n'est requise. | Actions recommendées:●Aucune action n'est requise. |
| 232 Avertissemment Le nombre | pre maximal de boîtiers autorisés pour la configuration actuelle a été dépasse.La plate-forme ne prend pas en charge le nombre de boîtiers configurés. Le boîtier indiqué par cet événement a été retire de la configuration.Actions recommendées:●Reconfigurez le système. | Actions commendées:●Reconfigurez le système. |
| 233 Avertissemment Le type | du disque indiqué n'est pas valide et n'est pas autorisé dans la configuration actuelle.Tous les disques de type interdit ont été reliés de la configuration.Actions recommendées:●Remplacez les disques non autorisés par des disques pris en charge. | Actions commendées:●Remplacez les disques non autorisés par des disques pris en charge. |
| 235 Erreur | Un processeur de gestion de boîtier (EMP) a détecté une erreur grave.Actions recommendées:●Remplacez le module de contrôleur ou le module d'extension indiqué. | Actions recommendées:●Remplacez le module de contrôleur ou le module d'extension indiqué. |
| Info. Un processur de gestion de boîtier (EMP) a signalé un événement.Actions recommendées:●Aucune action n'est requise. | Actions recommendées:●Aucune action n'est requise. | |
| 236 Erreur | Un arrêt spécial | a démarré. Ces types d'arrêts spéciaux indiquent la présence d'une fonctionnalité incompatible.Actions recommendées:●Remplacez le module de contrôleur indiqué par un module prénant en charge la fonctionnalité spécifiée. |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Gravité Descriptio | h/actions recommendées | |
| Info. Un arrêtspéspecial a démarré. Ces types d'arrêts spéciaux sont utilisés dans le cadre de la mise à jour de firmwareActions recommendées:·Aucune action n'est requise. | ||
| 237 Erreur | Un tentative de mise à jour de firmware a été abandonnée en raison d'un ou de plusieurs problèmesd'intégrité générale du système, ou parce que des données de cache non inscrbutibles auraient éteperdues pendant cette mise à jour.Actions recommendées:·Résolvé ce problème avant d'effectuer une nouvelle tentative de mise à jour de firmware. Pourles problèmes d'intégrité, exçuéz la commande CLI show system pour identifier les problèmesd'intégrité en question. Pour les données de cache non écrites, utilisez la commande CLI showunwritable-cache | |
| Une mese à jour de firmware a démarré et est toujours en cours. Cet événement fournit des détails surles étapes de mise à jour de firmware qui pourrait vous interresser en cas de problème avec cette miseà jour.Actions recommendées:·Aucune action n'est requise. | ||
| 238 | AvertissementUne tentative d'installation d'une fonctionnalité sous licence a échoué en raison d'une licence non valide.Actions recommendées:·Vérifie ce que la licence autorise pour la plate-forme, apportez les corrections nécessaires etréinstalléz la fonctionnalité. | |
| 239 Avertissement | Un déla d'expiration est survenu pendant le vidage de la mémoire eMMC.Actions recommendées:·Redémarrez le contrôleur de stockage ayant signé cet événement.Si cet événement est signé à nouveau, arrêtez le contrôleur de stockage et remplacez lacarte eMMC. | |
| 240 Avertissement | Une panne est survenue pendant le vidage de la mémoire eMMC.Actions recommendées:·Redémarrez le contrôleur de stockage ayant signé cet événement.Si cet événement est signé à nouveau, arrêtez le contrôleur de stockage et remplacez lacarte eMMC.Si cet événement est signé à nouveau, arrêtez le contrôleur de stockage et remplacez le modulede contrôleur. | |
| 241 Info. | L'événement déclarancheur de la double écriture automatique à l'origine de l'événement 242 a été résolu.Actions recommendées:·Aucune action n'est requise. | |
| 242 Erreur | La carte eMMCdu module de contrôleur est tombé en panne.Cette modification a rempli une condition justifiant l'activation de la fonctionnalité de double écritureautomatique, ce qui a désactisé la mémoire cache à écriture différée et place le système en modedouble écriture. Lorsque le problème est résolu, l'événement 241 est signé pour indiquer Iretablissement du mode écriture différée.Actions recommendées:·Si l'événement 241 n'a pas été signé depuis le présence événement, l'intégrité de la carte eMMCn'est probablement pas bien et la cause du problème doit être identifiée. Un autre événementrelatif à la carte eMMC a probablement été signé à peu pris au même moment (comme les événements 239, 240 ou 481). Reportez-vous aux actions recommendées correspondantes. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| 243 Info | Un nouveau boîtier | de contrôleur a été détecté. Cela se produit lorsqu'un module de contrôleur est déplace d'un boîtier à un autre et que le contrôleur détecte que l'adresse WWN du fond de panier central est différente de celle de son Flash local. |
| Actions recommendées: | ||
| •Aucune action n'est requise. | ||
| 245 Info | Un apparilé cible | de canal de disque existant ne répond pas aux commandes de découverte SCSI. |
| Actions recommendées: | ||
| • Recherche la présence de matériel ou de cables défectueux au niveau de l' apparilé cible, puis lancez une nouvelle analyse. | ||
| 246 Aventisment La pile | tissement | donton est absente, n'est pas installée correctement, ou est en fin de vie. |
| La pile fournit une alimentation de secours pour l'horloge temps réel (date/heure). En cas de coupure d'alimentation, la date et l'heure reviennent à la valeur 1980-01-01 00:00:00. | ||
| Actions recommendées: | ||
| • Remplacez le module de contrôleur ayant consigné cet événement. | ||
| 247 Aventisment La mémoire | tissement La mémoire | oire SEEPROM ID FRU de l'unité replacable sur site ne peut pas être lue. Les données ID FRU peuvent ne pas avoir été programmesés. |
| Les données ID FRU incluent l'adresse WWN, les numérores de série, les versions de firmware et de matériel, les informations de marque, etc. Cet événement est consignedé chaque fois qu'un contrôleur de stockage est démarré pour chaque unité replacable sur site qui n'est pas programmée. | ||
| Actions recommendées: | ||
| • Renvoyez l'unité replacable sur site pour faire reprogrammer ses données ID FRU. | ||
| 248 Info | Une licence de fonctionnalité | actionnalité valide a été installée avec succès. Reportez-vous à l'événancement 249 pour plus de détails sur chaque fonctionnalité sous licence. |
| Actions recommendées: | ||
| • Aucune action n'est requise. | ||
| 249 Info | Après l'installation | d'une licence valide, cet événement est consignedé pour chaque fonctionnalité sous licence pour afficher la nouvelle valeur de licence correspondante. L'événement indique si la fonctionnalité est sous licence, si la licence est temporaire et si la licence temporaire est arrivée à expiration. |
| Actions recommendées: | ||
| • Aucune action n'est requise. | ||
| 250 Aventisment Une licence | tissement | n'a pas pu être installée. |
| La licence n'est pas valide ou concerne une fonctionnalité qui n'est pas prise en charge sur votre produit. | ||
| Actions recommendées: | ||
| • Passez en revue le fichier lissez-moi fourni avec la licence. Vérifie que vous essayez d'instructor la licence dans le système pour lequel elle a été généraee. | ||
| 251 Info. | Une copie de volumecame a démarré pour le volume source indiqué. | Ne montez aucun volume avant la fin de la copie ( comme indiqué par l'événancement 268). |
| Actions recommendées: | ||
| • Aucune action n'est requise. | ||
| 253 Info | Une licence a été | déinstallée. |
| Actions recommendées: | ||
| • Aucune action n'est requise. | ||
| 255 Info | Les cartes de circuitssimprimaés des contrôleurs ne correspondant pas : la PCB du contrôleur A et celle du contrôleur B proviennent de fournisseurs différents. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Groupe/Gruppe | Gravité Descriptio | h/actions recommendées |
| Cela risque de limiter les configurations disponibles.Actions recommendées:•Aucune action n'est requise. | ||
| 257 Info | Le snapshot indiqué | jué a été préparé et validé et il est prêt à être utilisé.Actions recommendées:•Aucune action n'est requise. |
| 259 Info | Les commandes CAPI intrabandes ont été désactivées.Actions recommendées:•Aucune action n'est requise. | CAPI intrabandes ont été désactivées.Actions recommendées:•Aucune action n'est requise. |
| 260 Info | Les commandes CAPI intrabandes ont été activées.Actions recommendées:•Aucune action n'est requise. | CAPI intrabandes ont été activées.Actions recommendées:•Aucune action n'est requise. |
| 261 Info | Les commandes SES intrabandes ont été désactivées.Actions recommendées:•Aucune action n'est requise. | SES intrabandes ont été activées.Actions recommendées:•Aucune action n'est requise. |
| 262 Info | Les commandes SES intrabandes ont été activées.Actions recommendées:•Aucune action n'est requise. | SES intrabandes ont été activées.Actions recommendées:•Aucune action n'est requise. |
| 263 Aventisment Le disque | de secours indiqué est manquant. Soit il a été retire, soit il ne répond pas.Actions recommendées:•Remplacez le disque par un disque de même type (SSD, SAS d'entreprise ou SAS millieu de gamme) et de capacité égale ou supérieure.•Configurez le disque comme un disque de secours. | Actions recommendées:•Remplacez le disque par un disque de même type (SSD, SAS d'entreprise ou SAS millieu de gamme) et de capacité égale ou supérieure.•Configurez le disque comme un disque de secours. |
| 266 Info | La copie d'un volumecom maître a été abandonnée par un utilisateur.Actions recommendées:•Aucune action n'est requise. | me maître a été abandonnée par un utilisateur.Actions recommendées:•Aucune action n'est requise. |
| 267 Erreur La copie d'un volumecom échoué.Cet événement a deux varianthes:1. Si le volume source est un volume maître, vous pouvez le remonter. Si le volume source est un snapshot, ne le remontez pas avant la fin de la copie ( comme indiqué par l'événement 268).2. Causes possibles: l'espace disponible sur le pool devient insuffistant et est sur le point de dépasser le seul supérieur, les volumes ne sont pas disponibles ou il existe des erreurs d'E/S générales ACTIONS recommendées:•Pour la variante 1: aucune action n'est requise.•Pour la variante 2: recherchez d'autres événements consignés à peu près au même moment, indiquant un espace de pool insuffistant ou une panne de volume. Suivez les actions recommendées correspondantes. | Volume a échoué.Cet événement a deux varianthes:1. Si le volume source est un volume maître, vous pouvez le remonter. Si le volume source est un snapshot, ne le remontez pas avant la fin de la copie ( comme indiqué par l'événement 268).2. Causes possibles: l'espace disponible sur le pool devient insuffistant et est sur le point de dépasserle seul supérieur, les volumes ne sont pas disponibles ou il existe des erreurs d'E/S générales ACTIONS recommendées:•Pour la variante 1: aucune action n'est requise.•Pour la variante 2: recherchez d'autres événements consignés à peu près au même moment, indiquant un espace de pool insuffistant ou une panne de volume. Suivez les actions recommendées correspondantes. | |
| 268 Info | La copie du volumecom indiqué s'est terminée.Actions recommendées:•Aucune action n'est requise. | me mise à jour de firmware partenaire n'a pas pu être effectué.Cet événement a cinq varianthes: |
| 269 Erreur Une opération de | ||
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| 1. L'intégrité du système est insuffisante pour prendre en charge la mise à jour du firmware du partenaire.2. Le système contient des données de cache qui ne sont pas inscrétibles.3. Il est impossible de déterminer si des données de cache non inscrétibles sont prsentes.4. Les modules de contrôleur contiennent des versions de firmware non compatibles.5. Un firmware non compatible est lié dans le systèmeActions recommendées:Pour les variantes 1, 2 ou 3 : vous devez corriger ce problème pour poursuivre la mise à jour de firmware. Connectez-vous au système et exécutez la commande show system pour identifier les composants défectueux et trouver des recommendations pour restaurer l'intégrité du système. Vous pouvez utiliser la commande check firmware-upgrade-health pour vérifier que le système est prét pour la mise à niveau de firmware. Pour les données de cache non écrites, utilisez la commande CLI show unWRITABLE-CACHE.Pour la variante 4 : il est possible de réactiver manuellement cette fonctionnalité une fois que les modules de contrôleur exécutent des firmwares compatibles.Pour la variante 5 : les modules de contrôleur doivent être mis à jour vers la version la plus récentedu firmware. | ||
| Info. La mise à jour de firmware partenaire a démarré. Cette opération permet de copier le firmware d'un contrôleur sur un autre pour en faire correspondre les versions.Actions recommendées:Aucune action n'est requise. | ||
| 270 Avertissement Soit la lecture ou l'écriture des données IP persistantes de la mémoire SEEPROM ID FRU a rencontrié un problème, soit des données non valides ont été lues à partir de la mémoire SEEPROM ID FRU ACTIONS recommendées:Vérifiez les paramètres IP (y compris les paramètres IP du port hôte iSCSI pour un système iSCSI), et mettez-les à jour s'il sont incorect. | ||
| 271 Info. | Le système de stockage n'a pas pu obtenir de numéro de série valide à partir de la mémoire SEEPROM ID FRU du contrôleur : soit parce qu'il n'a pas pu dire les données ID FRU, soit parce que les données ne sont pas valides ou n'ont pas été programmées. Par conséquent, l'adresse MAC est obtenu à partir du numéro de série du contrôleur dans la mémoire Flash. Cet événement est consigné une seule fois au démarrage.Actions recommendées:Aucune action n'est requise. | |
| 273 Info. | La localisation des pannes PHY a été activée ou déactivée par un utilisateur pour le boîtier et le module de contrôleur spécifique.Actions recommendées:Aucune action n'est requise. | |
| 274 Avertissement La couche de PHY indiquée a été déactivée, automatiquement ou par un utilisateur. Les couches PHY de disque sont automatiquement déactivées pour les logements de disque vides ou en cas de problème. Les raisons suivantes indiquent probablement une panne matérielle:Désactivée en raison d'une interruption du comptage des erreursDéactivée à la suite d'un nombre excessif de modifications au niveau de la couche PHYLa couche PHY est prête, mais n'a pas passé le test COMINITActions recommendées:Si aucune des raisons ci-dessus ne s'available, aucune action n'est requise.Si l'une des raisons ci-dessus est indiquée et que l'évenancement se produit peu de temps après la mise sous tension du système de stockage, effectuez les opérations suivantes:○ Arrêté les contrôleurs de stockage. Ensuite, éteignez l'alimentation du boîtier spécifique, attendez quelques secondes, et remettez-le sous tension. | ||
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Gévaïtés | Gravité Description | /actions recommendées |
| ○Si le problème se reproduit et si le message de l'événement identifie un logement de disque, remplacez le disque de ce logement.○Si le problème se reproduit et si le message de l'événement identifie un module, procédéez comme suit :■ Si la couche PHY indiquée est de type Sortie, remplacez le cable du port de sortie du module■ Si la couche PHY indiquée est de type Entrée, remplacez le cable du port d'entrée du module■ Pour les autres types PHY indiqués ou si le remplacement du cable ne résout pas le problème, remplacez le module indiqué.○Si le problème persiste, recherche d'autres événements pouvant indiquer un défaut matériel, comme un événement indiquant une surchauffe ou une panne du bloc d'alimentation, et suivez les actions recommandées correspondantes.○Si le problème persiste, la panne peut provenir du fond de panier central du boîtier. Remplacez l'unité FRU du châssis.Si l'une des raisons ci-dessus est indiquée et que cet événement est consigné peu de temps après un basculment, une reliance d'analyse initiaee par l'utilitaire ou un redémarrage, effectuez les opérations suivantes :○Si le message de l'événement identifie un logement de disque, replacez le disque dans ce logement.Osi le problème persiste après avoir remis le disque en place, remplacez-le.Osi le message de l'événement identifie un module, procédéez comme suit :■ Si la couche PHY indiquée est de type Sortie, remplacez le cable du port de sortie du module.■ Si la couche PHY indiquée est de type Entrée, remplacez le cable du port d'entrée du module.Pour les autres types PHY indiqués ou si le remplacement du cable ne résout pas le problème, remplacez le module indiqué.Osi le problème persiste, recherche d'autres événements pouvant indiquer un défaut matériel, comme un événement indiquant une surchauffe ou une panne du bloc d'alimentation, et suivez les actions recommandées correspondantes.Osi le problème persiste, la panne peut provenir du fond de panier central du boîtier. Remplacez l'unité FRU du châssis. | ||
| 275 | Info. La couche PHI indiquée a été activéeActions recommendées :Aucune action n'est requise. | |
| 298 Aventissement Le paramètre mètre de l'horloge temps réel (RTC) du contrôleur n'est pas valide.Cet événement se produit le plus fréquement après une coupure de courant si la pile de l'horloge temps réel est défectueuse. L'heure a peut-être été définie 5 minutes avant la coupure d'alimentation, ou elle a été réinitialisée sur la valeur 1980-01-01 00:00:00.Actions recommendées :Vérifie la date et l'heure du système. Si l'une ou l'autre est incorrecte, redéfinissez-les à la valeur correcte.Recherchez également l'événement 246 et suivez l'action recommandée correspondante.Lorsque le problème est résolu, l'événement 299 est consigné. | ||
| 299 Info.Le paramètre RTC (horloge temps réel) du contrôleur a été restauré avec succès.Cet événement se produit le plus fréquement après une coupure d'alimentation inopinée.Actions recommendées :Aucune action n'est requise, mais si l'événement 246 est également consigné, effectuez l'action recommandée correspondante. | ||
| 300 Info.La fréquence du processeur est passée à high.Actions recommendées :Aucune action n'est requise. | ||
| 301 Info.La fréquence du processeur est passée à low. | ||
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Avaité Description | /actions recommendées |
| Actions recommendées:●Aucune action n'est requise. | ||
| 302 Info | La fréquence d'horloge de la mémoire DDR est passée à high. | Actions recommendées:●Aucune action n'est requise. |
| 303 Info | La fréquence d'horloge de la mémoire DDR est passée à low. | Actions recommendées:●Aucune action n'est requise. |
| 304 Info | Le contrôleur a détesté des erreurs I | 2C qui peuvent avoir été entièrement récapacités. |
| Actions recommendées:●Aucune action n'est requise. | ||
| 305 Info | Un numéro de série | de la mémoire Flash du contrôleur de stockage n'est pas valide comparé à celui de la mémoire SEEPROM ID FRU du module de contrôleur ou du fond de panier central. Le numéro de série valide a été récapérique automatiquement. |
| Actions recommendées:●Aucune action n'est requise. | ||
| 306 Info | Le numéro de série | du module de contrôleur dans la mémoire Flash du contrôleur de stockage n'est pas valide comparé à celui present dans la mémoire SEEPROM ID FRU du module de contrôleur. Le numéro de série valide a été récapérique automatiquement. |
| Actions recommendées:●Aucune action n'est requise. | ||
| 307 Critique | Le capteur de température d'une unité FRU de contrôleur a détesté une surchauffe qui a provoqué l'arrêt du contrôleur. | l'arrêt du contrôleur. |
| Actions recommendées:●Vérifie que les ventilateurs du système de stockage fonctionnent.●Vérifie que la température ambiente n'est pas trop élevé. La plage de Températures de fonctionnement du boîtier du contrôleur est comprise entre 5 °C et 35 °C (41 °F et 95 °F). La plage de Températures de fonctionnement du boîtier d'extension est comprise entre 5 °C et 40 °C (41 °F et 104 °F).●Vérifie la présence d'obstructions à la circulation d'air.●Vérifie que chaque logement du boîtier contient un module ou un cache. | ||
| Si le problème persististe, remplacez le module de contrôleur qui a enregistré l'erreur. | ||
| 309 Info | Généralément, lors que le contrôleur de gestion (MC) est démarré, les paramètres IP sont obtenu à partir de la mémoire SEEPROM ID FRU du fond de panier central dans laquelle ilis persistent. Si le système ne parvient pas à les écrire dans la mémoire SEEPROM lors de leur dernieres modifications, une balise est définie dans la mémoire Flash. Cette balise est vérifiée lors du démarriage et, si elle est définie, cet événement est consigné et les données IP containe dans la mémoire SEEPROM sont utilisées par le module de contrôleur. Les paramètres IP du contrôleur de gestion (MC) peuvent être incorrects après l'échange d'un module de contrôleur ou le remplacement du châssis du boîtier de stockage.●Si un module de contrôleur est échangé, les paramètres IP de la mémoire Flash du module de contrôleur de remplacement peuvent être utilisés.●Si le châssis du boîtier de stockage est remplace, les paramètres IP sont perdus et doivent être saisis à nouveau sur les deux modules de contrôleur. | Actions recommendées:●Aucune action n'est requise. |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Groupe | Gravité Description | /actions recommendées | |
| 310 Info. | Après une nouvelle analyse, la découverte back-end et l'initialisation des données d'au moins un processeur de gestion de boîtier (EMP) se sont terminées. Cet événement n'est pas consigné à nouveau lorsqu'le traitement se terminé pour les autres EMP du systèmeActions recommendées:●Aucune action n'est requise. | ●Aucune action n'est requise. | |
| 311 Info. | Cet événement est consigné lorsqu'un utilisateur lance le ping d'un hôte à l'aide de l'interface ISCSI.Actions recommendées:●Si l'opération ping a échoué, vérifie la connectivité entre le système de stockage et l'hôte distant. | ●Si l'opération ping a échoué, vérifie la connectivité entre le système de stockage et l'hôte distant. | |
| 313 Erreur | Le module de contrôleur indiqué est en panne. Cet événement peut être ignorer pour une configuration à un seul contrôleur.Actions recommendées:●S'il s'agit d'un système à double contrôleur, remplacez le module de contrôleur défectueux. Levoyant LED Fault/Service Required (Panne/Maintenance requise) est allumé (ne clignote pas). | ●S'il s'agit d'un système à double contrôleur, remplacez le module de contrôleur défectueux. Levoyant LED Fault/Service Required (Panne/Maintenance requise) est allumé (ne clignote pas). | |
| 314 Erreur | L'unité FRU induçue est en panne ou ne fonctionne pas correctement. Cet événement fait suite à un autre concernant l'unité FRU signalant un problème.Actions recommendées:●Pour déterminer si l'unité FRU doit être replacée, reportez-vous à la rubrique sur la vérification des échecs de composant dans le guide d'installation et de maintenance matérielles de votre produit. | ●Pour déterminer si l'unité FRU doit être replacée, reportez-vous à la rubrique sur la vérification des échecs de composant dans le guide d'installation et de maintenance matérielles de votre produit. | |
| 315 Critique | Que Ce module d'E/S est incompatible avec le boîtier dans lequel il est inséré.Actions recommendées:●Remplaceze ce module d'E/S par un module d'E/S compatible avec ce boîtier. | ●Remplaceze ce module d'E/S par un module d'E/S compatible avec ce boîtier. | |
| 317 Erreur | Une erreur grave a été détectée sur l'interface de disque du contrôleur de stockage. Le contrôleur sera arrêté de force par son parteiraire.Actions recommendées:●Suivez visuellément le câblage entre les modules de contrôleur et les modules d'extension.●Si le câblage est correct, remplacez le module de contrôleur ayant consigné cet événement.●Si le problème persististe, remplacez le module d'extension connecté au module de contrôleur. | ●Suivez visuellément le câblage entre les modules de contrôleur et les modules d'extension.●Si le câblage est correct, remplacez le module de contrôleur ayant consigné cet événement.●Si le problème persististe, remplacez le module d'extension connecté au module de contrôleur. | |
| 319 Avertissement | Le disque ne soit disponible indiqué est en panne.Actions recommendées:●Remplacez le disque par un disque du même type (SSD, SAS d'entreprise ou SAS milieu de gamme) et de capacité supérieure ou égale. Pour des performances d'E/S optimales en continu, le disque de replACEMENT doit fournir des performances identiques ou supérieures à celles du disque qu'il remplace. | ●Remplacez le disque par un disque du même type (SSD, SAS d'entreprise ou SAS milieu de gamme) et de capacité supérieure ou égale. Pour des performances d'E/S optimales en continu, le disque de replACEMENT doit fournir des performances identiques ou supérieures à celles du disque qu'il remplace. | |
| 322 | Avertissement | Le contrôleur dispose d'une version du contrôleur de stockage plus ancienne que la version utilisée pourisser la base de données d'authentication CHAP dans la mémoire Flash du contrôleur.La base de données CHAP ne peut pas être mise à jour. Cependant, de nouveaux enregistements peuvent être ajoutés, ce qui remplace la base de données existante par une nouvelle utilisant le dernier numéro de version connu.Actions recommendées:●Mettez à niveau le firmware du contrôleur vers une version dont le contrôleur de stockage est compatible avec la version de base de données indiquée.O Si aucun enregistrement n'a été ajouté, la base de données devient accessible et reste intacte.O Si des enregistements ont été ajoutés, la base de données devient accessible, mais elle contient uniquement les nouveaux enregistements. | ●Mettez à niveau le firmware du contrôleur vers une version dont le contrôleur de stockage est compatible avec la version de données indiquée.O Si aucin enregistrement n'a été ajouté, la base de données devient accessible et reste intacte.O Si des enregistements ont été ajoutés, la base de données devient accessible, mais elle contient uniquement les nouveaux enregistements. |
| 352 Info. | Les données d'assertion ou les données de vidage de pile du contrôleur du module d'extension sont disponibles. |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| Actions recommendées:●Aucune action n'est requise. | ||
| 353 Info | Les données d'assertion et les données de vidage de pile du contrôleur du module d'extension ont été effacées.Actions recommendées:●Aucune action n'est requise. | |
| 354 Avertissement La topologia SAS a changé sur un port de l'hôte. Au moins une couche PHY a été désactivée. Par exemple, le cable SAS connectant un port de l'hôte de contrôleur à un hôte a été déconnecté.Actions recommendées:●Vérifie la connexion du cable entre le port indiqué et l'hôte.Consultez le log pour déterminer si le problème persiste. | ||
| Info. La topologia SAS a changé sur un port de l'hôte. Au moins une couche PHY a été activée. Par exemple, le cable SAS connectant un port de l'hôte de contrôleur à un hôte a été connecté.Actions recommendées:●Aucune action n'est requise. | ||
| 355 Avertissement Le bouton de déboggage sur la plaque frontale était bloqué lors du démarrage.Actions recommendées:●Si le bouton reste bloqué, remplacez le module de contrôleur. | ||
| 356 Avertissement Cet événancement peut uniquement résulter de tests exécutés dans l'environnement de fabrication.Actions recommendées:●Suiveze le processus de fabrication. | ||
| 357 Avertissement Cet événancement peut uniquement résulter de tests exécutés dans l'environnement de fabrication.Actions recommendées:●Suiveze le processus de fabrication. | ||
| 358 Critique Toutes les couches PHY sont désactivées au niveau du canal de disque indiqué. Le système est dégradé et n'est pas toléré aux pannes, car tous les disques n'ont qu'un seul port.① REMARGUE: Les systèmes Série ME5 ne prenent en charge que les disques à double port.Actions recommendées:●Éteignez l'alimentation du boîtier du contrôleur, attendez quelques secondes, et remettez-le sous tension.●Si l'évenancement 359 a été consigné pour le canal spécifique, cela indique que la condition a disparu. Aucune action supplémentaire n'est requise.●Si l'erreur persiste, cela indique un problème matériel dans l'un des modules de contrôleur ou dans le fond de panier central du boîtier de contrôleur. Pour identifier l'unité FRU à replacer, consultez la section Dépannage et résolution des problèmes. | ||
| Avertissement Une partie des couches PHY, mais pas toutes, sont désactivées pour le canal de disque indiqué.Actions recommendées:●Consultez le log pour déterminer si la condition persistsente.●Si l'évenancement 359 a été consigné pour le canal spécifique, cela indique que la condition a disparu. Aucune action supplémentaire n'est requise.●Si l'erreur persistsente, cela indique un problème matériel dans l'un des modules de contrôleur ou dans le fond de panier central du boîtier de contrôleur. Pour identifier l'unité FRU à replacer, consultez la section Dépannage et résolution des problèmes. | ||
| 359 Info | Toutes les couches PHY désactivées au niveau du canal de disque indiqué ont récapacité et sont réalisables actives. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| Actions recommendées:●Aucune action n'est requise. | ||
| 360 Info | La vitesse de la couche PHY du disque indiqué a été renégociée. | Actions recommendées:●Aucune action n'est requise. |
| 361 Critique, erreur ou averissement | Le planificateur a rencontres un problème avec la planification indiquée. | Actions recommendées:●Effectuez l'action appropriée en fonction du problème indiqué. |
| Info. Une tâche planifiée a été lancée. | Actions recommendées:●Aucune action n'est requise. | |
| 362 Critique, erreur ou averissement | Le planificateur a rencontres un problème avec la tâche indiquée. | Actions recommendées:●Effectuez l'action appropriée en fonction du problème indiqué. |
| Info. Le planificateur a rencontres un problème avec la tâche indiquée. | Actions recommendées:●Aucune action n'est requise. | |
| 363 Erreur Lorsque le contrôle d'gestion est redémarré, les versions de firmware actuellément installées sont comparées à celles de l'offre groupée installée plus récente. Lors de la mise à jour de firmware, il est important que tous les composants soient mis à jour, sinon le système pourrait ne pas fonctionner correctement. Les composants vérifiés comprennent le CPLD, le contrôleur du module d'extension, le contrôleur de stockage et le contrôleur de gestion. | Actions recommendées:●Réinstalllez l'offre groupée de firmware. | |
| Info. Lorsque le contrôleur de gestion est redémarré, les versions de firmware actuellément installées sont comparées à celles de l'offre groupée installée plus récente. Si les versions correspondant, cet événement est consigné avec une gravité de niveau Informatif. Les composants vérifiés comprennent le CPLD, le contrôleur du module d'extension, le contrôleur de stockage et le contrôleur de gestion. | Actions recommendées:●Aucune action n'est requise. | |
| 364 Info | Le bus de diffusion est exécuté en tant que bus de génération 1. | Actions recommendées:●Aucune action n'est requise. |
| 365 Erreur Une erreur ECC | non corrigible s'est produit dans la mémoire CPU du contrôleur de stockage plusieurs fois, indiquant une probable panne matérielle. | Actions recommendées:●Remplacez le module de contrôleur ayant consigné cet événement. |
| Avertissement Ue erreur ECC non corrigible s'est produit dans la mémoire CPU du contrôleur de stockage. Cet événement est consigné avec une gravité de niveau Avertissement afin de fournir des informations pouvant être utiles au support technique, mais aucune action n'est requise dans l'immediat. Cet événement sera consigné avec une gravité de niveau Erreur si le remplacement du module de contrôleur est nécessaire. | Actions recommendées:●Aucune action n'est requise. |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Gravité Descriptio | h/actions recommendées | |
| 400 Info | Le log indiqué s'est rempli à un niveau justifiant son transfert vers un système de collecte de logs.Actions recommendées:·Aucune action n'est requise. | |
| 401 Aventissement Le log indiqué s'est rempli à un niveau qui pourrait entraîner une perte des données de diagnostic en l'absence de transfert vers un système de collecte de logs. Actions recommendées:·Transférrez le fichier log dans le système de collecte de logs. | ||
| 402 Erreur Le log indiqué est rempli et a commencé à écraser ses plus ancériennes données de diagnostic. Actions recommendées:·Déterminez pourquoi le système de collecte de logs ne les transfère pas avant qu'ils soient écrasés. Vous avez peut-être par exemple activé la fonctionnalité de gestion des logs sans configurer de destination d'envoil. | ||
| 412 Aventissement Un disq | de du groupe de disques RAID 6 indiqué est en panne. Le groupe de disques est en ligne, mais il est à l'état FTDN (tolerance aux pannes avec un disque à l'arrêt).S'il existe un disque de secours dédié (linéaire uniquement) ou un disque de remplacement global de taillie et de type appropriés, il est utilisé pour reconstruire automatiquement le groupe de disques. Les événements 9 et 37 sont consignés pour l'indiquer. Si aucun disque de secours n'est utilisable, mais s'il existe un disque de la taillie et du type appropriés avec fonctionnalité de disques de remplacement dynamiques activée, ce disque est utilisé pour reconstruire automatiquement le groupe de disques et l'événement 37 est consigné.Actions recommendées:RAID-6:·Si l'événement 37 n'a pas été consignedé, cela signifie qu'aucun disque de secours de la taillie et du type appropriés n'était disponible pour la reconstruction. Remplaceze le disque défaillant par un disque du même type et de capacité identique ou supérieure, et si nécessaire, désignez-le comme disque de secours. Confirmez cette opération en vérifier que les événements 9 et 37 sont consignés.Sinon, la reconstruction a démarré automatiquement et l'événement 37 a été consignedé. Remplacez le disque défaillant et configUREZ le disque de remplacement comme disque de secours dédié (linéaire uniquement) ou disque de remplacement global pour une utilisation ultérieure.Pour des performances d'E/S optimales en continu, le disque de remplacement doit fournir des performances identiques ou supérieures.Confirmez que tous les disques défaillants ont été replacés et qu'il existe suffisamment de disques de secours configurés pour une utilisation ultérieure.ADAPT:·Si l'événement 37 n'a pas été consignedé, l'espace de secours n'était pas disponible pour la reconstruction. Remplaceze le disque défectueux par un disque du même type ayant une capacité identique ou supérieure. La reconstruction doit démarrer et l'événement 37 doit être consignedé automatiquement.Pour des performances d'E/S optimales en continu, le disque de remplacement doit fournir des performances identiques ou supérieures.Assurez-vous que tous les disques défectueux ont été replacés pour assurer la tolérance de panne dans le futur. | |
| 442 | Avertissement L | des diagnostics POST ont déetecté une erreur matérielle dans une puce UART. Actions recommendées:·Remplacez le module de contrôleur ayant consigné cet événement. |
| 443 Erreur Le firmware du | boitier spécifique n'est pas pris en charge dans cette configuration. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| Le firmware du boîtier spécifique ne prend pas en charge ce boîtier pour une utilisation avec un châssis d'extension. Son firmware prend en charge ce boîtier uniquement en tant que boîtier JBOD à connexion directeActions recommendées:•Remplacez le boîtier spécifique. Il n'est pas pris en charge. | ||
| 454 Info | Un utilisateur a modifié le déali d'arrêt de rotation des disques du groupe de disques indiqué sur la valeur spécifique. | Actions recommendées:•Aucune action n'est requise. |
| 455 Avetissement Le contrôleleur a detecté que la vitesse de liaison de port à hôte configuraee dépassait la capacité d'un SFP FC. La vitesse a été automatiquement réduite à la valeur maximale prise en charge par tous les composants matériels du chemin d'accès des données. | Actions recommendées:•Remplacez le SFP du port indiqué par un SFP prénant en charge une vitesse plus élevé. | |
| 456 Avetissement L'IGN (SCSI Qualified Name) du système a été généraé à partir du numéro OUI (Organization Unique Identifier) par défaut, car les contrôleurs n'ont pas pu le dire à partir des données ID FRU du fond de panier central au moment du démarrage. Si l'IGN est incorrect pour la marque du système, il est possible que les hôtes iSCSI n'aisent plus accès au système. | Actions recommendées:•Si l'événement 270 avec code d'état 0 est consigné à peu près au même moment, redémarrez les contrôleurs de stockage. | |
| 457 Info | Le pool virtuel indiqué qu'a été créé. | Actions recommendées:•Aucune action n'est requise. |
| 458 Info | Des groupes de disques ont été ajoutés au pool virtuel indiqué. | Actions recommendées:•Aucune action n'est requise. |
| 459 Info | Le retrait des groupes de disques indiqués a démarré.À la fin de cette opération, l'événement 470 est consigné. | Actions recommendées:•Aucune action n'est requise. |
| 460 Erreur Le groupe de disques indiqué est manquant dans le pool virtuel spécifique. | Cela peut être dû à des disques manquants ou à des boîtiers déconnectés ou hors tension. | Actions recommendées:•Assurez-vous que tous les disques sont installés et que tous les boîtiers sont connectés et sous tension. Lorsque le problème est résolu, l'événement 461 est consigné. |
| 461 Info. | Le groupe de disques indiqué qui était manquant dans le pool virtuel spécifique a été récapacéré. | Cet événement indique qu'un problème signalé par l'événement 460 a été résolu. |
| 462 Erreur Le pool virtuel indiqué a atteint sa limite de stockage. | Actions recommendées:•Aucune action n'est requise. |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | h/actions recommendées |
| est consigné avec une gravité de niveau Avertissement si le seuil supérieur est dépassé et si le pool virtuel est surexploité. La surexploitation signifie que la taille totale utilisée de tous les volumes virtuels dépassé l'espace physique de ce dernier. Si l'utilisation du stockage descend sous un certain seuil, l'événement 463 est consigné.Actions recommendées:•Vouces nevez immédiatement prendre des mesures pour réduire l'utilisation du stockage ou pour ajouter de la capacité. | ||
| Avertissement | Le pool virtuel indiqué a dépassé le seuil le plus élevé de pages allouées, et le pool virtuel est surexploité.II existe trois seuils, dont deux peuvent être configurés par l'utilisateur. Le troisième paramètre, le plus élevé, est défini automatiquement par le contrôleur et ne peut pas être modifié. Cet événement est consigné avec une gravité de niveau Avertissement si le seuil supérieur est dépassé et si le pool virtuel est surexploité. La surexploitation signifie que la taille totale utilisée de tous les volumes virtuels dépassé l'espace physique de ce dernier. Si l'utilisation du stockage descend sous un certain seuil, l'événement 463 est consigné.Actions recommendées:•Vouces nevez immédiatement prendre des mesures pour réduire l'utilisation del stockage ou pour ajouter de la capacité. | |
| Info. Le pool | virtual indiqué a dépassé l'un de ses seuils de pages allouées définis.II existe trois seuils, dont deux peuvent être configurés par l'utilisateur. Le troisième paramètre, le plus élevé, est défini automatiquement par le contrôleur et ne peut pas être modifié. Cet événement est consigné avec une gravité de niveau Avertissement si le seuil supérieur est dépassé et si le pool virtuel est surexploité. La surexploitation signifie que la taille totALE utilisée de tous les volumes virtuels dépassé l'espace physique de ce dernier. Si l'utilisation du stockage descend sous un certain seuil, l'événement 463 est consigné.Actions recommendées:•Aucune action n'est requise pour les deux seuils les plus bas. En revanche, il serait judicieux de déterminer si l'utilisation de votre stockage augmente à une vitesse qui entraînerait rapidément le dépassement du seuil supérieur. Dans ce cas, prenez des mesures pour réduire l'utilisation del stockage ou achetez de la capacité supplémentaire.•En cas de dépassement du seuil supérieur, vous nevez immédiatement prendre des mesures pour réduire l'utilisation del stockage ou pour ajouter de la capacité. | |
| 463 Info | Le pool virtuel indi | que est repassé sous l'un des seuils de pages allouées définis.Cet événement indique qu'une condition signalée par l'événement 462 a été résolue.Actions recommendées:•Aucune action n'est requise. |
| 464 | Avertissement | Un utilisateur a inséré un cable ou SFP non pris en charge dans le port de l'hôte de contrôleur indiqué.Actions recommendées:•Remplacez le cable ou le SFP par un élément pris en charge. |
| 465 Info | Un utilisateur a retré un cable ou SFP non pris en charge dans le port de l'hôte de contrôleur indiqué.Actions recommendées:•Aucune action n'est requise. | |
| 466 Info | Le pool virtuel indi | que a été supprimé.Actions recommendées:•Aucune action n'est requise. |
| 467 Info | L'ajout du groupe | de disques indiqué s'est terminé avec succès.Actions recommendées: |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| •Aucune action n'est requise. | ||
| 468 Info | La température du circuit FPGA est revenue dans les limites de la plaque de fonctionnement normal et la vitesse des bus connectant le circuit FPGA aux adaptateurs descendants a été restaurée. La vitesse a été réduite pour compenser une surchauffe du circuit FPGA.Cet événement indique qu'un problème signalé par l'événement 469 a été résolu.Actions recommendées: •Aucune action n'est requise. | |
| 469 Aventissemment La vitesse se des bus connectant le circuit FPGA aux adaptateurs descendants a été réduite pour compenser une surchauffe du circuit FPGA.Lège système de stockage est opérationnel, mais les performances d'E/S sont réduitesActions recommendées: •Vérifie que les ventilateurs du système de stockage fonctionnement.•Vérifie que la température ambiente n'est pas trop élevé. La plaque de températures de fonctionnement du boîtier du contrôleur est comprise entre 5 °C et 35 °C (41 °F et 95 °F). La plaque de températures de fonctionnement du boîtier d'extension est comprise entre 5 °C et 40 °C (41 °F et 104 °F). •Vérifie que la presence d'obstructions à la circulation d'air.•Vérifie que chaque logement du boîtier contient un module ou un cache.•Si aucune de ces actions recommendées ne résout le problème, remplacez le module de contrôleur qui a enregistréré l'erreur.Lorsque le problème est résolu, l'événement 468 est consigné. | ||
| 470 Aventissemment Le retrait des groupes de disques indiqués a échoué.Le retrait d'un groupe de disques peut échoucher pour plusieurs raisons, et la cause spécifique de cet échéec est incluse avec l'événement. La plupart du temps, le retrait échoue en raison d'un espace disponible insuffistant dans le pool pour déplacer les pages de données des disques du groupe ACTIONS recommendées: •Résolvé le problème spécifique par le message d'erreur inclus avec cet événement et relancez la demande de retrait du groupe de disques. | ||
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| •Vérifiez que la température ambiente n'est pas trop élevé. La plage de températures de fonctionnement du boîtier du contrôleur est comprise entre 5 °C et 35 °C (41 °F et 95 °F). La plage de températures de fonctionnement du boîtier d'extension est comprise entre 5 °C et 40 °C (41 °F et 104 °F). •Vérifiez la présence d'obstructions à la circulation d'air. •Vérifiez que chaque logement du boîtier contient un module ou un cache. •Si aucune de ces actions recommendées ne résout le problème, remplacez le module de contrôleur qui a enregistré l'erreur. Lorsque le problème est résolu, l'événement 478 est consigné. | ||
| 477 Info. | La température du système de stockage est opérationnel, mais les performances d'E/S sont réduites. Actions recommendées: •Vérifiez que les ventilateurs du système de stockage fonctionnement. •Vérifiez que la température ambiente n'est pas trop élevé. La plage de températures de fonctionnement du boîtier du contrôleur est comprise entre 5 °C et 35 °C (41 °F et 95 °F). La plage de températures de fonctionnement du boîtier d'extension est comprise entre 5 °C et 40 °C (41 °F et 104 °F) •Vérifiez la présence d'obstructions à la circulation d'air. •Vérifiez que chaque logement du boîtier contient un module ou un cache. •Si aucune de ces actions recommendées ne résout le problème, remplacez le module de contrôleur qui a enregistré l'erreur. Lorsque le problème est résolu, l'événement 478 est consigné. | |
| 478 Info. | Un problème signalé par l'événement 476 ou 477 a été résolu. Actions recommendées: •Aucune action n'est requise. | |
| 479 Erreur Le contrôleur signant l'événement n'a pas pu envoyer les données vers la mémoire non volatile ou les restaurer à partir de cette dernière. Cela indique certainement une défaillance de la mémoire eMMC, mais cela peut également être dû à un autre problème avec le module de contrôleur. Le contrôleur de stockage ayant consigné cet événement va être arrêté de force par son contrôleur partenaire, qui va utiliser sa propre copie des données pour effectuer le vidage ou la restauration. Actions recommendées: •S'il s'agit de la première occurrence de cet événement, redémarrez le contrôleur de stockage arrêté de force. •Si cet événement est consignedé à nouveau, remplacez la mémoire eMMC. •Si cet événement est consignedé une nouvelle fois, arrêtez le contrôleur de stockage et remplacez le module de contrôleur. | ||
| 480 Erreur Un conflit d'adresses IP a été détecté pour le port ISCSI du système de stockage indiqué. L'adresse IP spécifiée est déjà utilisée. Actions recommendées: •Contactez votre administrateur reseau/données pour qu'il vous aide à résoudre le conflit d'adresses IP. | ||
| 481 Erreur La surveillance périodeque de la mémoire eMMC a détecté une erreur. Le contrôleur a été place en mode de double écriture, ce qui réduit les performances d'E/S. Actions recommendées: •Redémarrez le contrôleur de stockage ayant consigné cet événement. •Si cet événement est consignedé à nouveau, arrêtez le contrôleur de stockage et remplacez la carte eMMC. | ||
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Gravité Description | /actions recommendées | |
| • Si cet événement est consigné à nouveau, arrêtez le contrôleur de stockage et remplacez le module de contrôleur. | ||
| 482 Avertissement L'un des | bus PCIe utilise moins de voies que prévu.Cet événement est le résultat d'un problème matériel ayant poussa le contrôleur à utiliser moins de voies. Le système peut fonctionner avec moins de voies, mais les performances d'E/S sont dégradéesActions recommendées :•Remplacez le module de contrôleur ayant consignedé cet événement. | |
| 483 Erreur Une connexion | de module d'extension non valide a été détectée pour le canal de disque indiqué. Un port de sortie est connecté à un port de sortie, ou un port d'entrée est connecté à un port de sortie incorrect.Actions recommendées :•Suivez visuellement le câblage entre les boîtiers et corrigez-le. | |
| 484 Avertissement Aucun | disque de secours compatible n'est disponible pour la reconstruction de ce groupe de disques en cas de panne. Seuls les groupes de disques possédant des disques de seçours dédiés ou des disques de remplacement globaux adaptés démarrent la reconstruction automatiquement.Cette situation expose les données à un risque accru, car en cas de panne, une intervention de l'utilisteur est requise pour configurer un disque comme disque de secours dédié ou disque de remplacement global avant que la reconstruction ne puisse commencer sur le groupe de disques indiqué.Si le dernier disque de remplacement global a été supprimé ou utilisé pour une reconstruction, TOUS les groupes de disques ne possédant pas au moins un disque de secours dédié ou un disque de remplacement global sont exposés à un risque accru. Notez que même si des disques de remplacement globaux sont disponibles, ils ne peuvent pas été utilisés pour la reconstruction d'un groupe de disques si le dernier utilise des disques de capacité supérieure ou de type différent. Par conséquent, cet événement peut être consigné même s'il existe des disques de remplacement globaux non utilisés. Si la fonctionnalité de disques de remplacement dynamiques est activée, cet événement est consignedé même si un disque utilisé pour la reconstruction est disponible.Actions recommendées :•Configurez les disques comme des disques de secours dédiés ou comme des disques de remplacement globaux.Pour un disque de secours dédié, le disque doit être du même type que les autres disques du groupe linéaire et sa capacité doit être au moins égale à celle du disque de plus petite capacité dans le groupe linéaire. En outre, il doit fournir des performances identiques ou supérieures.Pour un disque de remplacement global, il vaut mieux désirir un disque dont la capacité est égale ou supérieure au disque de ce type ayant la plus grande capacité dans le système, avec des performances identiques ou plus élevées. Si le système contient une combinaison de disques de types différents (SSD, SAS d'entreprise ou SAS milieu de gamme), il doit y avoir au moins un disque de remplacement global de chaque type (à moins que des disques de secours dédiés soient utilisés pour protéger chaque groupe de disques d'un type donné, ce qui s'applique uniquement à une configuration de stockage linéaire). | |
| 485 | Avertissement Le groupe de disques indiqué a été mis en quarantaine pour empêcher l'écriture de données non valides qui peuvent exister dans le contrôleur ayant consignedé cet événement.Cet événement est consignedé pour signaler que le groupe de disques indiqué est hors ligne et en quarantaine (état QTOF) afin d'éviter la perte de données. Le contrôleur ayant consignedé cet événement a déetecté (à partir des informations enregistrées dans les métadonnées du groupe de disques) qu'il pourrait containir des données absolutes qui ne doivent pas été écrites sur le groupe de disques. Les données peuvent être perdues si vous ne suivez pas les actions recommandées avec précaution. Cette situation est généralement causée par le retrait d'un module de contrôleur sans l'arrêter au préalable, suivi de l'insertion d'un autre module de contrôleur à sa place. Pour éciter que ce problème ne se reproduise, arrêtez systématiquement le contrôleur de stockage d'un module de contrôleur avant de le retirer. Cette situation peut également être causée par la défaillance de la carte eMMC, comme indiqué par l'événement 204 Actions recommendées : | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Groupe | Gravité Description | h/actions recommendées |
| •Si l'événement 204 est consigné, suivez les actions recommendées correspondantes.•Si l'événement 204 N'EST PAS consigned, effectuez les actions recommendées suivantes :○Si l'événement 486 n'est pas consigned à peu prise au même moment que l'événement 485,reinsérez le module de contrôleur retire, arrêtez-le, puis retirez-le à nouveau.○Si les événements 485 et 486 sont consignés à peu prise au même moment, attendez au moins 5 minutes que la récapération automatique se termine. Ensuite, connectez-vous et confirmez que les deux modules de contrôleur sont opérationnels. (Vous pouvez déterminer si les contrôleurs sont opérationnels à l'aide de la commande CLI show controllers ou avec le SMC.) Dans la plupart des cas, le système revient à la normale et aucune action supplémentaire n'est requise. Si les deux modules de contrôleur ne deviennent pas opérationnels dans les 5 minutes, des données peuvent avoir été perdues. Si les deux contrôleurs ne sont pas opérationnels, suiveze ce processus de récapération :•Retirez le module de contrôleur ayant consigned l'événement 486 en premier.•Éteignez l'alimentation du boîtier du contrôleur, attendez quelques secondes, et remettez-le sous tension.•Attendez que le module de contrôleur redémarre, puis reconnectez-vous.•Vérifie l'état des groupes de disques. Si l'un des groupes de disques est hors ligne et en quarantaine (GTOF), annulez leur mise en quarantaine.•Réinsérez le module de contrôleur retire précédemment. Il devrait redémarrer correctement. | ||
| 486 Avertissement Une récapération a été lancée pour empêcher l'écriture de données non valides qui pourrait existerdans le contrôleur ayant consigned cet événement.Le contrôleur ayant consigned cet événement a déetecté (à partir des informations enregistrées dans les métadonnées du groupe de disques) qu'il pourrait contenir des données absolutes qui ne doivent pas être écrites sur le groupe de disques. Le contrôleur consigned cet événement, redémarre le contrôleur partaître, attend 10 secondes, puis force son propre arrêt. Le contrôleur partaître annule ensuite l'accreté du contrôleur et met en miroir les données de cache appropriées sur ce dernier. Dans la plupart des cas, cette procédure permet d'écrittre toutes les données sans aucune perte et sans écrire de données absolutesActions recommendées :•Attendez au moins 5 minutes pour que le processus de récapération automatique se termine.Ensuite, connectez-vous et vérifie que les deux modules de contrôleur sont opérationnels. (Vous pouvez déterminer si les contrôleurs sont opérationnels à l'aide de la commande CLI show redundancy-mode.) Dans la plupart des cas, le système revient à la normale et aucune action n'est requise.•Si les deux modules de contrôleur ne deviennent pas opérationnels dans les 5 minutes, reportez-vous aux actions recommendées pour l'événement 485, qui est consigned à peu prise au même moment. | ||
| 487 Info.Les statistiques de performances historiques ont été réinitialisées ACTIONS recommendées :•Aucune action n'est requise. | ||
| 488 Info.La création d'un groupe de volumes a commencé ACTIONS recommendées :•Aucune action n'est requise. | ||
| 489 Info.La création d'un groupe de volume s'est terminée ACTIONS recommendées :•Aucune action n'est requise. | ||
| 490 Info.La création d'un groupe de volumes a échoué ACTIONS recommendées :•Aucune action n'est requise. | ||
| 491 Info.La création d'un groupe de volumes a commencé. |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Groupe | Gravité Description | h/actions recommendées |
| Actions recommendées:●Aucune action n'est requise. | ||
| 492 Info | Les volumes d'un | groupe de volumes ont été dissociés.Actions recommendées:●Aucune action n'est requise. |
| 493 Info | Un groupe de volumes | mes a été modifié.Actions recommendées:●Aucune action n'est requise. |
| 495 Avertissement L'algorithm | nme de routagu du meilleur chemin a sélectionné le chemin d'accès de substitution pour le disque indiqué, car le nombre d'erreurs d'E/S sur le chemin principal a atteint son seuil.Lé contrôleur ayant consigné cet événement indiquequel canal (chemin) rencontres le problème. Par exemple, si le contrôleur B consigne le problème, ce dernier se trouve dans la chaîne de cables et de modules d'extension connectée au module de contrôleur B.Actions recommendées:●Si cet événement est toujours consigné pour le même disque d'un boîtier, procédez comme suit :○Remplacez le disque ○Si cette opération ne résout pas le problème, il vient probablement du fond de panier central du boîtier. Remplacez l'unité FRU du châssis dans le boîtier indiqué.Si cet événement est consigné pour plusieurs disques d'un boîtier ou de boîtiers différents, procédez comme suit :○Vérifiez la présence de cables SAS déconnectés dans le chemin incorrect. Si aucun cable n'est débranché, remplacez le cable connecté au port d'entrée du boîtier le plus en冲动,renton les pannes. Si cette opération ne résout pas le problème, remplacez les autres cables dans le chemin incorrect, un à la fois, jusqu'à ce que le problème soit résolu.Osi cette opération ne résout pas le problème, remplacez les modules d'extension du chemin incorrect. Commencez par le module le plus en冲动 dans le boîtier,**rencontrant les pannes.Si cette opération ne résout pas le problème, remplacez les autres modules d'extension (et le module de contrôleur) en amont du ou des boîtiers affectés, un à la fois, jusqu'à ce que le problème soit résolu.Osi cette opération ne résout pas le problème, la panne vient probablement du fond de panier central du boîtier. Remplacez l'unité FRU du châssis du boîtier le plus en冲动,**rencontrant les pannes. Si cette opération ne résout pas le problème et si plusieurs boîtiers,**rencontrent ces pannes, remplacez l'unité FRU du châssis des autres boîtiers,**rencontrant les pannes jusqu'à ce que le problème soit résolu. | |
| 496 | Avertissement L | Un type de disque non pris en charge a été détecté.Actions recommendées:●Remplacez le disque par un disque pris en charge. |
| Avertissement L | Un fournisseur de disque non pris en charge a été détecté.Actions recommendées:●Remplacez le disque par un disque pris en charge par le fournisseur de votre système. | |
| 501 Erreur Le matériel du boîter | bôtier n'est pas compatible avec le firmware du module d'E/S.Lé firmware du contrôleur du module d'extension a détecté une incompatibilité avec le type de fond de panier central. L'accès au disque a été désactivé dans le boîtier en prévention Actions recommendées:●Si vous utilisez un boîtier pris en charge, mettez à jour le système de stockage vers le firmware le plus récent. Si vous utilisez un boîtier non pris en charge, remplacez-le par un boîtier pris en charge. | |
| 502 Avertissement Le matériel | SSD indiqué a 5 % ou moins de vie restante. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| Cet événement est consigné à nouveau dés que l'apparil approche et atteint sa fin de vieActions recommendées:•Assurez-vous qu'un disque SSD de secours de même type et de même capacité est disponible.•Si un disque de rechange est disponible, remplacez le disque SSD maintainant. | ||
| Info. Le disque | Se SSD indiqué a 20% ou moins de vie restante.Cet événement est consigné à nouveau avec une gravité de niveau Avertissement lorsque le disque SSDapproche de la fin de son cycle de vie.Actions recommendées:•Obtenez un disque SSD de secours de même type et de même capacité si vous n'en ave pas àvotrec Disposition. | |
| 503 Info | Le système IBEEM | (Intelligent BackEnd Error Monitor) a découvert que des erreurs sont signalées encontinu au niveau de la couche PHY.Lesysteme IBEEM a consigné cet événement après avoir survillé la couche PHY pendant 30 minutes.Actions recommendées:•Aucune action n'est requise. |
| 504 Info | L'accès au début | Age de service du système a été activé ou désactivé par un utilisateur. L'activation del'accès au déboggage de service peut avoir des implications de sécurité. Une fois le diagnostic terminé,pensez à désactiver cet accès.Actions recommendées:•Aucune action n'est requise. |
| 505 | Avertissement | La taille du pool virtuel indiqué créé est inférieure à 500 Go, ce qui peut entraîner des comportementsimprévisibles.Lesysteme de stockage pourrait ne pas s'executer correctement.Actions recommendées:•Ajoutez des groupes de disques au pool virtuel pour augmenter la taille du pool. |
| 506 Info | L'avout du groupe | de disques indiqué a démarré.Ala fin de cette opération, l'évenement 467 est consigné.Actions recommendées:•Aucune action n'est requise. |
| 507 Info | La vitesse de liaison | On du disque indiqué ne correspond pas à la vitesse de liaison que le boîtier est capabled'atteindre.Cet événement est consigné lorsque la vitesse de liaison autonégociée est inférieure à la vitessemaximale prise en charge par le boîtier. Le disque est fonctionnel, mais les performances d'E/S sont réduites. Cet événement peut être consigné pour un canal de disque ou pour les deux canaux.Actions recommendées:•Si le disque appartient à un groupe de disques sans tolérance aux pannes (RAID 0 ou non RAID),déplacez les données sur un autre groupe de disques.•Remplacez le disque par un disque du même type (SSD, SAS d'entreprise ou SAS milieu de gamme)et de capacité supérieure ou égale. Pour des performances d'E/S optimales en continu, le disquede remplacement doit fournir des performances identiques ou supérieures à celles du disque qu'ilremplace. |
| 508 Erreur Le pool virtuel | Indiqué a été mis hors ligne. Tous ses volumes ont également été mis hors ligne.Toutes les données du pool virtuel ont été perdues. Cette condition peut survenir en cas d'inaccessibilitéou de corruption des métadonnées du pool virtuel.Actions recommendées: | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| • Recherche d'autres événements indiquant des défaillances dans le système et suivez les actions recommendées correspondantes. • Recréez le pool virtuel. • Restaurez les données à partir d'une sauvégarde le cas échéant. | ||
| 509 Erreur | Le volume des mètadonnées du pool virtuel indiqué a été mis hors ligne. Les mappings de volumes et les réservations persistantes sont inaccessibles ou perdus. Actions recommendées: • Recherche d'autres événements indiquant des défaillances dans le système et suivez les actions recommendées correspondantes. • Créez de nouveaux mappings pour les volumes. Les réservations persistantes seront restaurées par les systèmes hôtes automatiquement. | |
| 510 Info. | La clé de verrouillage du chiffrement FDE a été définie ou modifiée par un utilisateur. Actions recommendées: • Veiliez à enregistrer la phrase secrête de la clé de verrouillage et le nouvel ID de verrouillage. | |
| 511 Info. | La clé de verrouillage d'importation FDE a été définie ou modifiée par un utilisateur. Cette clé sert généralement à importer dans le système un disque FDE verrouillé par un autre système. Actions recommendées: • Assurez-vous que les disques importés sont intégrés au système. | |
| 512 Info. | Un utilisateur a fait passer le système à l'état sécurisé par chiffrement FDE. Le chiffrement de disque complet est désormais activé. Les disques retirés de ce système ne seront pas lisibles à moins d'être importés dans un autre système. Actions recommendées: • Aucune action n'est requise. | |
| 513 Info. | Un utilisateur a fait passer le système à l'état réaffecté par chiffrement FDE. Tous les disques ont été réaffectés et définis sur leur état d'usine. Le chiffrement FDE n'est plus activé sur le système. Actions recommendées: • Aucune action n'est requise. | |
| 514 Info. | La clé de verrouillage et la clé d'importation FDE ont été effacées par un utilisateur. Les opérations d'E/S peuvent se poursuivre tant que le système n'est pas redémarré. Actions recommendées: • Si le système est redémarré et que l'accès aux données est nécessaire, la clé de verrouillage doit être rétable. | |
| 515 Info. | Un disque FDE a été réaffecté par un utilisateur. Le disque a été réinitialisé à son état d'usine. Actions recommendées: • Aucune action n'est requise. | |
| 516 Erreur | Un disque FDE a été placé à l'état non disponible. Le message de l'événement 518 associé, qui indique qu'une opération de disque a échoué, peut fournir des informations supplémentaires. Actions recommendées: • Reportez-vous à l'action recommendée spécifiée dans le message de l'événement. | |
| 517 Info. | Un disque qui se trouaitAAParavariant à l'état de chiffrement FDE indisponible est réalisais disponible. |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| Le disque est revenu à un état normalActions recommendées:●Aucune action n'est requise. | ||
| 518 Erreur | Une opération de disque FDE a échoué.Cet événement fournit des détails sur l'opération ayant échoué.Actions recommendées:●Le disque doit peut être utilisé, importé, réaffecté ou remplaceé. | Passé à l'état chiffrement de disque complet dégradé.Cela indique en général qu'une erreur liée au disque s'est produit.Actions recommendées:●Un ou plusieurs disques doivent être retirés, importés, réaffectés ou remplacés. |
| 519 Erreur | Le système est passait à l'état chiffrement de disque complet dégradé n'est plus dégradé.Lesysystème est revenu à un état normal.Actions recommendées:●Aucune action n'est requise. | trouvait à l'état chiffrement de disque complet dégradé n'est plus dégradé.Lesysystème est revenu à un état normal.Actions recommendées:●Le fond de panier central devra peut être remplaceé si l'erreur persiste. |
| 520 Info | Une erreur s'est produit lors de l'accès à la mémoire SEEPROM du fond de panier central pour stocker ou recupérer les clés FDE.La mémoire du fond de panier central est utilisée pour stocker la clé de verrouillage FDE.Actions recommendées:●Examinez l'événement 207 consigné avant cet événement. Suivez les actions recommendées correspondantes. | Produite lors de l'accès à la mémoire SEEPROM du fond de panier central pour stocker ou recapérer les clés FDE.La mémoire du fond de panier central est utilisée pour stocker la clé de verrouillage FDE.Actions recommendées:●Suevez les actions recommendées correspondantes. |
| 522 Avertisment Un nettoyage de groupe de disques a rencontres une erreur à l'adresse de bloc logique (LBA) induquée.Les message de l'événement inclut toujours le nom du groupe de disques et l'adresse de bloc logique (LBA) concernée par l'érreur dans ce groupe. Si le bloc rencontre l'érreur se trouve dans la plage LBA utilisée par un volume, le message de l'événement inclut également le nom du volume et la LBA au sein de ce volume.Actions recommendées:●Examinez l'événement 207 consigné avant cet événement. Suivez les actions recommendées correspondantes. | Cet événement fournit des détails supplémentaires concernant un nettoyage de groupe de disques. Il vient compléter les informations de l'événement 206, 207 ou 522.Actions recommendées:●Suevez les actions recommendées correspondantes. | |
| 524 Erreur | Un capteur de température ou de tension a atteint un seul critique.Un capteur a relevé une température ou une tension se trouvant dans la plage critique. Lorsque le problème est résolu, l'événement 47 est signné pour le composant ayant consigné l'événement 524.Si l'événement concerne un capteur de disque, le comportement de ce dernier peut être imprévisible dans cette plage de températures.Explorez le journal des événements pour déterminer si plusieurs disques ont rapporté cet événement.Si c'est le cas, cette condition pourrait provenir d'un problème dans l'environnement.Si un seul disque signale cette condition, soit il peut s'agir d'un problème dans l'environnement, soit le disque est défaillant.Actions recommendées:●Vérifie que les ventilateurs du système de stockage fonctionnell. |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Groupe | Gravité Descriptio | h/actions recommendées |
| • Vérifiez que la température ambiente n'est pas trop élevé. La plage de températures de fonctionnement du boîtier du contrôleur est comprise entre 5 °C et 35 °C (41 °F et 95 °F). La plage de températures de fonctionnement du boîtier d'extension est comprise entre 5 °C et 40 °C (41 °F et 104 °F). • Vérifiez la présence d'obstructions à la circulation d'air. • Vérifiez que chaque logement du boîtier contient un module ou un cache. • Si aucune de ces actions recommendées ne résout le problème, remplacez le disque ou le module de contrôleur qui a enregistré l'erreur. | ||
| 525 Info | Un tiroir a été arrêté par un utilisateur. Le tiroir a été mis hors tension et peut être retiré en toute sécurité. Une nouvelle analyse doit être exécutée avant que les informations sur le tiroir mis à jour soient disponibles. Actions recommendées : • Redémarrez le tiroir à l'aide de la commande start drawer, ou retirez le tiroir pour le remplacer. | |
| 526 Info | Un tiroir a été dérépartiètés par un utilisateur. Le tiroir a été mis sous tension. Les disques de ce dernier peuventmettre plusieurs minutes à tourner. Une nouvelle analyse doit être exécutée avant que les informations sur le tiroir mis à jour soient disponibles. Actions recommendées : • Aucune action n'est requise. | |
| 527 Erreur Le firmware du Revenu | contrôleur du module d'extension est incompatible avec le boîtier. En prévention, le contrôleur du module d'extension a désactifé toutes les couches PHY et a signalé la page d'état de boîtier court dans la liste de diagnostics pris en charge. Actions recommendées : • Mettez à niveau le module de contrôleur à la的最后一 version de l'offre groupée prise en charge. | |
| 528 Erreur Le firmware du Remy | contrôleur du module d'extension a déetecté que le firmware du contrôleur du module d'extension partenaire est incompatible avec le boîtier. En prévention, le contrôleur du module d'extension a déactivé toutes les couches PHY et a signalé la page d'état de boîtier court dans la liste de diagnostics pris en charge. Actions recommendées : • Mettez à niveau le module de contrôleur partenaire à la的最后一 version de l'offre groupée prise en charge. | |
| 529 Erreur Le firmware du Lévy | module d'extension local est incompatible avec le boîtier. En prévention, le contrôleur du module d'extension a déactivé toutes les couches PHY et a signalé la page d'état de boîtier court dans la liste de diagnostics pris en charge. Actions recommendées : • Remplacez le module de contrôleur par un module compatible avec le boîtier. | |
| 530 Erreur Le firmware du Lévy | contrôleur du module d'extension local a déetecté un niveau d'incompatibilité avec le contrôleur du module d'extension partenaire. Cette incompatibilité peut être due à du matériel ou à un firmware non pris en charge. En prévention, le contrôleur du module d'extension local maintainé le contrôleur du module d'extension partenaire dans une boucle de réinitialisation. Actions recommendées : • Retirez le module de contrôleur partenaire du boîtier. Démarrez le module de contrôleur partenaire en mode contrôleur unique dans un boîtier distinct (sans le module de contrôleur ayant consigné cet événement). Chargez la的最后一 version compatible de l'offre groupée. Si le chargement de la version échoue, remplacez le module de contrôleur partenaire. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Groupe | Gravité Description | /actions recommendées |
| 533 Erreur Cet événement | fournit des détails sur le résultat du test du contrôleur de gestion sur le composant indiqué.Si le test réussit, le message indique que le composant estprésent et opérationnel. Si le test échoue, le message indique que le composant n'est pas disponible.Actions recommendées:Si l'événement indique que le test a échoué, remplacez le module de contrôleur ayant consigné cet événement. | |
| Info. Cet événement fournit des détails sur le résultat du test du contrôleur de gestion sur le composant indiqué.Actions recommendées:Aucune action n'est requise. | ||
| 539 Info | Pour le groupe de disques indiqué, qui a été corrompu, l'objet de recreation de la restauration du groupe a échoué ou réussi.Actions recommendées:Vérifiez que les volumes attendus ont été restaurés.Si les volumes attendus n ont pas été restaurés, la commande « recover volume » peut être utilisée.Après avoir vérifié la restauration de volume, effectuez la restauration du groupe de disques en exécutant la commande « recover disk-group complete » . | |
| 540 Info | Le volume indique, qui a été corrompu, a été restauréActions recommendées:Après avoir vérifié la restauration de volume, effectuez la restauration du groupe de disques en exécutant la commande « recover disk-group complete » . | |
| 541 Info. | L'étape de fin de la restauration du groupe de disques indiqué qui était corrompu a réussi.Actions recommendées:Aucune action n'est requise. | |
| 544 Info | Une opération de nettoyage de groupe de disques a dépasse son objectif de durée de 20 %.Le système tente de répondre aux objectifs de durée du nettoyage en ajustant les ressources système,mais des facteurs tels que la quantité de données ou une activités de l'hôte anormalement élevéepeuvent entrainer un dépassement de la durée demandée par les opérations de nettoyage ACTIONS recommendées:Si cet événement se produit à plusieurs reprises, l'objet de durée du nettoyage doit être augmenté pour accroître la probabilité que l'objet puisse être respecté. | |
| 545 Avertissemment Un module de contrôleur est connecté à un fond de panier central de boîtier existant, ce qui entraîne une dégradation des performances.Actions recommendées:Pour Brokerir de更好地 performances, remplacez l'unité FRU du châssis existant du boîtier par la version la plus récente de cette unité. | ||
| 546 Erreur Le contrôleur auvant consigné cet événement a forcé l'arrêt du contrôleur partenaire représentant laconfiguration de port de l'hôte incompatible ACTIONS recommendées:Remplacez le module de contrôleur arrêté de force par un module de contrôleur ayant la mêmeconfiguration de port de l'hôte que le module de contrôleur restant. | ||
| 548 Avertissemment La reconstruction du groupe de disques a échoué.Lorsqu'un disque tombe en panne, la reconstruction est effectuee à l'aide d'un disque de secours. Dans ce cas, la reconstruction a échoué en raison de la présence de données illisibles (erreur de support non conformément à l'action de l'administration). |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| corrignible) dans au moins un autre disque du groupe. De ce fait, une partie des données ne peut pas être reconstruite.Actions recommendées:• Si vous ne disposez pas d'une copie de sauvegarde des données de ce groupe de disques, effectuez une sauvegarde.• Prenez note de la configuration du groupe de disques, notamment sa taille et ses mappings d'hôte.• Recherche la présence d'un autre événement consigné à peu près au même moment indiquant une panne de disque, comme l'événement 8, 55, 58 ou 412. Suivez les actions recommendées pour cet événement.• Suprimez le groupe de disques.• Ajoutez de nouveau le groupe de disques.• Restaurez les données de la sauvegarde sur un nouveau groupe de disques. | ||
| 549 Critique Le module de contributeur indiqué a déetecté qu'il avait récapacité d'une défaillance interne du processeurActions recommendées:Remplacez le module de contrôleur. | ||
| 550 Critique Le chemin d'accès de lecture des données entre le contrôleur de stockage et les disques a été analysé comme non fiable. Le contrôleur de stockage a pris les mesures nécessaires pour corriger ce problème ACTIONS recommendées:Remplacez le contrôleur. | ||
| 551 Erreur Un EMP a signe l'un des problèmes suivants au niveau d'un bloc d'alimentation (PSU):• Le PSU ne parvient pas à communiquer avec l'EMP.• Le PSU d'un boîtier ne recoit aucune alimentation ou rencontres une panne matérielle.• Le firmware du bloc d'alimentation est corrompu.Actions recommendées:• Si l'EMP ne parvient pas à communiquer avec le PSU indiqué:○Attendez au moins 10 minutes et vérifie si l'erreur se résout ○ Si l'erreur persiste, vérifie que tous les modules du boîtier sont complètement insérés dans leur logement et que leurs loquets sont verrouillés le cas échéant.○Si cette opération ne résout pas le problème, prenez note du PSU concerné. Assurez-vous que le PSU partenaire n'est pas dégradé. En cas de dégradation de ce dernier, contactez le support technique.Osi le PSU partenaire n'est pas dégradé, retirez et réinsérez le bloc d'alimentation indiqué.Osi cette opération ne résout pas le problème, l'unité FRU indiquée est probablement défaillante et doit être remplaçée.Osi l'un des PSU d'un boîtier ne recoit aucune alimentation ou s'il rencontres une panne matérielle:○ Vérifie que le PSU indiqué est bien inséré dans son logement et que ses loquets sont verrouillés le cas échéant.OVérifie que le commutateur de chaque PSU est en position activée (le cas échéant).OVérifie que chaque cable d'alimentation est fermement connecté au PSU et à une prise électrique fonctionnelle.Osi aucune de ces actions recommandées ne résout le problème, le bloc d'alimentation indiqué est probablement défaillant et doit être remplaçé.OSI le firmware du bloc d'alimentation est corrompu:Lorsque le problème est résolu, un événement portant le même code est consigné avec une gravité de niveau Résolu. | ||
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Gravité Description | h/actions recommendées | |
| Si le PSU se trouve dans le boîtier, assurez-vous qu'il est correctement inséré dans son logement et que son loquet est verrouillé.Si aucune de ces actions recommendées ne résout le problème, le FRU indiqué est probablement défaillant et doit être replacé.Lorsque le problème est résolu, un événement portant le même code est consigné avec une gravité de niveau Résolu. | ||
| Résolu Une | alerte SES concernant un bloc d'alimentation dans le boîtier spécifique a été résolueActions recommendées:●Aucune action n'est requise. | |
| 552 Erreur | Un EMP a rapporté une condition d'alerte.Une panne matérielle a été détectée et tous les ventilateurs de la FRU indiquée sont défaillants.Lé ventilateur ne parvient pas à communiquer avec l'EMP.Actions recommendées:Si une panne matérielle a été détectée et si tous les ventilateurs de la FRU indiquée sont défaillants.OConsultez les informations d'intégrité du système pour déterminer quelles FRU contient les ventilateurs affectés. L'événement 551 ou 558 devrait fournir des informations supplémentaires sur les FRU concernées.Remplacez les FRU concernées.Si le ventilateur ne parvient pas à communiquer avec l'EMP.Attendez au moins 10 minutes et vérifie si l'erreur se résout.Si l'erreur persiste, vérifie que tous les modules du boîtier sont complètement insérés dans leur logement et que leurs loquets sont verrouillés le cas échéant.Si cette opération ne résout pas le problème, prenez note de la FRU concernée. Assurez-vous que la FRU partenaire n'est pas dégradée. En cas de dégradation de cette dernière, contactez le support technique.Si la FRU partenaire n'est pas dégradée, retirez et réinsérez la FRU indiquée.Si aucune de ces actions recommendées ne résout le problème, le FRU indiqué est probablement défaillant et doit être replacé.Lorsque le problème est résolu, un événement portant le même code est consigné avec une gravité de niveau Résolu. | |
| Avertissement | Un EMP a signalé l'un des problèmes suivants:●Un ventilateur de l'unité FRU indiquée a été désinstallé.Un ventilateur de l'unité FRU indiquée est tombé en panne et la redondance des ventilateurs de cette dernière a été perdue.Actions recommendées:●Si un ventilateur de l'unité FRU indiquée a été déinstalled:○Vérifie que la FRU indiquée se trouve dans le boîtier spécifique ○Si la FRU ne se trouve pas dans le boîtier, installez la FRU appropriée immédiatement.○Si la FRU se trouve dans le boîtier, assurez-vous qu'elle est correctement insérée dans son logement et que son loquet est verrouillé.OSi aucune de ces actions recommendées ne résout le problème, le FRU indiqué est défaillant et doit être replacé.Si un ventilateur de l'unité FRU indiquée est tombé en panne et si la redondance des ventilateurs de cette dernière a été perdue:○La FRU indiquée est défaillante et doit être replacée.Lorsque le problème est résolu, un événement portant le même code est consigné avec une gravité de niveau Résolu. | |
| Résolu Une | alerte SES concernant un ventilateur dans le boîtier spécifique a été résolue.Actions recommendées:●Aucune action n'est requise. | |
| 553 Erreur | Un capteur de température a rapporté une condition d'alerte. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Gévaïtés | Gravité Description | /actions recommendées |
| • Un capteur de température a déetecté une valeur dépassant le seuil de température critique dans la FRU indiquée.•Le capteur de température ne parvient pas à communiquer avec l'EMP/actions recommendées:• Si un capteur de température a déetecté une valeur dépassant le seuil de température critique dans la FRU indiquée.○Vérifie que la température ambiente n'est pas trop élevé. Pour la plage de fonctionnement normale, reportez-vous au guide d'installation et de maintenance matérielles de votre produit.○Vérifie la présence d'obstructions à la circulation d'air.○Vérifie que tous les modules du boîtier sont complètement insérés dans leur logement et que leurs loquets sont verrouillés le cas échéant.○Vérifie que tous les ventilateurs du boîtier fonctionnement.○Vérifie que chaque logement du boîtier contient un module ou un cache.○Si aucune de ces actions recommendées ne résout le problème, le FRU indiqué est probablement défaillant et doit être remplaced.•Le capteur de température ne parvient pas à communiquer avec l'EMP.•Attendez au moins 10 minutes et vérifie si l'erreur se résout.○Si l'erreur persiste, vérifie que tous les modules du boîtier sont complètement insérés dans leur logement et que leurs loquets sont verrouillés le cas échéant.○Si cette opération ne résout pas le problème, prenez note de la FRU concernée. Assurez-vous que la FRU partenaire n'est pas dégradée. En cas de dégradation de cette dernière, contactez le support technique.○Pour tous les types de FRU sauf le boîtier, si le FRU partenaire n'est pas dégradé, retirez l'unité FRU indiquée, puis réinsérez-la.○Si l'unité FRU indiquée est le boîtier lui-même, définissee une fenêtre de maintenance préventive et effectuez un cycle de marche/arrêt sur le boîtier à ce moment-là.○Si aucune de ces actions recommendées ne résout le problème, le FRU indiqué est probablement défaillant et doit être remplaced.Lorsque le problème est résolu, un événement portant le même code est consigné avec une gravité de niveau Résolu. | ||
| Avertissement | Un capteur de température a relevé une valeur qui n'est pas comprise dans les seuils de température de fonctionnement normale, mais comprend dans les limites de fonctionnement sûres ; ou un capteur de température a été désinstallé ACTIONS recommendées:• Si un capteur de température a relevé une valeur dépassant la plage de fonctionnement normale, mais se trouvant dans les limites de fonctionnement sûres.○Vérifie que la température ambiente n'est pas trop élevé. Pour la plage de fonctionnement normale, reportez-vous au guide d'installation et de maintenance matérielles de votre produit.○Vérifie la présence d'obstructions à la circulation d'air.•Si un capteur de température a été déinstallé:○Vérifie que la FRU indiquée se trouve dans le boîtier spécifique. •Si la FRU ne se trouve pas dans le boîtier, installez-la immédiatement. •Si la FRU se trouve dans le boîtier, assurez-vous qu'elle est correctement insérée dans son logement et que ses loquets sont verrouillés, le cas échéant. Lorsque le problème est résolu, un événement portant le même code est consigné avec une gravité de niveau Résolu. | |
| Résolu Une | aerte SES concernant un capteur de température dans le boîtier spécifique a été résolu ACTIONS recommendées:Aucune action n'est requise. | |
| 554 Erreur | Un capteur de tension a rapporté une condition d'alerte.Un capteur de tension a dédicté une valeur dépassant le seuil de tension critique dans la FRU indiquée. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Gévaité Description | /actions recommendées | |
| •Un capteur de tension ne parvient pas à communiquer avec l'EMP. Actions recommendées: •Si un capteur de tension a détesté une valeur dépassant le seuil de tension critique dans la FRU indiquée: ○Vérifie que tous les modules du boîtier sont complètement insérés dans leur logement et que leurs loquets sont verrouillés le cas échéant. ○Si cette opération ne résout pas le problème, l'unité FRU indiquée est probablement défaillante et doit être remplacee. •Si le capteur de tension ne parvient pas à communiquer avec l'EMP: ○Attendez au moins 10 minutes et vérifie si l'erreur se résout. ○Si l'erreur persiste, vérifie que tous les modules du boîtier sont complètement insérés dans leur logement et que leurs loquets sont verrouillés le cas échéant. ○Si cette opération ne permet pas de résoudre le problème, assurez-vous que le FRU partenaire n'est pas dégradé. Si tel est le cas, contactez le support technique. ○Pour tous les types de FRU sauf le boîtier, si le FRU partenaire n'est pas dégradé, retirez l'unité FRU indiquée, puis réinsérez-la. ○Si l'unité FRU indiquée est le boîtier lui-même, définièsez une fenêtre de maintenance préventive et effectuez un cycle de marche/arrêt sur le boîtier à ce moment-là. ○Si aucune de ces actions recommendées ne résout le problème, le FRU indiqué est probablement défaillant et doit être remplacee. Lorsque le problème est résolu, un événement portant le même code est consigné avec une gravité de niveau Résolu. | ||
| Avertissement U | •Un capteur de tension a relevé une valeur qui n'est pas comprise dans les seuls de tension de fonctionnement normale, mais comprend dans les limites de fonctionnement sûres; ou un capteur de tension a été retiret. Actions recommendées: •Si un capteur de tension a relevé une valeur dépassant la plage de fonctionnement normale, mais se trouvant dans les limites de fonctionnement sûres: ○Vérifie que tous les modules du boîtier sont complètement insérés dans leur logement et que leurs loquets sont verrouillés. ○Si cette opération ne résout pas le problème, l'unité FRU indiquée est probablement défaillante et doit être remplacee. •Si un capteur de tension a été retiret: ○Vérifie que la FRU indiquée se trouve dans le boîtier spécifique. ○Si la FRU ne se trouve pas dans le boîtier, installez-la immeditatement. ○Si la FRU se trouve dans le boîtier, assurez-vous qu'elle est correctement insérée dans son logement et que ses loquets sont verrouillés. ○Si aucune de ces actions recommendées ne résout le problème, le FRU indiqué est probablement défaillant et doit être remplacee. Lorsque le problème est résolu, un événement portant le même code est consigné avec une gravité de niveau Résolu. | |
| Résolu Une | •Verte SES concernant un capteur de tension dans le boîtier spécifique a été résolue. Actions recommendées: •Aucune action n'est requise. | |
| 555 Erreur Le firmware du | contrôleur du module d'extension local a détesté un niveau d'incompatibilité avec le matériel ou firmware du contrôleur du module d'extension partenaire. En prévention, le contrôleur du module d'extension local peut désactiver toutes les couches PHY. Actions recommendées: •Vérifie que les deux contrôleurs de module d'extension exécutent la bonne version du firmware. •Si les deux contrôleurs de module d'extension utilisent différentes versions du firmware, mettez à niveau le module de contrôleur partenaire vers la version appropriée du firmware compatible avec le boîtier. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| •Si ces actions recommendées ne résolvent pas le problème, remplacez le module de contrôleur partenaire.Lorsque le problème est résolu, un événement portant le même code est consigné avec une gravité de niveau Résolu. | ||
| Avertissement U | ne extension du module de contrôleur, un module d'extension ou un tiroir est associé, mais ne répond pas ; ou une extension dans un module d'extension a été retiree.Actions recommendées :•Vérifiez que la FRU indiquée se trouve dans le boîtier spécifique.•Si la FRU ne se trouve pas dans le boîtier, installez la FRU appropriée immédiatement.Si la FRU se trouve dans le boîtier, assurez-vous qu'elle est correctement insérée dans son logement et que ses loquets sont verrouillés, le cas échéant.Si aucune de ces actions recommendées ne résout le problème, le FRU indiqué est défaillant et doit être remplaced.Lorsque le problème est résolu, un événement portant le même code est consigné avec une gravité de niveau Résolu. | |
| Résolu Une | alerte SES concernant une extension dans le boîtier spécifique a été résoluActions recommendées :•Aucune action n'est requise. | |
| 556 Erreur | Un condition d'alerte U | alerte a été détectée au niveau d'une extension racine ou d'un élément d'extension de tiroir.Actions recommendées :•Remplacez le module contenant l'extension indiquée. Il peut s'agir d'un IOM, d'un fond de panier latéral ou d'un tiroir. Contactez le support technique pour le remplacement du module contenant l'extension de tiroir.PRECAUTION: Les fonds de panier latéaux sur les tiroirs de boîtier ne sont pas échangeables à chaud et ne peuvent pas faire l'objet de maintenance par le service clientèle.Si ces mesures recommendées ne résolvent pas le problème, contactez le support technique. Le boîtier doit être remplaced.Lorsque le problème est résolu, un événement portant le même code est consigné avec une gravité de niveau Résolu. |
| Avertissement U | ne condition d'alerte a été détectée au niveau d'une extension racine ou d'un élément d'extension de tiroir.Actions recommendées :•En cas de désinstallation, l'extension associée au fond de panier latéral ou au tiroir doit être installée.Contactez le support technique. Sinon, remplacez le module contenant l'extension indiquée. Il peut s'agir d'un fond de panier latéral ou d'un tiroir. Contactez le support technique pour le remplacement du module contenant l'extension du tiroir.PRECAUTION: Les fonds de panier latéaux sur les tiroirs de boîtier ne sont pas échangeables à chaud et ne peuvent pas faire l'objet de maintenance par le service clientèle.Si ces mesures recommendées ne résolvent pas le problème, contactez le support technique. Le boîtier doit être remplace.Lorsque le problème est résolu, un événement portant le même code est consigné avec une gravité de niveau Résolu. | |
| Résolu Une | alerte SES concernant une extension dans le boîtier spécifique a été résoluActions recommendées :•Aucune action n'est requise. | |
| 557 Erreur | Un processeur de gestation de boîtier (EMP) a signalé une condition d'alerte sur un capteur de courant.L'EMP ne parvient pas à communiquer avec le capteur de courant indiqué. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | h/actions recommendées |
| •Le capteur de courant a relevé une valeur au-delà du seuil critique. Actions recommendées: •Si l'EMP ne parvient pas à communiquer avec le capteur de courant indiqué: ○Attendez au moins 10 minutes et vérifie si l'erreur se résout. ○Si l'erreur persiste, vérifie que tous les modules du boîtier sont complètement insérés dans leur logement et que leurs loquets sont verrouillés le cas échéant. ○Si cette opération ne permet pas de résoudre le problème, assurez-vous que le FRU partenaire n'est pas dégradé. Si tel est le cas, contactez le support technique. ○Pour tous les types de FRU sauf le boîtier, si le FRU partenaire n'est pas dégradé, retirez l'unité FRU indiquée, puis réinsérez-la. ○Si l'unité FRU indiquée est le boîtier lui-même, définièsez une fenêtre de maintenance préventive et effectuez un cycle de marche/arrêt sur le boîtier à ce moment-là. ○Si aucune de ces actions recommendées ne résout le problème, le FRU indiqué est probablement défaillant et doit être remplaced. •Si le capteur de courant a relevé une valeur au-delà du seuil critique: ○Vérifie que tous les modules du boîtier sont complètement insérés dans leur logement et que leurs loquets sont verrouillés le cas échéant. ○Si aucune de ces actions recommendées ne résout le problème, le FRU indiqué est probablement défaillant et doit être remplace. Lorsque le problème est résolu, un événement portant le même code est signifié avec une gravité de niveau Résolu. | ||
| Avertissement Un processeur de gestion de boîtier (EMP) a signalé une condition d'alerte sur un capteur de courant. •Un capteur de courant a relevé une valeur au-delà du seuil d'advertissement définiti. •Un capteur de courant a été désinstallé. Actions recommendées: •Si un capteur de courant a relevé une valeur dépassant le seuil d'advertissement définiti: ○Vérifie que tous les modules du boîtier sont complètement insérés dans leur logement et que leurs loquets sont verrouillés le cas échéant. ○Si cette opération ne résout pas le problème, l'unité FRU indiquée est probablement défaillante et doit être remplace. •Si un capteur de courant a été désinstallé: ○Vérifie que la FRU indiquée se trouve dans le boîtier spécifique. ○Si la FRU ne se trouve pas dans le boîtier, installez-la immédiatement. ○Si la FRU se trouve dans le boîtier, assurez-vous qu'elle est correctement insérée dans son logement et que ses loquets sont verrouillés, le cas échéant. ○Si aucune de ces actions recommendées ne résout le problème, le FRU indiqué est probablement défaillant et doit être remplace. Lorsque le problème est résolu, un événement portant le même code est signifié avec une gravité de niveau Résolu. | ||
| Résolu Une alerte SES concernant un capteur de courant dans le boîtier spécifique a été résolu. Actions recommendées: •Aucune action n'est requise. | ||
| 562 Info | Les statistiques du pool virtuel ont été réinitialisées. Actions recommendées: •Aucune action n'est requise. | |
| 563 Info | Un disque a été redémarré. Actions recommendées: •Aucune action n'est requise. | |
| 565 Ave | tississement L'un des bus PCIe fonctionne actuelles à un débit insuffisant. | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Géralde | Gravité Description | /actions recommmandées |
| Cet événement est le résultat d'un problème matériel ayant poussa le contrôleur à fonctionner plus lentement que prévu. Le système fonctionne, mais les performances d'E/S sont dégradéesActions recommmandées:Redémarrez le contrôleur qui a consigné l'événement. Si le problème persiste, remplacez le module de contrôleur. | ||
| 566 Info. | L'un des ports DCR | R est occupé depuis au moins 5 minutes.Cet événement est le résultat d'une compensation de début lors du traitement des blocs de données courts. Le système est opérationnel, mais les performances des E/S s'en ressentent.Actions recommmandées:Aucune action n'est requise. |
| 568 Info. | Un groupe de disu | ues comprehend des disques physiques de tailles de secteurs mixtes (par exemple, des disques 512n et 512e dans le même groupe de disques).Cet événement est le résultat de la sélection par l'utilitaire de disques avec des formats de secteurs qui ne correspondant pas ou d'un remplacement de disque de secours global avec un format de secteur différent de celui du groupe de disques. Ceci pourrait affecter les performances de certaines charges de travail.Actions recommandées:Aucune action n'est requise. |
| 569 AventismentUne non- | -correspondance de cable d'hote SAS a été détectée pour un port. Les autres couches PHY indiquées ont été désactivées.Par exemple, un cable de sortie de ventilateur est connecté au port de l'hote d'un module de contrôleur, alors que le port est configuré pour utiliser des cables SAS standard, ou vice versa.Actions recommandées:Pour utiliser le cable connecté, utilisez la commande « set host-variables » de l'interface CLI pour configurer les ports afin d'utiliser le type de cable approprié.Vous pouvez également replacer le cable par le type de cable dont l'utilisation est configurée pour le port.Lorsque le problème est résolu, un événement portant le même code est consigné avec une gravité de niveau Résolu.Résolu La non- | -correspondance de cable d'hote SAS détectée a été résolue pour le port.Le type de cable approprié a été connecté.Actions recommandées:Aucune action n'est requise. |
| 571 Erreur L'espace attribué | aux snapshots a dépasse le pourcentage limite configuré pour ce pool virtuel.Si la strategie de limitation de l'espace attribué aux snapshots est définie pour supprimer les snapshots, le système commencerà à supprimer les snapshots en fonction du paramètre de priorité de conservation des snapshots jusqu'à ce que l'utilisation de cet espace repasse en début de la limite configurée. Sinon, le système commencerà à utiliser l'espace de pool général pour stocker les snapshots jusqu'à ce qu'il soit supprimés manuellement. Si l'utilisation du stockage repasse en dessous d'un certain seul, l'événement 572 est consigné.Actions recommandées:Si la strategie de limitation de l'espace attribué aux snapshots est définie pour envoyer une simple notification, vous doivent immédiatement prendre des mesures pour réduire l'utilisation de cet espace ou ajouter de la capacité de stockage.Si la strategie de limitation de l'espace attribué aux snapshots est définie pour les supprimer, le système réduit cet espace automatiquement, ou consigne l'événement 573 si aucun snapshot ne peut être supprimé.Avertissement L'espace attribué aux snapshots a dépassé le seuil supérieur défini. |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| Le paramètre de seuil supérieur indique que le pool a presque épuisé l'espace attribué aux snapshots. Les paramètres de seuil sont conçus pour indiquer lorsque le pool utilise une partie importante de l'espace configuré pour les snapshots et qu'il doit être surveillé. Si l'utilisation de la capacité de stockage passen dessous d'un seuil, l'événement 572 est consignéActions recommendées:●Réduisez l'utilisation de l'espace dédié aux snapshots en supprimant les snapshots superflus. | ||
| Info. L'espace | info. L'espace attribué aux snapshots a dépassé le seuil inférieur ou intermédiaire définis.Les paramètres de seuil sont conçus pour indiquer lorsque le pool utilise une partie importante de l'espace configuré pour les snapshots et qu'il doit être surveillé. Si l'utilisation de la capacité de stockage passen dessous d'un seuil, l'événement 572 est consignéActions recommendées:●Réduisez l'utilisation de l'espace dédié aux snapshots en supprimant les snapshots superflux. | |
| 572 Info. | Le pool virtuel indiquéqué est repassé sous l'un des seuils d'espace alloué aux snapshots définis.Cet événement indique qu'une condition signalée par l'événement 571 a été résolue.Actions recommendées:●Aucune action n'est requise. | |
| 573 Aventissement L'espace | Aventissement L'espace attribué aux snapshots dans un pool virtuel ne peut être réduit, car chaque snapshot ne peut être supprimé.Les snapshots alloués ne peuvent pas être automatiquement supprimés si leur priorité de conservation est définie sur never-delete (ne jamais supprimer). Les snapshots doivent également se trouver à l'extrémité d'une branch de'une arborescence afin de pouvoir être supprimés. Cet événement est consigné lorsqu'aucun snapshot dans le pool ne respecte ces contraintes.Actions recommendées:●Suprimez manuellement des snapshots pour réduire l'espace qu'ils utilisent. | |
| 574 Info. | Une connexion homologue a été créée.Actions recommendées:●Aucune action n'est requise. | |
| 575 Info. | Une connexion homologue a été supprimée.Actions recommendées:●Aucune action n'est requise. | |
| 576 Info. | Un ensemble de réplication a été créé, ou la création d'un ensemble de réplication a échoué.Actions recommendées:●Aucune action n'est requise. | |
| 577 Erreur La suppression d'un ensemble de réplication a échoué.Actions recommendées:●Aucune action n'est requise. | ||
| 578 Erreur Une réplicationn'a pas pu démarrer.La réplication a échoué en raison de la condition spécifique dans cet événement. Les motifs d'échéced'une réplication incluent l'accret du système secondaire, une perte de communication au niveau de la connexion homologue (potentiellément due à des modifications de configuration CHAP) ou un manque d'espace sur le pool (mais ne s'y limitent pas). | ||
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Descriptio | h/actions recommendées |
| Actions recommendées:Résolvez le problème spécifique par le message d'erreur inclus avec cet événement. | ||
| Info. Une réplication a été démarrée.Actions recommendées:Aucune action n'est requise. | ||
| 579 Aventissement La réplication a échoué.La réplication a échoué en raison de la condition spécifique dans cet événement. Les motifs d'échec d'une réplication incluent l'arrêt du système secondaire, une perte de communication au niveau de la connexion homologue (potentiellément due à des modifications de configuration CHAP) ou un manque d'espace sur le pool (mais ne s'y limitent pas).Actions recommendées:Résolvez le problème spécifique par le message d'erreur inclus avec cet événement. | ||
| Info. La réplication s'est terminée correctement ACTIONS recommendées:Aucune action n'est requise. | ||
| 580 Info. | Une réplication a été abandonnée ACTIONS recommendées:Aucune action n'est requise. | |
| 581 Aventissement Une réplication a été interrompu en interne par le système. Le système suspend la réplication en interne s'il déetecte une erreur au niveau de l'ensemble de réplication et si les réplications ne peuvent pas continuer pour une raison qualconque. Les motifs incluent l'arrêt du système secondaire, une perte de communication au niveau de la connexion homologue (potentiellément due à des modifications de configuration CHAP) ou un manque d'espace sur le pool (mais ne s'y limitent pas).Actions recommendées:Là réplication reprend automatiquement une fois l'erreur déscribe dans cet événement résolue. | ||
| Info. Une réplication a été interrompu par l'utilisateur ACTIONS recommendées:Aucune action n'est requise. | ||
| 582 Info. | Une réplication a été mise en file d'attente derrière la réplication active ACTIONS recommendées:Aucune action n'est requise. | |
| 583 Erreur Suite à une défauilleance, l'ensemble de réplication n'a pas été inversé.Pendant l'opération de restauration automatique, le sens de la réplication d'un ensemble de réplication n'a pas été inversé en raison d'une défaillance ACTIONS recommendées:Si un problème de connexion homologue a été signalé, vérifie que les cables d'interface appropriés sont connectés aux portes hôtes définis dans la connexion homologue.Si les cables appropriés sont connectés, vérifie-les ainsi que les commutateursRéseau pour détecter d'éventuels problèmes.Dans le cas contraire, assurez-vous que la configuration de la connexion homologue est valide. | ||
| Info. Le sens de la réplication d'un ensemble de réplication a été inversé. La réplication secondaire est maintainant principale, et inversé. | ||
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| Pendant l'opération de restauration automatique, le sens de la réplication d'un ensemble de réplication a été inversé.Actions recommendées:●Aucune action n'est requise. | ||
| 584 Info | Une connexion homologue a été modifiée.Actions recommendées:●Aucune action n'est requise. | |
| 585 Info | Un ensemble de réplication a été modifié.Actions recommendées:●Aucune action n'est requise. | |
| 586 Erreur La reprise de la reapplication a échoué en raison de la condition spécifique dans cet événement. Les motifs d'éché c'une réplication incluent l'accret du système secondaire, une perte de communication au niveau de la connexion homologue (potentiellement due à des modifications de configuration CHAP) ou un manque d'espace sur le pool (mais ne s'y limitent pas).Actions recommendées:●Résolvé le problème spécifique par le message d'erreur inclus avec cet événement. | ||
| Info. Une réplication a repris.Actions recommendées:●Aucune action n'est requise. | ||
| 587 Info | Une réplication estative atteinte a été retiree de la file.Actions recommendées:●Aucune action n'est requise. | |
| 588 Info | Un ensemble de réplication a subi un basculement.Lors de l'opération de restauration automatique, un ensemble de réplication a subi un basculement.Actions recommendées:●Aucune action n'est requise. | |
| 589 Info | Un ensemble de réplication a terminé l'opération Failback No Restore (Retour arrêt sans restauration) par un éché ou une réussite.Actions recommendées:●Aucune action n'est requise. | |
| 590 Erreur Un groupe de disques a été mis en quarantaine.Cette condition fait suite à l'éché c'une opération de nettoyage/restauration de contrôleur.Actions recommendées:●Pour restaurer le groupe de disques, utilisez la commande CLI de quarantine pour sortir le groupe de disques de sa quarantaine. Si plusieurs groupes de disques sont en quarantaine, vous devez les débloquer individuellement, indépendamment de leur tolérance aux pannes. Une fois le groupe sorti de quarantaine, il reprend son état dans lequel il se trouvait avant d'être mis en quarantaine. Par exemple, si le groupe de disques était en cours de reconstruction avant d'être mis en quarantaine, il reprend là où il s'était arrêté.AVEC un groupe de disques linéaire, si vous souhaitez localiser le problème de parité, utilisez la commande CLI scrub vdisk avec le paramètre fix déactivé. Cette étape est facultative et n'est pas requisse pour résoudre les problèmes d'intégrité des données.Pour un groupe de disques à tolérance aux pannes, exécutez soit scrub disk-groups pour un groupe de disques virtuels, soit scrub vdisk avec le paramètre fix activé pour un groupe de | ||
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| disques linéaires. Cette étape rendra la parité cohérente avec les données utilisateur existantes. De plus, elle est nécessaire pour résoudre les problèmes d'intégrité des données. •Pour un groupe de disques en reconstruction, attendez que la reconstruction se termine, puis exécutez soits SCR publique un groupe de disques virtuels, soit SCR vdisk avec le paramètre fix activé pour un groupe de disques linéaires. Cette étape rendra la parité cohérente avec les données utilisateur existantes. De plus, elle est nécessaire pour résoudre les problèmes d'intégrité des données. •Restaurez les données sur le groupe de disques à partir d'une copie de sauvégarde. | ||
| 593 Info | Un bus PCIe fonctionne à un débit différent. Actions recommendées: •Aucune action n'est requise. | |
| 594 Info | Le disque spécifique dans le groupe indiqué est manquant et le groupe de disques est en quarantaine. Dans le cas d'un stockage linéaire, quand le groupe de disques est en quarantaine, toute tentative d'accès à ses disques à partir d'un hôte échoue. Dans le cas d'un stockage virtuel, tous les volumes du pool sont passés de force en lecture seule. Si tous les disques redeviennent accessibles, le groupe de disques sort de quarantaine automatiquement avec l'etat FTOL. Si tous les disques ne redeviennent pas accessibles, mais qu'un nombre suffisant est disponible pour permettre la lecture à partir du groupe de disques et l'écriture sur ce dernier, alors il est sorti de quarantaine automatiquement avec l'etat FTDN ou CRIT. Si un disque de secours est disponible, la reconstruction commence automatiquement. Lorsque le groupe de disques est sorti de sa quarantaine, l'événement 173 est consigné. Pour une discussion plus détaillée sur la sortie de quarantaine, reportez-vous à la documentation de PowerVault Manager ou de la CLI. PRECAUTION: •Évitiez d'avoir recours à la sortie de quarantaine manuelle comme méthode de récapétation lorsque l'événement 172 est consigné, car cela rend la récapétation des données plus difficile, voire impossible. •Si vous effacez les données de cache non écrites pendant qu'un groupe de disques est en quarantaine ou hors ligne, ces données sont définitivement perdues. Actions recommendées: •Si l'événement 173 a ensuite été consigned pour le groupe de disques indiqué, aucune action n'est requise. Le groupe de disques a déjà été sorti de quarantaine. •Dans le cas contraire, procédez comme suit: ○Vérifiez que tous les boîtiers sont sous tension. ○Vérifiez que tous les disques et modules d'E/S de chaque boîtier sont complètement insérés dans leur logement et que leurs loquets sont verrouillés. ○Replacez tous les disques du groupe mis en quarantaine signalés comme manquants ou défaillants dans l'interface utilisateur. (NE PAS retireur et réinsérer les disques qui ne sont pas membres du groupe de disques mis en quarantaine.) ○Vérifiez que les cables d'extension SAS sont connectés entre chaque boîtier du système de stockage et qu'ils sont bien en place. (NE PAS retireur et réinsérer les cables, car cela peut entraîr des problèmes avec d'autres groupes de disques.) ○Vérifiez qu'aucun disque n'a été retiredu système involontairement. ○Recherchez d'autres événements indiquant des pannes dans le système et suivez les actions recommandées correspondantes. Mais, si l'événement indique qu'un disque est défiaillant et si l'action recommandée est de remplancer le disque, ne le remplacez PAS à ce moment-là, car il pourrait être requis utérieurement pour la récapétération des données. ○Si le groupe de disques est toujours en quarantaine après avoir suivi les étapes précédentes, arrêtez les deux contrôleurs et éteignez l'ensemble du système de stockage. Remettez-le sous tension, en commençant par les boîtiers de disques (boîtiers d'extension), puis le boîtier de contrôleur. ○Si le groupe de disques est toujours en quarantaine après l'exécution des étapes précédentes, contactez le support technique. | |
| 595 | Info. Cet événement indique le numéro de série de chaque module de contrôleur dans ce système. Actions recommendées: | |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| •Aucune action n'est requise. | ||
| 596 Aventisement La protection contre les pannes du boîtier est compromise pour le groupe de disques indiqué.Pour replacer le disque défectueux, le système n'a pas pu trouver un disque de rechange qui répond aux exigences pour réduire le risque de perte de données en cas de défaillance du boîtier. Le système a donc d'optionner un disque de rechange qui ne répond pas aux exigences. Dans le cas d'un groupe de disques RAID 6, cela signifie que plus de deux disques membres se trouvent dans le même boîtier.Pour les autres niveaux RAID, cela signifie que plusieurs disques membres se trouvent dans le même boîtier.Actions recommendées:•Remplacez le disque défectueux spécifique dans le boîtier indiqué pour restaurer la protection contre les pannes du boîtier. | ||
| 597 Aventisement La protection contre les pannes du tiroir estompromise pour le groupe de disques indiqué.Pour replacer le disque défectueux, le système n'a pas pu trouver un disque de rechange qui répond aux exigences pour réduire le risque de perte de données en cas de défaillance du tiroir. Le système a donc d'optionner un disque de rechange qui ne répond pas aux exigences. Dans le cas d'un groupe de disques RAID 6, cela signifie que plus de deux disques membres se trouvent dans le même tiroir. Pour les autres niveaux RAID, cela signifie que plusieurs disques membres se trouvent dans le même tiroirActions recommendées:•Remplacez le disque défectueux spécifique dans le boîtier indiqué pour restaurer la protection contre les pannes du tiroir. | ||
| 598 Aventisement,Infos. | La mesure des performances d'un lecteur a échoué.Actions recommendées:•Surveillance le disque. | |
| 599 ErreurLe firmware doitencore recupérer l'état de contrôle de l'élement Enclosure Power (alimentation du boîtier).L'élement Enclosure Power permet de contröler l'alimentation du boîtier. Cela peut se produit peu de temps après un redémarge ou l'insertion d'un module. Cet événement ne doit être traité comme une erreur que si le problème persiste pendant plus de 30 secondes après une réinitialisation ACTIONS recommendées:•Contactez le support technique.Lorsque le problème est résolu, un événement portant le même code est consigné avec une gravité de niveau Résolu. | ||
| Avertissement,RésoluLe firmware doit encore recupérer l'état de contrôle de l'élement Enclosure Power (alimentation du boîtier).L'élement Enclosure Power permit de contröler l'alimentation au niveau du boîtier-actions recommendées:•Aucune action n'est requise. | ||
| 602 Erreur,Avertissement | Une condition d'alerte a été détectée au niveau de l'élement Midplane Interconnect (interconnexion de fond de panier central).L'élement Midplane Interconnect signale l'état associé à l'interface entre le module d'E/S SBB et le fond de panier central. Il s'agit généralement d'une forme de problème de communication au niveau de l'interconnexion de fond de panier central ACTIONS recommendées:•Contactez le support technique. Fournissez les logs au personnel du support technique pour analyse.Lorsque le problème est résolu, un événement portant le même code est consigné avec une gravité de niveau Résolu. | |
| Résolu Unecondition précédente de type Avertissement ou Erreur a été résolue au niveau de l'élementMidplane Interconnect (interconnexion de fond de panier central). |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| L'élement Midplane Interconnect signale l'état associé à l'interface entre le module d'E/S SBB et le fond de panier central. Actions recommendées: •Aucune action n'est requise. | ||
| 603 Erreur, Avertissement | Une condition d'alerte a été détectée au niveau de l'élement SAS Connector (connecteur SAS). L'élement SAS Connector rapporte les informations d'état des connecteurs de port SAS internes et externes. Actions recommendées: •Contactez le support technique. •Lorsque le problème est résolu, un événement portant le même code est consigné avec une gravité de niveau Résolu. | |
| Info., Résolu Une condition d'alerte a été détectée au niveau de l'élement SAS Connector (connecteur SAS). L'élement SAS Connector rapporte les informations d'état des connecteurs de port SAS internes et externes. Actions recommendées: •Aucune action n'est requise. | ||
| 604 Avetissement Une tentative d'exercution d'un snapshot de réalisation a échoué. Un ensemble de réalisation a été configuré pour conserver les snapshots du volume. Une erreur peut survenir en cas d'échéance du snapshot. Actions recommendées: •Surveillance l'intérêté du système local, de l'ensemble de réalisation, du volume et de la connexion homologue. Un pool de stockage plein peut être la cause de cette panne. •Vérifiez l'intérêté et l'état du système de connexion homologue. •Assurez-vous que le nombre maximum de snapshots pouvant être mis sous licence (indiqué par la commande CLI show license) n'a pas été dépasse. | ||
| 605 Avetissement Cœur deTraitement inactif. Le module de contrôleur est doté de plusieurs cœurs de traitement. Le système dispose de suffisamment de cœurs actifs pour fonctionner, mais les performances sont dégradées. Actions recommendées: •Essayez de redémarrer tous les cœurs de traitement comme suit: •Arrêtez le module de contrôleur ayant consigné cet événement. •Retirrez le module de contrôleur, attendez 30 secondes, puis réinsérez-le. •Si cet événement est consigned à nouveau, contactez le support technique. | ||
| 606 Erreur Un contrôleur contient des données de cache non écrites pour un volume, et son supercondensateur n'a pas fonctionné. En cas de panne du supercondensateur, si le contrôleur n'est plus alimenté, il ne dispose pas d'une alimentation de secours lui permettant de vider les données non écrites du cache vers la carte eMMC. Actions recommendées: •Vérifiez que la(Strategie d'écriture dans le cache est définitie sur la double écrite pour tous les volumes. •Contactez le support technique pour en savoir plus sur le remplacement du module de contrôleur. | ||
| 607 Avetissement Le contrôleur local redémarre l'autre contrôleur. Actions recommendées: •Aucune action n'est requise. | ||
| 608 Erreur Une erreur de câblage back-end a été détectée. | ||
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| Actions recommendées: •Si le message indique que les deux contrôleurs sont connectés avec un type d'erreur indéfini, l'un des cables est mal connecté au port de sortie du contrôleur, formant une boucle dans la topologie SAS. Vérifiez le câblage back-end de chaque port de sortie du contrôleur pour identifier le branchement incorrect. •Si le message indique que les ports de sortie du contrôleur sont connectés l'un à l'autre, l'un des cables est mal raccordé au port de sortie du contrôleur, formant une boucle dans la topologie SAS. Vérifiez le câblage back-end et assurez-vous que les cables SAS sont raccordés aux portes appropriés pour le port spécifique. •Si le message indique qu'une boucle EBOD a été créé, l'un des cables est mal raccordé au port de sortie d'un boîtier d'extension, formant une boucle dans la topologie SAS. Vérifiez le câblage back-end et assurez-vous que les cables SAS sont raccordés aux portes appropriés pour le port spécifique. •Si le message indique qu'un cable est connecté au port central, mais que ce port n'est pas pris en charge, vérifie le câblage back-end et assurez-vous que les cables SAS sont bien reliés aux portes appropriés pour le port spécifique. Déplacez le cable du port central de l'IOM vers le port de gauche ou de droite, comme il convient. | ||
| 609 Erreur | Un condition d'alerta et éte déetectée sur un élément de verrouillage de la porte. L'élement de verrouillage de la porte signale un état associé au tiroir du boîtier. Le tiroir a été signalé comme ouvert pendant une longue période. Cela peut entraver le refroidissement, et pourrait cause une surchauffe du boîtier. | Actions recommendées: •Vérifiez que le tiroir est bien fermé et verrouillé. Lorsque le problème est résolu, un événement portant le même code est consigné avec une gravité de niveau Résolu. |
| Info. Une condition d'alerta et éte déetectée sur un élément de verrouillage de la porte. L'élement de verrouillage de la porte signale un état associé au tiroir du boîtier. Le capteur de tiroir le signale comme désinstallé. | Actions recommendées: •Aucune action n'est requise. | |
| Résolu Une condition précedente de type Informatif ou Erreur a été résolu au niveau de l'élement de verrouillage de la porte. | Actions recommendées: •Aucune action n'est requise. | |
| 610 Erreur | Une condition d'alerta et éte déetectée sur un élément du fond de panier latéral. | Actions recommendées: •Vérifiez que le tiroir du fond de panier latéral indiqué est bien fermé et verrouillé. ▲PRÉCAUTION: Les fonds de panier latéaux sur les tiroirs de boîtier ne sont pas échangeables à chaud et ne peuvent pas faire l'objet de maintenance par le service clientèle. •Si les actions recommendées ne permettent pas de résoudre le problème, contactez le support technique. Le boîtier doit être remplace. |
| Avertissement U | Une condition d'alerta et éte déetectée sur un élément du fond de panier latéral. Actions recommendées: •Le fond de panier latéral associé au tiroir doit être installé. Contactez le support technique. ▲PRÉCAUTION: Les fonds de panier latéaux sur les tiroirs de boîtier ne sont pas échangeables à chaud et ne peuvent pas faire l'objet de maintenance par le service clientèle. | |
| Résolu Une condition précedente de type Avertissement ou Erreur a été résolu au niveau de l'élement de fond de panier latéral. | Condition précedente de type Avertissement ou Erreur a été résolu au niveau de l'élement de fond de panier latéral. |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| Actions recommendées:●Aucune action n'est requise. | ||
| 611 Erreur | La notification par e-mail a échoué pour l'une des raisons suivantes:●Un serveur SMTP inaccessible ou une différence entre les domains de l'expéditeur et du serveur SMTP●Une configuration incorrecte.Actions recommendées:●Vérifiez les paramètres configurés et demandez aux destinataires de confirmer qu'ils ont reçu le message. | |
| Info. Notification par e-mail envoyée avec succès. Demandez aux destinataires de confirmer qu'ils ont reçu le message.Actions recommendées:●Vérifiez les paramètres configurés et demandez aux destinataires de confirmer qu'ils ont reçu le message. | ||
| 612 Info. | Une condition d'alerte a été détectée au niveau d'un connecteur SAS interne du châssis.Les message de l'évenement indique l'emplacement du connecteur SAS interne dans le châssis.Actions recommendées:●Aucune action n'est requise. | |
| 613 Erreur | Une condition d'alerte a été détectée au niveau d'un IOM.Actions recommendées:●Installez l'IOM indiqué ou tentez de le replacer.Si le problème persiste, remplacez l'IOM. | |
| Avertissement Une condition d'alerte a été détectée au niveau d'un IOM.Actions recommendées:●S'il est désinstallé, installez l'IOM indiqué. Sinon, tentez de le replacer.Si le problème persiste, remplacez l'IOM. | ||
| Info. Un IOM a été désinstallé.Actions recommendées:●Aucune action n'est requise. | ||
| Résolu Une condition précédente de type Avertissement ou Erreur a été résolue au niveau de l'IOM.Actions recommendées:●Aucune action n'est requise. | ||
| 614 Info. | Efface l'état dégradé du disque indiqué.Actions recommendées:●Aucune action n'est requise. | |
| 615 Info. | Une opération de rééquilibrage de groupe de disques ADAPT a démarré.Actions recommendées:●Aucune action n'est requise. | |
| 616 Averissment Une opération de rééquilibrage de groupe de disques ADAPT n'a été exécutée que partiellement.Actions recommendées:●Aucune action n'est requise. | ||
| Info. Une opération de rééquilibrage de groupe de disques ADAPT s'est terminée. | ||
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| Actions recommendées:●Aucune action n'est requise. | ||
| 617 Aventisement La capacité de secours cible n'est pas atteinte.Cet événement indique que l'espace disponible dans le système est insuffisant pour fournir le niveau complet de tolérance de panne spécifique par la capacité de secours cible. La disponibilité de la capacité cible peut être affectée par les opérations requérant de l'espace disponible dans le système, par exemple, la reconstruction des données à partir d'un disque défaillant.Actions recommendées:●Ajoutez des disques au groupe de disques, ou remplacez les disques en panne. Le système augmente automatiquement la capacité de secours pour répondre aux exigences placées sur le système par la capacité de secours cible. | ||
| 618 Résolu La capacité de secours cible est atteinte.Actions recommendées:●Aucune action n'est requise. | ||
| 619 Info. | Une panne a étéjectée dans le contrôleur pour introduire une erreur de liaison au niveau du récepteur.Actions recommendées:●Aucune action n'est requise. | |
| 620 Erreur Le zone du module d'extension est activé, ce qui peut limiter l'accès au disque.L'accès au disque change en fonction du port utilisé pour vous connecter au module d'extension.Actions recommendées:●Chargez une offre groupée de firmware valide pour désactiver le zone. | ||
| Résolu Le zone du module d'extension a été désactivé pour le boîtier indiqué.Actions recommendées:●Aucune action n'est requise. | ||
| 621 Info. | L'opération de rééquilibrage du disque ADAPT dégradé a démarré. Cette opération prend des zones de bandes tolérantes aux pannes et les dégrade afin que les zones de bande critiques poussent être dégradées.Actions recommendées:●Aucune action n'est requise. | |
| 622 Info. | L'opération de rééquilibrage du disque ADAPT dégradé est terminée. cette opération prend des zones de bandes tolérantes aux pannes et les rend dégradées afin que les zones de bande critiques poussent être dégradées.Actions recommendées:●Aucune action n'est requise. | |
| 623 Info. | Des paramètres de configuration du contrôleur de gestion ont été définis.Un ou plusieurs paramètres de configuration associés au contrôleur de gestion ont été modifiés, comme la configuration du SNMP, SMI-S (non pris en charge sur le système ME5084), la notification par e-mail et les chaînes système (nom du système, emplacement du système, etc.).Actions recommendées:●Aucune action n'est requise. | |
| 626 Info. | Détention d'un TPIID non pris en charge (ID de type fond de panier central).Actions recommendées:●Aucune action n'est requise. | |
| 628 Erreur Une non-correspondance de firmware a été identifiée pour le boîtier d'extension. | ||
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| Une non-correspondance de firmware peut provenir de la connexion d'un boîtier configuré en tant que JBOD (au lieu de EBOD) ou de l'installation d'un nouveau module FRU IOM avec un firmware incompatible. Actions recommendées: • Mettez à jour le firmware vers le niveau approprié pour connecter les boîters d'extension au boîtier du contrôleur. •Si vous receivez cet événement alors qu'aucun nouveau boîtier ou module IOM n'a été ajouté, veuillez contacter le support technique. | ||
| 630 Info | Un disque a démaché ré une opération de refabrication/reconstruction. L'opération entraîne une réduction de la capacité. Ne remplacez pas le disque tant que l'opération de refabrication/reconstruction n'est pas terminée. Cette opération peut prendre beaucoup de temps et l'achèvement est indiqué par l'événement 631. Actions recommendées: •Aucune action n'est requise. | |
| 631 Averississement Échéance d'une opération de refabrication/reconstruction. Le disque doit être remplace. Actions recommendées: •Remplacez le disque par un disque du même type et de capacité supérieure ou égale. Pour des performances d'E/S optimales en continu, le disque de remplacement doit fournir des performances identiques ou supérieures à celles du disque qu'il remplace. | ||
| Info Une opération de refabrication/reconstruction de disque s'est terminée avec succès. Actions recommendées: •Aucune action n'est requise. | ||
| 632 Erreur Un échec de restauration du vilage s'est produit. Un contrôle d'intégrité a échoué sur les données restaurées à partir du cache. Actions recommendées: •Prévoyez du temps pour que le contrôleur partenaire recupère les données et annule l'arrêt forcé du contrôleur. | ||
| 635 Avertissemment Un paragemètre PHY du contrôleur d'E/S a été modifié par un utilisateur. Actions recommendées: •Aucune action n'est requise. | ||
| 636 Erreur L'autre contrôleur a arrêté de force ce contrôleur pour une raison inconnue. Le système se restaque automatiquement. Actions recommendées: •Collectez les journaux et contactez le support technique pour obtenir de l'aide. | ||
| 637 Erreur L'autre contrôleur a arrêté de force ce contrôleur parle cullie a cession de répondre via l'intercontrôleur Heartbeat. Le système se restaque automatiquement. Actions recommendées: •Collectez les journaux et contactez le support technique pour obtenir de l'aide. | ||
| 638 Erreur Il s'agit d'un accès illégal à la mémoire par le processeur. Le système se restaque automatiquement. Actions recommendées: •Collectez les journaux et contactez le support technique pour obtenir de l'aide. | ||
| 639 Erreur Violation d'accès dans le logiciel. Le système se restaque automatiquement. Actions recommendées: •Collectez les journaux et contactez le support technique pour obtenir de l'aide. | ||
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre G | Gravité Description | /actions recommendées |
| 640 Erreur Le logiciel a tené | é de divisor par 0. Le système se restaque automatiquement. Actions recommendées: •Collectez les journaux et contactez le support technique pour obtaining de l'aide. | |
| 641 Erreur Détction d'une | erreur d'assertion ou de débogage OSM. Le système se restaque automatiquement. Actions recommendées: •Collectez les journaux et contactez le support technique pour obtaining de l'aide. | |
| 642 Erreur Détction d'une | erreur de panne PCI. Le système se restaque automatiquement. Actions recommendées: •Collectez les journaux et contactez le support technique pour obtaining de l'aide. | |
| 643 Erreur Détction d'une | erreur de panne d'interruption non masquable. Le système se restaque automatiquement. Actions recommendées: •Collectez les journaux et contactez le support technique pour obtaining de l'aide. | |
| 644 Erreur Impossible de télécharger le firmware sur le système car la signature du chiffrement ou de l'offre groupée n'est pas valide. Actions recommendées: •Vérifie que vous utilisez l'offre groupée de firmwares appropriée. | ||
| Avertissement Impossible de télécharger le firmware sur le système, car l'offre groupée de firmware utilise un format obsolète. Actions recommendées: •Vérifie que vous utilisez l'offre groupée de firmwares appropriée. | ||
| Info. Firmware telécharge avec succès sur le système. Actions recommendées: •Aucune action n'est requise. | ||
| 645 Critique Impossible de | éçupérer les données FRU valides. Actions recommendées: •Collectez les journaux et contactez le support technique pour obtaining de l'aide. | |
| 646 Info. | Indique l'une des modifications suivantes dans SupportAssist: •État modifié •Coordonnées modifiées •Paramètres de proxy modifiés ou effacés •Mode de fonctionnement modifié •Paramètres modifiés Actions recommendées: •Aucune action n'est requise. | |
| 647 Erreur Ce contrôleur de stockage redémarre en raison d'une erreur interne. Ce contrôleur de stockage a retrtré un blocage de l'interface de gestion et va redémarrer afin d'effectuer une restauration. Actions recommendées: •Collectez les journaux et contactez le support technique pour obtaining de l'aide. | ||
| 648 Erreur Échec du chargement des journaux SupportAssist, de la configuration CloudIQ ou des données de performances. Actions recommendées: •Aucune action n'est requise. |
Tableau 28. Descriptions des événements et actions recommandées (suite)
| Nombre Gravité Description /actions recommendées | |
| 649 Avetissement Une mise à jour de firmware du contrôleur est disponible pour votre système.Actions recommendées :Accédez à https:// Dell.com/support, saisissez votre numéro de série et téléchargez la mise à jour.Vous pouvez ensuite utiliser la fonctionnalité de mise à jour du firmware de PowerVault Manager pour effectuer la mise à jour. | |
| 650 Avetissement Une mise à jour de firmware du disque est disponible pour votre système.Actions recommendées :Accédez à https:// Dell.com/support, saisissez votre numéro de série et téléchargez la mise à jour.Vous pouvez ensuite utiliser la fonctionnalité de mise à jour du firmware de PowerVault Manager pour effectuer la mise à jour. | |
| 655 InfoÉché/créussite de l'envoi de la télémethrie SupportAssist. (Type de charge utile : configuration CloudIQ)Actions recommendées :Aucune action n'est requise. |
Connexion à l'interface de ligne de commande
Vous pouvez accéder à l'interface de ligne de commande à l'aide d'un cable micro-USB et d'un logiciel d'emulation de terminal.
- Connectez un câble micro-USB d'un ordinateur au port d'interface de ligne de commande du module de contrôleur A.
- Démarrer un émulateur de terminal et configurez les paramètres d'affichage et de connexion suivants :
Tableau 29. Paramètres d'affichage de l'émulateur de terminal
| Paramètre Valeur | |
| Mode d'émulation de terminal VT-100 ou ANSI (pour la prise en charge des couleurs) | SI (pour la prise en charge des couleurs) |
| Police Terminal | |
| Traductions Aucun | |
| Colonnes 80 |
Tableau 30. Paramètres de connexion de l'émulateur de terminal
| Paramètre Valeur | |
| Connecteur COM3 (par exemple) | 1,2 |
| Débit en bauds 115 200 | |
| Bits de données 8 | |
| Parité Aucun | |
| Bits d'arrêt 1 | |
| Contrôle du débit Aucun |
1 La configuration de votre ordinateur identifie le port COM utilisé pour le port USB de la baie de disques. 2 Vérifiez quel port COM doit être utilisé avec l'interface CLI.
- Si nécessaire, appuyez sur Entrée pour afficher l'invite de connexion.
a. À l'invite de connexion, saisissez le nom d'utilisateur d'un utilisateur pourvu du rôle de gestion, puis appuyez sur Entrée. b. À l'invite de saisie du mot de passe, saisissez le mot de passe de l'utilisateur, puis appuyez sur Entrée.
- Connexion de périphérique micro-USB
Connexion de périphérique micro-usb
Les sections suivantes décrivent la connexion au port micro-USB :
Port série émule
Lorsqu'un ordinateur est connecté à un module de contrôleur à l'aide d'un câble série micro-USB, le contrôleur présente un port série émulé à l'ordinateur. Le nom du port série émulé s'affiche avec un ID de fournisseur client et un ID de produit. La configuration du port série n'est pas nécessaire.

REMARQUE: Certains systèmes d'exploitation requièrent un pilote de périhérique ou un mode de fonctionnement spécial pour que le port CLI USB soit opérationnel. Consultez également la section Pilote de périhérique/Mode de fonctionnement spécial.
Applications hôteprises en charge
Les applications d'émulation de terminal ci-dessous peuvent être utilisées pour communiquer avec un module de contrôleur Série ME5 :
Tableau 31. Applications prises en charge pour l'émulation de terminal
| Application Système d'exploitation | |
| PuTTY Microsoft Windows (toutes les versions) | |
| Minicom Linux (toutes les versions) |
Interface de la ligne de commande
Lorsque l'ordinateur détecte une connexion au port série émulé, le contrôleur attend que des caractères soient saisis depuis l'ordinateur à l'aide de l'interface de ligne de commande. Pour afficher l'invite de l'interface CLI, vous devez appuyer sur la touche Entrée.

REMARQUE: Le câblage direct vers le port micro-USB est considéré comme une connexion hors bande, dans la mesure où elle se situe en dehors des chemins d'accès des données standard vers le boîtier de contrôleur.
Pilote de périphérique/mode de fonctionnement spécial
Certains systèmes d'exploitation nécessitent un pilote de périphérique ou un mode spécial de fonctionnement. Le tableau suivant indique les informations d'identification des produits et des fournisseurs requises pour certains systèmes d'exploitation :
Tableau 32. Code d'identification USB
| Type de code d'identification USB Code | |
| ID de fournisseur USB 0x210C | |
| ID de produit USB 0xA4A7 |
Les systèmes d'exploitation Windows Server 2016 et versions ultérieures fournissent un pilote série USB natif qui prend en charge le port micro-USB.
Les systèmes d'exploitation Linux ne nécessitant pas l'installation d'un pilote USB Série ME5. Toutefois, certains paramètres doivent être saisis lors du chargement du pilote afin d'activer la reconnaissance du port micro-USB sur un module de contrôleur Série ME5.
Saisissez la commande suivante pour charger le pilote de périhérique Linux avec les paramètres requis pour la reconnaissance du port micro-USB :
modprobe usbserial vendor=0x210c product=0xa4a7 use_acm=1

REMARQUE : Si vous le souhaitez, vous pouvez inclure ces informations dans le fichier /etc/modules.conf.
Dimensions du boîtier
Tableau 33. Dimensions des boîtiers 2U12 et 2U24
| Spécification mm pouces | ||
| Hauteur 87,9 mm 3,46 pouces | ||
| Largeur 483 mm 19,01 pouces | ||
| Profondeur (boîtier 2U12) 618,7 mm 24,36 pouces | ||
| Profondeur (boîtier 2U24) 547,8 mm 21,56 pouces |
Le boîtier 2U12 utilise des disques de grand format de 3,5 pouces. Le boîtier 2U24 utilise des disques de format compact de 2,5 pouces.
Tableau 34. Dimensions du boîtier 5U84
| Spécification mm pouces | ||
| Hauteur 222,3 mm 8,75 pouces | ||
| Largeur 483 mm 19,01 pouces | ||
| Profondeur | 981 mm | 38,62 pouces |

REMARQUE : Le boîtier 5U84 utilise des disques de grand format de 3,5 pouces dans le support DDIC. Il peut aussi utiliser des disques de format compact de 2,5 pouces avec un adaptateur de 3,5 pouces dans le support DDIC.
Poids du boîtier
Tableau 35. Poids des boftiers 2U12, 2U24 et 5U84
| Composant CRU | 2U12 (kg/lb) | 2U24 (kg/lb) | 5U84 (kg/lb) |
| Boîtier de stockage (vide) | 4,8/10,56 | 4,8/10,56 | 64/141 |
| Support de disque | 0,9/1,98 | 0,3/0,66 | 0,8/1,8 |
| Support de lecteur de disque vierge | 0,05/0,11 | 0,05/0,11 | — |
| Module de refroidissement de l'alimentation (PCM) | 3,5/7,7 | 3,5/7,7 | — |
| Bloc d'alimentation (PSU) | — | — | 2,7/6 |
| Module de refroidissement par ventilateur (FCM) | — | — | 1,4/3 |
| Module de contrôleur SBB (poids maximum) | 2,6/5,8 | 2,6/5,8 | 2,6/5,8 |
| Module d'extension SSB 1,5/3,3 | 1,5/3,3 | 1,5/3,3 |
Tableau 35. Poids des boîtiers 2U12, 2U24 et 5U84 (suite)
| Composant CRU 2U12 (kg/lb) 2U24 (kg/ | b) 5U84 (kg/lb) | ||
| Boftier RBOD (rempli de modules : poids maximum) | 32/71 30/66 135/298 | ||
| Boftier EBOD (rempli de modules : poids maximum) | 28/62 25/55 130/287 |
- Les poids indiqués sont nominaux et peuvent être modifiés.
- Les charges peuvent varier en fonction des différents modules de contrôle, IOM et blocs d'alimentation, ainsi qu'en fonction des différences de calibrage entre les échelles. Le poids peut également varier en fonction du nombre et du type de lecteurs de disque (SAS ou SSD) installés.
Exigences environnementales
Tableau 36. Température ambiantes et humidité
| Spécification Plage de températures Humidité relative Thermomètre | mouillé | max. |
| En fonctionnement | •RBOD: de 5 °C à 35 °C (41 °F à 95 °F) •EBOD: de 5 °C à 40 °C (41 °F à 104 °F) | 20 à 80 % (sans condensation) 28 °C |
| Hors fonctionnement (à l'envoi) | -40 °C à 70 °C (-40 °F à 158 °F) Sans condensation, 5 % à 100 % 29 °C |
Tableau 37. Autres exigences environnementales
| Spécification Mesure/description | |
| Ventilation | •Le système doit être utilisé uniquement avec l'installation d'une évacuation arrière à basse pression.La contre-pression créé par les portes de rack et les obstacles ne doit pas dépasser 5 Pa (~0.5 mm H2O) |
| Altitude en fonctionnement | •Boîtier 2U: 0 à 3 000 mètres (0 à 10 000 pieds)•La température de fonctionnement maximum est diminuée de 5 °C au-dessus de 2 133 mètres (7 000 pieds) |
| •Boîters 5U84: -100 à 3 000 mètres (-330 à 10 000 pieds)•La température de fonctionnement maximum est diminuée de 1 °C au-dessus de 900 mètres (3 000 pieds) | |
| Altitude hors fonctionnement -100 à 12 192 mètes | (-330 à 40 000 pieds) |
| Choc en fonctionnement 5 g, 10 ms, pulsation | semi-sinusoidales, axe Y |
| Choc hors fonctionnement | Boîters 2U: 30,0 g, 10 ms, pulsations semi-sinusoidales |
| Boîters 5U84: 30 g, 10 ms, pulsations semi-sinusoidales (axe Z): 20,0 g, 10 ms, pulsations semi-sinusoidales (axes X et Y) | |
| Vibration en fonctionnement | 0,21 Grms 5 Hz à 500 Hz, aléatoire |
| Vibrations hors fonctionnement | 1,04 Grms 2 Hz à 200 Hz, aléatoire |
| Vibration en transfert 0,3 G | rms 2 Hz à 200 Hz 0,4 décennie par minute |
| Acoustique | Puisance sonore de fonctionnement•Boîters 2U: < L WAd 6,6 Bels (re 1 pW) à 23°CCoBieters 5U84: < L WAd 8,0 Bels (re 1 pW) à 23°C |
Tableau 37. Autres exigences environnementales (suite)
| Spécification Mesure/description | |
| Orientation et montage Montage en rack 19 pôces (2 unités EIA ; 5 unités EIA) | |
Module de refroidissement de l'alimentation
Les spécifications du module PCM sont fournies dans le tableau suivant.
Tableau 38. Spécifications du module d'alimentation et de refroidissement 2U
| Spécification Mesure/description | ||
| Dimensions (taille) 84,3 mm (hauteur) x 104,5 mm (largeur) x 340,8 mm (longueur):Longueur de l'axe X:104,5 mm (4,11 pouces)Longueur de l'axe Y:84,3 mm (3,32 pouces)Longueur de l'axe Z:340,8 mm (37,03 pouces) | mm (largeur) x 340,8 mm (longueur):Longueur de l'axe X:104,5 mm (4,11 pouces)Longueur de l'axe Y:84,3 mm (3,32 pouces)Longueur de l'axe Z:340,8 mm (37,03 pouces) | |
| Alimentation de sortie maximale 580 W | ||
| Plage de tension 100-200 V CA | ||
| Fréquence 50/60 Hz | ||
| Sélection de la plage de tension Automatique | 90-264 V CA, 47-63 Hz | |
| Courant d'appel maximal 20 A | ||
| Power factor correction Tension d'entrée normale > 95 % | inmale > 95 % | |
| Efficacité 115 V CA/60 Hz 230 V CA/50 Hz | ||
| >80 % à 10 % de charge > | 80 % à 10 % de charge | |
| >87 % à 20 % de charge > | 88 % à 20 % de charge | |
| >90 % à 50 % de charge > | 92 % à 50 % de charge | |
| >87 % à 100 % de charge | >88 % à 100 % de charge | |
| >85 % en surtension | >85 % en surtension | |
| Courant harmonique | Conforme à la norme EN61000-3-2 | |
| Sortie | +5 V@ 42A, +12 V@ 38A, +5 V tension en veille @ 2.7A | |
| Plage de températures de fonctionnement | De 0 °C à 57 °C (32 °F à 135 °F) | |
| Enflichable à chaud | Oui | |
| Commutateurs et voyants | Commutateur d'alimentation principal et quatre voyants d'état | |
| Refroidissement du boîtier | Ventilateur de refroidissement à deux axes avec contrôle de vitesse variable | |
Bloc d'alimentation
Tableau 39. Caractéristiques du bloc d'alimentation pour 5U84
| Spécification Mesure/description | |
| Alimentation de sortie maximale Alimentation | de sortie continue maximale de 2 214 W à haute tension |
| Tension | •+12 V, à 183 A (2 196 W) •Tension en voille +5 V, à 2,7 A |
| Plage de tension | 200 à 240 V CA |
| Fréquence | 50/60 Hz |
Tableau 39. Caractéristiques du bloc d'alimentation pour 5U84 (suite)
| Spécification Mesure/description | |
| Power factor correction > 95 % à 100 % de charge | |
| Efficacité | •> 82 % à 10 % de charge •> 90 % à 20 % de charge •> 94 % à 50 % de charge •> 91 % à 100 % de charge |
| Temps de retard 5 ms entre l'ACOKn supérieur et les rails hors rigementsation (consultez la spécification SBB v2) | |
| Connecteur d'entrée principal IEC60320 C20 | avec rétention des cables |
| Poids 3 kg (6,6 lb) | |
| Ventilateurs de refroidissement Deux ventilateurs emplés : 80 mm x 80 mm x 38 mm (3,1 x 3,15 x 1,45 pouces) | |
Risque d'interférences radioélectriques
Commission fédérale des communications des États-Unis (FCC)

REMARQUE : Cet équipement a été testé et déclaré conforme aux limites d'un appareil numérique de classe A, conformément à la partie 15 des règles de la FCC. Ces limites sont conçues pour fournir une protection raisonnable contre les interférences nuisibles lorsque l'équipement est utilisé dans un environnement commercial. Cet équipement génère, utilise et peut émettre de l'énergie radiofréquence et, s'il n'est pas installé et utilisé conformément au manuel d'instructions, peut causer des interférences nuisibles aux communications radio. L'utilisation de cet équipement dans une zone résidentielle est susceptible de causer des interférences nuisibles, auquel cas l'utilisateur devra corriger les interférences à ses frais.
Des câbles et connecteurs correctement blindés et mis à la terre doivent être utilisés afin de respecter les limites d’émission de la FCC. Le fournisseur n’est pas responsable des interférences radio ou télévision causées par l’utilisation de câbles et connecteurs autres que ceux recommendés ou par des changements ou modifications non autorisés de cet équipement. Tout changement ou modification non autorisé pourrait annuler l’autorisation de l’utilisateur d’utiliser l’équipement.
Cet appareil est conforme à l'article 15 du règlement de la FCC. L'utilisation est soumise aux deux conditions suivantes : (1) cet appareil ne doit pas causer d'interférences nuisibles, et (2) cet appareil doit accepter toute interference reçue, y compris les interférences qui peuvent causer un fonctionnement non désiré.
Réglementation européenne
Cet équipement est conforme à la réglementation Européenne EN 55022 Classe A : Limites et méthodes de mesure des caractéristiques des perturbations radioélectriques des équipements informatiques et EN50082-1 : Immunité générique.
Ce produit n'est pas adapté pour une utilisation dans des espaces de travail comprenant des affichages visuels conformément au paragraphe 2 des réglementations relatives au lieu de travail.
Conformité en matière de sécurité
Tableau 40. Normes de conformité en matière de sécurité
| Homologation de type du produit du système | Standard |
| Conformité en matière de sécurité | UL 60950-1 |
| UL 62368-1 | |
| IEC 60950-1 | |
| IEC 62368-1 | |
| EN 60950-1 | |
| EN 62368-1 |
Conformité à la compatibilité électromagnétique (EMC)
Tableau 41. Normes de conformité EMC
| Homologation de type du produit du système | Normes |
| Niveaux limites d'émissions par conduction | CFR47 partie 15B classe A |
| EN 55032 | |
| CISPR classe A | |
| Niveaux limites d'émissions de rayons | CFR47 partie 15B classe A |
| EN 55032 | |
| CISPR classe A | |
| Harmoniques et scintillagement EN 61000-3-2/3 | |
| Niveaux limites d'immunité EN 55024 | |
Caractéristiques des câbles d'alimentation CA
Tableau 42. États-Unis d'Amérique : ils doivent être répertoriés dans les listes établies par les laboratoires de test reconnus au niveau national (NRTL), par exemple le laboratoire UL :
| Encombrement du châssis 2U12/2 | U24 5U84 | |
| Type de cable SV ou SVT, 18 AWG minimum, trois conducteurs, longueur maxi 2 m | SJT ou SVT, 12 AWG minimum, trois conducteurs | |
| Prise de courant (source d'alimentation CA) | Fixation de mise à la terre NEMA 5-15P120 V, 10 AIEC 320, C14, 250 V, 10A | IEC 320, C20, 250 V, 20AUne prise adaptée 250 V, 20 A |
| Socket IEC 320, C13, 250 V, 10A IEC | 520, C19, 250 V, 20A | |
Tableau 43. Europe et autres : conditions générales
| Encombrement du châssis 2U12/2 | U24 5U84 | |
| Type de cable Harmonisées, H05VV-F-3G1.0 Harmonisées, H05VV-F-3G2.5 | ||
| Prise de courant (source d'alimentation CA) | IEC 320, C14, 250 V, 10AUne prise adaptée 250 V, 16A | IEC 320, C20, 250 V, 16AUne prise adaptée 250 V, 16A |
| Socket IEC 320, C13, 250 V, 10A IEC | 520, C19, 250 V, 16A | |

REMARQUE: La prise de courant et l'assemblage du câble d'alimentation doivent être conformes aux normes en vigueur dans le pays et doivent être homologués par un organisme de sécurité reconnu dans ce pays.
Recyclage des déchets d'équipements électriques et électroniques (DEEE)
En fin de vie du produit, tous les déchets/déchets d'équipements électriques et électroniques doivent être recyclés conformément aux réglementations nationales applicables à la manipulation des déchets électriques et électroniques dangereux/toxiques.
Contactez votre fournisseur pour obtenir un exemplaire des procédures de recyclage applicables dans votre pays.

REMARQUE : Respectez toutes les précautions de sécurité détaillées applicables dans les chapitres précédents (restrictions de poids, de manipulation des batteries et des lasers, et ainsi de suite) lors du démontage et mise au rebut de cet équipement.


- Système de stockage dell powervault série ME5
- Chapitre 1: matériel du système de stockage. 6
- Chapitre 2: dépannage et résolution des problèmes 26
- Chapitre 3: retrait et remplacement d'un module. 44
- Chapitre 4: événements et messages d'événement. 74
- Annexe a: connexion à l'interface de ligne de commande 139
- Annexe c: normes et réglementations 145
- Publications connexes
- Matériel du système de stockage
- Repérez le numéro de série
- Configurations du boîtier
- Mise à jour vers une configuration à deux contrôleurs
- Retrait du deuxième contrôleur
- Gestion du boîtier
- Interfaces de gestion
- Fonctionnement
- Variantes de boîtiers
- 2U24
- Produit de base du boîtier 2U
- Panneau avant du boîtier 2U
- Panneau arrêté du boîtier 2U
- Composants du panneau arrière du boîtier 2U
- Module de contrôleur
- Module IOM du boîtier d'extension
- Module de refroidissement de l'alimentation
- Produit de base du boîtier 5U84
- Remarque:
- Panneau avant du boîtier 5U84
- Panneau arrêté du boîtier 5U84
- Composants du panneau arrêté 5U84
- Modules de contrôleur
- Module d'extension
- Module d'alimentation
- Comportement du voyant :
- Module de refroidissement par ventilateur
- Chassis de boîtier 5U84
- Tiroirs du boîtier 5U84
- Fonctionnalités de sécurité
- Figure 22. Détails sur l'encadrement des tiroirs
- Voyants du panneau OPS
- Panneau OPS du boîtier 2U
- Panneau des opérations du boîtier 5U
- Voyants du module de contrôleur 12 gbit/s
- Description des LED d'état de la mémoire cache
- Comportement pendant la mise sous/hors tension
- Comportement : état de la mémoire cache
- Panne de contrôle lorsqu'un seul contrôle est opérationnel
- Voyant LED d'état de la mémoire cache : action corrective
- Dépannage et résolution des problèmes
- Méthodologie de localisation des pannes
- Options disponibles pour l'exécution des étapes de base
- Utilisez powervault manager
- Utilisez le CLI
- Vérifiez les notifications d'événements
- Vérifiez les LED du boîtier
- Exécution des étapes de base
- Recueil des informations liées à la panne
- Determinez où la panne se produit
- Vérification des journaux d'événements
- Identifier la panne
- E/s hôte
- Les LED du boîtier 2U
- LED PCM du boîtier 2U
- LED du panneau OPS du boîtier 2U
- Actions:
- Les LED du module support de lecteur de disque du boîtier 2U
- Voyants du module d'e/s
- Voyants LED du boîtier 5U84
- Voyants LED du bloc d'alimentation ME5084
- Voyants LED du module FCM ME5084
- Voyants LED du panneau OPS ME5084
- Voyants LED du tiroir ME5084
- Voyants DDIC ME5084
- Voyants LED des modules de contrôleur 5U84 et d'e/s
- Problèmes de démarrage initiaux
- Dépannage des boîtiers 2U
- Pannes du PCM
- Surveillance et contrôle thermique
- Alarme thermique
- Dépannage des boîtiers 5U
- Considérations thermiques
- Si le boîtier ne démarre pas
- Correction des ID du boîtier
- Dépannage des pannes matérielles
- Identification d'une panne de connexion côté hôte
- Dépannage de connexion côte hôte avec ports hôtes 10gbase-t et SAS
- Identification d'une panne de connexion du port d'extension d'un module contrôleur
- Retrait et remplacement d'un module
- Mises en garde concernant les décharges électrostatiques (ESD)
- Prévention contre les décharges électrostatiques
- Méthodes de mise à la terre pour empêcher les décharges électrostatiques
- Traitement des pannes matérielles
- Precaution:
- Mises à jour de firmware
- Mise à jour du firmware partenaire
- Installation d'une offre groupée de firmwares
- Activation d'une offre groupée de firmwares
- Arrêt des hôtes rattachés
- Arrêt d'un module de contrôleur
- Utilisation de powervault manager
- Vérification de l'échéance d'un composant
- Unités remplaçables par l'utilisateur (CRU)
- Fixation ou retrait du panneau avant d'un boîtier 2U
- Remplacement d'un module support de lecteur dans un boîtier 2U
- Remplacement d'un module support de lecteur LFF
- Retrait d'un module support de lecteur LFF
- Installation d'un module support de lecteur LFF
- Remplacement d'un module support de lecteur SFF
- Retrait d'un module support de lecteur SFF
- Installation d'un module support de lecteur SFF
- Remise en place d'un module support de cache de lecteur
- Remplacement d'un support DDIC dans un boîtier 5U
- Installation d'un lecteur de disque de remplacement 2,5 pouces dans un DDIC (disk drive in carrier)
- Installation d'un lecteur de disque de remplacement 3,5 pouces dans un DDIC (disk drive in carrier)
- Accès aux tiroirs d'un chassin 5U84
- Ouverture d'un tiroir.
- Fermeture d'un tiroir
- Retrait d'un support DDIC à partir d'un boîtier 5U
- Installation d'un support DDIC dans un boîtier 5U
- Figure 56. installation d'un DDIC
- Remplissage des tiroirs
- Préparation
- Consignes d'installation
- Remplacement d'un module de contrôle ou d'un module d'e/s
- Remplacement d'un module de contrôleurs dans un boîtier de module à deux contrôleurs
- Retrait d'un module de contrôle d'un boîtier de module à deux contrôleurs
- Installation d'un module de contrôleur de remplacement dans un boîtier de module à deux contrôleurs
- Remplacement d'un module de contrôleurs dans un boîtier de module à contrôleur unique
- Retrait d'un module de contrôle d'un boîtier de module à contrôle unique
- Installation et configuration d'un module de contrôleur de remplacement dans un boîtier de module à contrôleur unique
- Retrait d'un module IOM
- Installation d'un IOM
- Remplacement d'un module de refroidissement de l'alimentation (PCM) dans un boîtier 2U
- Retrait d'un module de refroidissement de l'alimentation
- Installation d'un module de refroidissement de l'alimentation
- Remplacement d'un bloc d'alimentation dans un boîtier 5U
- Retrait d'un bloc d'alimentation
- Installation d'un bloc d'alimentation
- Remplacement d'un module de refroidissement par ventilateur (FCM) dans un boîtier 5U
- Installation d'un module de refroidissement par ventilateur
- Installation d'un module de ventilateur
- Exécution du processus d'installation des composants
- Vérification du bon fonctionnement du composant
- Utilisation des LED
- Utilisation des interfaces de gestion
- Exécution de mises à jour dans powervault manager après le remplacement d'un adaptateur HBA fibre channel ou SAS.
- Événements et messages d'événement
- Description des événements
- Connexion à l'interface de ligne de commande
- Connexion de périphérique micro-usb
- Port série émule
- Applications hôteprises en charge
- Interface de la ligne de commande
- Pilote de périphérique/mode de fonctionnement spécial
- Dimensions du boîtier
- Poids du boîtier
- Exigences environnementales
- Bloc d'alimentation
- Risque d'interférences radioélectriques
- Réglementation européenne
- Conformité en matière de sécurité
- Conformité à la compatibilité électromagnétique (EMC)
- Caractéristiques des câbles d'alimentation CA
- Recyclage des déchets d'équipements électriques et électroniques (DEEE)
Marque : DELL
Modèle : ME5024
Catégorie : Baie de disques